MOOC學習結果預測指標探索與學習群體特征分析
2017-05-30 10:48:04牟智佳武法提
現代遠程教育研究 2017年3期
牟智佳 武法提

摘要:高輟學率與低參與度是MOOC面臨的一個主要問題。根據學習結果預測,及時開展有效的教學干預是改善此問題的途徑之一。當前基于MOOC學習行為數據進行結果預測主要以次數分析為主,較少探索其他行為指標;在預測算法上以回歸分析為主,缺少不同預測算法效果的比較分析。以edX平臺上一門MOOC課程的學習行為數據為研究對象進行的探索研究發現:學習結果預測的主要參照行為指標組合為視頻學習次數、文本學習次數、評價參與時長、評價參與次數和論壇主題發起數;學習次數的預測效果要好于學習時長,并與學習時長和學習次數結合后的預測效果接近; BP神經網絡預測準確率要優于決策樹和樸素貝葉斯網絡,且預測準確率與樣本數量呈正相關;而在課程學習模塊的預測比較上,評價模塊和文本模塊的學習行為數據預測率較高,互動模塊預測率最低。研究還發現,MOOC學習群體包含三類,分別是以視頻學習和學習評價為主、以互動交流為輔的學習群體;以視頻學習和文本學習為主、以評價參與為輔的學習群體,以及以文本學習和學習評價為主、以互動交流為輔的學習群體。
關鍵詞:MOOC;學習行為數據;學習結果預測;預測指標;學習群體特征
中圖分類號:G434 文獻標識碼:A 文章編號:1009-5195(2017)03-0058-10 doi10.3969/j.issn.1009-5195.2017.03.008
一、研究緣起
當前國內外越來越多的高校參與MOOC課程建設并發布各自的特色課程,學習者在課程內容上有了更多的選擇權,但高輟學率和低參與度仍是當前MOOC課程所面臨的一個主要問題(Hew et al.,2014)。而基于學習者前期和中期的課程學習行為數據進行學習結果預測,并依據分析結果調整教學策略和教學內容以開展有效的教學干預,可以改善學習參與度和學習結果。與此同時,學習分析研究已經由初期的理論探討逐步走向實踐探索和成果轉化。在學習分析研究中,基于學習行為數據進行學習結果預測是學習分析和教育數據挖掘研究學術群體中關注的一項重要議題(Li?án et al.,2015)。而在數據的選擇上,學習分析研究正從關注大數據轉向有意義數據的探索(Merceron et al.,2016)。如何抓取到學習活動信息流中的關鍵行為數據并解析出學習者的個性學習行為特征是今后研究中要解決的一個問題(U.S. Department of Education,2015)。MOOC廣泛的學習參與群體和多樣化的學習行為數據使其成為學習分析研究的一個重要對象。如何基于MOOC學習行為數據有效預測學生的學習結果,并依據學習群體特征提供差異化的學習服務以改善學習參與度成為亟待解決的問題。本研究基于edX平臺的一門MOOC課程學習行為數據,探索能夠有效預測學習結果的數據類型和行為指標,并分析學生的群體學習特征,為學習結果預測分析和教學干預提供指導和參照。
二、文獻綜述
國內關于MOOC學習行為研究主要集中在學習行為影響因素分析、基于學習行為數據分析學習效果、學習成績預測、學習行為評價等方面。比較有代表性的研究有:賈積有等以Coursera平臺上的6門北京大學MOOC課程學習行為數據為分析對象,探索在線時間、觀看視頻和網頁次數、瀏覽和下載講義次數、論壇發帖數與學習成績之間的關系(賈積有等,2014)。李曼麗等以“學堂在線”平臺的“電路原理”課程數據為基礎,對MOOC學習者的課程學習動機、課程參與度、課程注冊時間與課程完成度等進行分析(李曼麗等,2015)。郝巧龍等用Clementine 構建MOOC 成績預測,并依托智慧樹平臺“數據結構”課程的行為數據通過回歸分析驗證模型的有效性(郝巧龍等,2016)。
國外關于MOOC學習行為的研究包括MOOC學習成敗和保留率的影響因素分析、學習動機和學習行為對MOOC完成度的影響、學習表現預測研究、學習情境在MOOC學習中的重要性分析等。如:Laxmisha Rai等從學習者角色、個人支持和人為干預、高困難度和自我動機、學習環境、職業需求、教師和學校聲望、實時反饋等方面分析了MOOC學習成敗的因素(Rai et al.,2016)。Bart Pursel等基于MOOC學習者的人口學數據、學習行為和課程互動數據,采用邏輯斯回歸分析探索這些數據變量如何表征課程完成度(Pursel et al.,2016)。Paula Barba等以Coursera平臺上的“宏觀經濟學”課程學習者為研究對象,分析以個人興趣、掌握方法目標與應用價值為主的學習動機和以視頻點擊與測評提交數為測量方式的學習參與在學習表現預測上的重要性(Barba et al.,2016)。在學習者參與MOOC學習的數量變化上,研究表明第一周課程教學之后,學習者參與的數量會急劇下降(Hill,2013),因此Suhang Jiang等研究者以學習者第一周的MOOC課程作業表現和社交互動數據為分析對象,并使用邏輯斯回歸作為分類器,預測學習者獲得課程證書的概率(Jiang et al.,2014)。
從國內外已有研究可以看出,研究者已經基于MOOC常見的學習行為數據進行學習成效分析,探索課程學習成敗的內在和外在因素,并對學習者最終學習表現進行預測。然而,在數據分析和預測上還存在以下幾方面的不足:(1)學習行為數據中以次數分析為主,應用時間分析較少,兩者之間未統一在一個學習分析層面上,對于各自的預測效果還尚不清晰;(2)在預測算法上以回歸分析為主,而采用機器學習模式的預測方法較少,且缺少不同預測算法效果的比較分析;(3)對有效預測學習結果的行為指標探索較少,學習行為數據較多,需要找到反映學習結果的關鍵行為指標為學習分析提供參照。針對上述問題,本研究以MOOC課程學習模塊為分類依據,以學習行為數據指標為中心,探索學習時長和學習次數的預測效果、課程學習模塊的預測效果、有效學習結果預測指標的提取及其計算方程、學習者的群體學習行為特征等內容,試圖為基于MOOC的學習行為分析和教學設計提供有益的啟示。
三、研究設計
1.研究問題
當前MOOC平臺能夠記錄學習者的鼠標點擊流數據,而在這些數據中時長和次數是兩項重要的數據類型。基于學習過程行為數據探索能夠反映學習結果的有效數據類型,分析指標和群體行為特征有助于開展針對性的學習干預,改善學習者參與度并降低輟學率。因此,本研究的問題包括以下三方面:(1)在學習行為數據中,學習時長和學習次數統計哪種方式更能較為準確地預測學習結果?哪類課程學習模塊數據預測效果較好?(2)各類學習行為數據與學習結果有怎樣的相關性?哪些行為指標能夠較好地預測學習結果?基于有效學習指標如何得出可計算的學習結果預測計算方程?(3)在課程內容學習上,學習者可以分為哪幾類學習群體?這些群體表現出怎樣的學習行為特征?
2.研究樣本與方法
研究選取edX上的一門MOOC課程“Introduction to Engineering and Engineering Mathematics”為研究對象。該課程是由University of Texas at Arlington大學工程學院Pranesh B. Aswath教授發起,由Alan Bowling、Panos Shiakolas、William E. Dillon、R. Stephen Gibbs等研究者參與講授的一門工程類基礎專業課程。該課程于2015年5月12號在edX平臺上線發布,并于同年8月10號結束授課,課程持續14周。該課程的設計目標是為高中學生和大學新生提供工程領域的梗概,以幫助他們在工程學上決策自己的職業生涯。課程授課語言是英語,免費向世界范圍內學習者開放。課程成績評價方式包括每周練習測驗(占總成績40%)、課后作業(占總成績40%)、綜合期末考試(占總成績20%)。練習測驗主要是選擇題,由系統平臺自動評閱打分,課后作業和綜合期末作業由同伴互評和教師評閱打分確定。在課程數據的使用權上,已獲得University of Texas at Arlington機構審核委員會(Institutional Review Board,IRB)的使用批準和課程負責人授權,準許使用剔除學生個人信息的數據。
在數據選取上,研究基于edX平臺上記錄的鼠標點擊流數據抽取與行為分析指標有關的時長和次數統計數據。由于平臺上涵蓋微視頻、文本學習材料、互動論壇、學習評價等學習模塊和材料,因此學習者的行為活動數據也涉及上述學習活動模塊。而在學習行為數據上除時長和次數等較為常見數據外,還有倍速播放、跳幀觀看、停留軌跡等信息。這些數據是學習者為獲取所需知識和理解內容產生的附屬行為,反映的是學習風格和學習偏好行為特征,其對學習結果是否產生普遍影響尚不確定。此外,這些數據在量化計算上缺少統一標準,因此暫不納入預測分析指標中。綜上所述,提取的學習行為指標包括視頻學習時長(VD)、視頻學習次數(VF)、文本學習時長(TD)、文本學習次數(TF)、互動參與時長(ID)、互動參與次數(IF)、評價參與時長(ED)、評價參與次數(EF)、論壇發帖數(PC)、主題發起數(TC)、回復數(RC)、點贊數(VF)等。在數據預處理上,研究者對學習時長設定一個閾值,即超過該閾值的被認定為離開學習任務,處于非學習狀態。設定該值的原因是考慮到學習者在網絡學習中的認知行為習慣,即在某一具體知識點中通常不會較長時間一直停留不動,而學習時間較長可能是由于學習者離開學習任務進行其他網絡活動以及學習者關掉瀏覽器但未注銷賬號造成。在時間閾值設定和估計上,Grabe和Sigler使用多種啟發式探索進行時間估計,所有超過3分鐘的學習行為時間將被替換成2分鐘,在選擇題的操作行為時間上最高設定為90秒,每一個模塊最后活動時間被估計成60秒(Grabe et al.,2002)。Ryan Baker將超過80秒的活動時間認定為脫離活動行為時間(Baker,2007)。Vitomir Kovanovic等通過對不同時間估計進行對比分析,認為短時間的時間估計和閾值設定對分析結果并沒有產生顯著影響,反而會對長時間學習者的活動行為分析進行干擾,進而影響分析結果;通過實際對比分析發現將單周模塊時間估計閾值設定為1800秒可以在不影響分析結果的前提下盡可能還原學習者的行為狀態,發現學習者之間的行為差異(Kovanovi? et al.,2015)。因此,本研究將每周模塊學習行為時間閾值設定為1800秒,超過該時間的學習活動時間將被替換。
在有效數據的提取上,研究采用兩種方式采集數據樣本:一是選取實際參與學習模塊的學習者行為數據,剔除在各項學習活動中數據均為0的樣本,最終獲得8804條大樣本數據;二是選取各個學習模塊中均有學習者參與活動的數據樣本,獲得1631條小樣本數據。通過大小樣本數據的分析,比較不同預測算法的準確率。在研究方法上,分別采用預測分類算法、屬性選擇、多元回歸分析和聚類方法對數據進行分析。其中預測分類算法用于分析學習時長和學習次數在學習結果上的預測準確率;屬性選擇用于選取能夠預測學習結果的有效學習行為分析指標;多元回歸分析用于計算有效學習行為指標與學習結果之間的回歸系數;聚類分析用于探索學習者的群體行為特征。在研究工具上,選擇機器學習分析工具Weka,采用有監督學習方式對數據集進行預測分析;SPSS對數據樣本進行顯著性差異分析和多元回歸分析。
3.研究過程
整個研究過程包括以下6步:(1)采用R工具對edX平臺上記錄的原始數據進行格式化,并提取不同學習模塊中的學習時長、學習次數和論壇互動數。(2)對每周課程內容的學習時長進行處理,超過設定閾值的樣本數據將被替換成1800秒,最后統計學習者的學習時長總和。(3)選擇決策樹、樸素貝葉斯網絡和BP神經網絡等三種具有代表性的預測分類算法,比較學習時長和學習次數在學習結果預測上的準確率,并分析不同預測分類算法的效果;在此基礎上分析不同學習模塊在學習結果預測上的效果。(4)采用屬性選擇,分析不同學習行為分析指標在學習結果預測上的權重順序以及準確預測學習結果的有效指標組合。(5)采用多元回歸分析有效學習結果預測指標的回歸系數,并生成學習結果預測計算方程。(6)采用聚類方法分析學習行為的群體特征,探索不同群組學生的學習表現和行為特征。
四、研究結果分析
1.學習時長與學習次數的預測比較
如前所述,學習時長和學習次數是MOOC學習行為活動中的兩種主要數據類型,本部分主要分析哪種數據類型更能有效預測學習結果以及不同預測分類算法的預測效果。在學習結果的評判上,由于預測分析算法是以標稱型屬性作為預測的類別變量,因此這里以學習者是否獲得課程證書作為最終成績判定。在樣本均值的差異比較上,因時長數值遠高于次數值,故這里不作兩種類型指標的顯著性差異分析。為了了解不同數據類型獨立和綜合預測效果,在分析學習時長和次數的預測準確率時,對所有行為指標進行分析以作為參照,預測評估策略選擇十折交叉驗證,分析結果見表1。預測準確率的誤差通過均方根誤差值(Root Mean Squared Error,RMSE)來評判。該值通過樣本離散程度來反映預測的精密度,其值越小表示測量精度越高。在預測準確率上,大樣本預測值要高于小樣本預測值,說明預測準確率與樣本數量呈正相關,各指標的RMSE值介于0.0740~0.1608,測量精度較高。在數據類型的預測準確度上,學習次數的預測效果要好于學習時長,特別是在小樣本分析條件下,平均預測準確率較高,且RMSE值較低。學習時長和學習次數的整體預測效果與學習次數較為接近。在預測分析算法的比較上,盡管小樣本分析條件下樸素貝葉斯網絡在學習時長的預測準確率要高于決策樹,但整體而言BP神經網絡預測準確率最高,決策樹的預測效果要好于樸素貝葉斯網絡。
2.課程學習模塊的預測比較分析
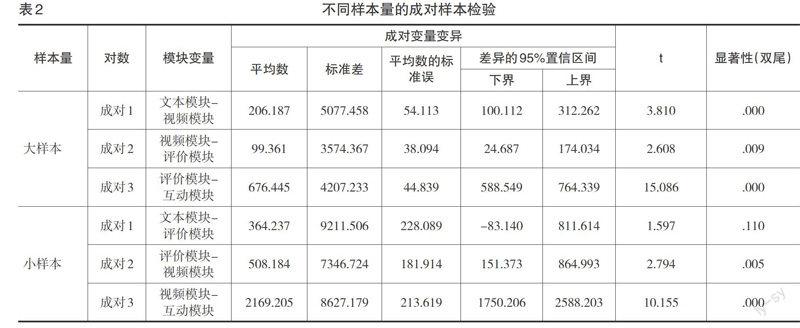
MOOC教學設計者為學習者提供了不同類型的學習材料和支持服務。為了了解不同學習模塊在學習結果預測上的效果,研究按學習者參與的活動模塊劃分學習行為數據。由于不同模塊中涵蓋的指標類型數據一樣,因此在進行預測分析之前需要檢驗各模塊樣本數據之間是否存在顯著性差異。通過對大樣本的均值統計分析可知,各模塊均值由高到低排序為文本、視頻、評價和互動,而小樣本均值排序為文本、評價、視頻和互動。在顯著性差異比較上,采用相依樣本t檢驗對不同樣本量下的模塊變量進行分析,結果見表2。在大樣本分析情境下,各模塊變量差異的95%置信區間未包含0這個數值,應拒絕虛無假設H1:μ1=μ2,接受對立假設H0:μ1≠μ2,且顯著性檢驗概率值p<0.05,表示模塊之間有顯著性差異存在。在小樣本分析情境下,文本模塊和評價模塊的置信區間涵蓋0,顯著性檢驗概率值p=0.110>0.05,表示兩者之間無顯著性差異存在。整體而言,除小樣本中的文本和評價模塊無顯著性差異之外,各模塊變量均有顯著性差異,適合對其進行學習結果預測分析。
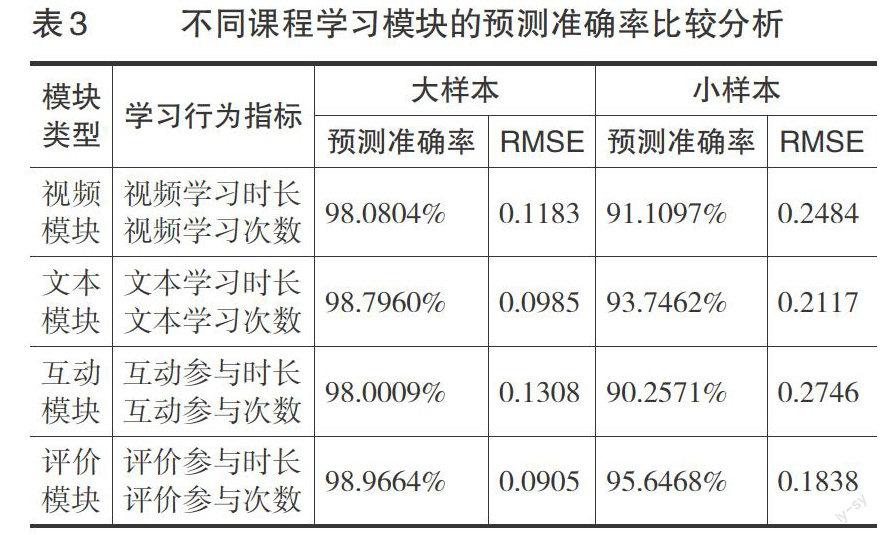
在預測算法選擇上,由于BP神經網絡算法的學習速度較慢且訓練失敗的可能性較大,基于前面比較分析結果采用決策樹作為預測分析算法,分析結果見表3。在整體預測準確率上,大樣本要高于小樣本數據,這一結果與前面分析一致。在大樣本分析條件下,盡管各學習模塊之間的預測準確率相近,區分度較低,但評價模塊和文本模塊的學習行為數據預測率較高,互動模塊預測率最低。在小樣本分析條件下,各模塊的預測準確率區分度較大,從數值大小對比上,預測準確率順序與大樣本一致。在RMSE值上,評價和文本模塊均低于其他模塊,說明測量精度較高。可以看出,盡管視頻是MOOC網絡學習平臺中的重要學習材料,但視頻學習并不是最能有效預測學習結果的模塊,評價模塊和文本模塊能夠較好地預測學習結果。從知識建構視角看,視頻學習側重知識傳遞,文本學習和學習評價側重學習者的知識內化,而學習結果測量的是學習者課程知識內化的程度(Pr?itz,2010)。
3.學習結果預測指標的權重與有效組合分析
(1)學習結果預測指標的權重分析
盡管學習行為活動數據有多種類型,但每種行為數據在學習結果上的預測重要程度可能存在差異。我們采用屬性排名方法對所有學習行為數據進行權重分析,以驗證學習行為指標在預測貢獻上的差異性。學習行為數據包括學習活動時長、次數以及論壇互動數在內的12項數據,評估器和搜索方法分別是InfoGainAttributeEval和Ranker,分析結果見表4。在指標權重排序上,大樣本和小樣本的排序結果基本一致,僅在視頻學習次數與文本學習次數、主題發起數和回復數兩方面有所交換,評價參與次數、文本學習次數和評價參與時長是兩種樣本數據下認定的共同重要指標。從兩種樣本數據的權重比例上看,參與評價、文本學習和視頻學習所占的權重比例較高,說明學習者側重知識內容學習和課程評價,參與互動交流較少。
(2)學習結果預測指標的有效組合分析
前面分析的學習行為指標權重結果說明了各指標在學習結果預測上的貢獻度存在差異。在屬性組合分析上,有過濾器和包裝方法兩種方式。前者用低計算開銷的啟發式方法衡量屬性子集的質量;后者通過構建和評估實際的分類模型來衡量屬性子集的質量,計算開銷大但分析性能較好。這里將應用這兩種分析方式對指標進行評估。為了進一步驗證篩選后的指標是否提高預測準確率,在進行屬性組合分析之后采用決策樹預測分類算法對不同屬性子集進行預測分析。在樣本數和屬性子集比較上,同樣采用大小樣本和全集進行對比參照分析,各項結果見表5。
在大樣本分析條件下,采用CfsSubsetEval評估器和GreedyStepwise搜索方法,得到評價參與次數(EF)和發帖數(PC)兩個有效行為分析指標組合。采用WrapperSubsetEval評估器和Bestfirst搜索方法得到視頻學習次數(VF)、文本學習次數(TF)、評價參與時長(ED)、評價參與次數(EF)、主題發起數(TC)等有效指標組合。在小樣本分析條件下,分別采用上述兩種方式得到評價參與次數(EF)和主題發起數(TC)組合以及文本學習次數(TF)、評價參與時長(ED)、評價參與次數(EF)與回復數(RC)組合。在評估器類型的比較分析結果上,盡管兩種評估器所得到的子集組合存在個別差異,但分類組合結果數量和內容比較接近。CfsSubsetEval評估器側重選擇與目標屬性相關性較強的屬性子集,同時篩選的子集之間無強相關性,而WrapperSubsetEval評估器綜合與目標屬性的相關性和篩選子集之間的關聯性進行分析,故篩選指標數量多于前者。在評估器的預測準確率上,包裝方法(WrapperSubsetEval評估器)在大小樣本條件下的預測效果均優于過濾方法(CfsSubsetEval評估器),且篩選后的有效行為分析指標預測準確率要高于所有行為分析指標組合。因此,這里將WrapperSubsetEval評估器在大樣本分析條件下所得出的屬性子集作為預測學習結果的主要參照行為指標組合,即包括視頻學習次數、文本學習次數、評價參與時長、評價參與次數和論壇主題發起數。
4.有效學習結果預測指標的回歸方程模型分析
前面采用不同的樣本類型和分類器選取有效的學習結果預測指標,盡管篩選的屬性子集有所區別,但從內容上能夠得出關鍵行為指標。為了進一步了解各有效組合指標與學習結果之間的回歸系數,以便于將學習結果的預測理論分析轉變成具有可操作性和可計算性的應用實踐,這里將基于有效指標組合與學習結果數據進行多元回歸分析。為使分析結果具有可遷移性和應用性,這里選取前面分析得出的有效組合指標作為分析依據,并使用學習成績作為學習結果評判依據。在回歸分析方法上,采用強迫進入變量法的解釋型回歸分析進行探索,分析結果見表6。由多元回歸系數可知,5個預測變量共同解釋學習結果變量65.4%的變異量。在顯著性分析上,由于預測變量是基于前面屬性選擇得出的有效行為指標,因此各變量均達到顯著性。在共線性統計量上,允差值愈接近于0,說明變量間有線性重合問題,而方差膨脹系數大于10時,則說明變量間有線性重合問題(吳明隆,2010)。上述5個變量的允差值介于0.1~0.5,方差膨脹系數均在5以下,未大于評價指標值10,說明進入回歸方程式的自變量間未存在明顯的多元共線性問題。在標準化回歸系數上,各值均為正數,說明其對學習結果的影響均為正向。從數值大小上看,β系數值越大,表示其對因變量有較高解釋力,其排列順序與前面指標權重分析結果大致相同。基于β系數值我們可以得出標準化回歸方程模型:學習結果=0.241×評價參與次數+0.146×評價參與時長+0.119×文本學習次數+0.043×視頻學習次數+0.036×主題發起數。依據該方程模型可以為實現MOOC平臺自動化預測學生的學習結果提供設計依據。
5.基于學習行為指標的學習群體特征分析
盡管參與MOOC學習的學生群體較多,但基于學習內容習慣和偏好可以將其進行分類,為不同學習群體提供差異化的互動學習材料和實時反饋。這有助于提高學習者參與度(Freitas et al.,2015)。本部分將采用聚類方法對學習行為數據進行族群探索和分析。在樣本數上,采用大樣本分析以產生顯著差異的群體類別。在行為指標選擇上,為了全面了解學習行為偏好,將所有行為指標作為分析對象,學習成績采用數值型屬性進行分析。在聚類算法上,采用常用的K均值算法進行分析,該算法接受輸入值K,之后將數據劃分成指定個數的簇。形成簇的條件是同一簇中對象相似度較高,不同簇中對象相似度較低。為了找到合適的分類群體數量,這里通過設定不同簇個數探索分類數及其百分比,分析結果見表7。可以看出,當簇個數為4時,迭代次數第一次達到最大值,同時平方誤差值較低且比較穩定。當簇個數大于4時,得到的分類數及其百分比之間存在相近的類別數,在解釋度上比較低。因此,選擇簇個數為4的聚類分析結果作為學習群體劃分的標準。
對學習行為指標進行聚類分析,結果見表8,各指標中的數值為平均值,其高低反映學習者的投入度。由于互動論壇中的發帖數、主題發起數、回復數、點贊數等數值遠低于時長和次數統計,因此在判斷互動論壇的投入度時采用相對評價方式,將時長、次數統計與互動論壇數統計分開比較,同時查看互動論壇數的相對值以了解學習群體參與度。由分析結果可知,聚類2和聚類4在學習模塊表現上較為相近,可將其合并為一種類型;聚類1和聚類3的互動參與時長和回復數相對其他兩類群體較高,因此可將其作為一個參照行為特征。基于上述分析,我們可以將學習群體分為以下三種類型:(1)以視頻學習和學習評價為主、以互動交流為輔的學習群體;(2)以視頻學習和文本學習為主、以評價參與為輔的學習群體;(3)以文本學習和學習評價為主、以互動交流為輔的學習群體。可以看出,不同的學習群體側重不同的學習模塊,視頻學習和學習評價是學習者主要參與的模塊,盡管有兩類群體參與互動交流,但僅將其作為輔助學習模塊,這些學習偏好在一定程度上反映了學習者不同的學習風格。從學習群體的成績表現來看,優秀學習群體能夠積極參與視頻學習、文本學習、互動交流和學習評價,且積極參與互動交流的學習群體成績要高于參與互動交流較低的學習群體,這在一定程度上說明互動交流能夠支持學習者的知識建構與內化(Yap et al.,2010)。
五、研究結論
本研究以edX上的一門MOOC課程學習行為數據為分析對象,對不同數據類型、學習活動模塊、有效學習行為指標、學習群體特征等進行了探索分析,得出以下6方面的主要結論:(1)在學習結果預測的數據類型上,學習次數的預測效果要好于學習時長,并與學習時長和學習次數結合后的預測效果接近,因此,可通過觀察學習次數或綜合學習時長與次數來評測學習結果。(2)在預測算法的比較上,BP神經網絡預測準確率要優于決策樹和樸素貝葉斯網絡,但由于各算法在處理能力、噪聲容錯能力、計算量等方面存在差異,因此需依據不同的應用情境和樣本量選擇合適的算法分析。在數據樣本量的比較上,預測準確率與樣本數量呈正相關。(3)在課程學習模塊的預測比較上,評價模塊和文本模塊的學習行為數據預測率較高,互動模塊預測率最低。(4)在學習結果有效指標的組合分析上,綜合不同評估器和搜索方法的分析結果,視頻學習次數、文本學習次數、評價參與時長、評價參與次數、論壇主題發起數是預測學習結果的主要參照行為指標組合。(5)基于WrapperSubsetEval分類器得出的有效組合指標和多元回歸分析,得出標準化的學習結果預測回歸方程模型為:學習結果=0.241×評價參與次數+0.146×評價參與時長+0.119×文本學習次數+0.043×視頻學習次數+0.036×主題發起數。(6)基于K均值算法得出三種類型的學習活動群體:以視頻學習和學習評價為主,以互動交流為輔的學習群體;以視頻學習和文本學習為主、以評價參與為輔學習群體;以文本學習和學習評價為主、以互動交流為輔的學習群體。
六、研究局限與展望
本研究雖然基于MOOC學習行為基礎數據進行了學習結果預測的比較分析,探索了有效學習數據類型、學習行為指標組合、學習結果預測計算方程和群體學習特征,但還存在以下兩方面的不足:
(1)當前只應用一門edX上的MOOC課程數據進行分析,研究結論的信度有待進一步驗證。今后將選取不同MOOC學習平臺以及多學科課程數據作為分析對象進行橫向比較和驗證分析,探索不同課程學習數據在結果分析上是否有顯著差異,以提高研究結論的可靠性。
(2)本研究選取的學習行為數據指標還比較有限,而影響學習結果預測的因素比較復雜。今后將探索其他學習行為數據對學習結果預測的影響,如學生個人的人口學信息數據、學習情感數據等。通過綜合多種不同類型的學習活動行為數據進行學習結果預測分析,以找到反映學習結果的關鍵行為數據和學習行為特質。
參考文獻:
[1]郝巧龍,魏振鋼,林喜軍(2016).MOOC學習行為分析及成績預測方法研究[J].電子技術與軟件工程,(7):167-168.
[2]賈積有,繆靜敏,汪瓊(2014).MOOC學習行為及效果的大數據分析——以北大6門MOOC為例[J].工業和信息化教育,(9):23-29.
[3]李曼麗,徐舜平,孫夢嫽(2015).MOOC學習者課程學習行為分析——以“電路原理”課程為例[J].開放教育研究, (2):63-69.
[4]吳明隆(2010).問卷統計分析實務——SPSS操作與應用[M].重慶:重慶大學出版社:390-391.
[5]Baker, R. S. J.(2007). Modeling and Understanding Students' Off-Task Behavior in Intelligent Tutoring Systems[A]. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems[C]. New York: Association for Computing Machinery: 1059-1068.
[6]Barba, P. G, Kennedy, G. E., & Ainley, M. D.(2016). The Role of Students' Motivation and Participation in Predicting Performance in a MOOC Motivation and Participation in MOOCs[J]. Journal of Computer Assisted Learning, 32(3):218-231.
[7]Freitas, S. I., Morgan, J., & Gibson, D.(2015). Will MOOCs Transform Learning and Teaching in Higher Education? Engagement and Course Retention in Online Learning Provision[J]. British Journal of Educational Technology, 46(3): 455-471.
[8]Grabe, M., & Sigler, E.(2002). Studying Online: Evaluation of an Online Study Environment[J]. Computers & Education, 38(4): 375-383.
[9]Hew, K. F., & Cheung, W. S.(2014). Students' and Instructors' Use of Massive Open Online Courses (MOOCs): Motivations and Challenges[J]. Educational Research Review, 12(6): 45-58.
[10]Hill, P.(2013). Emerging Student Patterns in MOOCs: A Graphical View[DB/OL]. [2013-03-10]. http://mfeldstein.com/erging-student-patterns-in-moocs-a-revised-graphical-view/.
[11]Jiang, S., Warschauer, M., & Williams, A. et al.(2014). Predicting MOOC Performance with Week 1 Behavior [A]. Proceedings of the 7th International Conference on Educational Data Mining[C]. Worcester: Worcester Polytechnic Institute:273-275.
[12]Kovanovi?, V., Ga?evi?, D., & Dawson, S. et al.(2015). Does Time-on-Task Estimation Matter? Implications on Validity of Learning Analytics Findings[J]. Journal of Learning Analytics, 2(3): 81-110.
[13]Li?án, L. C., & Pérez, ?. A. J.(2015). Educational Data Mining and Learning Analytics: Differences, Similarities, and Time Evolution[J]. International Journal of Educational Technology in Higher Education, 12(3): 98-112.
[14]Merceron, A., Blikstein, P., & Siemens, G.(2016). Learning Analytics: From Big Data to Meaningful Data[J]. Journal of Learning Analytics, 2(3): 4-8.
[15]Pr?itz, T. S.(2010). Learning Outcomes: What Are They? Who Defines Them? When and Where Are They Defined?[J]. Educational Assessment, Evaluation and Accountability, 22(2): 119-137.
[16]Pursel, B. K., Zhang, L., & Jablokow, K. W. et al.(2016). Understanding MOOC Students: Motivations and Behaviours Indicative of MOOC Completion[J]. Journal of Computer Assisted Learning, 32(3): 202-217.
[17]Rai, L., & Chunrao, D.(2016). Influencing Factors of Success and Failure in MOOC and General Analysis of Learner Behavior[J]. International Journal of Information and Education Technology, 6(4): 262-268.
[18]U.S. Department of Education(2015). Ed Tech Developer's Guide[R].Washington, D.C.:64-65.
[19]Yap, K. C., & Chia, K. P.(2010). Knowledge Construction and Misconstruction: A Case Study Approach in Asynchronous Discussion Using Knowledge Construction Message Map (KCMM) and Knowledge Construction Message Graph (KCMG)[J]. Computers & Education, 55(4): 1589-1613.
收稿日期 2017-01-03 責任編輯 汪燕
