基于HBASE的時空大數據關聯查詢優化
2017-07-10 10:27:26徐愛萍
計算機應用與軟件 2017年6期
徐愛萍 王 波 張 煦
1(武漢大學計算機學院 湖北 武漢 430072)2(湖北省環境監測中心站 湖北 武漢 430079)
基于HBASE的時空大數據關聯查詢優化
徐愛萍1王 波1張 煦2*
1(武漢大學計算機學院 湖北 武漢 430072)2(湖北省環境監測中心站 湖北 武漢 430079)
隨著數字采集和存儲技術的快速發展,視頻監測系統得到快速普及,以此帶來了海量的監測視頻數據。與文本數據不同的是,監測數據具有時空特征,如何在規模龐大且動態增長的數據量下進行高效的查詢成為許多時空數據應用所關心的問題。針對云存儲體系結構中監測視頻大數據高效的時空聯合查詢需求,充分利用時空特征值和屬性特征值在應用中的關聯關系,以及HBase數據庫在海量查詢方面的優良性能,提出了基于HBase Bloomfilter的時空大數據多重過濾機制,創新性地利用視頻文件特征值之間的依賴與關聯關系來安排rowkey索引鍵。在此基礎上設計出兩種時空關聯查詢算法。最后通過實驗證明了算法在時空大數據查詢方面的可行性、靈活性和高效性,對其他大數據關聯查詢應用有較好的指導意義。
云存儲 大數據 關聯查詢 時空特征
0 引 言
海量的時空大數據存儲與檢索的研究尚處于初步階段,主要局限于空間文本的處理研究方面。其數據存儲主要利用傳統的空間數據存儲系統根據空間數據模型進行數據存儲,研究點是采用曲線降維和存儲壓縮機制將多維空間數據進行降維壓縮成文本信息進行存儲,以方便HBase進行處理。常用的降維有PCA、Hilbet曲線等降維方法[1]。PCA基于主元分析的特征提取算法,對于樣本差別很大的空間樣本存在明顯的缺陷,匹配精度不夠;在數據查詢方面,RDBMS采用對一個或者若干個屬性建立索引以及優化分頁算法來達到性能上的提升。經典的分頁算法有ADO Recordset算法、基于TOP的快速查詢算法以及Limits算法[2],這些算法在數據集上進行分組分頁式加速,對關系數據庫的快速查詢起到很好的效果。文獻[3]提出了一種基于屬性相關性的SPARQL 查詢優化方法,文獻[4-5]通過優化索引表以及通過持續更新維護元數據對海量數據存儲進行查詢優化。這些方法通常要耗費大量的資源來維護查詢所需要的性能開銷,且面對海量的時空大數據查詢性能很低[6]。
云計算技術的出現為解決該問題提供了新的思路,特別是開源社區的活躍,Hadoop生態下的HBase、Hive以及MapReduce計算框架等技術的出現為PB級別的數據存儲提供支持[7]。本研究以監測視頻數據為信息載體,提出了一種基于各組特征值之間依賴關系而進行rowkey排序拼接的構成規則。首先挖掘監測視頻中具有時空特征依賴性的關聯特征值,并在HBase中建立高效、易擴展的存儲訪問索引,在此基礎上進一步提出了兩種基于HBase的時空關聯查詢算法,最后通過實驗驗證了本研究的可行性、高效性和可擴展性。
1 基于HBase的監測視頻的時空大數據存儲設計
1.1 HBase存儲模型
HBase是一個面向列的、版本化的、可伸縮的、以鍵值對形式來存儲數據的分布式存儲系統。與傳統的關系型數據模型不同的是,HBase采用類似于Google的Bigtable存儲模型[8],并支持“大表”的動態擴展,這種Bigtable存儲模型可以按如下定義進行形式化描述:
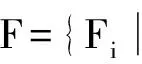
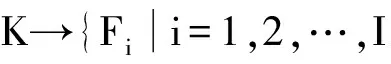
(1)
F→ {Sj,Cj,j=1,2,…,J}
(2)
(3)
其中符號→表示映射關系,超列集合S和列集合C可屬于同一層次,F可以同時映射至S、C。HBase將這種存儲模型實現為字典式大表,K為大表行健Row Key、F實現為列簇ColumnFamily、S和C組成列成員Famlily:Qualifier。行健、列成員以及時間戳來唯一標識一個cell,時間戳用來區分每個Cell可能出現的多個版本,每個cell中存放著一個無類型的字節碼。又由于其底層是一個稀疏的、分布式的、持久化存儲的多維度排序Map結構,通常用來處理分布在數千臺普通服務器上的PB級的大數據,又由于其優良的并行處理能力和高度可擴展性,本文選擇HBase作為時空大數據索引表存儲結構。
1.2 基于HBase時空大數據rowkey設計
1.2.1 監測視頻時空大數據的關聯依賴規則
其中數據記錄Recordi與其特征值存在如下關系:
時空特征不依賴業務特征而獨立存在,當時空特征T、G確定時:
(1) 任意的camera下必定有連續的case與之對應;
(2) 任意的case下必定有連續的record與之對應;
(3) 當camera、case、record均一定時,則Recordi唯一確定。
我們稱視頻監測時空大數據的業務特征case、camera、record之間存在相關依賴性,而時空特征Time、Geo與之形成時空關聯模式。例如,在某個時間某個街區,監測系統的探頭必定監測到某些事件的發生,這個事件必定分布于不同的記錄,如果我們確定了探頭號、事件號、記錄號,也就唯一了一個監測視頻記錄,反之則不成立。
表1給出了監測視頻時空大數據集Records中的信息描述,監控視頻的大數據對象相關依賴性特征值由一組關鍵字成:{Time,Geo ,camera,case,record,filepath},這組關鍵字即是滿足上述依賴規則的特征值序列,filepath指向上述序列所確定的文件記錄在存儲服務器中的路徑。
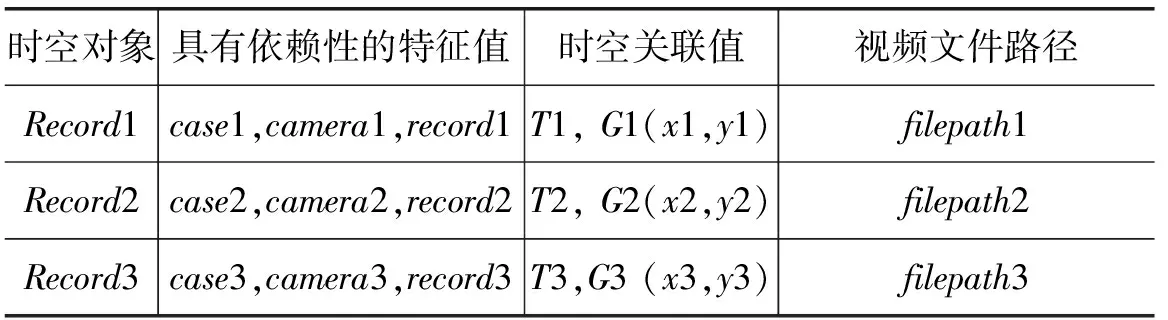
表1 監測視頻時空大數據Records的表結構
1.2.2 監測視頻時空大數據rowkey設計
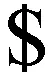
rowkey=T+Properties+Z-order值
(4)
這樣設計rowkey的好處在于:一方面,由于屬性特征具有相關依賴性,這樣安排rowkey很方便基于rowkey地去批量查詢某一時空特征下的連續記錄;另一方面,在HBase中,基于rowkey的查詢方式比過濾器的查詢方式簡單,并且指定起始位置的行掃描的IO操作效率比過濾器刪選要高效。同時Z-oder降維算法的高效壓縮機制使得其索引表能夠在保證其查詢性能的前提下大大降低數據所需的實際存儲空間。
1.3 基于HBase時空大數據列簇設計
在監測視頻Record的元信息基礎上進行整合,時間、空間特征整合為時空關聯特征。為時空關聯特征和屬性特征建立HBase列簇。為了進一步篩選特征值缺省下滿足查詢條件的rowkey,方便從時空關聯特征和屬性特征兩個維度數據處理,結合 HBase的過濾器機制,將屬性特征和時空關聯特征存儲到HBase表中并分別建立過濾列簇,用以解決在某特征值缺省情況下限定rowkey篩選的范圍。利用這種多重過濾機制加快時空數據的處理、增強查詢的靈活性。
1.3.1 時空關聯特征列簇設計
時空關聯數據模型將數據劃分為:矢量數據、時間數據、屬性數據以及拓撲數據,結合監測視頻數據應用場景涉及到的空間坐標數據、時間數據、業務數據(屬性數據)。我們利用HBase存儲模型將三類數據依次設計成時間數據列簇、空間矢量列簇。矢量空間點在GeoTool采用二維坐標存儲,在HBase中需將矢量空間點橫縱坐標解析成字符串類型進行存儲;時間數據采用14位時間占位符Time: yyyy-MM-dd hh:mm:進行存儲。空間數據和時間數據共同構成時空關聯列簇TGeo,TGeo列簇設計如表2所示。各列簇中的屬性名稱作為HBase的列限定符動態增加,使列簇模式可復用和擴展。
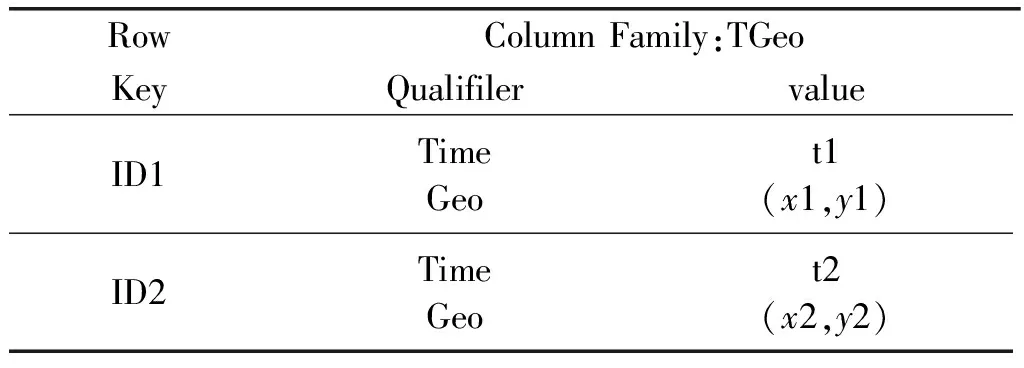
表2 TGeo列簇設計
屬性數據是建立在時空數據之上的一組監測視頻Record屬性特征集,存儲在Properties列簇中,存儲格式采用普通字符串,列屬性名稱為事件號、探頭號、記錄號,各占4位。例如,假設t1時刻在(x1,y1)處的監測站點記錄下一段監測視頻Record1,則視頻處理程序會通過監測視頻本體庫為Record1進行屬性標記,這些標記屬性有case1(事件號)、camera1(探頭號)、record1(記錄號),并且在記錄進行插入時,將文件所在的路徑filepath寫入到HBase表中。Properties列簇設計如表3所示。
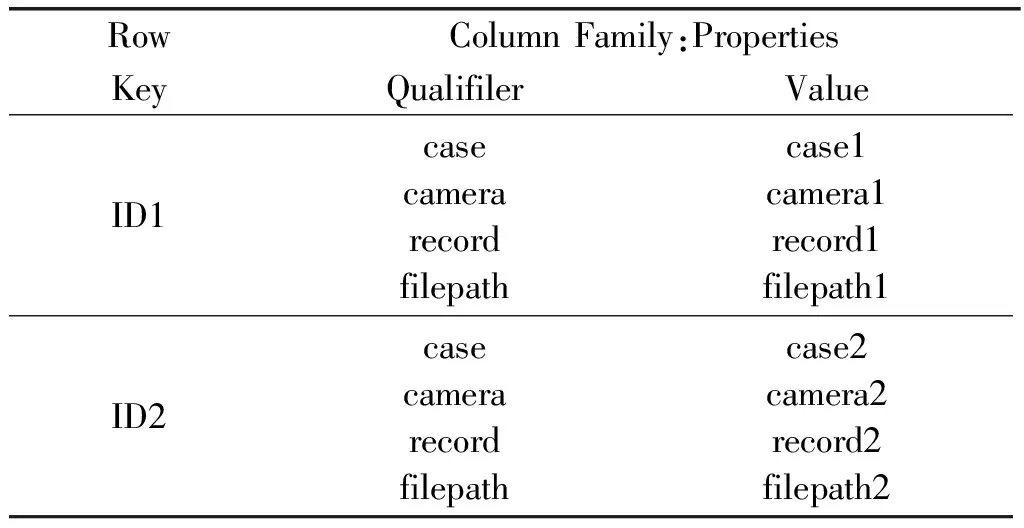
表3 Properties列簇設計
1.3.2 多重過濾鍵列簇設計
多重過濾機制的過濾列簇用來解決時空關鍵字查詢的,縮小候選鍵查找范圍, HBase單一的行健查詢規則無法過濾掉不滿足條件的結果集,例如,在片區A(我們這里假設片區A中包含的監測坐標點群為(1,1),(1,2),(1,3))中查找t時刻,(1,1)~(2,2)范圍內的所有記錄,如果采用HBase提供的基于行健的查詢接口scan,查詢過程分為兩步。首先,根據rowkey構成規則在rowkey中挑選出含縱坐標的行鍵,得到的(1,1),(1,2),(1,3)中,(1,3)縱坐標不在(1,1)~(2,2)范圍內,這個點不應出現在結果中,因此必須設計過濾鍵在HBase服務器段進行再次過濾。過濾列簇采用HBase的布隆過濾器[10](bloom filter)對查詢進行優化,列簇設計如表4所示。過濾列簇的Qualifiler(列限定符)包含:時空點橫縱坐標x+y構成的空間過濾鍵(記作G),和時間t構成的時空過濾鍵(記作T);事件號、探頭號、記錄號構成的屬性過濾鍵(記作P);Value存儲他們的值。
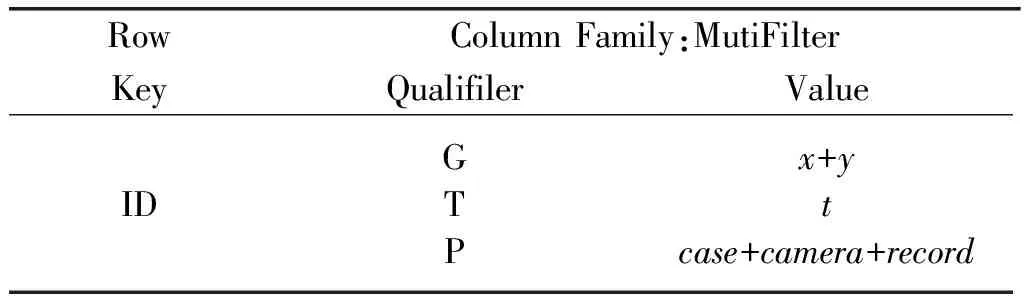
表4 MutiFilter過濾列簇設計
2 基于HBase的時空大數據聯合查詢優化策略
在建立上述基于HBase的監測視頻時空大數據的存儲基礎上,利用Rowkey值對海量的大數據進行時空關聯的查詢。查詢要求可分為單記錄查詢和多記錄查,由于HBase提供的行鍵查詢接口即可解決單記錄。這里我們主要對連續多記錄查詢接口進行算法設計,最終問題聚焦在:時空關聯的關鍵字查詢(標記為Q(Q.T,Q.G,Q.B),其中Q.T表示時間范圍關鍵字,Q.G表示空間范圍關鍵字,Q.B表示屬性關鍵字),找出時空范圍(Q.T,Q.S)上所有包含業務關鍵字Q.B的記錄。
為了解決這類查詢要求,本文提出了基于多重過濾鍵的Z曲線時空關聯查詢算法 ZRMF( Z-order Range with Multi Filter based Algorithm) ,對于給定的一個時空關聯查詢請求Q(Q.T,Q.G,Q.B),ZRMF算法主要分為三個步驟:
步驟一 計算出查詢空間范圍對應的 Z-order 值范圍 ZRange;
步驟二 根據Zrange以及計算出rowkey Range;
步驟三 調用 HBase的scan 接口掃描索引表 indexTable多重過濾列簇MutiFilter在 HBase 服務器端過濾掉所有不在Q.T范圍內的數據。
具體見算法1。
算法1 ZRMF時空關聯查詢算法
輸入: 時空關聯關鍵字查詢Q(Q.T,Q.G,Q.B),其中,Q.T由給出的時間范圍確定,Q.G由左下角頂點坐標 left Low和右上角頂點坐標right High確定,Q.B是業務特征進行字符串拼接組成的集合
輸出: 結果集列表RecordList
1. min Z←calculate Min Zorder(left Low )
2. max Z←calculate Max Zorder(right High)
3. Zrange←calculate Zorder Range(min Z,max Z)
4. for Ziin Zrange do
5. for Biin Q.B do
6. rowkeyRange←(Zi+Bi)右移14位
7. Scan scan←rowkeyRange,MutiFilter(T),
Properties:filepath
8. RecodSeti←indexTable.getScanner( scan)
教學過程最優化是把教學過程作為一個系統進行研究,將構成該系統的有機組成部分,即:教學過程中的人(教師和學生)、條件(教學物質條件、衛生條件、道德心理條件)、教學過程結構(教學目的和任務、教學內容、教學方法、教學組織形式、教學結果)及教學實施的基本環節當作整體進行研究[7]。
9. RecordList.add( RecordSeti)
10. end for
11. end for
ZRMF算法對于空間連續性好的情況(Q.G為連續可變范圍)有非常好的效果,這是因為,一方面相關依賴值固定的情況下采用行健(rowkey)掃描的方式進行數據查詢,復雜度為O(l),(其中l為region分組大小);另一方面,對于相關依賴特征值為取值范圍的情況,盡可能地利用正則表達式對查詢請求進行正則化,得到的正則查詢行間依然是以掃描rowkey的方式進行檢索,IO效率更高。但是當Q.G空間連續性不好,Zrang中無用的候選行健會更多,特別是當查詢空間范圍Q.G增大時,無效的Z-order對HBase通信量的占用越大,ZRMF算法效率降低。因此 我們在ZRMF算法基礎上提出了基于空間塊劃分的時空關聯查詢算法。該算法利用kd樹整個查詢空間范圍劃分為更小的空間塊,并在該劃分塊上建立索引范圍kdi,查詢的時候則將Zrange與kdi求交集,過濾掉無效的Z-order值,以此處理完每個劃分塊之后形成一個更精準的Zrange,后面的算法過程同ZRMF一樣。
具體見算法2。
算法2 kd-ZRMF時空關聯查詢算法
輸入: 時空關聯關鍵字查詢Q(Q.T,Q.G,Q.B),其中 Q.T由給出的時間范圍確定 ,Q.G由左下角頂點坐標left Low和右上角頂點坐標right High確定,Q.B是業務特征進行字符串拼接組成的集合
輸出: 結果集列表RecordList
2. max Z←calculateMaxZorder(right High)
3. Zrange←calculateZorder Range( minZ,max Z)
4. for kdiin kd-tree do
newZrangei←Zrange ∩kdi
newZrange.add (newZrangei)
5. end for
6. for Zi in newZRange do
7. for Biin Q.B do
8. rowkeyRange←(Zi + Bi)右移14位
9. Scan scan←rowkeyRange,MutiFilter(T),
Properties:filepath
10. RecodSeti←index Table.getScanner( scan)
11. RecordList.add( RecordSeti)
12. end for
13. end for
3 實驗分析與評估
3.1 實驗環境
本實驗采用真實云存儲系統,系統架構由兩部分組成,第一部分是搭建了12臺服務器作為Hadoop集群及其上的HBase集群,其中1個節點作為HMaster,其他11個節點作為RegionServer和ZooKeeper服務器。另一部分是安裝了thrift和自主研發的Geao-GIS系統。
3.2 數據導入
本文數據來源于Geao-GIS系統下武漢市視頻監測站點空間數據庫,它采用shapefile格式的空間數據模型將視頻監測點站標記成Symbol點值,橫縱坐標采用整型數據存儲。我們挑選其中Z值在0~500的symbol點,并將Symbol點的矢量空間數據以及各個Symbol的視頻數據元信息加載到HBase中,為方便實驗,分時段對數據進行加載,在加載過程中按照rowkey生成規則采用for循環方式對事件號,探頭號,記錄號進行連續生成。分別生成五張不同數據級別的HBase表,導入的數據量如表5所示。
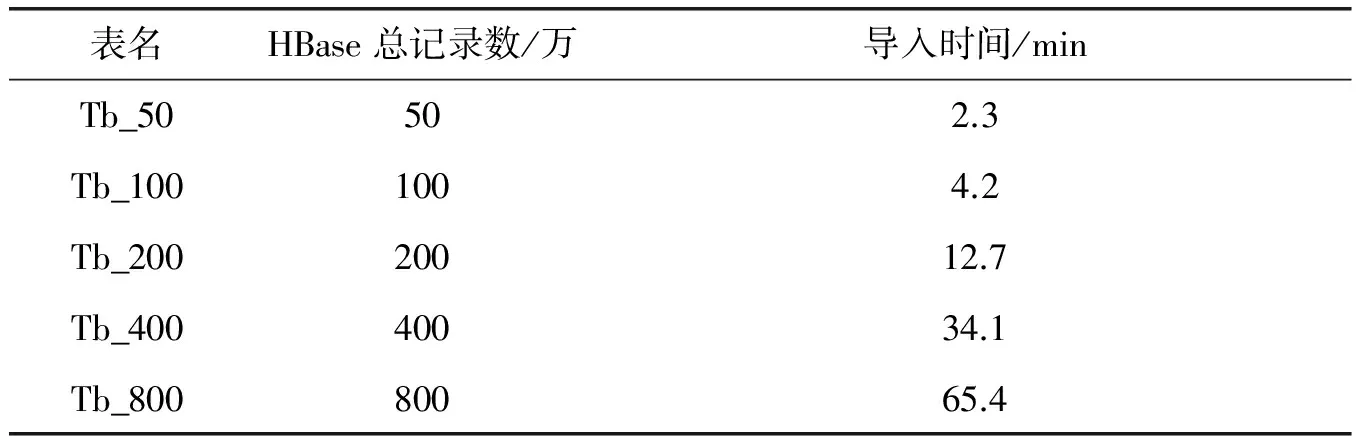
表5 數據導入情況
3.3 算法實驗與分析
在上述數據導入的基礎上,我們主要研究大規模數據量下基于HBase的時空大數據聯合查詢優化算法ZRMF的性能情況。本文將全表掃描的查詢標記為QBFT(Query Based On Full Table);將在Q.T和Q.G上構造索引的查詢標記為QBIT(Query Based On Index Table)。分別不同的數據量時對算法進行性能測試,并從屬性特征集、時空特征范圍兩個方面對算法的影響進行了實驗分析。
1) 數據量對算法的影響測試
實驗在50萬條、100萬條、200萬條、400萬條、800萬條進行類比,查詢條件Q.T:20150307100000,Q.G(1,4),Q.P(010100~010199),Q.T缺省,得到的查詢響應時間如圖1所示。
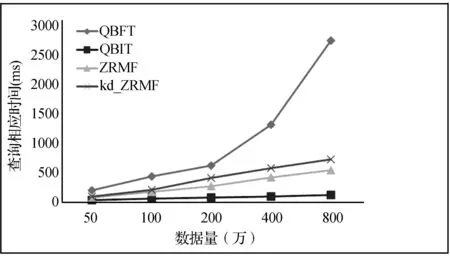
圖1 不同的數據量下的查詢響應時間
從圖1中我們分析得知,四類算法在數據量不大的時候都能表現較好的查詢效率,而伴隨著數據量的增長,全表掃描的查詢性能對數據量非常敏感,性能降低得嚴重;適當的索引使得QBIT充分利用HBase級聯索引表不斷收窄檢索空間,由于本實驗查詢的屬性特征值具有連續性,QBIT、ZRFM、kd_ZRMF均采用連續的rowkeyRange讀取空間連續的整塊數據作為cache,提高了查找效率。所不同的是 QBIT只需一次讀取,而ZRMF、kd_ZRMF讀取的次數直接取決于屬性特征集的大小,時間開銷稍大,但是數據量對性能的影響不大。
2) 屬性特征集合對算法的影響測試
本實驗為避免屬性特征連續的影響,采用離散屬性特征序列進行算法測試,查詢條件Q.T:20150307100000,Q.G:(1.1)~(4.4),Q.P:{100110,011001,101001,001100,001001}),查找實驗結果如圖2所示。
從圖2中可以看出,對于離散型屬性特征值的查找,QBIT基于連續rowkey查詢的優勢減弱,ZRFM則由于采用基于布隆過濾器的多重過濾機制,RowKey+ColFamily+Qualify的Scan去掉了不存在此Qualify的storefile,而且指明Qualify也能減少流量,因此即便屬性特征集增大,其性能仍然比較穩定。同時我們發現kd_ZRMF隨著屬性特征值集的增加查詢響應時間增加較快,且高于ZRMF。這是由于kd_ZRMF基于塊劃分的機制在保證候選間正確的情況下,其每個屬性特征值所包含的候選rowkey較多,增加了HBase的通信開銷。
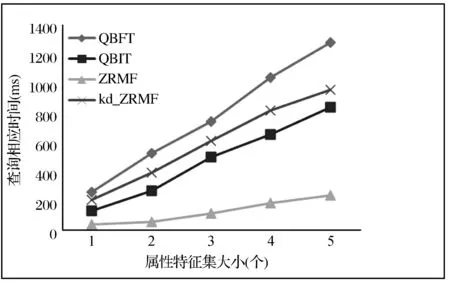
圖2 不同的屬性集下算法的查詢響應時間
3) 時空范圍對算法的影響測試
由于QBIT是建立在時空屬性上的索引查找,在時空值不確定情況下,無法采用前綴方式進行查詢,其查詢過程轉換為全表掃描,因此本部分實驗僅選取ZRMF、kd_ZRMF進行算法實驗。查詢條件Q.T:20150307100000~20150307110000,Q.P(010100~010199),空間范圍Q.G在各個ZRange段時算法的查詢響應時間。實驗結果如表6所示。
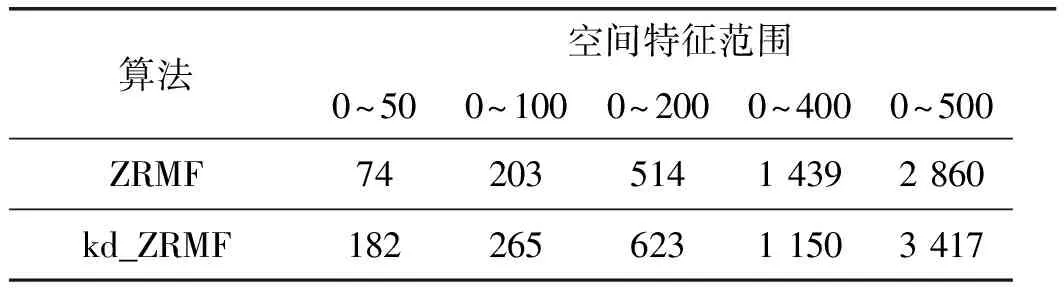
表6 ZRMF、kd_ZRMF在不同空間范圍的查詢響應時間
從表6中可以看出,ZRMF 和 kd-ZRMF 的查詢響應時間隨著查詢范圍的增大而有所增加,但仍處于可接受范圍內。當查詢空間范圍小于等于 200 時,ZRMF 具有較好的查詢性能; 而當查詢空間范圍超過 200 時,kd-ZRMF 表現出了比 ZRMF 更好的查詢性能,并且這種優勢隨著查詢空間范圍的增大表現得愈加明顯。
從以上三組實驗可以看出,通過合理設計表行鍵、過濾列簇以及查詢算法,將HBase 應用于時空大數據數據管理可以提高時空大數據的存儲效率。并且通過算法類比,相對于索引查詢方式,ZRMF和kd_ZRMF算法在靈活解決時空數據聯合聯合查詢請求的同時,算法性能更為穩定,且能夠很好地平衡存儲效率和查詢性能;而對于非時空特征的查詢,ZRMF和kd_ZRMF算法性能仍然不錯,但是受離散型屬性特征值的數目影響較大。
4 結 語
本文以時空大數據在視頻監測的應用作為研究背景,利用具有時空大數據特征的大數據的監測視頻作為數據源,巧妙地挖掘出其特征關聯關系并設計rowkey來構建候選查詢鍵。同時為提高查詢的準確性,利用HBase bloomfiter構造多重過濾鍵,并根據多種可能的查詢需求提出了兩種基于HBase的時空大數據查詢算法。最后通過實驗證明了ZRMF、kd_ZRNF算法在時空聯合查詢方面算法性能非常好,并且能滿足各類查詢請求。然而算法在處理屬性特征的查詢請求時性能尚有提升的空間,今后的工作中我們會對用戶的查詢請求進行分類,對不同的查詢分類動態地調整行健的位置,靈活運用索引表進行輔助查詢,用以提高時空關聯查詢的效率。
[1] 丁琛.基于HBase的空間數據分布式存儲和并行查詢算法研究[D].南京師范大學,2014.
[2] 樊新華. 關系數據庫的查詢優化技術[J]. 計算機與數字工程, 2009, 37(12):188-192.
[3] 林子雨, 賴永炫, 林琛,等. 云數據庫研究[J]. 軟件學報, 2012, 34(5):1148-1166.
[4] 汪璐,程耀東,陳剛等.海量存儲系統元數據服務器的設計及性能優化[J].計算機工程,2012,38(2):1-3.
[5] Sun Z, Shen J, Yong J. DeDu: Building a Deduplication Storage System over Cloud Computing[C]// Proc. of the 2011 15th International Conference on Computer Supported Cooperative Work in Design: IEEE 2011,348-355.
[6] Vashishtha H, Stroulia E. Enhancing query support in HBase Via An Extended Coprocessors Framework[C]// European Conference on Towards A Service-Based Internet. Springer-Verlag, 2011:75-87.
[7] Qin X P, Wang H J, Du X Y, et al. Big Data Analysis—Competition and Symbiosis of RDBMS and MapReduce[J]. Journal of Software, 2012, 23(1):32-45.
[8] Xu J W, Liang J L.Research on a Distributed Storage Application with HBase[J].Advanced Materials Research,2013,631:1265-1269.
[9] 張榆, 馬友忠, 孟小峰. 一種基于HBase的高效空間關鍵字查詢策略[J]. 小型微型計算機系統, 2012, 33(10):2141-2146.
[10] Dimiduk N, Khurana A. HBase 實戰[M]. 北京:人民郵電出版社,2013.
OPTIMIZATION OF SPATIAL AND TEMPORAL BIG DATA ASSOCIATION QUERY BASED ON HBASE
Xu Aiping1Wang Bo1Zhang Xu2*
1(SchoolofComputer,WuhanUniversity,Wuhan430072,Hubei,China)2(EnvironmentalMonitoringCenteofHubeiProvince,Wuhan430079,Hubei,China)
With the rapid development of digital acquisition and storage technology, video surveillance system has been rapidly popularized, which brings a lot of monitoring video data. Different from the text data, the monitoring data has the characteristics of time and space, and how to carry out efficient query under the large-scale and dynamic growth of data becomes a concern of many spatial and temporal data applications. To meet the requirement of space-time joint query for efficient monitoring of large video data in cloud storage architecture, in this paper, we make full use of the relationship between the temporal and spatial eigenvalues and the attribute eigenvalues in the application and the excellent performance of the HBase database in the massive query, propose HBase Bloomfilter’s multi-filtering mechanism of large data in space and time, and make use of the dependency and association between the eigenvalues of video files to arrange rowkey index keys in an innovative manner. On this basis, two kinds of spatiotemporal correlation query algorithms are designed. Finally, the feasibility, flexibility and efficiency of the algorithm are proved by experiments. It is useful for other large data association queries.
Cloud storage Big data Associated query Spatial and temporal characteristics
2016-04-16。國家水體污染控制與治理科技重大專項(2013ZX07503-001);湖北省重大科技創新計劃項目(2013AAA020)。徐愛萍,教授,主研領域:云存儲,空間分析,自然語言理解。王波,碩士生。張煦,工程師。
TP311
A
10.3969/j.issn.1000-386x.2017.06.008
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:30
當代陜西(2021年17期)2021-11-06 03:21:36
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年15期)2019-09-02 01:52:00
當代陜西(2019年10期)2019-06-03 10:12:04
學苑創造·A版(2018年11期)2018-02-01 06:29:20
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
讀者(2017年5期)2017-02-15 18:04:18
