基于MongoDB的文本分類研究
2017-06-21 23:23:37陳德森楊祖元
無線互聯科技 2017年5期
陳德森 楊祖元
摘要:文章基于流行的非關系型數據庫MongoDB,結合spark機器學習庫中的樸素貝葉斯分類器和支持向量機,對豆瓣影評及京東商評進行情感分類,并采用準確率、召回率、F-Measure等指標對分類效果進行評價,最后測試了spark-MongoDB平臺的擴展性能。
關鍵詞:文本分類;Spark;MongoDB;MLlib
互聯網發展促進了社交媒體、在線交易等新興媒介的發展,這些網站每天都會產生數以億計的數據。其中文本數據占據了重要位置,有80%的數據以文本形式存在的。如何有效利用這些文本數據去創造價值,是亟待解決的問題。
文本挖掘(Text Mining,TM)是指從非結構化文本中獲取用戶有用信息的過程。文本挖掘是從數據挖掘發展而來,但與傳統的數據挖掘相比,文本挖掘有其獨特之處,主要表現在:文檔本身是半結構化或非結構化的,無確定形式并且缺乏機器可理解的語義;而一般數據挖掘的對象以數據庫中的結構化數據為主,并利用關系表等存儲結構來發現知識。
針對上述問題,本文將結合MongoDB和Spark,在文本存儲及文本分類效果兩方面進行研究。
1.文本數據的存儲
上文所述產生的數據,通常是由關系數據庫管理系統來處理。實踐證明,關系模型是非常適合于客戶服務器編程,它是今天結構化數據存儲在網絡和商務應用的主導技術。然而在數據爆炸的互聯網時代,傳統的關系型數據在應對大規模和高并發訪問時顯得力不從心,因此一批NoSQL數據庫開始涌現,如MongoDB,Redis,Cassandra,HBase,CouchDB等。這些非關系型數據庫旨在解決大規模集合以及多重數據類型帶來的挑戰,尤其適合大數據處理。
1.1MongoDB數據庫
MongoDB是最近幾年非常火的一款NoSQL數據庫,由c++語言編寫,是一個基于分布式文件存儲的開源數據庫系統。在高負載的情況下,MongoDB可以通過添加更多的節點,來保證服務器性能。MongoDB旨在為Web應用提供可擴展的高性能數據存儲解決方案。(1)內存充足。MongoDB性能非常好,它將熱數據存儲在物理內存中,使得數據讀取十分快速。(2)高擴展性。MongoDB的高可用集群擴展性非常好,通過物理機的增加和在數據庫中配置Sharding,集群擴展簡單、高效。(3)Failover機制。MongoDB集群的主節點宕機后,通過選舉方式自動在從節點中選出新的主節點提供服務,不需要人工參與。(4)BSon的存儲格式。類JSon的存儲格式,使得MongoDB十分適合文檔的存儲與查詢。
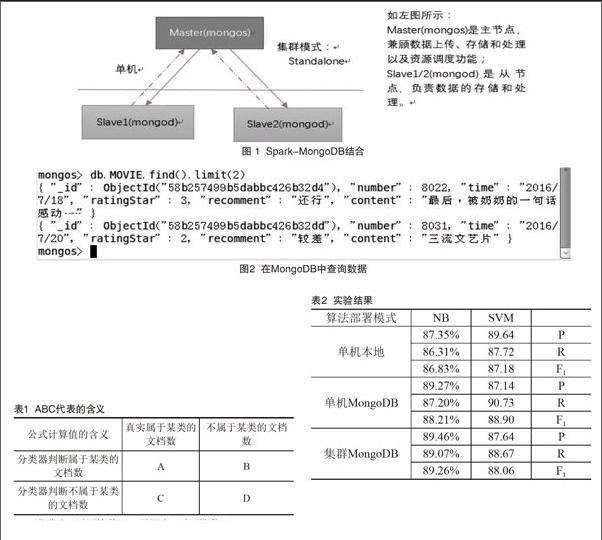
基于MongoDB的特點,本文嘗試用MongoDB結合Spark做文本分析研究。MongoDB支持3種部署方式,分別是單機模式、復制集模式、分片模式,本文采用的是分片模式。
1.2Spark結合Mong0DB
Spark是加州大學伯克利分校的AMP實驗室(UC Berkeley AMP lab),Matei Zaharia博士在2009年所創立的大數據處理和計算框架,是一個類Hadoop MapReduce的開源通用并行框架。不同于傳統的數據處理框架,Spark基于內存的基本類型(primitive)為一些應用程序帶來了100倍的性能提升。Spark允許用戶程序將數據加載到集群的內存中,用于反復查詢,非常適用于大數據和機器學習,已經成為最廣泛采用的大數據模塊之一。在本文中程序中,通過添加mongo-java-driver-3.3.0.jar.mongo-hadoo-core-2.0.1.jar實現MongoDB和Spark的連接,使用ANSJ中文分詞工具對讀入的短評進行中文分詞,最后使用Spark MLlib中的樸素貝葉斯分類器與支持向量機進行文本分析。
Spark-MongoDB結合的形式如圖1所示,其中MongoDB采用的是分片模式。
1.3實驗數據集
本文采用基于Java的網絡爬蟲獲取互聯網上的短評數據,共采集大概60萬條評論,涉及了《瘋狂動物城》《蝙蝠俠大戰超人》《木星上行》(Honor8》等豆瓣、京東的評論。將影評和手機銷售評論數據合并后,經過初步的清洗(去雙引號,清除空數據,編碼轉換utf-8等),將數據導入MongoDB數據庫中。在數據庫中查看數據:
在文本分析實驗中,按照評論的星級,將打1~2星的評論認為是差評,4~5星的評論認為是好評,以此來對短評進行文本分類。
1.4文本分類算法度量
在二分類問題中,通常使用的評價方法包括準確率,錯誤率,召回率,F-Measure,ROC曲線,準確率一召回率曲線下方面積,ROC曲線的下方面積以及等。在本文中,使用準確率、召回率、F值評估文本分類效果。其中,A,B,C所代表的含義如表1所示。
準確率(以下簡稱P);召回率(以下簡稱R)。
由于P值和R值出現矛盾的時候,還可以考慮用另外一種方法去分析,那就是F-Measure(又稱F-Score)。F-Measure是P值和10值的加權和平均。
當參數a取1時,就是常見的值,即:可見綜合P值和R值;當值較高時,說明分類方法有效。
接下來使用豆瓣數據集,驗證文本分析情感分析在各種部署環境下的算法準確度。
1.5實驗結果
從表2中可以看到,在單機本地,單機MongoDB,集群MongoDB集中模式中,樸素貝葉斯和支持向量機的分類效果相差無幾。算法準確度并沒有因為數據分散在各個不同節點而下降,可知分布式存儲是適合做機器學習的。基于SparkMLlib的機器學習庫的算法效率也比較高,可見已經可以適應一般的實際應用場景。
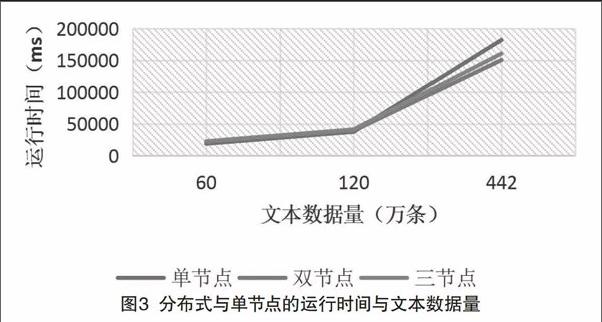
通過自我復制的方式對數據進行擴大,驗證Spark-MongoDB分布式計算能力。使用分詞工具分詞,分別在單節點、雙節點、三節點做分詞和統計總詞數的操作,通過運行時間比較他們之間的處理效率。其中單節點(主節點)是雙核6G內存,單節點(從節點)是單核3G內存。
從圖3中可以看出,分布式與單節點的運行時間比較中,在數據量達到一定程度后,加速比是大于1的,證明MongoDB集群在大數據處理方面確實比單機的效率要高。但由于數據量大小的原因以及內存的限制,它們之間的差別并不是很明顯,甚至還出現了雙節點速度比三節點快的尷尬,造成這種現象的原因是因為啟動多個節點,在通信和資源調度方面會花費一定的時間。但總體而言依舊可以看出分布式平臺比單節點操作具有更平緩的時間增長曲線。如果在更大規模的數據量以及性能更好的機器集群上,相信它們之間會有比較明顯區別。由此可知,在實際應用中,如果需要處理的數據量很大的話,應用Spark-MongoDB分布式平臺處理大數據將是一個很好的解決方案。
2.結語
由上述實驗可知,spark自帶的機器學習庫,對一般文本的分類準確率已經比較高,結合文檔型MongoDB做文本分析,將會是分布式環境下大數據分析的不錯選擇,具有實際應用價值。
