領域驅動的高效用co-location模式挖掘方法
2017-04-20 03:38:30江萬國王麗珍陳紅梅
計算機應用 2017年2期
江萬國,王麗珍,方 圓,陳紅梅
(云南大學 信息學院,昆明 650091)
(*通信作者電子郵箱lzhwang2005@126.com)
領域驅動的高效用co-location模式挖掘方法
江萬國,王麗珍*,方 圓,陳紅梅
(云南大學 信息學院,昆明 650091)
(*通信作者電子郵箱lzhwang2005@126.com)
空間并置(co-location)模式是指其實例在空間鄰域內頻繁共現的空間特征集的子集。現有的空間co-location模式挖掘的有趣性度量指標,沒有充分地考慮特征之間以及同一特征的不同實例之間的差異;另外,傳統的基于數據驅動的空間co-location模式挖掘方法的結果常常包含大量無用或是用戶不感興趣的知識。針對上述問題,提出一種更為一般的研究對象——帶效用值的空間實例,并定義了新的效用參與度(UPI)作為高效用co-location模式的有趣性度量指標;將領域知識形式化為三種語義規則并應用于挖掘過程中,提出一種領域驅動的多次迭代挖掘框架;最后通過大量實驗對比分析不同有趣性度量指標下的挖掘結果在效用占比和頻繁性兩方面的差異,以及引入基于領域知識的語義規則前后挖掘結果的變化情況。實驗結果表明所提出的UPI度量是一種兼顧頻繁和效用的更為合理的度量指標;同時,領域驅動的挖掘方法能有效地挖掘到用戶真正感興趣的模式。
空間模式挖掘;co-location模式;高效用co-location模式;有趣性度量指標;領域驅動;語義規則
0 引言
與傳統的事務數據相比,空間數據具有海量性、高維性和語義信息更加豐富等特點,這些特點使得空間數據的知識發現比傳統數據更具挑戰性。空間數據往往具有較強的地理相關性,即兩個空間對象所處位置越近,就越有可能具有相同的性質。空間co-location模式是空間特征集的一個子集,子集中特征的實例頻繁地在空間鄰域共現。空間co-location模式廣泛存在于實際生活中,例如瘧疾往往發生在蚊蟲泛濫和水污染嚴重的區域。
在現有的大量空間co-location模式挖掘研究中, 一般將模式中特征的最小參與率(即參與度(Participation Index, PI))作為模式有趣性的度量指標,僅關注了模式中特征實例共現的頻繁性,忽略了特征之間和同一特征中不同實例之間可能存在的差異。而已有的空間高效用co-location模式挖掘研究中,雖然引入了模式效用率(Pattern Utility Ratio, PUR)作為模式有趣性的度量指標,將模式中不同特征對模式的興趣性貢獻區分對待,但在實際中我們還注意到相同空間特征中不同實例對模式興趣性的貢獻仍然存在差異,而相關研究未見報道。
另一方面,以數據為中心的空間co-location模式挖掘通常忽略了數據特定的領域背景和用戶偏好等約束信息,挖掘結果往往針對性差、數量大,并包含了大量無用或用戶不感興趣的結果,這樣的挖掘結果通常是不可行動的。因此,考慮數據來源和應用背景的領域知識,在空間co-location模式挖掘過程中引入基于領域知識的語義規則是有益的。
在本文中,我們充分考慮了特征之間和實例之間的差異性,以及數據和應用的領域知識,最終能得到更有針對性的挖掘結果。
1 相關工作
空間co-location模式挖掘是空間關聯規則挖掘的一個特例,最早在文獻[1-2]中被提出。文獻[3]中提出了co-location模式的有趣性度量指標——最小參與率(PI)。PI的定義滿足向下閉合性(先驗原理),所以能夠利用這一性質有效地進行候選模式剪枝。空間co-location模式挖掘大體包括兩大主要工作:產生候選模式和計算候選模式的表實例,其中計算表實例是時間復雜度最高的部分,此后的很多研究都集中在候選模式的剪枝和表實例的計算優化兩個方面。文獻[3-5]中分別提出了經典的join-based(全連接)算法、partial-join(部分連接)算法和Join-less(無連接)算法,這些算法都是類Apriori的。Join-less算法采用了新穎的物化模型——星型鄰居,在計算表實例時通過查詢操作來代替連接操作。與上述的類Apriori算法不同,文獻[6]中提出了新的空間鄰近關系的物化模型,并給出了類似于FP-growth(Frequent-Pattern growth)的CPI-tree(Co-location Pattern Instance tree)算法。文獻[7]中又提出了一種結合“候選-測試”方式和CPI-tree模型優勢的新物化模型——iCPI-tree,基于該模型的算法具有更高的效率。文獻[8]中系統地總結了空間co-location模式挖掘的方法和研究現狀。
文獻[9]首次提出了基于“特征外部效用(單價)”和“特征在模式中的內部效用(數量)”的空間高效用co-location模式挖掘方法,給出了高效用co-location模式的有趣性度量指標——PUR(模式效用率)。文獻[10]則進一步提出了擴展模式效用率的概念,并出了一個擴展剪枝算法EPA。但文獻[9]和[10]的研究中沒有考慮同一特征不同實例的效用差異。
文獻[11]中提出了領域驅動數據挖掘的方法論來縮小學術研究和商業應用的差距。在領域驅動數據挖掘中,需要重點考慮領域知識的表示以及如何在挖掘中使用領域知識。文獻[12-13]中提出了基于語義網絡的知識表示技術;文獻[14]提出了基于本體的領域知識表示技術;文獻[15]詳細介紹了基于領域驅動的知識發現方法,提出了獲取專家領域知識的算法和領域驅動的Semantic-Apriori算法;文獻[16]首次提出了一個基于本體的空間co-location規則挖掘的一般框架,通過引入約束規則和多次過濾得到了精簡有效的空間co-location挖掘結果;本文則簡化了文獻[16]的方法,分類基于領域知識的語義規則并應用到挖掘過程中。
2 相關概念和定義
2.1 Co-location相關概念
不同的空間特征代表了不同類別的空間數據,通常也稱為空間對象(spatial object),常用f表示。比如房子、超市、學校、人等在概念上可以形成一個類別,都可以稱為一個空間特征。空間特征集是所有空間數據劃分類別的集合,常用F表示,記為F={f1,f2,…,fn}。一個空間co-location模式c是F的一個子集,c中的特征個數|c|稱為模式c的階數。空間區域中一個具體位置上的一個空間數據稱為一個空間實例,為了區分不同特征的不同實例,給每個特征中的每個實例一個唯一的編號。于是,每一個空間實例被記為“特征名.實例編號”,如圖1所示,圖中共有4個空間特征A、B、C和D,空間特征A有4個實例A.1、A.2、A.3和A.4,B有5個實例B.1、B.2、B.3、B.4和B.5,C有3個實例C.1、C.2和C.3,D有2個實例D.1和D.2。如果兩個空間實例之間的歐氏距離不大于用戶給定的一個距離閾值d,那么稱這兩個空間實例滿足空間鄰近關系。為了便于描述,將滿足鄰近關系的空間實例在圖中用實線連接。
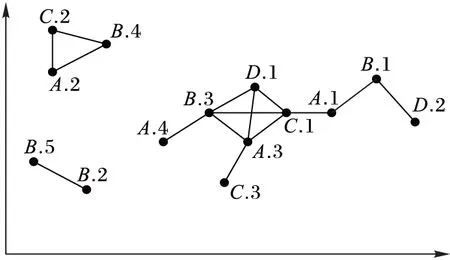
圖1 空間特征及其實例示例
如果一個空間實例集合I中,兩兩實例均滿足空間鄰近關系,則稱I是一個團。如果團I包含了co-location模式c中的所有特征,并且I的任何一個子集無法包含c中的所有特征,那么I被稱為c的一個行實例。例如,在圖1中,實例集合{A.3,B.3,D.1}是模式{A,B,D}的一個行實例。一個模式c的所有行實例的集合稱為c的表實例,記為T(c)。例如,圖1中,T({A,B,C})={{A.2,B.4,C.2},{A.3,B.3,C.1}}。
在co-location模式挖掘中,采用參與度PI來衡量模式的有趣性(頻繁性),PI被定義為模式中所有特征的參與率(ParticipationRatio,PR)的最小值[1-7]。對于一個k階模式c={f1,f2,…,fk},特征fi(1≤i≤k)在c中的參與率PR被定義為fi在T(c)中不重復出現的實例個數與fi的總實例個數的比值。如果模式c的參與度PI不小于用戶給定的閾值min_prev,那么稱模式c是頻繁的(有趣的)。
在圖1中,對于模式c={A,B,C},其表實例為{{A.2,B.4,C.2},{A.3,B.3,C.1}},由PR和PI的定義可得PI(c)=min{2/4, 2/5, 2/3}=2/5。若min_prev=0.3, 那么{A,B,C}是一個頻繁的co-location模式。
2.2 領域驅動相關概念
領域知識通常是領域內主體(專家、用戶)對經驗、規律和喜好的自然表達,在實際應用中需要將它們轉換為計算機可以理解的形式,也就是領域知識的形式化表達。目前對于領域知識的形式化表達的研究相對較成熟,常見的方法有:
1)基于產生式規則的表達(或基于條件式規則的表達), 其基本形式為p→q。基于產生式規則的知識表達具有自然、靈活、通用性強和易維護等優點。
2)基于語義網絡的表達。語義網絡通過圖(Graph)的方式刻畫領域知識中概念之間的關系、約束或者相關行為[15]。語義網絡能夠清晰直觀地將領域知識表達出來,易于理解和溝通,同時具有較好的可擴展性,在目前的知識圖譜構建中使用較多。
3)基于本體的表達。本體是針對領域實體的本質抽象,關注領域實體的屬性、實體之間的關聯、約束和層次關系等。通常一個完整的本體包括類(概念)、關系、函數、公理系統和實體這五個部分。
數據挖掘過程可以分為挖掘前、挖掘中和挖掘后三個階段,領域知識可以應用于任何一個階段。在挖掘前可以通過領域知識進行數據預處理,比如應用在數據的獲取、轉換和加載(ExtractionTransformationLoading,ETL)過程中;在挖掘中,利用領域知識過濾無效候選;在挖掘后,可以利用領域知識進行冗余模式的剔除,對挖掘結果進行分類和排序等操作。
2.3 高效用co-location相關定義
在實際中,不同特征的價值(效用值)往往是千差萬別的,比如天然水晶和玻璃。有時候,同一種特征中不同實例的價值也存在較大的差異,比如10克拉的水晶和100克拉的水晶。
在本文中,考慮更為復雜的空間實例作為研究對象——帶效用值的空間實例。圖2是六種不同植被的空間分布示例,表1是圖2中每種植被的總效用值,圖2中實例的上標數據代表該實例的效用值。
在考慮特征中實例效用差異的情況下,采用傳統的PI度量指標,可能會遺漏一些有意義的模式或者挖掘出一些沒有意義的模式。
在圖2中,以co-location模式c1={A,B,C}為例,其表實例為{{A.110,B.48,C.29},{A.37,B.58,C.29}}, 其參與度為PI(c1)=1/4。特征A的實例在模式c1中參與的效用占A總效用的17/28,類似,特征B在c1中的實例效用占比為16/25,特征C的實例效用占比為9/12。若min_prev=0.3,那么模式c1被識別為非有趣的模式。但是,模式c1中每個特征參與的效用都超過了自身總效用的50%,所以c1應該是一個有意義的模式。同樣,對于模式c2={E,F},PI(c2)=2/3,若min_prev=0.5,那么c2是一個有趣模式。但是特征E在c2中的實例效用僅占其總效用的4/14,特征F為3/18,在c2中的每個特征參與的效用占比都很少,不應該被識別為有趣模式。
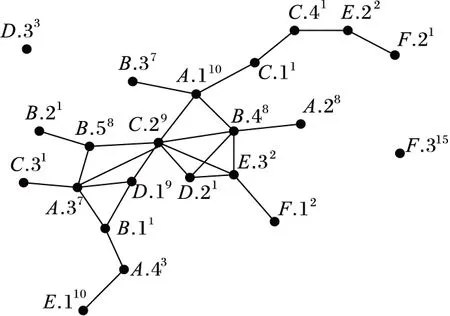
圖2 帶效用值的空間實例示例
表1 圖2中每種植被的實例和總效用
Tab.1InstancesandtotalutilityvalueofeachvegetationinFig.2

特征實例總效用AA.110 A.28 A.37 A.4328BB.11 B.21 B.37 B.48 B.5825CC.11 C.29 C.31 C.4112DD.19 D.21 D.3313EE.110 E.22 E.3214FF.12 F.21 F.31518
定義1 帶效用值的空間實例。帶有效用值為v的空間特征fi的第j個實例記為fi.jv,或將實例fi.jv的效用記為:u(fi.j)=v。
例如,特征A代表水晶,A.110代表一顆10克拉水晶,其效用為u(A.1)=10。
定義2 特征的總效用。給定空間特征fi及其實例集si,fi的總效用定義為其所有實例的效用之和,形式化描述為:
定義3 特征在模式內的參與效用。給定一個k階co-location模式c={f1,f2,…,fk},特征fi∈c在模式c中的參與效用記為u(fi,c),形式化為:
定義4 特征在模式中的內效用率(Intra-Utility Ratio, IntraUR)。給定一個k階co-location模式c={f1,f2,…,fk},特征fi∈c在模式內的參與效用占其總效用的比值被定義為特征fi在模式c中的內效用率,形式化為:
IntraUR(fi,c)代表特征fi對模式c的直接貢獻或者影響。例如,在圖2中,特征A在模式c={A,B,C}中的內效用率為:
定義5 特征在模式中的間效用率(Inter-Utility Ratio, InterUR, InterUR)。給定一個k階co-location模式c={f1,f2,…,fk},特征fi∈c在模式c中的間效用率定義為:
InterUR(fi,c)代表特征fi對模式c內其他特征的影響程度(或貢獻程度),代表特征的一種間接影響。比如,電子產品促銷活動中,電腦的銷售會對鼠標、鍵盤等外部設備的銷售有一定的影響。在圖2中,特征A在模式c={A,B,C}中的間效用率為:
定義6 特征的效用參與率(Utility Participation Ratio, UPR)。給定一個k階co-location模式c={f1,f2,…,fk},特征fi∈c在模式c中的效用參與率UPR(fi,c)定義為特征在模式c中的內效用率(IntraUR)和間效用率(InterUR)的加權和,形式化為:
UPR(fi,c)=w1×IntraUR(fi,c)+w2×InterUR(fi,c)
其中:0≤w1,w2≤1,w1+w2=1。
UPR考慮了特征在模式中的直接影響(內效用率)和間接影響(間效用率),綜合地評價了特征在模式中的重要程度。w1、w2分別代表IntraUR和InterUR的權重,通常由用戶指定。以圖2為例,設w1=0.7,w2=0.3, 對于模式c={A,B,C},特征B的效用參與率計算如下:
UPR(B,c)=0.7×IntraUR(B,c)+
0.3×InterUR(B,c)=0.643
定義7 模式的效用參與度(Utility Participation Index, UPI)。給定一個k階co-location模式c={f1,f2,…,fk},模式c的效用參與度UPI(c)被定義為c中所有特征的UPR值中的最小值,形式化描述如下:
由定義7可知,UPI的取值范圍為[0,1]。當忽略特征之間和同一特征的不同實例之間的差異性以及特征之間影響時,UPI就等于PI。所以,基于PI的co-location模式挖掘是基于UPI的模式挖掘的一種特例。當一個模式c的UPI(c)≥λ(用戶指定的效用參與度閾值)時,稱c是一個高效用co-location模式。
傳統的頻繁co-location模式不一定是高效用模式;同樣,高效用co-location模式未必是頻繁模式。例如,在圖2中,當w1=w2=0.5,λ=0.5時,模式{E,F}的表實例為{{E.22,F.21}, {E.32,F.12}},PI=0.67>λ,UPI({E,F})=0.23<λ;模式{C,D}的表實例為{{C.29,D.19}, {C.29,D.21}},PI({C,D})=0.25<λ,UPI({C,D})=0.76>λ。
同時,與PI不同,UPI并不滿足向下閉合性質,例如在圖2中,設w1=w2=0.5,模式{A,D}的表實例為{{A.37,D.19},UPI({A,D})=0.47;模式{A,C,D}的表實例為{{A.37,C.29,D.19},UPI({A,C,D})=0.485>UPI({A,D})。不滿足向下閉合性質意味著挖掘基于UPI的高效用co-location模式比挖掘基于PI的頻繁co-location模式的難度更大。
不過,根據UPI的定義,可以證明以下引理:
引理1 若co-location模式c的表實例為空,那么c的所有超模式c′?c的UPI(c′)=0。
證明 假設模式c的表實例為空,則c的任意超集c′?c的表實例一定為空,所以,對于任意fi∈c′有UPR(fi,c′)=0,則UPI(c′)=0。
根據引理1,如果一個模式c的表實例為空,那么它的所有超集c′?c都是非高效用co-location模式。
本文采用語義約束規則來形式化表達高效用co-location模式挖掘中涉及到的領域知識。結合co-location模式的挖掘目標,定義了三種語義規則,分別為:抽象語義規則、分類語義規則和互斥語義規則,具體如下:
定義8 抽象語義規則。給定空間特征集F={f1,f2,…,fn}, 將m(m 例如:在植被分布數據集中,可以將“青岡林、石櫟林、潤楠林、木荷林、白克木林和蚊母樹林”等特征抽象為“常綠闊葉林”。抽象語義規則有助于獲取更高層次的知識。 定義9 分類語義規則。給定空間特征集F, 根據特征fi∈F的某個屬性取值將特征fi具體細分為m(m≥1)個特征,形式化定義如下: 在植被分布數據集中,可以根據植被實例的位置信息對植被進行細分。比如對松樹根據實例所在位置細分為三葉松(秦嶺地區)、白皮松(關山林區)和云南松(川滇地區),即: 分類語義規則可以有效地細分空間特征,使挖掘結果更加具有可行動性,通常這些結果對具體事務的執行者或者實施者可能更加有效。 定義10 互斥語義規則。給定空間特征集F,若特征fi,fj∈F不能同時出現,則稱fi與fj互斥,形式化表述為: 例如,在植被數據集中,耐旱植物和喜濕植物不會生長在一起,如鴨跖草和仙人掌。互斥語義規則能夠有效地排除異常數據導致的錯誤挖掘結果。 下面是一條分類語義規則的XML信息示例: … 其中:rule標簽代表一條規則;type屬性表示語義規則的類型,取值空間為“AR”(抽象語義規則)、“CR”(分類語義規則)或“MR”(互斥語義規則);location子標簽規定了該條規則作用的空間區域。 對于基于UPI的空間高效用co-location模式挖掘,可以采用“生成-測試”形式的類Apriori方法。整個挖掘過程主要包含三個階段: PhaseⅠ: 數據預處理、空間鄰近關系計算; PhaseⅡ: 候選模式的生成以及候選剪枝; PhaseⅢ: 候選模式的表實例計算,UPI值計算,以及篩選高效用co-location模式。 將領域知識作為一種額外的數據資源,進行形式化表示并應用于空間高效用co-location模式的挖掘過程中。圖3給出了一個領域驅動的空間高效用co-location模式挖掘的一般框架。 在圖3的挖掘框架中,將抽象語義規則和分類語義規則作用于PhaseⅠ階段,將互斥規則作用于PhaseⅡ階段,通過互斥規則來提前剪枝候選模式。一次挖掘工作結束后,如果專家從挖掘結果中獲取了新的領域知識,算法利用擴增后的領域知識再次進行挖掘;反復執行此過程,直到沒有新的領域知識加入。 圖3 一個領域驅動的高效用co-location挖掘框架 下面給出領域驅動的空間高效用co-location模式挖掘的基本算法: 輸入: F={f1,f2,…,fn}:空間特征集; S:帶效用值的空間實例集; R:空間鄰近關系(實際中用距離閾值d來度量); w1:特征的IntraUR權重; w2:特征的InterUR權重; λ:高效用模式的UPI閾值; ARs:抽象語義規則集; CRs:分類語義規則集; MRs:互斥語義規則集。 輸出: UPI值大于等于λ的高效用co-location模式。 變量: SN={SNf1,SNf2,…,SNfn}:所有空間特征的星型鄰居; k:co-location模式的階數; Ck:k階候選高效用co-location模式; CTIk:k階候選高效用co-location模式的表實例; Hk:k階高效用co-location模式集; H:所有高效用co-location模式集; NonHk:k階非高效用co-location模式集; new_DK_flag:代表是否有新的領域知識加入。 過程: 1) new_DK_flag=true; //當有新的領域知識加入時需要反復挖掘 2) while(new_DK_flag) do //利用抽象規則,分類規則進行預處理 3) abstract_features(F,S,ARs); 4) classify_features(F,S,CRs); //生成星型鄰居集合 5) SN=gen_star_neighborhoods(F,S,R); 6) H1=F;k=2; //判斷是否還能夠生成k+1階候選模式 7) while (not emptyHk-1and not emptyNonHk-1) do //通過k-1階模式生成k階候選模式 8) Ck=gen_candidate_colocations(Hk-1,NonHk-1); //利用互斥規則和引理進行剪枝 9) Ck=mutex_rules_pruning(Ck,MRs); 10) Ck=other_pruning(Ck); //計算未被剪枝模式的表實例 11) CTIk=gen_table_instance(Ck,SN); //計算模式的效用參與度 12) compute_UPI(Ck,CTIk); 13) Hk=select_high_utility_colocations(Ck,λ); 14) NonHk=U(Ck-Hk); 15) k=k+1; 16) End do 17) ReturnH=∪(H1,H2,…,Hk); 18) new_DK_flag= update_domain_knowledges(ARs,CRs,MRs,H); 19) End do 算法第3)~6)行屬于Phase I階段, 利用抽象語義規則對多個特征進行抽象,利用分類語義規則對特征進行細分,這個過程會調整空間數據中的特征集和特征實例的分布。然后,采用網格劃分或者平面掃描的方式[3]計算出所有空間鄰近關系,將空間鄰近關系物化為星型鄰居模式[5],初始化所有1階模式的UPI為1.0,并將其放入H1。 第8)~10)行屬于PhaseⅡ段,第8)行主要負責從k-1(k≥2)階模式(高效用Hk-1和非高效用NonHk-1)中擴展生成k階候選高效用co-location模式。生成候選模式的方式為: Ck={c′|c′=c∪{fk}, c∈Hk-1∪NonHk-1,fk>fi∈c} 其中Ck是候選模式,特征按照字典序有序。當k=2時,直接從星型鄰居模型中產生二階候選模式。該方法不會遺漏任何候選模式,同時也不會重復生成候選模式。接著,在第9)行采用互斥語義規則,過濾同時包含互斥語義規則中的特征的候選模式。第10)行采用前文介紹的引理過濾候選模式。 第11)~14)行屬于PhaseⅢ階段,第11)行主要通過擴展k-1階模式的表實例來計算k(k≥2)階候選模式的表實例。當k=2時,可以直接從星型鄰居模型中查找2階候選模式的表實例;當k>2時,通過擴展k-1階模式的表實例,計算表實例方式采用join-less算法的方法[5]。然后在第12行)根據候選模式的表實例計算UPI值,在第13)~14)行將UPI大于等于λ的模式放入Hk中,將其余模式放入NonHk中。 第15)行執行k=k+1,代表接下來的循環中將挖掘k+1階模式。隨著co-location模式階數的增長,重復執行第8)~10)行,直到無法生成更高階模式為止。 第18)行執行和用戶的交互,若用戶有新的領域知識加入,則重新執行整個挖掘過程,直到沒有新的規則加入為止。 4.1 實驗數據集 實驗中采用的數據為人工合成數據,所有人工合成數據分布在1 000×1 000的區域中,特征實例的效用在服從正態分布情況下隨機產生,特征的實例個數和特征的總效用均為隨機生成。在實驗部分,F代表空間特征集,d代表空間鄰近關系距離閾值,n代表實例個數,w1代表IntraUR的權重,w2代表InterUR的權重,λ代表UPI閾值,ARs代表抽象語義規則集,CRs代表分類語義規則集,MRs代表互斥語義規則集。 4.2 實驗運行環境 實驗中涉及的所有算法均用Java語言實現,硬件環境為:IntelCorei3 2.13GHz,4GB內存;軟件環境為:Windows10,JRE1.8。 4.3 效用占比評估 為了驗證本文提出的度量指標UPI相比傳統的PI[3]和PUR[9-10]興趣度度量更為合理,設置實驗數據集信息為:|F|=15,d=30,n=10 000;實驗參數為:w1=0.9,w2=0.1,λ=0.01,語義規則集為空。圖4(a)展示的是在PI、PUR和UPI三種不同興趣度度量指標下挖掘到的top-k有趣模式的Q(c)值之和,而圖4(b)則展示了三種不同度量指標挖掘結果中不同階數的top-20有趣模式的平均效用。結果表明,基于UPI的挖掘結果在上述兩方面的值均高于基于PI和PUR的結果,反映了基于UPI度量挖掘到co-location模式的總效用和平均效用均更高。 4.4 頻繁性評價 模式的頻繁性代表了模式存在的普遍性,其對挖掘結果的可用性具有重要意義。PI(參與度)是模式頻繁性的經典衡量指標,本節在實驗數據集及參數信息設置不變的情況下,對比基于不同興趣度度量的挖掘結果的頻繁性。 圖5(a)顯示了三種度量指標下的挖掘結果中top-k模式的頻繁性之和;圖5(b)顯示了三種度量指標下挖掘到的有趣模式中各階的top-20有趣模式的平均頻繁性。由于基于PI度量指標的目標是挖掘頻繁性高的模式,基于PI的挖掘結果總是具有最高的頻繁性。實驗結果表明,基于UPI的結果的頻繁性在各階上都高于基于PUR的結果,并且僅僅略低于PI的結果。 圖4 三種度量指標的效用占比評估 圖5 三種度量指標的頻繁性評估 4.5 領域知識對挖掘過程的影響 本節的實驗在模擬數據上加入了一些領域知識,以對比加入領域知識以后高效用模式的數量變化。數據集和參數信息為:|F|=15,n=20 000,d=20,w1=0.9,w2=0.1,λ=0.7,ARs語義規則集減少了5個特征,CRs語義規則集新增了5個特征,MRs語義規則定義了3對特征集。表2給出了單獨使用每個規則集對高效用模式數量的影響。在表2中,ARs規則集減少了特征,但是增加了抽象特征實例數和分布范圍,所以增加了部分高效用模式;CRs規則集增加了空間特征,將特征的實例劃分到不同的新特征,降低了新特征實例的部分范圍,從而會減少高效用模式的數量。對于MRs規則集,互斥規則使得原來可能高效的模式由于保存了互斥特征而直接變為無效模式。在實際情況中,尤其是在植被數據中,互斥的植物在自然條件下基本不會出現在同一鄰域內,所以可以通過互斥規則剔除異常模式。由于領域知識會改變數據集中的特征和實例的分布情況,所以實驗中發現領域知識對算法效率的影響是不確定的。 表2 不同語義規則對高效用模式數量的影響 在實際中,不同空間特征和同一特征的不同實例的價值(效用)存在差異性,因此,本文提出研究帶效用值的空間實例,同時,提出了IntraUR(內效用率)和InterUR(間效用率)分別衡量特征對模式的直接影響和間接影響,通過UPR(效用參與率)來衡量特征對模式的綜合影響,提出的度量指標兼顧了模式的普遍性和效用兩方面。另一方面,通過引入語義規則將領域背景知識和約束條件等用于挖掘過程,以挖掘用戶真正感興趣的模式。在未來研究工作中需要進一步研究高效的剪枝策略;在領域驅動挖掘方面,將考慮基于本體的高效用co-location模式挖掘。 ) [1]MORIMOTOY.Miningfrequentneighboringclasssetsinspatialdatabases[C]//KDD’01:Proceedingsofthe7thACMSIGKDDInternationalConferenceonKnowledgeDiscoveryandDataMining.NewYork:ACM, 2001: 353-358. [2]SHEKHARS,HUANGY.Discoveryspatialco-locationpatterns:asummaryofresults[C]//SSTD2001:Proceedingsofthe7thInternationalSysmposiumonAdvancesinSpatialandTemporalDatabases,LNCS2121.Berlin:Springer-Verlag, 2001: 236-256. [3]HUANGY,SHEKHARS,XIONGH.Discoveringcolocationpatternsfromspatialdatasets:ageneralapproach[J].IEEETransactionsonKnowledgeandDataEngineering, 2004, 16(12): 1472-1485. [4]YOOJS,SHEKHARS,SMITHJ,etal.Apartialjoinapproachforminingco-locationpatterns[C]//GIS’04:Proceedingsofthethe12thAnnualACMInternationalWorkshoponGeographicInformationSystems.NewYork:ACM, 2004: 241-249. [5]YOOJS,SHEKHARS,CELIKM.Ajoin-lessapproachforspatialco-locationpatternmining:asummaryofresult[C]//ICDM’05:Proceedingsofthethe5thIEEEInternationalConferenceonDataMining.Washington,DC:IEEEComputerSociety, 2005: 813-816. [6]WANGL,BAOY,LUJ,etal.Anewjoin-lessapproachforco-locationpatternmining[C]//CIT2008:Proceedingsofthe8thIEEEInternationalConferenceonComputerandInformationTechnology.Piscataway,NJ:IEEE, 2008: 197-202. [7]WANGL,BAOY,LUZ.Efficientdiscoveryofspatialco-locationpatternsusingtheiCPI-tree[J].TheOpenInformationSystemsJournal, 2009, 3(2): 69-80. [8] 王麗珍,陳紅梅.空間模式挖掘理論與方法[M].北京:科學出版社,2014: 4-13.(WANGLZ,CHENHM.TheoryandMethodofSpatialPatternMining[M].Beijing:SciencePress, 2014: 4-13.) [9] 楊世晟,王麗珍,蘆俊麗,等.空間高效用co-location模式挖掘技術初探[J].小型微型計算機系統,2014,35(10):2302-2307.(YANGSC,WANGLZ,LUJL,etal.Primaryexplorationforspatialhighutilityco-locationpatterns[J].JournalofChineseComputerSystems, 2014, 35(10): 2302-2307.) [10]YANGS,WANGL,BAOX,etal.Aframeworkforminingspatialhighutilityco-locationpatterns[C] //FSKD2015:Proceedingsofthethe12thInternationalConferenceonFuzzySystemsandKnowledgeDiscovery.Washington,DC:IEEEComputerSociety, 2015: 631-637. [11]CAOL.ZHANGC.Domain-drivenactionableknowledgediscoveryintherealworld[C]//PAKDD2006:Proceedingsofthe10thPacific-AsiaConferenceeonAdvancesinKnowledgeDiscoveryandDataMining,LNCS3918.Berlin:Springer-Verlag, 2006: 821-830. [12]SIMMONSRF.Storageandretrievalofaspectsofmeaningindirectedgraphstructures[J].CommunicationsoftheACM, 1966, 9(3): 211-215. [13]QUILLIANMR.Semanticmemory[M]//ReadingsinCognitiveScience.SanFrancisco,CA:MorganKaufmannPublishersInc., 1968: 80-101. [14]GRUBERTR.Atranslationapproachtoportableontologyspecifications[J].KnowledgeAcquisition—SpecialIssue:CurrentIssuesinKnowledge, 1993, 5(2): 199-220. [15] 朱正祥.領域驅動知識發現方法研究[D].大連:大連理工大學,2010:23-56.(ZHUZX.Researchonthemethodofdomain-drivenknowledgediscovery[D].Dalian:DalianUniversityofTechnology, 2010: 23-56.) [16] 包旭光,王麗珍,方園.OSCRM:一個基于本體的空間co-location規則挖掘框架[J].計算機研究與發展,2015,52(S1):74-80.(BAOXG,WANGLZ,FANGY.OSCRM:Aframeworkofontology-basedspatialco-locationrulemining[J].JournalofComputerResearchandDevelopment, 2015, 52(S1): 74-80.) ThisworkispartiallysupportedbytheNationalNaturalScienceFoundationofChina(61472346, 61662086),theNaturalScienceFoundationofYunnanProvince(2016FA026, 2015FB114, 2015FB149). JIANG Wanguo, born in 1990, M.S.candidate.His research interests include spatial data mining, knowledge discovery. WANG Lizhen, born in 1962, Ph.D., professor.Her research interests include data mining, database. FANG Yuan, born in 1990, Ph.D.candidate.Her research interests include spatial data mining, knowledge discovery. CHEN Hongmei, born in 1976, Ph.D., associate professor.Her research interests include data mining, knowledge discovery. Domain-driven high utility co-location pattern mining method JIANG Wanguo, WANG Lizhen*, FANG Yuan, CHEN Hongmei (SchoolofInformationScienceandEngineering,YunnanUniversity,KunmingYunnan650091,China) A spatial co-location pattern represents a subset of spatial features whose instances are frequently located together in spatial neighborhoods.The existing interesting metrics for spatial co-location pattern mining do not take account of the difference between features and the diversity between instances belonging to the same feature.In addition, using the traditional data-driven spatial co-location pattern mining method, the mining results often contain a lot of useless or uninteresting patterns.In view of the above problems, firstly, a more general study object — spatial instance with utility value was proposed, and the Utility Participation Index (UPI) was defined as the new interesting metric of the spatial high utility co-location patterns.Secondly, the domain knowledge was formalized into three kinds of semantic rules and applied to the mining process, and a new domain-driven iterative mining framework was put forward.Finally, by the extensive experiments, the differences between mined results with different interesting metrics were compared in two aspects of utility ratio and frequency, as well as the changes of the mining results after taking the domain knowledge into account.Experimental results show that the proposed UPI metric is a more reasonable measure in consideration of both frequency and utility, and the domain-driven mining method can effectively find the co-location patterns that users are really interested in. spatial pattern mining; co-location pattern; high utility co-location pattern; interesting metric; domain-driven; semantic rule 2016- 08- 12; 2016- 09- 11。 國家自然科學基金資助項目(61472346, 61662086);云南省自然科學基金資助項目(2016FA026, 2015FB114, 2015FB149)。 江萬國(1990—),男,陜西漢中人,碩士研究生,主要研究方向:空間數據挖掘、知識發現; 王麗珍(1962—),女,山東博興人,教授,博士,CCF高級會員,主要研究方向:數據挖掘、數據庫; 方圓(1990—),女,云南麗江人,博士研究生,主要研究方向:空間數據挖掘、知識發現; 陳紅梅(1976—),女,重慶人,副教授,博士,主要研究方向:數據挖掘、知識發現。 1001- 9081(2017)02- 0322- 07 10.11772/j.issn.1001- 9081.2017.02.0322 TP311.13 A
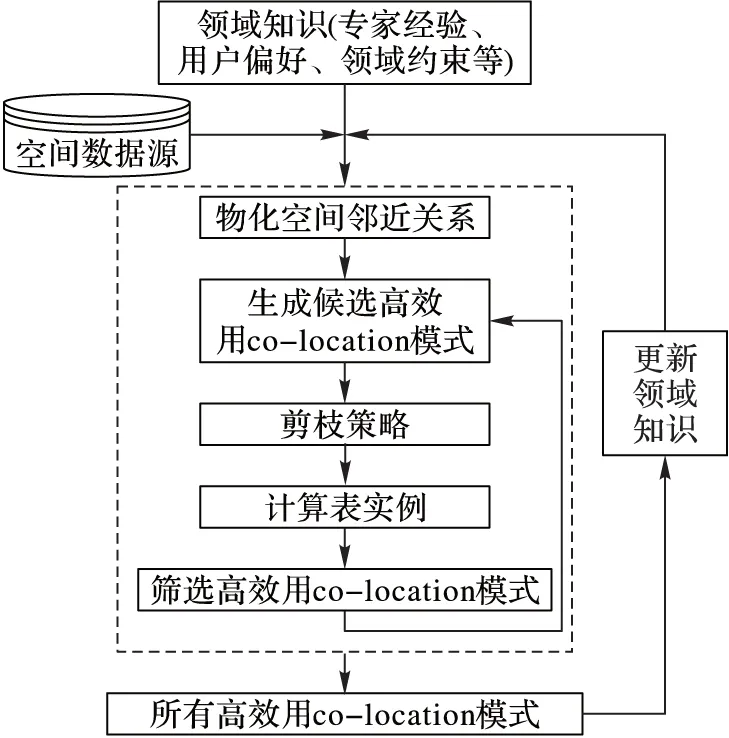
3 領域驅動挖掘的一般框架
4 實驗評估與分析
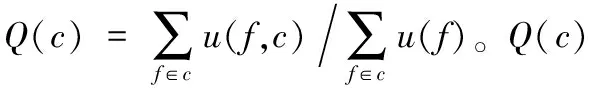
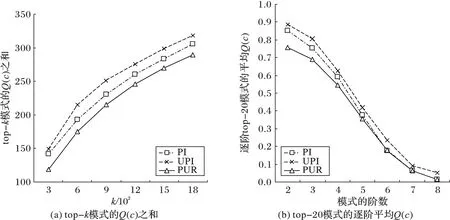
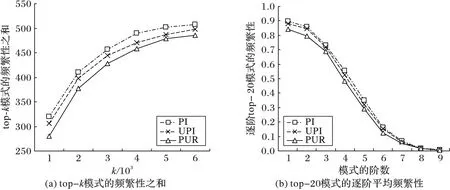

5 結語
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
開放教育研究(2020年2期)2020-03-31 01:54:14
Coco薇(2017年11期)2018-01-03 20:59:57
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
現代語文(2016年21期)2016-05-25 13:13:44
山東青年(2016年1期)2016-02-28 14:25:25
大連民族大學學報(2015年2期)2015-02-27 08:28:11
當代修辭學(2014年3期)2014-01-21 02:30:44
公務員文萃(2013年5期)2013-03-11 16:08:37
