基于蟻群優化的選擇性集成數據流分類方法
2017-05-13 03:53:51王軍劉三民劉濤
長江大學學報(自科版) 2017年5期
王軍,劉三民,劉濤
(安徽工程大學計算機與信息學院,安徽 蕪湖 241000)
基于蟻群優化的選擇性集成數據流分類方法
王軍,劉三民,劉濤
(安徽工程大學計算機與信息學院,安徽 蕪湖 241000)
基于集成學習的數據流分類問題已成為當前研究熱點之一,而集成學習存在集成規模大、訓練時間長、時空復雜度高等不足,為此提出了一種基于蟻群優化的選擇性集成數據流分類方法,用蟻群優化算法挑選出優秀的基分類器來構建集成分類模型。該方法首先對所有基分類器采用交叉驗證計算分類精度,同時采用Gower相似系數求出基分類器之間的差異性,然后把分類精度和分類器差異性作為分類器挑選標準,從全部基分類器中選出一部分來構建集成模型,最終挑選的基分類器不僅具有良好的分類精度,同時保持一定差異性。在標準仿真數據集上對構建的集成分類模型進行仿真試驗,結果表明,該方法與傳統集成方法相比在準確率和穩定性方面均有顯著提高。
數據流分類;概念漂移;選擇性集成;蟻群優化算法;差異性
隨著信息化技術的發展和應用需求不斷深入,數據流已廣泛存在于各行各業,如網絡數據、天氣預測數據、無線傳感數據、金融和電網數據等[1]。如何挖掘出這些數據流中有價值的信息,已成為當前研究的熱點問題。而數據流隱含噪聲同時具有時序特性和概念漂移現象,導致傳統分類模型難以適應數據流的分類問題。
目前,國內外關于數據流分類已取得較多研究成果,以集成學習作為數據流分類模型已成為主流。把集成學習引入到數據流分類中,不僅提高了算法學習精度,增強了學習能力,同時還強化了算法在復雜環境中的學習效果。Street等[2]較早將集成學習應用到數據流分類中,保持集成規模不變,用新分類器替換舊分類器實現對新知識的學習。而概念漂移發生初期體現新概念的基分類器不足以抗衡其他分類器,導致該算法在概念漂移發生初期對樣本無法準確分類,鑒于此,Wang等[3]在SEA算法基礎上提出改進算法AWE,該算法根據基分類器對最新訓練樣本的分類準確率來設置分類器權值,給準確率高的基分類器分配較高權重,有效增強集成模型預測精度。針對數據流出現概念漂移導致分類模型頻繁變更問題,Farid等[4]基于集成學習實現了一種自適應數據流分類方法,使集成分類模型保持良好的穩定性和靈活性。隨后,毛沙沙等[5]利用旋轉森林策略獲得樣本子集來訓練分類器,使基分類器之間保持一定差異性,提高集成模型泛化能力。同年,Liao等[6]針對數據流分類問題提出一種新的集成分類模型,通過靈活分配基分類器權重使集成分類模型快速適應數據流中概念漂移的發生。與此同時,Gogte等[7]結合聚類思想實現一種混合集成分類模型,能快速捕獲概念漂移,同時有效解決已標記樣本少難題;鄒權等[8]基于集成學習并結合分層思想在層級結構基礎上通過集成學習來構建分類模型,使集成學習更加靈活的應用于數據流分類;針對含噪動態數據流分類,王中心等[9]實現了一種自適應集成分類算法,采用Bayes過濾噪聲,通過動態更新分類模型來快速適應概念漂移。從以上研究可以看出,采用集成學習進行數據流分類具有明顯優勢。而從現有文獻分析可知,通常采取增加基分類器數量來提高集成模型的分類精度和泛化能力,使集成規模不斷增大,不僅導致存儲空間急劇增加,同時集成規模過大導致集成模型訓練時間長、算法時空復雜度高等問題。為此,筆者提出了一種基于蟻群優化的選擇性集成數據流分類方法。
1 蟻群優化算法
蟻群算法最早由意大利學者Dorigo Macro等[10]在人工生命會議上提出,隨后國內外研究人員對其不斷進行改進,開發出多種不同的蟻群算法版本并成功應用于優化領域。夏小云等[11]對蟻群優化算法理論研究進行了系統概述,論述了算法的尋優原理、收斂性、復雜度、近似性等,同時分析總結了蟻群優化算法在求解和優化各類問題上的性能。
蟻群優化算法是模擬自然界真實螞蟻覓食行為,螞蟻在走過的路徑上釋放一種稱為信息素的物質同時能感知信息素,該物質對螞蟻選擇路線起到誘導作用,路徑上走過的螞蟻越多信息素含量越高,螞蟻選擇該路徑的概率也就越高,最終收斂于最優路徑。
蟻群優化算法的基本原理可以用最短旅行商問題予以說明。假設有n個城市,螞蟻數量為m,dij表示城市i、j之間的距離,τij(t)代表t時刻城市i、j之間的路徑上信息素含量,則在t時刻螞蟻k由城市i轉移到城市j的概率為:
(1)
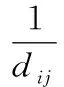
τij(t+1)=(1-ρ)τij(t)+Δτij
(2)
式中,ρ∈(0,1)表示信息素揮發系數; Δτij表示該次迭代中路徑ij上信息素的增量,初始時刻為0,計算方法如下:
(3)
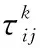
(4)
式中,Q為常數表示信息素強度,對算法收斂速度起作用; Lk是第k只螞蟻在此次循環中走過的路徑長度,經過一定次數的循環迭代后,當滿足停止條件(收斂或到達循環次數)時,得到最優路徑和最短路徑長度。
2 選擇性集成學習
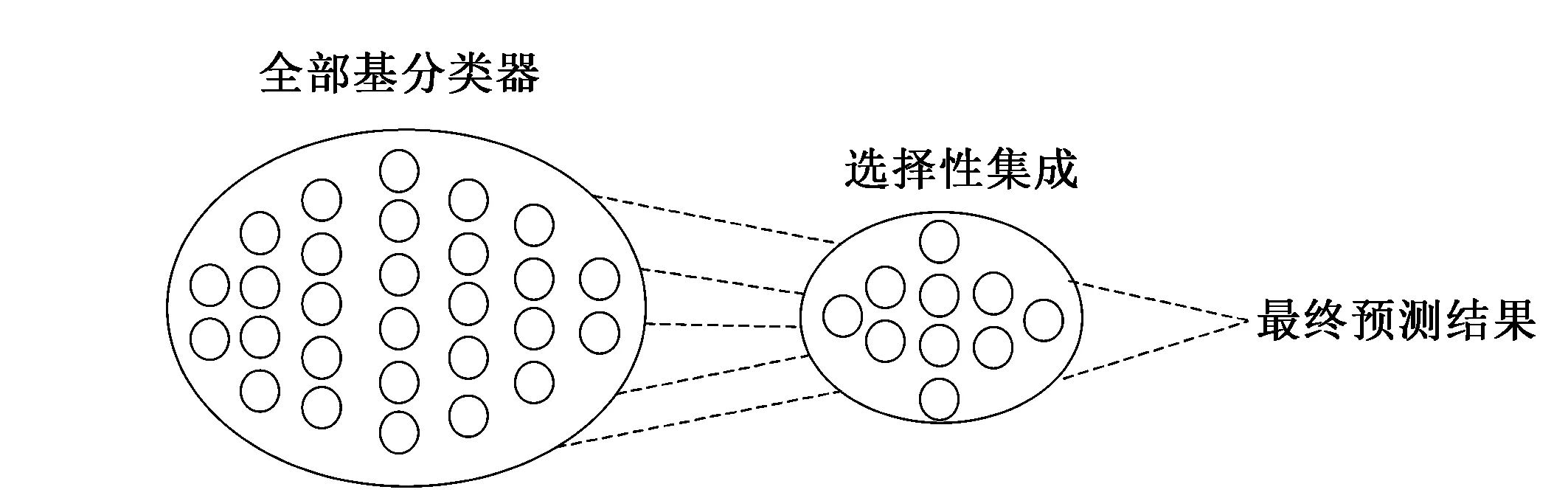
圖1 選擇性集成原理示意圖
選擇性集成學習最早由Zhou等[12]提出,其思想是從全部基分類器中剔除作用不大、分類性能不好的分類器,用剩余的分類器構建集成模型能得到更好的預測效果,即“Many Could Be Better Than All”。目前選擇性集成已成為集成學習領域預測效果最好的學習范式。其原理示意圖如圖1所示。
選擇性集成作為集成學習中一種新的學習范式提高了集成學習的學習效果,同時解決了集成規模過大帶來的困擾。目前選擇性集成數據流分類也已取得眾多研究成果。趙勝穎等[13]提出一種基于智能群體的選擇性神經網絡集成方法,利用智能群體的快速收斂提高了算法效率、降低計算復雜度。此外,Liu等[14]基于k-means方法提出一種選擇性集成學習算法,克服了集成學習中存儲空間大、訓練時間長、反復訓練等問題。與此同時,為保持集成模型中分類器之間的差異性,該團隊又設計一種基于k-均值和負相關的選擇性集成學習方法[15],該方法有效解決基分類器之間的冗余問題,提高了集成模型預測效率。綜上可知選擇性集成在數據流分類中具有明顯優勢,而根據挑選規則不同選擇性集成可分為基于選擇方法、聚類方法、排序方法和優化方法的選擇性集成學習算法[16]。其核心思想是根據挑選規則選擇部分優秀的基分類器來構建集成模型,從而提高集成模型的分類精度和預測效率同時節省存儲空間。其中選擇性集成基本框架如下:
1)Input: 訓練集T1,驗證集T2,基分類器訓練算法C,基分類器集合T,選擇的基分類器集合S,測評方法M;
2)初始化:基分類器集合T=?;
3)訓練過程:
Fort=1,2,…,T;
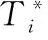
得到基分類器集合T={C1,C2,…,CT};
EndFor
4)選擇過程:
在驗證集T2上對各基分類器Ct進行測試,得到測試結果Rt,利用測評方法M針對測試結果Rt進行測評;
根據測評結果,挑選出符合條件的基分類器CS添加到集合S中;
5)Output: 選擇的基分類器集合S={C1,C2,…,CS};
3 ACOBSE方法
由于構建分類精度高和泛化能力好的集成分類模型,不僅基分類器要具有較高的分類準確率,同時分類器之間要保持一定差異性。基于蟻群優化的選擇性集成數據流分類方法(ACO algorithm Based Selective Ensemble,ACOBSE)就是利用群體智能中經典的蟻群優化算法ACO來選擇分類精度高、個體差異性大的基分類器來構建集成模型。該方法首先對訓練集采用BatchMode方式訓練出多個基分類器,通過交叉驗證計算出它們的分類精度,同時采用Gower相似系數計算出基分類器之間的差異性,然后把分類精度和分類器差異性作為基分類器挑選標準從全部分類器中選出部分分類精度高、差異性大的分類器來構建集成模型。該方法不僅減小了集成規模同時利用蟻群優化算法的快速收斂性來提高算法效率。
為便于描述,對常用的基本概念給出定義:
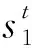
2)概念漂移。是指數據產生的聯合概率分布隨時間變化而發生不可預知的變化,即Pt(x,y)≠Pt+1(x,y),其中,x代表樣本向量,y表示樣本類別。
3)集成學習。對待測樣本進行分類時,用若干弱分類器對同一個樣本進行預測,再把結果按照某種策略融合獲得最終預測結果,集成學習決策函數可形式化為:
其中,ht(x)為弱分類器;HT(x)為集成后的強分類器;at表示基分類器權重。
3.1 交叉驗證
交叉驗證的基本思想是將數據分為2部分:一部分作為訓練集用于分類器的訓練,另一部分作為測試集用于分類器預測精度的檢驗。由于2部分數據不同,使得對預測精度的估計也更接近真實情況。目前常用的交叉驗證有K折交叉驗證、5×2交叉驗證t檢驗和F檢驗等。筆者采用的是K折交叉驗證t檢驗方法。
K折交叉驗證原理是將數據等分為K份,選擇其中K-1份作為訓練集用于分類器的訓練,剩余一份作為測試集用于分類器預測精度的檢驗,將K份數據逐一作為測試集進行訓練和測試,最終得到K個度量值。K折交叉驗證t檢驗計算方法如下:
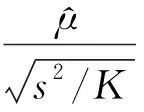
(5)
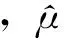
(6)
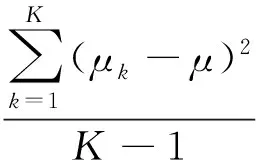
(7)
式中,μk表示在第k折交叉驗證算法中度量值的差值。
K折交叉驗證t檢驗主要分為2折交叉驗證、5折交叉驗證和10折交叉驗證t檢驗,筆者采用K折交叉驗證中最常用的10折交叉驗證t檢驗來計算基分類器的分類精度。把分類器預測精度作為挑選基分類器的標準之一,使構建的集成模型獲得良好的分類性能。
3.2 分類器差異性
目前對集成學習領域的研究不再局限于對算法的提出和改進,更多關注對基分類器關系的研究,尤其是分類器差異性研究。分類器之間具有差異性是集成分類模型生效的必要條件,同時也是集成模型具有良好泛化能力的關鍵因素。若集成模型中進行組合的基分類器是相同、無差異的,分類性能并不會提高。因此要提高集成模型的分類性能,基分類器之間必須具有一定差異性,即至少存在一些分類器對其它分類器判斷錯誤的樣本作出正確的決策。筆者定義的分類器差異性是結合Gower相似系數計算得到,該計算模型具有分類模型獨立和預測能力獨立等優點[17]。
為方便描述,假設e表示測試樣本,E代表測試樣本集,符號de(cx,cy)表示分類器x、y在樣本e上的差異性,符號se(cx,cy)代表分類器x、y在樣本e上的相似性,二者滿足如下性質:
①0≤se(cx,cx),de(cx,cy)≤1;
②de(cx,cy)=1-se(cx,cy);
結合Gower相似系數計算出分類器基于單個樣本的相似性,計算方法見式(8):
se(cx,cy)=1-δe(cx,cy)
(8)
在式(8)基礎上,基分類器基于單樣本的差異性計算方法如下:
de(cx,cy)=1-se(cx,cy)=δe(cx,cy)
(9)
(10)
式中, |C|表示樣本類別數;概率PDxj(e)表示基分類器x在單個測試樣本e上關于類別j的后驗概率;PDyi(e)表示基分類器y在單個測試樣本e上關于類別j的后驗概率;Rj(e)代表測試樣本e基于類j的后驗概率極差:
Rj(e)=max{PD1j(e),…,PDnj(e)}-min{PD1j(e),…,PDnj(e)}
(11)
綜上,在單個測試樣本上基分類器差異性計算方法的基礎上,可導出在樣本集E上基分類器之間的差異性計算方法:
(12)
3.3 ACOBSE算法描述
在上述交叉驗證和分類器差異性計算模型基礎上,結合多分類器動態集成思想,給出選擇性集成數據流分類方法的算法描述。其中DS表示訓練數據流,DB代表驗證數據集,初始基分類器數量為n,最大集成規模為20,α表示信息素對螞蟻選擇分類器的的作用程度,β表示分類器差異性對螞蟻選擇分類器的作用程度,則ACOBSE算法的詳細描述如下:
1)Input: 訓練集DS,驗證集DB,基分類器數量n,選擇的基分類器集合S,集成規模T,參數α,參數β;
2)初始化相關參數:S=?,T=20;
3)訓練過程:
基于訓練集DS,采用批處理方式訓練出n個基分類器,并用10折交叉驗證t檢驗計算出各分類器的分類精度;
對訓練出的基分類器根據式(9)分類器差異性計算方法,基于驗證集DB求出基分類器之間的差異性;
4)挑選過程:
螞蟻首先基于準確率選擇一個基分類器并添加到集合S中,同時把該基分類器標記為已訪問;
Fort=1,2,…,T;
根據轉移概率計算螞蟻下一個要選擇的分類器,轉移概率計算方法是基于式(1)思想構建,把分類精度和分類器差異性兩者作為相關參數進行基分類器的挑選,具體計算方法如下:
(13)

5)Output:集成分類模型在測試數據集上的分類準確率;
其中,tao(i)表示分類器i的信息素濃度,取值為對應基分類器的分類精度值;differ(j)(i)代表集合S中最新基分類器j與目標分類器i之間的差異性。
4 仿真試驗與結果分析
4.1 仿真數據集
試驗所用數據集源自平臺MOA環境中的移動超平面數據集[18]。該數據集樣本屬性值在[0,1],并通過m維度超平面隨機生成,樣本標簽分為正類標簽和負類樣本2類,在形成數據集過程中主要考慮3個參數n、s、t的變化:噪聲參數n表示在數據流中引入的噪聲數據量;參數t表示每隔N個樣本,樣本標簽權值的改變量;參數s表示每隔一定數量樣本移動超平面方向以概率s發生翻轉。規定每個數據集含有2W個樣本,并在參數t=0.1、s=10%固定條件下,設置仿真試驗數據集共有5個特征屬性,其中2個特征屬性隨時間變化發生概念漂移現象,同時通過改變噪聲參數n(0,10%,20%),即不含噪聲、10%噪聲、20%噪聲,生成3個數據集(記為H0、H1、H2)進行測試。
4.2 試驗方案
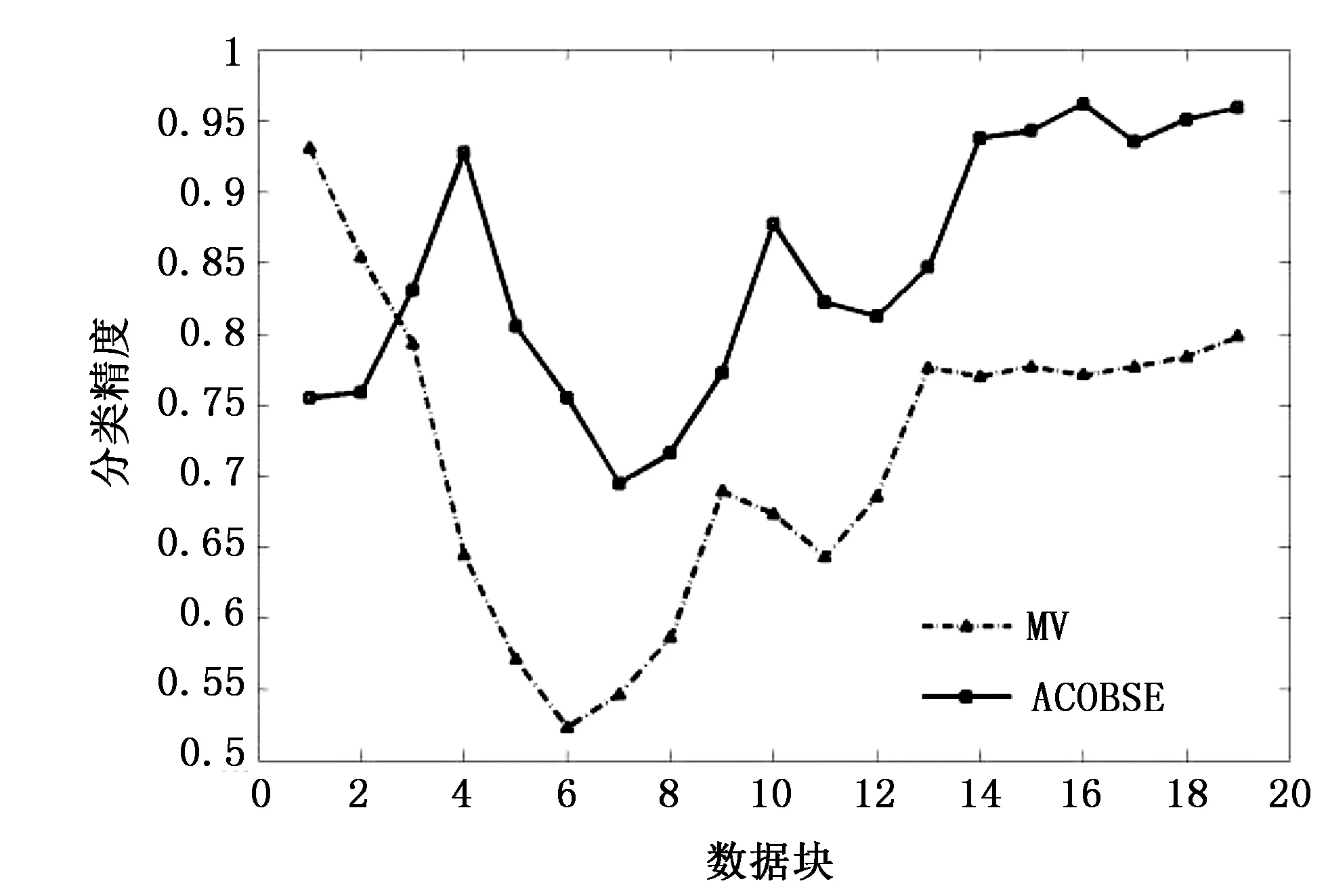
圖2 數據集H0(不含噪聲)試驗結果
仿真試驗基于WEKA平臺在Eclipse環境下完成,在標準仿真數據集上進行試驗。同時結合現有文獻采用基于準確率選擇集成的簡單投票方法(Majority Voting,MV)與該集成分類算法進行對比。試驗采用Bayes學習器作為基分類器,采用BatchMode訓練生成,其中數據塊大小為1000個樣本,首先訓練40個基分類器,采用10折交叉驗證得出各基分類器的分類精度,集成規模定為20。2種集成分類模型在3個數據集上分類情況分別如圖2~圖4所示。 從圖2~圖4可知,基于蟻群優化的選擇性集成方法是可行的的,分類準確率比基于傳統準確率選擇性集成方法要好。這主要是因為ACOBSE方法用基分類器的分類精度作為信息素濃度,利用蟻群優化算法構建集成模型時,挑選的是分類精度相對較高的基分類器,提高了集成分類模型的預測精度。與此同時,當數據流含有噪聲時,ACOBSE算法的分類精度起伏程度相比基于準確率動態集成方法要低(見圖3和圖4),說明ACOBSE方法能更好地應對概念漂移的發生,只有當數據流中概念漂移達到一定程度之后才會對集成模型的分類精度帶來影響,即算法具有良好的魯棒性。當概念漂移發生之后,ACOBSE方法分類曲線圖出現低峰,但能夠快速恢復其識別準確率,且分類精度下降幅度比MV方法小,說明ACOBSE方法能夠很好地適應概念漂移,能夠及時捕捉、快速適應概念漂移的出現,使集成模型保持正常分類水平。ACOBSE方法在構建集成分類模型時,用分類器差異性作為基分類器挑選標準之一,保持基分類器之間的多樣性,使集成模型具有良好的泛化能力,這也是該算法在分類初期預測效果一般,而一旦發生概念漂移該算法的分類精度要明顯優于傳統集成方法的主要原因。在數據流包含噪聲較高的環境下,ACOBSE算法在進行數據流分類時出現尖峰次數比MV分類方法相比要少(見圖4),而且尖峰起伏程度相對比較低。每次出現尖峰即是數據流發生概念漂移現象,數據集包含噪聲越大發生概念漂移的幾率就越大,而ACOBSE方法曲線圖中尖峰較少,說明ACOBSE方法比傳統集成方法具有更好的穩定性,能夠快速適應概念漂移并對數據流中出現的新概念準確分類。這主要是因為ACOBSE方法在挑選基分類器時不僅考慮分類精度,同時把分類器差異性作為衡量標準之一,保持各基分類器之間的多樣性,使集成模型面對概念漂移依然具有良好的泛化能力。
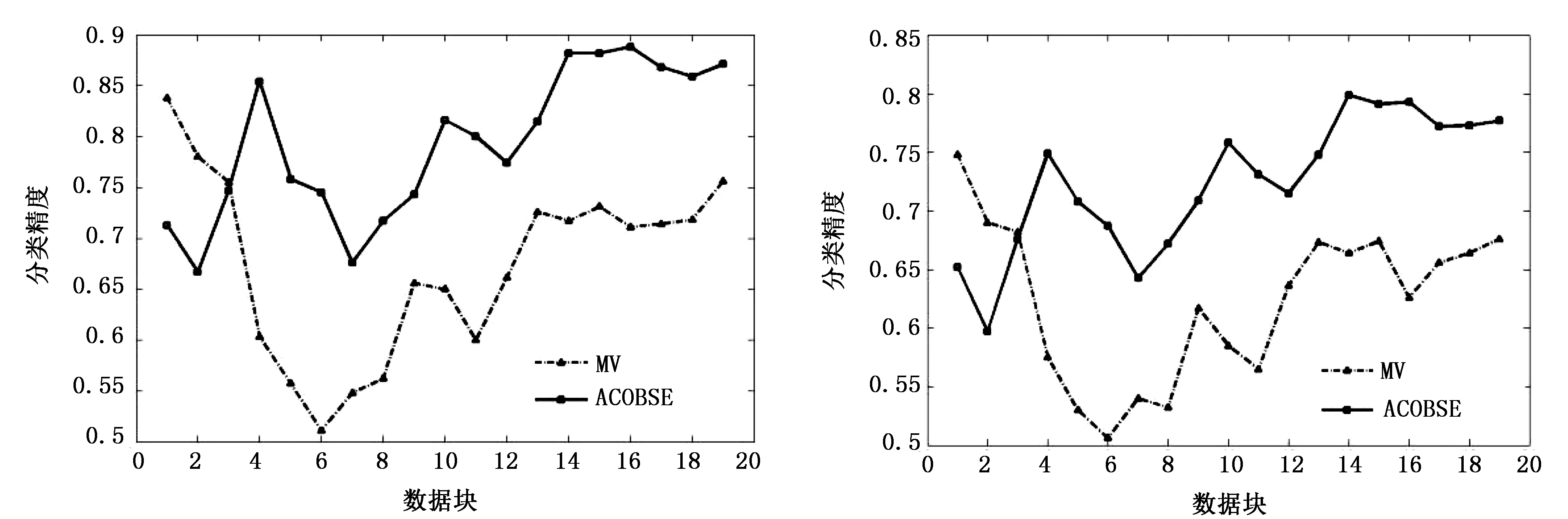
圖3 數據集H1(10%噪聲)試驗結果 圖4 數據集H2(20%噪聲)試驗結果
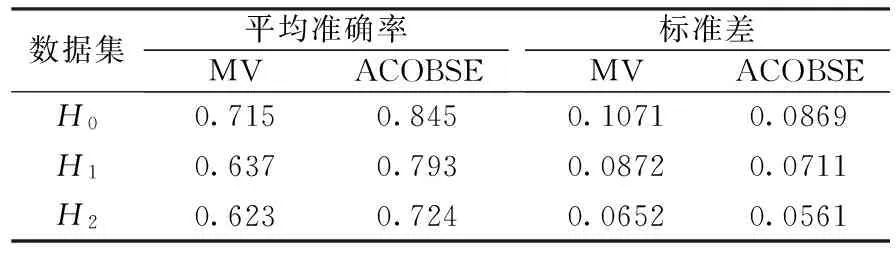
表3 2種集成模型試驗結果
從表3準確率統計分析可知,ACOBSE算法明顯優于傳統集成方法MV,分類準確率約高出12%,在一定噪聲環境下依然擁有較高的準確率,說明ACOBSE算法能較好的應對數據流中隱含的噪聲,且快速適應數據流中出現的概念漂移現象。當數據集從不含噪聲變成含有噪聲數據時,ACOBSE方法的分類精度值下降明顯少于MV方法,說明ACOBSE方法在面對含有噪聲的數據時穩定性更好,具備較強的抗噪特點。因為ACOBSE方法在構建集成模型時,用分類器之間的差異性作為挑選標準之一,保持集成分類模型中分類器之間的多樣性,使集成模型面對隱含噪聲和概念漂移的數據流依然具有良好的分類準確率和泛化能力。與此同時,ACOBSE方法構建的集成模型分類穩定性相對傳統MV方法較好,在一定噪聲環境下依然能夠準確對數據流進行分類,且隨著噪聲的增加ACOBSE方法依然表現出較好的穩定性,說明該算法具有較強的魯棒性。
綜上所述,基于蟻群優化算法的選擇性集成數據流分類方法是可行的,能夠挑選出性能優良的基分類器構建集成分類模型。
5 結語
針對動態數據流分類問題,筆者提出并實現了一種基于蟻群優化的選擇性集成方法。該算法不僅考慮基分類器的分類精度,同時計算分類器之間的差異性,最終挑選的基分類器不僅具有良好的分類精度,同時保持一定差異性,這也是算法在噪聲環境下保持分類穩定性的關鍵因素。仿真試驗表明,基于蟻群優化的選擇性集成數據流分類方法在分類精度和穩定性方面均有不錯效果,是一種可行的數據流分類方法。然而實際數據流中大量數據是無標簽的樣本,因此如何在具有不完全標記的數據流環境下或樣本不平衡條件下,基于主動學習和半監督學習技術設計數據流的概念漂移檢測與分類方法是后續的主要研究內容。
[1]Dietterich T G. Machine learning research:four current directions[J]. AI Magazine, 1997, 18(4):97~136.
[2]Street W N, Kim Y S. A streaming ensemble algorithm (SEA) for large-scale classification[A] .ACM SIGKDD International Conference on Knowledge Discovery & Data Mining[C]. 2001:377~382.
[3]Wang H, Fan W, Yu P S, et al. Mining concept-drifting data streams using ensemble classifiers[A] .ACM SIGKDD International Conference on Knowledge Discovery and Data Mining[C].2003:226~235.
[4]Farid D M, Zhang L, Hossain A, et al. An adaptive ensemble classifier for mining concept drifting data streams[J]. Expert Systems with Applications, 2013, 40(15):5895-5906.
[5]毛莎莎, 熊霖, 焦李成,等. 利用旋轉森林變換的異構多分類器集成算法[J]. 西安電子科技大學學報(自然科學版), 2014, 41(5):48~53.
[6]Liao J W, Dai B R. An ensemble learning approach for concept drift[A] .International Conference on Information Science and Applications (ICISA)[C]. 2014:1~4.
[7]Gogte P S, Theng D P. Hybrid ensemble classifier for stream data[A].International Conference on Communication Systems and Network Technologies (CSNT)[C]. 2014:463~467.
[8]鄒權, 宋莉, 陳文強,等. 基于集成學習和分層結構的多分類算法[J]. 模式識別與人工智能, 2015, 28(9):781~787.
[9]王中心, 孫剛, 王浩. 面向噪音和概念漂移數據流的集成分類算法[J]. 小型微型計算機系統, 2016, 37(7):1445~1449.
[10]Colorni A, Dorigo M, Maniezzo V. Distributed optimization by Ant Colonies[A] .Ecal91-European Conference on Artificial Life[C]. 1991.
[11]夏小云, 周育人. 蟻群優化算法的理論研究進展[J]. 智能系統學報, 2016, 11(1):27~36.
[12]Zhou Z H, Wu J X, Tang W. Ensembling neural networks: many could be better than all[J]. Artificial Intelligence, 2002, 137(1-2):239~263.
[13]趙勝穎, 高廣春. 基于蟻群算法的選擇性神經網絡集成方法[J]. 浙江大學學報(工學版), 2009, 43(9):1568~1573.
[14]Liu L, Wang B, Zhong Q, et al. A selective ensemble method based on K-means method[A] .International Conference on Computer Science and Network Technology[C].2015:665~668.
[15]Liu L, Wang B, Yu B, et al. A novel selective ensemble learning based on K-means and negative correlation[M].Cloud Computing and Security,Springer International Publishing, 2016.
[16]張春霞, 張講社. 選擇性集成學習算法綜述[J]. 計算機學報, 2011, 34(8):1399~1410.
[17]劉余霞, 呂虹, 劉三民. 一種基于分類器相似性集成的數據流分類研究[J]. 計算機科學, 2012, 39(12):208~210.
[18]Hulten G, Spencer L, Domingos P. Mining time-changing data streams[A].Acm Sigkdd Intl Conf on Knowledge Discovery & Data Mining[C]. 2001:97~106.
[編輯] 洪云飛
2016-12-10
國家自然科學基金項目(61300170);安徽省自然科學基金項目(1608085MF147);安徽省高校省級優秀人才重點項目(2013SQRL034ZD)。
王軍(1992-),男,碩士生,現在主要從事機器學習、數據挖掘方面的研究工作。
劉三民(1978-),男,博士,副教授,現主要從事模式識別、機器學習、數據挖掘方面的教學與研究工作,aqlsm@163.com。
TP391
A
1673-1409(2017)05-0037-07
[引著格式]王軍,劉三民,劉濤.基于蟻群優化的選擇性集成數據流分類方法[J].長江大學學報(自科版),2017,14(5):37~43.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
