基于VSM的文件密級檢測系統(tǒng)設(shè)計(jì)與實(shí)現(xiàn)
2017-04-13 01:42:38張明星鄧時(shí)滔李海怒
軟件導(dǎo)刊 2017年3期
張明星,鄧時(shí)滔,李海怒
(中國核動(dòng)力研究設(shè)計(jì)院,四川 成都 610005)
基于VSM的文件密級檢測系統(tǒng)設(shè)計(jì)與實(shí)現(xiàn)
張明星,鄧時(shí)滔,李海怒
(中國核動(dòng)力研究設(shè)計(jì)院,四川 成都 610005)
基于科研單位內(nèi)部系統(tǒng)向外導(dǎo)出文件的實(shí)際情況,針對人工在對文件密級判定過程中存在效率低、易失誤等方面的局限,分析了向量空間模型、相似度算法和分詞技術(shù),設(shè)計(jì)了一套基于VSM的文件密級檢測系統(tǒng),將涉密文件資源庫中的文件轉(zhuǎn)化為向量從而構(gòu)建涉密文件向量集。系統(tǒng)運(yùn)行時(shí),將待檢測文件轉(zhuǎn)化為文件向量,并與向量集中的文件向量進(jìn)行余弦相似度計(jì)算,判斷待檢測文件密級,從而在一定程度上實(shí)現(xiàn)了基于內(nèi)容的密級檢測功能。實(shí)驗(yàn)結(jié)果表明,系統(tǒng)能夠在較短時(shí)間內(nèi)完成對文件密級的檢測,正確率較高,系統(tǒng)的應(yīng)用能夠有效提高密級文件管理的安全性和智能性。
向量空間模型;密級檢測;信息安全
0 引言
目前,政府機(jī)構(gòu)、科研單位、大型企業(yè)的內(nèi)部信息系統(tǒng)大多采用與國際互聯(lián)網(wǎng)等外部系統(tǒng)隔離的方式來確保內(nèi)部敏感信息的安全。在實(shí)際業(yè)務(wù)工作中,內(nèi)部與外部系統(tǒng)文件交換頻度高,在內(nèi)部文件信息向外部導(dǎo)出的過程中,如果依靠人工來判斷文件的密級,往往效率低下,而且由于文件多,存在人為判斷失誤導(dǎo)致涉密數(shù)據(jù)泄露的風(fēng)險(xiǎn),造成文件涉密內(nèi)容知悉范圍的擴(kuò)大。此外,如果密級文件的密級標(biāo)識被刪除,就需要人工對文件內(nèi)容進(jìn)行審查,無疑增大了文件密級判定的難度。因此,通過計(jì)算機(jī)信息化手段建立基于內(nèi)容的文件密級自動(dòng)檢測系統(tǒng),已成為防止內(nèi)部數(shù)據(jù)外泄的研究重點(diǎn),也是保障內(nèi)部系統(tǒng)數(shù)據(jù)安全的關(guān)鍵。
基于科研單位由內(nèi)向外導(dǎo)出文件的實(shí)際需求,內(nèi)部系統(tǒng)中的文件導(dǎo)出前,通過與當(dāng)前領(lǐng)域的涉密文件進(jìn)行相似度比對,對文件密級進(jìn)行檢測,相似度越大,說明文件相似程度越高,密級就類似,反之就越低。本文設(shè)計(jì)了一套涉密文件自動(dòng)檢測系統(tǒng),通過分詞算法對文件進(jìn)行分詞,采用空間向量模型對文件進(jìn)行重構(gòu),建立涉密文件向量集,根據(jù)計(jì)算文件向量之間的夾角余弦相似度完成對文件密級的檢測。
1 向量空間模型
向量空間模型(Vector Space Model,簡稱VSM)是一個(gè)關(guān)于文獻(xiàn)表示的統(tǒng)計(jì)模型,廣泛用于文本檢索、自動(dòng)文摘、文本分類和搜索引擎等信息檢索領(lǐng)域中[1]。根據(jù)向量空間模型的基本思想,將當(dāng)前涉密文件資源庫中全部m個(gè)涉密文件中所有詞條構(gòu)成一個(gè)n維向量空間V(t1、t2、t3...tn),其中n為詞條的總個(gè)數(shù)。對于文件資源庫中的每一個(gè)文件i(i=1,2,3,...,m),定義向量Vi=(wi1,wi2,wi3,...,win),其中win表示詞條tk(1≤k≤n)在文件i中的重要程度,即權(quán)重。權(quán)重的計(jì)算方法采用tf-idf公式[2-3]:
(1)
式(1)中,tfik表示詞條tk在涉密文件i中出現(xiàn)的次數(shù),即特征詞頻率,tfik越高意味著tk對于文件i越重要;dfk表示整個(gè)文件集合中包含詞條tk的文件個(gè)數(shù),即特征詞的文件頻率;N表示全部文件數(shù)量,分母為歸一化因子。idfk=log(N/dfk)為逆向文件頻率,idfk越高意味著詞條tk對于涉密文件的區(qū)別作用越大,權(quán)重也就越高。
對于待檢測的文件同樣需要被處理轉(zhuǎn)換為向量,并用與涉密文件向量集相同的方式表示,即n維向量,q=(wq1,wq2,wq3,...wqn)。待檢測的文件向量采用布爾框架進(jìn)行向量化,如果待檢測文件中包含詞條tk則權(quán)重為1,否則為0。
在涉密文件和待檢測文件向量化表示的基礎(chǔ)上,待檢測文件與各涉密文件之間的相似度通過對應(yīng)的向量在n維向量空間中的相對位置來確定,即通過計(jì)算兩個(gè)文件向量夾角的余弦函數(shù)確定文件的相似度[4],如式(2)所示:

(2)
2 系統(tǒng)設(shè)計(jì)
本文提出的基于VSM的文件密級檢測系統(tǒng)原理如圖1所示。
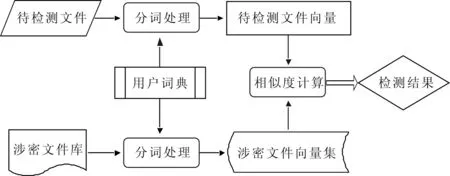
圖1 基于VSM的涉密文件檢測系統(tǒng)原理
系統(tǒng)主要流程為:
(1)文件預(yù)處理及涉密文件向量集建立。將當(dāng)前領(lǐng)域內(nèi)的所有涉密文件進(jìn)行匯總,形成文件庫。由于文件中包含有圖片、圖表等非文本信息,因此需對文件進(jìn)行預(yù)處理,即對文件進(jìn)行純文本提取。純文本提取主要將涉密文件庫中不同格式的文件轉(zhuǎn)化為統(tǒng)一的文件格式,去除文件中的圖像、標(biāo)點(diǎn)等非文本信息,以便能夠正確識別文件內(nèi)容并進(jìn)行下一步的分詞處理。本檢測系統(tǒng)主要涉及的文件格式為word格式,通過純文本提取技術(shù)將文件轉(zhuǎn)化為txt格式的文件。
由于中文語義的多樣性和領(lǐng)域中存在專業(yè)詞匯,分詞算法難以對一些詞匯進(jìn)行正確區(qū)分,從而影響分詞效果。因此需要建立用戶詞典,收集特定語義的詞匯和專業(yè)詞匯,在文件分詞過程中將涉及的相關(guān)詞匯加以正確區(qū)分。
通過向量空間模型算法建立涉密文件向量集是密級檢測系統(tǒng)的關(guān)鍵部分,式(1)在計(jì)算詞匯的權(quán)重時(shí)沒有考慮詞條在文檔中的位置對權(quán)重的影響[5]。一般而言,出現(xiàn)在封面和前言中詞條的重要程度高于出現(xiàn)在正文中的詞條,出現(xiàn)在封面中詞條的重要程度高于出現(xiàn)在前言中的詞條。因此,為有效提高文件相似度計(jì)算算法的精度,本文對傳統(tǒng)的向量空間模型權(quán)重計(jì)算方式進(jìn)行了改進(jìn),引入了詞條在文件中出現(xiàn)的位置因素。根據(jù)實(shí)際應(yīng)用情況,本系統(tǒng)將詞條出現(xiàn)的位置分為3種:封面、前言和正文。根據(jù)詞匯在文件中出現(xiàn)的不同位置,采用式(3)對詞條的權(quán)重進(jìn)行加權(quán):
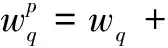
(3)

(2)待檢測文件向量建立。對于待檢測文件,系統(tǒng)通過上述方法完成純文本提取、分詞,通過布爾框架建立待檢測文件向量。
(3)相似度計(jì)算。根據(jù)式(2)中的算法,密級檢測系統(tǒng)將待檢測文件向量與涉密文件向量集的文件向量逐一進(jìn)行相似度計(jì)算,按照相似度大小排序,設(shè)置一定的閾值將相似度較小的文件過濾,給出與待檢測文件相似的涉密文件名稱及密級,作為判斷待檢測文件涉密程度的參考。
3 系統(tǒng)實(shí)現(xiàn)
3.1 技術(shù)路線
本文設(shè)計(jì)的密級檢測系統(tǒng)基于WindowsXP操作系統(tǒng),以Sun公司的Java作為開發(fā)語言,并在MyEclipse平臺(tái)上實(shí)現(xiàn),系統(tǒng)采用經(jīng)典的B/S架構(gòu)和JSP+Servlet技術(shù)。
(1)文件讀取技術(shù)。本系統(tǒng)針對的文件為word格式文件,通過導(dǎo)入Java包完成對文件的讀取,代碼如下:
importorg.textmining.text.extraction.WordExtractor;
FileInputStreamfileN=newFileInputStream(newFile(wordT)); // 創(chuàng)建輸入流讀取word文件
WordExtractorextractor=null;
StringtxtFile=null;
extractor=newWordExtractor();// 創(chuàng)建WordExtractor
txtFile=extractor.extractText(fileN); // 對word文件進(jìn)行提取
(2)分詞技術(shù)。中文分詞主要采用中國科學(xué)院計(jì)算技術(shù)研究所漢語詞法分析系統(tǒng)ICTCLAS[6],它是目前最好的中文分詞工具并廣泛使用于中文分詞領(lǐng)域。它提供了用戶詞典的接口,可以動(dòng)態(tài)地增加、刪除用戶詞典中的詞從而調(diào)節(jié)分詞效果,這樣就保證了本文涉及的特定領(lǐng)域中的專業(yè)詞匯能夠作為用戶詞典的詞參與分詞過程,從而提高系統(tǒng)對專業(yè)詞匯分詞的正確性。
(3)相似度計(jì)算實(shí)現(xiàn)。本系統(tǒng)根據(jù)式(2)實(shí)現(xiàn)待檢測文件與涉密文件向量集的文件向量進(jìn)行余弦相似度計(jì)算,Java代碼如下所示。代碼中的“e:javaFileSource”為涉密文件庫中的文件,通過純文本提取、分詞等處理后,以txt文本格式存放在計(jì)算機(jī)硬盤中的路徑,vect0、vect為Java語言中的Vector變量,分別存放檢測文件、涉密文件中的詞條及權(quán)重等值。
FilefileDir=newFile("e:javaFileSource"); //FileSource為分詞后的密級文件資源庫
File[]files=fileDir.listFiles();
for(inti= 0;i {Vectorvect=getFileVect(files[i],"e:javaFileSource"); doublesum=0,b=0,c=0; //相似度計(jì)算代碼 for(intn= 1;n { doubled=Double.parseDouble(vect0.get(n).toString()) *Double.parseDouble(vect.get(n).toString()); sum=sum+d; b=b+Double.parseDouble(vect0.get(n).toString()) *Double.parseDouble(vect0.get(n).toString()); c=c+Double.parseDouble(vect.get(n).toString()) *Double.parseDouble(vect.get(n).toString()); } doubleres=sum/(Math.sqrt(b*c)); if(res>Keydor) //Keydor為閾值 {System.out.println(" 與檢測文件密級相似的文件為" +vect.get(0).toString()+ " 相似度" +res); } } 3.2 實(shí)驗(yàn)效果 目前本系統(tǒng)已完成原型系統(tǒng)開發(fā),在系統(tǒng)測試中選取了數(shù)百份涉密文件資料,完成分詞并建立了上萬維的向量空間,構(gòu)建了涉密文件向量集。在實(shí)驗(yàn)中通過檢測文件向量與涉密文件向量集進(jìn)行相似度計(jì)算并設(shè)置了相似度閾值,系統(tǒng)運(yùn)行結(jié)果返回了與檢測文件相似的涉密文件,并對檢測文件的密級進(jìn)行確定。通過對上百份文件進(jìn)行檢測,系統(tǒng)的正確率為83.4%,完成一份文件檢測的平均時(shí)間為15.7s。實(shí)驗(yàn)結(jié)果表明,本系統(tǒng)能夠方便、快捷、準(zhǔn)確地對文件的密級進(jìn)行檢測和判斷。 為有效避免涉密文件向外部系統(tǒng)導(dǎo)出存在的風(fēng)險(xiǎn),本文運(yùn)用計(jì)算機(jī)信息化手段,將向量空間模型應(yīng)用于文件密級檢測系統(tǒng),通過待檢測文件與文件庫中的涉密文件進(jìn)行相似度比對,判斷文件的密級。根據(jù)對向量空間模型的分析和原型系統(tǒng)實(shí)驗(yàn)效果可知,本系統(tǒng)針對文件內(nèi)容的密級檢測是有效可行的。 [1] 焦玉英,宋曉晴.基于VSM的文檔信息檢索改進(jìn)[J].情報(bào)理論與實(shí)踐,2007,30(1):97-104. [2] 蔡瑋,黃陳蓉.一種基于向量空間模型的主觀題批改算法[J].計(jì)算機(jī)與現(xiàn)代化,2008(12):88-90. [3] 張成偉,鄭誠.基于改進(jìn)VSM的文本信息檢索研究[J].計(jì)算機(jī)技術(shù)與發(fā)展,2009,19(1):71-73. [4] 郝祥根,楊思春,高遠(yuǎn)飆,等.基于向量空間模型的中文問答系統(tǒng)研究與實(shí)現(xiàn)[J].蘇州科技學(xué)院學(xué)報(bào):自然科學(xué)版,2009,26(1):76-80. [5] 謝翠香.基于改進(jìn)向量空間模型的學(xué)術(shù)論文相似性辨別系統(tǒng)設(shè)計(jì)[J].電腦知識與技術(shù),2009.5(19):5103-5105. [6] 鄭魁,疏學(xué)明,袁宏永.網(wǎng)絡(luò)輿情熱點(diǎn)信息自動(dòng)發(fā)現(xiàn)方法[J].計(jì)算機(jī)工程,2010,36(3):4-6. (責(zé)任編輯:孫 娟) 張明星(1985-),男,四川廣安人,碩士,中國核動(dòng)力研究設(shè)計(jì)院工程師,研究方向?yàn)閿?shù)據(jù)庫軟件系統(tǒng)設(shè)計(jì)開發(fā);鄧時(shí)滔(1988-),男,四川安岳人,碩士,中國核動(dòng)力研究設(shè)計(jì)院工程師,研究方向?yàn)橛?jì)算機(jī)網(wǎng)絡(luò)技術(shù);李海怒(1986-),重慶人,碩士,中國核動(dòng)力研究設(shè)計(jì)院工程師,研究方向?yàn)檐浖こ獭?/p> 10.11907/rjdk.162562 TP309 A 1672-7800(2017)003-0156-044 結(jié)語
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08電子制作(2018年18期)2018-11-14 01:48:06光學(xué)精密工程(2016年6期)2016-11-07 09:07:19海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
