基于云計算技術的電力大數據預處理屬性簡約方法
2017-06-30 10:41:38皮霄林
科技創新導報 2017年12期
皮霄林
摘 要:隨著當今時代信息技術的快速發展,大數據概念一經提出便被廣泛應用到了多個行業領域當中,將之應用于電網系統當中表現出了十分明顯的多類型、大體量、高效率特性,基于這一現狀之下顯然已經無法再用傳統的屬性約簡方式來對電力大數據進行計算與處理。因此,基于云計算的電力大數據預處理屬性約簡方法也便應運而生。該文主要就基于MapReduce技術的電力大數據預處理屬性約簡方法展開了深入探究,并最終就其正確性與對節點數目的影響進行了驗證分析。
關鍵詞:云計算技術 電力大數據 MapReduce技術 屬性約簡
中圖分類號:TP18 文獻標識碼:A 文章編號:1674-098X(2017)04(c)-0158-02
身處于當今的大數據時代,電力企業信息化程度和智能電力系統的建設,將促使電力數據的體量實現指數級增長;在電力大數據應用方面,對于行業內外各方面的數據分析均會導致電力數據計算與處理類型成本增多。充分挖掘軟硬件資源的潛在價值,減小投入支出,更多的從海量的數據信息當中發掘出其中有價值的數據,促使相關的管理人員能夠獲得更加多元化的知識內容,將是在大數據時代開展電網管理與控制工作最為重要的一項難題。
1 概述
在具體的電網數據分析工作中,對于最終決策起到主導作用的因素很可能僅是其中的某一部分,而要將這些最為關鍵的因素及時尋找出來將會對于縮減數據處理規模、提升數據處理效率意義重大。有研究人員就通過應用經典粗糙集理論將對于風力速度有可能產生影響的屬性進行了約簡處理,同時在對風力速度的預測過程之中也達到了較為滿意的效果。一般的數據約簡處理方法盡管在減小時間復雜程度、提升效率上價值明顯,然而,此類屬性所采取的約簡算法都是假定將所有的數據內容一次性錄入系統內,很明顯這無法適用于電力大數據系統。還有研究采用傳統關系數據庫技術屬性約簡方式,來處理小規模屬性約簡問題,盡管在時間性能方面取得了較為滿意的效果,然而采取此類方法所能夠應對處理的數據規模及時效性均會受制于硬件限制。
而將云計算技術應用于電力大數據預處理當中,則能夠給予其軟件及硬件資源和相關的數據處理提供以新的途徑方式。在本次研究中重點就針對美國谷歌公司所提出的MapReduce編程模型展開了深入的分析與探討,具體就粗糙集相對正域理論和現行的知識約簡計算方式展開了深入剖析,結合其模型設計與計算最終對基于云計算技術的電力大數據預處理屬性約簡方法的正確性,及其對節點數目的影響展開了實證分析,最終的實驗結果顯示,此項計算方法不當可大幅度提升電力大數據集的屬性約簡計算效率,同時還可達到較為優異的可拓展性效果。
2 基于MapReduce技術的電力大數據預處理屬性約簡
將一個電力大數據集視作為是一項電力知識表達系統,相應的便需求出對指定決策屬性集的條件屬性,也就是將這一電力大數據集的屬性約簡問題轉歸成計算正域勢的問題。應用MapReduce計算以上問題,其具體方法為:map函數同時對于多個數據分片進行訪問,依據實際需求,將屬性及屬性值取出,并以此產生出
Hadoop在進行復雜任務處理之時是對任務數量的增多,而并非是提高map與reduce的復雜性,因此基于云環境下進行電力大數據預處理屬性約簡,則可設計出多個函數及主程序。在此方面的約簡處理過程當中,可將某項具體的電力大數據集視作為是一項電力知識表達系統,并基于這一基礎之上,再開展屬性約簡處理,并可將其視作為是對正域勢的計算,具體的計算方式如下所示:
(1)map函數位于同一時段內針對多項數據分片各自獨立展開訪問,同時依據實際要求規范來獲取屬性和屬性值,進而產生出鍵值對
(2)Reduce函數對即為各節點處的map與所發送的key值所相對應的鍵值對序列,同時還需針對相應的等價類個數予以計算處理。
應用Hadoop針對復雜任務予以處理之時,其主要側重于對任務數量的增多,而并非是針對map以及Reduce函數復雜性的加強。因而,在基于云計算技術的電力大數據預處理屬性約簡方面,針對性設計出兩項map,三項Reduce以及call job函數,同時還可攜帶一項主控程序,最終再結合以實際需求,各自給定算法,即可針對大數據預處理屬性展開約簡計算。
和傳統約簡方法相對比來看,基于云計算的約簡方法不但可促使無法針對大數據集進行處理的情況迎刃而解,同時還能夠顯著提升整體簡約處理的效率,大大減小簡約復雜性,可同時實現對空間與時間的雙重精簡。鑒于此,在目前的電力企業發展過程之中,這一技術已成為電力大數據預處理屬性約簡的核心手段之一。
3 驗證分析
現就針對基于云計算的電力大數據預處理屬性約簡方法,由算法正確性和節點數據的影響兩方面來探討其在電力大數據預處理之中的效用價值。
3.1 正確性
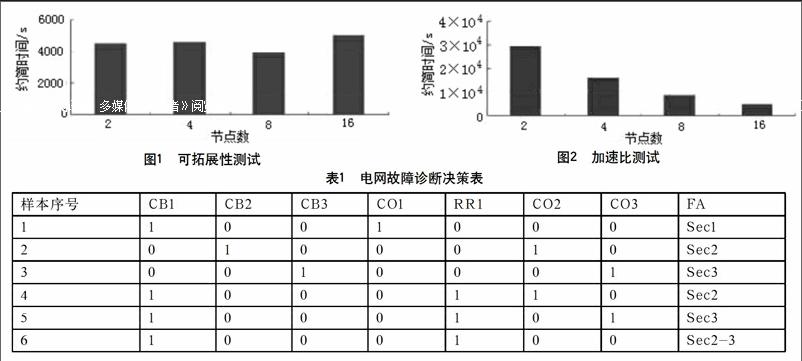
采用某一電網故障診斷決策表來闡明基于云計算的電力大數據預處理屬性約簡方法的正確性。下表1為由6個樣本所構成的電網故障診斷決策表。
采用偽分布模式進行Hadoop程序的運行,便可獲得決策表核{CO2,CO3}和一項約簡{CO2,CO3,CB1,CO1}。經驗證表明,結果正確。
3.2 節點數目的影響
在本次研究中選用Hadoop平臺搭建了一個集群實驗環境,其中的Hadoop版塊為Hadoop-0.20.0,應用臨近平均值針對缺失數值予以填補,促使數據離散成一系列的0,1列表,以促進數據處理效率的提升,并由此獲得13項條件屬性及1項據測屬性電力知識表達系統S。
(1)可拓展性
這一特性是依據節點數量并按照特定比例來提高并行算法精確性。為驗證算法的可拓展性,選取四個節點值來充當測試數據集,即2,4,8,16四個節點。如下圖1所示,觀察圖1可發現,盡管因為硬件與平臺運行資源耗損因素導致節點數上升到16之后算法能力有所降低,然而各作業的運行時間基本相當,此即表明了并行算法的良好拓展性。
(2)加速比
加速比即為在數據規模保持恒定不變的前提下,持續增多節點數量并行算法能力。較為合理的加速比往往是線性結構的,然而因為各項計算機設備間的通信、任務調度等因素影響,具體的加速比常常是要小于理想狀態的。如下圖2所示,測試數據集為20GB,同樣為2,4,8,16四個節點,經觀察約簡時間與節點數量關系可表明,本次研究所提出的算法可達到較為優異的加速比性能。
4 結語
總而言之,在電力行業高速發展的當今時代,應大力加強對于相關云計算技術的深入研究及應用,同時在云計算技術的基礎之上來開展關于電力大數據預處理屬性約簡,促進電力大數據處理效率能夠得以大幅度的提升,并為企業的管理人員提供詳盡、可靠的參考依據。
參考文獻
[1] 彭小圣,鄧迪元,程時杰,等.面向智能電網應用的電力大數據關鍵技術[J].中國電機工程學報,2015(3):503-511.
[2] 王德文,孫志偉.電力用戶側大數據分析與并行負荷預測[J].中國電機工程學報,2015(3):527-537.
