基于CNN特征和標簽信息融合的圖像檢索
2017-10-19 06:33:55李秀華宋立明
長春工業大學學報 2017年4期
李秀華, 高 珊, 宋立明
(長春工業大學 計算機科學與工程學院, 吉林 長春 130012)
基于CNN特征和標簽信息融合的圖像檢索
李秀華, 高 珊*, 宋立明
(長春工業大學 計算機科學與工程學院, 吉林 長春 130012)
針對基于內容的圖像檢索(CBIR)中圖像底層視覺特征與高層語義特征之間存在的“語義鴻溝”問題,提出了一種基于卷積神經網絡(CNN)特征和標簽信息融合的圖像檢索算法。首先使用CNN模型提取圖像的CNN特征以及標簽信息,然后使用余弦距離分別計算這兩個特征的相似度,最后將這兩個相似度進行加權融合,用作圖像檢索排序準則。在caltech101和caltech256數據集上分別進行實驗,實驗結果表明,所提算法加強了圖像特征與高層語義的結合,大大提高了圖像檢索的查準率。
卷積神經網絡; CNN特征; 標簽; 圖像檢索
0 引 言
隨著Internet的高速發展,圖像信息快速增長,如何從海量的數字圖像集合中快速提取有價值的內容已經成為人們的迫切需求[1]。基于內容的圖像檢索(CBIR)應運而生,它是一門直接從查詢圖像的底層特征(如顏色、形狀、紋理等)出發,通過特征匹配,在圖像庫中找出與之相似的圖像,從而實現檢索的技術。幾十年來,盡管研究者們進行了廣泛的研究,獲得了大量的成果,但仍有一個難題阻礙著CBIR系統的成功,那就是人們熟知的通過機器提取的圖像底層特征和人們所理解的圖像高層語義之間的差距,即 “語義鴻溝”問題[2]。
近年來,深度學習技術得到很大的發展,深層結構將底層特征和通過非線性變換提取的高層特征結合起來,使它有能力學習圖像的語義表示,因此,深度學習有可能成為跨越“語義鴻溝”的橋梁[3-4]。卷積神經網絡(Convolutional Neural Network, CNN)作為深度學習的一種算法,自從被提出后,在圖像視覺等領域得到廣泛的研究,也被證明在一些圖像分類和圖像檢索任務中取得了良好的結果。但是,以往使用卷積神經網絡來做圖像檢索的文章中都僅用全連接中某一層的向量作為特征,沒能很好地結合圖像的標簽語義信息。文中提出一種將CNN特征和標簽信息進行融合的算法,來提高圖像檢索的查準率。
1 卷積神經網絡
卷積神經網絡的思想最早是 LeCun[5]等在1989年提出的,并且成功應用于英語手寫字體識別中。卷積神經網絡是一種多層前饋網絡,包括輸入層、卷積層、池化層和輸出層,每層由多個二維平面組成,每個平面由多個神經元組成。輸入層可直接接收二維視覺模式,如二維圖像,有助于學習當前分類任務最為有效的視覺特征。卷積層為特征抽取層,每個神經元的輸入與前一層的局部感受域相連,并提取該局部的特征。卷積層的計算過程如下:
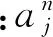
σ(·)----激活函數;
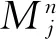
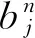
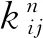
池化層為特征映射層,每個池化層由多個特征映射組成,每個特征映射為一個平面,平面上所有神經元的權值相等。經過池化層,可降低特征的維數,也可防止過擬合。池化層的計算過程如下:
式中:down(·)----下采樣函數,該函數對輸入圖中每個不重復的圖像塊求和,得到輸出圖中的一個點值,每個輸出有個特定的乘性偏置β。
輸出層為全連接方式,該結構可充分挖掘網絡最后抽取的特征與輸出類別標簽之間的映射關系[6]。
2 基于CNN特征和標簽信息融合的圖像檢索算法
提出了一種將CNN特征與圖像標簽信息融合的圖像檢索算法,由于網絡輸出層的輸出為類別標簽,它包含最好的語義信息,因此,將標簽信息融合進CNN特征來進行圖像檢索,可以更好地結合圖像語義,提升檢索的查準率。
1)使用卷積神經網絡模型對圖像庫整體進行特征提取,文中使用網絡模型中第二個全連接層的輸出(fc2)作為圖像的CNN特征,建立圖像特征庫。此CNN特征是輸入圖像的像素經過多次卷積和池化后形成的2 048維或4 096維向量。
式中 :fc1----第一個全連接層的輸出;
w1----權重。
激活函數σ通常使用ReLU函數,表達式為:
同時,文中使用模型中輸出層的輸出(prob)作為圖像的標簽信息,建立圖像的標簽信息庫。此標簽信息是經過softmax分類器后的1 000維向量,代表樣本屬于給定類的概率。
式中:fc3----第三個全連接層的輸出,為1 000維向量;
w2----權重。
2)由用戶向網絡中輸入待查詢的圖像,通過卷積網絡提取出待查詢圖像的CNN特征及標簽信息。提取方法與步驟1)相同。
3)分別計算待查詢圖像的CNN特征與特征圖像庫之間的相似度及待查詢圖像的標簽信息與標簽信息庫之間的相似度,使用余弦距離作為相似度的衡量標準,公式如下:
式中:q----查詢圖像的特征向量;
D----檢索庫中圖像的特征向量;
dist1----待查詢圖像的CNN特征與特征圖像庫之間的相似度;
dist2----待查詢圖像的標簽信息與標簽信息庫之間的相似度。
余弦值越大,說明查詢圖像與圖像庫的相似程度越大。
4)這兩種相似度進行加權融合,形成總相似度,按照總相似度從大到小的準則,返回檢索的圖片,公式如下:
式中: dist----總相似度;
ω1,ω2----權重。
算法流程如圖1所示。
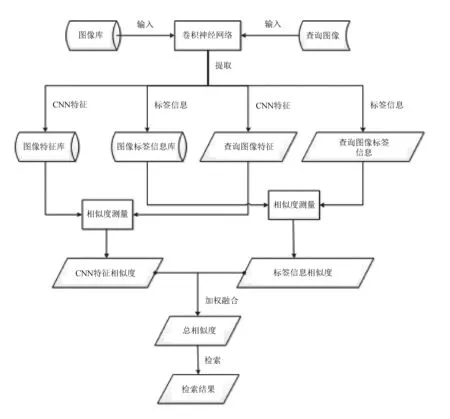
圖1 算法流程圖
3 實驗與分析
實驗使用當前比較流行的ResNet[7]和VGG-F[8]兩種模型作為提取特征的卷積神經網絡,在對相似度進行加權融合時,CNN特征的權重ω1設為0.9,標簽信息的權重ω2設為0.1(此權重配置是經過實驗得到的最優配置)。
3.1實驗數據集
實驗選用了兩個公開的數據集:caltech101[9]和caltech256[10-11]。caltech101數據集總共包含9 144幅圖像,101類,包括動物、車輛、花朵等,這些種類在形狀上有顯著差異,每一類圖像最少包含31幅,最多800幅。caltech256數據集總共包含30 607幅圖像,256類,相比于caltech101,它在物體的大小、位置和形態上都提供了更多的差異,每一類至少包含80幅圖像。
3.2性能評價指標
實驗采用查準率(precision)、查全率(recall)、曲線(PR curve)和平均查準率(mean Average Precision, mAP)作為性能評價指標。查全率反映檢索的全面性,查準率反映檢索的準確性,公式如下:
式中:a----檢索結果中相關圖像的個數;
b----檢索結果的圖像個數;
c----系統中所有相關圖像個數;
Q----查詢圖像集,Q={d1,d2,…,dmq};
Rqk----檢索到dk元素時的排序結果。
3.3實驗結果及分析
3.3.1 檢索實例分析
文中分別在基于ResNet和VGG-F模型的檢索系統中進行了實驗,結果分別如圖2~圖5所示。
(a) caltech101數據集查詢圖像示例 (b) 僅用CNN特征檢索結果

(a) caltech256數據集查詢圖像示例 (b) 僅用CNN特征檢索結果

(c) 僅用標簽信息檢索結果 (d) 使用融合特征檢索結果圖3 caltech256數據集在ResNet模型系統中的檢索結果top30
實驗返回的檢索結果前30張中不相關圖像的張數見表1。
由表1可以看出,使用融合特征時不相關的圖像張數最少,最好時為0張,表明本算法可以提升檢索的查準率。
3.3.2 檢索性能分析
3.3.2.1 平均查準率(mAP)
實驗在兩個數據集上對所有的圖像類別都進行了測試,在caltech101數據集上隨機返回2 000張圖像,在caltech256數據集上隨機返回5 000張圖像,平均查準率結果見表2。
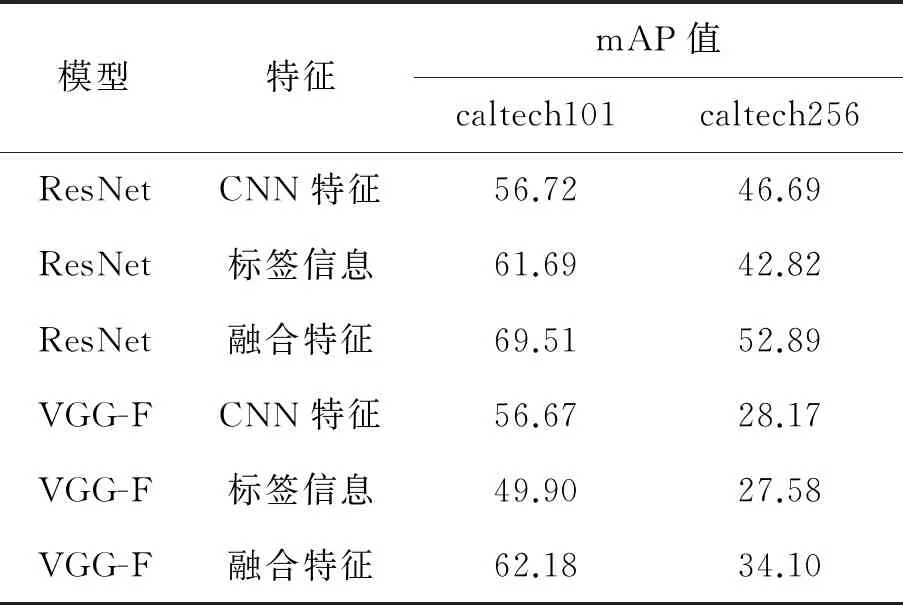
表2 檢索結果平均查準率比較 %
由表2可以看出,在caltech101和caltech256數據集中,使用融合特征的檢索平均查準率均有提升,最少提升5.51%,最多提升12.79%,同樣表明,本算法可以提高檢索的查準率。
3.3.2.2 查準率-查全率曲線(PR 曲線)
實驗在兩個數據集上對所有的圖像類別都進行了測試,在caltech101數據集上隨機返回2 000張圖像,在caltech256數據集上隨機返回5 000張圖像,并設置查全率間隔為0.02,根據查全率計算出查準率。caltech101 和caltech256數據集在基于ResNet和VGG-F模型系統中的檢索PR曲線分別如圖6~圖9所示(橫軸為查全率,縱軸為查準率)。
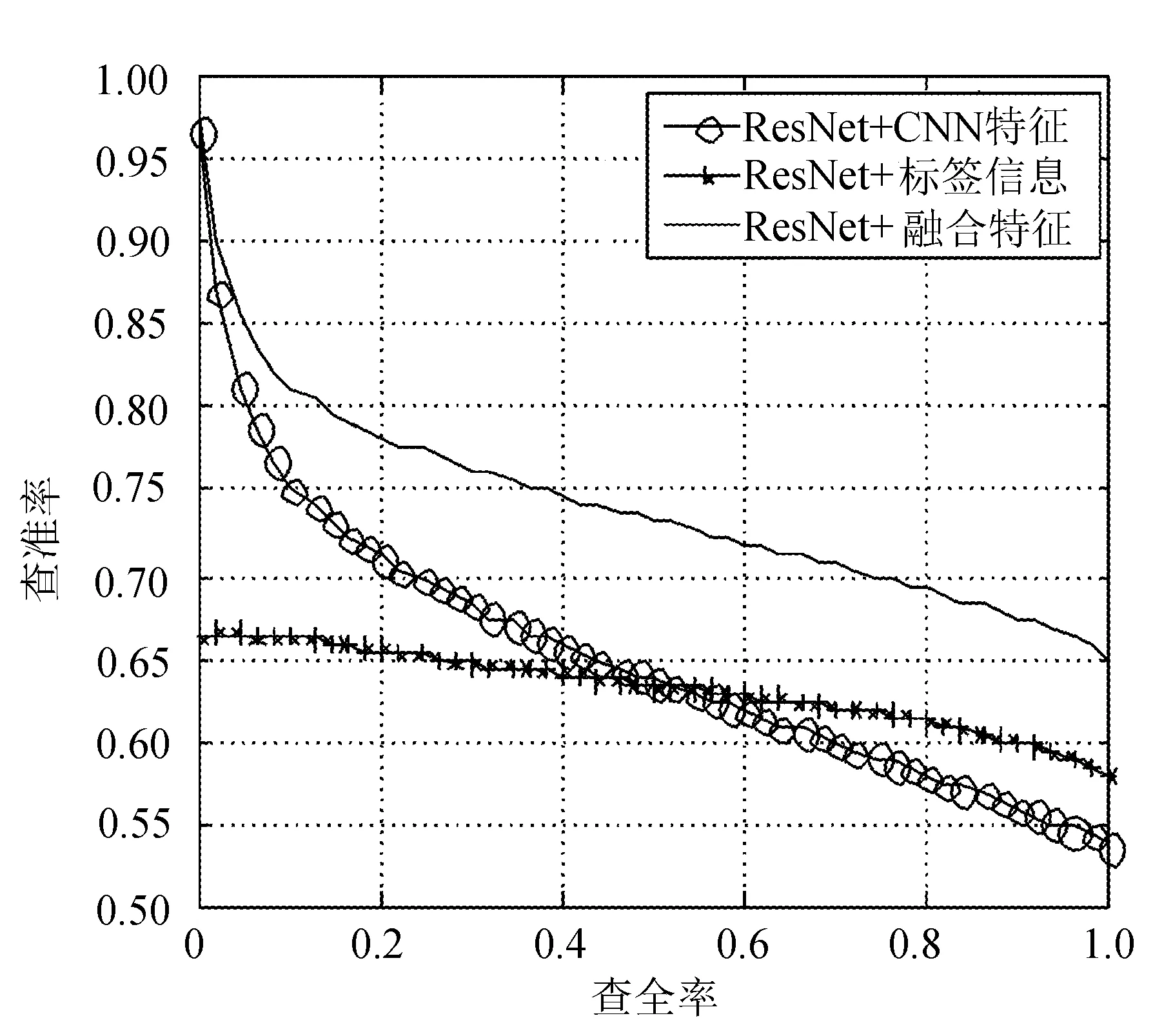
圖6 caltech101在ResNet模型系統中的PR曲線
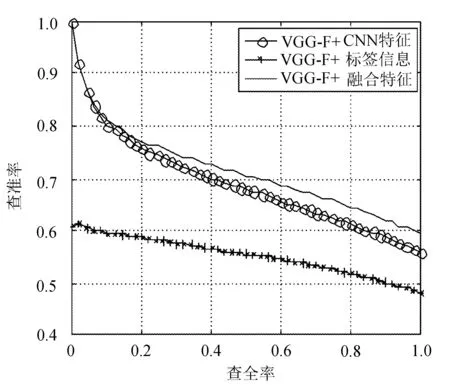
圖7 caltech101在VGG-F模型系統中的PR曲線

圖8 caltech256在ResNet模型系統中的PR曲線
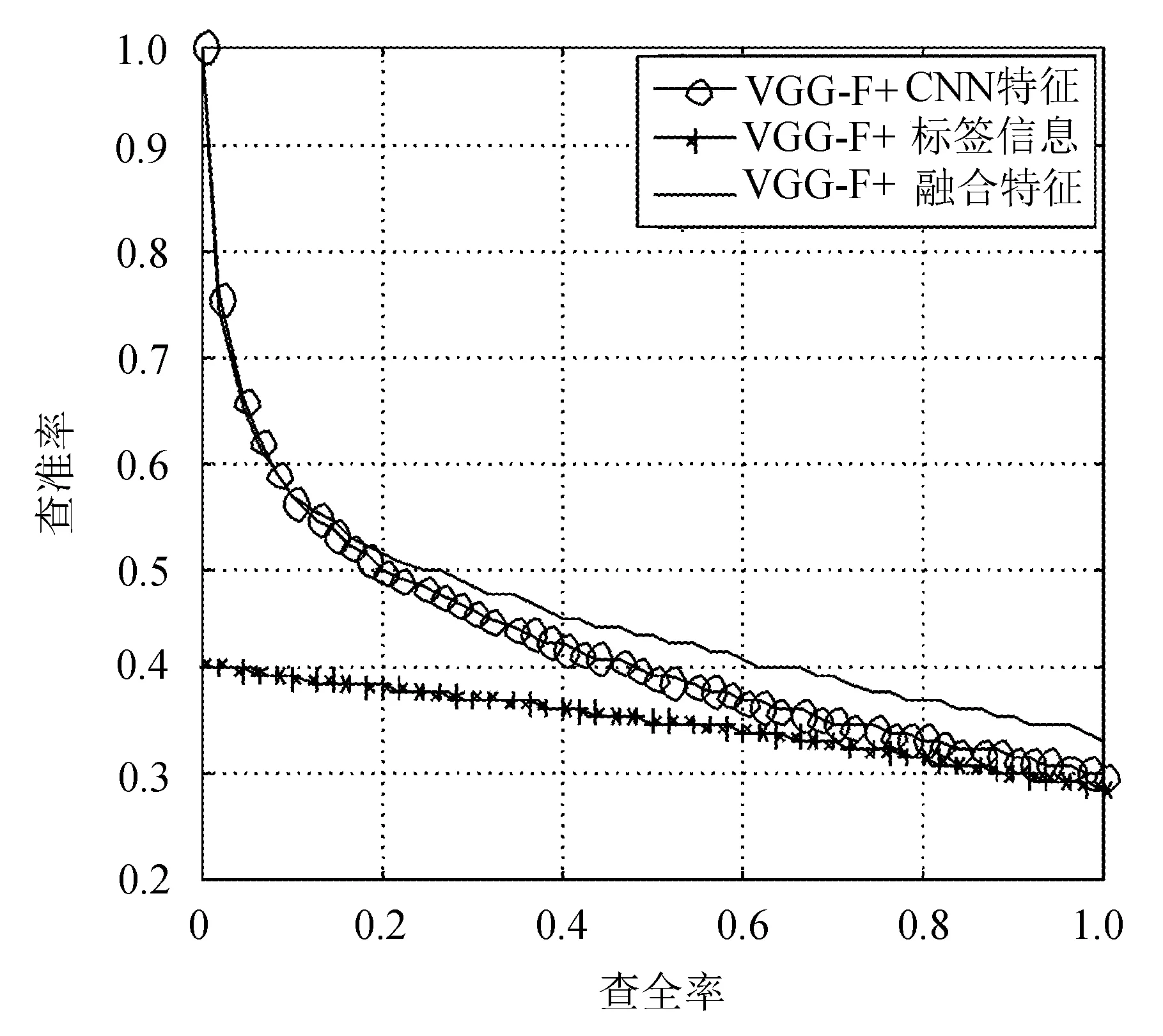
圖9 caltech256在VGG-F模型系統中的PR曲線
從圖中可以看到,當查全率相同時,使用融合特征的查準率均優于僅使用CNN特征或標簽信息的查準率,說明本算法能夠提升檢索的查準率。
4 結 語
提出了基于CNN特征和標簽信息融合的圖像檢索算法,主要對比分析了使用融合特征和僅用CNN特征或標簽信息的檢索查準率。實驗表明,文中算法在ResNet和VGG-F兩種模型里都適用,并且在caltech101和caltech256兩個數據集上檢索查準率都有所提升。文中在進行相似度融合時,只進行了簡單的加權融合,并且標簽信息的泛化能力不是很好,因而影響檢索結果。將進一步研究提升標簽信息泛化能力及融合的方法。
[1] 周明全,耿國華,韋娜.基于內容圖像檢索[M].北京:清華大學出版社,2007:231.
[2] Wan J, Wang D, Hoi S C H, et al. Deep learning for content-based image retrieval: A compre-hensive study[C]//Proceedings of ACM Int-ernational Conference on Multimedia.[S.l.]:ACM,2014,22:157-166.
[3] Wang H, Cai Y, Zhang Y, et al. Deep learning for image retrieval: What works and what doesn′t[C]//2015 IEEE Internat-ional Conference on Data Mining Worksh-op (ICDMW).[S.l.]:IEEE,2015:1576-1583.
[4] 劉兵,張鴻.基于卷積神經網絡和流形排序的圖像檢索算法[J].計算機應用,2016,36(2):531-534.
[5] LeCun Y, Boser B, Denker J S, et al. Backpropagation applied to handwritten zip code recognition[J]. Neural Computation,1989,1(4):541-551.
[6] 謝劍斌,興軍亮,張立寧,等.視覺機器學習[M].北京:清華大學出版社,2015:170-173.
[7] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]// Proceedings of the IEEE Computer Vision and pattern Recognition.2016:770-778.
[8] Russokovsky O, Deng J, Su H, te al. Image Net large scale visual recognition chaccenge[J]. International Jourmal of Computer Vision,2014,115(3):211-252.
[9] Fei Fei L, Fergus R, Perona P. One-shot learning of object categories[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2006,28(4):594-611.
[10] Griffin G, Holub A, Perona P. Caltech-256 object category dataset[EB/OL]. (2007-08-21)[2017-03-21]. http://authors library cattech edu/7694.
[11] 王宏志,劉媛媛,孫琦.基于小波變換矩陣的改進脊波變換圖像去[J].吉林大學學報:理學版,2010,48(1):99-103.
ImageretrievalbasedonthefusionofCNNfeaturesandlabelinformation
LI Xiuhua, GAO Shan*, SONG Liming
(School of Computer Science & Engineering, Changchun University of Technology, Changchun 130012, China)
To solve the “semantic gap” existing between image low and high level semantics in the content-based image retrieval (CBIR), an image retrieval algorithm based on the fusion of convolution neural network (CNN) feature and label information is proposed. First, CNN features and labels of images are extracted using CNN model, and then similarity of both the features and labels are calculated with cosine distance. The fused similarities by weight are used as sorting criteria for image retrieval. Experiments based on caltech101 and caltech256 data sets indicate that the algorithm enhances image retrieval precision by combining the image features and high-level semantics.
convolution neural network; CNN feature; label; image retrieval.
TP 391
A
1674-1374(2017)04-0346-08
2017-03-21
吉林省科技廳基金資助項目(KJT2016-1)
李秀華(1971-),女,漢族,吉林樺甸人,長春工業大學副教授,博士,主要從事圖像處理及智能控制方向研究,E-mail:1156061155@qq.com. *通訊作者:高 珊(1993-),女,漢族,河北石家莊人,長春工業大學碩士研究生,主要從事圖像處理與智能控制方向研究,E-mail:779661456@qq.com.
10.15923/j.cnki.cn22-1382/t.2017.4.06
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
