改進的頻繁和高效用項集挖掘算法
2017-11-28 09:00:29張健劉韶濤
華僑大學學報(自然科學版) 2017年6期
張健, 劉韶濤
(華僑大學 計算機科學與技術學院, 福建 廈門 361021)

改進的頻繁和高效用項集挖掘算法
張健, 劉韶濤
(華僑大學 計算機科學與技術學院, 福建 廈門 361021)
提出一種基于局部效用質(zhì)量值的上界剪枝新方法,引入偽投影技術避免真實地構造物理投影,基于二者提出改進的FHIMA-P算法.在提出的FHIMA-P算法中引入事務合并和投影事務合并技術,提出最終的FHIMA-MP算法,并在mushroom和accident數(shù)據(jù)集上進行實驗.結果表明:FHIMA-P算法的運行時間相比FHIMA-ALL算法縮短,而FHIMA-MP算法則較前兩者效率有非常大的提高;在不同參數(shù)下,mushroom和accident數(shù)據(jù)集中大量可合并事務(投影事務)數(shù)目也很好地證明了事務(投影事務)合并的有效性.
頻繁項集; 高效用項集; 偽投影; 事務合并
關聯(lián)規(guī)則最初是挖掘頻繁項集[1-4],項集的支持度大于等于最小支持度時,這個項集是頻繁的.高效用項集挖掘[5-9]是頻繁項集挖掘的擴展,項集的效用值大于等于最小效用值時,這個項集是高效用的.高效用項集挖掘中,每個項在事務中可以出現(xiàn)多次,并且可以有不同的權重,因此,高效用項集挖掘更加復雜.現(xiàn)有算法多將支持度和效用值單獨考慮,很少將這兩種衡量標準同時考慮.李慧等[10]首次將支持度和相對效用值線性加權,定義為質(zhì)量值,提出挖掘數(shù)據(jù)庫中高質(zhì)量項集的FHIMA算法.FHIMA算法使用PrefixSpan算法[11]的思想,遞歸地構造前綴的投影數(shù)據(jù)庫挖掘頻繁和高效用項集.然而,如果是物理地復制得到投影數(shù)據(jù)庫,開銷很大.因此,本文引入偽投影技術進行優(yōu)化,提出一種本地效用質(zhì)量值上界剪枝的方法,在 FHIMA算法基礎上,引入事務合并和投影事務合并技術,提出FHIMA-MP算法.
1 頻繁高效用項集挖掘算法FHIMA
FHIMA算法是基于前綴投影的模式增長算法,它把支持度σ(X)和相對效用值線性加權λΦ(X)后的變量定義為質(zhì)量,在給定參數(shù)下,挖掘所有高質(zhì)量項集.FHIMA算法有以下3個執(zhí)行步驟.1) 刪去數(shù)據(jù)庫中非頻繁高效用項集的項(不滿足最小支持度和事務效用權重估計的1-項集),得到頻繁高效用1-項集,數(shù)目為n.2) 將數(shù)據(jù)庫中各條事物按?(1-項集事務效用權重遞增的順序)排序,排序后按照?順序?qū)⑺阉骺臻g劃分為n個具有不同前綴的投影數(shù)據(jù)庫.3) 在這n個投影數(shù)據(jù)庫中,遞歸構造子投影數(shù)據(jù)庫進行挖掘,挖掘中進行算法搜索空間剪枝.
2 FHIMA算法改進
2.1局部效用剪枝和數(shù)據(jù)庫偽投影
FHIMA算法的剪枝是剪掉以該節(jié)點為根的整棵子樹,經(jīng)過分析,在這以前如果適當減少這棵子樹上的節(jié)點,得到的剪枝上界將更緊湊,結果將更高效.
在高效用項集挖掘算法中,一般第一步用事務效用權重的閉包屬性[6]刪去不可能從中得到高效用項集的項目.借鑒這點,提出了局部效用剪枝的概念.文中除自定義符號外,所有符號和文獻[10]一致.
定義1局部效用lu(X,c),其中,X是任意一個項集;項c∈EI(X).項集X∪c的局部效用定義為
).
性質(zhì)1X是任意一個項集,對于項c∈EI(X),如果項集C是項集X通過添加EI(X)中元素后得到的項集,則有l(wèi)u(X,c)≥u(C)成立.
證明 因為項集C是通過添加項集X擴展項集中元素后得到的項集,所以項集C的效用小于等于項集X的效用加上X的擴展項集中全部元素效用之和,即
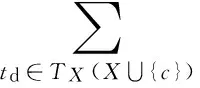
X是任意一個項集,對于項c∈EI(X),如果lu(X,c)小于最小效用值,則所有項集X的擴展項集中包含項c的都是低效用的,也就是項c這個節(jié)點可以從子樹中刪去.
得到基于局部效用剪枝的質(zhì)量值上界計算式為
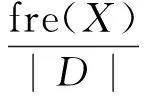
利用這個上界,從投影數(shù)據(jù)庫中刪去不滿足條件的項目,可以進一步縮減搜索空間.
定義2以項集a為前綴的投影事務定義為α-T={i|i∈T∧i∈EI(a)}.
定義3以項集a為前綴的投影數(shù)據(jù)庫定義為α-D={a-T|T∈D∧a-T≠Φ}.
在FHIMA算法中,如果物理地復制得到投影數(shù)據(jù)庫,則花費在計算a-D上的時間是O(n×l)(n是投影數(shù)據(jù)庫的事務數(shù),l是事務平均長度).為了避免物理地復制,運用偽投影技術.對數(shù)據(jù)庫中每一條事務添加一個偏移量指針指向它,在每條事務中查找擴展項集中第一個項相對于整條事務的偏移量,從而得到投影事務,進而得到整個數(shù)據(jù)庫的偽投影.采用偽投影將a-D的算法時間復雜度降為O(n).
2.2事務合并和投影事務合并技術
事務合并是將兩條或多條事務合并為一條事務,從而減少數(shù)據(jù)庫規(guī)模的一種策略.
定義4稱兩條事務是可合并的,當且僅當它們按照規(guī)則排序后所含的項是完全相同時,而不管它們的內(nèi)部效用值或支持度是否相同.
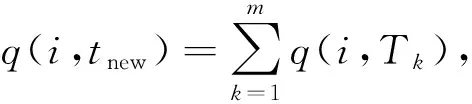
投影數(shù)據(jù)庫比原來規(guī)模更小,因而,會有更多滿足可合并條件的事務.
需要注意,對于投影事務合并先要得到投影數(shù)據(jù)庫,得到投影數(shù)據(jù)庫時項的效用值是相加,但支持數(shù)不是.應該先和它前綴項集的支持數(shù)比較,取較小的作為投影后相應項的支持數(shù).
事務合并和投影事務合并顯然會大大減少數(shù)據(jù)庫的掃描次數(shù),但關鍵的問題是如何高效地實現(xiàn)這兩種合并.最直接的做法就是將所有的事務進行相互比較,看哪些是可以合并的,但這種操作算法的時間復雜度為O(n2).為了將時間復雜度降低到O(n),定義如下的偏序全排序.
定義7?T定義在全排序?的基礎上,假設有兩條事物ta={i1,i2,…,im}和tb={j1,j2,…,jk}.這個偏序全排序關系定義如下4種情況.
1) 如果這兩條事物可合并,且事物編號tb大于ta,則最終偏序關系為Tb?TTa.
2) 如果kgt;m,對任意整數(shù)x,x滿足0≤xlt;m,都有im-x=jk-x,則最終偏序關系為Tb?TTa.
3) 如果存在x是整數(shù),x滿足0≤xlt;min(m,k),此時,對所有整數(shù)y,y滿足xlt;ylt;min(m,k)且jk-x?im-x,im-y=jk-y,則最終偏序關系為Tb?TTa.
4) 當不滿足這3種關系時,則最終偏序關系為Tb?TTa.
按照?T順序排序后,可以得到性質(zhì)2.根據(jù)性質(zhì)2,所有可合并的事務在數(shù)據(jù)庫(或投影數(shù)據(jù)庫)中能通過比較相鄰事務得到,這樣就能在線性時間內(nèi)找到它們.
性質(zhì)2項集a的投影數(shù)據(jù)庫a-D按T排序后,滿足可相互合并的事務在排序后的投影數(shù)據(jù)庫中是連續(xù)出現(xiàn)的.
3 實驗結果與分析
3.1實驗設置
為了對比算法性能,將實現(xiàn)FHIMA算法挖掘全部頻繁高效用項集的算法命名為FHIMA-ALL,與加入偽投影和局部效用剪枝優(yōu)化后的FHIMA-P算法和在FHIMA-P算法中加入事務(投影事務)合并后的FHIMA-MP算法進行對比.實驗平臺為Intel(R) Core(TM) i5-3470,主頻 3.20 GHz,內(nèi)存8 GB,Windows 7 旗艦版 64位 SP1,編程語言為Java,開發(fā)環(huán)境Eclipse 4.4.0.數(shù)據(jù)集為fimi[http:∥fimi.ua.ac.be/]網(wǎng)站下載的mushroom和accident數(shù)據(jù)集.和文獻[6-8]中方法一樣,各數(shù)據(jù)集中各項的內(nèi)部效用值使用對數(shù)正態(tài)分布生成1到10之間的數(shù),事務中各項的數(shù)量是隨機生成1到10之間的數(shù).
3.2不同參數(shù)設置的算法對比
3.2.1 支持度閾值 不同支持度下,mushroom和accident的運行時間,如圖1所示.圖1中:t為時間;η為最小支持度.由圖1可知:支持度越小,算法挖掘的頻繁和高效用項集越多,2種算法運行時間隨支持度的增加開始變少,FHIMA-P算法比FHIMA-ALL算法運行時間短,F(xiàn)HIMA-MP算法則比前2個算法的效率更高.原因在于,首先,在數(shù)據(jù)庫中,有許多滿足可合并的事務,F(xiàn)HIMA-MP算法將它們合并成一條事務,大大壓縮了事務數(shù)據(jù)庫;其次,由于算法挖掘都在構造的投影數(shù)據(jù)庫中進行,而投影數(shù)據(jù)庫因其規(guī)模更小滿足可合并要求的事務更多,所以,加入事務合并和投影事務合并技術大大提高了算法的運行效率.

(a) mushroom數(shù)據(jù)集 (b) accident數(shù)據(jù)集圖1 不同支持度下mushroom和accident的運行時間Fig.1 Running time in different support on mushroom and accident dataset

(a) mushroom數(shù)據(jù)集 (b) accident數(shù)據(jù)集圖2 不同支持度下mushroom和accident的事務(投影事務)合并數(shù)Fig.2 Numbers of transactions (projected transactions) that can be merged in different support on mushroom and accident dataset
不同支持度下,mushroom和accident的事務(投影事務)合并數(shù),如圖2所示.圖2中:n為事務(投影事務)合并數(shù);η為最小支持度.由圖2可知:mushroom和accident數(shù)據(jù)集中,事務(投影事務)合并數(shù)隨支持度的增加而減少,并且在指定支持度下,它們都存在百萬級別的事務(投影事務)合并數(shù).
3.2.2 相對效用值閾值 不同相對效用值下,mushroom和accident的運行時間,如圖3所示.由圖3可知:當最小相對支持度變大時,3種算法運行時間也是逐漸變少,并且3種算法效率大小關系仍和支持度從小到大變化時一致,即FHIMA-P算法比FHIMA-ALL算法運行時間更短,F(xiàn)HIMA-MP算法相比前兩個算法運行效率有顯著的提高.
不同相對效用值下,mushroom和accident的事務(投影事務)合并數(shù),如圖4所示.由圖4可知:3種數(shù)據(jù)集中事務(投影事務)合并數(shù)隨相對效用值的增加而減少,在最小效用值閾值下,同樣存在著百萬級別的事務(投影)事務合并數(shù),這是FHIMA-MP算法比FHIMA-P算法效率更高的原因.
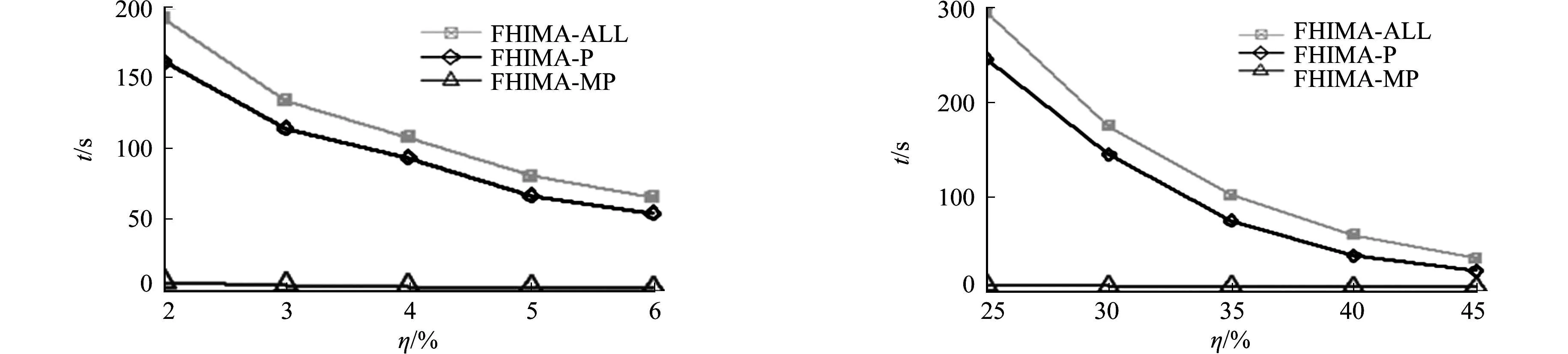
(a) mushroom數(shù)據(jù)集 (b) accident數(shù)據(jù)集圖3 不同相對效用值下mushroom和accident的運行時間Fig.3 Running time in different relative utility on mushroom and accident dataset
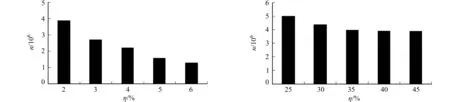
(a) mushroom數(shù)據(jù)集 (b) accident數(shù)據(jù)集圖4 不同相對效用值下mushroom和accident的事務(投影事務)合并數(shù)Fig.4 Numbers of transactions (projected transactions) that can be merged in different relative utility on mushroom and accident dataset
3.2.3 加權系數(shù)閾值 加權系數(shù)λ代表相對效用值的重要程度.不同加權系數(shù)λ下,mushroom數(shù)據(jù)集上的運行時間和(投影)事務合并數(shù),如圖5所示.由圖5可知:3種算法運行時間都在逐漸增加,且它們效率高低關系與支持度和相對效用的變化一致;當λ變大時,mushroom中事務(投影事務)合并數(shù)逐漸增加,當λ增加到一定程度,3種算法效率和事務(投影事務)合并數(shù)的增速都開始變緩.這是因為此時相對效用值起主導作用,再增加λ,對算法效率提升已經(jīng)不明顯了.

(a) 運行時間 (b) 事務(投影事務)合并數(shù)圖5 不同加權系數(shù)λ下mushroom數(shù)據(jù)集上的運行時間和(投影)事務合并數(shù)Fig.5 Running time and numbers of transactions (projected transactions) that can be merged in different weighting coefficient λ on mushroom dataset
當λ=0時,F(xiàn)HIMA-P和FHIMA-MP算法轉(zhuǎn)變?yōu)橥诰蝾l繁項集的算法.為了比較算法在λ=0時挖掘頻繁項集的效率,將FHIMA-P和FHIMA-MP算法分別與Apriori算法[1]和FpGrowth算法[2]進行比較,結果如圖6,7所示.為了更直觀對比效果,將對比的4個算法拆分成2幅圖.
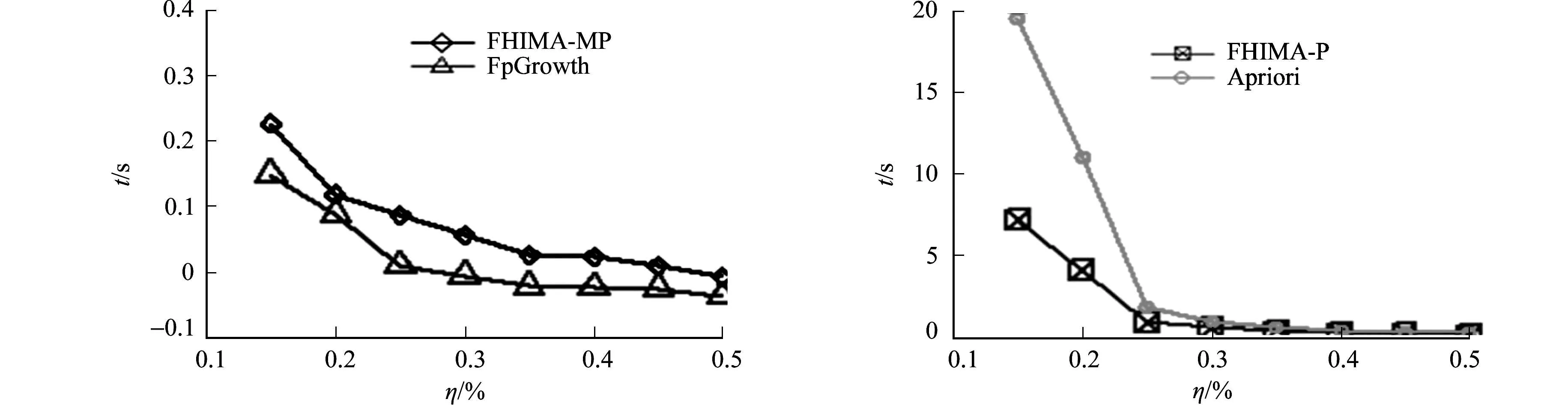
(a) FHIMA-MP和FpGrowth算法 (b) FHIMA-P和Apriori算法圖6 mushroom上不同支持度下運行時間對比圖Fig.6 Comparation of running time in different support on mushroom dataset

(a) FHIMA-MP和FpGrowth算法 (b) FHIMA-P和Apriori算法圖7 Accident上不同支持度下運行時間對比圖Fig.7 Comparation of running time in different support on accident dataset
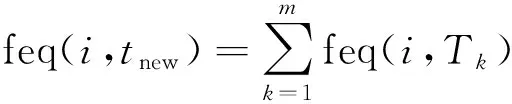
4 結論
在FHIMA算法的基礎上,引入事務偽投影和局部效用剪枝,提出改進的FHIMA-P算法.引入偽投影,避免了物理地復制構造投影數(shù)據(jù)庫,另外,為了進一步減少算法搜索空間,定義了一種基于局部效用的質(zhì)量值剪枝,從而提高算法效率,最終實驗也證明了這種改進的有效性.最后,觀察到數(shù)據(jù)庫中有很多事務是可以合并的,并且由于文中算法的特點,將這種合并擴展到投影數(shù)據(jù)庫中.同時,為了快速找到滿足相互之間可合并條件的事務,定義了一種排序規(guī)則.實驗結果證明:在FHIMA-P算法基礎上,加入事務(投影事務)合并技術的FHIMA-MP算法相比于之前的FHIMA-P算法效率有非常顯著地提高,另外,在加權系數(shù)為0時,F(xiàn)HIMA-P算法明顯比Apriori算法高效,且FHIMA-P算法由于事務(投影事務)合并仍然適用效率則遠高于FHIMA-P算法和Apriori算法,它的效率只比FpGrowth算法稍低,從而進一步證明了事務(投影事務)合并的高效性.
接下來,有關頻繁高效用項集挖掘方法的研究,還可以從完全頻繁項集、基于約束條件的頻繁項集、最大頻繁項集、頻繁閉項集等類型著手嘗試.在確定性數(shù)據(jù)中,每種類型的頻繁項集都有其對應的挖掘方法,還可以將頻繁高效用挖掘推廣到時間序列數(shù)據(jù)、不確定數(shù)據(jù)及其他類型適合挖掘的數(shù)據(jù)上.
[1] AGRAWAL B R,SRIKANT R.Fast algorithm for mining association rules[C]∥Proc of International Conference on Very Large Data Bases.Santiago:VLDB,1994:487-499.DOI:10.1109/tencon.2003.1273266.
[2] HAN Jiawei,PEI Jian,YIN Yiwen.Mining frequent patterns without candidate generation[C]∥Proc of 2000 ACM-SIGMOD International Conference on Management of Data (SIGMOD′00).Dallas:Conference Publications,2000:1-12.DOI:10.1023/b:dami.0000005258.31418.83.
[3] DENG Zhihong,WANG Zhonghui,JIANG Jiajian.A new algorithm for fast mining frequent itemsets using N-lists[J].Sciece China Information Sciences,2012,55(9):2008-2030.DOI:10.1007/s11432-012-4638-z.
[4] DENG Zhihong,LYU Shenglong.Fast mining frequent itemsets using Nodesets[J].Expert Systems with Applications,2014,41(10):4505-4512.DOI:10.1016/j.eswa.2014.01.025.
[5] YAO Hong,HAMILTON H J,BUTZ C J.A foundational approach to mining itemset utilities from databases[C]∥Proceedings of the Fourth SIAM International Conference on Data Mining.Florida:DBLP,2004:482-486.
[6] LIU Ying,LIAO Weikeng,CHOUDHARY A.A two-phase algorithm for fast discovery of high utility itemsets[C]∥PAKDD′05 Proceedings of the 9th Pacific-Asia Conference on Advances in Knowledge Discovery and Data Mining.Hanoi:Springer Berlin Heidelberg,2005:689-695.DOI:10.1007/11430919_79.
[7] TSENG V S,WU C W,SHIE B E,etal.UP-Growth: An efficient algorithm for high utility itemset mining[C]∥Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.Washington D C:ACM Press,2010:253-262.DOI:10.1145/1835804.1835839.
[8] LIU Mengchi,QU Junfeng.Mining high utility itemsets without candidate generation[C]∥ACM International Conference on Information and Knowledge Management.New York:ACM Press,2012:55-64.
[9] KRISHNAMOORTHY S.Pruning strategies for mining high utility itemsets[J].Expert Systems with Applications,2015,42(5):2371-2381.DOI:10.1016/j.eswa.2014.11.001.
[10] 李慧,劉貴全,瞿春燕.頻繁和高效用項集挖掘[J].計算機科學,2015,42(5):82-87.DOI:10.11896/j.issn.1002-137X.2015.05.017.
[11] PEI Jian,HAN Jiawei,MORTAZAVI-ASL B,etal.PrefixSpan: Mining sequential patterns efficiently by prefix-projected pattern growth[C]∥Proceedings of the 17th International Conference on Data Engineering.Washington D C:IEEE Press,2001:215-224.DOI:10.1109/icde.2001.914830.
(責任編輯: 黃曉楠英文審校: 吳逢鐵)
ImprovedMiningAlgorithmforFrequentandHighUtilityItemsets
ZHANG Jian, LIU Shaotao
(College of Computer Science and Technology, Huaqiao University, Xiamen 361021, China)
A new method that uses the upper bound of quality to prune the search space based on local utility quality is proposed, meanwhile, pseudo projection technique is introduced to avoid actually construct the physical projection, then based on these two points, an improved FHIMA-P algorithm is proposed. By adding the transaction merging and projected transaction merging technique in FHIMA-P algorithm, the final FHIMA-MP algorithm is proposed. An experiment is conducted on mushroom and accident dataset, the result shows that the running time of FHIMA-P algorithm is shorter than that of FHIMA-ALL algorithm, while the FHIMA-MP algorithm improves significantly compared with the previous two algorithms′ efficiency. Moreover, the huge number of transactions (projected transaction) that can be merged on mushroom and accident dataset in different papameters also prove the effectiveness of transaction (projected transaction) merging technique.
frequent itemsets; high utility itemsets; pseudo projection; transaction merging
10.11830/ISSN.1000-5013.201603067
TP 311
A
1000-5013(2017)06-0880-06
2016-03-24
劉韶濤(1969-),男,副教授,主要從事軟件體系結構與軟件復用的研究.E-mail:shaotaol@hqu.edu.cn.
福建省科技計劃重大項目(2011H6016)
猜你喜歡
甘肅教育(2020年14期)2020-09-11 07:57:42
財經(jīng)(2017年2期)2017-03-10 14:35:35
財經(jīng)(2016年15期)2016-06-03 07:38:02
財經(jīng)(2016年3期)2016-03-07 07:44:46
山東青年(2016年1期)2016-02-28 14:25:25
財經(jīng)(2016年6期)2016-02-24 07:41:51
時代英語·高二(2015年1期)2015-03-16 00:08:11
中國衛(wèi)生(2014年11期)2014-11-12 13:11:32
當代修辭學(2014年3期)2014-01-21 02:30:44
公務員文萃(2013年5期)2013-03-11 16:08:37
