基于支持向量機和粒子群優化的油層開采狀態識別
2017-04-27 05:25:33李學貴許少華
制造業自動化 2017年4期
關鍵詞:優化
李學貴,許少華,李 娜
(1.東北石油大學 計算機與信息技術學院,大慶 163318;2.山東科技大學 信息科學與工程學院,青島 266590;3.大慶油田化工有限責任公司 東昊分公司,大慶 163312)
數字信號處理
基于支持向量機和粒子群優化的油層開采狀態識別
李學貴1,許少華2,李 娜3
(1.東北石油大學 計算機與信息技術學院,大慶 163318;2.山東科技大學 信息科學與工程學院,青島 266590;3.大慶油田化工有限責任公司 東昊分公司,大慶 163312)
針對開發小層生產狀態評價問題,基于油井套損檢測信號和儲層巖性、物性、生產動態等動靜態數據,提出了一種支持向量機和粒子群優化相結合的判別算法,較大提高了對多學科信息的綜合能力和判別的準確性。
支持向量機;粒子群優化;開采狀態識別
0 引言
油管受到腐蝕、外力等作用,就會引起套管的損壞,影響油層的注水效果和油水產量,破壞油層的開采狀態。油水井的套管損壞給油田正常勘探開發生產帶來很大的危害,不僅造成經濟損失,而且影響開發效果。大慶油田自投入開發以來至目前共計發現套損井近2萬口,占到開發總井數的15.3%,每年以1200口的速度遞增[1,2]。套損井的存在嚴重制約了油田正常生產,已經成為了制約油田穩產的難題。其危害在于:1)油井由于套損出現了大量的報廢和停產,嚴重影響了產量;2)增加了大量的修井成本;3)破壞了開發小層的注采平衡關系,影響了地層壓力和地質情況,又誘發新的套損。
目前,許多科研人員也對套損成因機理做了大量的研究,較多的研究都是從力學角度出發,設定邊界條件,進行有限元模擬,定性研究套損情況,但是由于地質情況的復雜性及相關數據的不完備性造成了研究的局限性,很多力學參數特別是動態參數是估算而來,很難給出一個定性或者是定量的結論,研究區域以及研究領域的差異性很難用一種通用的機理來進行套損成因描述。近年來,許多學者考慮將神經網絡等智能方法應用到套損預測,但是神經網絡的結構設計過于依賴經驗,支持向量機[3,4]基于結構風險最小化原則,泛化能力更優于神經網絡,模型參數設置也更簡單,被廣泛應用油田勘探開發匯總[5~10]。為此將支持向量機應用油水井的套管損壞問題,實現油層開發狀態識別,具有比較重要的實用價值。
1 支持向量機套管損壞識別模型
基于支持向量機的套管損壞識別模型在套損數據的特征空間中尋找最優分類超平面,構建全局最優的套損分類器。SVM就是通過某種事先選擇的非線性映射將輸入向量映射到一個高維特征空間,在這個特征空間中構造最優分類超平面。
支持向量分類機的核函數受核函數參數σ影響,求解問題的關鍵轉化為在最優核函數下尋找最優的懲罰因子C和核函數參數σ,以使得正確分類率最大。因此,以C和σ為對象在不同核函數類型下,C和σ在一定范圍內取值,對于選定的C和σ,計算此組C和σ下訓練集驗證分類準確率,最終取得訓練集驗證分類準確率最高的那組C和σ作為最佳的參數。懲罰系數C與核參數σ選擇過程實際上是一個優化搜索過程,采用優化算法就可以不必遍歷所有參數點,也能找到全局最優解。針對支持向量機參數優化問題,采用粒子群優化算法對SVM參數尋優。

圖1 支持向量機套管損壞識別算法流程
粒子群優化算法主要設置最大進化次數、種群大小,自身因子和全局因子,慣性因子等參數。由于優化SVM的主要目的在于獲得更高的分類正確率,因此采用訓練集進行CV意義下分類準確率Vacc作為粒子群優化算法的適應度函數,基于粒子群優化算法的SVM參數尋優算法描述如下:
Step 1:設置粒子群優化算法參數,最大進化次數、種群大小,自身因子和全局因子,慣性因子等參數,定義適應度函數Vacc;
Step 2:根據當前粒子位置,計算適應度函數;
Step 3:根據適應度函數值確定當前最優解;
Step 4:判斷是否滿足迭代終止條件,滿足條件轉到Step 6,不滿足Step 5;
Step 5:更新粒子速度,根據粒子速度更新位置,進化步數t=t+1,轉到Step 2;
Step 6:迭代結束,輸出迄今為止的最優解S。
2 油層開采狀態識別指標相關分析
對于套損指標相關分析模型,選出對套損類型影響較大的套損指標因變量,采用的相似系數度量方法為夾角余弦和相關系數。
2.1 夾角余弦
指標Xi的n次觀測值(x1i,x2i,…,xni)可以看成n維空間向量,則Xi和Xj的夾角αij的余弦稱為兩向量的相似系數,記為:

圖2 PSO優化SVM參數算法流程
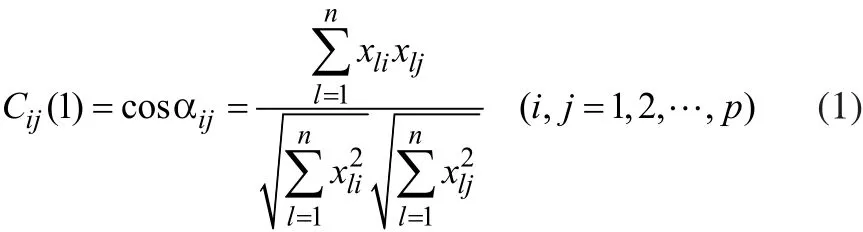
當指標Xi和指標Xj平行時,其夾角αij=0,夾角余弦Cij(1)=1,說明這兩個指標向量完全相似,相似度100%;當指標Xi和指標Xj正交時,夾角αij =π2,夾角余弦Cij(1)=0,說明這兩個向量不相關,相似度為0。
2.2 相關系數
相關系數是用以反映指標之間相關關系密切程度的統計指標,指標Xi和指標Xj的相關系數常用rij表示,記為Cij(2),即:

當Cij(2)=1時,表示兩變量線性相關,一般Cij(2)≤1。
3 基于油水井套損情況診斷的油層開采狀態識別
油層開采狀態識別數據采用S開發區某區塊小層數據進行資料處理,該區塊壓裂井數多、壓裂層段多、壓裂方式全,是典型的套損井較多的區塊。選取區塊中的15口產生套損油井的共301個小層的靜態數據構成數據集,另取該區塊7口井的共141個小層數據組成測試樣本集,套損類型包括錯斷、變形。計算油層數據指標與套損類型的相關系數值,計算結果如表1所示,根據相關系數計算結果判斷套損數據指標對不同對于套損類型的影響進行分析后,選取套損深度、二類砂巖頂深、二類砂巖厚度、砂巖頂深、砂巖厚度、有效頂深、有效厚度、有效厚度累計、孔隙度、滲透率、巖性11個數據指標作為識別的輸入指標數據。
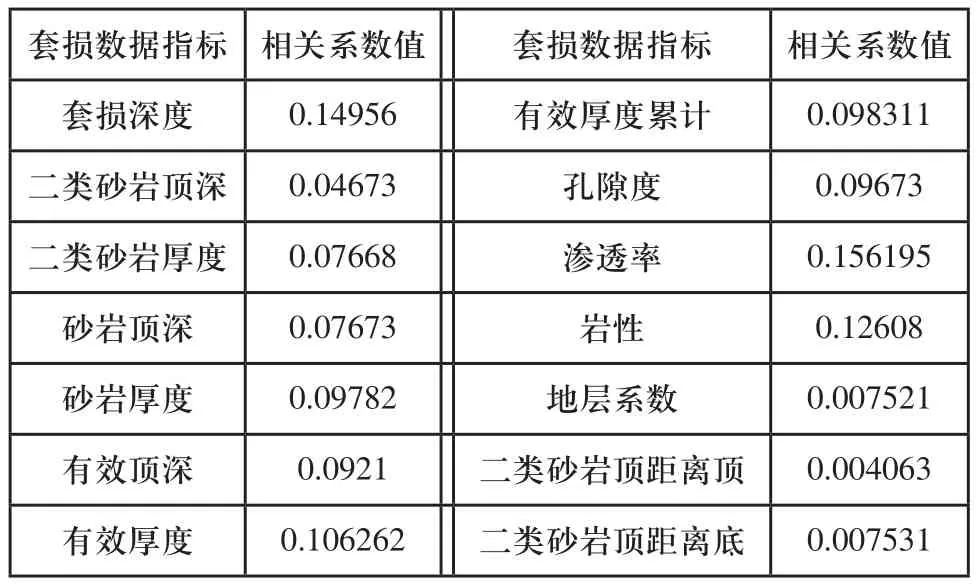
表1 套損數據指標與套損類別的相關系數結果
箱線圖(Boxplot)是一種描述數據分布的統計圖,利用它可以從視覺的角度來觀察變量值的分布情況,對指標數據進行繪制箱線圖,如圖3所示。

圖3 套損數據指標箱線圖
將11種通過相關分析選擇的數據指標和套損類型繪制樣本數據散點圖,分別繪制12張二維散點圖展示數據分布情況,如圖4所示。
基于粒子群算法的支持向量機參數尋優模型,最大迭代次數設置為100,種群數量設置10,懲罰因子C的范圍取[0,10],核參數σ取值范圍[0,10],迭代次數與適應度變化曲線如圖5所示。

圖4 套損數據指標散點圖
【】【】
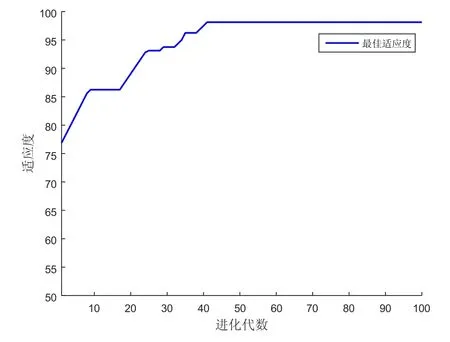
圖5 粒子群算法進化迭代適應度曲線
仿真實驗采用遺傳算法參數尋優方法作為參比模型,支持向量機的核函數分別三種核函數:線性核函數、徑向基(RBF)核函數和Sigmoid核函數。不同算法和三種核函數的套管損壞類型識別結果如表2所示。
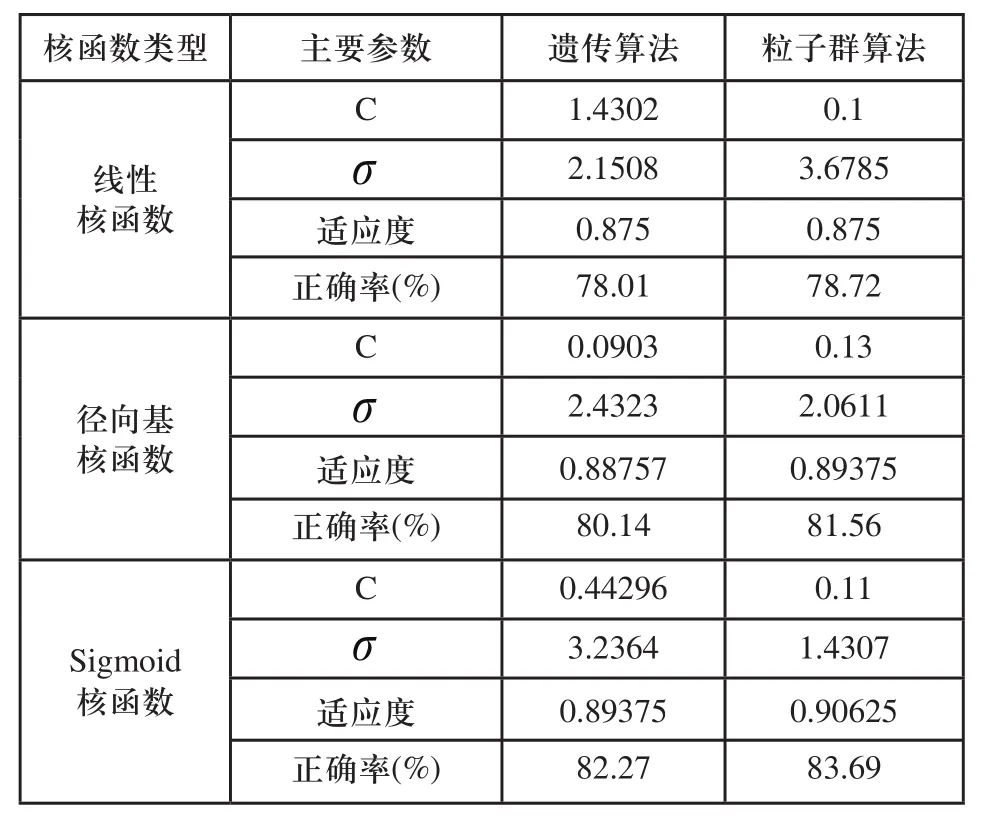
表2 套損識別的識別率比較
從表2仿真實驗結果可以看出,采用粒子群優化算法對SVM參數進行尋優的分類準確率上也優于遺傳算法,得到了較好的效果,為解決油層開采狀態識別問題提供了一種較為有效的方法。
4 結論
針對基于機采井套損檢測數據的開發小層生產狀況診斷分析問題,建立了基于粒子群優化的支持向量機診斷分析模型,可較好解決實際油田開發評價研究中的小樣本建模問題,提高預測模型和診斷分析模型的泛化能力。將PSO-SVM用于基于油田生產過程數據的開發指標預測和基于套管井損檢測數據的開發小層生產狀況分析問題,取得了良好的應用結果。
[1] 陸蔚剛,李自平,劉建忠,陳淑華,劉海龍.油田套損信息管理系統存在的問題及對策[J].大慶石油地質與開發,2006,25(6):79-81.
[2] 張斌然,張紅濱,解玉鋒,等.大慶油田套損井綜合管理平臺的構建[J].中外能源,2014,19(6).
[3] Vapnik VN.The Nature of Statistical Learning Theory[M].Neural Networks IEEE Transactions on,1995,10(5):988-999.
[4] Scholkopf B,Smola A J,Williamson R C.New support vector machines[J].Neural Computation,2000,12(5):1207-1245.
[5] 石廣仁.支持向量機在裂縫預測及含氣性評價應用中的優越性[J].石油勘探與開發,2008,35(5):588-594.
[6] 樂友喜,劉雯林.應用支持向量機方法預測聚合物驅參數[J].石油勘探與開發,2004,31(3):122-124.
[7] 于代國,孫建孟,王煥增,陳偉中,李召成,張振成.測井識別巖性新方法-支持向量機方法[J].大慶石油地質與開發,2005,24(5):93-95.
[8] 楊斌,匡立春,孫中春,施澤進.一種用于測井油氣層綜合識別的支持向量機方法[J].測井技術,2005,29(6):511-514.
[9] 袁士寶,蔣海巖,鮑丙生,陶軍.基于支持向量機的火燒油層效果預測[J].石油勘探與開發,2007,34(1):104-107.
[10] 石廣仁.支持向量機在多地質因素分析中的應用[J].石油學報,2008,29(2):195-198.
Production condition evaluation of development layer based on support vector machine and particle swarm optimization
LI Xue-gui1, XU Shao-Hua2, LI Na3
TP183
A
1009-0134(2017)04-0008-04
2016-12-19
國家自然科學基金(61170132);中國石油科技創新基金(2010D-5006-0302)
李學貴(1982 -),男,山東臨沂人,講師,博士研究生,研究方向為神經網絡和數據挖掘。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
能源工程(2022年1期)2022-03-29 01:06:28
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
今日農業(2020年16期)2020-12-14 15:04:59
消費導刊(2018年8期)2018-05-25 13:20:08
家庭影院技術(2018年4期)2018-05-09 07:07:41
電子制作(2017年20期)2017-04-26 06:57:45
