一種多層次分布式數據挖掘方法的改進研究
2017-05-18 13:25:02黃成兵
現代電子技術 2017年9期
黃成兵


摘 要: 針對多層次分布式數據存在高維特征和類間不平衡因素的問題,提出一種基于隨機決策樹檢索模型的數據挖掘技術。采用隨機相位重組方法進行分布式數據的層次空間重構,在重構的層次空間中提取多層次分布式數據的關聯維特征量,采用高階特征壓縮方法進行降維處理,實現分布式數據的自適應挖掘。仿真結果表明,采用該方法進行數據挖掘的準確性能較好、查準率較高、計算開銷降低、性能優越。
關鍵詞: 多層次分布式數據; 數據挖掘; 決策樹; 檢索; 數據庫
中圖分類號: TN911.1?34; TP391 文獻標識碼: A 文章編號: 1004?373X(2017)09?0070?03
Abstract: Aiming at the high?dimensional feature and inter?class imbalance factor exiting in the multi?level distributed data mining method, a multi?level distributed data mining technology based on random decision tree retrieval model is proposed. The random phase recombination method is used to reconstruct the hierarchical space of the distributed data. The correlation dimension characteristic quantity of the multi?level distributed data is extracted in the reconstructed hierarchical space, and performs the dimension reduction with the high?order feature compression method to realize the adaptive mining of distributed data. The simulation results show that the method has high accuracy for data mining, high precision ratio, low computation cost, and superior performance.
Keywords: multi?level distributed data; data mining; decision tree; retrieval; database
0 引 言
在大數據環境下,大量的多層次分布式數據通過云技術積累并存儲于網絡數據庫中,形成高維數據,在對多層次分布式數據采集和存儲的過程中,由于采集手段的差異性以及測量誤差的存在,導致數據挖掘的精度不高,從而影響了網絡數據庫的訪問精度,需要對多層次分布式數據進行有效挖掘,結合特征提取和數據信息融合方法,進行多層次分布式數據的狀態特征參量提取。研究多層次分布式數據挖掘方法在數據庫訪問和數據結構優化存儲設計方面具有重要意義。
對多層次分布式數據的挖掘是建立在數據信息流模型構建和特征提取的基礎上,目前使用的數據挖掘算法很多,按類別可分為模糊挖掘算法、層次挖掘算法、網格區域分割挖掘方法等[1?2],通過對數據結構的屬性類別分類處理和信息融合,實現數據信息特征檢測和挖掘,取得較好的挖掘精度。文獻[3]提出一種云計算環境下基于樸素貝葉斯分類的多層次分布式數據挖掘方法,進行多層次分布式數據歸類,提取多層次分布式數據的語義關聯性和規則性特征,實現數據優化挖掘,但該算法的計算開銷較大,數據信息檢測和挖掘的實時性不好。
文獻[4]提出一種基于相關子空間的數據挖掘方法,采用屬性維上的局部稀疏程度重新定義相關子空間,采用局部數據集的概率密度給出相關子空間中的計算公式,獲取相關子空間中的數據分布特征,引入LSH分布式策略,實現對分布式數據的挖據,該方法提高了多層次分布式數據庫檢索的查準性,但是該算法隨著多層次分布式數據庫規模的增大,信息挖掘的準確性不好。
針對上述問題,提出一種基于隨機決策樹檢索的多層次分布式數據挖掘方法。首先進行數據信息流構建和數據特征分析,對多層次分布式數據信息流進行特征空間重構;然后在重構的特征空間中提取多層次分布式數據的關聯維特征量,采用高階特征壓縮方法進行降維處理,實現分布式數據的自適應挖掘;最后進行仿真試驗分析。
1 多層次分布式數據信息流重構
1.1 分布式數據的特征空間結構模型
采用隨機相位重組方法進行分布式數據的層次空間重構,構建多層次分布式數據的高維特征空間分布結構模型,假設多層次分布式數據的有限數據集為:
采用Takens嵌入定理進行多層次分布式數據的特征分布空間重構[5]:設是維的多層次分布式數據在高階矢量場的緊流形;是光滑的矢量場;是上的一個光滑函數。采用高階線性微分方程進行數據樣本的添加或者刪減,則當表示是一個嵌入向量。對于多層次分布式數據采樣時間序列它的相空間重構軌跡為:
式中:表示數據分布特征空間的狀態矢量;是重構延時;是嵌入維數;是對多層次分布數據挖掘的采樣時間間隔。多層次分布式數據在聚類中心的收斂控制函數為:
利用奇異半正定性原理,建立多層次分布式數據挖掘的二次規劃模型,在重構的特征空間中提取多層次分布式數據的關聯維特征量。
1.2 數據流的關聯維特征提取
在重構的特征空間中構建一組齊次方程,求得多層次分布式數據挖掘的極大線性無關組,得到多層次分布式數據的信息融合中心的極大線性無關組表達式分別為:
3 仿真試驗分析
為了驗證本文方法在實現多層次分布式數據的特征選擇和優化挖掘中的應用性能,進行仿真試驗分析。試驗采用Matlab 7 仿真軟件設計,在數據庫中進行多層次分布式數據特征信息采樣,采樣樣本的時間間隔為0.25 s,數據的點數為2 000點,特征空間重構的嵌入時延參數,維數干擾強度為0~12 dB,根據上述仿真參量設定,進行多層次分布式數據挖掘,得到的樣本數據如圖1所示。
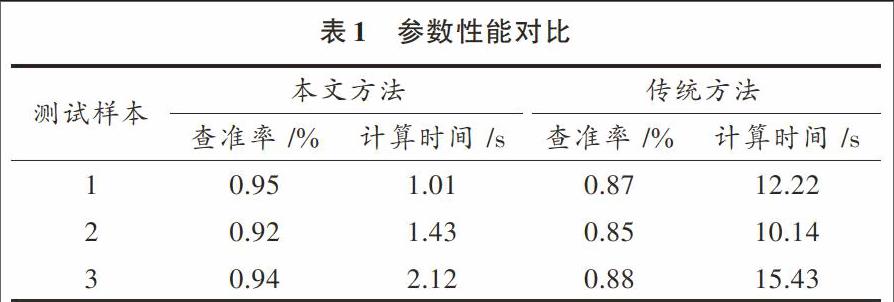
分析圖2的結果得知,采用本文方法進行數據挖掘,可降低多層次分布數據的空間組合維數,提高挖掘精度,與傳統方法進行挖掘的準確性對比,得到的對比結果如圖3所示,查準率和計算時間對比見表1,分析圖3和表1結果得知,采用本文方法進行數據挖掘的準確性較好,查準率較高,且降低了計算開銷。
4 結 語
針對多層次分布式數據存在高維特征和類間不平衡因素的問題,本文提出一種基于隨機決策樹檢索模型的數據挖掘技術。并利用仿真試驗對本文方法與傳統方法的性能進行對比,仿真結果表明,采用本文方法進行數據挖掘的準確性能好,查準率較高,計算開銷降低,性能優越,具有較好的應用價值。
參考文獻
[1] 王慧,張翠羽.基于改進遺傳算法的網絡差異數據挖掘算法[J].計算機仿真,2015,32(5):311?314.
[2] 梁聰剛,王鴻章.微分進化算法的優化研究及其在聚類分析中的應用[J].現代電子技術,2016,39(13):103?107.
[3] 張紅蕊,張永,于靜雯.云計算環境下基于樸素貝葉斯的數據分類[J].計算機應用與軟件,2015,32(3):27?30.
[4] 張繼福,李永紅,秦嘯,等.基于MapReduce與相關子空間的局部離群數據挖掘算法[J].軟件學報,2015,26(5):1079?1095.
[5] 蔣本立,張小平.大數據網絡的均衡調度平臺設計與改進[J].現代電子技術,2016,39(6):62?65.
[6] 李根,樊龍,萬定生,等.基于Map/Reduce的決策樹分類挖掘方法應用研究[J].計算機與數字工程,2016,44(8):1504?1510.
[7] 聶軍.基于K?L特征壓縮的云計算冗余數據降維算法[J].微電子學與計算機,2016(2):125?129.
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
財經(2017年15期)2017-07-03 22:40:49
電力與能源(2017年6期)2017-05-14 06:19:37
財經(2017年2期)2017-03-10 14:35:35
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
信息通信技術(2015年6期)2015-12-26 01:16:46
河南科技(2014年23期)2014-02-27 14:18:43
