智庫信息組織策略及其在大數據環境下的挑戰*
2017-08-07 10:31:19安楠祝忠明
智庫理論與實踐 2017年3期
■ 安楠祝忠明
1中國科學院蘭州文獻情報中心 蘭州 7300002中國科學院大學 北京 100049
智庫信息組織策略及其在大數據環境下的挑戰*
■ 安楠1,2祝忠明1
1中國科學院蘭州文獻情報中心 蘭州 7300002中國科學院大學 北京 100049
[目的/意義]高水平的新型智庫離不開高水平的信息支持機制,大數據時代背景下傳統的智庫信息組織機制已無法適應當前的數據特征及決策要求,構建支持決策過程的知識庫已成為智庫發展的必然趨勢。[方法/過程]本文選取《全球智庫報告2016》中具有參考價值的國外智庫機構作為研究對象,應用文獻調研法和案例分析法總結歸納了目前智庫常見的信息組織方式,分析了大數據下數據價值鏈及其對組織環節的要求,并據此提出智庫知識庫構建的必要性。[結果/結論]最終提出一個通用的面向決策過程的智庫知識庫框架,并采用語義本體方法構建了知識庫內部的知識組織模型,以期為智庫在大數據下逐漸實現半自動到自動化的決策研究過程提供參考借鑒。
智庫 知識庫 大數據 信息組織 組織策略 決策研究 本體
1 引言
智庫是公共政策的研究分析和參與機構,針對國內、國際問題開展政策導向性的研究、分析和咨詢,以使得政策制定者和公眾能夠依據可靠的信息進行決策[1]。其主要作用是為決策制定者提供及時、全面、準確的支持信息,支持信息的范圍、數量、質量、服務內容、服務方式等都將直接影響到決策制定的效果[2],因此擁有完善的信息支持機制是智庫產生高質量決策咨詢成果的重要保障。
大數據時代信息呈現出體量巨大、形式繁多、更新速度快及價值密度低的4V數據特征[3-4],在這種數據爆炸的形勢下,任何研究過程都呈現出一種數據驅動的趨勢,如何從海量信息中及時發現、提取有價值的知識為自己所用,將成為影響智庫決策研究過程及產出效率的關鍵。
大數據驅動下的智庫決策研究必須解決以下兩個問題:一是如何構建一個統一的數據模型,使得任何大數據資源都能夠通過該數據模型的加工處理最終成為可支持決策研究的智能數據,逐漸實現半自動到自動化的決策研究過程。二是如何針對決策研究過程對各種來源各種形式的相關信息進行語義化處理,加強數據之間的關聯以提升知識發現的能力,為決策者提供更有價值的政策參考信息。因此,本文將圍繞大數據分析能力需求及智庫決策研究過程嘗試構建支持多源異構的數據集成框架,為語義化地建造支持大數據情報處理和分析的智能數據集提供統一的概念模型。
2 智庫信息組織機制現狀研究
智庫如何對數據內容進行組織加工將直接影響到研究人員與情報專家對信息資源的利用效率,科學合理的組織方式不僅能提高數據存取效率,更有助于挖掘數據中的潛在價值信息,產生增值效應。
2.1 國外智庫信息組織機制發展現狀
現代意義上的智庫最早形成于二戰時期的西方國家,相比我國,西方國家無論在智庫研究領域還是智庫自身建設方面都已發展得相對完善,選取西方有影響力的智庫作為研究對象將更具代表性。本文依據賓大《全球智庫報告2016》的綜合排名及各項領域排名,選取了排名靠前的十余家具有代表性的國外智庫作為研究對象(見表1),通過對其官方網站上信息資源的展示方式以及可獲取的各種類型智庫產品的調研,對其信息組織策略進行了分析。
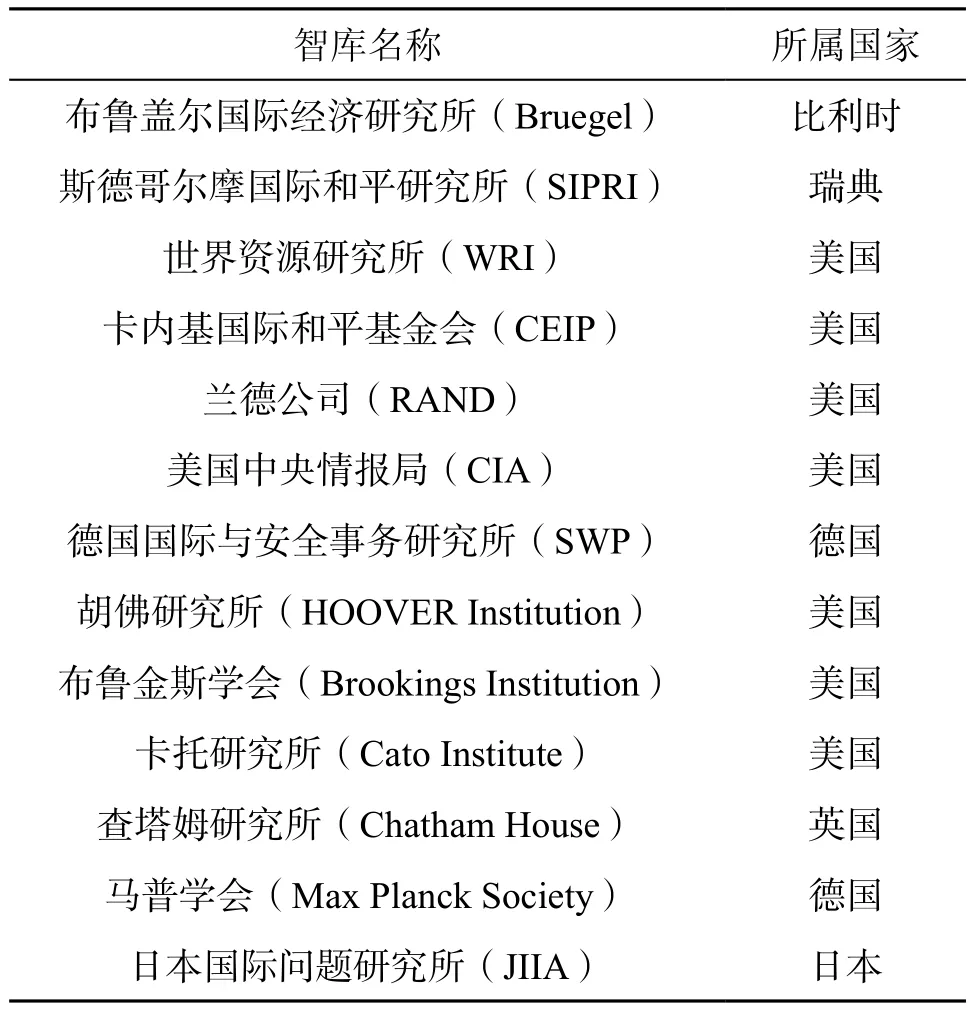
表1 調研涉及的國外智庫Table 1 Foreign think tanks involved in the research
通過調研比較與分析,歸納了西方智庫機構常見的信息搜集及組織策略(見圖1),總結了當前西方智庫信息支持機制的發展現狀。在智庫的信息搜集策略中,主要以需要較多依靠人工參與的手動采集和半自動采集為主,其中搜集公開數據以其可操作性較強、數據范圍廣、相對成本低等特點成為智庫最常用的信息搜集方式之一,幾乎所有上述智庫都將通過互聯網獲取公開數據作為數據搜集的最常規途徑。此外因智庫研究的實時性和新穎性,智庫經常對所需數據有特殊要求或涉及到諸如戰爭形勢、行為科學、藥物病理等特定項目,沒有完全適用的數據或先前數據參考價值不大,因此智庫研究人員還需通過直接生產創造途徑作為對間接搜集獲取途徑的補充,其中文獻調查法因其低成本且易開展成為使用頻率最高的直接獲取數據方式,例如美國布魯金斯學會、胡佛研究所、卡內基國際和平基金會等老牌智庫在傳統調研運用中都是最典型的代表。當然,在調查研究過程中智庫專家經常不拘泥于某種特定方法,而是各種方法相互交錯、靈活運用。依據內容的組織形式,搜集到的信息資源可被組織為數據庫、信息檢索系統、知識庫3種形式(詳見圖1)。
2.1.1 數據庫(數據集) 對于智庫通過直接或間接途徑搜集到的數據,組織方式之一就是將其結構化為數據庫或數據集,這種結構化數據形式的優點是便于管理、共享性高、冗余度低、容易擴充。
布魯蓋爾國際經濟研究所(Bruegel)是一家專注于國際經濟政策研究的智庫,其將關于政策經濟的7個專業數據集對外開放[5],包括(1)全球及地區基尼系數;(2)歐元區貨幣總量Divisia指數;(3)178個國家的實際有效匯率;(4)全球經濟下的歐洲企業:外部競爭下的內部政策;(5)持有的主權債券;(6)歐元體系流動性;(7)在PATSTAT應用程序上基于回歸的記錄鏈接。斯德哥爾摩國際和平研究所(SIPRI)以其對全球安全問題權威性的評估享譽世界,SIPRI所有研究的根據和來源均完全開放,因此其研究成果成為國際政治家、研究人員及媒體人員經常使用的權威性資料來源。SIPRI擁有4個專業數據庫:(1)多邊和平行動數據庫;(2)軍費開支數據庫;(3)武器轉讓數據庫;(4)軍需工業數據庫。此外,SIPRI還全面掌握了關于軍備控制和裁軍的數據集[6],包括軍火禁運報告、國家軍火報告、全球軍火貿易價值報告等等,這些專業數據庫對SIPRI的研究活動提供了強有力的信息支持。
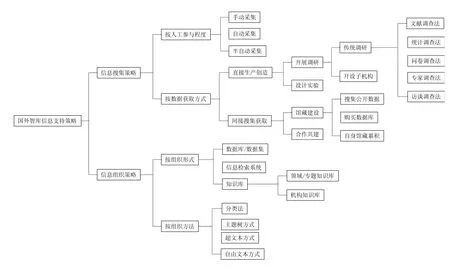
圖1 國外智庫信息支持策略Figure 1 Information support strategies of foreign think tanks
2.1.2 信息檢索系統 一個機構信息檢索系統的完善程度也可以直接反映出其信息組織的好壞,對于智庫來說,強大的檢索系統不僅能從內部為研究專家提供高效率的數據支持,同時為用戶快速準確地獲取所需信息提供了便利。
卡內基國際和平基金會提供了簡潔易用的站內檢索系統,用戶可選擇精確匹配或任意匹配的方式對題名、作者名或全文進行檢索,檢索結果可通過文檔類型、發表年份、地區、主題、項目進一步篩選,并可按照日期或相關度對結果進行排序。蘭德公司的檢索系統功能相對完善,用戶可以通過關鍵詞匹配、額外屬性、文檔特征等多種檢索條件進行限定,額外屬性包括頁面標題、所屬蘭德部門、內容類型、起始日期等,文檔特征涵蓋了題名、作者、主題、ISBN等,用以快速定位到相關資源。美國中央情報局(CIA)作為美國乃至世界著名的情報機構之一,力求對海量情報進行科學管理使其效果得到最大程度發揮,這也令CIA成為情報機構中進行信息資源管理與增值的典范。CIA的解密檔案檢索系統在對檔案材料進行數字化保存時采用了元數據方法(見表2),統一的元數據標準將海量信息資源進行科學歸類,同時能夠將文本、音視頻等不同類型的媒介資源進行有機融合,使其在同一個存取體系內進行統一檢索,極大提高了信息利用效率。

表2 CIA解密文檔檢索系統元數據Table 2 Metadata of CIA decrypted document retrieval system
2.1.3 知識庫 在信息環境中知識庫(knowledge repository)可以被定義為一個組織圍繞特定應用目的(如支持科研、教育或管理過程等)建立的知識集合。一般地,知識庫有兩種基本的類型:領域/專題知識庫和機構知識庫。前者收集、組織和傳播特定學科領域或主題的知識內容,后者主要提供對一個機構產出的知識進行保存和傳播管理的服務。知識庫作為一種存儲、組織和管理數字知識的機制,在科研領域已經有著較為廣泛的應用,然而在智庫等決策咨詢機構中的應用還尚不成熟,相當一部分智庫由于資金、資源等原因或者還沒有意識構建智庫內部的知識庫,仍停留在信息“存儲庫”的階段。
本文結合之前已有的研究[7],通過調研從館藏建設、情報搜集、技術支持3個方面對比分析了美國蘭德公司(RAND)和德國國際和安全事務研究所(SWP)在知識庫建設過程中的情況(見表3),通過分析可以看出,RAND和SWP都非常重視對信息資源的建設,內部館藏豐富,數據庫內容涉及廣泛。在知識組織方面均采用了分類組織的方式,依據研究主題建立專題知識庫,同時也選擇地區作為研究項目分類的依據。兩大智庫均通過技術手段開發了信息支持系統,并且都積極嘗試與其他機構部門開展信息資源共享、信息共建等合作,以彌補自身專業缺陷,同時能減少數據冗余。
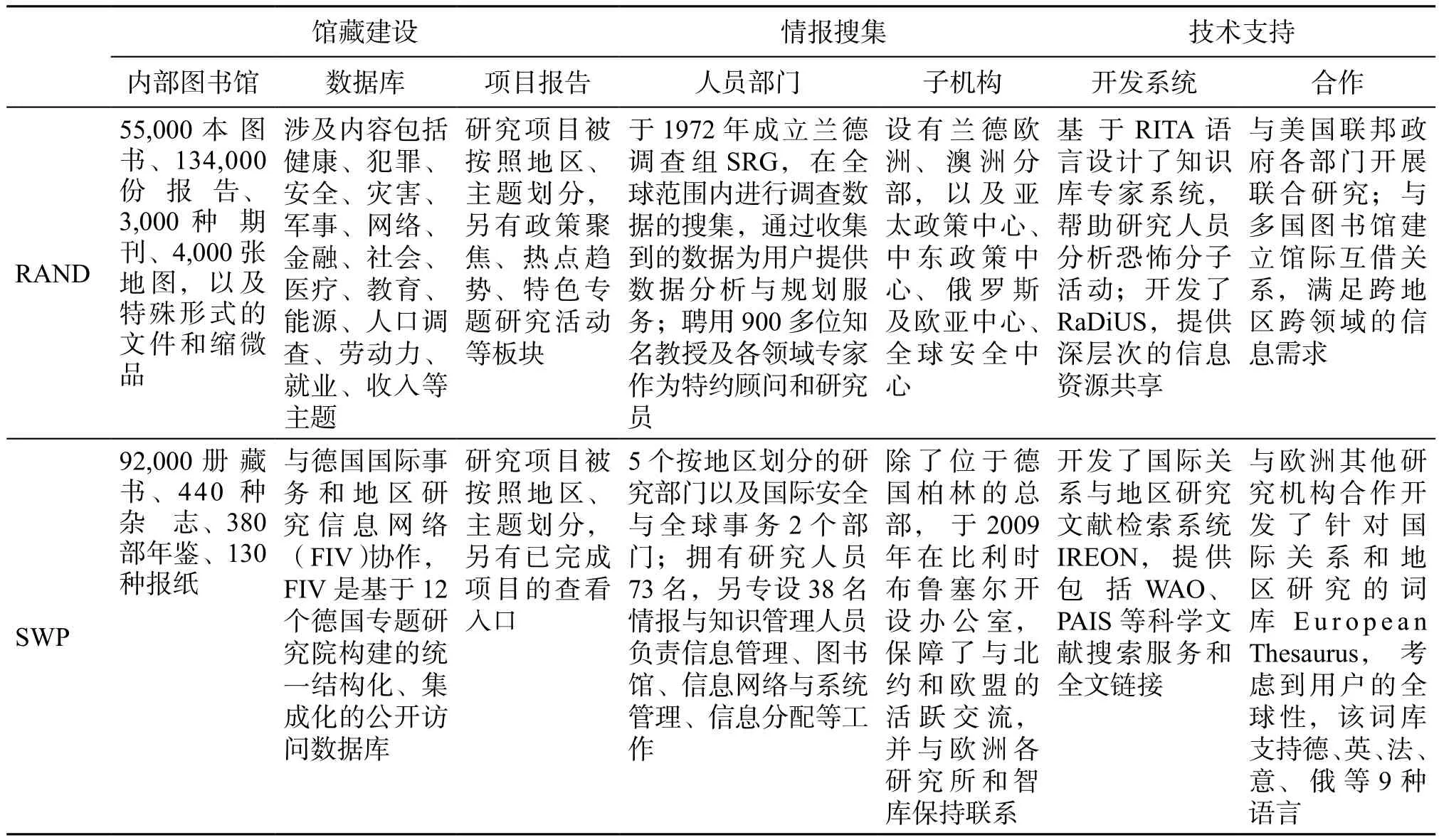
表3 RAND與SWP知識庫構建情況對比Table 3 Comparison of knowledge repositories between RAND and SWP
2.2 大數據時代對智庫信息組織的挑戰
由調研可以看出,雖然當下全球各大智庫的信息支持機制已發展得較為全面,但是仍存在很多不足。一方面,以數據庫/數據集形式組織起來的信息之間是相對獨立的,即使數據庫對所存儲的信息會從主題或其他特征進行大致分類,但在更細粒度層面的數據上,數據之間彼此獨立,缺乏必要的關聯,不利于智庫在進行數據挖掘和數據分析時對潛在知識的發現。此外,這種數據相互獨立的信息組織方式沒有基于上下文(context-based)的聯系,缺乏語境化和情景化的知識應用,即針對同一概念在不同情景下的理解能力較弱。另一方面,在以信息檢索系統形式組織信息的智庫中,絕大部分僅僅標注了信息的外延,并沒有針對信息內容進行更深層的語義化標注,不利于計算機對數據信息的理解以及智庫決策過程自動化的發展,這在大數據時代智庫對國際形勢響應速度要求越來越高的情況下顯然已經阻礙了智庫的決策產出效率。為了能夠將大數據中的無意義數據加工為可支持決策研究的智能數據,各種信息必須從非結構化的、彼此獨立存在的粗粒度數據被加工成結構化的、計算機可操作的、相互關聯的、具有上下文語境的細粒度數據。
全球知名咨詢公司麥肯錫最早提出了“大數據”時代的到來,大數據時代各種數字資源急劇增長,逐漸成為信息資源的主流。面對大數據的4V特征,傳統的智庫信息支持機制已無法高效處理如此海量的異構數據,如何有效地從紛雜的數據中獲取有價值的信息,如何對采集到的海量信息進行科學的管理和組織,并以此為用戶提供迅速、準確的服務,這些問題要求新型智庫必須及時調整對數據的采集、存儲及組織策略以適應當前的大數據特征。 T.Gustafson和D.Fink于2013年提出“大數據價值鏈”的概念[8],認為每條大數據價值鏈簡化后都至少應由4個基本階段組成:數據獲取—數據存儲—數據分析—數據應用。智庫作為知識組織型機構,其決策研究及決策產出過程實際上也是一個知識增值的過程。基于此,提出大數據環境下的智庫數據價值鏈(如圖2),智庫數據價值鏈反映了智庫決策研究及產出的各個階段圍繞數據進行的活動,而大數據則對各環節提出了要求。
與一般依賴計算機自動化抽取、處理并分析大數據得到結果的商業化研究的數據價值鏈不同,智庫數據價值鏈進行知識增值的過程是一個基于前者對大數據的充分處理和組織后,作為決策研究的支持數據提供給智庫專家,與智庫專家的隱形知識共同作用最后形成智庫產品的過程。在這種數據驅動的決策過程下,最終提供給智庫專家的支撐數據的及時性、全面性、準確性以及數據組織完善程度都將直接影響到最后智庫產品的產出效率和質量。
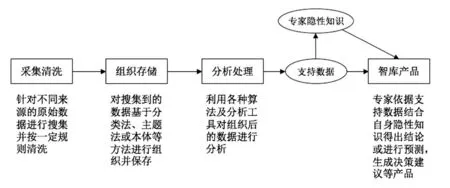
圖2 大數據環境下的智庫數據價值鏈Figure 2 The data value chain of think tanks in the context of big data
從智庫數據價值鏈中對各環節的要求可以看出,大數據時代對傳統智庫研究的一系列流程都產生了影響,其中最關鍵的應是處于中間環節的數據組織階段。作為承前啟后的中間環節,智庫在開展數據組織工作時既要適應之前智庫從各種數據源采集的復雜數據類型,又需為后續進行存儲及數據分析要使用的技術和工具提前做好相應準備。綜上,大數據環境下智庫需要一個能夠結合管理手段和信息技術對捕獲并保存的信息進行有效組織和管理的信息支持系統,即智庫知識庫。
3 基于本體的智庫知識庫數據集成框架
智庫知識庫[9](Knowledge Repository)泛指支持和服務于智庫運作的知識庫系統,是智庫知識能力建設的重要機制。圍繞智庫研究和服務的決策領域,進行相關知識內容的收集、保存、組織和提供服務,是智庫知識庫的首要任務;同時,發布和傳播智庫自身產出的決策咨詢產品也是智庫知識庫的重要功能。因此,智庫知識庫兼具領域知識庫和機構知識庫的雙重屬性和功能——既是智庫正常運作及決策產品產出的重要信息支撐工具,也是智庫有效管理并利用其知識資產的工具。
實現信息的語義化是大數據環境下智庫數據組織環節的首要目標。通過分析與總結相關文獻[10-11],本文針對智庫知識庫構建了一個基于決策支持本體的數據集成框架(如圖3),該框架依次按照數據資源→數據集→文檔→實體4個層次對大數據資源粒度由粗到細進行描述和組織,描繪了大數據環境下不同來源不同類型的數據信息經過信息抽取后在智庫知識庫中被進一步語義化處理,最終都轉化為可用于支持決策研究的“智能數據”的過程。智能數據是指通過對海量數據進行處理分析后,從數據中提取出有價值的信息和知識,使數據具有“智能”,相比大數據的“大”而言,智能數據擁有更高的數據價值,更值得進行深入挖掘,可通過建立模型尋求現有問題的解決方案或進行預測,“啤酒+尿布”就是一個典型的智能數據應用案例。該數據集成框架的信息處理過程主要包含了以下5個階段:信息抽取階段、數據存儲階段、數據準備階段、語義數據模型和決策應用階段。
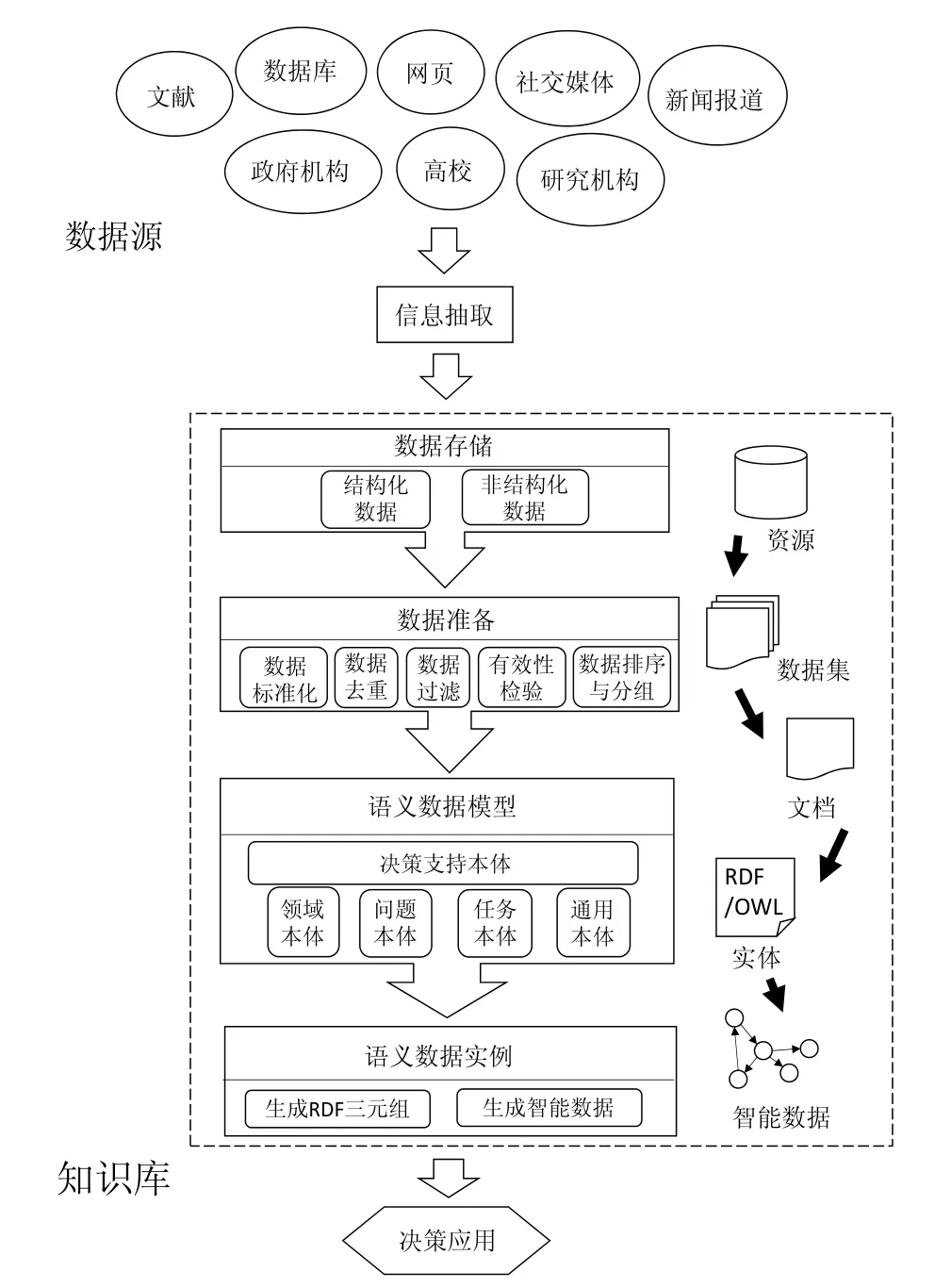
圖3 基于決策支持本體的數據集成框架Figure 3 Data integration framework based on decision support ontology
3.1 信息抽取階段
這是智庫對大數據環境下信息資源進行語義化處理過程的第一步,主要是從適當的信息源中抽取相關數據資料,信息源可以是從外界自動抓取數據的外部信息源,也可以是從內部機構人員處收集成果的內部信息源。針對信息資源格式的不同,可以將抽取過程分為結構化抽取和非結構化抽取兩部分進行,并分別存儲在不同類型的存儲庫中。
3.2 數據存儲階段
將上一階段從智庫機構內部和外部數據源搜集到的數據進行保存。針對數據的類型分為結構化數據存儲和非結構化存儲兩種方式,存儲工具也從傳統的數據庫管理系統(DBMS)如MySql、PostgresSQL等,到企業級數據倉儲(EDW)和大規模并行處理數據庫(MPP)如PADB和SAND等,此外HDFS、HBase這種分布式文件系統和MongoDB、CouchDB等NoSQL數據庫也經常被用于非結構化數據的存儲。
3.3 數據準備階段
在數據準備階段,存儲設備中的結構化和非結構化信息資源將根據智庫機構的服務對象和研究目標按照專題(topic)、學科領域(subject/ domain)或項目(project)等被組織成數據集的形式,并在各個數據集中被進一步細分為一個個由文本組成的文檔。
這一過程中涉及到對數據的清洗以使數據符合目標模式,其中一些典型的處理方法包括對數據的規范化、數據去重、完整性約束違規檢查、基于正則表達式過濾數據、排序和分組數據等等。
3.4 語義模型階段
語義數據模型是數據集成框架的核心部分,也是面向決策研究的信息資源實現語義化的關鍵。
在語義數據模型中,支持決策研究的本體將首先被構建,之后依據智庫決策研究涉及的具體領域和問題進行專業領域本體、問題本體和任務本體的構建,此外還將復用現有的本體和各種通用本體,以針對不斷更新的信息對本體模型進行擴展。最后經過本體間數據字段的映射、相似數據字段對齊等一系列操作形成一個面向決策研究過程的通用的語義數據模型。因本研究重點關注針對智庫決策過程的支持信息的數據組織,問題本體和任務本體的構建暫不在討論范圍之內。到這一階段為止,智庫知識庫的數據組織模型的構建已基本完成,大數據下從任何來源采集到的任何數據都可以經過上述一系列步驟實現面向決策研究的語義化,成為一個個相互關聯的實例,從而更有利于決策者挖掘其中的潛在知識,為決策制定提供信息支持。
3.5 決策應用階段
經過充分語義化后的數據資源已經成為具有較高價值的智能數據,可以根據決策研究過程中的不同需求從不同角度為決策者提供信息支持。與目前傳統的較多人工參與的智庫決策信息支持機制相比,一方面該信息處理框架利用各種信息處理技術和工具將大數據作為原材料進行深度加工,使其成為能被計算機自動處理的“可計算信息”,逐步實現半自動直至自動化的決策過程。另一方面,得益于大數據巨大的數據體量,以及語義化模塊對數據資源的語義化處理,使得更深層次的潛在知識和知識關聯得以被挖掘并發現,最終提供給決策者的是智能化的決策支持數據而非一般數據信息,因而這種基于大數據分析的決策研究方法能夠得出較傳統方法更科學、更可靠也更迅速的決策結果。
4 決策支持本體的構建
本體作為“共享概念模型的明確的形式化規范說明”[12],其目標是獲取、描述和表示相關領域的知識,提供對該領域知識的共同理解,確定領域內共同認可的詞匯,并從不同形式的形式化模式上給出了這些詞匯(術語)和詞匯之間相互關系的明確定義[13]。針對大數據下智庫在信息采集和組織環節面臨的海量非結構化數據,本文選擇使用本體方法對這些復雜類型數據進行語義化處理,實現本體驅動的決策過程。
面向決策過程的決策支持本體是智庫知識庫中數據語義模型的核心組成部分,決策支持本體的結構設計包含3個階段:需求分析、本體建模和本體實施。
4.1 需求分析
首先通過文獻調研和網絡調研識別出圍繞決策研究過程的關鍵問題,對其進行分解,提煉出實體類型和關系類型。在決策研究過程中涉及的實體和關系具有一些重要的特征,對本體的設計提出了相應的要求,主要包括:
(1)決策研究過程中涉及的實體種類較多,如事件、人員、機構、地理位置等,這些實體又可能被進一步細分。例如某次水資源污染事件中,涉及的機構類型可能包括企業、司法部門、工商部門等。此外,事件的關注者有時也是直接參與事件的實體人員或機構,例如當地居民不僅關注并投訴了該事件,也是飲用了污染水的受害者。本體需要具有容納各種各樣相關實體的能力。
(2)與決策研究相關的實體和關系具有時效性, 決策議題、相關事件、參與者和關系都存在于特定的時間內。本體需要描述時間維度, 以支持對事件發展過程的表示和分析。
(3)對每一個實體和關系,都有大量對應的數據資料為其提供豐富的描述和評論。這些數據資料經過處理整合,可以提供揭示性的定量或定性參考。決策本體有必要將這些基礎性的支撐性數據資料也包含在內。
(4)決策本體應保留對其他本體的接口,支持對現有本體和新建本體的擴展。例如科技領域問題會用到學科領域本體,支撐性資料會用到出版物本體。
本體設計的整體要求是在支持上述分析的同時,邏輯模型應盡量簡明。
4.2 本體建模
明確需求之后,要選取合適的構建方法對決策研究問題進行本體建模。面向決策研究過程的本體設計就是根據決策支持本體的構建目標建立其概念模型的過程。構建決策支持本體的目標是建立基于決策支持信息的語義檢索系統,為智庫專家和政策研究人員提供語義化的信息查詢方式,突破傳統的智庫決策信息支持機制,提供語義級的決策信息查詢服務。
本文根據決策研究問題的實際情況和需要,選擇國際上較為成熟的七步法作為參照主體來構建科技智庫知識庫中的決策支持本體。具體構建步驟如下:
(1)確定本體的范疇和目的
界定決策支持本體的范疇,即要明確如何描述一個決策相關的事件或資源,以及描述到何種程度。目的是希望能夠建立一個通用的面向決策研究過程的本體,用以描述針對某決策議題或事件引發的問題,以及針對問題作出的回應、涉及到的項目、相關參與人、機構及其相互之間的關系等等。
(2)考慮復用現有本體的可能性
本文選擇復用DC和ABC本體。都柏林核心DC作為目前使用最為廣泛的本體之一,其對資源基本情況的語義描述具有很廣泛的適用性和擴展性。改變模型的能力使得ABC本體適合于描述各種各樣的實體和它們之間的關系,包括所有媒體類型的對象(文本、圖像、視頻、音頻、網頁和多媒體等)。它還可以用于模擬諸如知識內容和時間實體的抽象概念,例如對象發生的性能或生命周期事件。因此本文最終選擇復用DC和ABC本體中的相關類和屬性,同時利用XML schema、RDF schema、OWL等命名空間。所有復用的本體如表4所示。

表4 復用本體Table 4 Reused ontologies
(3)列出本體中的重要術語
確定本體中核心概念的具體表述詞匯及其邏輯關系,最常見的方式就是直接抽取對應領域主題詞表和分類表中的主題詞和分類詞。
(4)列出關鍵實體和類
對提取出的核心概念進行評估,按照一定的邏輯規則進行分組,設計合理的類及其層次結構。本文通過參考相關研究的論文及研究結果[14-15],結合決策研究過程的實際特征,最后確定從問題類(Issue)、決策產品類(Decision output)、決策建議類(Decision suggestion)、參與者類(Participant)、資源類(Resource)這5個核心方面構建決策本體,并據此展開整個類層次結構。
問題類(Issue)是指由科技領域或其他相關領域事件(Event)引發產生的各種問題。
決策產品類(Decision output)是指智庫研究人員及決策者針對產生的問題進行科技政策研究,最終得到的決策產品以及在研究過程中產生的各種中間數據。具體分類體系如圖4所示。
決策建議類(Decision suggestion)是科技智庫決策研究過程的最終產物,是決策產品類的一個子類。決策產品的另一個子類是中間產品類(Mid-product),指在決策者進行政策制訂的過程中原始數據經參與研究的智庫專家及研究人員的加工生成一系列為其提供思路的中間數據,這些中間數據對于今后類似項目的研究有很大參考價值,通常也被智庫進行組織并保存。
參與者類(Participant)是指所有直接或間接參與到決策研究過程中的個人(Individual)或組織(Organization),其分類體系如圖5所示。
資源類(Resource)是指在決策研究過程中為決策產品的生成提供支持的各類信息資源,包括各種數據(data)、方法(method)、模型(model)、工具(tool)等,同時也為科技問題的溯源和詢證(evidence-based)提供了途徑,詳細分類體系如圖6所示。

圖4 決策產品分類Figure 4 The classification of decision output
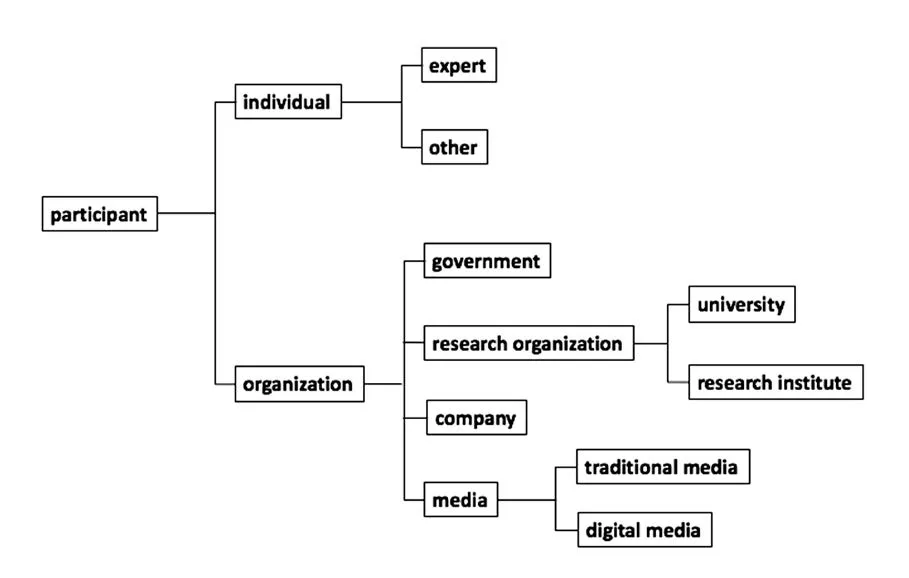
圖5 參與者分類Figure 5 The classification of participants
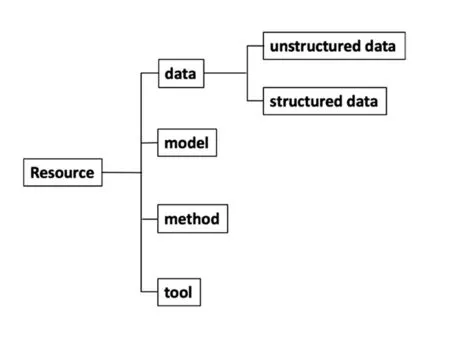
圖6 資源分類Figure 6 The classification of resources
最終構建的決策支持本體的總體框架見圖7,整個本體框架分成3層:核心層、擴展層和支撐層:
①核心層——問題Issue、決策產品Decision output;
②擴展層——參與者Participant、事件Event、項目Project、任務Task、決策建議Decision suggestion、中間產品Mid-product等;
③支撐層——資源Resource、數據Data、模型Model、方法Method、工具Tool等。
分層結構提供了簡明的邏輯模型,使得核心層、擴展層和支撐層的實體關系清晰有序;不同層次存儲的數據結構復雜度和精確度不同,允許系統根據查詢需求對準確性和全面性的權衡,滿足個性化的查詢和分析結果。
(5)分析實體的屬性
本體的數據屬性是表示類或概念與值的關系,例如年齡屬性“at age of”的數值將代表某種生物的具體年齡,而本體的對象屬性則表示類之間的非等級關系,例如屬性“trigger”或“cause”可以用以表示兩個類之間的因果關系,一個類觸發了另一個類,恰當地定義數據屬性和對象屬性可以有效地反映類間的關系。限于篇幅僅展示核心層的部分屬性如下表5。

圖7 科技智庫的決策支持本體總體框架Figure 7 Decision-making ontology of science and technology think tanks

表5 核心層類的部分屬性Table 5 Parts of properties of classes in the core layer
(6)分析屬性的約束
對屬性進行必要的約束限制,針對數據屬性的約束條件包括描述屬性的值的類型(字符串、布爾型、枚舉型等)、值域、基數(單個基數或多個基數)等特性。例如將時間屬性的Year字段的最大值設為2017,又比如人的性別只能從“男”或“女”兩個值中選擇一項等。
(7)創建實例
根據之前步驟已經建立的概念模型創建具體的實例。本文使用protégé4.3選擇一個具體領域的問題進行部分實例添加作為展示。此外,也可借助API工具實現對實例的批量導入。本文將創建的本體以OWL文本的格式保存在本地計算機中以便于本體的復制與備份,并可隨時進行編輯和修改。
4.3 智庫知識庫的實施過程
智庫知識庫的總體運作流程見圖8(以科技智庫為例)。通過API工具和爬蟲工具可以在互聯網上抓取所研究領域的相關事件和問題內容,同時收集用戶的政策需求或政策方案,對自然語言進行處理后,再通過信息抽取等文本處理工具分析上述內容,提取其中的實體和類型,使用上述本體構建模型和Protégé等編輯工具進行本體的構建與數據維護,并且可依據信息源的性質及數據特征引入外部本體,如在本例中的DC元數據和科技領域本體。最終將從現實世界所采集的內容全部實現實體化,形成相互具有語義關聯的智能數據,結合之前用戶的政策需求或政策方案提供相應的匹配結果,為政策制定者提供決策支持信息。最終預期達到的目標是能夠基于智庫采集處理的大數據信息構建一套面向決策研究過程的語義驅動的檢索系統(圖9)。
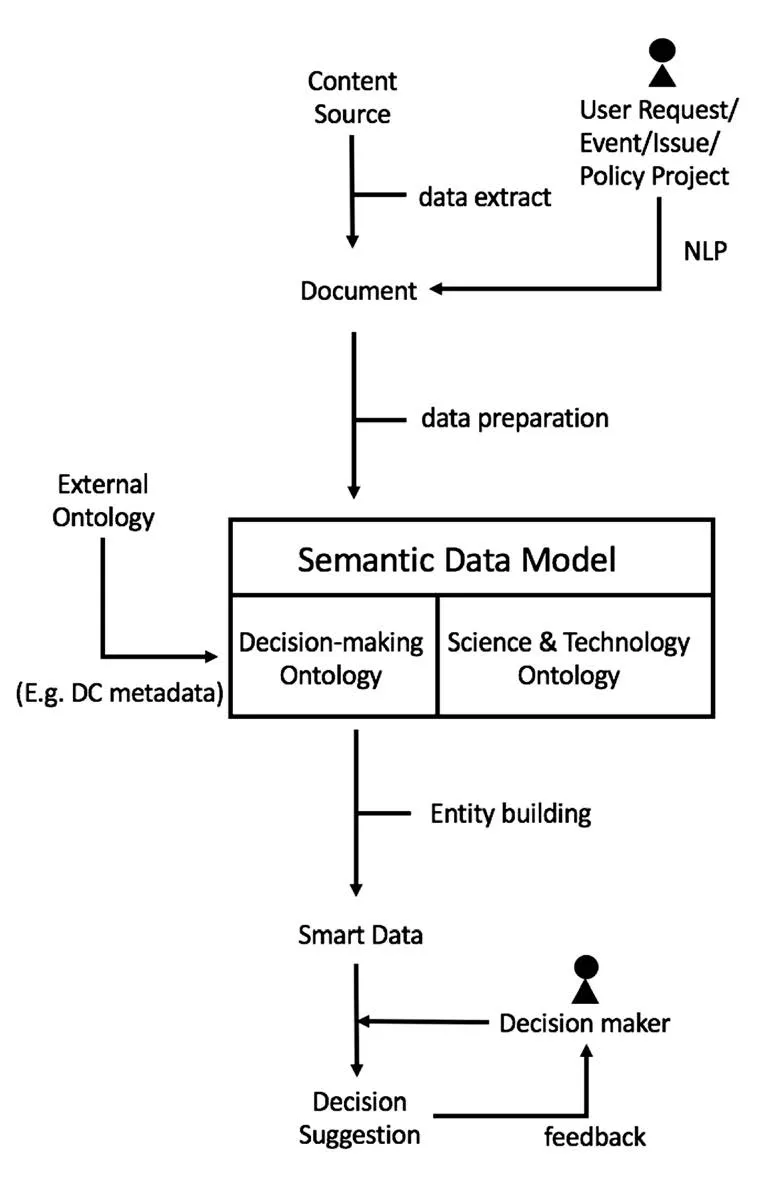
圖8 智庫知識庫運作流程Figure 8 Knowledge repository operation process of think tanks
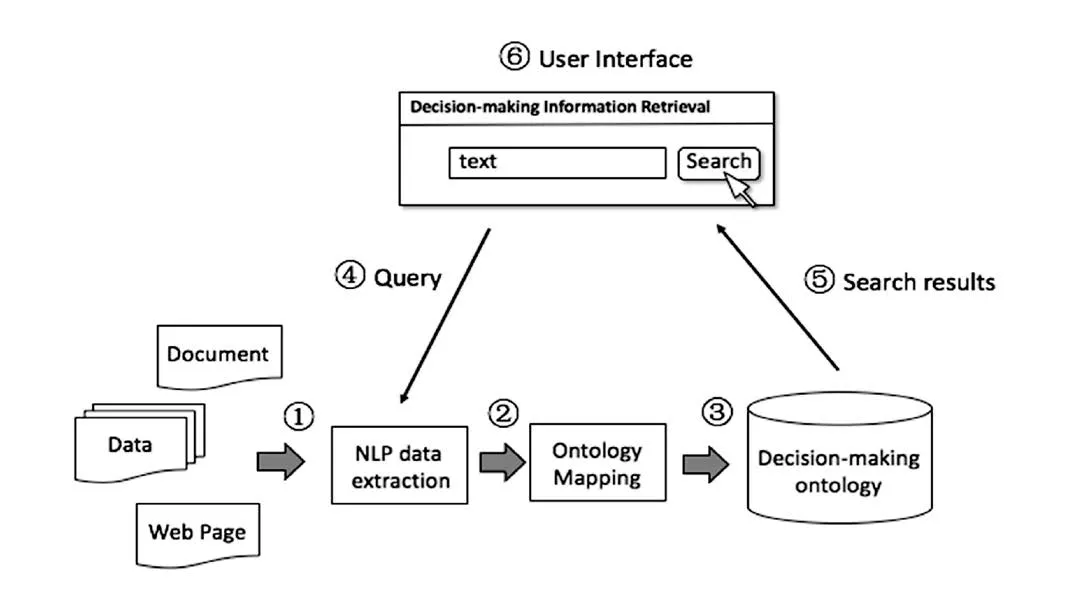
圖9 語義驅動的決策檢索系統示例Figure 9 An example of a semantic-driven decisionmaking retrieval system
在這套檢索系統中,社會熱點事件、某個社會問題、新聞報道、研究出版物等大數據下的海量數據資料被智庫抽取并進行自然語言處理,再經過智庫知識庫的處理并存儲,成為智能數據。在檢索時,用戶的查詢需求同樣先進行自然語言處理,之后請求數據以相同的方式被映射到智庫知識庫中的決策本體中,繼而匹配之前生成的實體化數據,返回給用戶基于智能數據的檢索結果,這種基于語義驅動和智能數據的檢索系統相比傳統智庫在決策研究中的資料查找和收集方式,能夠得到更為全面、更為科學、相互關聯的檢索結果,概括來講就是基于上下文情境(context based)的結果,這種檢索結果可以更容易地進行潛在知識挖掘,帶有情境也更方便被直接投入決策應用。例如,對“霧霾防治”相關信息進行檢索,通過該語義驅動的決策檢索系統,用戶將會得到某次霧霾發生事件的起因、起止時間、地點、相關人員、相關機構、相關出版物描述,以及霧霾防治政策的相關研究機構、研究人員、政策實施情況、產生的影響等等一系列信息。由此實現了一種面向決策研究的、提供上下文情境的語義化的檢索機制。打破了傳統的較依賴人工的智庫決策信息支持機制。
5 總結
本文主要調研了當前智庫傳統信息支持機制及其在大數據時代背景下受到的挑戰,從而提出了一種一般性的語義化的智庫決策信息處理框架,并依據該框架設計了科技智庫知識庫的數據組織模式,以期為大數據下新型智庫的建設提供參考借鑒。
關于針對智庫政策領域研究的本體創建,目前在國內的嘗試還少之又少,后續要進行的工作還有很多。在不斷完善該智庫決策信息處理框架功能并維護決策本體的同時,本文下一步的研究工作將圍繞決策本體的本體映射、本體評價、集成擴展等方面繼續進行。
[1] James G. McGann, University of Pennsylvania, 2016 Global Go To Think Tank Index Report[EB/OL]. [2016-08-10]. http://repository.upenn.edu/think_tanks/10/.
[2] 吳育良. 國外智庫決策信息支持研究及啟示[J]. 圖書館理論與實踐, 2015(10): 31-35.
[3] 廖球, 嚴揚帆, 莫崇菊. 大數據時代機構自建學術數據庫研究[J]. 圖書館學刊, 2014(4): 34-36.
[4] MOORTHY J, et al. Big data: prospects and challenges[J]. The Journal for Decision Makers, 2015, 40(1): 74-96.
[5] Bruegel. Datasets[EB/OL]. [2017-03-01]. http://bruegel. org/publications/datasets/.
[6] SIPRI. Databases[EB/OL]. [2017-03-01]. https://www. sipri.org/databases.
[7] 許鑫, 吳珊燕. 智庫知識庫的構建研究[J]. 情報理論與實踐, 2014(3): 68-72.
[8] Studer R, Benjamins C R, Fensel D. Knowledge Engineering, Principles and Methods[J]. Data and Knowledge Engineering, 1998, 25(1-2): 161-197.
[9] Benjamin Horne, Tanya Torres, Jessica Mackenzie. Think Tank Management: Establishing a Knowledge Repository[EB/OL]. [2016-12-30]. http://www.ksiindonesia.org/en/news/detail/think-tank-managementestablishing-a-knowledge-repository.
[10] Srividya K Bansal, Sebastian Kagemann. Semantic Extract-Transform-Load framework for Big Data Integration[J]. Computer, 2015, 48(3): 42-50.
[11] Francesco Corcoglioniti, Marco Rospocher, etc. The KnowledgeStore: A Storage Framework for Interlinking Unstructured and Structured Knowledge[J]. International Journal on Semantic Web and Information Systems, 2015, 11(2): 1-35.
[12] Studer R, Benjamins C R, Fensel D. Knowledge Engineering, Principles and Methods[J]. Data and Knowledge Engineering. 1998, 25(1-2).
[13] 廖軍. 基于領域本體的信息檢索研究[D]. 長沙: 中南大學, 2007.
[14] Leo Wanner, Marco Rospocher, etc. Ontology-centered environmental information delivery for personalized decision support[J]. Expert System with Applications, 2015(42): 5032-5046.
[15] Studer R, Benjamins C R, Fensel D. Knowledge Engineering, Principles and Methods[J]. Data and Knowledge Engineering. 1998, 25(1-2): 161-197.
作者貢獻說明:
安 楠:開展調研,撰寫論文;
祝忠明:提供思路,指導修改。
The Challenges and Data Organization Strategies for Foreign Think Tanks Within the Context of Big Data
An Nan1,2Zhu Zhongming1
1Lanzhou Library, National Science Library of Chinese Academy of Sciences, Lanzhou 730000
2University of Chinese Academy of Sciences, Beijing 100049
[Purpose/signif i cance] The high level of new types of think tanks cannot be separated from the high level information support mechanism. The traditional think tank information organization mechanism in the big data era cannot adapt to the current data characteristics and decision-making requirements. Constructing the knowledge repository that supports the decision-making process is becoming the inevitable trend of the development of think tanks. [Method/process] This paper chose foreign think tanks with reference value in 2016 Global Go To Think Tank Index Report as the research objective, and summarized several kinds of information organization methods which were common in the current think tanks by using the literature research method and case analysis method. It also analyzed the data value chain and its requirements for all aspects of think tanks, and accordingly put forward the necessity of the construction of knowledge repository of think tanks. [Result/ conclusion] Finally, a general knowledge repository framework for decision-making process is proposed, and the knowledge organization model in the knowledge repository is constructed by the semantic ontology method to provide references for the achievement of the transformation from the semi-automatic decision-making process to the automatic one.
think tank knowledge repository big data information organization organizational strategy decision research ontology
G359
10.19318/j.cnki.issn.2096-1634.2017.03.04
2017-04-16
2017-05-18 本文責任編輯:唐果媛
*本文系中國科學院文獻情報能力建設項目“中國科學院知識資產存繳管理中心建設”(項目編號:Y6ZG421001)的研究成果之一。
安楠(ORCID: 0000-0002-9981-8720),中國科學院蘭州文獻情報中心碩士研究生,E-mail:annan@mail.las. ac.cn;祝忠明(ORCID: 0000-0002-2365-3050),中國科學院蘭州文獻情報中心研究館員,博士生導師,E-mail:zhuzm@ llas.ac.cn。
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
開放教育研究(2020年2期)2020-03-31 01:54:14
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
中華手工(2017年2期)2017-06-06 23:00:31
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
中外會展(2014年4期)2014-11-27 07:46:46
外語學刊(2011年1期)2011-01-22 03:38:33
