面向特征選擇問題的協同演化方法
2017-06-01 12:21:31滕旭陽董紅斌孫靜
智能系統學報 2017年1期
滕旭陽,董紅斌,孫靜
(哈爾濱工程大學 計算機科學與技術學院,黑龍江 哈爾濱 150001)
面向特征選擇問題的協同演化方法
滕旭陽,董紅斌,孫靜
(哈爾濱工程大學 計算機科學與技術學院,黑龍江 哈爾濱 150001)
特征選擇技術是機器學習和數據挖掘任務的關鍵預處理技術。傳統貪婪式特征選擇方法僅考慮本輪最佳特征,從而導致獲取的特征子集僅為局部最優,無法獲得最優或者近似最優的特征集合。進化搜索方式則有效地對特征空間進行搜索,然而不同的進化算法在搜索過程中存在自身的局限。本文吸取遺傳算法(GA)和粒子群優化算法(PSO)的進化優勢,以信息熵度量為評價,通過協同演化的方式獲取最終特征子集。并提出適用于特征選擇問題特有的比特率交叉算子和信息交換策略。實驗結果顯示,遺傳算法和粒子群協同進化(GA-PSO)在進化搜索特征子集的能力和具體分類學習任務上都優于單獨的演化搜索方式。進化搜索提供的組合判斷能力優于貪婪式特征選擇方法。
特征選擇;遺傳算法;粒子群優化;協同演化:比特率交叉
特征選擇在數據挖掘和機器學習中不僅可以減少數據的維度,降低所需處理的數據量,而且還可以提升某些學習算法的表現[1],比如:分類學習、聚類、回歸問題和時間序列預測等。然而維數據特征選擇面臨著特別龐大的搜索空間等,當存在n維特征時解的搜索空間為2n,因此窮舉搜索是不可行的[2]。特征選擇方法大致可分為3類:過濾式(filter)、包裹式(wrapper)和嵌入式(embedding)[3]。過濾式方法與具體學習方法無關,主要依據數據的內在屬性對特征進行過濾,再用選擇出的特征訓練模型。包裹式方法將最終要使用的學習器的學習性能作為評價子集評價標準。嵌入式方法將特征選擇過程與學習器訓練過程融為一體,兩者在同一過程中優化。wrapper方法對于具體學習器效果好,但其計算代價高,泛化能力差。filter方法雖然在具體學習方法中精度低于wrapper方法,但其泛化能力強,計算效率高,在大規模數據集上更加適用。因此,本文選用基于信息熵度量的filter評價方式。
為了保證搜索的高效,許多學者選擇了貪婪式搜索方法來選擇子集,代表性方法有基于信息增益的方法(IG)[4]和基于信息比率的方法(GR)[5]。然而貪婪方法無可避免地導致其結果為局部最優,因為其在選擇過程中僅考慮當前輪的單個最佳或最差特征[6]。為了解決上述問題,全局搜索的方式則成為特征選擇問題中一種有效的尋優方式。演化計算作為一種具有良好全局搜索能力的代表技術近年來被越來越多地使用在特征選擇技術中[7]。隨著各個領域內數據維度不斷地增加,自2007后遺傳算法(genetic algorithm,GA)與粒子群優化(particle swarm optimization,PSO)成為特征選擇進化搜索策略中兩個主流的全局搜索方法,特別是PSO方法因其搜索速度得到了廣泛的使用。Peng等[8]在2005年提出了最大相關最小冗余的特征選擇方法(mRmR),該方法使用了貪婪式搜索方式。在2011年和2012年學者們驗證了使用mRmR進行度量并采取群智能進化搜索的方式可以獲得更優的特征子集[9,10]。
雖然在特征選擇問題中演化算法的搜索能力優于貪婪式搜索,但不同的演化算法自身也存在局限性。因此更多的學者開始研究協同演化的方法,其中包括策略的協同[11]和種群的協同[12]。本文選用GA與PSO兩種進化種群的協同。PSO 的優勢在于對解的記憶能力強及高效的收斂速度,但該方法極容易陷入到局部最優解,表現出極強的趨同性和較低的種群多樣性。GA方法中染色體之間共享信息,種群較為均勻地移動并保持多樣性,但其收斂速度相對較慢。因此,本文提出了一種面向特征選擇問題的協同演化方法(GA-PSO),演化過程中既保證了全局搜索能力以防止陷入局部最優,又提升了演化速度。
1 基礎知識
1.1 特征選擇
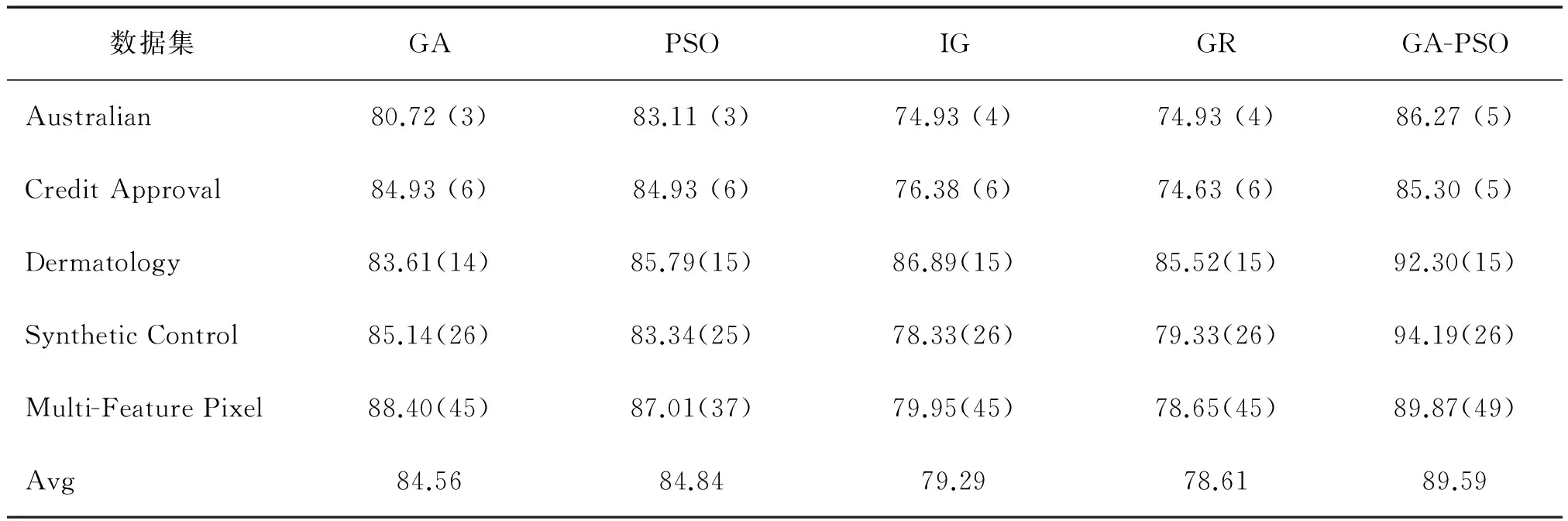
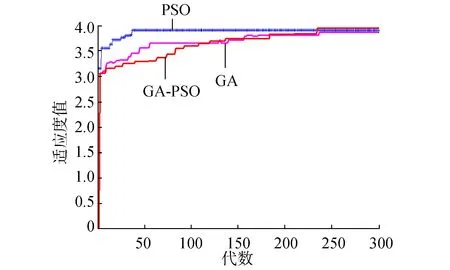
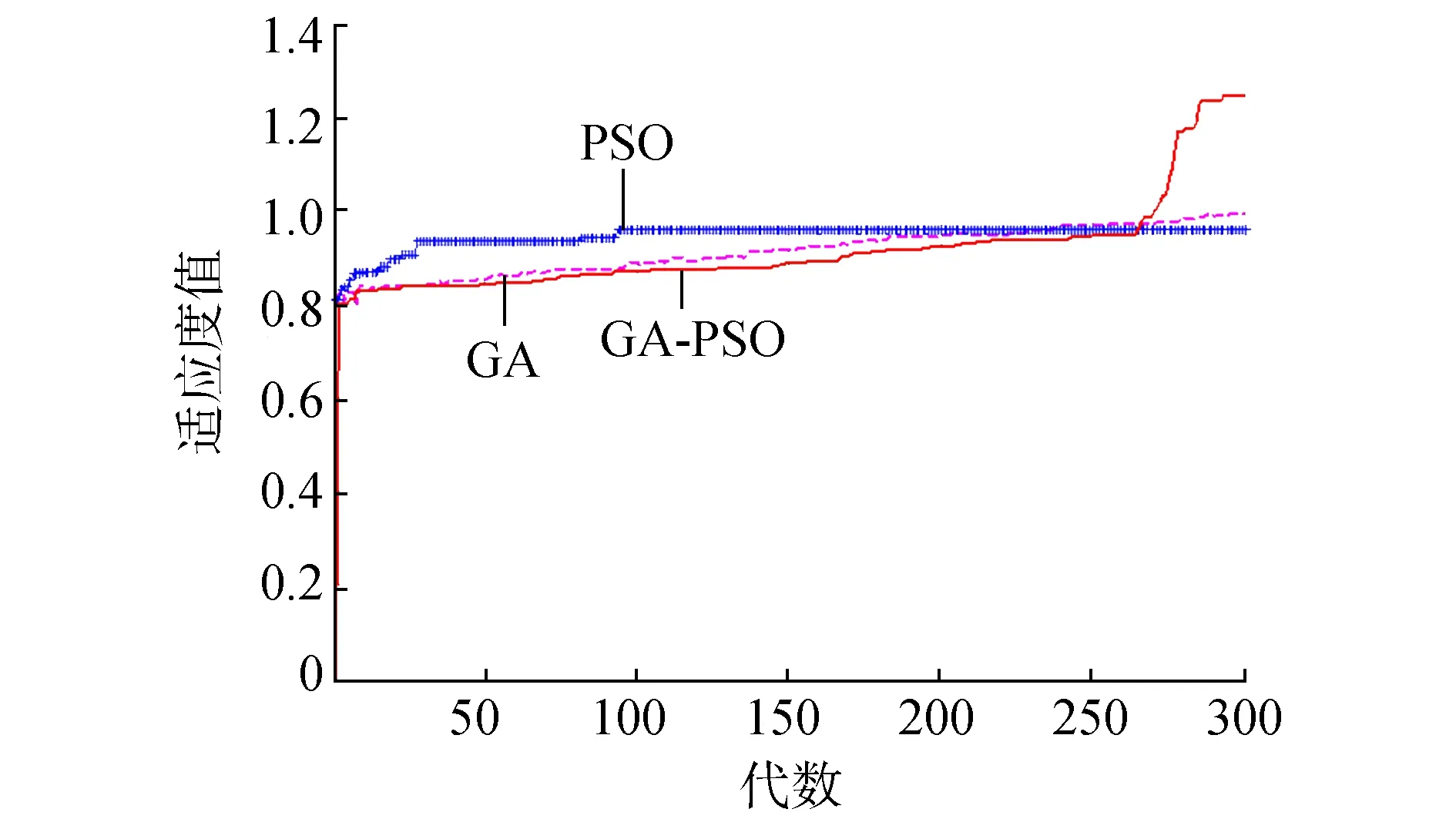
數據集D中含有k個樣本D={x1,x2,…,xk},并且D中的每個樣本都有特征集合F,F包含n維特征,xi∈Rn。對于分類問題,可將D中樣本劃分為目標向量C中的m個不同的類C={C1,C2,…,Cm}。特征選擇的目的,是在原始特征集合N中尋找到一個最佳特征子集P,其中含有p維特征(p 特征選擇處理包括4個組件:特征子集生成、子集評估、終止條件和結果驗證。如圖1所示,在階段1中根據一個確定的搜索策略特征子集生成組件會預先產生候選特征子集。每一個候選特征子集都會被一個確定的評估方式所度量,并與之前最佳的候選特征子集做比較,如果新的特征子集表現得更加優越,那么替換原有的最佳特征子集。當滿足設定的終止條件時,生成和評估這兩個過程將不再循環。在階段2中,最終所選的特征子集需要被一些給定的學習算法進行結果驗證,其中ACC為學習正確率[3]。 圖1 特征選擇處理的統一視角Fig.1 A unified view of feature selection process 1.2 遺傳算法基本原理 遺傳算法作為一種自適應全局優化搜索算法,其選擇、交叉與變異的3個算子成為種群尋優和保持解多樣性的關鍵。其基本執行過程如下。 1) 初始化:確定種群規模N、交叉概率Pcross、變異概率Pmutation和終止進化準則。 2) 個體評價:計算每個個體的適應度。 3) 種群進化: ①選擇算子:個體被選中的概率與其適應度函數值成正比。 ②交叉算子:根據交叉概率Pcross對2條染色體交換部分基因,構造下一代新的染色體。 ③變異算子:根據概率Pmutation對群體中的不同個體指定的基因位進行改造。 ④終止檢驗:如已滿足終止準則,則輸出最優解;否則轉到2)。 1.3 二元粒子群優化基本原理 粒子群優化算法,源于對鳥群捕食的行為研究,是由Kennedy和Eberhart等[13]開發的一種新的進化算法。粒子在搜索空間內尋優,并定位當前路徑中的最佳位置。每一個粒子都需要考慮自身當前的位置和速度,記錄它們自己的最優解(最佳位置)pbset,并根據粒子群體內全局最優解gbest調整當前自身位置,粒子的具體更新如下: 基于上述研究,學者Kennedy調整了連續PSO方法中速度和位置的更新方式,提出了適用于解決離散問題的二元粒子群算法(binary particle swarm optimization,BPSO)[14]。該思想中的粒子僅可以在二元空間中進行搜索,粒子的位置向量僅可以用0或1表示。BPSO方法中影響其尋優能力的關鍵之一就是轉換函數,利用該函數將連續的速度值轉化為離散的位置。在最初的研究中使用式(3)中的sigmoid函數作為轉換函數將實值的速度映射為[0,1]之間的值。 2.1 編碼方式 本文使用了二進制比特串的編碼方式,該編碼方式通用于遺傳算法和二元粒子群方法,如圖2所示。將每個二進制串作為一個個體(粒子),個體(粒子)中的每一維(每一比特)都代表一個候選特征,當該位為1時表示該特征被選中,并添加到候選的特征子集中;當該位為0時表示該特征未被選中。依據此編碼方式將特征選擇問題轉換為尋找最佳個體(粒子)的問題。 圖2 二元粒子群的編碼方式Fig.2 Coding scheme of BPSO 2.2 適應度函數 本文使用互信息熵理論對特征子集進行整體評估,兩個變量的互信息值越大,則意味著兩個變量相關程度越緊密;當互信息為零時,則意味著兩個變量完全不相關。特征集合F={f1,f2,…,fn}中某一特征fi與類別的互信息度量如下: 式中:H為變量的熵值,用以度量隨機變量信息的不確定性。以類別向量為例,H(C)通常用作描述離散隨機變量C={c1,c2,…,cn}熵值,ci是變量C的可能取值,p(ci)為概率密度函數。 當已知特征變量和類別變量fi和C的聯合概率密度時(對于離散數據意味著兩個變量對應的屬性值聯合出現的頻度),兩者的聯合熵為 基于特征與類別向量的信息熵度量構建適應度函數,適應度函數的度量體現了進化過程對優良個體的保留,對低劣個體的淘汰。本文在設計適應度函數時不僅考慮了特征與類別的相關性,而且將特征子集規模也作為影響個體(粒子)適應度的一部分,適應度函數的設計試圖找出子集規模小,并且特征與類別高度相關的特征集合。具體適應度函數設計如下: 式中:MI部分為特征與類別關聯性度量;S部分為特征子集規模控制。假設當前候選特征子集為在全部n維特征中選出的p維特征: 本文設計式(8)和式(9)兩個適應度函數,在尋優過程中試圖尋找最大值。其原理在于,小規模數據集特征維度較少,在進化過程中對特征空間搜索較為全面。采用式(8)重點考察特征與類別的相關性。而對于大規模數據集,特征維度較大,進化搜索特征空間的過程中很難控制特征子集規模,并且容易在候選特征較多時形成局部最優,所以在式(9)中增大了對特征子集規模的懲罰系數。假設式(8)和式(9)獲得相同的適應度函數值,式(9)需要盡量減小k值,使得選擇特征盡量少以取得關聯性度量和子集規模的平衡。 2.3 比特率交叉算子 在遺傳算法中,交叉算子通過模擬自然界生物的雜交過程對個體進行交叉操作,不斷產生新個體、增加種群的多樣性、擴大尋優范圍,從而使得遺傳算法具有較強的搜索能力。直觀地講,交叉算子影響了遺傳算法對求解空間影響的搜索能力,并對能否找到全局最優解發揮了至關重要的作用[15]。 傳統的GA算法交叉操作采用的是單點交叉,但是在該交叉操作中很可能出現“近親繁殖”的現象,即進行交叉操作的一對個體基因型相似,減緩了遺傳算法的搜索速度,或者會出現局部收斂或早熟收斂,從而影響種群的進化方向。因此本文針對特征選擇問題提出了比特概率交叉算子,在基因交叉的過程中,首先判斷兩個個體的基因相似比特率,并將比特率與交叉概率作比較,若小于該概率則進行個體基因交叉操作。具體過程如算法1所示。 算法1 比特概率交叉算子 輸入 兩個個體的二進制比特基因信息位f(i,:)和f(j,:),染色體長度n,交叉概率Pcross。 輸出 交叉后兩個個體的基因型f(i,:)和f(j,:)。 1)m=0。 2)Fork=1:n。 3)若兩個體的第k位比特位相同則m=m+1。 4)End For。 5)計算個體間基因型相似比s=m/n。 6)Ifs 7)隨機選定基因型個體的某一位Poscross。 8)Forh=Poscross:n。 9)交換個體Poscross位到第n位的基因。 10)End For。 11)End If。 通過比特率交叉算子可以避免基因型相近的個體進行交叉操作,即可以避免產生“隱性致病基因”,防止相近個體的近親繁殖,并增強種群個體的多樣性。 2.4 GA-PSO協同演化方法的實現 本文提出的GA-PSO算法的主要思想是比特位信息交互。傳統的PSO特征選擇有一定的缺陷,比較容易陷入全局最優解并且過早收斂,進化過程中會將搜索引向本次迭代的全局和個體最佳位置,因此進化的多樣性差。協同的思想對于PSO特征選擇方法的幫助在于,通過本文提出的最佳個體比特信息位交換策略,每次進化產生最佳個體的比特信息位不僅僅由PSO決定,事實上它和GA中的最佳個體共享那些能夠引起適應度值增加的優秀比特信息位。將這些優秀的比特基因隨機地插入到粒子群中最佳個體對應的信息位上。這種方法不僅有可能使最佳個體變得更優秀,還為PSO算法增加了多樣性,避免過早地陷入局部最優解。對于GA特征選擇方法來說,尋優速度較慢,尤其在高維特征下往往不能獲得令人滿意的結果。從信息共享機制來說,遺傳算法的信息共享方式主要是通過兩個個體之間的交叉操作,而粒子群算法的信息共享方式是通過種群中的最優個體傳遞信息給其余個體。這兩種信息共享機制就相應地決定了兩種算法的表現,粒子群算法每代都選出當前最優個體,并進行全局范圍的信息共享,使得整個粒子群能向著最優的方向快速趨近;而遺傳算法的交叉操作具有一定的隨機性,且由于是一對一進行交叉,每一次迭代中作用的范圍相對較小,使得種群中的優秀基因交流較慢,整個種群的進化比較漫長,所以PSO特征選擇尋優速度較快,效率更高。通過信息交互,在迭代過程中種群可以獲得更為優秀的個體基因型,這有助于加速GA種群的進化過程,提高收斂速度。同時,通過上文的比特率交叉算子可以避免相近的基因型交叉產生不“健康”的后代個體。具體的GA-PSO協同演化算法如算法2和算法3所示。 算法2 協同演化算法 輸入 粒子群和種群初始化參數。 輸出 最佳個體。 1)初始化粒子群和種群。 2)協同演化。 ①計算各個粒子的適應度值。 ②選擇粒子群算法最佳個體PSObest。 ③選出遺傳算法最佳個體GAbest。 ④最佳個體比特信息位交換。 ⑤PSO:更新粒子速度及位置。 ⑥GA: 選擇、比特率交叉(算法1)和變異。 3)判斷終止條件,若不滿足返回2),滿足進入4)。 4)比較GAbest與PSObest,輸出最佳個體。 算法3 最佳個體比特信息位交換 輸入 上一代最佳個體和本輪最佳個體。 輸出 交換比特信息位后的PSObest及HSbest。 1) 隨機選取PSO中引起最佳個體適應度值增加的信息位PSObit。 2) 隨機選取GA中引起最佳個體適應度值增加的信息位GAbit。 3) if PSObest優于 GAbest, 將GAbest中對應的信息位改為PSObit; else 將PSObest中對應的信息位改為GAbit; end 本文提出的GA-PSO協同演化算法,通過協同共享的思想讓PSO和GA互相彌補各自的弱點,互相協助從而產生更強的個體。對于本文面向的特征選擇問題,更好的個體可以從兩個角度進行判斷:特征與類別相關性越高,個體適應度值越高;特征子集規模越小,個體適應度值越高。面向特征選擇問題的協同演化方法執行流程如圖3所示。 圖3 協同演化算法的流程圖Fig.3 Flow chart of co-evolution algorithm 為了驗證本文提出算法的有效性,實驗結果從兩個方面進行分析:1)分析算法在不同數據集下分類的準確率;2)提出的算法與GA和PSO進行適應度值和收斂性比較。本文實驗特征選擇部分的運行環境為MATLAB 2014a,分類準確率運行環境為weka3.8。對數據的離散化處理采用經典的MDL方法。種群規模為20,迭代次數為300。GA中交叉概率為0.6,變異概率為0.15;PSO中c1=c2=2,w=0.4。 3.1 算法分類準確率的結果分析 本文實驗部分選用了UCI(UC Irvine machine learning repository)數據庫中的5個高維多類別數據集,特征維度從14維升至240維,不同數據集中樣本的類別數目最少為2類,最多為10類。其中,Australian與Credit Approval為兩個信用卡申請類數據集,Dermatology為皮膚病數據集,Synthetic Control是名為合成控制圖數據集,Multi-Feature Pixel是名為Multi-feature “0”到“9” 手寫圖數據集中的一個子集合。各數據集的詳細信息如表1所示。 表1 UCI數據集描述 實驗對比的特征選擇算法有GA、PSO、IG以及GR。為了驗證算法性能,選取SVM、1-NN和Na?ve Bayes 三個分類器,并且使用十折交叉驗證的方法測試在不同數據集下各個算法所選擇特征子集的分類。對于GA,PSO和GA-PSO三種進化搜索的方法,實驗得出每個算法連續運行20次時的平均分類準確率。而IG(information gain)信息增益和GR(gain ratio)增益比率都是以互信息為基礎的經典的排序特征選擇算法,因此在實驗中分別對每個數據集的特征進行排序,并且手動地選擇與進化算法規模相近的排名前p個特征,p為選擇的特征數量。具體的分類結果如表2~4所示。表2~4中數值表示各特征選擇算法選擇的特征子集在相應的數據集下使用分類器得到的分類準確率。Avg表示平均分類準確率,括號內數字為平均選擇的子集規模。 從表2中可以看出,本文提出的方法在5個數據集上均取得了最好的結果,比如在Synthetic Control數據集中,在選出相近的特征子集下,提出的方法的平均分類準確率比其他算法的平均分類準確率高出了平均2.98%。同樣如表3和表4所示,在1-NN和Na?ve Bayes分類器中,對于每個數據集本文提出的方法的平均分類準確率都比其他的算法具有優勢,在保證特征子集近似的情況下,能夠得到較好的分類效果。 表2 1-NN分類器的分類準確率 表3 SVM分類器的分類準確率 表4 Na?ve Bayes分類器的分類準確率 綜合GA-PSO在SVM、KNN和Na?ve Bayes 三個分類器下的表現,本實驗結果驗證了GA-PSO算法在不同規模數據集下分類性能的有效性,從分類準確率的角度評定本文提出的GA-PSO算法優于傳統的GA和PSO進化算法,也優于經典的特征選擇排序算法,平均分類精度有明顯提升。 3.2 算法適應度值的分析 在進化算法中,對于求最大化的目標函數而言,適應度值高的個體能夠在最大的程度上得到保留。適應度值高的個體的基因型對種群的進化方向起著指導作用。因此對于不同的演化方法,另一個評定的角度是在同一個適應度函數作用下比較哪種算法能夠得到更高的適應度值的個體。為了分析比較提出算法在進化過程中適應度值的變化情況,分別畫出了GA-PSO、GA和PSO算法在Synthetic Control、Dermatology和Multi-Feature Pixel數據集下單次迭代過程中適應度函數值的折線圖,如圖4~6所示。 圖4 Dermatology 數據集中的對比Fig.4 Comparison on Dermatology 圖5 Synthetic Control數據集中的對比Fig.5 Comparison on Synthetic Control 圖6 Multi-Feature Pixel數據集中的對比Fig.6 Comparison on Multi-Feature Pixel 對適應度值的分析:通過圖4可以看出,在0~150代GA-PSO保持著GA近似水平的適應度值,PSO的適應度值稍高,在150代以后GA-PSO和GA適應度值逐步提升,超過PSO,最終GA-PSO得到最高的適應度值;在圖5中,在240代后GA-PSO超過GA和PSO,最終GA-PSO取得最高的適應度值;在圖6的超高維數據集中,GA-PSO的尋優優勢更加明顯。GA-PSO比傳統的進化算法PSO和GA具有更強的搜索能力,在相同條件下總是能保持進化以找到更優的個體。 對收斂性的分析:隨著特征規模的增大,PSO總是過早收斂,這說明PSO算法容易陷入局部最優解,尤其對于高維特征數目的數據集,PSO不能保證良好的全局搜索;GA的全局搜索能力要優于PSO;GA-PSO則一直保持著良好的搜索能力,尤其在大規模數據集中,GA-PSO的表現更為突出,在300代以內,適應度值一直保持著提升,能夠有效地避免陷入全局最優解。 綜上所述,本文所提出的算法在進化過程中能夠產生比較優秀的個體,獲得比較高的適應度值,從而可以取得更好的分類準確率。這證明了,GA-PSO算法在進化過程中逐步尋優的能力,能夠找出相對優秀的特征子集。 本文提出了面向特征選擇問題的協同演化算法GA-PSO。為了保證種群多樣性,提出了一種基于比特率的交叉算子。針對GA和PSO尋優的不同特點進行共同演化,并將影響最佳個體形成的比特基因位作為公共信息實現共享。通過實驗對比驗證了協同演化的方法要優于單一進化的方法,并且驗證了全局搜索的特征選擇方法優于傳統的貪婪式特征選擇方法。本文的研究不僅可以有效地解決特征選擇問題,在其他的組合優化離散問題中也可以使用該思路進行協同演化。未來將進一步研究子集規模的自適應控制以及其他適應度評價方法。 [1]DASH M, LIU H. Feature selection for classification[J]. Intelligent data analysis, 1997, 1(1/2/3/4): 131-156. [2]GUYON I, ELISSEEFF A. An introduction to variable and feature selection[J]. The journal of machine learning research, 2002, 3(6): 1157-1182. [3]ZHAO Zheng, MORSTATTER F, SHARMA S, et al. Advancing feature selection research. ASU feature selection repository[R]. Phoenix: School of Computing, Informatics, and Decision Systems Engineering, Arizona State University, Tempe, 2010. [4]BATTITI R. Using mutual information for selecting features in supervised neural net learning[J]. IEEE transactions on neural networks, 1994, 5(4): 537-550. [5]YANG Yiming, PEDEREN J O. A comparative study on feature selection in text categorization[C]//Proceedings of the 14th International Conference on Machine Learning. San Francisco, CA, USA 1997: 412-420. [6]周志華. 機器學習[M]. 北京: 清華大學出版社, 2016: 247-266. [7]XUE Bing, ZHANG Mengjie, BROWNE W N, et al. A survey on evolutionary computation approaches to feature selection[J]. IEEE transactions on evolutionary computation, 2016, 20(4): 606-626. [8]PENG Hanchuan, LONG Fuhui, DING C. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy[J]. IEEE transactions on pattern analysis and machine intelligence, 2005, 27(8): 1226-1238. [9]UNLER A, MURAT A, CHINNAM R B. Mr2PSO: a maximum relevance minimum redundancy feature selection method based on swarm intelligence for support vector machine classification[J]. Information sciences, 2011, 181(20): 4625-4641. [10]CERVANTE L, XUE Bing, ZHANG Mengjie, et al. Binary particle swarm optimisation for feature selection: a filter based approach[C]//Proceedings of 2012 IEEE Congress on Evolutionary Computation. Piscataway. Brisbane, Australia, 2012: 1-8. [11]DONG Hongbin, TENG Xuyang, ZHOU Yang, et al. Feature subset selection using dynamic mixed strategy[C]// Proceedings of 2015 IEEE Congress on Evolutionary Computation. Sendai, Japan, 2015: 672-679. [12]NEMATI S, BASIRI M E, GHASEM-AGHAEE N, et al. A novel ACO-GA hybrid algorithm for feature selection in protein function prediction[J]. Expert systems with applications, 2009, 36(10): 12086-12094. [13]KENNEDY J, EBERHART R. Particle swarm optimization[C]//Proceedings of 1995 IEEE International Conference on Neural Networks. Perth, Australia, 1995: 1942-1948. [14]KENNEDY J, EBERHART R. A discrete binary version of the particle swarm algorithm[C]//Proceedings of 1997 IEEE International Systems, Man, and Cybernetics. Orlando, USA, 1997: 4104-4108. [15]李書全, 孫雪, 孫德輝, 等. 遺傳算法中的交叉算子的述評[J]. 計算機工程與應用, 2012, 48(1): 36-39. LI Shuquan, SUN Xue, SUN Dehui, et al. Summary of crossover operator of genetic algorithm[J]. Computer engineering and applications, 2012, 48(1): 36-39. Co-evolutionary algorithm for feature selection TENG Xuyang, DONG Hongbin, SUN Jing (College of Computer Science and Technology, Harbin Engineering University, Harbin 150001, China) Feature selection is a key preprocessing technology of machine learning and data mining. The traditional greed type of feature selection methods only considers the best feature of the current round, thereby leading to the feature subset that is only locally optimal. Realizing an optimal or nearly optimal feature set is difficult. Evolutionary search means can effectively search for a feature space, but different evolutionary algorithms have their own limitations in search processes. The evolutionary advantages of genetic algorithms (GA) and particle swarm optimization (PSO) are absorbed in this study. The final feature subset is obtained by co-evolution, with the information entropy measure as an assessment function. A specific bit rate cross operator and an information exchange strategy applicable for a feature selection problem are proposed. The experimental results show that the co-evolutionary method (GA-PSO) is superior to the single evolutionary search method in the search ability of the feature subsets and classification learning. In conclusion, the ability of combined evaluation, which is provided by an evolutionary search, is better than that of the traditional greedy feature selection method. feature selection; genetic algorithm (GA); particle swarm optimization (PSO); co-evolution; bit rate cross 滕旭陽,男,1987年生,博士研究生,主要研究方向為機器學習、智能優化算法。 董紅斌,男,1963年生,教授,博士生導師,主要研究方向為多智能體系統、機器學習。 孫靜,女,1993年生,碩士研究生,主要研究方向為機器學習、數據挖掘。 10.1992/tis.201611029 http://kns.cnki.net/kcms/detail/23.1538.TP.20170302.1522.002.html 2016-11-19. 日期:2017-03-02. 國家自然科學基金項目(61472095,61502116);黑龍江省教育廳智能教育與信息工程重點實驗室開放基金項目. 孫靜. E-mail:sunjing@hrbeu.edu.cn. TP301 A 1673-4785(2017)01-0024-08 滕旭陽,董紅斌,孫靜.面向特征選擇問題的協同演化方法[J]. 智能系統學報, 2017, 12(1): 24-31. 英文引用格式:TENG Xuyang,DONG Hongbin,SUN Jing.Co-evolutionary algorithm for feature selection[J]. CAAI transactions on intelligent systems, 2017, 12(1): 24-31.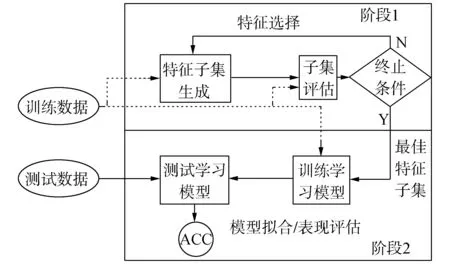
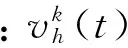
2 求解特征子集的協同演化方法


3 實驗結果與分析



4 結束語


 猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28當代陜西(2019年10期)2019-06-03 10:12:04兒童故事畫報(2019年5期)2019-05-26 14:26:14數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54Coco薇(2016年2期)2016-03-22 02:42:52Coco薇(2015年1期)2015-08-13 02:47:34小雪花·成長指南(2015年7期)2015-08-11 15:03:12小雪花·成長指南(2015年4期)2015-05-19 14:47:56
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28當代陜西(2019年10期)2019-06-03 10:12:04兒童故事畫報(2019年5期)2019-05-26 14:26:14數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54Coco薇(2016年2期)2016-03-22 02:42:52Coco薇(2015年1期)2015-08-13 02:47:34小雪花·成長指南(2015年7期)2015-08-11 15:03:12小雪花·成長指南(2015年4期)2015-05-19 14:47:56
