基于流式計算的數據抽取系統設計
2017-05-02 07:34:02王巖
環球市場 2017年9期
王 巖
北京搜房網絡技術有限公司
基于流式計算的數據抽取系統設計
王 巖
北京搜房網絡技術有限公司
在現在這個互聯網飛速發展的時代,企業數據也成幾何級增長,如何從海量數據中提取、整理出企業想要的數據,使看似無用的數據變得有價值,數據抽取也許是開發過程中經常遇到的問題。通過使用流式計算的思想,對原有系統數據源進行分類,引入消息隊列、數據緩沖池、并行消息隊列等概念,可以很好的解決此問題。
消息隊列、數據緩沖池、流式運算、生產者消費者
1、傳統數據抽取系統設計介紹
面對上百萬的數據需要清理、加工成新的數據,并且在清洗數據的過程中還要與其他數據庫、第三方Web服務進行交互,如果按照傳統的設計思路,我們經常會采用分頁方式及順序執行的方式進行設計。如:通過分頁方式提取數據,然后從第一頁到最后一頁數據進行與其他數據庫進行數據清理、加工,之后再把整理好的數據以分頁的方式從第一頁到最后一頁與第三方Web服務進行交互,最后在用分頁方式將所有數據存入到數據庫中。這種方式是一種開發高效的設計方式,可以在一定程度上節省開發時間和成本,但卻是一個緊繃的結構,通常會造成程序運行時間的浪費,而且由于步驟上下游的耦合度過高,經常會遇到上游宕機,下游無法處理等問題。雖然看似這種設計方式可以節約開發成本,但是因為整體結構設計緊耦,會導致項目后期維護難度增加。
2、流式計算的數據抽取系統設計
流運算是計算機程序的一種數據整理、分析的方式,在流運算當中,高級軟件的運算法則在接收流數據時就開始對其進行分析、整理。了解了流運算的概念之后,接下來我們所要做的就是對數據、步驟進行分類、業務解耦。
2.1 數據分類
基礎數據源,我們將被提取的數據稱之為基礎數據源,基礎數據源可以按特征進行數據分類,如:城市、日期等。注意:選擇的特征分類不易過多,且特征可以涵蓋所有數據源信息。
數據字典,是指將一些數據字典或者數據量小且不變的數據稱之為數據字典,這種數據數據量小,但在清洗、加工數據過程中起關鍵性作用,如:城市與城市簡稱對應表、ID與相應名稱對應表等。
目的數據,我們將最終得到的數據稱之為目的數據,它經過多個步驟最終存入數據庫或者形成XML服務。
第三方數據源,因為基礎數據源無法直接作為最終的目的數據,需要通過其他數據庫進行數據整理、加工,我們稱之為第三方數據源,這種數據源在整個數據整理的過程中,有可能會有多次并且是不同數據庫的第三方數據源。
第三方Web服務,通過基礎數據源的某一列的值進行Http請求獲得相應數據,稱之為第三方Web服務。
2.2 流式運算設計
流式運算設計的主要思想是解耦和步驟的拆分,數據的分類其實是對業務的整理和解耦,并且按照不同類型的數據操作進行步驟的拆分。流式運算所采用的核心技術是消息隊列。
消息隊列中間件是大型系統中不可缺少的組件,它采用數據先進先出的原則,解決系統邏輯耦合,異步消息,流量削鋒等問題,實現高性能,高可用,可伸縮的架構。常見的消息隊列中間件有:MSMQ、Kafka、RabitMQ等。消息隊列常見的模型有:點對點和發布、訂閱。消息隊列核心設計思想是生產者、消費者模式,在實際的軟件開發過程中,經常會碰到如下場景:某個模塊負責產生數據,這些數據由另一個模塊來負責處理(此處模塊是廣義的,可以是類、函數、線程等)。產生數據的模塊,就形象地稱為生產者;而處理數據的模塊,就稱為消費者。消息隊列具有可靠緩存,可以防止數據丟失,防止數據堆積;消息隊列還具有流式模型,因為它的生產者、消費者模型也完全符合這種storm(流)模式;消息隊列還具有消息總線功能,它以一種總線的方式出現,負責消息的傳遞和分發,直接減少了模塊間的耦合程度。
對于原有系統的改造中,因為業務數據的多樣性和復雜性,我們需要使用多個消息隊列組合使用,將不同的數據分類固化到不同的消息隊列當中,如:第一個消息隊列提取全部的數據字典和分頁方式提取基礎數據源,第二個消息隊列與第三方數據進行交互處理數據,第三個消息隊列與Web服務進行交互處理數據等等。同時,為了更好的提升每個步驟的處理效率,我們引入了數據緩沖池和并行消息隊列的概念。數據緩沖池是消息隊列與消息隊列之前通過程序運用緩存技術構建的一個數據緩沖池,當數據緩沖池達到一定數量的時候開啟下一個消息隊列進行數據運輸、處理,例如:如果數據緩沖池閾值設置為100,那么如果當某個消息隊列每次處理20條數據式,這個消息隊列必須運行5次后,使得數據緩沖池大小達到100以后,才能開啟它后面的消息隊列。并行消息隊列的概念是指每個消息隊列可以橫向擴充,例如:當數據緩沖池中有100條數據時,每條消息隊列處理20條數據,為了提高運行速度,可以通過代碼增加了5條消息隊列,那么當程序運行時候5條消息隊列并行處理,這5條消息隊列稱之為并行消息隊列。注意,并行消息隊列采用多線程開發的思想,并行消息隊列越多會對這個消息隊列的第三方數據庫或者第三方Web服務造成負載壓力,配置不合理反而會造成性能問題。
3 流式運算架構設計(見圖1)
在第一個消息隊列啟動之前,數據字典通過全量的方式,加載到程序緩存當中。因為基礎數據源通過不同特征(如:城市)進行了分類,程序通過多線程的方式,開啟不同線程執行各自的程序,即北京、上海、天津等城市并行執行后續消息隊列操作,以下舉例為分類為北京的數據,第一個消息隊列(Queue1)開始以分頁的方式對基礎數據源進行抽取。當第一個數據緩沖池滿了以后,開啟第二個消息隊列(Queue2),程序與第三方數據源進行交互并對數據進行加工。當第二個數據緩沖池滿了以后開啟第三個消息隊列(Queue3),并通過程序請求第三方Web服務對數據進行加工。最后當第三個數據緩沖池滿了以后,開啟第四個消息隊列,第四個隊列(Queue4)對最后形成目的數據,并入庫或者形成xml服務。如果過程中還有其它第三方數據源或者第三方Web服務,可以縱向增加消息隊列(QueueN)即增加了數據處理步驟。如果當某個消息隊列時間消耗過長或者阻塞時候,可以通過增加并行消息隊列,提高并發,例如:Queue31、Queue32。在流式運算數據抽取系統中,需要在程序中增加運行日志,運行日志主要包括每個消息隊列的開始時間和結束時間,每個步驟中出錯日志,以及處理多少條過濾多少條,因為流式運算系統,運行日志起到對整體程序健康度的監測,通過監測每個消息隊列的運行日志中的運行時間,可以在耗時較長的消息隊列增加并行消息隊列來提高整體的運算速度。
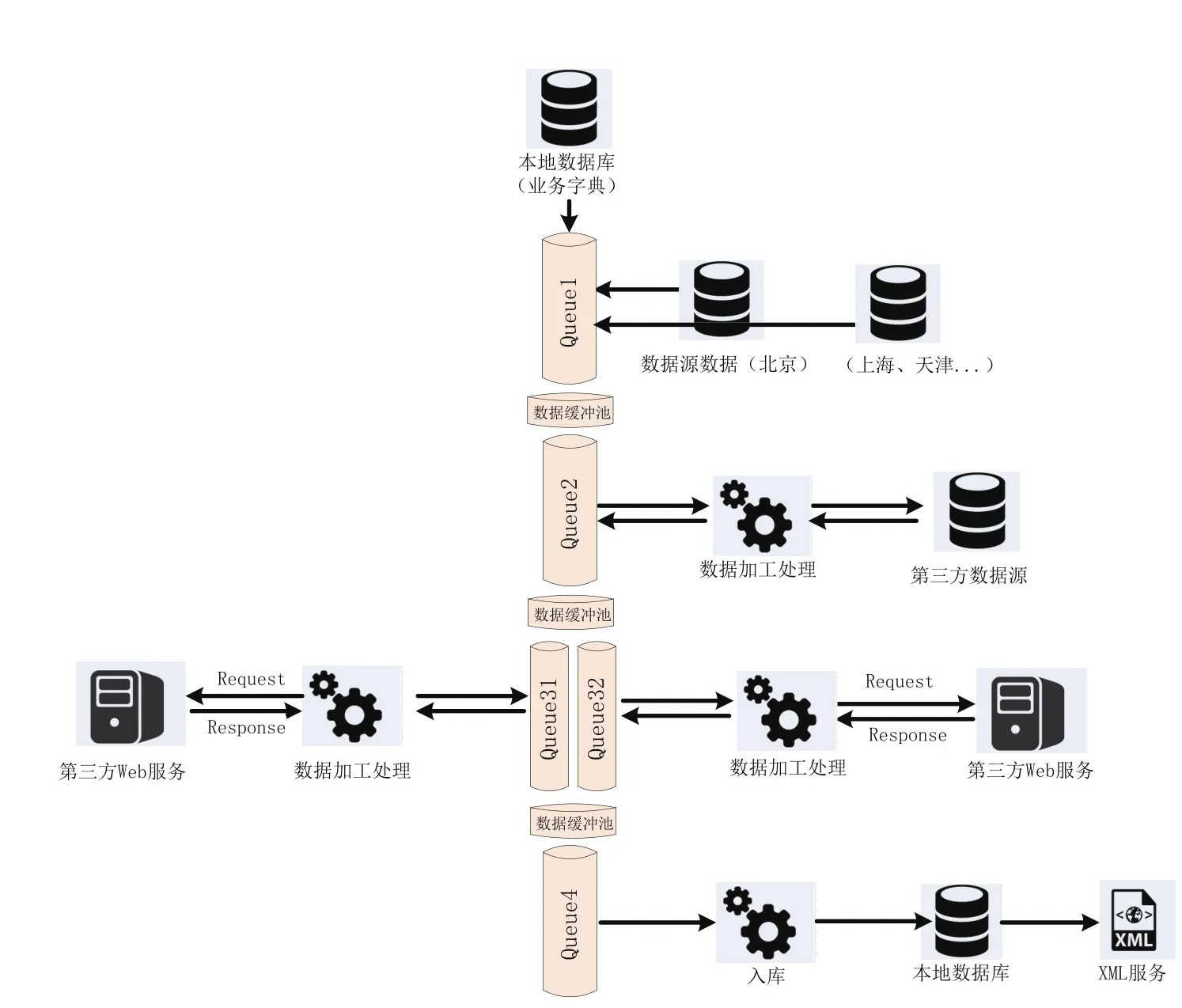
圖1
這種流式運算數據抽取系統的設計,實現程序的縱向拓展和橫向拓展,通過增加消息隊列實現縱向拓展,使數據處理之間解耦。通過增加并行消息隊列實現橫向拓展,提高單步并發。在實際應用中這種設計方式,可以大大提高程序每分鐘處理量,降低程序之間的耦合性,并且不會出現某一部分數據出現問題導致整個程序無法產出目的數據。在開發方面,流式運算方式將步驟解耦,搭建好整體框架以后可以很好的分配相關人員開發相關業務,大大提高了開發質量和開發效率。
4、結束語
流式運算是處理大數據手段之一,通過多個消息隊列可以搭建一個強壯的流式運算框架,再根據需求開發不同業務,就形成了流式計算的數據抽取系統,這種系統屬于后臺系統,多與系統中的計劃任務結合使用,通過計劃任務定時定點啟動流式計算數據抽取系統,實現數據的篩選整理,入庫或產出相關的數據服務,為后續業務系統提供基礎數據源進行分析展示。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
人大建設(2019年12期)2019-05-21 02:55:44
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
中山大學法律評論(2018年1期)2018-03-30 01:21:00
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
家庭影院技術(2017年9期)2017-09-26 03:41:45
環球時報(2017-03-30)2017-03-30 06:44:45
