
基于積分投影和LSTM的微表情識別研究
2017-04-26 08:40:10李競李董東杜玉改成鵬
計算機時代 2017年4期
李競+李董東+杜玉改++成鵬
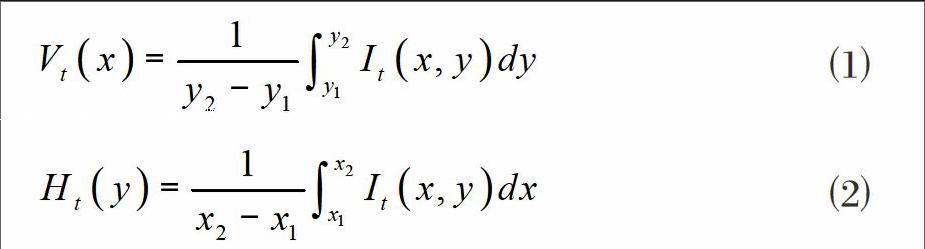

摘 要: 現有的微表情識別研究主要是利用基于局部二值模式(LBP)改進的算法并結合支持向量機(SVM)來識別。最近,積分投影開始應用于人臉識別領域。長短時記憶網絡(LSTM)作為循環神經網絡,可以用來處理時序數據。因此提出了結合積分投影和LSTM的模型(LSTM-IP),在最新的微表情數據庫CASME II上進行實驗。通過積分投影得到水平和垂直投影向量作為LSTM輸入并分類,同時采用了防止過擬合技術。實驗結果表明,LSTM-IP算法取得了比以前的方法更好的精度。
關鍵詞: 積分投影; 循環神經網絡; 長短時記憶網絡; 防止過擬合技術; 精度; 留一法
中圖分類號:TP391.4 文獻標志碼:A 文章編號:1006-8228(2017)04-13-04
Abstract: The existing research on micro expression recognition is mainly based on the improved LBP (local binary patterns) algorithm and SVM (support vector machine). Recently, integral projection has been applied in the field of face recognition. The long and short memory network (LSTM), as a kind of recurrent neural network, can be used to process time series data. So LSTM-IP model, which combines integral projection with LSTM, is proposed, and experimented on the latest micro-expression database CASME II. The horizontal and vertical projection vectors obtained by integral projection are used as the input of LSTM and classified, and the over-fitting preventing method is used. The experimental results show that LSTM-IP algorithm gets better results than the previous method.
Key words: integral projection; recurrent neural network; long and short memory network; prevent over-fitting; accuracy; leave-one-subject-out cross validation
0 引言
人們表情的短時間變化,也叫微表情,心理學在這方面的研究很早就開始了。近年來,有關利用機器學習的方法來對微表情進行研究的學者越來越多,其成為當前一個熱門研究方向。微表情的研究成果可用于測謊[2-4]、臨床診斷等方面,因為一般人即便是心理醫生也很難注意到1/25~1/5秒人表情的變化[1],而這時,機器可以很好的對微表情進行自動的識別。
最近,基于積分投影和紋理描述符的方法被用在人臉識別[5],然而,很少有研究將積分投影用于包含人臉的時間序列中進行識別。微表情與人臉識別有很大不同,特征很難單從每幀圖片中提取,這時就需要考慮時間軸。LSTM可以對時序數據進行分類,以前基本用在語音識別和自然語言處理的任務中,很少用于圖像識別,可能是因為LSTM處理的是一維的數據,而圖像是二維的數據。將圖像的二維信息積分投影到一維(水平方向和垂直方向),并以此作為LSTM的輸入并分類,這樣就能將二者很好的結合起來。
本文構造了基于積分投影和LSTM的深度學習的模型來對微表情進行識別。得到的結果不僅比以前的基于局部二值模式(LBP)的方法好,而且也略微的優于最近基于積分投影的論文中的方法。
1 CASME II微表情數據集介紹
2014年,中科院心理研究所建立了更進一步改進的自然誘發的微表情數據庫CASMEII[8]。CASMEII有26個平均年齡為22歲左右的亞洲人,9類表情(happiness, surprise, disgust, fear, sadness, anger, repression, tense, negative)組成。用來錄制的高速相機為200 fps。高速相機可以捕捉更細節的微表情。CASMEII是據我們所知目前最好的自然誘發的微表情數據庫。
2 基于差分圖像的積分投影
Mateos等人的開拓性工作[6-7]表明積分投影可以提取同一人臉圖像的共同基本特征。積分投影將人臉的特征水平和垂直投影,可以用公式⑴和⑵表示:
其中It(x,y)表示時間為t時,圖像位于(x,y)時的像素值,Ht(y)和Vt(x)表示水平和垂直積分投影。直接將積分投影應用到CASME II微表情數據集上效果如圖1所示。
然而,由于微表情的變化是十分微小的,若直接采用上面的積分投影會有很多噪聲,從圖1(c)可以看出區分不是很明顯。因此,我們采用改進的積分投影方法。可以用公式⑶和⑷表示:
我們將每個視頻下的2到N幀微表情的圖像減去第1幀,將得到的差分圖像做積分投影,效果如圖2所示。
從圖2的(c)可以看出,采用基于差分圖像的水平積分投影效果更好,去掉了不必要的噪聲。
3 長短時記憶網絡
循環神經網絡(RNN)可以用來處理時序數據,但它有一個明顯的缺陷,就是不能記憶發生在較久以前的信息。長短時記憶網絡(LSTM)[9]是一種特殊的RNN,比RNN多了一些特殊的門和細胞,可以學習長期依賴信息。LSTM結構如圖3所示。
最上面橫著帶箭頭的線包含細胞單元,作用是記憶之前LSTM單元的信息。x和+表示點分的乘法與加法,表示Sigmoid激活函數(如公式⑸),tanh表示雙曲正切激活函數(如公式⑹)。
最下面圓圈中的X和最上面圓圈中的h分別表示時序輸入和輸出。
通用的LSTM結構可以參考圖4,圖4中,底層節點為輸入,頂層節點為輸出,中間層為隱藏層節點或記憶塊。(a)描述的是傳統的 感知機(MLP)網絡,即不考慮數據的時序性,認為數據是獨立的;(b)將輸入序列映射為一個定長向量(分類標簽),可用于文本、視頻分類;(c)輸入為單個數據點,輸出為序列數據,典型的代表為圖像標注;(d)這是一種結構序列到序列的任務,常被用于機器翻譯,兩個序列長度不一定相等;(e)這種結構會得到一個文本的生成模型,每詞都會預測下一時刻的字符。
4 LSTM-IP模型
因為CASME II數據集每個視頻下微表情圖像幀數是不一樣的,為了方便我們統一LSTM的輸入,所以我們提取了最能代表這個視頻微表情的10幀,同時,本文將整個數據集圖像的尺寸統一到200×200像素,將原來彩色圖像轉化為灰度圖像。通過基于差分圖像的積分投影,得到一個視頻下差分圖像每幀圖像的水平和垂直投影,一個圖像可以得到一個200維的水平向量和一個200維的垂直向量,因為差分圖像是后面9張減去了第一張圖像,所以一個視頻下共有9個水平向量和9個垂直向量,初始化兩個9×200大小的一維向量分別保存水平向量和垂直向量。
本文采用圖4(b)和圖4(e)結合的LSTM結構,如圖5所示。
頂層的X_IP表示將一個視頻下9個差分圖像的水平投影組成的9×200的一維特征向量作為輸入,經過第一層LSTM得到9×128的一維特征向量,接著經過第二層LSTM得到9×128的一維特征向量,最后經過一層LSTM得到一個128的特征向量,Y_IP也是同樣的處理過程。最后將這兩部分的128的特征向量連接起來作為一個256的特征向量輸入softmax分類器,結果輸出屬于五類微表情的哪一類。在圖5的每兩層之間加入一層Dropout層,Dropout的比率設為0.5。LSTM內部參數初始化采用了glorot_normal,相比較于其他初始化方法,glorot_normal效果最好。
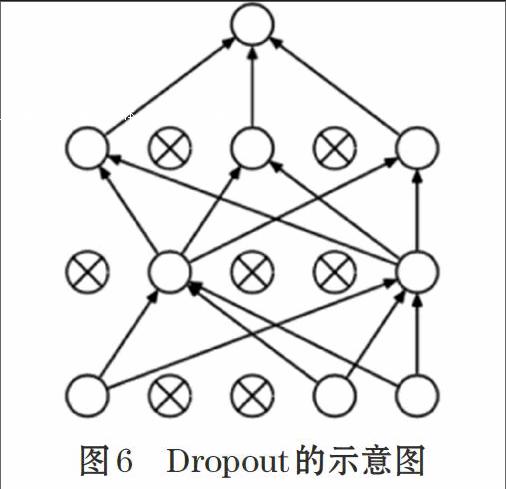
Softmax和Dropout在深度學習中都是常用的技術。Softmax是邏輯斯特回歸應用于多分類的推廣。Dropout[10]這種技術的作用是減少過擬合,是一種正則化技術,通過防止由完全連接的層引起神經元的參數過多,有助于減少神經網絡的過度擬合問題。給定 dropout率p,其在我們的LSTM中被設置為0.5,50%單位將被保留,而另外50%將被放棄。簡單地說,“Dropout”只是隨機忽略一些神經元。然而在測試階段,每個神經元的輸出將通過因子1-p(保持率)加權以保持與訓練階段中產生相同的效果。如圖6所示。
我們的實驗采用基于Theano的keras框架,keras借鑒了Torch的搭建深度學習網絡的方式,而且使用筆者比較熟悉的Python語言(Torch使用Lua語言),keras的底層可以是Theano或者Tensorflow,可能是因為keras最先在Theano開發的,經過實驗比較單個GPU下,Theano的速度要比Tensorflow快,所以我們的底層采用Theano。
5 實驗結果與分析
現在微表情識別的算法主要是基于LBP改進的算法,例如LBP-TOP[11](Local Binary Pattern-Three Orthogonal Planes)、LBP-SIP[12](LBP-Six Intersection Points)和LOCP-TOP[13](Local ordinal contrast pattern-
TOP)等。我們將LSTM-IP算法與以前的方法做了比較,如表1所示。
實驗是在CASME II上做的,因為CASME II微表情數據集是最新最好的微表情數據集。STLBP-IP也是基于積分投影的,結合了1DLBP來提取特征。通過表1的比較我們發現,基于積分投影的算法效果好于原來基于LBP的算法,可以得出,采用提取積分投影特征的方法在微表情數據集CASME II上效果比較好。可以看出,STLBP-IP的性能優于文獻[27]的重新實現,STLBP-IP的精度提高了20.64%。從表1中可知,時間插值法(TIM)可以提高LBP-TOP的性能,其中LBP-TOP增加到39.68%。然而,與STLBP-IP相比,LBP-TOP在微表情識別上的效果上有很大的差距(19.43%)。比較兩種基于積分投影的方法,本文提出的方法略微好于STLBP-IP,但通過閱讀STLBP-IP的論文筆者發現,這種方法存在繁瑣的調參過程,比如圖像如何分塊,SVM核參數的選擇,而本文提出的LSTM-IP算法可以自動從差分圖像的積分投影中學習,調參的內容比較少,而且速度也很快。這些結果表明,LSTM-IP實現了令人滿意的效果,而不是LOCP-TOP和LBP-SIP。 這部分地解釋了LSTM-IP通過使用積分投影來保持形狀和辨識的能力。
實驗采用了留一法交叉驗證,CASME II有26個subjects,通過把每個subject作為測試,其余作為訓練,循環26次,最后把每次測試得到的正確視頻個數相加除以總的視頻數,得到識別精度,這種方法現在是微表情識別主流的驗證方法。
6 結束語
基于差分圖像的積分投影方法,保存了我們微表情形狀的特征,然后增強微表情的辨別力。深度學習在圖像識別領域已經取得了很不錯的成績,而現在深度學習的技術還沒有應用于微表情識別。本文將差分圖像的積分投影與LSTM結合,從實驗結果上看,結果要好于以前的方法。我們認為深度學習的探索不會停止,會有越來越多新的網絡模型產生,也會有越來越多的深度學習的技術應用于微表情識別。
我們將繼續探索基于深度學習的微表情識別的方法及技術手段。卷積神經網絡在圖像識別上取得了很好的成績,但筆者也將卷積神經網絡應用于微表情上,效果并不好,可能是因為微表情在圖像上變化比較細微,卷積神經網絡不容易捕捉到特征,但如果考慮了一個視頻時間序列的特性,也許會有比較好的結果,對此還有待進一步研究。隨著技術的進步,相信微表情識別效果會越來越好,并最終能夠應用于我們的生活中。
參考文獻(References):
[1] Ekman P. Micro Expressions Training Tool[M]. Emotion-
srevealed. com,2003.
[2] Ekman P. Darwin, deception, and facial expression[J].
Annals of the New York Academy of Sciences,2003.1000(1):205-221
[3] Ekman P. Lie catching and microexpressions[J]. The
philosophy of deception,2009:118-133
[4] Ekman P, O'Sullivan M. From flawed self-assessment to
blatant whoppers: the utility of voluntary and involuntary behavior in detecting deception[J]. Behavioral sciences & the law,2006.24(5):673-686
[5] Benzaoui A, Boukrouche A. Face recognition using 1dlbp
texture analysis[J]. Proc. FCTA,2013: 14-19
[6] Mateos G G. Refining face tracking with integral projections
[C]//International Conference on Audio-and Video-Based Biometric Person Authentication. Springer Berlin Heidelberg,2003: 360-368
[7] García-Mateos G, Ruiz-Garcia A, López-de-Teruel P
E. Human face processing with 1.5 D models[C]//International Workshop on Analysis and Modeling of Faces and Gestures. Springer Berlin Heidelberg,2007:220-234
[8] Yan W J, Li X, Wang S J, et al. CASME II: An improved
spontaneous micro-expression database and the baseline evaluation[J]. PloS one, 2014.9(1):e86041
[9] Hochreiter S, Schmidhuber J. Long short-term memory[J].
Neural computation,1997.9(8):1735-1780
[10] Hinton G E, Srivastava N, Krizhevsky A, et al. Improving
neural networks by preventing co-adaptation of feature detectors[J]. Computer Science,2012.3(4):212-223
[11] Zhao G, Pietikainen M. Dynamic texture recognition
using local binary patterns with an application to facial expressions[J]. IEEE transactions on pattern analysis and machine intelligence,2007.29(6).
[12] Wang Y, See J, Phan R C W, et al. Lbp with six
intersection points: Reducing redundant information in lbp-top for micro-expression recognition[C]//Asian Conference on Computer Vision. Springer International Publishing,2014:525-537
[13] Chan C H, Goswami B, Kittler J, et al. Local ordinal
contrast pattern histograms for spatiotemporal, lip-based speaker authentication[J]. IEEE Transactions on Information Forensics and Security,2012.7(2):602-612
[14] Huang X, Wang S J, Zhao G, et al. Facial
micro-expression recognition using spatiotemporal local binary pattern with integral projection[C]//Proceedings of the IEEE International Conference on Computer Vision Workshops,2015:1-9
