
基于事件驅動的多智能體強化學習研究
2017-06-01 12:21:31張文旭馬磊王曉東
智能系統學報 2017年1期
張文旭,馬磊,王曉東
(西南交通大學 電氣工程學院,四川 成都610031)
基于事件驅動的多智能體強化學習研究
張文旭,馬磊,王曉東
(西南交通大學 電氣工程學院,四川 成都610031)
本文針對多智能體強化學習中存在的通信和計算資源消耗大等問題,提出了一種基于事件驅動的多智能體強化學習算法,側重于事件驅動在多智能體學習策略層方面的研究。在智能體與環境的交互過程中,算法基于事件驅動的思想,根據智能體觀測信息的變化率設計觸發函數,使學習過程中的通信和學習時機無需實時或按周期地進行,故在相同時間內可以降低數據傳輸和計算次數。另外,分析了該算法的計算資源消耗,以及對算法收斂性進行了論證。最后,仿真實驗說明了該算法可以在學習過程中減少一定的通信次數和策略遍歷次數,進而緩解了通信和計算資源消耗。
事件驅動;多智能體;強化學習;分布式馬爾科夫決策過程;收斂性
近年來,基于事件驅動的方法在多智能體研究中得到廣泛關注[1-3]。在事件驅動的思想中,智能體可以根據測量誤差間歇性的更新狀態,減少通信次數和計算量。文獻[4]首次在多智能體系統的協作中運用事件驅動的策略,并設計了基于事件驅動機制的狀態反饋控制器。隨后,文獻[5-7]將基于事件驅動的控制器擴展到非線性系統,以及復雜網絡等領域。但是,目前事件驅動與強化學習的結合還相對不足[8-9],并主要集中在對多智能體的控制器設計上,較少有學者關注其在學習策略層的應用。在現有的多智能體強化學習算法中,由于智能體攜帶的通信設備和微處理器性能有限,其學習過程中通常存在兩個問題:1)智能體間的信息交互需占用較大的通信帶寬;2)在學習的試錯和迭代過程中,消耗了大量的計算資源。以上問題都將減少智能體的工作時間,或增加設計上的復雜性。本文區別于傳統的多智能體學習算法,側重于事件驅動在多智能體學習策略層的研究,首先從自觸發和聯合觸發兩個方面定義觸發函數,然后在分布式馬爾可夫模型中設計了基于事件驅動的多智能體強化學習算法,最后對算法的收斂性進行了論證。
1 問題描述
1.1 分布式馬爾可夫模型

1.2Q-學習
文獻[11]提出了一類通過引入期望的延時回報,求解無完全信息的MDPs類問題的方法,稱為Q-學習(Q-learning)。Q-學習是一種模型無關的強化學習方法,通過對狀態-動作對的值函數進行估計,以求得最優策略。Q-學習算法的基本形式如下:
Q*(s,a)=R(s,a)+γ∑s′∈SP(s,a,s′)maxQ*(s′,a′)
式中:Q*(s,a)表示智能體在狀態s下采用動作a所獲得的獎賞折扣總和;γ為折扣因子;P(s,a,s′)表示概率函數;最優策略為智能體在狀態s下選用Q值最大的策略。Q-學習存在的最大問題為,智能體需要通過試錯的方式找到最優策略,這樣的方式使得Q-學習需要考慮所有的可能策略,從而需要消耗大量計算資源。
2 觸發規則設計
在事件驅動思想中,智能體把從環境中得到的觀測誤差作為重要的評判標準,當它超過一個預設的閾值時事件被觸發,智能體更新狀態并計算聯合策略,而事件觸發的關鍵在于對觸發函數的設計。
2.1 自事件觸發設計
DEC-MDPs模型中,每一個智能體通過獨立的觀測獲取局部信息,然后廣播到全隊,所以每一個智能體首先需要自觸發設計。在時刻t,當每一個智能體觀測結束后,其根據上一刻觀測與當前觀測的變化率,進行一次自觸發過程,智能體用自觸發方式來判斷是否需要廣播自身的觀測信息。智能體i從t-1時刻到t時刻的觀測變化率定義為
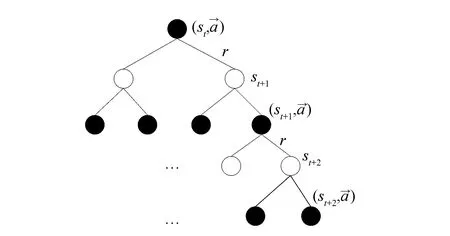
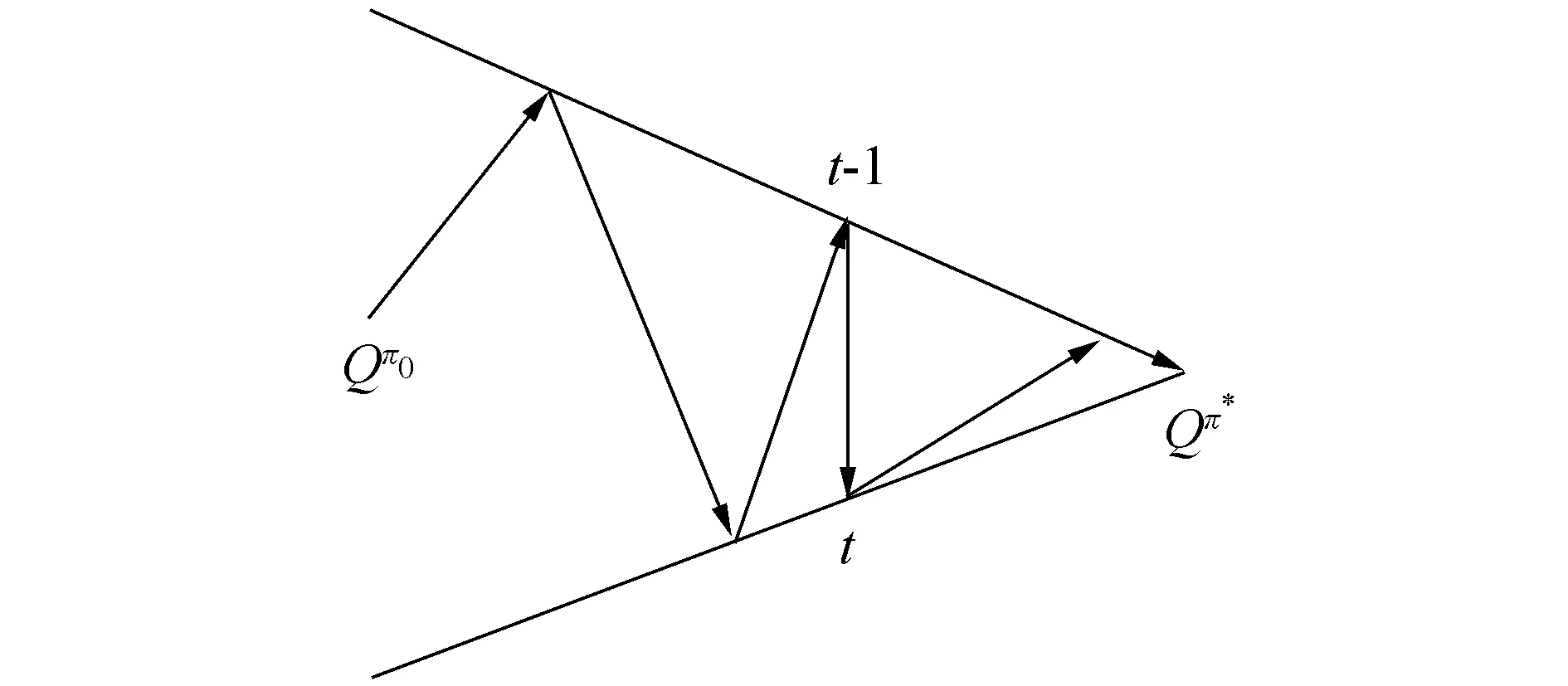
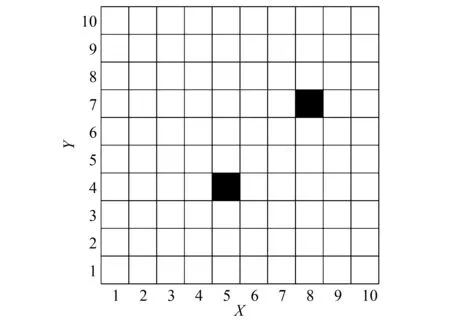
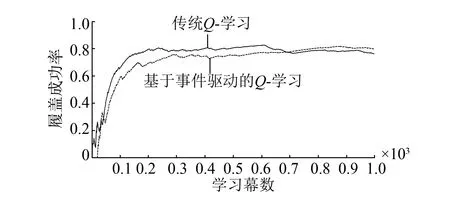
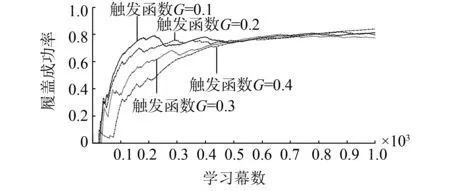
式中:oi(t)為在t時刻的觀測值。定義0 2.2 聯合事件觸發設計 聯合事件觸發的對象是智能體團隊,考慮的是一個聯合觀測的變化情況。假設在時刻t智能體團隊獲得當前的聯合觀測O(t)=(O1(t),O2(t),…,On(t))。此時,智能體團隊從t-1時刻到t時刻的聯合觀測變化率定義為 式中:p=1/n為ei(t)的分布律,令 定義0 自事件觸發和聯合事件觸發的區別在于: 1)自事件觸發的對象是單個智能體,對應的事件由智能體自身的觀測變化率所觸發,觸發后的行動為進行廣播式通信,自事件觸發的目的是為了減少通信資源消耗;而聯合事件觸發針對的是智能體團隊的聯合觀測變化率,觸發后的行動是計算聯合策略,目的在于減少計算資源消耗。 2)當單個智能體的觀測發生變化時,并不一定導致團隊的聯合觀測變化率發生較大改變。即當環境整體發生變化時,雖然每一個智能體的觀測都發生了變化,但對聯合觀測而言,所有智能體在兩個時刻的變化率相對無變化,所以制定的聯合策略可能無明顯變化,此時也認為智能體團隊不需要被觸發。比如在機器人足球問題中,t-1時刻機器人團隊的聯合策略為,機器人A帶球行動且其他隊友跑位行動。到t時刻后,機器人A和其他機器人的觀測(雙方機器人的站位和距離)都發生了較大變化,機器人團隊在通過廣播通信獲得全局觀測信息后,根據觀測信息進行判斷,兩個時刻雙方機器人的相對站位和相對距離可能無大變化。此時,如果團隊計算新的聯合策略,也將是機器人A帶球且其他隊友跑位,與t-1時刻的聯合策略相同。所以,認為團隊在t時刻無需計算新的聯合策略,可以直接使用上一刻的策略。圖1為事件觸發流程圖。 圖1 事件觸發流程圖Fig.1 The flow chart of event-triggered 本節介紹了基于事件驅動的強化學習算法,以及對事件驅動下計算資源消耗進行了分析,同時對算法的收斂性進行了論證。 3.1 基于事件驅動的強化學習設計 在完全通信情況下,DEC-MDPs被簡化為M-MDPs模型,所以直接考慮基于事件驅動的多智能體馬爾可夫模型(event-triggered M-MDPs),其由一個六元組〈I,{S},{Ai},P,R,e〉構成,其中e表示事件觸發函數,當團隊的觸發函數大于閾值時,團隊被觸發并執行聯合行動策略,同時發生狀態轉移,轉移函數為P={st+1|st,a,e}。基于事件驅動的強化學習過程不同于經典的強化學習,如圖2所示,智能體需要首先根據觸發函數來判斷事件是否被觸發,如果被觸發才執行一個聯合行動并影響環境。 圖2 基于事件驅動的強化學習框架Fig.2 The frame of reinforcement learning with event-triggered 對于任意一個策略和下一個狀態,在狀態s的值和后繼狀態值之間存在如下關系: (a)傳統的Q-學習 (b)基于事件驅動的Q-學習圖3 兩種方式回溯圖Fig.3 The backtracking of two methods 根據貝爾曼迭代,Q值逐漸收斂到一個最優Q值,在傳統的強化學習中,每一個學習步智能體都需要通過查表方式找到最大的Q值,其迭代表達式為 事件驅動的思路則不同,當智能體沒有被觸發情況下,將直接選用上一個Q值作為當前的Q值,在基于事件驅動的Q-學習中,Q值迭代過程可以表示為 式中k表示上次觸發時刻和當前時刻的差值。 3.2 計算資源消耗 對于基于事件驅動的決策樹,在智能體不被驅動的樹層中,下一刻狀態將直接等于當前狀態,即st+1=st,狀態轉移概率為 3.3 算法收斂性分析 智能體每次的策略評估,即策略迭代,都是從前一個策略的值函數開始。在事件驅動的強化學習中,智能體只有在觀測信息變化情況下,才更新信念空間并進行策略評估,否則直接使用上一時刻的策略。假設在t時刻,智能體沒有被事件所觸發,那么智能體在t時刻不參與式(9)的迭代,直接使用t-1時刻迭代后的Q值。此時,在達到最優策略的過程中,Q值的迭代計算過程由每一時刻都計算,減少為事件觸發時刻才計算。 如圖4(a)和式(10)所示,Q值從初始到收斂至最優Q*的過程,是一個漸進收斂的過程,Q值通過迭代,從t-1時間到t時刻逐漸接近最優;如圖4(b)和式(11)所示,在智能體不被驅動的情況下,Q值不進行迭代,在t-1時刻直接使用t時刻的Q值,減少了Q值的迭代計算。 (a)經典的Q-學習策略迭代 (b)基于事件驅動的Q-學習策略迭代圖4 兩種方式策略迭代Fig.4 Policy iteration of two methods 推論1 基于事件驅動的Q-學習算法,不會影響算法的收斂性。 1)對所有的U1和U2∈F0,對所有的x∈χ, 2)對所有的U和V∈F0,對所有的x∈χ, Ft(x)(‖v*-V‖ 式中:當t→時,λt以概率1收斂到0。 3)對所有的k>0,當t→時收斂到0。 4)當t→時,存在0≤γ<1對所有的x∈X有 Gt(x)δt(x)+Ft(x)‖v*-Vt‖ 在滿足條件1)和2)的情況下,雖然基于事件驅動的動作序列T中有相同的動作Tk=Tk+1,但仍然滿足李普西斯條件,所以不會影響Q-學習的收斂,證畢。 考慮一個多智能體覆蓋問題,2個智能體隨機出現在一個大小為10×10的格子世界中,如圖5所示。每一個智能體都有上下左右4個行動,且觀測范圍為自身周圍一圈共8個格子,觀測到的格子分為“沒走過”“走過”和“障礙物”3個狀態,分別對應著30、-5和-10的回報值,世界的邊界對智能體作為障礙物;且每一個智能體可以進行廣播式通信。在這個場景中,每一個智能體獲得的是一個局部觀測,當它們進行廣播通信后,對于整個世界,獲得的仍然是一個局部的觀測。但考慮到對整個世界的全局觀測需要極大的計算量,所以實驗設定每一時刻當兩個智能體通信后,所獲得的信息對它們而言是一個全局觀測。 智能體團隊的任務為盡快走完所有的格子,即完成對格子世界的覆蓋,當走過的格子超過90%以上,認為此次覆蓋任務成功,當智能體在1 000步仍不能完成90%的覆蓋時,認為此次任務失敗。其中定義學習率為0.6,折扣因子為0.2。 圖5 多智能體覆蓋問題Fig.5 The coverage problem of multi-agent 圖6比較了事件驅動與傳統Q-學習任務成功率,可以看出兩種算法成功率一致,但是由于Q值迭代次數減少,使得事件驅動Q-學習的收斂速度變慢。 圖6 事件驅動與傳統Q-學習的成功率Fig.6 The success rate of event-triggered Q and classical Q 圖7說明了聯合觸發函數與算法收斂速度的關系,可以看出聯合觸發函數選取越小,算法收斂性越慢。因為聯合觸發函數越小,事件觸發的次數就越少,從而導致Q值迭代次數減少,收斂速度變慢。 圖7 聯合觸發函數與收斂速度Fig.7 The joint event-triggered function and convergence speed 在學習過程中,智能體團隊在每一步需要遍歷Q值數量為(38×4)2≈229.3次,由表1可以看出,隨著學習步數的增加,事件驅動將大量減小Q值的遍歷次數,繼而減少計算資源占用,相比較傳統的Q-學習存在明顯的優勢。 表1 事件驅動傳統Q-學習遍歷次數 Table 1 The number of traverse of event-triggered and classicalQ 步數Q-學習事件驅動Q-學習減少總遍歷次數50≈229.3×50≈229.3×42≈232.3100≈229.3×100≈229.3×79≈233.6200≈229.3×200≈229.3×153≈234.9300≈229.3×300≈229.3×221≈235.6500≈229.3×500≈229.3×386≈236.2 表2比較了在一次成功的任務中,事件驅動與傳統Q-學習的通信次數。可以看出,事件驅動減少了智能體間的通信次數。同時與表1比較,可以看出自事件觸發和聯合事件觸發次數的區別。 表2 事件驅動與傳統Q-學習通信次數 Table 2 The number of communication of event-triggered and classicalQ 步數Q-學習事件驅動Q-學習減少通信次數50504551001008911200200172283003002584250050041090 本文提出了一種基于事件驅動的多智能體強化學習算法,側重于多智能體在學習策略層的事件驅動研究。智能體在與環境的交互中,可以根據觀測的變化來觸發通信和學習過程。在相同時間內,采用事件驅動可以降低數據傳輸次數,節約通信資源;同時,智能體不需要每一時刻進行試錯和迭代,進而減少計算資源。最后,對算法的收斂性進行了論證,仿真結果表明事件驅動可以在學習過程中減少一定的通信次數和策略遍歷次數,進而緩解通信和計算資源消耗。進一步工作主要基于現有的研究,將事件驅動的思想應用于不同類的強化學習方法中,并結合事件驅動的特點設計更合理的觸發函數。 [1]ZHU Wei, JIANG ZhongPing, FENG Gang. Event-based consensus of multi-agent systems with general linear models[J]. Automatica, 2014, 50(2): 552-558. [2]FAN Yuan, FENG Gang, WANG Yong, et al. Distributed event-triggered control of multi-agent systems with combinational measurements[J]. Automatica, 2013, 49(2): 671-675. [3]WANG Xiaofeng, LEMMON M D. Event-triggering in distributed networked control systems[J]. IEEE transactions on automatic control, 2011, 56(3): 586-601. [4]TABUADA P. Event-triggered real-time scheduling of stabilizing control tasks[J]. IEEE transactions on automatic control, 2007, 52(9): 1680-1685. [5]ZOU Lei, WANG Zidong, GAO Huijun, et al. Event-triggered state estimation for complex networks with mixed time delays via sampled data information: the continuous-time case[J]. IEEE transactions on cybernetics, 2015, 45(12): 2804-2815. [6]SAHOO A, XU Hao, JAGANNATHAN S. Adaptive neural network-based event-triggered control of single-input single-output nonlinear discrete-time systems[J]. IEEE transactions on neural networks and learning systems, 2016, 27(1): 151-164. [7]HU Wenfeng, LIU Lu, FENG Gang. Consensus of linear multi-agent systems by distributed event-triggered strategy[J]. IEEE transactions on cybernetics, 2016, 46(1): 148-157. [8]ZHONG Xiangnan, NI Zhen, HE Haibo, et al. Event-triggered reinforcement learning approach for unknown nonlinear continuous-time system[C]//Proceedings of 2014 International Joint Conference on Neural Networks. Beijing, China, 2014: 3677-3684. [9]XU Hao, JAGANNATHAN S. Near optimal event-triggered control of nonlinear continuous-time systems using input and output data[C]//Proceedings of the 11th World Congress on Intelligent Control and Automation. Shenyang, China, 2014: 1799-1804. [10]BERNSTEIN D S, GIVAN R, IMMERMAN N, et al. The complexity of decentralized control of Markov decision processes[J]. Mathematics of operations research, 2002, 27(4): 819-840. [11]WATKINS C J C H, DAYAN P.Q-learning[J]. Machine learning, 1992, 8(3/4): 279-292. Reinforcement learning for event-triggered multi-agent systems ZHANG Wenxu, MA Lei, WANG Xiaodong (School of Electrical Engineering,Southwest Jiaotong University, Chengdu 610031, China) Focusing on the existing multi-agent reinforcement learning problems such as huge consumption of communication and calculation, a novel event-triggered multi-agent reinforcement learning algorithm was presented. The algorithm focused on an event-triggered idea at the strategic level of multi-agent learning. In particular, during the interactive process between agents and the learning environment, the communication and learning were triggered through the change rate of observation.Using an appropriate event-triggered design, the discontinuous threshold was employed, and thus real-time or periodical communication and learning can be avoided, and the number of communications and calculations were reduced within the same time. Moreover, the consumption of computing resource and the convergence of the proposed algorithm were analyzed and proven. Finally, the simulation results show that the number of communications and traversals were reduced in learning, thus saving the computing and communication resources. event-triggered; multi-agent; reinforcement learning;decentralized Markov decision processes;convergence 張文旭,男,1985年生,博士研究生,主要研究方向為多智能體系統、機器學習。發表論文4篇,其中被EI檢索4篇。 馬磊,男,1972年生,教授,博士,主要研究方向為控制理論及其在機器人、新能源和軌道交通系統中的應用等。主持國內外項目14項,發表論文40余篇,其中被EI檢索37篇。 王曉東,男,1992年生,碩士研究生,主要研究方向為機器學習。獲得國家發明型專利3項,發表論文4篇。 10.11992/tis.201604008 http://kns.cnki.net/kcms/detail/23.1538.TP.20170301.1147.002.html 2016-04-05. 日期:2017-03-01. 國家自然科學基金青年項目(61304166). 張文旭.Email: wenxu_zhang@163.com. TP181 A 1673-4785(2017)01-0082-06 張文旭,馬磊,王曉東. 基于事件驅動的多智能體強化學習研究[J]. 智能系統學報, 2017, 12(1): 82-87. 英文引用格式:ZHANG Wenxu, MA Lei, WANG Xiaodong. Reinforcement learning for event-triggered multi-agent systems[J]. CAAI transactions on intelligent systems, 2017, 12(1): 82-87.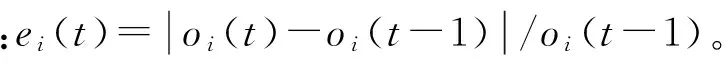

3 基于事件驅動的強化學習
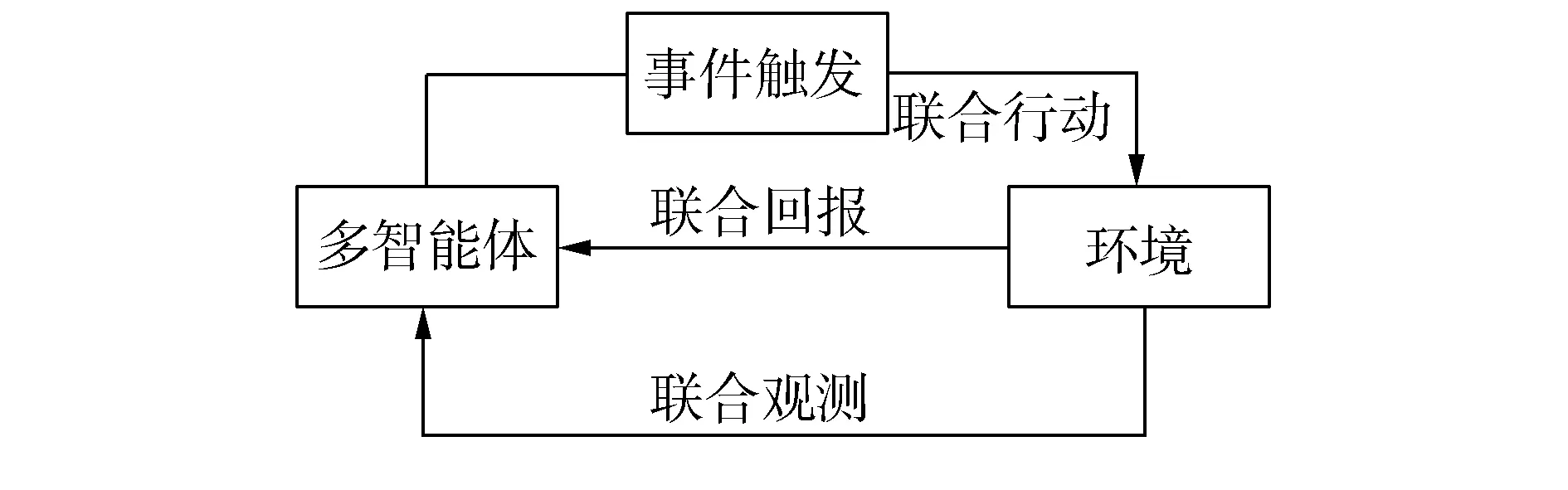
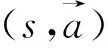

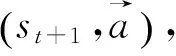

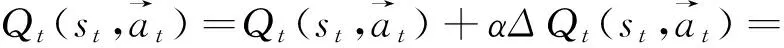
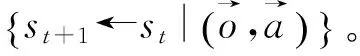

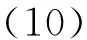



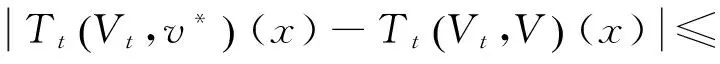

4 仿真結果及分析


5 結束語


 猜你喜歡
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52中學生數理化·高一版(2020年3期)2020-04-21 08:03:20中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10表面工程與再制造(2019年6期)2019-08-24 06:40:04文苑(2018年23期)2018-12-14 01:06:06文苑(2018年19期)2018-11-09 01:30:14文苑(2018年17期)2018-11-09 01:29:26文苑(2018年21期)2018-11-09 01:22:32商周刊(2018年18期)2018-09-21 09:14:46
猜你喜歡
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52中學生數理化·高一版(2020年3期)2020-04-21 08:03:20中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10表面工程與再制造(2019年6期)2019-08-24 06:40:04文苑(2018年23期)2018-12-14 01:06:06文苑(2018年19期)2018-11-09 01:30:14文苑(2018年17期)2018-11-09 01:29:26文苑(2018年21期)2018-11-09 01:22:32商周刊(2018年18期)2018-09-21 09:14:46
