關于大數據框架中底層數據傳輸和網絡的分析與研究
2017-07-20 22:12:22趙嘉凌蔡文偉白偉華
物聯網技術 2017年7期
趙嘉凌++蔡文偉++白偉華
摘 要:文中從大數據應用環境下以數據處理、云存儲和容錯處理等方面與網絡進行協同工作的需求為基礎,分析了大數據應用下底層數據和網絡多方面的問題,為大數據框架中底層數據的傳輸和網絡優化提供了研究基礎。
關鍵詞:大數據;應用感知;云計算;軟件定義網絡;云存儲
中圖分類號:TP391 文獻標識碼:A 文章編號:2095-1302(2017)07-00-06
0 引 言
大數據(Big Data)[1]可被定義為具有4V特征的數據,即數據量及規模巨大且持續增長(Volume,一般指數據量達到PB以上級別);多源/多樣/多結構性,不同的數據源、數據類型(Variety,復雜文檔及多媒體,結構化、半結構化和非結構化數據);高速性,由于存在用戶數量龐大與實時性等因素,數據的生成、增長速率快,數據處理、分析的速度要求也高(Velocity);有價值性/精確性,數據量龐大,雖然價值密度低或個別數據無價值,但數據總體上是有價值的(Value/Veracity)。
大數據環境已成熟,云計算中的大數據分析/處理,大數據處理與網絡/硬件的協同工作,大數據的私有性及云平臺的能耗等方面對網絡及其資源調度的需求,使得大數據應用與物理網絡之間的交互尤顯重要,一方面讓網絡呈現出“應用感知網絡(Application Aware)”的特性,使之更好地服務于大數據應用;另一方面,如何讓大數據應用/用戶方便高效地訪問、調度網絡資源,減輕大數據應用在網絡訪問決策上的負擔是當前大數據應用研究中的熱點問題。
1 云計算環境下的虛擬化
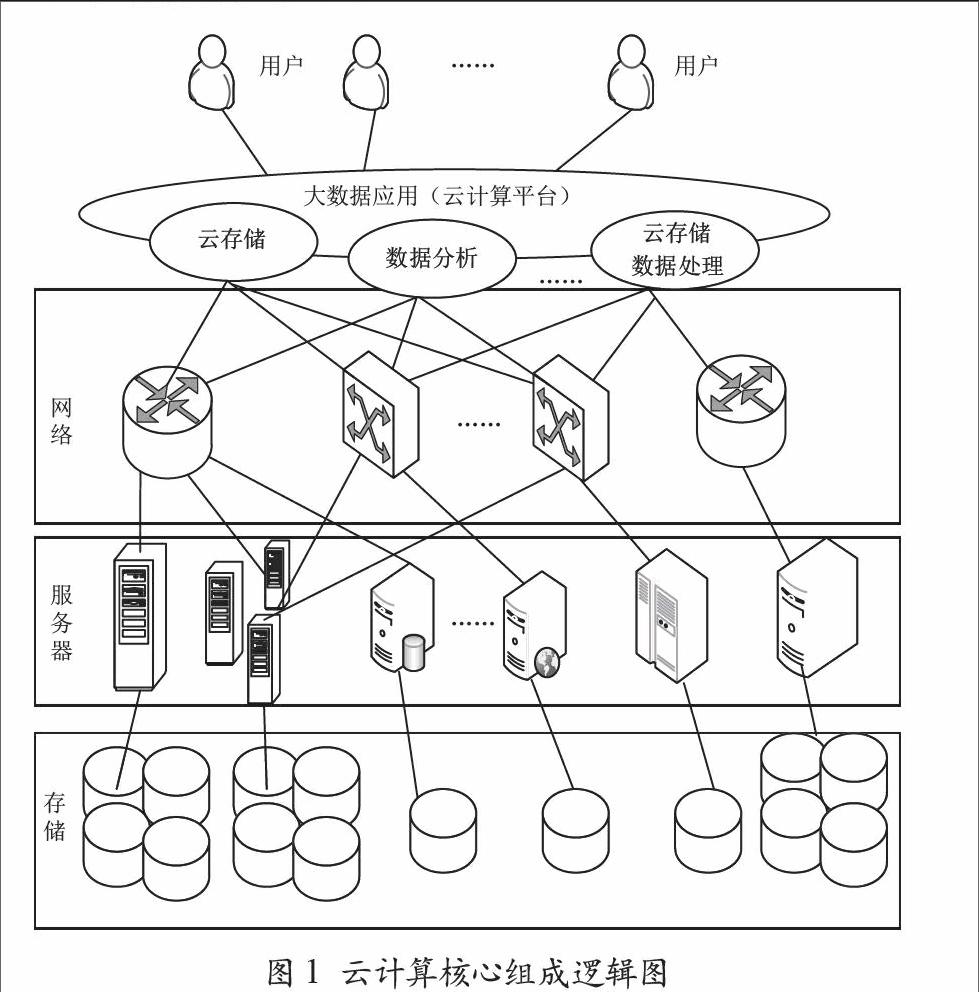
云計算[2]作為下一代計算模式,具有超大規模、高可擴展性、高可靠性、虛擬化、按需服務和價格低廉等特點,通過調用網絡中大量計算節點/服務器完成核心計算業務的任務,向用戶提供多層次的服務如基礎設施、平臺、存儲服務和軟件服務等。在大數據應用中,云計算的核心功能主要有數據存儲/管理(以數據存儲為主的存儲型云平臺)和數據分析/處理(以數據處理為主的計算型云平臺)。云計算提供商將大量計算節點與網絡設備連在一起,構建一個或若干個大規模(由具有萬甚至百萬級以上的計算節點所組成)數據中心,通過云平臺實時訪問、調用網絡、存儲、計算等資源為用戶服務。
云計算核心組成邏輯如圖1所示。云計算主要由服務器、存儲和網絡組成。為了使得云能夠更快、更方便地響應企業用戶的需求,服務器(層)和存儲(層)已經通過在實際基礎設施和云環境之間構建抽象層實現虛擬化,滿足配置、管理和使用服務器及存儲資源的要求。但最終還需要依靠網絡將資源連接集成以搭建一個完整的云環境。“大數據應用環境下與網絡的交互”以及“網絡與計算資源的交互”面臨以下三方面的要求:
(1)大數據應用層與網絡的交互:網絡結構相對穩定,但由于云環境的高擴展性以及節點規模的龐大,使得服務器和存儲這兩方面的資源會時常發生變化,如服務器/節點的添加——斷電、故障、恢復、新增節點等或存儲磁盤的故障、失效等。面對這些變化,上層大數據應用如何能更好、更快地獲取計算資源的變化?
圖1 云計算核心組成邏輯圖
(2)計算資源與網絡的交互:在大數據處理中,各計算資源的狀態與承擔的任務及負荷各不相同,為合理使用計算資源并計算資源負載平衡,網絡如何能更快更方便地告知上層大數據應用其所獲得的感知信息,并讓應用或用戶調整其調用計算資源的策略?
(3)計算資源按上層大數據應用的需求動態調整:上層應用復雜多變,面對應用/服務的變化,其所需的計算資源也不同,如何更快地調整、組織計算資源讓其適應并為上層應用提供服務?
為滿足上述需求,添加兩個具有擴展性的接口層形成大數據應用與計算資源(服務器/存儲)的中間層,這兩個接口層如下:
(1)大數據應用層與網絡層之間的交互接口層;
(2)網絡層與計算資源層(服務器/存儲)之間的交互接口層。
2 開放式協同平臺的中介——SDN
2011年10月,美國麻省理工大學Kate Greene教授提出了SDN (Software-Defined Networking,SDN)軟件定義網絡技術的概念[3]。所謂SDN,是指根據不同的使用需要,通過軟件來完成所有路由器與交換機的動態配置。并于2011年3月成立了以實現該概念為目的的網絡聯盟Open Network Foundation (ONF),提倡使用OpenFlow作為實現SDN的重要技術。
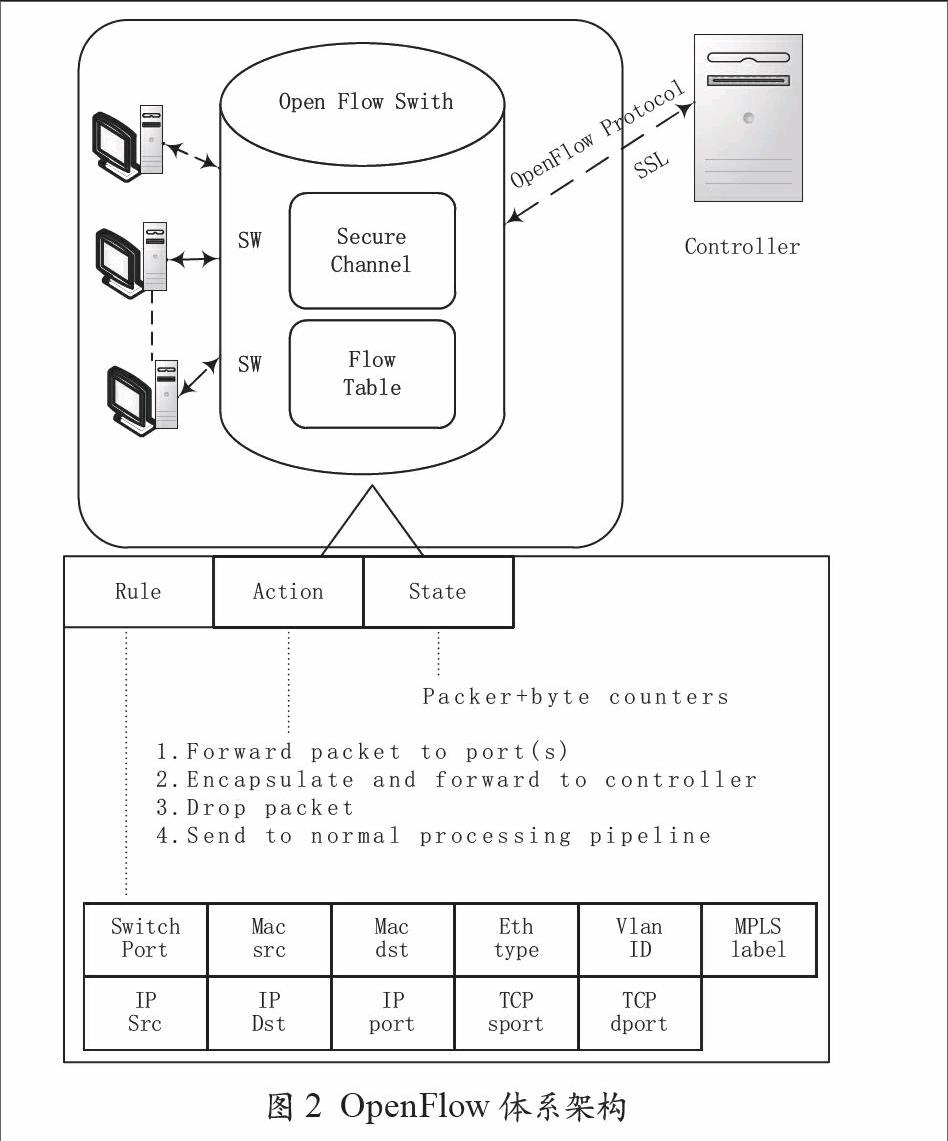
OpenFlow網絡的最大特點是將傳統的交換機路由控制部分與數據傳送部分分離,使得網絡設備可以專注于數據包轉發,從而極大地簡化了交換機的體系。OpenFlow網絡的主要構成元素包括支持OpenFlow協議的交換機(OpenFlow Switch),交換機控制器(OpenFlow Controller)以及用于交換機與控制器之間的控制協議(OpenFlow Protocol),其體系結構如圖2所示。
OpenFlow網絡可以處理包含在數據包中的各種信息,如MAC地址,IP地址,VLANID,MPLS標識,TCP端口等共15類,將這些信息與數據包的處理方法相結合,用于設計OpenFlow交換機的Flow Table。Flow Table即數據包的處理規則與處理方法對照表,如對含有特定VLANID信息的數據包執行數據包轉發、丟棄或多播等操作。
網絡管理人員通過對Flow Table進行詳細設計便可輕松實現對數據包交換路徑的精準控制。隨著云計算應用的不斷增多,頻繁的網絡重新配置不可避免。VLAN組網技術支持網絡管理員動態對網絡進行配置,是目前HDFS云存儲的主要組網技術。但VLAN組網技術面臨以下問題:
(1)當子網數量不斷增加時,采用VLAN對網絡進行管理將會使情況變得很復雜;
(2)只能利用VLANID進行組網,組網的靈活性不高,無法適應來自云計算的不同需求。
(3)除電信運營商級的VLAN技術外,數據中心級VLAN技術幾乎不能實現異地云存儲服務器之間的連接。異地云存儲系統互連的重要性在于通過將數據備份在不同的物理地點來消除單一故障(電力中斷,火災等)引起的服務中斷,這正是ONF聯盟將OpenFlow列為云計算網絡控制技術之一的主要原因。
圖2 OpenFlow體系架構
3 存在問題及分析
3.1 從大數據處理的角度分析
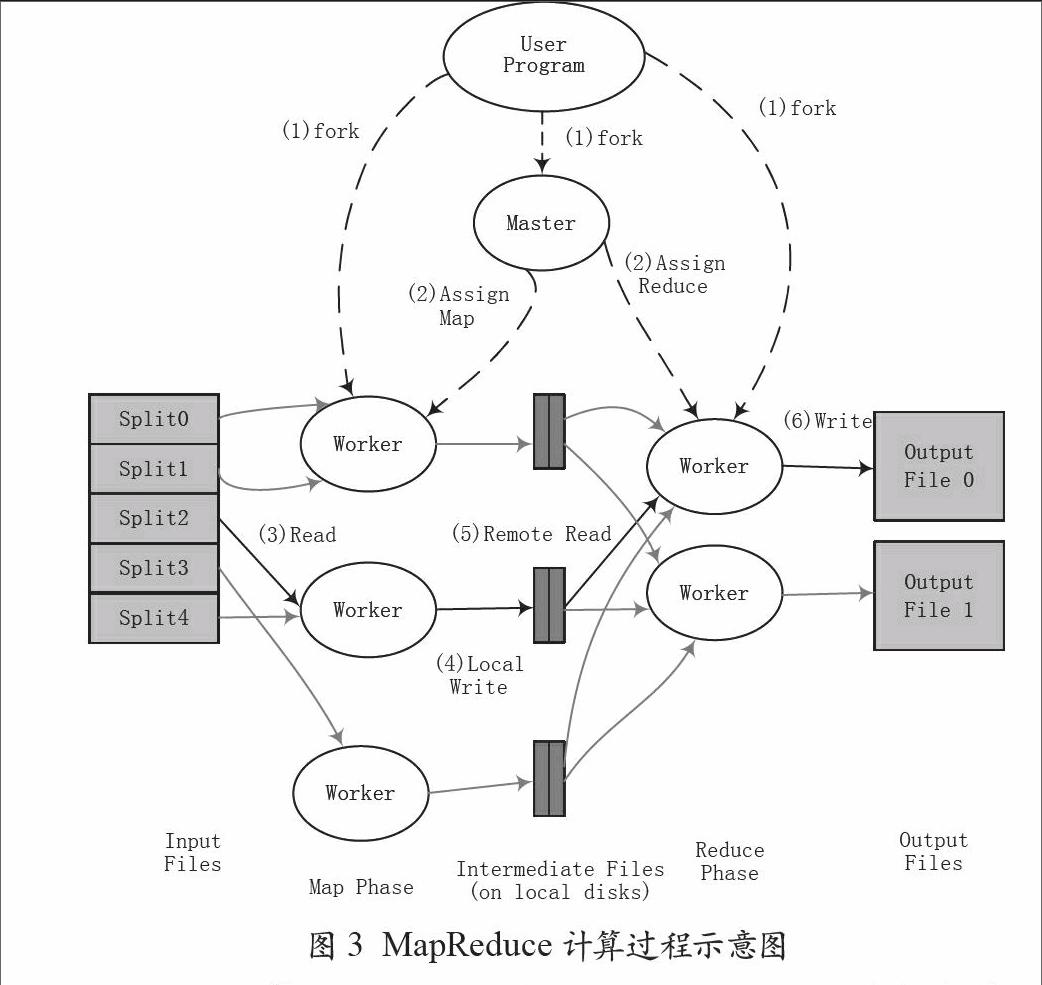
在大數據應用的環境下,大數據分析/處理的計算框架以MapReduce編程模型最具代表性。MapReduce計算模型在執行中,首先對數據源進行分塊,然后交給不同Map任務區來處理,執行Map函數,根據數據處理的規則對數據分類,并寫入本地磁盤;Map階段完成后,進入Reduce階段,執行Reduce函數,具有同樣Key值的中間結果從多個Map任務所在的節點被收集到一起(稱為Shuffle)進行合并處理(稱為Merge),輸出結果寫入本地磁盤。最終通過合并所有Reduce任務得到最終結果。
以MapReduce計算模型為基本核心原理,相似的計算模型有如下幾種:
Hadoop[4]:核心由HDFS和MapReduce組成,其中Hadoop-MapReduce是Google MapReduce的開源實現。
Dryad[5]:與MapReduce計算模型相似,其總體構建用來支持有向無環圖(Directed Acycline Graph,DAG)類型數據流的并行程序。Dryad的整體框架根據程序的要求完成調度工作,自動完成任務在各節點上的運行。
Hadoop++[6]:Hadoop++是通過自定義Hadoop框架中的split等函數來提升數據查詢和聯接性能,即通過Hadoop用戶自定義函數方式對Hadoop-MapReduce實現非入侵式優化。
CoHadoop[7]:Hadoop無法突破把相關數據定位到同一個node集合下的性能瓶頸。CoHadoop是對Hadoop的一個輕量級擴展,目的是允許應用層控制數據的存儲。應用層通過某種方式提示CoHadoop某些集合里的文件相關性較大,可能需要合并,之后CoHadoop嘗試轉移這些文件以提高數據讀取效率。MapReduce計算過程示意如圖3所示。
圖3 MapReduce計算過程示意圖
Haloop[8]:Haloop是一個Hadoop-MapReduce框架的修改版本,其目標是為了高效支持迭代,遞歸數據分析任務。遞歸的連接可能在Map端,也可能在Reduce端。Haloop的基本思想是緩存循環不變量(即靜態變量)到salve nodes。每次迭代重用這些數據。
HadoopDB[9]:HadoopDB是一個混合系統。其基本思想是采用現有的MapReduce作為與正在運行著單節點DBMS實例的多樣化節點的通信層,實現并行化數據庫。查詢語言采用SQL表示,并使用現有工具將其翻譯成MapReduce可以接受的語言,使得盡可能多的任務被推送到每個高性能的單節點數據庫。
G-Hadoop[10]:通過現有的MapReduce計算模型配合高速的存儲區域網(Storage Area Network,SAN)實現在多群聚環境,為大數據應用提供一個并行處理的環境。
P2P-MapReduce[11]:是一個動態分布式環境中自適應的MapReduce框架(2P-MapReduce),利用P2P模式在動態分布式環境中管理計算節點的參與、主機失敗和作業恢復等,為大數據應用提供服務。
Spark[12]:Spark是一個與Hadoop相似的開源云計算系統,支持分布式數據集上的迭代作業,是對Hadoop的補充,用于快速數據分析,包括快速運行和快速寫操作。Spark啟用內存分布數據集,除能夠提供交互式查詢外,還可優化迭代工作負載。
Hyracks[13]:一個受MapReduce啟發,基于分區并行數據流的大數據并行處理系統,用戶可將計算表示成數據操作器和連接器的有向無環圖(Directed Acycline Graph,DAG)類型數據流。
大數據處理框架的設計思想見表1所列。
(1)MapReduce計算執行過程中的Shuffle階段——執行完Map階段后會產生大量中間結果數據,該階段根據中間輸出結果中的Key值進行分類并分發到相關節點執行Reduce函數;
(2)其余類MapReduce計算模式、迭代、遞歸等也需要進行大量分片和合并操作。
在這兩個過程中產生的大量中間結果數據要在不同的節點(Map節點/Reduce節點)之間傳輸,數據規模越大、參與計算的節點越多、Map-Reduce的迭代/遞歸次數越多,節點間傳輸的頻度及數據量也越大,占用網絡的帶寬及時間也越長,最終可能導致網絡擁擠與堵塞,嚴重影響大數據處理框架的性能。
缺乏應用感知網絡的支持,這些大數據處理框架其性能得不到很好的發揮,因此,在大數據處理框架與網絡之間構建一抽象層,通過抽象層實現大數據處理框架與網絡之間的交互是一個有效的解決方式。一方面大數據處理框架無需修改現有的計算模式,直接通過該層告知基礎設施其所需計算資源的類別,而非特定的某一計算資源,從而讓計算資源調度策略從數據處理框架中脫離出來,使得計算過程主要關注數據的分析/處理,減輕大數據處理框架的包袱;另一方面通過該抽象層為第三方提供網絡訪問/調整的接口,在網絡物理結構不變的前提下按大數據應用需求調整網絡邏輯結構,方便資源調度策略的優化和實施,構建應用感知網絡更好地為大數據應用提供服務。
3.2 從云存儲的角度分析
在大數據應用的環境下,存儲是核心的組成之一,HDFS(Hadoop Distributed File System,HDFS)是當前主流的一款開源云存儲框架,是一個分布式文件系統,更是適合運行在普通硬件上的分布式高容錯文件系統,當前絕大多數云存儲系統都通過HDFS實現。
HDFS的系統架構如圖4所示。
HDFS采用Master/Slave架構。HDFS主要由Namenode(master)和一系列Datanode(workers)構成。一個HDFS集群由一個Namenode和一定數目的Datanode組成。HDFS支持傳統的層次型文件組織。Namenode是一個中心服務器,負責管理文件系統的namespace以及客戶端對文件的訪問。HDFS有著高容錯性的特點,部署在低廉的硬件上,提供高傳輸率來訪問應用程序的數據,是為以流的方式存取大文件而設計,適合擁有超大數據集的應用程序。HDFS支持大數據文件,能夠提供大數據傳輸的帶寬和數百個節點的集群服務,能夠支持千萬級別的文件。所有的HDFS通訊協議都構建在TCP/IP協議上。HDFS設計目標對網絡的需求:
(1)硬件故障/錯誤及副本策略
硬件故障/錯誤是常態而非異常。HDFS集群由成百上千的服務器構成,每個服務器上存儲著文件系統中數據的一部分,任一個服務器都有可能失效。因此錯誤檢測和快速、自動恢復是HDFS最為核心的架構目標。此時,在網絡上需解決網絡可用的計算節點數量減少,一部分文件的可用副本數減少等問題。為確保文件副本的數量,數據需備份,以防故障。
(2)流式數據訪問
HDFS應用程序需要流式訪問數據集。HDFS進行的是數據批處理,而非用戶交互處理;相比數據訪問的低延遲,更應保證數據訪問的高吞吐量。
(3)大規模數據集
大數據應用中的應用程序是在大規模數據集基礎上的計算。HDFS上一個典型文件的大小一般都為G字節至T字節。因此,大文件存儲且能提供整體上數據傳輸的高帶寬,能在一個集群里擴展到數百個節點,使得網絡中的計算節點之間、存儲節點之間必然有大量數據傳輸。
(4)計算移到數據附近
數據離應用程序越近,計算就越高效,尤其是在數據達到海量級別時。因為這樣就能降低網絡阻塞的影響,提高系統數據的吞吐量。
(5)數據復制及副本存放
HDFS能夠在集群機器上可靠地存儲超大文件,其將文件分割成若干“塊”,除了最后一個,所有“塊”大小一致。為了容錯,文件的所有數據塊都有副本。每個文件的數據塊大小和副本系數都可配置,應用程序可以指定某個文件的副本數目。數據復制與采用的副本策略有關,且由于故障、更新、備份(HA的主要解決方案:Hadoop的元數據備份方案、Secondary NameNode方案、Checkpoint node方案、Backup Node方案、DRDB、Facebook的Avatarnode方案)等原因,數據復制經常發生在同機架的不同存儲節點之間及不同機架的不同存儲節點之間,這個過程必然依靠網絡。
其他一些云存儲系統如GFS(HDFS是GFS的開源實現)、CoHadoop、StorNext FS、Lustr、Total Storage SAN File System、DDFS(Disco Distributed File System)等,其設計目標主要為上述幾個方面。
云存儲系統設計目標的實現依賴于暢通的網絡。云存儲作為大數據應用的核心支撐,其效能直接影響到大數據應用的性能,云存儲框架與網絡及計算資源的(服務器/存儲)高耦合(數據調度、存儲調度、副本存放、數據操作等與具體計算資源的選擇與使用高耦合)關系,將影響應用框架的可擴展性。在云存儲的文件操作與網絡中的存儲資源之間插入中間抽象層,云存儲系統只需告知抽象層申請的計算資源的類別,通過抽象層與計算資源之間的接口訪問某類資源,實現文件的相關操作,一方面能方便地直接訪問抽象層反饋的計算資源集,另一方面將操作的具體實現過程標準化,通過抽象的接口簡化云存儲系統的操作。
3.3 從大數據分析/處理任務調度的角度分析
大數據分析/處理都在集群(Cluster)的基礎上完成,通過網絡連接多個成為節點的計算機為應用提供計算、數據存儲和通信資源等。以Hadoop集群所提供的大數據分析/處理為代表,Hadoop集群中節點負責數據存儲、集群維護管理和數據分析/處理的任務。在作業/任務調度中,分為JobTracker(控制節點)和TaskTracker(任務節點/執行節點)。一般情況下,Namenode和 JobTracker合并在同一臺物理服務器上,Datanode和TaskTracker作為集群的主要部分也會被安裝在相同節點上且大量散布于集群中。
集群結構如圖5所示[14,15]。
控制節點負責HDFS和MapReduce執行的管理(JobTracker),其余節點為執行節點(TaskTracker),負責數據的存儲和計算。任務調度是JobTracker指派任務(tasks)到相應TaskTracker上執行的過程。任務調度過程如下:
(1)JobTracker調度和管理其它TaskTracker,并將Map任務和Reduce任務分發給空閑的TaskTracker,讓這些任務并行運行,并負責監控任務的運行情況。
(2)TaskTracker負責具體任務的執行,并向JobTracker報告自己所處的狀態,接受其管理調度;一個重要的任務是原始輸入數據和中間運算結果的存儲和傳遞(在網絡中不同TaskTracker之間傳遞中間結果數據)。
(3)JobTracker和TaskTracker之間通過網絡以心跳機制實現通信。
(4)當一個Map任務被分配到執行節點執行時,系統會移動Map計算程序到該節點——在數據存儲的Datanode節點上執行這部分數據的計算,以減少數據在網絡上的傳輸,降低對網絡帶寬的需求。
(5)在一個Reduce任務被分配到一個空閑的TaskTracker節點上執行時,JobTracker會先將中間結果的key/value對在執行Map任務的TaskTracker節點上局部磁盤位置信息發送給Reduce任務,Reduce任務采用遠程過程調用機制從Map任務節點的磁盤中讀取數據。
任務/作業調度方法直接關系到Hadoop集群的整體系統和系統資源的利用情況。針對MapReduce集群先后提出了很多調度策略,包括FIFO調度、HOD調度、計算能力調度、公平調度等。
在任務/作業的調度中,無論何種調度策略,對網絡的使用及需求如下:
(1)JobTracker在分配任務前,必須與該任務使用的數據源所存儲的節點(節點集)建立聯系,并通過節點的空閑狀態以判斷是否在該節點啟動任務。針對一個文件,其被劃分為多個塊存儲在各節點上,每個文件塊對應多個(默認設置為3)副本,每個副本存儲在不同的節點上,因此,一個任務對應要判斷多個節點的狀態。當多個任務并行時,JobTracker要審閱大規模節點的狀態,當前JobTracker節點與這些節點之間的網絡狀態對任務啟動的策略及判斷有非常大的影響;
(2)JobTracker無法判斷及獲知被選中的計算節點的當前網絡狀況及其歷史網絡情況,因此計算節點的網絡狀況這一因素在任務調度中被忽略,不利于有效利用網絡以提高大數據分析/處理性能;
(3)在Reduce任務分配時,JobTracker由于不了解TaskTracker節點的當前網絡狀況及其歷史網絡情況,無法根據TaskTracker節點的網絡狀況來選擇最優的節點啟動Reduce任務,故無法高效快速地獲取Map任務產生的大量中間數據,從而影響了數據分析/處理的性能;
(4)在任務執行的過程中,JobTracker與大規模的TaskTracker節點之間利用網絡來實現心跳機制的通信,JobTracker需要有穩定的網絡來支持。
其它如表1所列的大數據處理框架中的任務調度也存在類似問題。所以,針對上述問題,在計算資源及網絡的上層架設一抽象層,負責統計網絡的當前狀況及各節點的網絡狀態,維護計算資源的狀態,任務調度器只需向該抽象層提出執行的任務(主要為TaskTracker的任務)及申請使用的計算資源的類別,從抽象層中獲取得到相應類別的計算資源,最后執行任務。通過架設這一抽象層,可以做到:
(1)大數據應用環境下的任務調度器,只需關注調度策略及使用的計算資源類別,抽象層負責維護具體的計算資源的狀態,反饋告知調度器可按需查詢抽象層中所維護的計算資源的信息,實現計算資源對調度器的虛擬化;
(2)通過向抽象層中加載針對計算資源狀態分析、網絡歷史情況分析及節點網絡狀況分析的第三方策略獲得計算資源的最優或次優集,能更有效地利用網絡來優化任務調度,通過提供計算資源調度策略的接口,有利于提高當前計算框架的數據分析/處理性能;
(3)由于抽象層對任務調度器反饋的是某類計算資源中最優或次優的可選節點集,能實現節點及網絡的負載平衡,預防Map/Reduce任務之間大數據量傳輸所造成的網絡擁擠及堵塞,避開網絡帶寬的瓶頸。
3.4 從大數據處理中容錯處理的角度分析
由于大數據應用環境下,數據的規模、計算資源(存儲、服務器)的規模和同時并行處理的任務規模都極其龐大,各種情況的失效[16,17](服務器故障、軟件故障、存儲器故障、運行環境故障等)已成為一種常態行為。
MapReduce是一種并行編程模型,作為典型的大數據處理框架,被經常用以處理和生成大數據集。任務調度以及容錯機制作為模型的重要組成部分,會對整個大數據處理框架的性能產生直接影響[18,19]。提高整個大數據應用環境的容錯性[20](分布存儲的容錯性、物理拓撲結構的容錯性、數據的容錯性等)是云計算面臨的一項挑戰。大數據應用環境下,為提高容錯性對網絡的需求主要有以下幾個方面:
(1)節點失效、存儲介質故障導致文件數據丟失。選擇另外一個或多個有足夠存儲空間的節點來存儲受影響的文件后,常態化需要在跨機架或同一機架跨節點之間進行數據的復制/遷移 ,因此需要得到網絡在時間和帶寬上的支持;
(2)元數據服務器失效/JobTracker失效。為防止元數據服務器失效,應對元數據備份眾多方案,在實施方面,網絡需在備份操作期間保持穩定且維持一定的帶寬,以便傳輸日志、元數據信息等,保證數據的一致性;
(3)任務(Task)失效。任務失效分為Map任務失效和Reduce任務失效兩種。針對Map任務失效,JobTracker會在從對應數據副本的節點上重新調度Map任務,此時面臨如何在副本對應節點集上選擇一個網絡狀態最好的節點,以便Map任務產生的中間結果數據傳輸出去;針對Reduce任務失效,JobTracker會在另一個節點重新調度Reduce任務,此時將面臨如何選擇其網絡狀態最好,能方便獲取各Map任務產生的中間結果的節點。Map任務和Reduce任務的狀態信息由TaskTracker向JobTracker匯報;
(4)TaskTracker失效。當TaskTracker失效時,JobTracker會將TaskTracker中的所有任務發配到另外的TaskTracker來執行,為防止TaskTracker失效產生的問題,在集群上會增加TaskTracker的數量。因此,JobTracker通過心跳機制獲取和維護大規模的TaskTracker節點集信息,JobTracker對網絡需求高。
針對上述4個大數據處理中容錯對網絡的需求,在數據處理框架與計算資源之間架設抽象層,有以下好處:
(1)在該抽象層中通過動態XML文件形成元數據備份方案邏輯映射、JobTracker管理TaskTracker的邏輯映射,方便數據處理應用程序按需獲取計算資源信息,為實現利用或選擇最優的有效計算資源提供數據支持和接口;
(2)抽象層在節點上的分布執行有利于將JobTracker對TaskTracker的管理分散層次化,以降低JobTracker過于集中管理帶來的瓶頸(計算能力、網絡帶寬)問題;
(3)有利于實現JobTracker與TaskTracker之間聯系的虛擬化,通過抽象層的網絡訪問接口,方便控制網絡能按JobTracker與TaskTracker的需求進行調整(分配網絡帶寬、使用時間),體現網絡的應用感知性,提高系統吞吐率。
4 結 語
本文從大數據應用環境下以數據處理、云存儲和容錯處理等方面對與網絡進行協同工作的需求為基礎,分別以大數據處理、云存儲、大數據分析/處理任務調度和大數據處理中的容錯處理這四個不同角度對與網絡進行協同工作的需求為基礎,分析了大數據應用下底層數據和網絡的相關問題,為大數據框架中底層數據傳輸和網絡的優化提供了研究基礎。
參考文獻
[1] NatureNews:Bigdata:Wikiomics[EB/OL].http://www.nature.com/news/2008/080903/full/455022a.html
[2] SP Nist. A NIST definition of cloud computing[J]. Communications of the Acm, 2015,53(6):50.
[3] N.McKeown. Keynote talk: Software-defined networking[C].In Proc. of IEEE INFOCOM09, Apr.2009.
[4] Hadoop[EB/OL]. http://hadoop.apache.org/
[5] Isard M, Budiu M, Yu Y, et al. Dryad: distributed data-parallel programs from sequential building blocks[J].ACM Sigops Operating Systems Review,2007,41(3): 59-72.
[6] Dittrich J, Quiané-Ruiz J A, Jindal A, et al. Hadoop++: Making a yellow elephant run like a cheetah (without it even noticing)[J]. Proceedings of the VLDB Endowment, 2010, 3(1-2): 515-529.
[7] Eltabakh M Y, Tian Y, ?zcan F, et al. CoHadoop: Flexible data placement and its exploitation in hadoop[J]. Proceedings of the VLDB Endowment, 2012, 4(9): 575-585.
[8] Bu Y, Howe B, Balazinska M, et al. HaLoop: Efficient iterative data processing on large clusters[J].Proceedings of the VLDB Endowment, 2010, 3(1-2): 285-296.
[9] Abouzeid A, Bajda-Pawlikowski K, Abadi D, et al. HadoopDB: an architectural hybrid of MapReduce and DBMS technologies for analytical workloads[J]. Proceedings of the VLDB Endowment, 2009, 2(1): 922-933.
[10] Wang L, Tao J, Ranjan R, et al. G-Hadoop: MapReduce across distributed data centers for data-intensive computing[J].Future Generation Computer Systems, 2013,29(3):739-750.
[11] Marozzo F, Talia D, Trunfio P. P2P-MapReduce: Parallel data processing in dynamic Cloud environments[Z].Journal of Computer and System Sciences, 2011.
[12] Zaharia M, Chowdhury M, Franklin M J, et al. Spark: cluster computing with working sets[C].Proceedings of the 2nd USENIX conference on Hot topics in cloud computing. USENIX Association, 2010: 10.
[13] Borkar V, Carey M, Grover R, et al. Hyracks: A flexible and extensible foundation for data-intensive computing[C].Data Engineering (ICDE), 2011 IEEE 27th International Conference on. IEEE, 2011: 1151-1162.
[14] Apache Hadoop framework[EB/OL]. http://hadoop.apache.org. 2010-06-20/2010-11-07.
[15] Hadoop On Demand Documentation[EB/OL]. http://hadoop.apache.org/core/ docs/r0.172/hod.html. 2010-06-20/2010-11-07.
[16] J. Dean.Experiences with MapReduce, an Abstraction for Large-Scale Computation[C]. In Proc of PACT06.
[17] J. Dean.Designs. Lessons and Advice from Building Large Distributed Systems[C]. The 3rd ACM SIGOPS International Workshop on Large Scale Distributed Systems and Middleware (LADIS), Big Sky, MT, October 2009.
[18] S.Y. Ko, I. Hoque, B. Cho, I. Gupta. On Availability of Intermediate Data in Cloud Computations[C].the USENIX Workshop on Hot Topics in Operating Systems (HotOS), 2009.
[19] G. Wang, A.R. Butt, P. Pandey, K. Gupta. A Simulation Approach to Evaluating Design Decisions in MapReduce Setups[C]. In Proc of MASCOTS2009.
[20] Zheng Q. Improving MapReduce fault tolerance in the cloud[Z]. In: Taufer M, Rünger G, Du ZH, eds. Proc. of the Workshops and PhD Forum (IPDPS 2010). Atlanta: IEEE Presss, 2010.
猜你喜歡
電腦知識與技術(2016年21期)2016-10-18 23:34:52
電腦知識與技術(2016年21期)2016-10-18 23:24:44
電腦知識與技術(2016年21期)2016-10-18 22:11:15
新聞世界(2016年10期)2016-10-11 20:13:53
大學教育(2016年9期)2016-10-09 08:54:03
科技視界(2016年20期)2016-09-29 13:34:06
科技視界(2016年20期)2016-09-29 10:53:22
中國記者(2016年6期)2016-08-26 12:36:20
