基于神經網絡與MapReduce的科技云數據清洗模型
2017-07-20 12:34:12楊朔楊威陶礫金鳳飛
計算機時代 2017年7期
楊朔+楊威+陶礫+金鳳飛
摘 要: 科技云服務平臺積累了大量科技數據,而數據質量問題會對大數據的應用產生致命影響,因此需要對存在質量問題的大數據進行清洗。文章提出了一種數據清洗模型,采用神經網絡,依據數據相關性原則實現高可擴展性的大數據清洗。使用該模型,能夠以計算機自動化數據修正的方式代替數據補錄與修正工作,有效地提升工作效率。
關鍵詞: 海量數據; 數據清洗; 神經網絡模型; 多任務優化; MapReduce
中圖分類號:TP399 文獻標志碼:A 文章編號:1006-8228(2017)07-06-03
Data cleaning model of the science and technology cloud based on
neural networks and MapReduce
Yang Shuo, Yang Wei, Tao Li, Jin Fengfei
(Zhejiang Topcheer Information Technology Co.,Ltd., Hangzhou, Zhejiang 310006, China)
Abstract: The science and technology cloud service platform has accumulated a large number of scientific and technological data, and the data quality problem will result in a fatal impact on the application of big data. Therefore, the massive data with quality problem need to be cleaned. In this paper, a data cleaning model is proposed, which according to the data correlation principle, uses neural networks to realize the big data cleaning with high scalability. Using this model, the repeated data refills and corrections can be replaced by computer automatic data correction, the work efficiency is effectively improved.
Key words: massive data; data cleaning; neural network model; multitask optimization; MapReduce
0 引言
科技創新云服務平臺的建設過程中,集成了大量科技數據,由于數據的來源廣泛,數據標準不同,數據錄入要求及錄入人的素質差異,導致大量的“臟”數據產生,從而導致了數據的可用性降低,影響整個數據分析的過程。
1 現狀分析
云平臺現有的數據分為幾大類,一是基礎數據,如機構信息、載體信息、人員信息等,該類信息有明確的來源,可通過業務認定系統以及工商、行政、公安、民政等第三方管理部門的接口進行驗證;二是業務數據,由業務相關人員完成填報,需要經過監管部門和專家校驗,出錯的可能性不大,有一定的時效性和制約性;三是其他輔助數據,如證明材料等等。因為云平臺的數據是面向某一主題的數據的集合,這些數據從多個業務系統中抽取而來,而且包含歷史數據,這樣就避免不了有的數據是錯誤的,有的數據相互之間有沖突。目前不符合要求的數據主要有不完整的、錯誤的、重復的數據三大類。
⑴ 不完整的數據主要是一些應該有的信息缺失,如儀器設備信息中儀器設備的英文名稱、產地國別、生產制造商、主要技術指標等等,這類數據在業務填報時往往不做要求,但在需要查找定位設備時卻有很重要的意義。
⑵ 錯誤的數據產生的原因主要是業務系統不夠健全,在接收輸入后沒有進行判斷或無法判斷正確值域的情況下直接寫入后臺數據庫造成的。
⑶ 重復的數據的產生原因主要因為數據入口不統一,同一個數據通過不同的入口被錄入系統,由于申報口徑并不統一,申報人不同,導致無法判斷是否為重復數據。
科技數據本身的嚴謹性很重要,其相關性也是數據分析的重要因素,為了能有效的利用科技數據,將其作為科技工作決策提供依據,基礎數據就需要盡量完整、嚴謹并且具有明晰的關系網,而這就需要進行數據清洗。數據清洗(Data cleaning)——對數據進行重新審查和校驗的過程,目的在于刪除重復信息、糾正存在的錯誤,并提供數據一致性。
傳統的清洗方式一般是要求數據來源方重新梳理補全并修正,但這樣工作量很大,特別是不同的管理入口負責人并不能確保哪一方的數據是正確的,僅僅針對系統中幾十萬條待處理的科研儀器設備,就有很大的難度,更何況是云平臺內TB級的海量數據,所以就需要有一種計算機自動化的方式來進行數據清洗工作。
2 模型設計
以科研設備為例,簡單的設備信息記錄的清洗通過對單一表的分析無法實現自動化數據清理,但是將設備的基本信息與申報單位信息、單位之間的關聯信息、設備維護人員信息、設備使用信息等大量相關內容進行組合,將單一的設備信息變成多維度的綜合信息后,就可以利用設備的關系網進行分析。因此本文設計通過神經網絡,利用云平臺中的海量數據進行分析,從而去除重復,修正錯誤并盡可能的補足缺失內容。
2.1 構建遺傳神經網絡
人工神經網絡(artificial neural network,ANN)是一種模擬人腦信息處理機制的網絡系統,它對輸入輸出樣本進行自動學習,將輸入輸出之間的映射規則自動抽取并分布存儲在網絡的連接中,能夠以任意的精度逼近復雜的非線性映射。BP(backpropagation)神經網絡是至今為止應用最為廣泛的神經網絡。雖然得到廣泛應用,BP神經網絡也存在不足,最明顯的兩點不足是收斂速度慢和易陷入局部極小值。遺傳算法(GA- Genetic Algorithm)是一種自適應的全局搜索算法,具有全局收斂、并行性和魯棒性等特點。
本文采用神經網絡和遺傳算法結合的方法,利用遺傳算法搜索神經網絡的權值的最優解,可以在一定程度上能克服傳統神經網絡易陷入局部極小值的缺點。基于以上分析,將遺傳神經網絡應用到計算整個記錄的相關性中。
2.1.1 參數設定
遺傳神經網絡各個參數設定如下。
⑴ 神經網絡的網絡結構
理論證明:三層BP神經網絡可以以任意精度逼近非線性函數腳。本文采用三層結構,輸入層、隱藏層和輸出層的節點數分別為以n,m,1;神經元的激勵函數一般采用Sigmoid函數,即
⑵ 適應度函數
在遺傳算法中,對適應度函數的要求是:單調,連續,非負和最大化。由于目標函數是神經網絡中的誤差平方和,且為求其最小值,因此適應度函數定義如下。
該式中,S訓練樣本總數,M輸出神經元的個數,E全局誤差,t期望輸出,y實際輸出。
⑶ 遺傳算子:選擇、交叉是遺傳算法的基本算子
選擇算子:采用輪盤賭選擇方式,以個體適應度值的高低來進行隨機選擇。保證了高適應度值的個體以大的概率遺傳到下一代中去。計算適應度為的個體對應的選擇概率為
交叉算子:從父代里隨機選擇兩個個體,隨機地、獨立地選擇相同數目的連接權值進行交換。選取的交換數目由自適應交換率決定。這使得適應值大的個體交換率小,適應值小的交換率大,從而保證優良個體的遺傳性。
變異算子:采用自適應變異率,將變異率同個體的適應度值聯系起來,使適應度大的個體變異率小,適應度小的個體變異率大。
2.1.2 網絡訓練過程
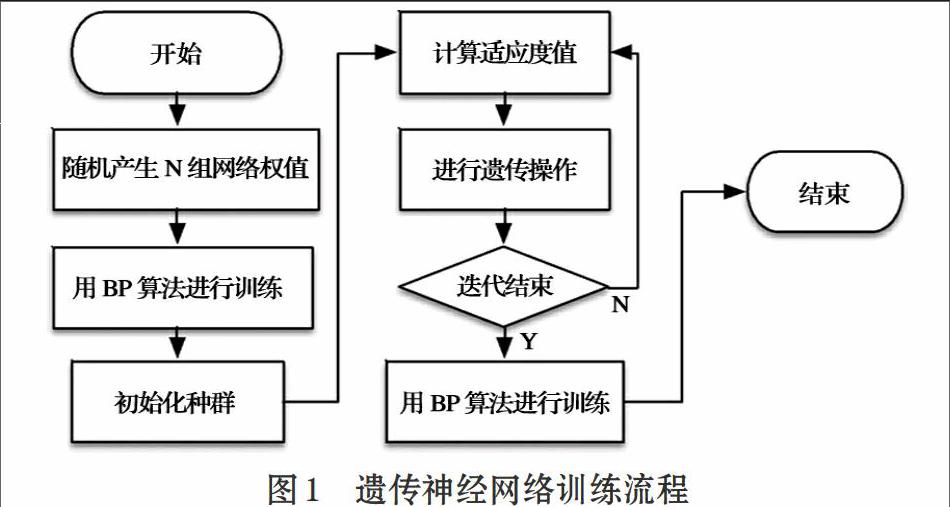
先用BP算法訓練一個預定結構的神經網絡,直到全局誤差不再減少為止,然后在此基礎上用遺傳算法進行若干代的優化,最后,再利用BP算法進行局部的調整。這種組合方法的基本思想是先用BP算法確定使誤差函數取最小值的權值組合,再利用遺傳算法去掉可能的局部極小值,最后再利用BP算法進行局部優化。
網絡訓練流程如圖1所示。
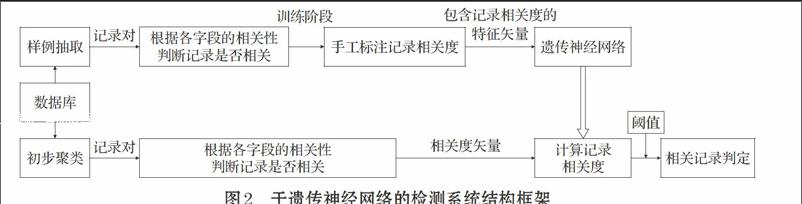
2.1.3 記錄相關性檢測框架
基于遺傳神經網絡的相似重復記錄檢測系統的框架如圖2所示,系統分為訓練階段和檢測階段。
在訓練階段,首先,從數據集中抽取若干對記錄作為訓練樣例,其次,使用上文中提出的記錄相關度計算方法根據兩個記錄的對應字段的相關性計算出的記錄的相關度,并手工標注記錄對的相關度;最后,將包含記錄相關度的特征矢量作為輸入,訓練遺傳神經網絡。
在檢測階段,為了降低時間復雜度,先對數據集進行初步聚類,初步聚類采用基于Canopies的方法進行,這種方法可以在數據集上快速產生若干個重疊的可能的相關記錄聚類;然后將同一聚類中的記錄兩兩組成記錄對,使用上文中提出的記錄相關度計算方法計算出記錄對的相關度,得到記錄對的相關度矢量,再利用訓練好的遺傳神經網絡計算記錄的相關度。最后選擇合適的閾值,確定相關的記錄。
2.2 數據修正
整理出相關數據后,可使用Hadoop 平臺對相關數據進行基于任務合并的并行大數據清洗。下面通過圖3和式1簡要介紹本模塊的實現。
[開始][參數估計][連接][修正][結束]
⑴
⑴ 參數估計模塊
整個修正系統是用貝葉斯分類的思想來計算出概率最大的記錄作為標準記錄。參數估計模塊的任務是利用式⑴計算出所有的概率,其中P(X)對所有取值為常數,所以只需要計算P(X|Ci)P(Ci)即可。在各個取值的先驗概率未知的情況下,不妨假設其是等概率的,因此只需計算P(X|Ci)即可。對于具有多屬性的數據集則采用式⑵來計算P(X|Ci)。
⑵
因此,整個參數估計模塊就是用來計算所有屬性的每個取值的概率。概率論中認為,當樣本空間足夠大時概率≈頻率,系統用統計不含缺失值的元組中各個屬性取值出現的頻率的方式來計算概率P(X|Ci)。
⑵ 連接模塊
系統在修正模塊會根據式⑵計算出擁有差異數據的元組在它的依賴屬性取值確定的所確定的各個待修正值的概率。但是由于MapReduce函數在map階段和reduce階段一次只能處理一條記錄,所以系統必須使依賴屬性取值和其條件概率關聯起來,這就是連接模塊存在的必要性和需要解決的問題。連接模塊的輸入數據為參數估計模塊的輸出數據和原待修正數據,輸出數據是將含修正數據的元組中依賴屬性取值與該取值條件概率相關聯的文件。
此模塊的輸入數據為原待修正數據和參數估計模塊的輸出,輸出數據為經過填充之后的數據。利用式⑵計算出每個Ci(待填充屬性可能的取值)對應的條件概率,選擇其中P(X|Ci)概率最大的Ci進行填充。
⑶ 修正模塊
修正模塊由一輪MapReduce實現,首先將連接模塊的輸出結果和原始輸入數據以偏移量為鍵值進行連接運算,map階段和連接模塊類似,reduce階段利用式⑵計算出每個Ci(待填充屬性可能的取值)對應的條件概率,選擇其中P(X|Ci)概率最大的Ci作為基準數據對其他同組數據進行修正。
3 總結
本文提出的數據清洗模型,可用于數據的相關性分析,使用MapReduce編程框架利用并行技術可對現有的科技云服務平臺數據進行清理,能夠在保留原始數據的前提下提高數據質量。目前該模型成功地對科研設備數據完成了清洗,用計算機自動化數據修正的方式代替了重復數據的補錄和修正工作,有效地提升了工作效率。下一步將把該模型擴展應用到云平臺的所有相關數據,完成數據清洗工作的同時,研究提高決策分析的準確程度。
參考文獻(References):
[1] 宋均,祝林.基于云計算的海量數據處理平臺設計與實現[J].
電訊技術,2012.52(4):566-570
[2] 馮秀芳,肖文炳.神經網絡的數據分類算法在物聯網中的應
用[J].計算機技術與發展,2012.22(8):245-248
[3] 楊東華,李寧寧,王宏志等.基于任務合并的并行大數據清洗
過程優化[J].計算機學報,2016.1:97-108
[4] 金連,王宏志,黃沈濱等.基于Map-Reduce的大數據缺失值
填充算法[J].計算機研究與發展,2013.50(z1):312-321
[5] 孟祥逢,魯漢榕,郭玲等.基于遺傳神經網絡的相似重復記錄
檢測方法[J].計算機工程與設計,2010.31(7):1550-1553
[6] 徐曉.基于RBF神經網絡的數據挖掘研究[J].計算機與網絡,
2014.19:67-69
[7] 李仲,劉明地,吉守祥等.基于枸杞紅外光譜人工神經網絡的
產地鑒別[J].光譜學與光譜分析,2016.36(3):720-723
