分布式環境下的頻繁數據緩存策略
2017-08-12 12:22:05殷慧文張一川
計算機應用與軟件 2017年8期
易 俗 殷慧文 張一川 張 莉
1(遼寧大學創新創業學院 遼寧 沈陽 110036) 2(東北大學軟件學院 遼寧 沈陽 110819)
?
分布式環境下的頻繁數據緩存策略
易 俗1殷慧文1張一川2張 莉2
1(遼寧大學創新創業學院 遼寧 沈陽 110036)2(東北大學軟件學院 遼寧 沈陽 110819)
大數據環境下利用分布式緩存技術能夠提供高性能、高可用的數據查詢。針對輕量級數據庫應用的頻繁數據緩存策略具有高效、易擴展的優點,更有利于輕型分布式數據庫應用的查詢優化改進。因此,通過分析用戶行為和用戶查詢特征,研究針對近期頻繁查詢數據的數據緩存策略,能夠預測高命中率的緩存數據,提高數據查詢效率。首先分析并給出查詢頻繁度的定義,其次根據時間因素對緩存數據選取的影響細化用戶查詢操作,并通過查詢數據的查詢頻繁度應對查詢過程中不同的緩存命中情況整合節點間的緩存數據。最后,實驗證明該數據緩存策略具有較高的數據命中率,能夠提高數據查詢的效率。實現方面可根據實際需要采用不同的緩存屬性組合,具有良好的易擴展性。
數據緩存策略 查詢頻繁度 集群環境 分布式系統 大數據
0 引 言
隨著大數據時代的到來,數據呈現出4V(Volume、Variety、Value、Velocity)[1]特性,即數據量大、類型繁多、價值密度低且處理速度快。這些特性也對數據庫系統提出了高并發讀寫、海量數據的高效存儲和訪問,以及高可擴展性和可用性的需求[2]。傳統的關系數據庫雖然穩定性高且對于集中式存儲的存儲查詢效率較高;但面對大數據的這些特性,關系數據庫高一致性和查準率已經不存在優勢,而關系數據庫的擴展性以及對海量數據的響應速度都遇到了障礙,不能勝任大數據的存儲管理要求,以及滿足不了高性能、高可用的分布式查詢處理要求。
非關系型數據庫——NoSQL[3-4]的數據存儲不需要固定的表結構,也不存在連接操作,雖然不遵循傳統關系型數據庫的ACID特性,但是對于非結構或者半結構化的分布式數據存儲和管理效率較高。NoSQL對數據庫事務一致性需求低,實時讀寫快,且對復雜的查詢響應較快。因此NoSQL更適用于大數據的存儲和處理。
NoSQL的數據分布式存儲減少了單個服務器的存儲壓力,提高了數據的故障恢復能力;但是這種分布式查詢處理的要求要比集中式查詢變得更加復雜,需要從高性能、高可用和易擴展角度研究分布式環境下的優化技術和策略,以提高數據查詢處理。
現實生活中的數據庫應用多以選擇、投影、連接查詢為主,如銀行、學校、辦公管理等業務。這些數據庫應用不同于科學計算、數據挖掘等分析應用,不需要協同過濾、機器學習和圖等具有復雜算法的計算過程,算法的復雜特點在一定程度上將直接影響分布式系統的優化方法和目標。本文從算法角度將僅針對數據屬性和元組的數據庫查詢應用定義為輕量級應用。對于輕量級的分布式數據庫系統的查詢應用尤其需要滿足易擴展、針對性良好等特點。針對頻繁數據特征優化目標的緩存策略研究,能夠提供較為準確且快速的查詢優化策略,是分布式數據庫系統領域的研究熱點。
1 相關工作
隨著硬件技術的發展,大量研究針對分布式內存對象緩存系統,比如Memcached[5]、BigTable[6]、PACMan[7]和GridGrain[8]等。由于磁盤容量往往比內存大很多,想通過內存永久存放、讀取和處理數據是不能解決的問題。因此,通常利用緩存作為內存。
在大數據環境下,數據查詢效率依賴于緩存數據的設計,如何選取高命中率緩存數據,以及管理不同節點間的數據緩存是當今大數據查詢的研究熱點。文獻[9-10]中提出了元數據緩存的解決方案,通過緩存底層存儲數據的元數據以實現查詢數據的快速定位。由于元數據緩存多建立在客戶端,進而減輕了總控節點的工作負荷。在緩存命中的情況下,客戶端可跳過總控節點,直接與存儲節點建立映射,獲得更佳的查詢性能。但這種緩存方式可擴展性不佳,對于大規模分布式系統,很難將底層數據全部緩存至客戶端。同時,由于元數據緩存在客戶端內,系統中任何數據變動都有可能破壞客戶端內緩存數據與底層存儲數據的一致性,導致客戶端“臟數據”的讀取。基于共享數據緩存的分布式緩存體系[11-12]通過數據共享的方式減少服務器間的數據交換,提高緩存數據利用率。在這種緩存體系下,集群中節點的緩存數據被共享至緩存池中,每個節點可根據查詢任務的不同,訪問不同節點內的緩存數據,進而起到降低節點間通信開銷、提高查詢效率的作用。但這種緩存方式對共享緩存池的維護有較高要求,共享池資源管理易成為系統性能瓶頸,增加了系統開發、維護開銷,緩存池內數據更新代價也較大,不能及時對近期頻繁查詢數據進行處理。此外,文獻[13]從圖論的角度探討了緩存數據部署對查詢效率的影響,地理位置相鄰的節點間緩存數據具有更低的數據傳輸延遲,全局查詢效率更高,但同時也承擔著更高的節點故障風險。這種方法雖未解決緩存數據的選取問題,但為集群中節點緩存的設計提供了新的思路。
針對大數據查詢效率問題,本文提出了條件屬性查詢頻繁度的概念,并基于此對Apriori算法進行改進,實現了一種分布式環境下的數據緩存策略,以建立頻繁查詢數據的高命中緩存的方式,既解決大數據的高效查詢問題,又能夠針對輕量級查詢應用具有易擴展的特性,強調時間因素在緩存數據選取上的重要性。
2 數據緩存策略
分布式集群中的工作節點由于內存資源有限,對于存儲在本地的大量數據,可能出現被查詢數據無法一次全部加載入內存的情況,而多次內存與磁盤間的數據傳輸又會增加查詢任務的執行時間,降低查詢效率。對于一些輕量級數據管理業務而言,數據庫查詢請求多數為其中一些關鍵數據屬性的頻繁查詢處理。因此,在數據裝載內存過程中,將頻繁處理的屬性數據盡量載入內存作為數據庫查詢的主要目標,能夠調高頻繁數據的查詢機會,從而提高數據庫查詢處理的效率。
當前主流的NoSQL數據庫多采用LIRS算法實現數據緩存機制,LIRS算法使用IRR(Inter-Reference Recency)和Recency兩個參數。IRR:一個頁面最近兩次的訪問間隔;Recency:頁面上次訪問至今訪問了多少其他頁。能夠針對數據的近期更迭給出緩存策略。但是,這種與業務無關的處理方法無法對較長時間內頻繁查詢的業務屬性數據進行更合理的統計,不能采取有針對性的策略緩存查詢數據。
針對輕量級數據庫查詢系統的應用環境中數據更新頻率較低,且數據具有更強的業務語義。因此從查詢屬性入手,深入考察查詢條件屬性對業務的關聯程度,能夠更準確地發現較長時間內的頻繁屬性查詢數據,進一步提高緩存數據的命中率。
本文引入查詢屬性頻繁度的概念,使用一種改進的Apriori算法—FD-Apriori確定頻繁數據,并根據頻繁數據處理數據緩存。該算法可根據查詢記錄日志文件分析獲得較長時間內頻繁查詢的數據,并將具有高頻繁度的數據進行緩存,獲得相比于LIRS算法命中率更高的緩存數據。同時,該方法易于擴展,能夠更有效地支持輕量級數據庫系統的查詢優化。
2.1 Apriori算法
Apriori算法使用頻繁項集性質的先驗知識,基于逐層搜索迭代方法獲得不同維度的頻繁項集,即通過較低維頻繁項集獲得較高維的頻繁項集候選集,經過進一步支持度驗證獲得較高維頻繁項集的方法實現頻繁項集的挖掘[14-15]。
Apriori算法包括以下兩類操作:
1) 連接步:根據已有的頻繁k項集集合獲得頻繁項集的候選集集合Ck+1。將Lk中各項集的項按字典序排序,對于Lk集合中任意兩k項集l1、l2,若有l1[1]=l2[1],l1[2]=l2[2],l1[k-1]=l2[k-1],l1[k]≠l2[k],則對l1、l2做連接∞操作,獲得k+1項集Ck+1={l1[1],l1[2],…,l1[k-1],l1[k],l2[k]}。重復上述連接操作,得到的k+1項集集合即為頻繁k+1項集的候選集集合Ck+1。
2) 剪枝步:篩選Ck+1中不滿足頻繁要求的項集,獲得頻繁k+1項集集合Lk+1。根據先驗性質——頻繁項集的所有非空子集也一定是頻繁的,檢驗連接步操作獲得的Ck+1中各項集子集支持度計數是否滿足最小支持度計數min_sup,去除Ck+1中不滿足先驗性質的項集,進而獲得頻繁k+1項集Lk+1。
Apriori算法在執行過程中,通過重復迭代“連接步—剪枝步”操作進而獲得記錄集D中所有滿足頻繁要求的n項集(n≥1)。
2.2 基于Apriori算法的數據緩存策略
本文提出了基于條件屬性查詢頻繁度的數據緩存策略。首先,該策略的核心為條件屬性查詢頻繁度概念的提出及計算方法;其次,在此基礎上通過改進現有Apriori算法,提出FD-Apriori算法以獲取具有較高查詢頻繁度的條件屬性組;最后,針對計算得到的條件屬性數據集,給出緩存情況的分類,以及緩存更新步驟。具體情況如下。
首先,在數據查詢過程中,查詢屬性分為結果屬性與條件屬性。而近期查詢頻率較高的條件屬性又可分為兩種:始終保持高查詢頻率的條件屬性,以及在近期短時間內被大量檢索的條件屬性。對此,本文針對條件屬性定義查詢頻繁度FD的概念,用于區分頻繁查詢屬性、解釋屬性的頻繁性。
定義1條件屬性的查詢頻繁度:條件屬性的頻繁性度量,用于區分不同條件屬性間查詢熱度的高低。通過設置查詢計數上限以及加權函數的方式強調近期查詢對屬性頻繁性的影響。
對于查詢條件屬性a,a的查詢頻繁度FD計算過程為:
① 根據查詢日志獲得屬性a第t天被查詢次數。其中t表示日志記錄時間距離有效記錄起始時間的天數,t越大,表示日志記錄時間距離當前時間越近。
② 對Count(t)進行規范化處理。設置近期記錄比例qrec區分近期記錄與歷史記錄。對于第t天查詢日志Dt,當t≥qrec×T時,Dt所包含記錄屬于近期記錄;當t
(1)
③ 根據加權函數W(t),對Countstd進行加權操作。加權函數W(t)應滿足以下條件:
W(t)應為增函數,以突出近期記錄的重要性,獲得近期短時間內被大量檢索的頻繁屬性。
不同時間t應對應不同權值,以區分處于不同查詢層次的屬性。
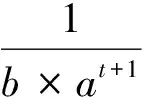
④ 計算屬性a的頻繁度如式(2)所示:
FD=∑W(t)×Countstd
(2)
其次,在FD(條件屬性頻繁度)概念的支持下,本文以頻繁度替換傳統Apriori算法中的支持度,從而獲得一種能夠準確篩選出頻繁查詢條件屬性的改進Apriori算法—FD-Apriori。
FD-Apriori的偽碼,如算法1所示。
FD-Apriori算法使用一種逐層搜索的迭代方法,利用“K-1項集”用于搜索“K項集”。首先,找出根據條件查詢頻繁度的頻繁“1項集”集合,該集合記作A1,如偽碼中第1)步至第4)步。A1用于找頻繁“2項集”的集合A2,而A2用于找A3。通過迭代的方式找到“K項集”。每個Ak都需要對整個日志數據庫進行一次掃描。
算法的核心思想是偽碼中的第7)步(連接步)和第11)步(剪枝步)。其中,連接步是自連接,原則是保證前k-2項相同,并按照字典順序連接;在剪枝步中保證任一頻繁項集的所有非空子集也必須是頻繁的。即某個候選的非空子集不是頻繁的,那么該候選肯定不是頻繁的,從而可以將其從Ck中刪除。
該算法簡單直觀的描述就是為了根據定義的FD(條件屬性查詢頻繁度)發現頻繁項集。過程為掃描、計數、比較、產生頻繁項集、連接、剪枝、產生候選項集的重復迭代處理,直到不能發現更大的頻集。
算法1FD-Apriori算法
輸入:查詢日志D(D=∑Di,Di表示第i天查詢日志) ,最小頻繁度minfd
輸出:A-D中各長度的頻繁查詢條件屬性組集
方法:
1) k=1
2) A1=φ
3) if(a.fd in D≥minfd){
4) add a into A1
//檢索查詢日志,獲得長度為1的頻繁查詢條件屬性組集
5) }
6) while(true){
7) Ck+2=Ak∞Ak+1
//連接步操作,獲得K+1長度的頻繁查詢條件屬性組候
//選集
8) Ak+2=φ
9) for(ak+1: Ak+1){
10) if(ak+1.fd in D ≥minfd)
11) add ak+1into Ak+1
//剪枝步操作,去除候選集中非頻繁的屬性組
12) }
13) }
14) if(ak+1≠φ)
15) k++
16) else
17) break
//當不存在更大長度的頻繁查詢條件屬性組集時,結束
//循環
18) return A=∪kAk
在NoSQL數據庫中,數據存儲方式多樣,如以鍵值對方式存儲數據的Cassandra、以列族存儲的HBase等。接下來僅以數據塊的概念泛指NoSQL型數據庫中數據存儲的最小單元進行討論。
在集群存儲節點上,第一次運行FD-Apriori算法獲得在當前存儲節點中頻繁被檢索的數據塊,第二次在頻繁數據塊上運行該算法,獲得在數據查詢中查詢頻率較高的條件屬性組集合。在FD-Apriori算法返回的屬性組集合中包含不同長度的條件屬性集,根據系統實際需要將不同長度的滿足頻繁定義的條件屬性組對應數據緩存至內存中,并針對查詢較頻繁的結果屬性建立B+樹索引以處理緩存中屬性部分命中的情況。當用戶進行查詢操作時,若查詢的數據塊在內存中,分布式系統不再從磁盤中讀取查詢數據,而是直接在內存中進行查詢并返回查詢結果,可在一定程度上減少內存與磁盤間的數據交換次數,節省查詢開銷。
在應用緩存策略的節點上,對于一次實際數據查詢,如圖1所示的3種不同命中情況。
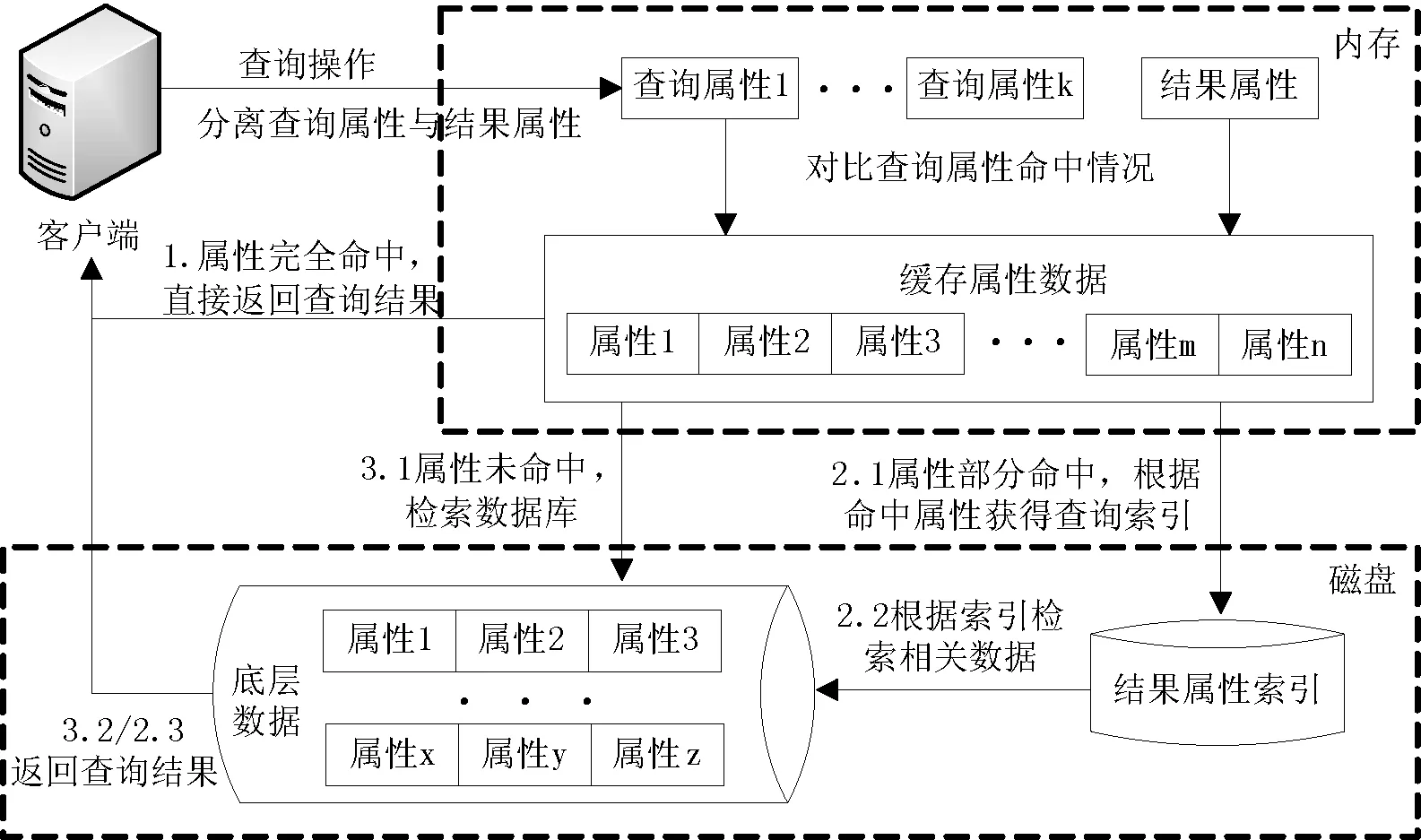
圖1 查詢屬性不同命中情況處理流程
(1) 未命中:查詢中的條件屬性不在內存緩存中。此時需要重新從磁盤中加載數據塊數據進行查詢操作,查詢速度較慢。
(2) 部分命中:查詢中的條件屬性僅有一部分在內存緩存中。由于查詢結果屬性個數較少且固定,可通過建立索引的方式提高查詢效率。此時可根據內存中已有的屬性數據對數據庫中的記錄進行篩選,減少需進一步在數據庫中檢索的數據量。同時,提供相應結果屬性的索引值,加速數據的檢索。這種情況下雖仍需從磁盤中讀取數據,但因索引的建立以及查詢規模較小,查詢速度相比于未命中情況仍比較理想。
(3) 完全命中:查詢中的條件屬性全部在內存緩存中。這是最理想的情況,可直接返回查詢結果。
對于同樣的查詢集,上述3種命中情況的出現取決于內存中的屬性緩存方式。當以屬性組的形式緩存數據時,屬性組的長度越大,查詢完全命中的可能性也就越大;但同時,部分命中情況下被篩選掉的無關數據量可能會相應減少。通常情況下,較長屬性組適合查詢環境中存在某一類極高頻查詢的情況,中等長度屬性組則更適合存在多類頻率較高且接近的查詢的查詢環境。本文將在實驗模擬章節測試不同長度屬性組對查詢結果的影響。
由于本文采取的是一種靜態的數據緩存策略,緩存數據具有固定的生命周期,相比于LIRS類數據緩存算法,需定期更新內存中的緩存數據。由于在計算條件屬性的查詢頻繁度過程中,以天為單位進行查詢次數計數,故應以天為更新頻率進行緩存數據的更新。緩存更新操作應在一天中節點訪問負荷最小的時間段進行。緩存更新共分為6步:
(1) 禁用內存緩存數據,出現數據查詢請求時直接檢索存儲底層的數據塊,此時緩存屬性命中率為0。
(2) 根據近T天查詢日志運行FD-Apriori算法,獲得頻繁查詢數據塊與頻繁查詢屬性組集。
(3) 對頻繁查詢數據塊加鎖,限制數據塊內數據的修改操作,保證緩存更新期間緩存數據與底層數據的一致性。
(4) 對比待緩存頻繁查詢數據與內存中已有緩存數據,保留相同的緩存數據,對于不同的緩存數據,清除舊頻繁數據,加載新頻繁數據。
(5) 將頻繁查詢數據塊解鎖,恢復數據塊內數據的修改權限。
(6) 更新緩存數據索引結構,啟用內存緩存數據。
3 實現及仿真實驗
3.1 緩存策略在HBase上的實現
基于FD-Apriori算法的頻繁數據緩存策略具有易擴展性,能夠面向輕量級數據庫應用給出快速解決方案。本文將針對HBase數據設計并實現上述數據緩存策略的應用范例。HBase是一個面向列的NoSQL數據庫,其作為Hadoop 項目的一部分,運行于HDFS文件系統之上[16-17]。
在數據讀取方面,HBase采取按列存儲策略,相比于按行存儲策略,減少了數據讀取過程中冗余數據的讀取,提高了數據讀取效率,使數據檢索更加迅速有效。在存儲方面,HBase將規模較大的數據表分割成若干區域(region),每個區域順序存儲數據表中一定數量的記錄,將多個相關區域合并操作,即可獲得完整的表信息。HBase數據表分割過程,如圖2所示,其中Table表示現有數據表,Region表示分割過程產生的數據區域。
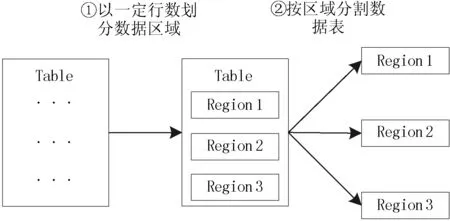
圖2 HBase分割數據表過程
HBase中的區域對應上文提到的數據塊概念。基于本文的數據緩存策略,根據數據查詢情況篩選出查詢頻繁的數據表區域,將頻繁度最高的若干區域中的頻繁屬性數據緩存至內存緩沖區中。當該區域中的數據被訪問時,根據查詢屬性與內存中緩存屬性的命中情況,進行不同的數據查詢操作。在HBase環境下,改進后的數據查詢過程,如圖3所示。
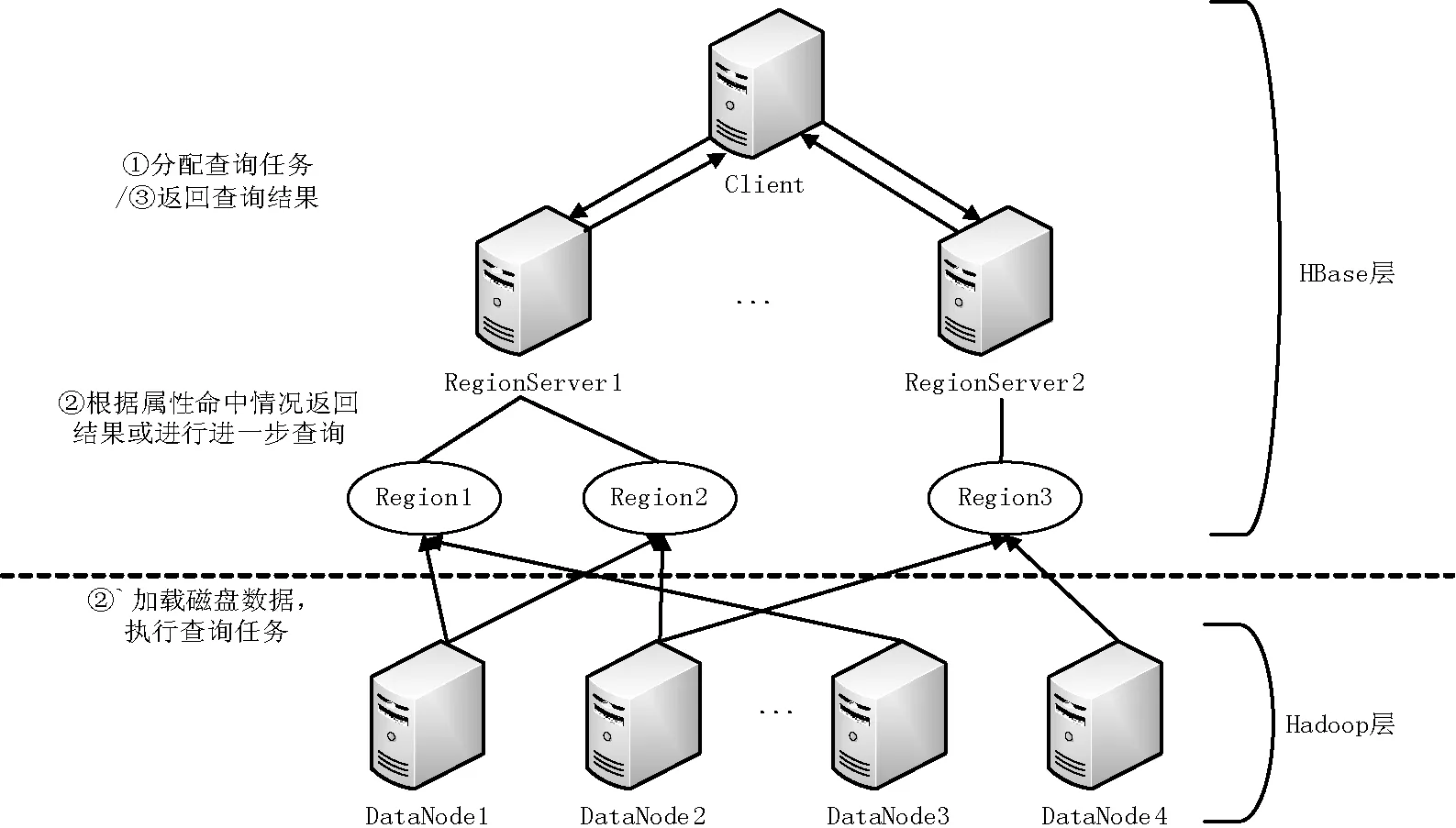
圖3 HBase環境下改進的數據查詢過程
由于HBase采取按列存儲策略存儲表數據,對于內存中的頻繁屬性數據,可使用列組的形式進行緩存。在列組結構中,數據以按行存儲的形式進行組織,雖然在緩存建立、更新過程中會帶來額外的壓力。但列組結構能夠加快內存中屬性間的匹配速度,減少部分命中情況下記錄篩選的時間開銷,提高查詢效率。
3.2 實驗設計
為驗證基于FD-Apriori算法的頻繁數據緩存策略在數據庫查詢效率方面表現,本文采用Hadoop-HBase搭建分布式實驗環境,進而考察算法的優化效果。
在實驗數據選擇方面,針對本文研究背景提出的輕量級分布式數據庫查詢應用,查詢業務采用以銀行個人儲蓄存取、查詢業務數據,以及小額貸款查詢、處理業務數據。由于銀行真實數據的獲取涉及到一定的隱私保護問題,因此本文根據少部分基礎業務數據,按照屬性約束隨機生成大量數據,以此作為真實場景模擬查詢數據以及相應的用戶查詢行為。
實驗構建了8節點的小型Hadoop集群環境,CPU為i7處理器,內存為16 GB。模擬數據方面在40 MB基礎業務數據的基礎上,通過屬性規則約束隨機生成數據量為100 GB的模擬數據,令T=7,將模擬數據分成7等份,以模擬不同時間的查詢日志。在應用本文緩存策略前,一條正常SQL Select語句的查詢時間平均約為1 500 ms。
通過統計用戶查詢中各屬性的查詢情況,可以獲得不同長度的滿足頻繁定義的條件屬性組合。在此基礎上,分別考察(1)利用LIRS算法的緩存策略的平均查詢時間。以及在緩存相同個數屬性的前提下,考察(2)基于FD-Apriori算法的頻繁數據單一屬性緩存平均查詢時間。(3)基于FD-Apriori算法的頻繁數據兩屬性組緩存平均查詢時間。(4)基于FD-Apriori算法的頻繁數據三屬性組緩存平均查詢時間,從而對比檢驗頻繁數據緩存的執行情況以及多組屬性緩存策略的變化。除此之外,還將設計實驗從頻繁數據的命中率角度檢驗FD-Apriori算法不同屬性組的結果。
3.3 實驗分析結果
在不同算法以及不同緩存屬性組方式下,平均查詢效率如圖4所示,查詢命中情況,如圖5所示。
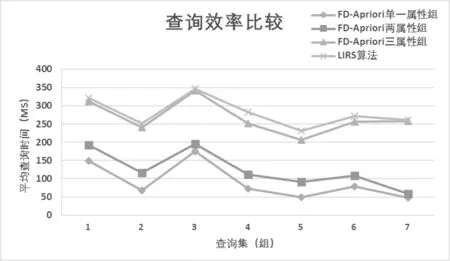
圖4 不同緩存方式查詢效率比較
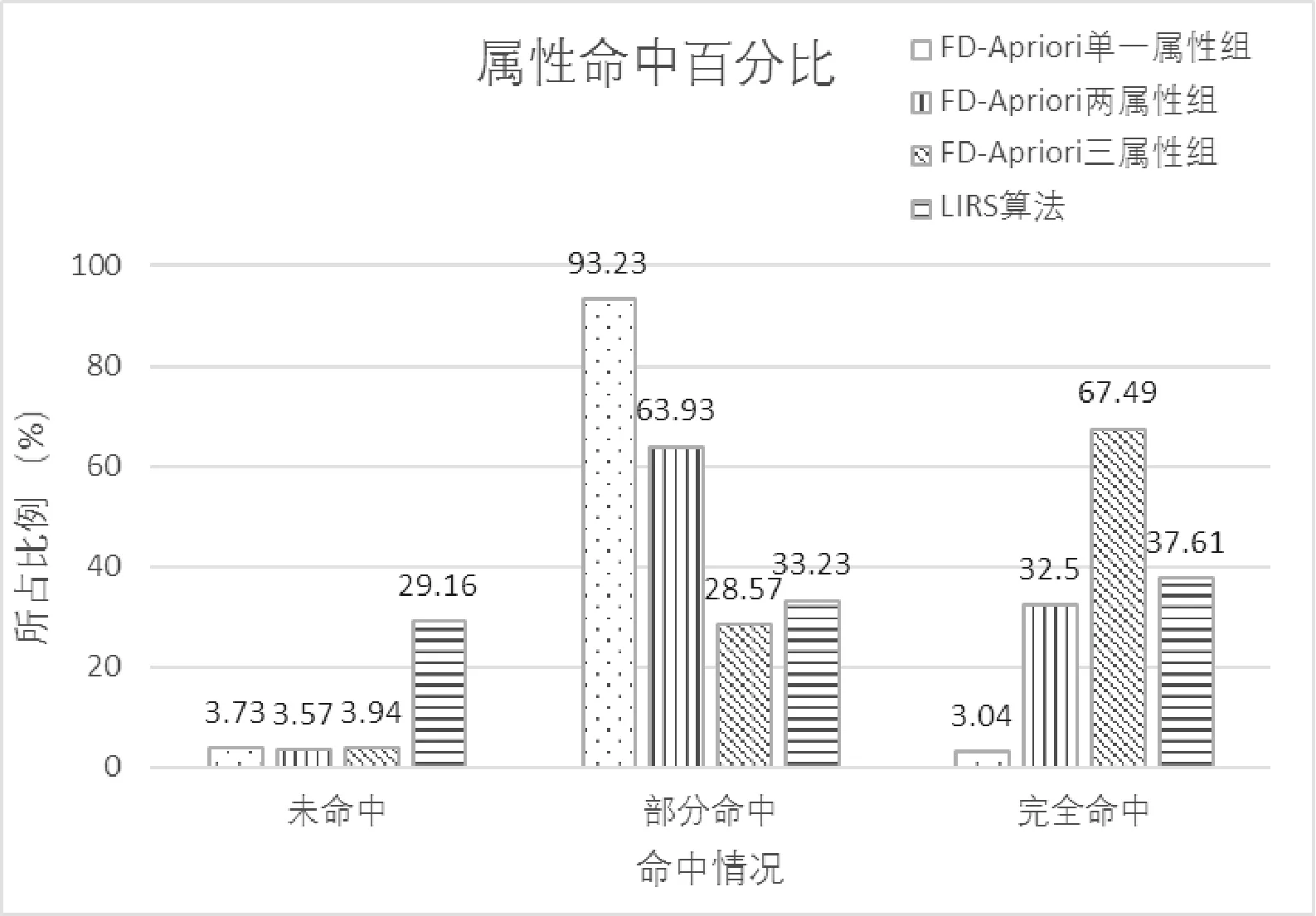
圖5 不同緩存方式屬性命中情況比較
由圖4可知,本文的數據緩存策略在頻繁區域中能夠明顯提高數據查詢效率,而對于其他區域中的數據查詢,由于未做任何處理,故不會影響其上的查詢操作。在圖4中可以發現,LIRS算法緩存策略執行效率低于FD-Apriori算法,當單一屬性時效率差異并不明顯,而當頻繁屬性組增多的時候,FD-Apriori算法的頻繁數據特征將使得目標效率變化較大。從執行效率角度緩存兩、三屬性組相比單一屬性具有更高的查詢效率。這是由于在實際查詢過程中,單一屬性的條件查詢頻率較低,緩存完全命中率不理想,相比于多屬性查詢,單一屬性緩存不能很好地去除不相關記錄,篩選出的記錄規模較大,為之后在數據庫中的索引檢驗工作帶來了巨大的時間開銷。
同時,由圖5可以發現,LIRS算法由于完全沒有考慮到頻繁屬性因素,因此對于命中對比情況的比較較為平均,基本上不能夠支持以數據頻繁度為目標的數據緩存策略。在FD-Apriori算法的支持下,隨著頻繁屬性的數量增多,命中情況有所提高。
此外,盡管兩屬性組緩存相比三屬性組緩存完全命中率相差較多,但其部分命中率高達63.93%。對于屬性組中屬性個數處于中間規模的緩存。盡管犧牲了一部分緩存完全命中率,但該類緩存能夠更出色地完成中間記錄的精簡工作,縮減內存中因部分屬性命中而產生的中間結果集,并根據結果屬性索引快速定位數據,進而減輕數據庫的檢索壓力,取得了更高的查詢效率。圖4中兩屬性組緩存平均查詢效率略高于三屬性組緩存正屬于這種情況。
4 結 語
本文提出了數據查詢過程中查詢頻繁度的概念以及基于Apriori算法的頻繁數據緩存策略。實驗表明,本文的數據緩存策略能夠明顯提高頻繁區域中數據的查詢效率,而緩存數據中的屬性個數以及屬性分組情況則需要根據實際需求做出不同的調整。在進一步的工作中,本研究將對內存緩存中的存儲過程進行優化,減少稀疏數據結構對有限空間的浪費。
[1] Labrinidis A,Jagadish H V.Challenges and opportunities with big data[C]//Proceedings of the VLDB 2012.Istanbul,Turkey,2012:2032-2033.
[2] Bizer C,Boncz P,Brodie M L,et al.The meaningful use of big data:four perspectives-four challenges[J].Acm Sigmod Record,2011,40(4):56-60.
[3] Han J,Haihong E,Le G,et al.Survey on NoSQL database[C]//International Conference on Pervasive Computing and Applications.IEEE,2011:363-366.
[4] 申德榮,于戈,王習特,等.支持大數據管理的NoSQL系統研究綜述[J].軟件學報,2013,24(8):1786-1803.
[5] Memcached Team.Memcached:A distributed memory object caching system[OL].[2015].http://memcached. org/.
[6] Chang F,Dean J,Ghemawat S,et al.Bigtable:a distributed storage system for structured data[J].Acm Transactions on Computer Systems,2008,26(2):205-218.
[7] Ananthanarayanan G,Ghodsi A,Wang A,et al.PACMan:coordinated memory caching for parallel jobs[C]//Usenix Conference on Networked Systems Design and Implementation.USENIX Association,2012:20-20.
[8] GridGain Team.Gridgain:In-memory computing platform[OL].[2015].http://gridgain.com/.
[9] 許祥,羅宇.一種SAN環境下集群文件系統的元數據緩存研究[J].計算機研究與發展,2012,49(S1):240-244.
[10] 周功業,吳偉杰,陳進才.一種基于對象存儲系統的元數據緩存實現方法[J].計算機科學,2007,34(10):146-148.
[11] 秦秀磊,張文博,魏峻,等.云計算環境下分布式緩存技術的現狀與挑戰[J].軟件學報,2013,24(1):50-66.
[12] 劉祖云,胡進德.分布式共享存儲研究[J].成都大學學報(自然科學版),2008,27(1):45-47.
[13] 李文中,陳道蓄,陸桑璐.分布式緩存系統中一種優化緩存部署的圖算法[J].軟件學報,2010,21(7):1524-1535.
[14] Agrawal R,Imielinski T,Swami A N.Mining Association Rules Between Sets of Items in Large Databases[C]//Proceedings of the 1993 ACM SIGMOD International Conference on Management of Data,1993:207-216.
[15] Agrawal R,Srikant R.Fast alg orithms for mining asso-ciation rules[C]//Proceedings of the 20th VLDB Conference Santiago,Chile,1994:487-499.
[16] HBase:bigtablelike structured storage for hadoop hdfs[EB/OL].2010.http://Hadoop.apache.org/hbase/.
[17] Fan Chang,Jeffrey Dean,Sanjay Chemawat,et al.Bigtable:a distributed storage system for structured data[C]//Proceedings of 7th USENIX Symposium on Operating Systems Design and Implementation (OSDI’06),Seattle,WA,USA:USENIX Association,2006:205-218.
FREQUENTDATACACHINGSTRATEGIESINDISTRIBUTEDENVIRONMENT
Yi Su1Yin Huiwen1Zhang Yichuan2Zhang Li2
1(InnovationandEntrepreneurshipCollege,LiaoningUniversity,Shenyang110036,Liaoning,China)2(CollegeofSoftware,NortheasternUniversity,Shenyang110819,Liaoning,China)
Using distributed caching technology can provide high performance and high availability data query in large data environment. The frequent data caching strategies for lightweight applications have the advantages of high efficiency and easy extension. Especially, it is beneficial to improve the query optimization for lightweight distributed database system. Therefore, this research studies the data caching strategies for the recent frequent query data by analyzing the characteristics of user behavior and user query. It can predict the high hit rate of the cache data and improve the efficiency of data query. Firstly, the definition of the frequency of the query was analyzed and given. Secondly, we refined the operation of the user's query according to the influence of the time factor for the cache data. And we dealt with the different cache hits in query process through the data query frequency. Then, we integrated the cached data between nodes. Finally, the experimental results showed that the data caching strategy has a high data hit rate. It also can improve the efficiency of data query. According to the actual needs, the implementation can use different combination of cache attributes, and possesses a good scalability.
Data caching strategy Query frequency Cluster environment Distributed system Big data
2016-11-23。國家自然科學基金項目(61202088);中央高校基本科研業務費專項資金項目(51704003);遼寧省檔案局科技項目(L-2017-X-24);遼寧省高校健康管理協同創新中心資助項目。易俗,實驗師,主研領域:云計算,分布式計算。殷慧文,講師。張一川,講師。張莉,講師。
TP3
A
10.3969/j.issn.1000-386x.2017.08.003
猜你喜歡
甘肅教育(2020年14期)2020-09-11 07:57:42
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
數學大世界(2018年1期)2018-04-12 05:39:14
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
時代英語·高二(2015年1期)2015-03-16 00:08:11
中國衛生(2014年11期)2014-11-12 13:11:32
