多尺度卷積循環神經網絡的情感分類技術
2017-11-28 09:00:29吳瓊陳鍛生
華僑大學學報(自然科學版) 2017年6期
吳瓊, 陳鍛生
(華僑大學 計算機科學與技術學院, 福建 廈門 361021)

多尺度卷積循環神經網絡的情感分類技術
吳瓊, 陳鍛生
(華僑大學 計算機科學與技術學院, 福建 廈門 361021)
結合卷積神經網絡對于特征提取的優勢和循環神經網絡的長短時記憶算法的優勢,提出一種新的基于多尺度的卷積循環神經網絡模型,利用卷積神經網絡中的多尺寸濾波器提取出具有豐富上下文關系的詞特征,循環神經網絡中的長短時記憶算法將提取到的詞特征與句子的結構聯系起來,從而完成文本情感分類任務.實驗結果表明:與多種文本情感分類方法相比,文中算法具有較高的精度.
文本情感分類; 卷積神經網絡; 循環神經網絡; 長短時記憶; 多尺度
從海量而龐雜的網絡評論信息中分析和挖掘用戶的興趣取向或公眾態度,已成為政府和業界關注的問題.網絡輿情文本的情感分類技術已經成為自然語言處理的研究熱點.目前,情感分類方法有多種.基于深度學習的分類方法,傳統的支持向量機、樸素貝葉斯的分類方法和基于句法分析的方法都有不錯的效果.Wang等[1]提出多項樸素貝葉斯(MNB)模型和使用樸素貝葉斯特征的支持向量機模型(NBSVM).為了防止過擬合,Hinton等[2]提出dropout方法;Wang等[3]通過對dropout方法進行改進,提出高斯dropout(G-dropout)和快dropout(F-dropout).Dong等[4]從另外一個角度,根據情感表達的方式,構建統計分析器,得出句子的情感極性.卷積神經網絡(convolutional neural network,CNN)通過卷積濾波器提取特征[5].Kalchbrenner等[6]利用卷積神經網絡對句子進行建模.Kim[7]利用一個簡單的單層卷積神經網絡,通過多種輸入特征與參數設置方式進行對比實驗.Severyn等[8]使用與Kim相似的卷積網絡結構,但是參數初始化方式不同,完成對twitter文本的情感分析.Zhang等[9]針對Kim提出的卷積神經網絡,從多個角度對實驗結果的影響進行討論.另一種網絡結構是循環神經網絡(recurrent neural network,RNN),傳統的循環神經網絡在梯度反向傳播過程中,可能會產生梯度消失現象.為了解決這個問題,Hochreiter等[10]提出了長短時記憶模型.可以看出,卷積神經網絡可以方便地利用濾波器的尺寸,提取句子中每個詞與其上文和下文中的關系,而通過使用長短時記憶模型可以處理任意句子長度序列,還可以更好地體現句子語法規范.因此,為了更加方便靈活地提取詞的上下文特征,充分利用語言特性,本文提出了基于多尺度的卷積循環神經網絡模型.
1 多尺度的卷積循環神經網絡模型
提出的多尺度卷積循環神經網絡模型,如圖1所示.它包含兩級結構:在卷積神經網絡部分,使用Mikolov等[11]從谷歌新聞中訓練出來的300維的詞向量作為每個詞對應的特征,通過多尺度的卷積濾波器,提取多種具有豐富上下文的信息的特征;循環神經網絡通過將得到的詞的上下文信息特征進行組合,輸入到網絡中,最終的到情感分類結果.
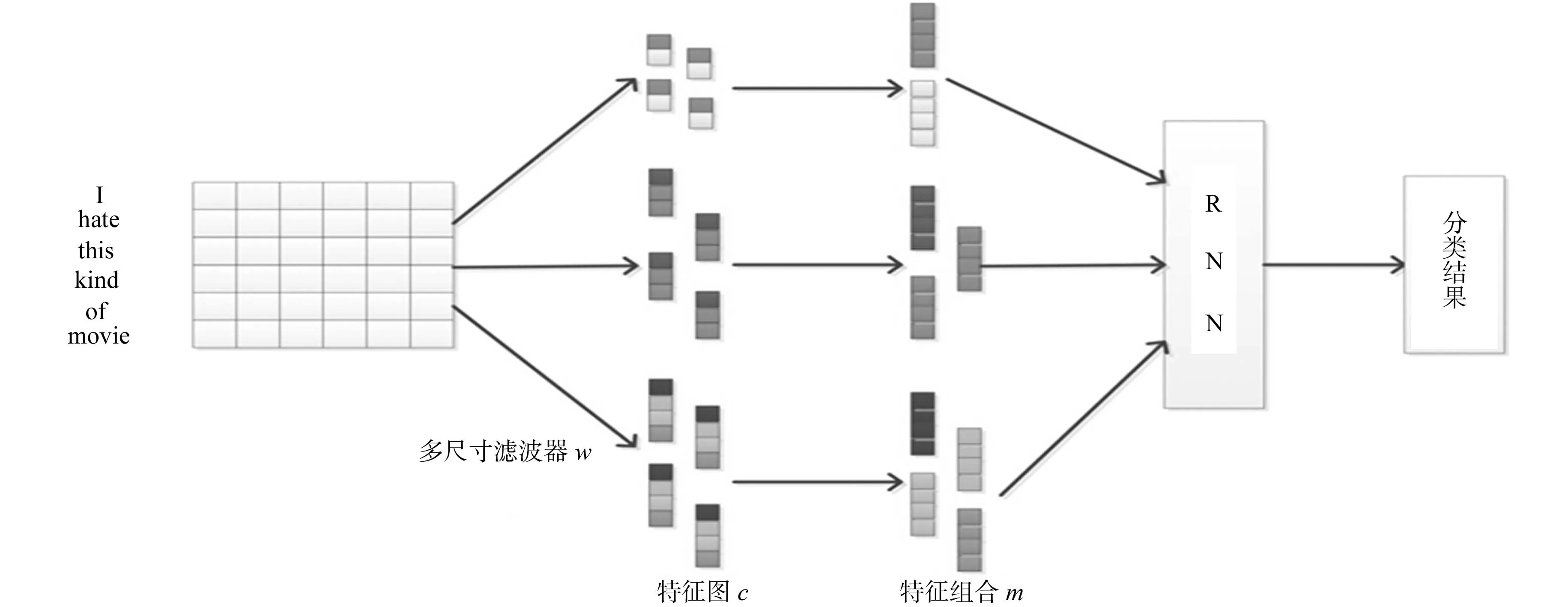
圖1 多尺度卷積循環神經網絡模型Fig.1 Model architecture with multiscale convolution recurrence neural network
1.1句子矩陣
xi表示一個句子的第i個詞所對應的詞向量,每個詞向量的維度為300維.由于句子包含的單詞數量不等,通過補0的方式,將句子全部擴充成相同的長度.那么,一個長度為n的句子可以表示為
式(1)中:+代表詞向量的縱向連接操作.那么,利用谷歌的詞向量,就可以將所有句子都轉換成大小相同的句子矩陣X1:n∈Rn×300,作為模型的輸入.
1.2卷積提取特征
對句子矩陣卷積操作時,會涉及濾波器的選擇及初始化.一個濾波器W∈Rhk,其中,h代表每次卷積參與到的詞的數量,也就是濾波器的尺寸;k代表詞向量的維度,這樣一個濾波器通過與一個包含h個詞的字符串進行卷積運算后,就得到了一個標量特征.如當W濾波器卷積某一個字符串Xi:i+h-1時,特征ci就產生了,其表達式為

式(2)中:b∈R是一個偏置項;f是一個非線性激活函數.那么,當這個濾波器對整個句子矩陣進行逐窗口{X1:h,X2:h+1,…,Xn-h+1:n}計算時,就會產生一個特征圖C∈Rn-h+1,表示為
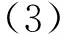
在特征圖產生后,并不對它進行池化操作,因為得到的特征順序對情感分類有很大的作用.不難理解,句子之所以構成句子,是因為它是詞的有序組合,所以會產生語法和句法.因此,特征的順序對于句子結構的表示具有重要性.
以上描述了一種尺寸的濾波器對一個句子矩陣進行操作的過程.文中模型使用多尺寸的濾波器,每種尺寸包含多個濾波器對輸入矩陣進行操作.所以,在對句子矩陣進行多尺寸的多個濾波器濾波后,每種尺寸的多個濾波器產生出多個特征圖.那么,通過某一尺寸的某個濾波器得到的特征圖C,變換成

式(4)中:i表示第i個尺寸的濾波器,實驗采用3種尺寸的濾波器;j表示同一尺寸的第j個濾波器,由于卷積神經網絡中的濾波器的參數是隨機生成的,同一尺寸包含的多個濾波器可以提取多種不同的特征,從而獲得同一尺寸下更豐富的特征,更精準地分析句子情感.對得到的多個特征圖進行組合,即
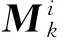
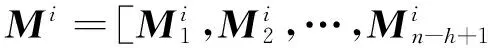
式(5),(6)中:i代表第i種濾波器尺寸;m代表每個尺寸濾波器的個數.這樣,就得到輸入到循環神經網絡的輸入特征.
1.3循環神經網絡
循環神經網絡模型是長短時記憶的循環神經網絡[10],其模型結構如圖2所示.
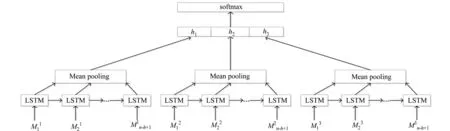
圖2 RNN結構圖Fig.2 Architecture of RNN
長短時記憶(long short-term memory,LSTM)算法引入了一個新的內存單元的結構,它主要包含4個主要元素:輸入門、自連接的神經元、忘記門和輸出門.輸入門控制輸入信號的多少;輸出門控制內存單元輸出對其他神經元的影響;忘記門控制自連接神經元受多少之前狀態的影響.它的每一個內存單元標識為一個LSTM單元,每個LSTM單元按照下式,逐個時刻t進行計算,即
式(7)~(12)中:σ表示sigmoid函數;W*,U*表示隨機初始化的參數,下標i,c,f,o分別代表輸入門、自連接、忘記門和輸出門.
那么,通過將每種尺寸濾波器濾波得到的特征Mi,逐一輸入到循環神經網絡中的對應位置,從而得到對應尺寸的狀態向量hi,最后,將每種尺寸濾波器得到的狀態向量拼接成一個狀態向量,送入softmax分類器進行[0,1]分類,便可得到句子所對應的情感分類.
1.4正則化
在訓練模型的過程中,使用dropout方法和權重向量L2范數約束[2]這兩種方法防止過擬合現象的發生.dropout方法是通過人為設置的隨機概率,將一些單元設置為0,從而讓網絡中的有些節點不工作.對于不工作的那些節點,可以暫時認為不是網絡結構的一部分,但是它的權重也要保留,因為這些節點的權重只是暫時不更新.當下一批樣本輸入時,它就有可能又要工作,那么當訓練模型的時候,相當于每一次都在訓練不同的網絡,所以通過這樣的方法可以有效地防止過擬合現象的發生.而權重向量的L2范數約束是在梯度更新過程中,將權重的L2范數強制的約束在某一范圍中,使權重參數的元素值都很小,避免出現個別元素的值較大,對分類結果產生較大影響,從而有效地防止過擬合現象,提高模型的泛化能力.
2 實驗與分析
為了測試文中模型,將提出的多尺度卷積循環神經網絡模型與其他模型的情感分類實驗結果進行對比分析.實驗使用的是預訓練的詞向量,它來源于谷歌開源的word2vector工具,連續詞袋結構從谷歌新聞中訓練而來,向量的維度是300維[11].使用3種數據集進行對比分析,一個是電影評論(MR)的數據集,每條數據是由一句話組成,總共包含5 331個消極評論和5 331個積極評論;一個是多種產品的顧客評論(CR),總共包含1 367條消極評論和2 406條積極評論;一個是觀點極性判斷的數據集(MRQA),一共包含7 293條消極觀點和3 311條積極評論.其中,MR數據集與CR數據集是評論數據集,它們的語句長度更長,而MRQA數據集主要是判斷觀點極性,所以數據集中的句子長度相對較短,甚至包含部分的單個單詞和單詞短語.3個數據集的標簽都是采用0和1對情感極性進行標注,其中,0代表消極,1代表積極.
對于所有數據集,采用5折交叉驗證;迭代次數為30次;L2范數的約束系數設置為3;每批訓練的大小為50個句子;dropout設置為0.5;選擇3種濾波器尺寸,分別為5,7,9;特征圖選擇的數量為200.卷積前句子長度是對應數據集中句子的最大長度,而當輸入到LSTM模型時,句子長度變為卷積前數據集中最大句子長度減去濾波器大小的長度,對應每個單詞向量的維度變為特征圖的數量(即200維),LSTM模型最終的輸出為二維向量,分別代表其情感極性.對于句子長度較長的數據集,濾波器的尺寸選擇在一定范圍內的增加可以提高準確率;但是當尺寸選擇過大、甚至超越句子的平均長度時,準確率就會降低很多.由于特征圖是用來盡可能提取豐富的特征,所以特征圖選的數量越多,會增加實驗的準確率;當增加到一定程度時,準確率基本不變化;再繼續增大時,反而會降低準確率.隨著濾波器的尺寸和特征圖數量的增加,訓練過程會變得相當耗時,且需要較大的內存空間存儲.因此,通過對比不同數據集的實驗結果,選擇對各個數據集都相對合適的參數.
采用隨機梯度下降算法的Adadelta更新規則[12],該更新規則可以自適應地調整學習率,減少人為指定學習率給更新帶來的影響.為了保證算法的魯棒性,避免隨機擾動帶來的影響,實驗結果是經過多次實驗求平均值的結果,從而使該方法有更好的魯棒性.情感分類結果準確率(η),如表1所示.表1中:
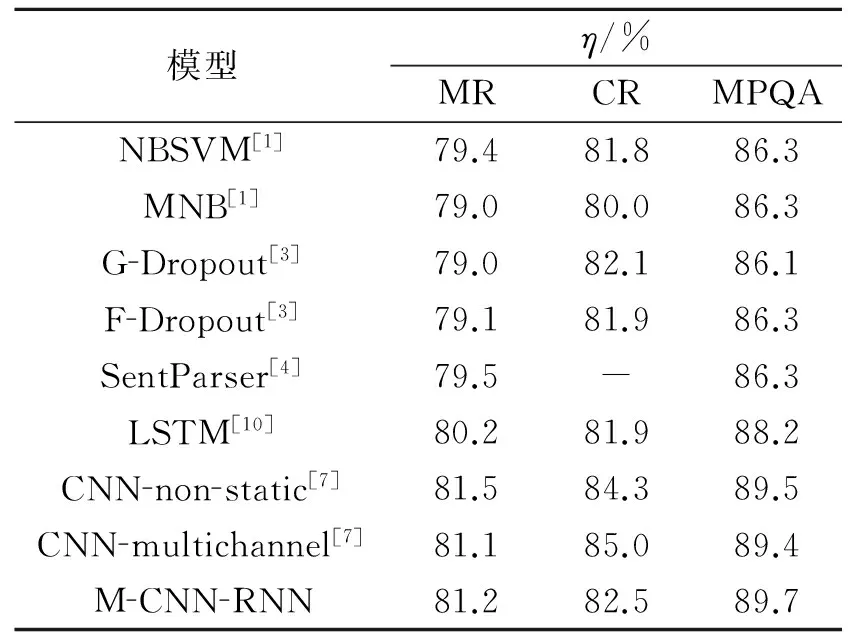
表1 情感分類結果Tab.1 Sentiment classification results
M-CNN-RNN代表文中提出的模型.
選擇對比的模型都是近幾年比較經典的模型,并且都在數據集中取得了不錯的效果.通過對比實驗結果發現,提出的模型獲得了很好的結果.通過卷積神經網絡多種尺寸的濾波器,可以提取比一般三元語法特征更多更廣泛的上下文特征.在卷積神經網絡后面連接循環神經網絡分類器可以將詞與句子的語法關系更好地體現出來,而且可以充分地利用卷積濾波器所提取出來的特征.所以,文中模型可以超越幾乎所有的模型,也可以看出,提出的模型很適合情感分類任務.但是在MR和CR數據集中,情感分類結果略低于CNN兩種模型結構的準確率.因為在評論數據集中,通常句子主要是表達用戶及顧客的情感,然而卻并不注意句子的語法規范,所以語句中的重點很明顯,其他字詞起的作用不大.而恰好在CNN-not-static和CNN-multichannel兩種模型中,它們在進行卷積濾波操作后,對得到的特征進行池化操作,會將卷積濾波后所提取到特征中的最顯著的特征保存下來,然后進行分類.而文中模型是利用卷積濾波器得到的全部特征進行情感分類,為了保證特征的完整性,并沒有進行池化操作.因此,CNN兩種模型的準確率會略高于文中模型.
3 結束語
通過結合深度學習領域中常用的兩種主流方法卷積神經網絡和循環神經網絡,提出基于多尺度的卷積循環神經網絡模型.該模型利用卷積神經網絡中的多尺寸濾波器,提取出具有豐富上下文關系的詞特征,循環神經網絡中的長短時記憶算法將提取到的詞特征與句子的結構聯系起來,從而將句子的結構與詞的相互依賴關系盡可能好地體現出來.通過實驗對比分析,文中模型獲得了很好的實驗結果,體現出該模型對情感分類的適用性.接下來,需要探索如何將注意力模型應用到文中模型中,改進網絡的結構,使它更適應現實生活中的語言模型,提升文本情感分析的效果.
[1] WANG Sida,MANNING C D.Baselines and bigrams: Simple, good sentiment and topic classification[C]∥Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics.Stroudsburg:ACM,2012:90-94.
[2] HINTON G,SRIVASTAVA N,KRIZHEVSKY A,etal.Improving neural networks by preventing co-adaptation of feature detectors[J].Computer Science,2012,3(4):212-223.
[3] WANG Sida,MANNING C D.Fast dropout training[C]∥Proceedings of the 30 th International Conference on Machine Learning.Atlanta:JMLR,2013:118-126.
[4] LI Dong,WEI Furu,LIU Shujie,etal.A statistical parsing framework for sentiment classification[J].Computational Linguistics,2014,41(2):293-336.DOI:10.1162/COLI_a_00221.
[5] LECUN Y,BOTTOU L,BENGIO Y,etal.Gradient-based learning applied to document recognition[J].Proceedings of the IEEE,1998,86(11):2278-2324.DOI:10.1109/5.726791.
[6] KALCHBRENNER N,GREFENSTETTE E,BLUNSOM P.A convolutional neural network for modelling sentences[C]∥Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics.Baltimore:Eprint Arxiv,2014:655-665.DOI:10.3115/v1/P14-1062.
[7] KIM Y.Convolutional neural networks for sentence classification[C]∥Proceedings of Conferenceon Empirical Methods in Natural Language Processing.Doha:[s.n.],2014:1746-1751.DOI:10.3115/v1/d14-1181.
[8] SEVERYN A,MOSCHITTI A.Twitter sentiment analysis with deep convolutional neural networks[C]∥Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval.New York:ACM,2015:959-962.DOI:10.1145/2766462.2767830.
[9] ZHANG Ye,WALLACE B.A sensitivity analysis of (and practitioners′ guide to) convolutional neural networks for sentence classification[EB/OL].(2016-04-06)[2016-06-15].http://arxiv.org/pdf/1510.03820v4.pdf.
[10] HOCHREITER S,SCHMIDHUBER J.Long short-term memory neural computation[J].Neural Computation,1997,9(8):1735-1780.DOI:10.1162/neco.1997.9.8.1735.
[11] MIKOLOV T,SUTSKEVER I,CHEN Kai,etal.Distributed representations of words and phrases and their compositionality[C]∥Proceedings of Neural Information Processing Systems.South Lake Tahoe:Advances in Neural Information Processing Systems,2013:3111-3119.
[12] ZEILER M.Adadelta: An adaptive learning rate method[EB/OL].(2012-12-22)[2016-06-15].http://arxiv.org/pdf/1212.5701v1.pdf.
(責任編輯: 黃曉楠英文審校: 吳逢鐵)
SentimentClassificationWithMultiscaleConvolutionalRecurrentNeuralNetwork
WU Qiong, CHEN Duansheng
(College of Computer Science and Technology, Huaqiao University, Xiamen 361021, China)
Combining the advantages of convolution neural network (CNN) for feature extraction and recurrent neural network (RNN) for long shot-term memory, a new model based on multiscale convolutional recurrent neural network is proposed. This model utilize multi-size filter of CNN to extract word feature which contain a rich context information and use the long short-term memory algorithm of RNN to reflect the grammatical relations about the word and the sentence, and then completing the sentiment classification task. The experimental results show that: through comparing with many other sentiment classification, this new model has a high accuracy.
text sentiment classification; convolutional neural network; recurrent neural network; long short-term memory; multiscale
10.11830/ISSN.1000-5013.201606077
TP 391.4
A
1000-5013(2017)06-0875-05
2016-06-28
陳鍛生(1959-),男,教授,博士,主要從事計算機視覺與多媒體技術的研究.E-mail:dschen@hqu.edu.cn.
國家自然科學基金資助項目(61370006); 福建省科技計劃(工業引導性)重點項目(2015H0025)
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中國生殖健康(2020年5期)2021-01-18 02:59:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
北極光(2019年12期)2020-01-18 06:22:10
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小太陽畫報(2019年10期)2019-11-04 02:57:59
當代陜西(2019年10期)2019-06-03 10:12:04
中國生殖健康(2018年5期)2018-11-06 07:15:40
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
