基于異常檢測(cè)的尿沉渣圖像分割
2017-07-10 10:27:26嵇啟春
計(jì)算機(jī)應(yīng)用與軟件 2017年6期
李 悅 嵇啟春
(西安建筑科技大學(xué) 陜西 西安 727000)
基于異常檢測(cè)的尿沉渣圖像分割
李 悅*嵇啟春
(西安建筑科技大學(xué) 陜西 西安 727000)
在尿沉渣圖像中,由于其樣本特性,使得在細(xì)胞圖像采集時(shí)會(huì)有大量的雜質(zhì)。這些雜質(zhì)形狀不規(guī)則,顏色不單一,用傳統(tǒng)的圖像分割算法難以去除。針對(duì)這個(gè)問題,提出一種基于異常檢測(cè)的圖像分割算法。該方法用形態(tài)學(xué)的方法對(duì)二值圖像進(jìn)行輪廓提取,根據(jù)其輪廓進(jìn)行特征提取并且進(jìn)行標(biāo)記,然后用提取的輪廓特征以及標(biāo)記構(gòu)建異常檢測(cè)模型。最終根據(jù)該模型對(duì)圖象進(jìn)行分割,并且定量地對(duì)該模型進(jìn)行評(píng)價(jià)。實(shí)驗(yàn)結(jié)果表明,基于異常檢測(cè)模型的尿沉渣檢測(cè)方法能夠以較高精度將雜質(zhì)從細(xì)胞圖像中分離。
尿沉渣圖像 形態(tài)學(xué) 異常檢測(cè)
0 引 言
在醫(yī)學(xué)細(xì)胞圖像處理研究中,細(xì)胞的識(shí)別和分割是最重要也是最困難的,其中,細(xì)胞的分割將圖像分割為前景和背景,是把圖像中感興趣的部分提取出來的過程,它是細(xì)胞識(shí)別的前提。在尿沉渣圖像中,我們需要將紅白細(xì)胞從圖像中分割出來,但是如圖1所示,在尿沉渣的拍攝過程中,由于尿沉渣本身易受污染,使得圖片有很多未知的不規(guī)則雜質(zhì),這些雜質(zhì)干擾了尿沉渣的圖像分割,進(jìn)而影響到了細(xì)胞的準(zhǔn)確識(shí)別,所以這是尿沉渣圖像分割需要首要解決的問題。

圖1 尿沉渣圖片
由于尿沉渣圖像中的雜質(zhì)沒有固定的模式,所以尿沉渣的分割比較困難。在細(xì)胞圖像分割中常用的幾種方法中,謝鳳英等[1-2]用分水嶺算法分割免疫細(xì)胞圖像,該算法雖然分割精度較高,并且比較簡(jiǎn)單,但是其需要手動(dòng)選取種子點(diǎn),并且對(duì)微弱邊緣會(huì)產(chǎn)生響應(yīng),以至于對(duì)雜質(zhì)也會(huì)產(chǎn)生響應(yīng)。印勇等[3]用改進(jìn)的canny算子分割尿沉渣圖像,該算法能夠自適應(yīng)地選取canny算子中所需要的雙閾值,并且能夠產(chǎn)生連續(xù)性和閉合性更好的邊緣,但是該算法沒有辦法去除面積較大的、形狀不規(guī)則的雜質(zhì),所以當(dāng)圖像中有大面積不規(guī)則雜質(zhì)時(shí),該算法無(wú)法達(dá)到較好的分割效果。程培英等[4]將OSTU算法用于圖像分割,該算法是基于最大化類間方差法[5],能夠?qū)D像進(jìn)行快速的分割。當(dāng)圖像的灰度直方圖是雙峰結(jié)構(gòu)時(shí),該算法能夠很好地將目標(biāo)從背景中快速分割出來,但是當(dāng)背景較為復(fù)雜,目標(biāo)和背景的灰度有交叉的時(shí)候,該算法則無(wú)法很好的工作,會(huì)將大量的雜質(zhì)當(dāng)做目標(biāo)分割出來。
針對(duì)上述分割算法的不足,本文結(jié)合尿沉渣圖像的特點(diǎn),提出了一種基于異常檢測(cè)的圖像分割算法。該算法使用形態(tài)學(xué)算法提取二值圖像的輪廓,計(jì)算樣本的輪廓特征并對(duì)樣本進(jìn)行標(biāo)記,接著對(duì)標(biāo)記為紅白細(xì)胞的部分樣本進(jìn)行訓(xùn)練和建模,最后用沒有進(jìn)行訓(xùn)練的細(xì)胞和雜質(zhì)樣本進(jìn)行檢驗(yàn),以檢驗(yàn)的準(zhǔn)確率評(píng)價(jià)模型的優(yōu)劣。
1 基于數(shù)學(xué)形態(tài)學(xué)的輪廓提取
1.1 數(shù)學(xué)形態(tài)學(xué)
數(shù)學(xué)形態(tài)學(xué)是建立在嚴(yán)格數(shù)學(xué)理論基礎(chǔ)上的學(xué)科,其算法已經(jīng)成為許多圖像處理和計(jì)算機(jī)視覺技術(shù)中的理論基礎(chǔ),被廣泛應(yīng)用于輪廓的提取中[6]。數(shù)學(xué)形態(tài)學(xué)是一種非線性濾波方法,其中,二值數(shù)學(xué)形態(tài)學(xué)變換是一種針對(duì)集合的處理過程, 基本運(yùn)算包括腐蝕、膨脹、開運(yùn)算和閉運(yùn)算,這些運(yùn)算的實(shí)質(zhì)是表達(dá)物體或形狀的集合與結(jié)構(gòu)元素間的相互作用,這里結(jié)構(gòu)元素的形狀將決定所提取信號(hào)的形狀信息。其中圖像中的每一點(diǎn)x的腐蝕運(yùn)算定義為:
X=E?B={x:B(x)?E}
(1)
膨脹運(yùn)算定義為:
X=E⊕B={x:B(x)∩E≠O}
(2)
式中B(x)表示結(jié)構(gòu)元素,E代表二值圖像。腐蝕的結(jié)果是將結(jié)構(gòu)元素B平移后使其完全包含在E中的點(diǎn)的集合。膨脹的結(jié)果是平移B使其與E的交集為非空的集合。除了腐蝕運(yùn)算和膨脹運(yùn)算,形態(tài)學(xué)濾波還包含開運(yùn)算與閉運(yùn)算。開運(yùn)算定義為對(duì)圖像先使用腐蝕,再進(jìn)行膨脹,閉運(yùn)算定義為先對(duì)圖像進(jìn)行膨脹,再進(jìn)行腐蝕。開運(yùn)算可以去除圖像中的細(xì)小雜質(zhì),閉運(yùn)算可以填充圖像中的小洞。
1.2 基于形態(tài)學(xué)的輪廓提取
基于形態(tài)學(xué)的輪廓提取是基于形態(tài)學(xué)的方法提取輪廓,提取流程如圖2所示。

圖2 基于形態(tài)學(xué)的輪廓提取流程
首先對(duì)圖像進(jìn)行高斯濾波平滑圖像,然后對(duì)平滑后的圖像進(jìn)行二值化,OSTU算法能夠根據(jù)最大化類間方差的方法找到進(jìn)行二值化的閾值,但是由于細(xì)胞圖像的灰度直方圖并不為雙峰的,所以二值化后會(huì)產(chǎn)生雜質(zhì)以及孔洞,需要用形態(tài)學(xué)濾波去除二值圖像中的部分細(xì)小雜質(zhì)和孔洞。接下來再使用形態(tài)學(xué)方法對(duì)圖像進(jìn)行輪廓提取,本文先使用3×3的結(jié)構(gòu)元素S對(duì)二值圖像A進(jìn)行腐蝕得到被腐蝕的圖像B,然后用原始邊緣圖像減去被腐蝕后的圖像從而得到輪廓圖像H,公式表示為:
H=A-B=A-A?B
(3)
使用二值圖像腐蝕算法提取的醫(yī)學(xué)細(xì)胞圖像的邊緣輪廓有單像素寬的特點(diǎn),克服了傳統(tǒng)輪廓提取算法邊緣粗壯的特點(diǎn),而且方便了輪廓跟蹤。在對(duì)輪廓進(jìn)行跟蹤時(shí),我們按照從下到上,從右到左的順序依次掃描圖片,當(dāng)掃描到一個(gè)未標(biāo)記的目標(biāo)點(diǎn)時(shí),將其標(biāo)記為起點(diǎn),然后按照8鄰接的方式依次掃描被標(biāo)記點(diǎn)的右、右上、上、左上、左、左下、下、右下8個(gè)順序(如圖3所示),找到下一個(gè)屬于輪廓的點(diǎn)并進(jìn)行標(biāo)記,然后根據(jù)新標(biāo)記的輪廓點(diǎn)繼續(xù)尋找下面的點(diǎn)進(jìn)行標(biāo)記,直到搜尋到原點(diǎn)或者沒有滿足條件的點(diǎn)為止。其過程如圖4所示,將最下面的一個(gè)點(diǎn)當(dāng)做起始點(diǎn),按照逆時(shí)針的方向進(jìn)行標(biāo)記。

圖3 8鏈碼方式 圖4 輪廓提取過程
1.3 輪廓特征的提取
輪廓特征主要有面積、周長(zhǎng)、似圓性以及對(duì)比度。根據(jù)這些特征,結(jié)合尿沉渣圖像中紅細(xì)胞,白細(xì)胞等的特點(diǎn),我們可以過濾掉大部分的雜質(zhì),以得到一個(gè)較好的分割效果。其中面積的定義為輪廓域內(nèi)的像素總和:
(4)
周長(zhǎng)定義為輪廓邊界的長(zhǎng)度:
(5)
似圓性定義為:
(6)
對(duì)比度定義為:
(7)
式中,S表示被度量的輪廓域,f(x,y)表示點(diǎn)(x,y)上的像素值,Ne表示鏈碼為偶數(shù)的數(shù)量,No表示鏈碼為奇數(shù)時(shí)的數(shù)量,c(x,y)為點(diǎn)(x,y)的4鄰域。當(dāng)似圓性Bs越接近為1時(shí),表示該輪廓越接近為圓。當(dāng)對(duì)比度Cs越大時(shí),說明輪廓內(nèi)像素灰度變化越大,灰度越不均勻。
2 基于輪廓特征的異常檢測(cè)模型
根據(jù)已經(jīng)采集好的特征,我們首先要對(duì)特征進(jìn)行轉(zhuǎn)換,消除特征之間的相關(guān)性,接下來使用轉(zhuǎn)換后的特征作為異常檢測(cè)算法的輸入,通過異常檢測(cè)模型,對(duì)雜質(zhì)進(jìn)行篩選,該流程如圖5所示。

圖5 基于輪廓特征的異常檢測(cè)算法流程
其中異常檢測(cè)方法使用使用基于密度估計(jì)構(gòu)建模型的方法,在2.1節(jié)中進(jìn)行介紹,特征轉(zhuǎn)換使用PCA算法,在2.2節(jié)中進(jìn)行介紹。
2.1 異常檢測(cè)模型算法簡(jiǎn)介
在疾病檢測(cè)、細(xì)胞分割等領(lǐng)域,一般只有目標(biāo)物(如細(xì)胞)有相對(duì)固定的模式,而對(duì)于異常(如噪聲,雜質(zhì)等)往往呈現(xiàn)出很大的隨機(jī)性,所以在分類時(shí),我們只能通過對(duì)目標(biāo)物特征的學(xué)習(xí)并建立模型來進(jìn)行異常檢測(cè)[7-8]。
因?yàn)楫惓z測(cè)中異常類的數(shù)據(jù)常常缺乏,所以不能直接使用有監(jiān)督的方法來進(jìn)行學(xué)習(xí)分類,只能夠通過對(duì)已有正常類的數(shù)據(jù)進(jìn)行建模,從而歸為無(wú)監(jiān)督學(xué)習(xí)的范疇。無(wú)監(jiān)督的學(xué)習(xí)也可以分為基于密度估計(jì)、基于重構(gòu)和基于支撐等幾類,本文主要使用基于密度估計(jì)構(gòu)建異常檢測(cè)模型,所以主要對(duì)基于密度估計(jì)構(gòu)建異常檢測(cè)模型做介紹。
在基于密度估計(jì)構(gòu)建的異常檢測(cè)模型中,我們假設(shè)目標(biāo)類服從多元高斯模型,即:
(8)
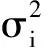
2.2 基于PCA的輪廓特征選擇
PCA(即主成分分析)是一個(gè)可以對(duì)特征進(jìn)行降維,用更少的特征代替原有特征的算法,其可以讓數(shù)據(jù)在損失最少信息的情況下使新特征之間互不線性相關(guān)[9-10]。本文對(duì)采集好的輪廓特征進(jìn)行降維,以得到新的線性無(wú)關(guān)的特征,其降維過程分為以下幾步:
步驟1 特征中心化,即對(duì)每一維的特征都做歸一化,其歸一化方法如式(9)所示:
(9)
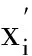
步驟2 將歸一化的數(shù)據(jù)組合成一個(gè)矩陣A,其每一行為一個(gè)樣本,求矩陣A的協(xié)方差矩陣B,由于A矩陣已經(jīng)進(jìn)行歸一化,所以協(xié)方差矩陣B的計(jì)算公式如下:
(10)
矩陣B為對(duì)稱矩陣,ai、bi表示不同的特征,m為樣本數(shù)。矩陣B對(duì)角線上的元素為對(duì)應(yīng)特征的方差,非對(duì)角線上的元素為對(duì)象兩個(gè)特征之間的協(xié)方差,當(dāng)其數(shù)值為正數(shù)時(shí),說明兩個(gè)特征之間為正相關(guān),為負(fù)值時(shí)說明兩個(gè)特征之間為負(fù)相關(guān),當(dāng)為0時(shí),說明兩個(gè)向量之間不相關(guān)。
步驟3 協(xié)方差矩陣對(duì)角化,由步驟2可以得出,如果協(xié)方差矩陣的非對(duì)角線上的元素為0,則說明兩個(gè)特征之間是線性無(wú)關(guān)的,并且由于協(xié)方差矩陣B為對(duì)稱矩陣,其在線性代數(shù)上,其具有以下非常好的性質(zhì):
定理1 實(shí)對(duì)稱矩陣不同特征值對(duì)應(yīng)的特征向量必然正交。
定理2 若實(shí)對(duì)稱矩陣的某個(gè)特征值是r重的話,則必然存在r個(gè)線性無(wú)關(guān)的特征向量對(duì)應(yīng)于該特征值,并可以將這r個(gè)特征向量正交化。
所以,根據(jù)以上性質(zhì),一個(gè)n維的實(shí)對(duì)稱矩陣一定可以找到n個(gè)正交的特征向量所組成的矩陣Q,并對(duì)應(yīng)著n個(gè)特征值,假設(shè)由n個(gè)特征值組成的矩陣為Λ,它們具有以下關(guān)系:
(11)
λi越大則說明其所對(duì)應(yīng)的特征i越重要,將其對(duì)應(yīng)的特征向量與樣本特征做乘積,則可以將樣本特征轉(zhuǎn)換為新的特征,并且我們可以根據(jù)式(12)計(jì)算新特征信息量占原特征信息量的比例pi,pi越大則說明該特征包含的信息量與原有特征相差不大。
(12)
其中n為特征數(shù)目,最后我們可以根據(jù)P的大小以及期望降低的維數(shù)對(duì)特征進(jìn)行選擇。
使用MATLAB對(duì)該算法進(jìn)行實(shí)現(xiàn)的方法如下。
input=mapminmax(input_train);
%對(duì)訓(xùn)練數(shù)據(jù)按照式(9)的方式進(jìn)行歸一化
[V,D] = eig(input);
%計(jì)算歸一化后的數(shù)據(jù)input的特征值和特征向量,V是由特征向量構(gòu)成的矩陣,D是對(duì)角線矩陣,其對(duì)角線上的每一個(gè)值是對(duì)應(yīng)特征向量的特征值
最后,我們根據(jù)D中特征值的大小按照式(12)選取特征向量對(duì)輸入特征進(jìn)行轉(zhuǎn)換。
2.3 基于輪廓特征構(gòu)建異常檢測(cè)模型
異常檢測(cè)是機(jī)器學(xué)習(xí)中的一個(gè)概念,對(duì)于給定的一個(gè)數(shù)據(jù)集,對(duì)其概率分布建立一個(gè)模型并設(shè)立一個(gè)閾值,當(dāng)輸入一個(gè)新樣本,用建立好的模型對(duì)其進(jìn)行預(yù)測(cè)并與閾值進(jìn)行對(duì)比,若其預(yù)測(cè)值小于設(shè)定的閾值則認(rèn)為其是異常。該模型要求輸入特征服從高斯分布,并且特征之間是線性無(wú)關(guān)的。異常檢測(cè)模型的搭建為以下幾步[11-12]:
步驟1 選擇特征xi作為指示異常的特征,本文選擇對(duì)輪廓特征用PCA進(jìn)行特征提取后的特征;
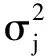
(13)
(14)
其中m表示樣本總數(shù),x(i)表示第i個(gè)特征;
步驟3 給定一個(gè)新樣本x,按照式(8),計(jì)算p(x),若p(x)<ζ,則該樣本為異常。ζ為常數(shù),可以根據(jù)交叉驗(yàn)證來選擇,其越大,則錯(cuò)識(shí)別率越高,其越小,則未識(shí)別率越高。
步驟4 模型由查準(zhǔn)率P和查全率R來進(jìn)行評(píng)判,查準(zhǔn)率P定義為:
(15)
衡量的是檢測(cè)結(jié)果為細(xì)胞的樣本中實(shí)際輸入也為細(xì)胞樣本所占的比例;查全率定義為:
(16)
衡量的是被識(shí)別為細(xì)胞的樣本占總細(xì)胞樣本的比例。
使用MATLAB計(jì)算p(x)的方法如下:
P=zeros(1,cell_number);%初始化P值
for i=1:cell_number
for j=1:4
P(i)=1/sqrt(2*pi*sigma(j))*exp(-(x(i,j)-u1)^2)
/(2*sigma(j)^2);
%按照式(8)計(jì)算每個(gè)樣本的p(x)
end
end
3 實(shí)驗(yàn)結(jié)果分析
本文使用NIKON顯微鏡在100倍物鏡下拍攝的尿沉渣圖像,圖像大小為640×480,選擇其中的50幅圖片中的細(xì)胞進(jìn)行訓(xùn)練,其中一共有697細(xì)胞,用10幅圖像中的細(xì)胞進(jìn)行測(cè)試,其中有128個(gè)細(xì)胞以及120個(gè)雜質(zhì)作為測(cè)試數(shù)據(jù)。在Matlab2012下搭建軟件開發(fā)環(huán)境,我們將細(xì)胞作為正例,雜質(zhì)作為反例,先對(duì)特征進(jìn)行提取,細(xì)胞特征的統(tǒng)計(jì)結(jié)果如表1所示。接下來對(duì)特征進(jìn)行選擇,按照2.2節(jié)所示的算法計(jì)算得細(xì)胞的四個(gè)特征根分別為:λ1=180.5,λ2=130.1,λ3=91.5,λ4=20.5。可以看出前3個(gè)特征根明顯大于第4個(gè),根據(jù)式(12)計(jì)算,前三個(gè)特征所包含的信息量占原有特征信息量的95.2%,所以我們只使用前3個(gè)特征構(gòu)建異常檢測(cè)模型,它們所對(duì)應(yīng)的特征向量矩陣為:

(17)
將所有樣本進(jìn)行特征轉(zhuǎn)換,即將QT與特征向量D相乘,可以得到新的特征,接下來,用轉(zhuǎn)換后的特征按照2.3節(jié)的方法構(gòu)建異常檢測(cè)模型,結(jié)果如表2所示。
D=[d1d2d3d4]
(18)
其中D代表每個(gè)樣本按照式(9)歸一化后的特征向量,d1表示歸一化后的面積特征,d2表示歸一化后的周長(zhǎng)特征,d3表示歸一化后的似圓性特征,d4表示歸一化后的對(duì)比度特征。

表1 細(xì)胞特征分布

表2 實(shí)驗(yàn)結(jié)果
由式(15)和式(16),得到模型查準(zhǔn)率P=93%,查全率R=93.7%,查準(zhǔn)率以及查全率都在90%以上,即可以滿足一般的監(jiān)測(cè)需要。
最后本文用其中的一幅測(cè)試圖片的分割結(jié)果與其他算法進(jìn)行對(duì)比,得到如下結(jié)果:
從圖6可以看出,在尿沉渣圖片中有大量形狀,顏色不同的雜質(zhì),當(dāng)我們使用分水嶺算法對(duì)圖像進(jìn)行分割時(shí)(圖7),其可以將細(xì)胞分割出來,但同時(shí)也將一些面積比較大,顏色與細(xì)胞圖像相近的雜質(zhì)分割出來了。當(dāng)使用OSTU進(jìn)行細(xì)胞圖像分割時(shí)(圖8),該算法找到能夠最大化類間方差的閾值,將此閾值作為分割點(diǎn)進(jìn)行分割,當(dāng)圖片中的雜質(zhì)與細(xì)胞顏色接近時(shí),該算法會(huì)將雜質(zhì)當(dāng)作細(xì)胞分割出來。并且由于細(xì)胞內(nèi)部顏色不均勻,在分割時(shí)會(huì)在細(xì)胞內(nèi)部產(chǎn)生孔洞,用OSTU算法做圖像二值化后,需要用形態(tài)學(xué)的方法消除孔洞和一些小的雜質(zhì),但是無(wú)法消除面積比較大的雜質(zhì)。從圖9可以看出,當(dāng)使用異常檢測(cè)模型去分割圖片時(shí),由于使用了更多的特征,所以可以很好地將不規(guī)則的雜質(zhì)輪廓剔除,并且可以定性地分析分割效果,人為選擇一些參數(shù),從而達(dá)到較好的分割效果。
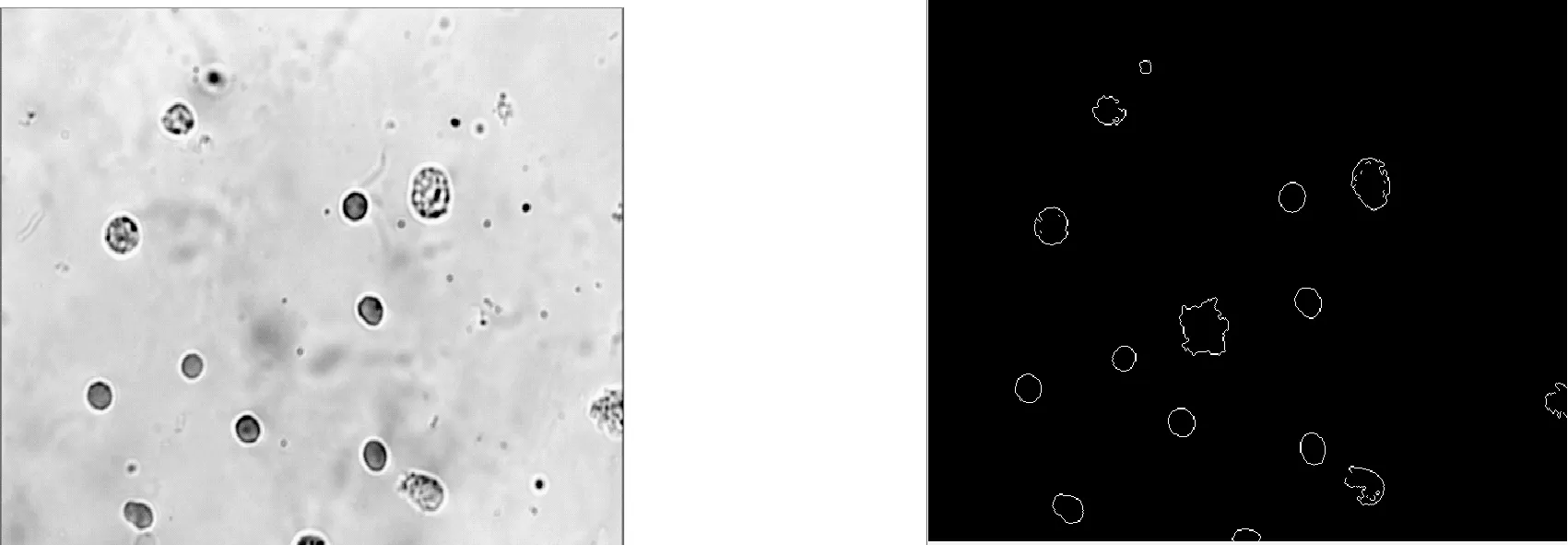
圖6 原始圖片 圖7 分水嶺算法

圖8 OSTU算法 圖9 異常檢測(cè)算法
4 結(jié) 語(yǔ)
尿沉渣檢測(cè)是醫(yī)院常規(guī)的檢測(cè)項(xiàng)目,傳統(tǒng)的檢測(cè)方法主要依靠醫(yī)務(wù)人員操作顯微鏡去人工識(shí)別尿沉渣中所含的成分,這種方法消耗大量的人力,所以需要開發(fā)自動(dòng)化程度更高的尿沉渣檢測(cè)儀,而尿沉渣的自動(dòng)檢驗(yàn)中尿沉渣的圖像分割是一個(gè)難題,怎樣能夠比較準(zhǔn)確地分割圖像,對(duì)尿沉渣自動(dòng)識(shí)別來說是關(guān)鍵的一步。本文通過結(jié)合傳統(tǒng)的OSTU分割算法,用輪廓特征構(gòu)建異常檢測(cè)模型,具有以下優(yōu)點(diǎn):(1)識(shí)別精度高,由于結(jié)合了多個(gè)特性,異常檢測(cè)模型能夠更好地將細(xì)胞從圖像中分割出來;(2)可以定量地分析結(jié)果,傳統(tǒng)的算法只能從最后的分割圖像中定性地判斷分割的好壞,但是異常檢測(cè)模型可以根據(jù)查準(zhǔn)率和查全率定量分析分割結(jié)果。基于這些特點(diǎn),該算法比較適合在尿沉渣自動(dòng)檢測(cè)儀上使用,有很大的應(yīng)用前景。
[1] 謝鳳英,姜志國(guó),周付根.基于數(shù)學(xué)形態(tài)學(xué)的免疫細(xì)胞圖象分割[J].中國(guó)圖象圖形學(xué)報(bào),2002,7(11):1119-1121.
[2]WangD.Unsupervisedvideosegmentationbasedonwatershedsandtemporaltracking[J].IEEETransactionsonCircuits&SystemsforVideoTechnology,1998,8(5):539-546.
[3] 印勇,劉平,劉丹平.采用改進(jìn)Canny算子分割尿沉渣圖像[J].計(jì)算機(jī)工程與應(yīng)用,2010,46(14):196-198.
[4] 程培英.一種新穎的OSTU圖像閾值分割方法[J].計(jì)算機(jī)應(yīng)用與軟件,2009,5(26):228-231.
[5]OTSUN.Athresholdselectionmethodfromgraylevelhistograms[J].IEEETransonSMC,1979,9(1):62-69.
[6] 鄒柏賢,林京壤.圖像輪廓提取方法研究[J].計(jì)算機(jī)工程與應(yīng)用,2008,44(25):161-163.
[7] 田杰,韓冬,胡秋霞.基于PCA和高斯混合模型的小麥病害彩色圖像分割[J].農(nóng)業(yè)機(jī)械學(xué)報(bào),2014,45(7):267-270.
[8] 郭偉,劉鑫焱,肖振久.基于邊緣前景的混合高斯模型目標(biāo)檢測(cè)[J].計(jì)算機(jī)工程與應(yīng)用,2015,51(18):209-213.
[9] 朱志潔,張宏偉,韓軍,等.基于PCA-BP神經(jīng)網(wǎng)絡(luò)的煤與瓦斯突出預(yù)測(cè)研究[J].中國(guó)安全科學(xué)學(xué)報(bào),2013,23(4):45-50.
[10] 何曉群.多元統(tǒng)計(jì)分析[M].北京:中國(guó)人民大學(xué)出版社,2012:135.
[11] 陳斌,陳松燦,潘志松,等.異常檢測(cè)綜述[J].山東大學(xué)學(xué)報(bào)(工學(xué)版),2009,12(39):12-21.
[12] 李百惠,楊庚.混合高斯模型的自適應(yīng)前景提取[J].中國(guó)圖象圖形學(xué)報(bào),2013,18(12):1620-1625.
URINARY SEDIMENT IMAGE SEGMENTATION BASED ON ANOMOLY DETECTION
Li Yue*Ji Qichun
(Xi’anUniversityofArchitectureandTechnology,Xi’an727000,Shaanxi,China)
In the urine sediment image, due to its sample characteristics, it makes a lot of impurities in the cell image acquisition. These impurities are irregular in shape, and the color is not single, using traditional image segmentation is difficult to remove. Aiming at this problem, an image segmentation algorithm based on anomaly detection is proposed. The algorithm uses the morphological method to extract the binary image contour, according to its contour feature extraction and marking, and an anomaly detection model is constructed using the extracted contour features and the markers. Finally, the image is segmented according to the model, and the model is evaluated quantitatively. The experimental results show that the urine sediment detection method based on the anomaly detection model can separate the impurity from the cell image with high accuracy.
Urinary sediment image Morphology Anomaly detection
2016-05-30。李悅,碩士生,主研領(lǐng)域:圖像處理,機(jī)器學(xué)習(xí)。嵇啟春,教授。
TP3
A
10.3969/j.issn.1000-386x.2017.06.038
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
