某些體檢指標與冠心病的相關性分析
2017-10-23 16:23:31霍倩倩田翔張艷
學習導刊 2017年2期
霍倩倩+田翔+張艷
摘要:文章通過對得到的醫院體檢數據、門診數據進行分析,將體檢和診斷冠心病建立聯系,并改進數據挖掘算法Apriori算法來進行關聯分析。
關鍵字:數據挖掘;冠心病;Apriori算法;python
1.問題的提出
冠心病是冠狀動脈粥樣硬化性心臟病的簡稱,冠狀動脈供應心臟自身血液,冠狀動脈發生粥樣硬化或者痙攣,使得冠狀動脈變得狹窄甚至是鼻塞,導致心肌缺血缺氧的一種心臟病。冠心病由于其發病率高,死亡率高,嚴重危害著人類的身體健康,從而被稱作是“人類的第一殺手”。所以對于冠心病患者的相關性分析成為近幾年的熱點,如何從已經得到的患者的數據中,找到與冠心病相關的數據,并進一步研究分析,或者與冠心病可能導致成因的數據加以分析,成為人們研究的重點。
據了解目前國內外研究冠心病發病相關因素主要停留在訪談法、A型行為量表測試收集資料法、問卷調查、病歷分析等人工統計、分析階段,鮮有相關資料證明是基于數據挖掘方面的冠心病發病相關因素研究分析的。隨著計算機、網絡技術的發展,獲得有關資料已經變得簡單易行。但是對于數量較大、涉及面廣的數據,僅僅依靠簡單地匯總,按照固定的模式進行分析統計是無法完成這一任務的,甚至是效率低下,得不到相應的結果,所以,一種智能化的,綜合應用各種統計方法、數據庫等的技術應運而生,這就是目前較為流行的數據挖掘。
數據挖掘又被稱為數據庫知識發現,是一種交叉學科,包括統計學、機器學習、數據庫、模式識別等等,它是利用各種方法從海量的凌亂的有噪聲的數據中提取隱含在其中的事先未知的有價值的模式或者規律的復雜過程,其過程包括對于數據庫的建立和管理、提取數據、數據預處理、建立模型、模型評估等一系列過程。在海量數據、高維數據的現在,要注重從數據本身的特征出發,發現數據中隱藏的價值。
冠心病的確診一般最常見的是心電圖,再就是64排CT檢查,通過檢查血管狹窄的情況,來判斷是否患病,且一般沒有預測。之前的研究是基于檢查以及確診以及治療的,沒有對于體檢后是否可以由某些體檢數據得到與冠心病相關列的指標,本文將對冠心病與體檢數據進行關聯分析,本文的數據是由醫院記錄的多年的體檢數據,以及體檢后病人在此醫院就診的數據,對得到的數據進行分析,看冠心病與哪些體檢指標有關聯,希望獲得一些對人類有貢獻的知識。
2.國內外研究進展
冠心病是一種嚴重危害人類健康的常見疾病、多發病癥,已經成為在不同國家和地區發病和死亡的最常見病癥之一。在大多數發展中國家,包括我國在近幾十年對于冠心病之死亡率也大幅度上升,預計到2020年,冠心病將成為全球人口死亡和殘疾的最主要的元兇[1]。
其研究的內容是基于醫學理論的,有脂肪浸潤學說,血小板活化、聚集和血栓形成學說、肉皮損傷學說、炎癥學說等等,大部分研究的是冠心病的發病機制,以及藥物對于冠心病治療的研究,當然也有對于單項發病因素進行研究的案例,例如血漿載脂蛋白與冠心病的相關性研究[2][3] 。
大部分的研究是在醫學領域,對于病理的研究與分析。研究冠心病患者的冠心病危險因素的特點以及臨床表現,探討冠心病病變的相關性。通過對患者各項指標的測量,得到了冠心病的危險因素,包括高敏括高敏C-反應蛋白hs-CRP水平、左心室射血分數等[4]。目前對于揭示冠心病特征的變化規律,揭示冠心病癥候特征的變化規律等[5]。
3.本文研究分析
本文將對從醫院獲得的上萬條病人的體檢數據以及病人的門診確診數據進行研究分析。病人的體檢數據中有很多數據,比如有血、血漿、血清、尿等檢測項目,進一步對于各項又有小的檢測項目,比如光是血清又有兩百多項項目,有HIV,ALD、類風濕因子等等,對于如此巨大的數據量,想要獲得需要的信息,就需要對數據進行處理。
將導出的數據、各種量表及病人的相關數據整理,建立病人的原始資料數據表。此表中包含醫院給出的所有數據,包括冗余數據,無效數據等。進一步需要對得到的數據進行處理。各個表格數據類型不盡相同,且不是對應于每個病人或者體檢者有相應的檢查數據、診斷數據以及住院數據,但是體檢流水號是唯一的,所以對于各個表格進行連接靠著體檢流水號的唯一性進行的。經過對數據的清洗,去重等操作,再進一步查找與冠心病有關的體檢項目。
最終得到患冠心病的患者大部分都檢查了血漿、學液等幾項指標,對于得到的指標,并不是每個病人都檢查了此項內容,再對其中的每一小項進行研究,得到了血漿中與冠心病有關的七個小項,進一步分析得到此項指標比正常人高出兩倍。
4.本文研究方法與步驟
4.1問題的確定
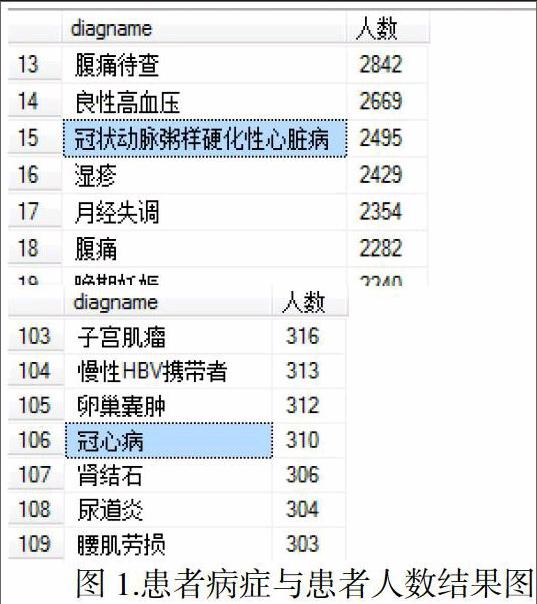
對于從醫院獲得的數據,建立數據庫ceshi,將得到的體檢數據、門診數據以及住院數據分別建立表tj_jy,tj_mz以及tj_zy;由于獲取的數據是雜亂的,且有很多重復的數據,所以先對數據進行簡單的預處理,去除重復的數據,得到新的表ti_jy_qc, tj_mz_qc以及tj_zy_qc。對于得到的結果進行進一步處理,以便確定所要研究的內容。根據三個表格,先查詢得到所有病人所患病癥種類,讓其按照數量降序排列,以便找到要研究的病癥,得到病癥后根據數量的多少來查看哪些具有研究價值,并且選擇自己感興趣的部分進行研究;用sql查詢患者病癥以及患者人數結果如下:
發病率較高的如發燒、咳嗽、高血壓等大多為常見病,且對其的研究已經很全面,則選擇了冠心病作為研究對象,從獲得的數據中冠心病患者大約有兩萬多人,而且冠心病多發生于中老年。冠心病是冠狀動脈性心臟病(coronary artery heart disease, CHD)的簡稱,是一種最常見的心臟病,是指因冠狀動脈狹窄、供血不足而引起的心肌機能障礙和(或)器質性病變,故又稱缺血性心肌病。冠心病是一種由冠狀動脈器質性(動脈粥樣硬化或動力性血管痙攣)狹窄或阻塞引起的心肌缺血缺氧(心絞痛)或心肌壞死(心肌梗塞)的心臟病,亦稱缺血性心臟病。冠心病的發生與冠狀動脈粥樣硬化狹窄的程度和支數有密切關系,同時患有高血壓、糖尿病等疾病,以及過度肥胖、不良生活習慣等是誘發該病的主要因素。冠心病是全球死亡率最高的疾病之一,根據世界衛生組織2011年的報告,中國的冠心病死亡人數已列世界第二位,所以具有研究價值,確定研究對象后進行進一步的研究與分析。endprint
4.2研究對象的確定
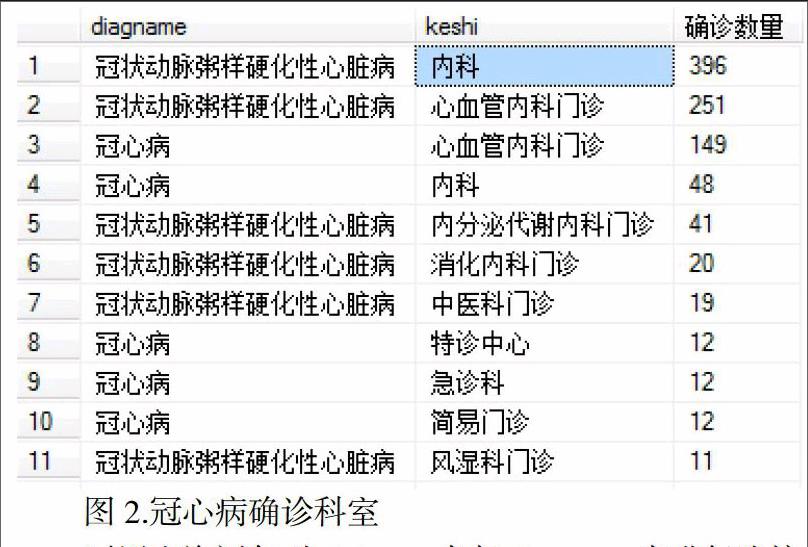
根據選定的研究對象,確定所研究的對象的相關科室以及患者在此之前所體檢的項目;根據查詢確定冠心病確診的門診科室,如下所示:
再用查詢語句對tj_jy_qc表與tj_mz_qc表進行連接,查看患者之前所檢查的項目研究冠心病與哪些體檢項目有關聯,進而研究有何種關聯;根據之前的檢查結果,冠心病的確診是在內科以及心血管內科門診確診,所以限定科室為內科或者心血管內科門診,以便快速的查詢,經查詢在限定科室內得到患者所進行的體檢項目:
注:根據之前查詢結果得到冠心病大部分是在心血管內科門診確診,所以此處限定科室,以便查詢結果,涂黑部分為病人名字,為保證個人隱私,做涂黑處理。
得到兩個表之間是有關聯的,再對兩個表進行連接,查看檢查的項目中冠心病患者主要檢查了哪些項目,經查詢得到大部分患者檢查過的項目有血漿,尿液,全血,血等,對于每個病人檢查的項目中查詢冠心病患者中檢查最多的是哪個,以便去訂研究對象,對上述查詢結果進行保存,可以直接導出到表格xiangguanjiancha.xlsx,建立表xiangguanjiancha儲存得到的結果,再對得到的結果進行查詢檢查最多的體檢項目。
建立xiangguanjiancha表,將之前得到的保存結果xiangguanjiancha.xlsx導入xiangguanjiancha表中,查看患者檢查的項目中哪項檢查數量最多,經查詢得到患者大部分檢查了血漿,下一步則要對體檢值進行研究。
4.3研究對象值的確定
檢查體檢檢驗中,血漿檢查的二級項目有哪些,再對檢查的項目建表,進行研究,
查詢體檢檢驗中所檢查的各個項目的具體小項目,例如血清中檢查了什么,得到查詢結果結果如下:
將查詢結果導出到EXCEl表中,根據SQL的命名規則,是不允許有中文以及不區分大小寫的,所以對于得到的結果進行英文的命名,建立數據字典,將得到的結果建立表格xue_jiang。建立病人表,查詢tj_jy表,將所有的病人導入表格patient中,以便在數據庫中建立patient表,去掉重復的體檢流水號,建立患者表,再將得到的結果保存到一個新表中,作為病人的記錄表patient,建立patient,并將結果導入數據庫中,進一步查詢患有冠心病的患者,將患者數據導入表gxbpatient中,將的到的結果保存在gxbpatient表中便于進一步研究,同時檢查患有冠心病的患者血漿中檢查了哪些指標;得到195個患者血漿檢測的二級項目246個,再對這246個二級項目進行分析,因為并不是每個患者都檢查了這些二級項目,所以大部分為空值,對于空值的處理,首先選擇非空值超過80%的二級項目進行處理,空值超多80%的則忽略不研究,再對得到二級項目的空值進行分析。此處對于表的操作用python處理,Python是一種面向對象、直譯式計算機程序設計語言。也是一種功能強大而完善的通用型語言,已經具有十多年的發展歷史,成熟且穩定。Python 具有腳本語言中最豐富和強大的類庫,足以支持絕大多數日常應用。Python語法簡捷而清晰,具有豐富和強大的類庫。它能夠很輕松的把用其他語言制作的各種模塊(尤其是C/C++)輕松地聯結在一起。所以次出用python處理。代碼見附錄python代碼1。
處理結果如下所示,得到從醫院中獲得的病人數據中患者的體檢項目血漿的二級項目哪些具有研究意義:
分別是xue_jiang表中的第22/30/47/76/90/170/223/248/249項。將這些二級項目取出,保存在表gxbxjz(冠心病血漿值)中;再建立表gxbxjz以便對得到的冠心病患者血漿值二級目錄值進行研究。
經觀測,要研究的血漿的二級項目均為連續值,所以空值的填補用平均值。用python分別對gxbtjz與patient表進行處理,得到所要檢測的二級項目值之間的關系,為了簡易處理,計算二者的平均值進行比較分析。得到結果如下所示。
---病人的平均值:0.647126566 28.99658098 2.04196926 17.54878065 0.520438877 2.38056535 1.110689336 0.029725826 142.3368553
----冠心病患者平均值0.472993197 57.30806608 4.234275996 22.63556851 1.048386783 4.725111759 2.511690962 0.056448008 288.4373178
對比可以得到得到的平均值為普通的兩倍多,其九項的內容分別是:甘油三酯(TG),肌酐(CREA),尿素(BUN),丙氨酸氨基轉換酶(ALT),高密度脂蛋白C(HDL-c),葡萄糖(GLU),低密度脂蛋白C(LDL-c),尿素氮/肌酐(BUN/CR),尿酸(URIC)。
有研究表明冠心病患者[2]的血漿apoB100/apoA1明顯高于普通人群,經相關性分析,載脂血蛋白(高密度脂蛋白C:HDL-c;低密度脂蛋白C:LDL-c)與冠心病密切相關,是冠心病最顯著的獨立相關危險因素,與以往的研究結果相似。與本文檢測內容一致。所以以后病人在體檢時,如果這幾項指標超過正常值,則需要進一步做檢查,查看是否患有冠心病,并且注意調整,以預防冠心病的發生。
4.4數據挖掘在冠心病體檢項目中的應用
根據上面的研究與分析,得到冠心病患者體檢中血漿項目的體檢是較為全面的,下面用數據挖掘算法進行驗證分析得到冠心病與血漿中這些檢驗項是有關聯的。根據前面分析得到的表gxbhzxjjy(冠心病患者血漿檢驗),對它進行預處理,刪除不相關列,比如tjliu、卡號、p_name明顯不相關的直接刪除;因為只有195條記錄但是屬性值有246條,所以進行預處理可以直接在EXCEL表中進行處理,因為空值較多,且空值表示沒有檢驗此項內容的,為簡便表示,做如下替換:NULL賦值為0,陰性、陰性(-)賦值為1,陽性、陽性(-)賦值為2,求每一列的和,值為0表示冠心病患者都沒有檢驗此項,直接刪除,以簡化處理,對于留下的數據,非空值賦值為其屬性值,空值則刪除,得到每項記錄。endprint
為了找冠心病相關聯因素,對數據進行處理,將0值刪除,空值補充為平均值,將結果另存為gai.txt.
5.Apriori算法在冠心病研究中的應用
關聯規則是數據挖掘的一個重要研究方向,其目的是發現大量數據中項集之間的關聯或者相關聯系。挖掘關聯規則就是在大量實物數據中找出用戶感興趣的關聯性,即事務數據庫中滿足用戶給董的條件(最小支持度與最小置信度)的項目集合,我們將這個項目集合成為頻繁項目集,簡稱頻繁集。上述挖掘過程通常分為兩個步驟:一是掃描事務數據庫,從中找出所有滿足用戶指定最小支持度的頻繁項集;而是利用頻繁項集生成所需的關聯規則,分析醒目之間的關聯性。
5.1經典Apriori算法
Apriori算法[6]是挖掘關聯規則的經典算法,由Agrawal等人于1994年提出,是一種具有重要影響的挖掘關聯規則頻繁項集的算法,其核心是基于兩階段頻繁項集的遞推算法,通過候選項集找到頻繁項集。Apriori算法使用一種稱作逐層搜索的迭代方法, 項集用于搜索生成 項集,將Apriori相紙用于茶渣頻繁項集的時候,只要發現一個候選集的飛空自己不頻繁,則可以判斷這個候選集不頻繁[7]。可以將這個過程分為兩個步驟:連接和剪枝。
(1) 連接步:產生候選項集 ;
(2) 剪枝步:掃描數據庫,計算候選項集 中每個候選的技術是否滿足最小支持度來確定 。然而 可能很大,為了減少對數據庫的掃描次數,可以利用Apriori的性質[7]將候選集從 中刪除。
通過以上描述,我們看出監管利用Apriori的性質來減少了對數據庫的掃描,但是依然存在不足:(1)他可能產生大量候選集;(2)他可能需要重復掃描數據庫以計算每個候選集的頻繁程度。所以對于Apriori的改進方法在于降低候選集的數量和減少對數據庫的掃描次數。
5.2Apriori算法的改進
命題1:如果一個數據項在數據庫中是頻繁的,則該數據項的自己在數據庫匯總也是頻繁的。
命題2:如果一個數據項在數據集中是非頻繁的,則包含該數據項的父集也是非頻繁的。
由5.1的描述可知,如果我們從單一元素所構成的集合下手,根據支持度判別條件對該樹進行“剪枝”,將大大降低計算的次數。
得到 后,如果根據組合原理直接生成 然后對每個可能的組合計算支持度,計算量依然很大。這里再次進行剪枝。為了不失一般性,對于 層中的每個集合先排序,然后將滿足以下條件的集合融合,構成 層。之所以這樣做是因為,根據命題2,如果集合C4層的{acde}是頻繁集,那么 層中必定要存在 和 。因此只需在 成對這兩個集合融合即可,不必再將 和 融合,在 層對元素排序的目的也正是在此,快速地找到滿足條件的子集并融合,避免重復計算。
在得到 層后,計算其中每個集合的支持度,需要從數據庫中遍歷所有的數據項看是否包含該集合。假設由 生成 這一規則不滿足置信度公式,回顧置信度的公式,也就是說 在數據庫中出現的次數偏多,而 出現的次數偏少,根據命題1, 的子集也是頻繁項,根據命題2, 的父集也很少出現,從而 生成 等規則的置信度更低,然后將其從集合樹上減去。
通過上面的分析得到算法優化的步驟如下所示:
1). 遍歷數據庫,得到所有數據項構成的并集(也就是得到 層)
2). 計算 層中每個元素的支持度(該過程可用Hash表優化),刪除不符合的元素,將剩下的元素排序,并加入頻繁項集R
3). 根據融合規則將 層的元素融合得到 ,
4). 重復2),3)步直到某一層元素融合后得到的是空集
5). 遍歷 中的元素,設該元素為
6). 按照方法 先生成 層規則
7). 計算該層所有規則的置信度,刪除不符合的規則,將剩下的規則作為結果輸出。
8). 生成下一層的規則,計算置信度,輸出結果。
運行結果如下所示,因為設定閾值不同,導致得到的結果不盡相同,但包含著查詢中體檢項目,綜上,冠心病與血漿檢驗中的ATL,可以得到結論:在日常體檢中,如果ATL值、BUNCR值等比正常水平偏高,則需要進行進一步檢測以及調整近期飲食與注意鍛煉[8]。
參考文獻
[1] 史琦.基于數據挖掘的冠心病不穩定性心絞痛中醫證候識別規律的研究.博士論文,2012年5月
[2] 雷蕾,陳麗.血漿載脂蛋白與冠心病的相關性研究.當代醫學.2011年4月第17卷第12期
[3] 張衛.冠心病患者糖化血紅蛋白、脂蛋白a與冠脈病變程度的關系.2014年碩士論文
[4]高閱春,何繼強,姜騰勇,陳方.冠心病患者冠狀動脈病變嚴重程度與冠心病危險因素的相關分析.中國循環雜志2012年03期
[5]毛靜遠,牛子長,張伯禮.近40年冠心病中醫證候特征研究文獻分析.中醫雜志 2011年11期
[6] 趙建松,陳在平. 基于SQL的Apriori改進算法研究. 天津理工大學學報.209年4月
[7] 顧慶峰,宋順林. Apriori算法在SQL中的改進與應用. 計算機工程與設計. 2007年7月
[8] 閆志虹. 中西醫結合治療冠心病的研究進展. 中國保健營養. 2013年1月endprint
猜你喜歡
現代臨床醫學(2022年4期)2022-09-29 07:38:00
天津醫科大學學報(2021年4期)2021-08-21 02:14:32
昆明醫科大學學報(2021年4期)2021-07-23 01:21:50
基層中醫藥(2020年10期)2020-11-27 01:58:58
智慧健康(2019年36期)2020-01-14 15:22:58
財經(2017年2期)2017-03-10 14:35:35
海南醫學(2016年8期)2016-06-08 05:43:00
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
