硬件加速系統中的PCIe-SRIO橋技術
2017-09-03 10:13:56許家麟韓思齊孫寧霄吳瓊之
電子設計工程 2017年15期
許家麟,韓思齊,孫寧霄,吳瓊之
(北京理工大學 信息與電子學院,北京100081)
硬件加速系統中的PCIe-SRIO橋技術
許家麟,韓思齊,孫寧霄,吳瓊之
(北京理工大學 信息與電子學院,北京100081)
針對一種基于PCI Express和Serial RapidIO混合式互連架構的硬件加速系統,介紹了其中基于FPGA實現的低延遲、多通道、跨平臺的PCIe-SRIO橋接方法。介紹了該PCIe-SRIO橋的邏輯架構,詳細敘述了數據調度方法,給出了系統實現成果以及性能測試結果。該成果解決了標準計算機與硬件加速部件的高速接口問題,比同功能的專用ASIC器件具有更好的適應性以及擴展性。
硬件加速;PCI Express;RapidIO;FPGA
基于混合架構的硬件加速是計算機領域中很重要的研究方向之一。它是指將一些特定的任務從通用CPU移植到硬件處理模塊上并進行相應的算法優化。由于硬件設備的專用結構,這些硬件處理模塊往往比在基于順序指令集的CPU上運行同樣功能的軟件在速度上有大幅度的提升[1]。
文中的主要研究內容是通用CPU和嵌入式計算硬件之間的橋接。這是硬件加速系統的關鍵技術問題之一,既要求較高的傳輸速率,也要求數據類型、長度、通道數量的靈活性。當前,計算機系統多采用PCI Express(PCIe)與外設進行數據交互。而高性能的分布式嵌入式處理系統則多采用Serial RapidIO(SRIO)作為接口標準。實現PCIe總線到RapidIO橋,意味著實現了通用計算機與多結點、多類型的分布式硬件計算子系統的接口能力,為硬件加速系統提供了跨架構的數據傳輸通道。文中介紹了一種基于FPGA的PCIe-SRIO橋接方法,在性能和功能上有效的支撐了大規模硬件加速系統的實現。
文獻3中提出了一種PCI-SRIO的橋轉接技術,重點描述了PCI到RapidIO各種事務的轉接方法,為本文提供了一種設計思路,但是PCI總線已逐漸被淘汰,而PCIe-SRIO橋轉接技術的需求則在各應用領域逐漸顯現出來。文獻2介紹了一種用于CPU與FPGA間DMA通信方案,采用了Scatter Gather的內存管理方法,提高了DMA效率,并且提供了驅動以及API,可應用于Xilinx、Altera的多種FPGA,為本文實現PCIe-SRIO橋接奠定了基礎。文獻4和文獻5分別介紹了FPGA實現RapidIO協議以及RapidIO互連網絡。然而,以上文獻都是在單獨的討論某一方面的具體問題,例如DMA或者RapidIO的實現。相比之下,本文主要從通用計算機與嵌入式處理系統融合的角度上討論如何建立兩個架構間的高速橋接,并進行了系統實現。
1 系統架構
圖1給出了本文所針對的硬件加速系統的拓撲結構。負責橋接的FPGA以PCIe接口連接至計算機,計算機通過DMA實現與FPGA的數據交換。FPGA實現PCIe-SRIO橋接,并將數據交由SRIO路由設備分發至各個SRIO網絡結點進行處理。處理完成的數據則沿原路徑反向傳輸回計算機。
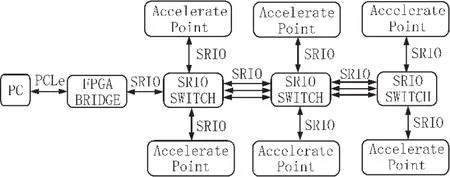
圖1 計算機與嵌入式系統的SRIO互連結構圖
計算機作為此硬件加速網絡的一個終端節點,既是數據源端也是數據輸出端,同時還是整個系統的控制核心。因此,該體系架構要求FPGA實現的PCIe-SRIO橋接具有極高的傳輸能力和靈活性,具體表現為以下幾點:
高傳輸率:傳輸速率應能滿足計算機與計算網格之間的實時數據交換,否則硬件加速的處理能力將失去意義。
多線程:在硬件加速應用中,輸入輸出數據的分集、類型、長度以及依賴關系等等會隨著算法設計而發生很大變化。在軟件上則經常體現為多個不同功能的線程并發工作,每個線程都會有各自的數據傳輸需求。
信令系統:除了高速數據傳輸,橋接設備應該還能實現信令的傳遞,使得計算機可以與某個RapidIO網絡結點進行數據流傳輸的同時對該結點進行監視和控制。
多平臺:應能工作在不同的操作系統下,并且能夠根據具體的網絡結構和數據傳輸需求調整PCIe-SRIO橋的配置。
在工程領域,目前主流的橋接方案是采用專用ASIC 芯片,例如 IDT(Integrated Device Technology)公司的TSI721。然而,固定功能的ASIC在一些特定的應用場合下會面臨諸多問題,例如傳輸線程數較少、溫度范圍窄、可擴展性不足等。文中所選用的FPGA方案與ASIC方案的對比參見表1。

表1 ASIC與FPGA實現實現橋接的性能和功能對比
2 邏輯框架
本系統中PCIe到SRIO的數據搬移、調度和管理均由FPGA邏輯固件實現。邏輯設計可以分成PCIe處理模塊、SRIO處理模塊、橋接模塊3個部分。PCIe處理模塊主要負責與上位機驅動的DMA過程,SRIO模塊負責按照RapidIO協議進行邏輯層的打包并實現傳輸層和物理層,橋接部分則實現以上兩個模塊的對接并且實現數據的調度。整體結構如圖2所示。
PCIe的DMA實現部分,選用了RIFFA(ReusableIntegrationFrameworkforFPGAAccelerators,可復用的集成FPGA加速架構)解決方案。它實現了CPU與FPGA間的DMA傳輸,支持Windows、Linux操作系統,并支持多種計算機編程語言和多種FPGA器件。
SRIO模塊的主要任務是提供RapidIO協議規定的各種事務操作的基本接口。RapidIO協議是一種基于包的數據交換協議。最常用的幾種包格式有:SWRITE(寫數據流)、NREAD(讀數據)、NWRITE_R(有響應寫數據)、NWRITE(無響應寫數據)。其中SWRITE適合于大量數據流的傳輸,與DMA實現對接;NREAD與NWRITE_R適合實現寄存器的讀寫。SRIO模塊主要以Xilinx的SRIO IP核[6]為基礎,接口形式為HELLO FORMAT,展現給用戶為AXI[7]接口。SRIO模塊內部包含3種接口:I/O接口、Message接口、Maintenance接口,其中前兩者又分別獨立為發起端(initiator)、目的端(target),即一共有 5 個獨立的內部數據通道,均為AXI形式。這5個通道與PCIe模塊一側的Endpoint channel1-5分別一一對應。
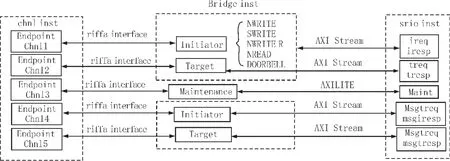
圖2 PCIe-SRIO橋邏輯架構
3 SRIO事務流程
本設計的核心內容是將SIRIO的各個事務操作映射到PCIe和主機端的操作流程。在滿足RapidIO協議的同時,此處我們還需要解決SRIO模塊與PCIe模塊之間的接口適配問題。SRIO處理模塊的接口形式AXI Stream,其數據流傳輸是一種根據tlast信號表征數據流結束的一種無限長度傳輸機制。而PCIe的DMA傳輸是一種定長度傳輸機制。這兩者存在著天然的不兼容問題,給事務流程的設計帶來一定的難度。
同時,為了解決前述的信令需求,在基本的SRIO讀寫操作基礎上擴展了寄存器讀寫協議,將系統中所有的參數、命令、狀態等信令機制全部封裝為寄存器讀寫。這樣一來,橋接模塊需要完成的指令類型就包含了讀寄存器、寫寄存器、讀數據流、寫數據流、維護包操作幾種類型。對于不同的指令類型具體處理流程如下:
1)讀寫寄存器指令:
分別打包為NREAD、NWRITE_R格式,并且使能TX_active信號,狀態機進入接收響應數據狀態,接收數據長度為1。SRIO端的響應接口會分別接收到寫響應以及回讀寄存器值。成功接收到數據后,TX_done拉高,狀態機跳轉至DMA上傳階段,發起長度為1的DMA上行操作,完成一次寄存器讀寫。
2)讀數據流操作:
需要在讀數據流前通過寄存器讀寫來控制遠端SRIO設備發起設定長度LEN的SWRITE操作,然后狀態機進入發起一次長度為LEN的DMA上行狀態,數據量傳輸結束后跳回空閑狀態,完成一次數據流讀取操作。
3)寫數據流操作:
系統中要求遠端設備預知下行數量LEN,因此也要通過寄存器讀寫來控制遠端SRIO設備做好接收數據準備,也可以通過doorbell控制DSP等SRIO設備,這里主要是面向執行硬件加速的FPGA處理板。完成寄存器控制后,狀態機進入DMA下行階段,長度為預先設置的LEN。
4)維護包操作:
類似于讀寫寄存器操作,狀態機進入指令解析后從指令中獲取hop count、地址、數據信息,并通過SRIO IP核完成maintenance打包的AXI-LITE接口實現寄存器讀寫,然后使能TX_active信號,狀態機進入接收響應數據狀態,接收數據長度為1。SRIO端的AXI-LITE接口會寫響應或者回讀寄存器值。成功接收到數據后,TX_done拉高,狀態機跳轉至DMA上傳階段,發起長度為1的DMA上行,完成一次維護包操作。
其中下行的各種包格式在進入SRIO發送模塊之前,會進行邏輯判決。傳輸數據流用的SWRITE包的打包單元是256字節的小包,在傳輸大量數據流時,判決模塊會在兩小包間查詢是否有DOORBELL、NWRITE_R、NREAD 等擁有更高的優先級的包存在,如果有則優先發送這些包,因此系統可以實現在數據流傳輸的過程中讀寫寄存器,訪問遠端設備狀態。
實際系統應用中,實現數據流的上下行傳輸是由一系列寄存器操作和數據流操作完成的。RapidIO協議中常用于數據流傳輸的包是SWRITE,這種包具有最高的打包效率,可以最大限度的提升系統的數據傳輸帶寬,因此在發送數據時選用的是這種包格式。
針對數據流讀取操作,通常是主端發起NREAD來獲取數據流,但是這種打包效率較低。由于FPGA的程序設計是透明的,而且對遠端SRIO設備的控制都處理為寄存器操作,可以輕松實現控制遠端SRIO設備發起數據流寫操作,因此仍使用SWRITE包進行傳輸,再由橋模塊解包并完成數據流上傳。具體流程如圖4所示。
狀態機的設計包容錯誤指令,以流水線的形式實現PCIe指令/數據到RapidIO包的轉換,整個流程的時間開銷為固定的9個時鐘周期(時鐘頻率150Mhz),使延遲量控制在了60 ns,適用于實時性較強的系統。
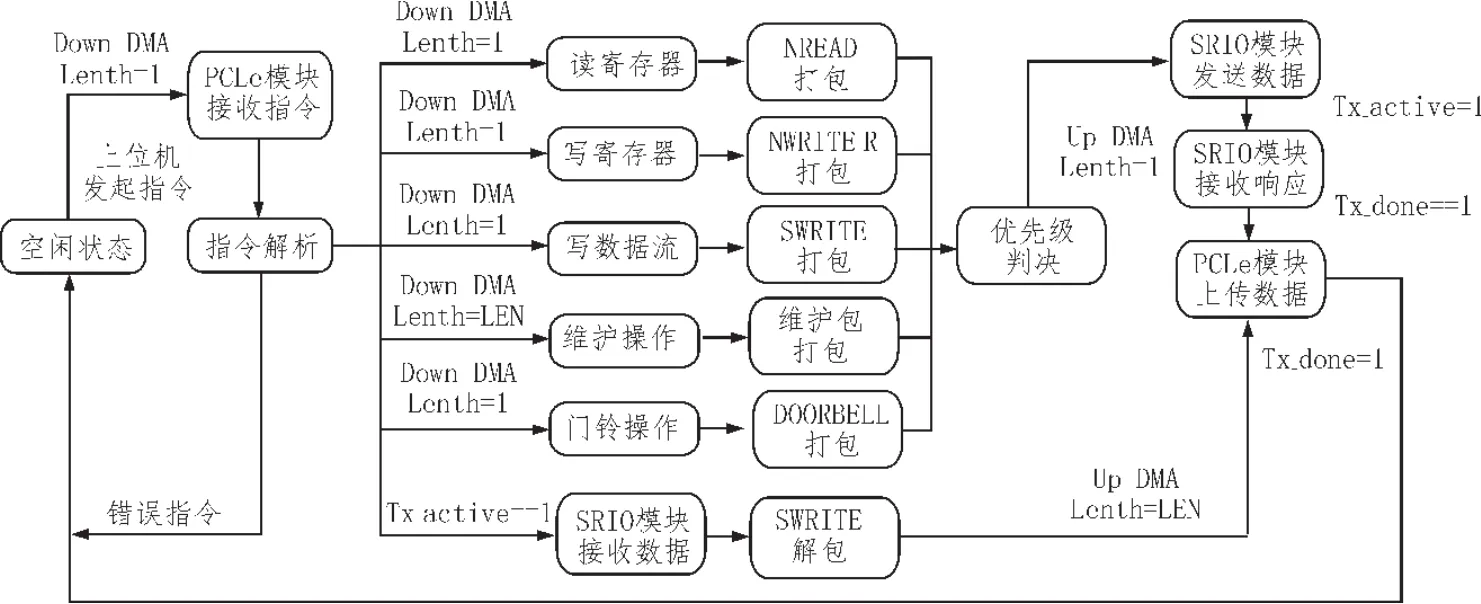
圖3 數據調度處理流程
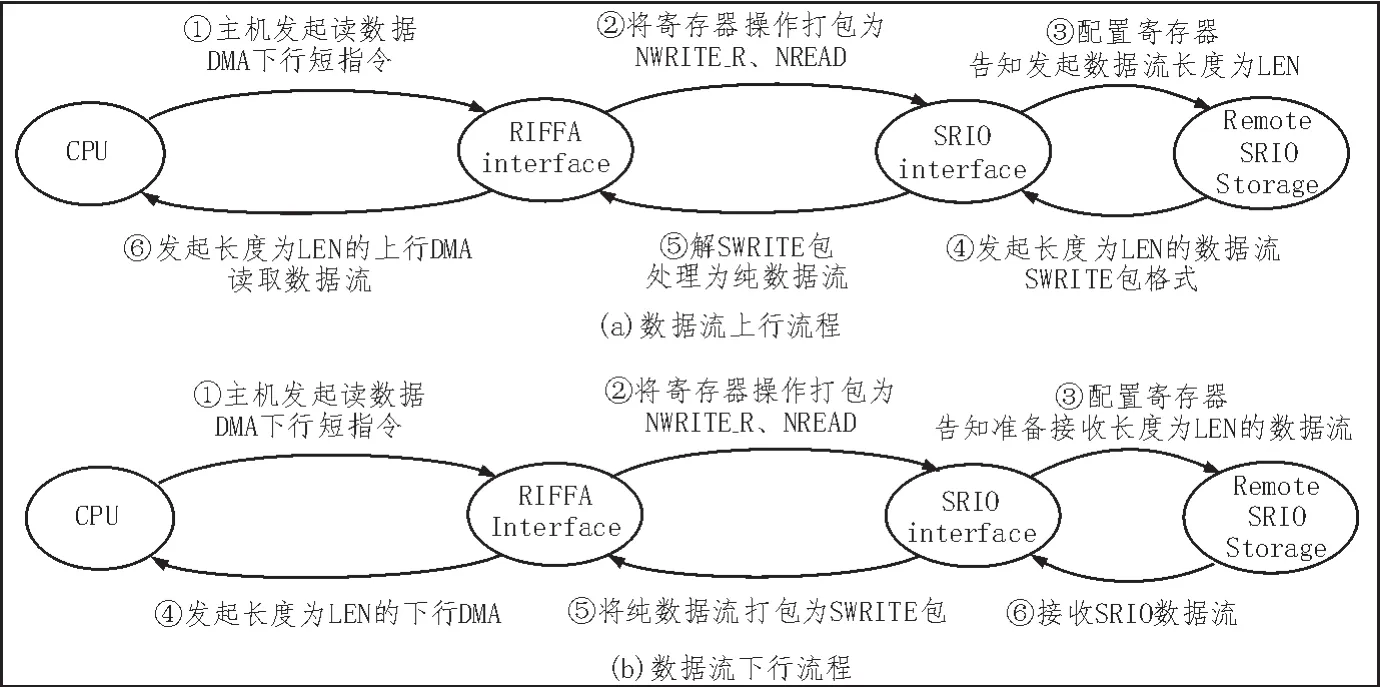
圖4 數據流處理流程
4 系統實現與測試
文中提出的解決方案在某FPGA硬件加速系統中得到了應用。通用計算機搭配PCIe-SRIO橋,通過4X SRIO連接RapidIO路由板卡,進而連接至若干FPGA數據處理板卡。具體的測試系統配置如表2所示。
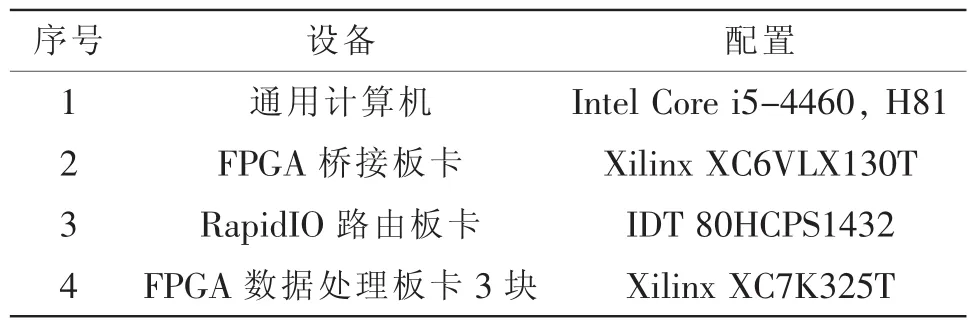
表2 測試系統配置表
基于上述測試環境,計算機通過橋接模塊與各FPGA處理板卡實現數據傳輸,由主機和處理FPGA互發SWRITE數據包來進行上下行速率測試。測試結果如下圖所示,方塊曲線代表SWRITE下行速度隨著包長度變化的趨勢,三角曲線則代表SWRITE上行速度的變化趨勢。測試結果表明,該橋接模塊的上行、下行傳輸在包長度達到16 kB后,即可達到700~800 MB/s的速率;包長度超過1 MB后,則可穩定的達到1 GB/s的速率。
5 結束語
文中展示了基于PCIe DMA傳輸的PCIe-SRIO橋接在FPGA上的實現方法,并給出了系統實現和性能測試結果。RapidIO作為目前高性能嵌入式系統廣泛應用的互連技術,在實踐中會對PCIe-SRIO橋接的功能和性能提出越來越高的要求,而基于FPGA可編程特性使得本文的PCIe-SRIO橋接方案具有非常大的靈活性和可擴展性。我們未來的工作方向有:1)改善數據調度流程進一步提高流數據的傳輸帶寬;2)研究信令系統傳輸能力的改善潛力;3)在國產化FPGA、CPU以及操作系統下實現本系統。
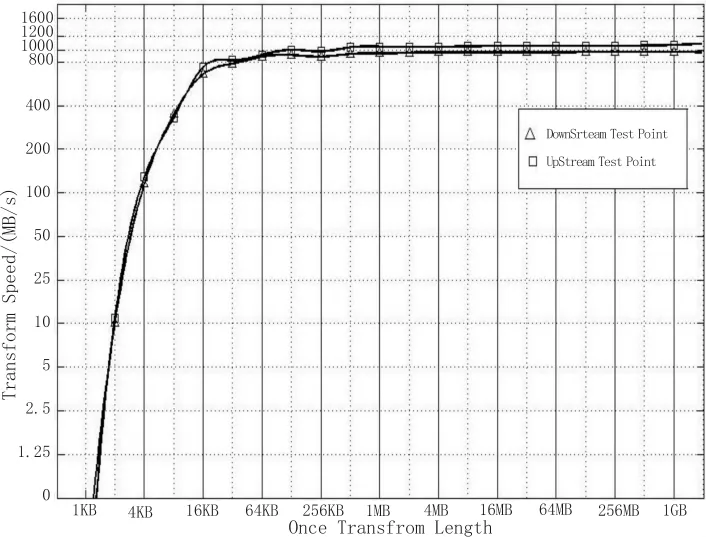
圖5 橋接模塊傳輸數據流的性能測試結果
[1]Possa P,Schaillie D,Valderrama C.FPGA-based hardware acceleration:A CPU/accelerator interface exploration[C]//Electronics,Circuits and Systems(ICECS), 2011 18th IEEE International Conference on.IEEE,2011:374-377.
[2]Jacobsen M D.Smart Frame Grabber:A Hardware Accelerated Computer Vision Framework[D].University of California,SAN DIEGO,2014.[3]Fuller.The Interconnect Problem[J].Journal of the American College of Cardiology, 2015, 65(10):1-12.
[4]ARM, “AMBA AXI and ACE Protocol Specification AXI3, AXI4, and AXI4-Lite ACE and ACELite”, Oct.2011.
[5]王輝球.一種基于FPGA的Serial RapidIO交換設計[J].電子世界, 2014(6):122-122.
[6]秦小娟.SRapidIO總線在通信設備中的應用[D].南京:東南大學,2014.
[7]馮龍輝,張興明,楊鎮西,等.基于RapidIO控制符產生單元設計與實現 [J].電子技術應用,2015,41(11):48-50.
[8]上官珠,范國忠,高文昀,等.基于RapidIO協議的高速數據互聯模塊設計[J].現代電子技術,2014,(15):28-31.
[9]鄧豹.RapidIO交換互連與配置管理研究[J].航空計算技術,2014(2):124-127.
[10]陳剛,張京,唐建.一種基于FPGA的PCIe總線及其DMA的設計方法 [J].兵工自動化,2014(5):75-77.
[11]趙會彬,馬衛平,梁曉英.基于PCIE點對點傳輸的FPGA系統 [J].計算機系統應用, 2014,23(4):201-204.
[12]吳峰鋒,賈嵩,王源,等.一種低時延的串行RapidIO端點設計方案 [J].北京大學學報:自然科學版,2013,49(4):570-578.
[13]陳宏銘,李蕾,姚益武,等.基于AXI總線串行RapidIO端點控制器的FPGA實現[J].北京大學學報:自然科學版, 2014,50(4):697-703.
[14]王維,劉垚,孔超,等.基于RapidIO技術的網絡交換板卡的設計與實現 [J].應用聲學,2012(3):229-234.
[15]母其勇,王永良,高飛,等.基于SRapidIO及PCIe協議的雷達多通道數據光纖高速記錄系統[J].計算機應用, 2015(z2):30-33.
[16]張娟娟,陳迪平,柴小麗.VxWorks下RapidIO互連系統的實現[J].計算機工程, 2011,37(3):236-237.
[17]鄭建,徐海.Serial RapidIO橋接以太網設計和實現[J].微處理機, 2015(1):16-18.
PCIe-RapidIO bridge for hardware acceleration systems
XU Jia-lin, HAN Si-qi, SUN Ning-xiao,WU Qiong-zhi
(School of Information and Electronics, Beijing Institute of Technology, Beijing 100081, China)
This paper presents a hybrid interconnection architecture based on both PCI Express and Serial RapidIO for hardware acceleration applications.It introduces a low-latency,multi-channels and platform-compatibility PCIe-SRIO bridge running in FPGA.This paper introduces the logic architecture of the PCIe-SRIO bridge, describes the data scheduling method in details, and provides the system implementation and performance test results.This PCIe-SRIO bridge can provide high speed interface between standard computers and hardware accelerators,and it has better adaptability and expansibility than ASIC devices with the same function.
hardware acceleration;PCI express;RapidIO;FPGA
TN919.5
:A
:1674-6236(2017)15-0189-05
2016-07-06稿件編號:201607043
許家麟(1992—),男,山東菏澤人,碩士研究生。研究方向:電子科學與技術、信號與信息處理。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
小學科學(學生版)(2021年7期)2021-07-28 06:44:42
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
趣味(數學)(2020年9期)2020-06-09 05:35:08
科技傳播(2019年22期)2020-01-14 03:06:34
科技傳播(2019年22期)2020-01-14 03:06:30
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
消費導刊(2017年20期)2018-01-03 06:26:40
