基于Hopfield神經網絡的云存儲負載均衡策略
2017-10-21 08:22:04劉曉峰
計算機應用 2017年8期
李 強, 劉曉峰
(1.太原理工大學 財經學院,太原 030024; 2.山西省財政稅務專科學校 信息學院,太原 030024; 3.太原理工大學 大數據學院,太原 030024)
(*通信作者電子郵箱122824940@qq.com)
基于Hopfield神經網絡的云存儲負載均衡策略
李 強1,2, 劉曉峰3*
(1.太原理工大學 財經學院,太原 030024; 2.山西省財政稅務專科學校 信息學院,太原 030024; 3.太原理工大學 大數據學院,太原 030024)
(*通信作者電子郵箱122824940@qq.com)
針對當前Hadoop存儲效率不高,且副本故障后恢復成本較高的問題,提出一種基于Hopfield神經網絡(HNN)的存儲策略。為了實現系統整體性能的提升,首先分析影響存儲效率的資源特征;然后建立資源約束模型,設計Hopfield能量函數, 并化簡該能量函數;最后,通過標準用例Wordcount測試,分析8個節點的平均利用率, 并與三個常用算法包括基于資源的動態調用算法、基于能耗的算法和Hadoop默認存儲策略進行性能和資源利用方面的比較。實驗表明,與對比算法相比,基于HNN的存儲策略在效率上分別平均提升15.63%、32.92%和55.92%。因此,該方法在應用中可以更好地實現資源負載平衡,將有助于改善Hadoop的存儲能力,并可以加快檢索。
云存儲;Hadoop;Hadoop分布式文件系統;副本策略;負載均衡
0 引言
云存儲作為云計算的一種重要應用,通過對數據資源的統一化管理,能為用戶提供高可靠性和可用性的大數據存儲方式,受到到商界和學術界的特別重視[1-2]。基于Google云的云存儲服務案例告訴我們,云并不一定建立在大規模和高可靠性的專用機器上,如果通過采用策略算法實施于一群普通PC上,就可以實現廉價的大規模存儲。而這些硬件基礎設施的可靠性并不一定高,一旦發生故障將導致永久性的數據遺失,所以為了提高可靠性,云存儲系統往往采用副本技術來實現數據的冗余備份。副本技術將一個文件復制多份,然后采用算法將這些備份分布在不同的存儲介質上,一方面可以防止存儲設備宕機造成的危害,另一方面可為系統提供負載均衡,減輕單臺存儲造成的性能瓶頸,實現多臺同時訪問,以提高系統的整體性能和可靠性。
在Hadoop文件系統中使用ReplicationTargetChooser類實現副本算法,該默認算法設置3個副本:第一個副本存放在客戶所在的DataNode上;第二個副本放在與第一個副本不同的機架中,并隨機選擇該機架中的一個DataNode進行存放;而第三個副本則存放于第一個副本所在的機架但與第一個副本不同的DataNode中。如果有更多副本則隨機安放在系統的DataNode中。這種分布策略在一定程度上提高了系統的可靠性和負載能力,但這種策略隨機性強,數據均衡性不是很強,所以需要進一步改進副本存放策略以提高系統的負載均衡能力[1]。在默認的副本復制方式下,系統的整體性能并不高,但是在近幾年,云存儲管理方式才得到一些國內外學者的關注。
2010年,國外學者Bonvin等[2]提出了一種可以自組織、故障忍耐,并可縮放的模型實現云存儲。同期間在IEEE的國際會議上,Wei等[3]也提出了一種云存儲簇的概念,使用成本效益合算方法實現動態復制管理。缺省的Hadoop副本存放策略基本上采用隨機方式存放,并沒有考慮各個存儲節點的異構性。為了解決該問題,文獻[4]中提出了依據節點處理能力計算備份的存儲位置,在一定程度上提升了系統的整體存儲性能,主要解決了系統中的異構性問題。2012年,周敬利等[5]提出了一種基于歷史訪問記錄和積極刪除文件的方法來實現數據的復制,實現了文件訪問時間與文件保持一致性之間的代價平衡。文獻[6]中通過使用哈希分布算法實現節點數據均勻分布,同時也實現了負載均衡;但是僅從容量的角度來提升性能,無法滿足異構式分布系統的需求。文獻[7]中依據節點距離和負載能力之間均衡,實現對文獻[6]中的方法進一步改進。2013年,張興[8]提出了一種比較全面的副本存放策略,該方法參考服務器負載均衡的策略,主要從磁盤空間的使用率、磁盤I /O訪問率、CPU使用率和內存使用率來評價系統的負載均衡能力;但是該策略沒有考慮網絡因素和節點的分布方式對系統的影響,所以還有很多發展的空間。2014年,付雄等[9]提出了一種基于分簇思想且采用網絡帶寬和負載均衡的方法來布置副本的技術,并在實驗中得到證實。但該方法是一種靜態簇方法,不能支持簇的動態加入。此外,使用臨時副本技術也增加了管理上的難度。
應用在作業調度中的典型代表技術有粒子群算法、蟻群算法、BP神經網絡、概率神經網絡[10]和霍普菲爾德神經網絡(Hopfield Neural Network, HNN)等。其中,HNN已經成功應用在Job-Shop[11]和多處理器作業調度方面[12]。HNN算法在文獻[11-12]中針對時間約束和資源約束可以很好地結合,并通過實驗結果表明可以達到資源的最佳配置。
在Hadoop分布式文件系統(Hadoop Distributed File System,HDFS)集群中,為了達到每個數據存儲節點之間的負載平衡,往往需要對副本存儲方案進行改進,選擇合適的節點作為目標節點實現副本的存儲。資源的負載平衡問題,其本質就是一個受限資源的分配問題,對應于數學上的NP問題。本文采用HNN來實現副本存儲位置的選擇,進一步提高云節點上數據存儲和檢索的性能。
1 存儲節點的特征
為了可以較詳細地描述系統中某個節點的使用狀況,采用5個指標進行描述,包括CPU平均使用率、內存平均占用率、 I/O平均訪問率、 網絡平均訪問率和磁盤平均利用率。根據經驗和參考其他文獻,選取如表1所示的9個特征參數描述節點狀態。
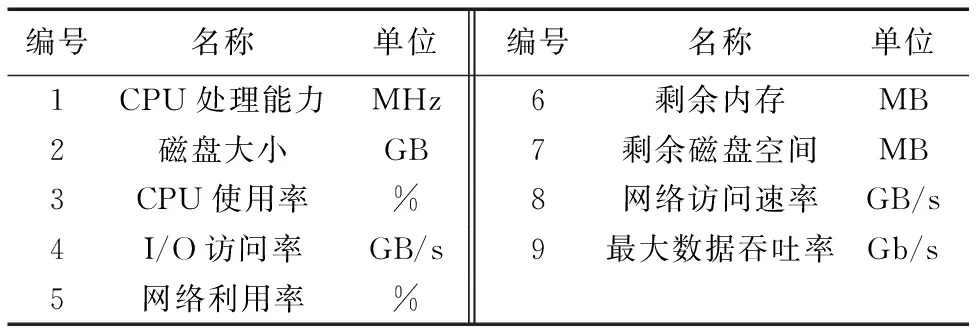
表1 節點特征參數Tab. 1 Characteristic parameters of nodes
2 基于HNN的存儲策略
2.1 約束條件的表達
文獻[13]指出HNN實現優化的本質是求解對應能量函數的極值問題。在求解問題的過程中,首先設計一個能量函數,不斷地改變對應神經元的變量,最終尋找到該問題的極值,也就是該神經網絡達到了穩定的狀態。為了設計該對應問題的能量函數,需要創建函數項,包括目標函數和問題的約束條件。
使用變量Zmln表示為編號為m的數據塊在第l個存儲節點上的第n個磁盤上存放的狀態標識。也就是當Zmln=1時,指明數據塊m在第l個節點上的第n個磁盤上存放,否則Zmln=0。其中:m=1,2,…,M,M為數據塊的最大編號;l=1,2,…,N,N為存儲節點的個數;n為磁盤編號,n=1,2,…,S,S為最大磁盤數。
約束條件1 一個數據塊的副本只能存放在任意一個存儲節點上的一個磁盤中,可以按式(1)表示。
(1)
約束條件2 一個數據塊的副本只能放在一個存儲節點上,可按式(2)表示。
(2)
約束條件3 數據塊m存放需要的磁盤數限制:
(3)
其中:Bm是數據塊m需要的最少的磁盤數。如果式(3)中所需要的磁盤數為Bm時,其值為0,即最小值。
約束條件4 存儲過程中無空閑存儲節點約束:
(4)
該約束項用來保證在存儲過程中不會出現所有的存儲節點閑置。
約束條件5 每個數據塊分配最大磁盤數:
(5)
其中:tm是數據塊m需要存放的最大磁盤量;K(Jmln)為單位步長函數,當Zmln=1,n-tm>0并且K(Jmln)>0時,此項大于0,否則此項等于0。
約束條件6 資源共享競爭互斥:
(6)
針對共享資源競爭的問題,即兩個數據塊存放的相同扇區不能同時使用同樣的資源,如網絡、CPU和具體存儲單元等。在式(6)中,F代表磁盤扇區的總量,t表示存儲時間片,Rmlnhk和Rxynhk分別代表了數據塊m和數據塊x的資源需求矩陣的元素。若Rmlnhk=1,表示在h存儲時間時數據塊m需要資源k,Rxlnhk的作用等同于Rmlnhk。該約束項的作用是保證這兩個不同磁盤的數據不能同時使用資源k。
當滿足以上任意一個條件約束時,該約束對應的約束條件項值為0。聯合以上所有的約束條件表達項,可以按式(7)統一表達所有約束:
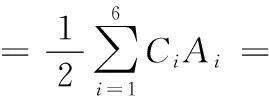
(7)
其中:Ai是各個項的權重因數,并且保證Ai>0。
經過約束條件的組合設置,并設計能量函數,就可以實現優化目標,解決滿足資源要求的分配問題[11]。
2.2 能量函數的設計
HNN具有高度的并行執行能力,可以被用來解決資源的優化組合配置問題。通過將上述約束條件聯合成能量函數,可以滿足李雅普諾夫函數條件,該系統存在穩定的控制狀態,即該能量函數有解[13]。整理式(7)可以得到式(8)。
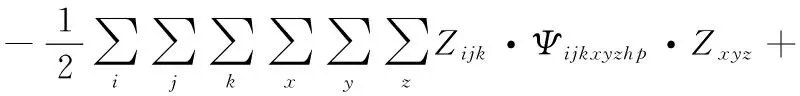
(8)
其中:
(9)
其中:兩個神經元突觸之間的連接強度用ψijkxyzhp表示,神經元閾值用變量ζxyz表示。該問題可由二值狀態的離散型神經元表示,該變量的變化可由式(10)推導得出。
(10)
3 實驗與分析
3.1 實驗方法
為了觀察該基于HNN的存儲策略的性能,采用Hadoop三個標準的用例進行測試,包括WordCount、TaraSort和MRBench,并且與基于資源的動態調用算法、基于能耗的算法和Hadoop默認存儲策略進行對比。本文采用的是預先周期節點情況采樣策略,定期更新HNN的輸入參數,采樣周期為20 s,該方法可以避免動態方法訪問頻率過高,同時也可以減少不必要的I/O開銷。
該系統配置為8個節點,其中一個節點為管理節點,其余7個為存儲節點。網絡參數Ai設置如下:A1=4.1,A2=4.1,A3=1.1,A4=2.3,A5=2.3,A6=4.1;并設置網絡按串行方式迭代200步。
3.2 實驗分析
對比測試結果如表2所示,可以看出與基于資源的動態調用算法、基于能耗的算法和Hadoop默認存儲策略相比,基于HNN的存儲策略在Wordcount用例上分別快178 ms、236 ms和226 ms;在Terasort用例上分別快138 ms、353 ms和523 ms;在MRBench用例上分別快118 ms、324 ms和568 ms。此外,基于HNN的存儲策略、基于資源的動態調用算法和基于能耗的算法在執行效率上比Hadoop默認存儲策略分別可提升55.92%、40.29%和23.04%;與基于資源的動態調用算法、基于能耗的算法和Hadoop默認存儲策略相比,本文推薦的存儲策略在執行效率上分別平均可以提升15.63%、32.92%和55.92%。分析其比較效果是因為基于HNN的存儲策略獨立運行在管理節點上,并不參與存儲,在存儲節點上沒有消耗,所以沒有明顯地增加系統開銷和時間。基于資源的動態調用算法側重于等待時間而輕資源消耗,而基于能耗的算法偏重于資源利用而輕時間消耗,這兩種算法均未能均衡對待時間和資源,導致系統整體開銷增加,時間消耗增大。如某些節點資源處理能力弱卻因等待時間長而被動態算法選擇,事實上處理能力強的節點更加合適,所以會增加整體系統消耗時間;又如異構系統中節點資源不均等,資源多且能耗也大,但是能耗算法將選擇其他資源小且能耗也小的節點,產生非能力分配等情況,反而系統的整體消耗將會增加。所以從總體消耗來觀察,HNN具有顯著優勢。
如表3所示,節點1中的CPU利用率、內存利用率、I/O利用率和網路利用率相對其他節點較高,而磁盤利用率較低,分析其原因為該節點是管理節點,主要維護數據的索引,并不真實存儲數據。同時,可以計算得到7個計算節點的CPU利用率、內存利用率、I/O利用率、網路利用率和磁盤利用率分別平均分布在72.625%、73.12%、66.5%、53.55%和46.5%,且可觀察到該5個指標分布相對均衡。
通過3個用例對四個算法進行相同的測試,如表4所示,基于HNN的存儲策略的I/O平均利用率、網路平均利用率和磁盤平均利用率相對其他算法較低,究其原因為負載均衡后,減少了不必要的I/O和網絡開銷,也就是由于基于HNN的存儲策略針對磁盤參數、I/O參數和網絡參數可以均衡地表達在約束條件中。而基于能耗的算法中CPU平均利用率、內存平均利用率顯著較高,而I/O平均利用率、網路平均利用率和磁盤平均利用率較低,其原因為把大量的運算布置在本地,過度降低I/O的能耗而導致CPU和內存的代價增高。基于資源的動態調用算法的CPU平均利用率、內存平均利用率和磁盤平均利用率相對于其平均利用率和網絡平均利用率較低,其原因是為了實現資源的動態平衡,而在不同節點之間進行數據交換,增大了I/O和網絡的開銷。Hadoop默認存儲策略由于在數據負載平衡之間沒有較準確地按需調配,導致系統的總的開銷都比較大。

表2 幾種算法執行時間對比Tab. 2 Execution time comparison of several algorithms
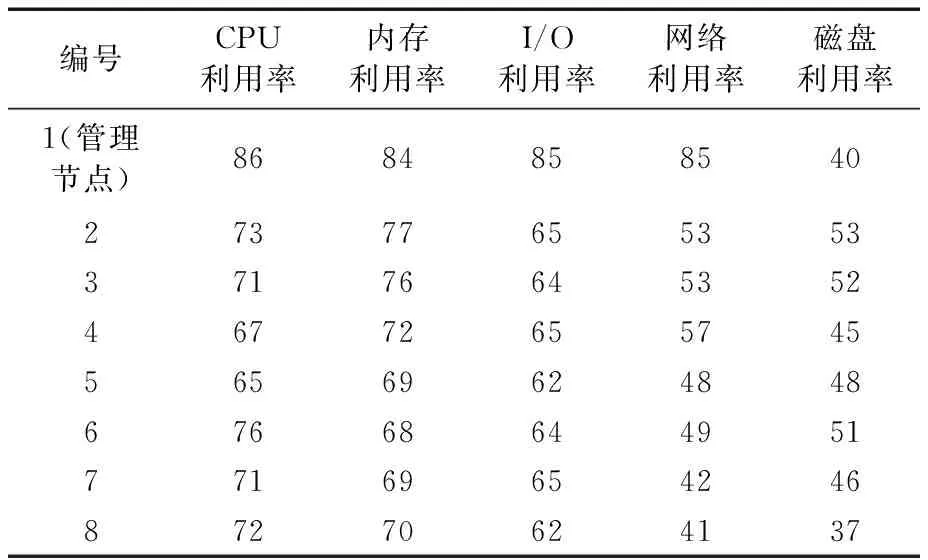
表3 8個節點的平均資源利用率Tab. 3 Average resource utilization rate of 8 nodes
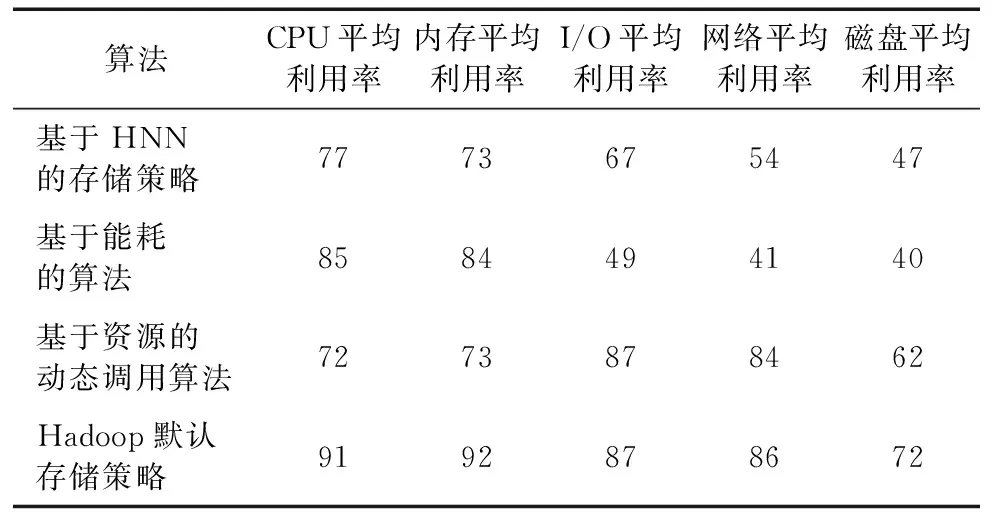
表4 用例的性能比較 %Tab. 4 Performance comparison of use cases %
4 結語
本文首先分析了Hadoop默認存儲策略存在的問題,該問題最終會導致系統負載不均,以及系統恢復數據高成本的缺陷;然后,分析系統各個資源對存放數據的影響,建立一套綜合資源利用模型;最后,使用人工智能HNN技術實現數據存放策略的改進,并通過實驗驗證了該方法可以實現存儲負載均衡,顯著地提升系統的存儲性能和檢索效率。
高彈性的系統能力是云計算的顯著特征,但是在系統規模增大或作業數顯著增加時,現有的云作業調度算法的性能容易達到峰值。如何改進作業調度策略,提升系統的整體作業吞載率,實現作業調度算法的優化,將是我們下一步研究的重點。
References)
[1] BORTHAKUR D. Hadoop [EB/OL]. [2011- 06- 15]. http://lucene.apache.org/hadoop.
[2] BONVIN N, PAPAIOANNOU T G, ABERER K. A self-organized, fault-tolerant and scalable replication scheme for cloud storage [C]// SoCC ’10: Proceedings of the 1st ACM Symposium on Cloud Computing. New York: ACM, 2010: 205-216.
[3] WEI Q, VEERAVALLI B, GONG B, et al. CDRM: a cost-effective dynamic replication management scheme for cloud storage cluster [C]// CLUSTER ’10: Proceedings of the 2010 IEEE International Conference on Cluster Computing. Washington, DC: IEEE Computer Society, 2010: 188-196.
[4] RUAN X, XIE J, DING Z, et al. Improving MapReduce performance through data placement in heterogeneous Hadoop clusters [C]// Proceedings of the 2010 IEEE International Symposium on Parallel and Distributed Processing, Workshops and Phd Forum. Washington, DC: IEEE Computer Society, 2010: 1-9.
[5] WANG Z, LI T, XIONG N, et al. A novel dynamic network data replication scheme based on historical access record and proactive deletion [J]. The Journal of Supercomputing, 2012, 62(1): 227-250.
[6] 周敬利,周正達.改進的云存儲系統數據分布策略[J].計算機應用,2012,32(2):309-312. (ZHOU J L, ZHOU Z D. Improved data distribution strategy for cloud storage system [J]. Journal of Computer Applications, 2012, 32(2): 309-312.)
[7] 林偉偉.一種改進的Hadoop數據放置策略[J].華南理工大學學報(自然科學版),2012,40(1):152-153. (LIN W W. An improved data placement strategy for Hadoop [J]. Journal of South China University of Technology (Natural Science Edition), 2012, 40(1): 153-158.)
[8] 張興.基于Hadoop的云存儲平臺的研究與實現[D].成都:電子科技大學,2013:22-38. (ZHANG X. Research and Implementation of cloud storage plateform based on Hadoop [D]. Chengdu: University of Electronic Science and Technology of China, 2013: 22-38.)
[9] 付雄,貢曉杰,王汝傳.云存儲系統中基于分簇的數據復制策略[J].計算機工程與科學,2014,36(12):2296-2304. (FU X G, GONG X J, WANG R C. A cluster based data replication strategy in cloud storage systems [J]. Computer Engineering & Science, 2014, 36(12): 2296-2304.)
[10] 李強,劉曉峰,賀靜.基于語音特征的情感分類[J].小型微型計算機系統,2016,37(2):385-388. (LI Q, LIU X F, HE J. Sentiment classification based on voice features [J]. Journal of Chinese Computer Systems, 2016, 37(2): 385-388.)
[11] 王萬良,吳啟迪,徐新黎.基于Hopfield神經網絡的作業車間生產調度方法[J].自動化學報,2002,28(5):838-844. (WANG W L, WU Q D, XU X L. Hopfield neural network approach for job-shop scheduling problems [J]. Acta Automatica Sinica, 2002, 28(5): 838-844.)
[12] 王秀利,吳惕華.一種求解多處理器作業調度的Hopfield神經網絡方法[J].系統工程與電子技術,2002,24(8):13-16. (WANG X L, WU T H. Scheduling multiprocessor job using Hopfield neural network [J]. Systems Engineering and Electronics, 2002, 24(8): 13-16.)
[13] HOPFIELD J J, TANK D W. Neural computation of decision in optimization problems [J]. Biological Cybernetics, 1985, 52(3): 141-152.
This work is partially supported by the National Natural Science Foundation of China (61502330), the Scientific and Technological Innovation Programs of Higher Education Institutions in Shanxi (20161131), the Project of Soft Science Plan of Shanxi Province (2016041008- 5).
LIQiang, born in 1980, M. S., associate professor, senior engineer. His research interests include Hopfield neural network.
LIUXiaofeng, born in 1979, Ph. D., lecturer. His research interests include Hopfield neural network.
LoadbalancingstrategyofcloudstoragebasedonHopfieldneuralnetwork
LI Qiang1,2, LIU Xiaofeng3*
(1.CollegeofFinanceandEconomics,TaiyuanUniversityofTechnology,TaiyuanShanxi030024,China;2.CollegeofInformation,ShanxiFinanceandTaxationCollege,TaiyuanShanxi030024,China;3.CollegeofDataScience,TaiyuanUniversityofTechnology,TaiyuanShanxi030024,China)
Focusing on the shortcoming of low storage efficiency and high recovery cost after copy failure of the current Hadoop, Hopfield Neural Network (HNN) was used to improve the overall performance. Firstly, the resource characteristics that affect the storage efficiency were analyzed. Secondly, the resource constraint model was established, the Hopfield energy function was designed and simplified. Finally, the average utilization rate of 8 nodes was analyzed by using the standard test case Wordcount, and the performance and resource utilization of the proposed strategy were compared with three typical algorithms including dynamic resource allocation algorithm, energy-efficient algorithm and Hadoop default storage strategy, and the comparison results showed that the average efficiency of the storage strategy based on HNN was promoted by 15.63%, 32.92% and 55.92% respectively. The results indicate that the proposed algorithm can realize the resource load balancing, help to improve the storage capacity of Hadoop, and speed up the retrieval.
cloud storage; Hadoop; Hadoop Distributed File System (HDFS); replica strategy; load balancing
TP393.027
A
2017- 01- 18;
2017- 03- 10。
國家自然科學基金資助項目(61502330);山西省高等學校科技創新項目(20161131);山西省軟科學計劃研究項目(2016041008- 5)。
李強(1980—),男,山西太原人, 副教授,高級工程師,碩士,CCF會員,主要研究方向:Hopfield神經網絡; 劉曉峰(1979—),男,山西懷仁人,講師,博士,主要研究方向:Hopfield神經網絡。
1001- 9081(2017)08- 2214- 04
10.11772/j.issn.1001- 9081.2017.08.2214
猜你喜歡
江蘇安全生產(2023年1期)2023-02-08 05:58:38
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
中學生數理化·高一版(2020年3期)2020-04-21 08:03:20
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
數學大世界(2018年1期)2018-04-12 05:39:14
資源再生(2017年3期)2017-06-01 12:20:59
