基于文獻的地質實體關系抽取方法研究
2017-11-01 06:12:32呂鵬飛王春寧朱月琴
中國礦業 2017年10期
呂鵬飛,王春寧,朱月琴
(1.中國地質圖書館,北京 100083;2.中國科學院大學,北京 100049;3.中國地質調查局發展研究中心,北京 100037;4.國土資源部地質信息技術重點實驗室,北京 100037)
基于文獻的地質實體關系抽取方法研究
呂鵬飛1,2,王春寧1,朱月琴3,4
(1.中國地質圖書館,北京100083;2.中國科學院大學,北京100049;3.中國地質調查局發展研究中心,北京100037;4.國土資源部地質信息技術重點實驗室,北京100037)
實體關系抽取是信息抽取的一項重要內容,通過實體關系的抽取能夠發現文本中的有價值信息。本文在分析和比較了有監督、無監督、弱監督以及開放式等關系抽取方法的原理和特點的基礎上,建立了基于文獻的地質實體關系抽取模型:采用統計語言模型作為關系抽取方式、采用Bootstrapping算法作為關系擴展方式。最后據此進行了關聯關系發現和關系擴展發現實驗。
文獻;關系抽取;統計語言模型;Bootstrapping
進入大數據時代,隨著獲取數據的規模、范圍和深度在不斷寬展和延伸,人們關注的重點開始從起初數據的積累,向挖掘數據的深層次價值、實現數據的“增值”轉變。在成礦預測領域,同樣面臨這樣的問題,地質調查工作的成果基本上是信息性的成果,地質調查工作者在百年的工作實踐中,積累了海量的成果報告、勘查資料、文獻等數據資源,這些數據資源中蘊含著豐富的地質信息,如何在成礦規律和預測的研究過程中充分利用這些數據?如何將數據轉化為新的認識或知識,為地質找礦實踐提供積極的數據支撐。本文論述了一套基于文獻的地質實體關系抽取模型的研究方法,嘗試通過建立地質實體的關聯關系網絡實現發現潛在知識的目的。
1 關系抽取綜述
為了解決從文本數據中獲取有價值的信息,信息抽取技術應運而生。信息抽取被定義為從非結構化信息中獲取結構化數據的過程[1]。信息抽取一般包含兩個任務:實體識別和關系抽取。實體識別是通過自然語言處理技術從文本中提取實體要素,而關系抽取是在實體識別的基礎上結合語義環境提取出實體之間的關系[2]。Etzioni認為關系抽取是分析檢查文本中的實體對,并判斷它們之間是否存在關系[3]。通過實體識別獲得的一個個離散的實體要素對于理解文本語義、發現有價值的知識點毫無幫助。有價值的信息往往是通過實體間的關系來體現的,比如在成礦預測研究中礦種和特定生物的關聯關系、和巖石的伴生關系等。此外,關系抽取在很多領域具有應用價值。例如在檢索系統中,傳統的檢索方式是基于關鍵詞的匹配檢索,而關系抽取技術則可以實現智能語義檢索。比如輸入“石墨烯”不光可以得到關鍵詞里含有石墨烯的文本資料,還可以得到類似“前沿技術”、“知名學者”、“研究機構”等結果。此外,實體關系抽取在自動問答、自動標引、機器翻譯方面具有重要的研究意義。
關系抽取技術路線經歷了從模式、詞典等簡單方法到機器學習、基于本體的關系抽取等復雜方法,從基于分詞、句法等匹配的淺表分析到基于語義的深層分析的發展過程[4]。基于模式和詞典的方式準確率較高,但要求前期制定細致的規則和語料,而且跨領域移植很困難;本體是對信息資源進行語義化和有序化,理想化的本體包含實體及其關系,但由于本體構建需要投入巨大的工作量,目前仍然沒有較為成熟的體系和應用。機器學習采用自然語言處理中的統計語言模型作為基礎,實質上是一個源于數據的模型訓練過程。機器學習的關系抽取方式是通過對大量文本數據進行抽取、轉換、分析和模型化處理,從中自動分析獲得規律,并利用規律對未知數據進行預測,從中提取出有助于關聯分析的關鍵性數據。它的優勢是入手簡易、效率較高。采用機器學習的關系抽取方法按照對人工干預標注數據的依賴的程度可以分為:有監督關系抽取、遠距離監督關系抽取、半監督關系抽取[5]。此外,近來隨著大數據的理念和落地應用日趨成熟,開放式關系抽取方式開始興起,下面分別做介紹。
1.1 有監督關系抽取
有監督的關系抽取方法是最基本的機器學習方法,思路是在已標注的語料上建立機器學習模型,然后使用模型在目標文本里進關系識別。有監督的學習效率較高,但前期需要大量的工作量投入人工標注語料。這種方法的問題在于適用于訓練語料豐富的領域,所以跨領域移植性較弱。其典型算法諸如決策樹、人工神經網絡和支持向量機等算法,已廣泛用于機器學習及模式識別、人工智能等領域中[6]。
1.2 遠距離監督關系抽取
遠距離監督又叫弱監督或無監督,它不需要建立人工標注的關系模型,是以預先定義關系模式和關系實例作為種子,通過機器學習,發現新的關系模板和實例。實現過程首先根據實體對出現的上下文將相似度高的實體對聚為一類,然后選擇具有代表性的詞語來標記這種關系[7]。遠距離監督關系抽取一般基于統計語言模型的關系抽取思想。遠距離監督關系抽取方法克服了費時費力的人工語料標注環節,不需要或需要很少預先處理的語料支撐,能自動地提取文本中包含的實體關系。而且由于不依賴于特定的訓練語料,該方法對各領域的適應性很高。相較于有監督的關系抽取方法,遠距離監督關系抽取方法的缺點是準確率較低。
1.3 半監督關系抽取
顧名思義,人工干預標注程度基于有監督和無監督之間的方法我們稱之為半監督的關系抽取方法,半監督實體關系抽取無需大規模標注語料,只需人工標注少量關系實例,適用于缺乏標注語料的實體關系抽取。最典型的實例是Bootstrapping算法。Bootstrapping源于“重抽樣”的統計思想,即通過現有模式不斷擴展出新的模式,屬于啟發式的方法[8]。
1.4 開放式關系抽取
傳統的關系抽取方式是有“限定”作為先決條件的,限定的范圍包括:目標數據的范圍、實體的類型、限特點定的關系等。而在網絡時代,我們面對的是大量的無規則、開放的數據,因而有學者提出了開放式關系抽取的思想,主要基于以下特點:目標數據開放,不再限定數據的領域范圍和數量;抽取類型開放,不在限定抽取的實體、關系類型。自動識別、分析、抽取語義類型[9]。開放式關系抽取方法是順應大數據時代要求的產物,一經提出引起了廣泛的關注,但至今成熟應用的案例還不多。
1.5 關系抽取方法比較
以上的關系抽取方法各有優缺點,關系抽取方法的選擇需要結合語料準備和應用需要具體問題具體分析,通過比較分析得出以下結論。
1) 由于地質領域缺乏較為齊整的人工標注的地質信息本體,因此排除有監督關系抽取的方法。
2) 傳統開放域抽取的方法基本上都是基于語法分析,而中文的短語結構分析和依存關系分析的水平還未能達到應用的水平。故本項目考慮改進傳統的開放域抽取方法,引入統計語言方法代替語法規則的方法。故采用基于統計語言模型的關系抽取方式。
3) 基于Bootstrapping的方法可以很好的結合人的先驗知識和龐大語料帶來的統計效果,而且便于人去使用和修改,此外結合領域當中的關系專業性較強的特點,借助Bootstrapping方法可以利用龐大的語料對于人為規定的實體關系進行擴展,從而快速實現信息的同種關系抽取。因此,選擇基于Bootstrapping的方法進行關系擴展。
2 實體關系抽取模型研究
2.1 統計語言模型算法
2.1.1 統計語言模型算法研究
統計語言模型最早是由賈里尼克提出,他認為一個句子是否合理,就看它的可能性大小,這個可能性就是概率[10]。簡單來說,統計語言模型就是可能出現的句子或其他語言學單位的一個概率分布。統計語言模型可以形式化統一表示為式(1)。
p(S)=p(w1,w2,…,wn)=
p(S)就是用來計算句子S概率的模型。那么,如何計算p(wi|w1,w2,…,wi-1),最簡單的辦法就是采用極大似然估計(Maximum Likelihood Estimate,MLE),見式(2)。
p(wi|w1,w2,…,wi-1)=

(2)
其中,count(w1,w2,…wi)表示詞序(w1,w2,…,wi)在語料庫中出現的頻率。但由于數據稀疏和參數空間過大,導致實際中無法得到應用。所以,實際中通常采用N元語法模型(N-Gram),它采用馬爾科夫假設:語言中每個單詞只與其前面N-1的上下文有關。假設下一個詞的出現只依賴它前面的一個詞,即二元語法模型(BiGram),則有式(3)。
p(S)=p(w1)p(w2|w1)p(w3|w1,w2)…
p(wn|w1,w2,…,wn-1)=
(3)
理論上講,N值越大計算出來的值精確度越高。但是隨著N值的增大,模型的復雜度也越大[7]。具體來說計算p(w1)、p(w2)很容易,但是當N=3時,計算p(w3|w1,w2)已經有些困難了,當N>3時,計算量將變的非常大。所以對于N的選擇:理論上越大越好;經驗上Trigram(三元模型)用的最多;原則上能有Bigram解決的,就不用Trigram。
2.1.2 構建基于統計語言模型的關系抽取模型
在實驗中采用三元語法模型,滿足二元馬爾科夫假設。具體操作步驟如下所示。
1) 分詞,對每個句子進行分詞;過濾出名詞、動詞和介詞。
2) 對關系詞進行過濾,過濾出不及物動詞(例如,奔跑)以及以人為主語的詞(例如,看見)。
3) 獲得關系三元組可能集合:句子中所有n-v/p-n結構的三元組,不考慮相鄰關系。
并計算獲得的所有三元組的聯合概率作為該三元組的得分(用二元語法模型);獲得關系三元組的候選集合:找出得分最高的n-v/p-n三元組作為候選的關系三元組。
4) 確定關系三元組:通過規則,對關系三元組的候選集合進行過濾,得到關系三元組,目前主要通過兩條規則進行過濾:對于抽取出來的n1-(v/p)-n2結構,如果n1和n2之間距離超過5,我們認為這個關系較弱而舍棄;對于抽取出來的n1-(v/p)-n2結果,如果n2后面是一個動詞,我們認為這個關系抽取的不完整故舍棄。例如:“我對他說,明天放假”,會抽取出來“我-對-他”的關系三元組,而這個關系不完整。
5) 關系三元組置信度計算:加入評分函數,計算抽取的關系三元組的置信度。評分函數利用統計語言模型統計關系對出現的次數,并參與聯合概率計算:如式(3)所示,語言中每個單詞只與其前面n-1的上下文有關。接下來的關鍵問題就是如何計算Pp(wn|wn-1)。現在有了大量機讀文本后,這個問題變得很簡單,只要數計算(wn,wn-1)在統計的文本中出現了多少次,以及wn-1本身在同樣的文本中前后相鄰出現了多少次,然后用兩個數相除就可以了p(wn|wn-1)=p(wn,wn-1)/p(wn-1)。
關系抽取流程如圖1所示。
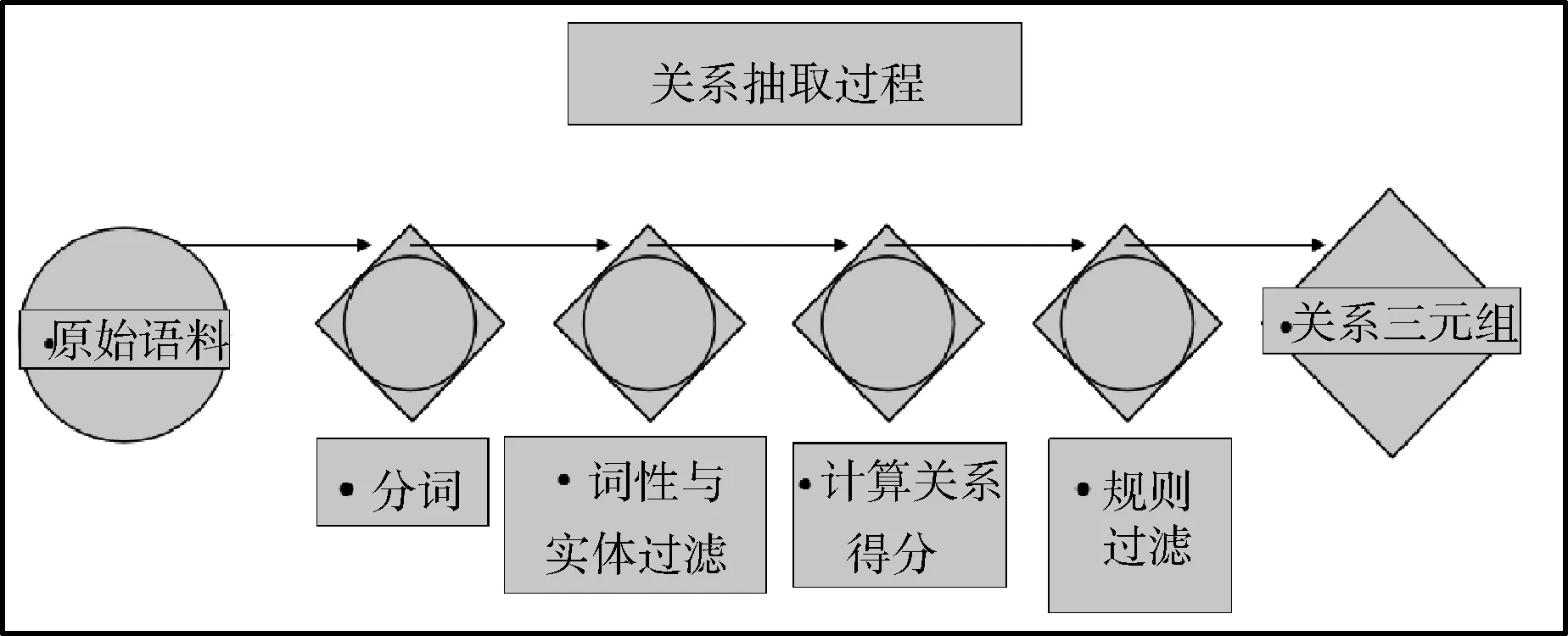
圖1 基于統計語言模型的關系抽取模型流程圖
2.2 Bootstrapping算法
2.2.1 Bootstrapping算法研究
統計語言模型解決的是關系抽取的問題,而Bootstrapping解決的是關系擴展的問題。Bootstrapping首先利用少量已標記樣本的特征及其結果度量建立初始學習模型,主要的思路是通過人工指定幾個初始的種子,隨后系統會尋找滿足人工提供種子的句式模板,利用得到的模板找到新的種子不斷的迭代下去,最終達到舉一反三的目的。該方法的缺點是對初始關系種子的質量要求較高。比如我們現在知道“中國-北京”,“美國-華盛頓”兩個國家-首都的關系,但是還想知道所有其他的國家-首都關系,那么就可以用Bootstrapping方法,以“中國-北京”,“美國-華盛頓”為基礎,可以找到語料中幾乎所有的國家-首都關系。
2.2.2 構建基于Bootstrapping算法的關系擴展模型
依據Bootstrapping算法的基本思想,設計算法流程共分為以下幾個步驟:上下文構建階段、模板抽取階段、候選種子抽取階段和候選種子評分階段。
1) 上下文構建階段。上下文構建階段主要是利用一種前綴字典樹的數據結構來存儲種子的前后的文字,在抽取上下文的時候,只選擇在同一個分句當中的內容即任何標點符號都作為邊界處理。前綴字典樹是一種壓縮存儲的數據結構,他的特征在于父節點是子節點的前綴。構造兩個字典樹,分別存儲種子之前的文字和之后的文字。
2) 模板抽取階段。模板抽取階段主要是利用上下文構建得到的兩個字典樹,找到滿足所有種子的最長的句式模板。
3) 候選種子抽取階段。候選種子抽取階段主要是利用找到的句式模板,在整個語料中找到滿足句式句子并利用句式抽出去對應位置的種子,作為候選種子。
4) 候選種子評分階段。候選種子評分階段主要是利用隨機游走的方法從圖中進行迭代直到到達圖中的任何一點的概率收斂。在這里的圖的結構如下:共有三種類型的節點,分別為文檔、句式和候選種子,文檔和句式之間的關系是包含,句式和種子之間的關系是抽取,文檔和種子的關系是含有。具體如圖2所示。
在具體算法的實施過程中,首先由人工給出2~3個種子,每次迭代的過程中,從已有的種子集合中抽取三個種子并加上上一次迭代得到的分數最高的種子作為本次迭代的初始種子,利用上述的四個階段提取種子,每次僅選取最高的一個加入到種子集合當中。具體抽取流程如圖3所示。
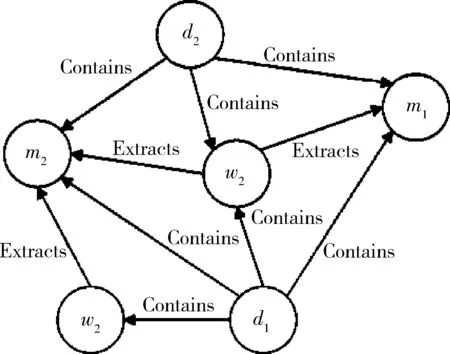
圖2 種子評分所采用的隨機游走方法結構圖
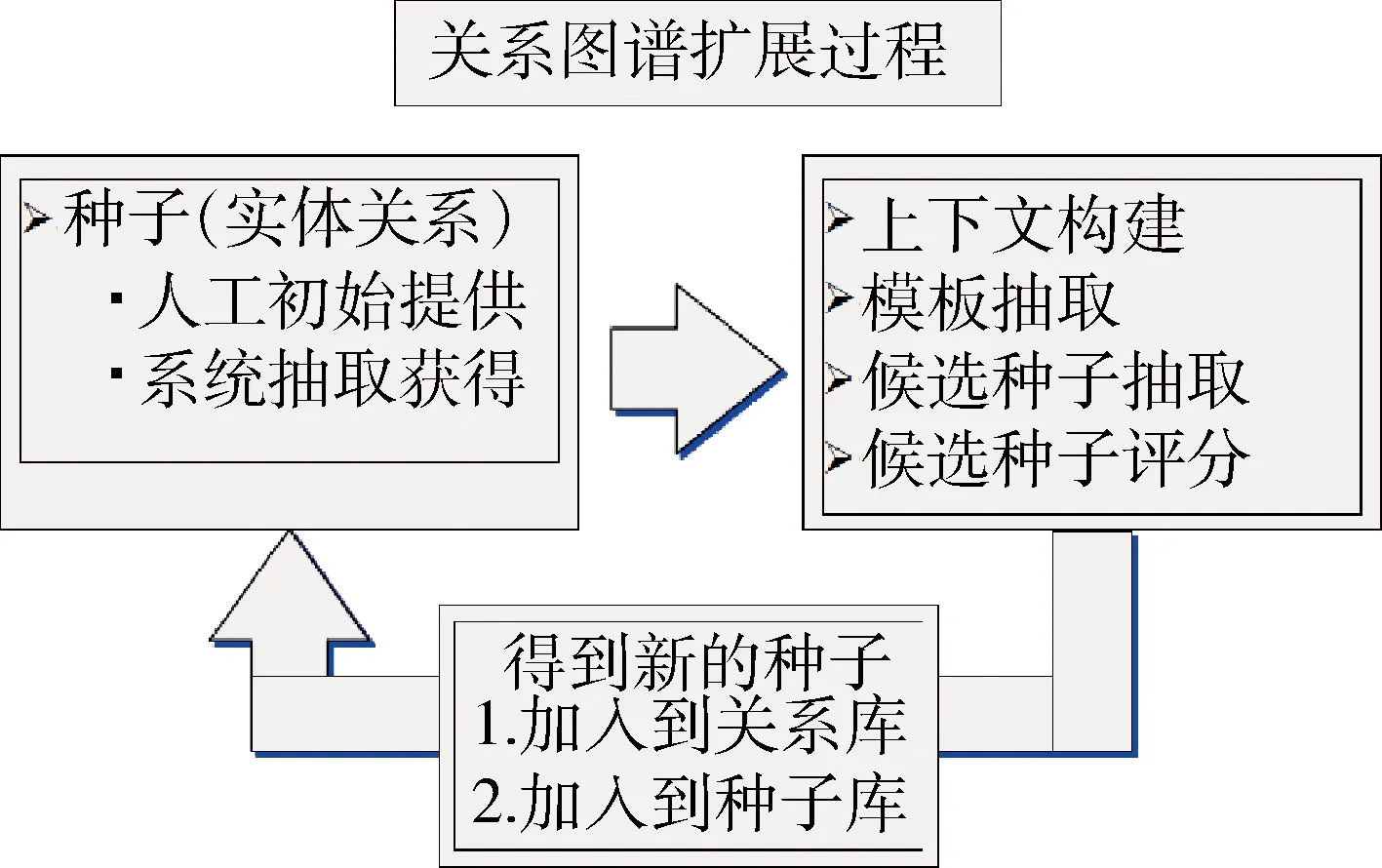
圖3 基于Bootstrapping算法的關系擴展模型流程圖
3 關系抽取實驗
實驗的目的是從文獻數據中發現潛在的關聯關系,建立實體間的關聯網絡,為成礦預測工作提供未被發現的、有價值的新知識點。根據前期需求調研,本次實驗將圍繞發現并驗證“金礦”和“生物”兩個領域間的關系展開。
3.1 數據源準備
目標數據源主要有兩類:第一類為生物和金礦會議文獻,生物會議文獻約44 640篇,金礦會議文獻約1 647篇,大小共約457 M;第二類為生物和金礦期刊文獻,生物期刊文獻約387 660篇,金礦期刊文獻約28 740篇,大小共約9.54 G。文獻類型為txt類型。
3.2 實驗環境
1) 服務器配置:CPU:Intel Xeon E5-2609 V3,內存:24 GB。
2) 操作系統:RedHat 4.4.7-4(Linux內核版本2.6.32) 64位。
3) 數據庫:MySQL 5.6。
4) 分布式搜索引擎:ElasticSearch2.3.4。
5) 開發環境:MyEclipse 2015、Java版本:1.8.0.131。
3.3 關聯關系發現實驗
3.3.1 實驗描述
發現“金礦”與“微生物”領域關鍵詞之間的關聯關系。
3.3.2 實驗步驟
1) 獲得候選關系對集合,在詞典里提取金礦和微生物詞表,并進行兩兩配對。
2) 獲得可能關系對集合,挑選出語料中關系對至少同現10次的關系對和所有同現的語句。
3) 確定關系,采用統計語言模型的方法在關系對同現的語句中抽取關系詞,用來表達關系對的關系。每個同現語句至多抽取一個關系,每個關系對可能有多個關系詞,這些詞統統保留(因為是關系發現,沒有足夠的證據表明哪個關系詞是錯誤的)。
4) 關系過濾,對于句子中關系對距離過遠的關系丟棄。
3.3.3 實驗結果
實驗結果如圖4、圖5所示。
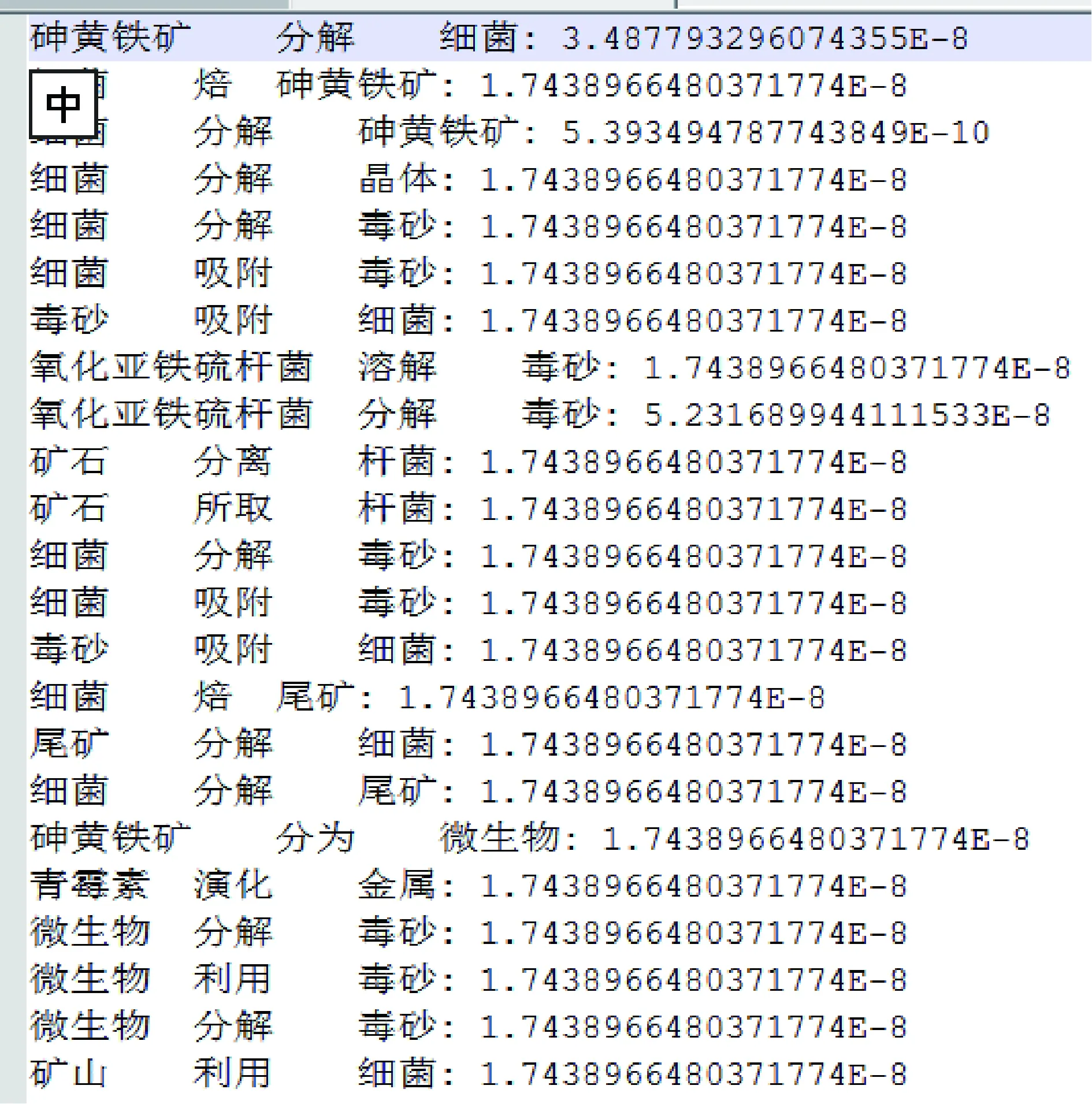
圖4 “金礦”與“微生物”關聯關系發現結果
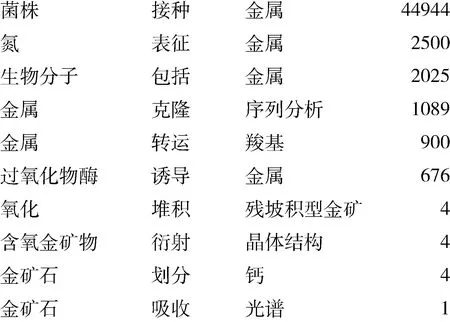
圖5 “金礦”與“微生物”關聯關系發現結果改進
在隨后的實驗中,考慮到此次研究的目的是新知識發現,限定關系對至少出現10次以上并不能很好的發現新知識(出現頻次高的一般不是新知識),故在實驗中取消了至少出現10詞的過濾規則。
3.3.4 實驗分析
本次實驗的目的是發現分析“金礦”和“微生物”間的關系,驗證并完善基于統計語言模型的關系抽取模型。下一步改進方向包括以下兩方面。
1) 無用關系去除。可以通過不斷完善停用詞表來實現。
2) 關系的歸類分析。在目前的統計語言模型中沒有考慮關系的歸類,遍歷出的關系維度很大,考慮引入基于業務專家指導的關系聚類技術,提高模型的實用性。
3.4 關系擴展發現實驗
3.4.1 實驗描述
驗證基于Bootstrapping算法的關系擴展模型,主思路如下:提供兩對關系對(種子),模型將會自動擴展這兩對關系對,并根據提交的關系對(種子)進行搜索,查詢到由此生成的句式模板和候選集合(候選關系)。根據篩選得到的候選集合(候選關系)進行判定。
3.4.2 實驗步驟
1) 關系對(種子)提交。人工提交一個關系對(種子),模型自動識別判斷交的關系對(種子)關系。
2) 定義抽取模板。根據關系對(種子)抽取一個模板,再根據這個模板抽取其對應的候選關系,如發現新關系在進行種子提交和定義新抽取模板,如此循環,直到再也無法抽取出模板為止。
3) 句式模板抽取。根據模板中的兩個關系實體通過Elastic Search(IK分詞器的Elastic Search搜索引擎,下同)來搜索文獻中包含這兩個實體的句子。只要輸入的關系實體之間有相關關系,則這兩個關系實體可以抽出至少一個模板。當兩對關系都被抽取過模板之后,需要對模板集合中的對應字段進行檢索,僅保留對應于兩個種子的模板。最后利用得到的模板進行候選集合(候選關系)的抽取工作
4) 候選關系對抽取。根據待抽取模板在Elastic Search中查找包含該模板的句子。再利用模板的類型和內容決定需要過濾的部分,過濾掉多余的字符串,只保留生成的關系。
5) 關系判定。然后對生成的關系進行清理,除去不完整的關系對(如關系實體殘缺、關系實體有標點)。
3.4.3 實驗結果
輸入“礦石-黃鐵礦”、“礦石-黃銅礦”關系對作為種子。實驗結果如圖6所示。
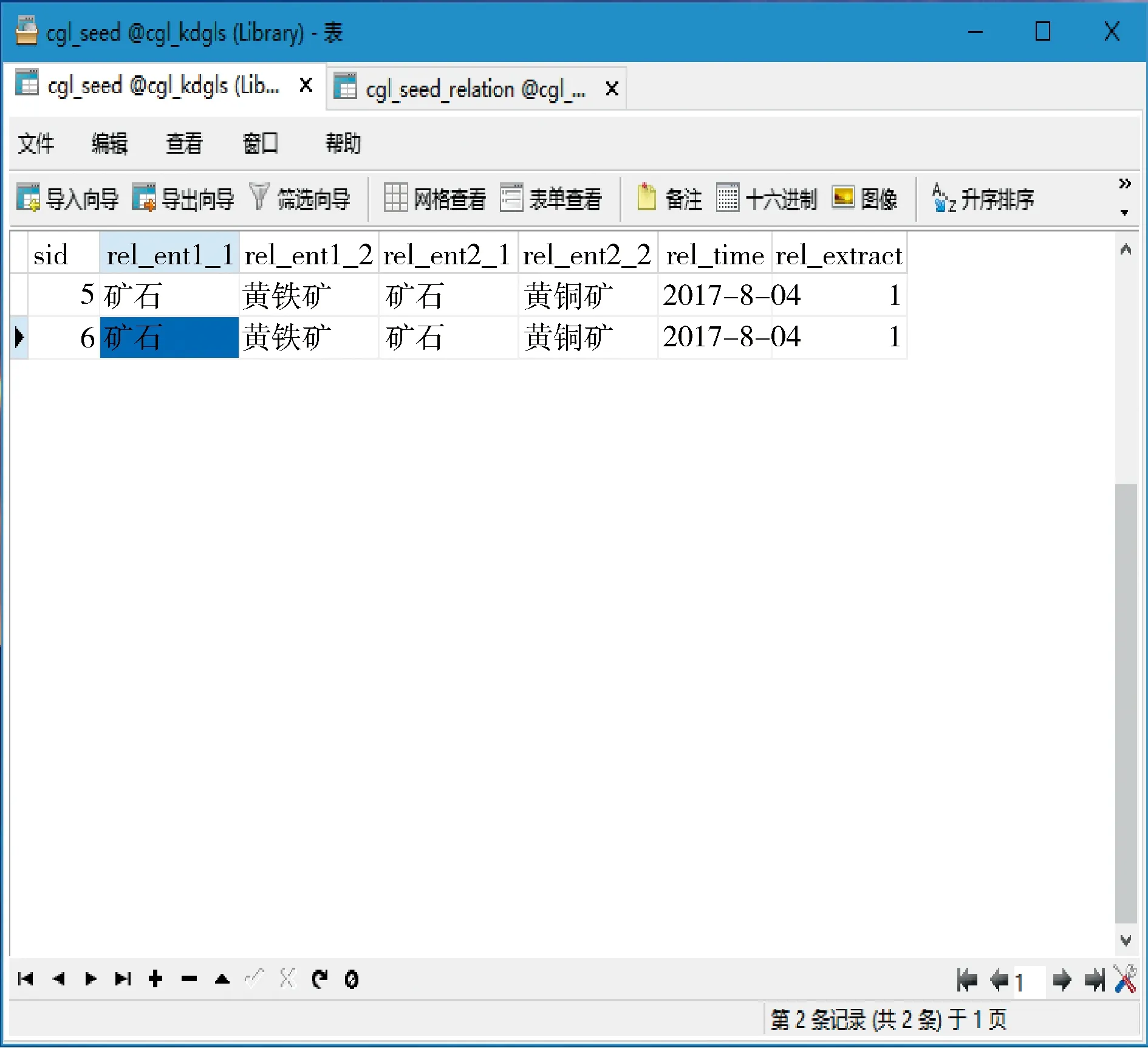
圖6 輸入關系對(種子)表的關系對
3.4.4 實驗分析
1) 實驗驗證了在給定的關系對(種子)在適當的關系條件下,可以根據其定義抽取模板,進而抽取新的候選關系對的過程。抽取的關系和模板保存在數據庫中的“cgl_seed_relation”表中, rel_template字段記錄了抽取出的關系,而rel_ent1和rel_ent1分別對應了關系中的arg0和arg1。
2) 候選集合(候選關系對)中某個關系對出現的頻率遠高于其它的關系對,這種高頻結果可能是前人已經總結過的成果,可以直接利用起來。相應的如果某個關系對在一些高頻模板中出現的頻率很低,這樣的關系對可能還沒有被挖掘出價值,因此可以作為新的研究的重點。
3) 在實驗中我們發現抽取出的模板和候選關系對有一些在語義上不連貫。產生該情況的原因一部分是中文亂碼,另一部分是由于生成的模板中只有虛詞(模板中只有介詞的情況多見)。在下一階段中我們需要進一步使用NLP相關算法對生成的結果加以限制。
4 結 論
地質文獻是地質調查工作的成果的重要載體和呈現方式,很多研究發現都是通過對地質文獻研究分析而誕生的。本文通過建立地質實體關系抽取模型的方式自動發現分析地質文獻中實體間的關系并進行了實驗驗證。關系抽取模型包括了關系抽取模型和關系擴展模型兩部分:關系抽取模型采用了極大似然估計的三元統計語言模型收取出候選關系集合,并通過制定過濾規則和評分函數進行關系的過濾和排序;關系擴展模型采用了Bootstrapping算法,在試驗中將人工定義的種子模板通過檢索Elastic Search來發現擴展新的關系模板。在后續的工作中,需要加入不同領域、體裁、規模的文本擴充試驗,以驗證方法的可移植性和實用性;同時需要進一步優化算法模型,研究關系分析過濾以及關系歸類算法,提升實驗精度。最終的目的是通過統計語言模型發現成礦預測領域有價值的關系,再通過關系擴展模型進行關系擴展,實現發現新知識,為成礦預測提供積極數據支持的目的。
[1] Jurafsky D,Martin J H.Speech and Language Processing.An Introduction to Natural Language Processing,Computational Linguistics and Speech Recognition (Draft)[C]∥Prentice Hall PTR.1999:638-641.
[2] 馮志偉.當前自然語言處理發展的幾個特點[J].華文教學與研究,2006(1):34-40.
[3] A Culotta,A McCallum,J Betz.Integrating probabilistic extraction models and data mining to discover relations and patterns in text[C]∥In:Proceedings of the main conference on Human Language Technology Conference of the North American Chapter of the Association of Computational Linguistics,Association for Computational Linguistics,New York.2006.
[4] 徐健,張智雄.典型關系抽取系統的技術方法解析[J].數字圖書館論壇,2008(9):13-18.
[5] 劉方馳,鐘志農,雷霖,吳燁.基于機器學習的實體關系抽取方法[J].兵工自動化,2013,32(9):57-62.
[6] Natalia K.Review of Relation Extraction Methods:What is New Out There?[J].Communications in Computer & Information Science,2014,436(1):15-28.
[7] 王晶.無監督的中文實體關系抽取研究[D].上海:華東師范大學,2012.
[8] 劉珍,王若愚,劉瓊.基于Bootstrapping的因特網流量分類方法[J].北京郵電大學學報,2014(5):66-70.
[9] 秦兵,劉安安,劉挺.無指導的中文開放式實體關系抽取[J].計算機研究與發展,2015(5):1029-1035.
[10] 吳軍.數學之美[M].北京:人民郵電出版社,2015:28.
Studyongeologicentityrelationextractionmethodbasedonliterature
LYU Pengfei1,2,WANG Chunning1,ZHU Yueqin3,4
(1.National Geological Library of China,Beijing 100083,China;2.University of Chinese Academy of Sciences,Beijing 100049,China;3.Development and Research Center,China Geological Survey,Beijing 100037,China;4.Key Laboratory of Geological Information Technology of Ministry of Land and Resources,Beijing 100037,China)
Relation extraction is an important section of information extraction,which play an crucial role in valuable information discovering.On the ground of analyzing and comparing,including supervised methods,unsupervised methods,self-supervise methods and open information extraction methods,this essay has built a Geologic Entity Relation Extraction Model,using statistical language models for relation extraction and bootstrapping models for relation extension.Finally,according to the above analysis,the experiment of incidence relation discovery and relation extension discovery were carried out.
literature;relation extraction;metallogenic prognosis;statistical language model;bootstrapping model
P208
A
1004-4051(2017)10-0167-06
2017-06-27責任編輯趙奎濤
國土資源部公益性行業科研專項項目資助(編號:201511079);國家重點研發計劃“基于‘地質云’平臺的深部找礦知識挖掘”資助(編號:2016YFC0600510)
呂鵬飛(1978-),男,碩士研究生,高級工程師,主要從事地質文獻數據分析與挖掘方面的研究工作,E-mail:23690271@qq.com。
朱月琴(1975-),女,博士,高級工程師,主要從事地質大數據、地圖綜合與可視化研究工作,E-mail:yueqinzhu@163.com。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
人大建設(2020年4期)2020-09-21 03:39:12
數學物理學報(2020年2期)2020-06-02 11:29:24
人大建設(2017年2期)2017-07-21 10:59:25
人大建設(2017年9期)2017-02-03 02:53:31
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
