基于數(shù)據(jù)挖掘的AI公司職位推薦研究
2017-11-30 20:44:55任然然
價(jià)值工程 2017年34期
任然然
摘要:本文以AI公司的人力資源現(xiàn)狀為背景,通過對(duì)其人員離職現(xiàn)狀數(shù)據(jù)的統(tǒng)計(jì)分析,采用基于案例推理算法,制定了基于數(shù)據(jù)挖掘的職位推薦模型,為該公司有意轉(zhuǎn)崗或離職人員提供公司內(nèi)部職位推薦服務(wù),進(jìn)而降低員工對(duì)離職率,確保該公司員工的穩(wěn)定性。
Abstract: Based on the analysis of the current situation of AI's personnel, this paper uses the case-based reasoning algorithm to develop the job recommendation model based on data mining, and provides internal job referral services for the employees with the intention to transfer or leave the company, thereby reducing employee turnover rates and ensuring the stability of the company's employees.
關(guān)鍵詞:人力資源;基于案例推理;推薦算法
Key words: human resources;case-based reasoning;recommendation algorithm
中圖分類號(hào):F279.23 文獻(xiàn)標(biāo)識(shí)碼:A 文章編號(hào):1006-4311(2017)34-0042-03
1 背景
北京AI公司是一家是領(lǐng)先的中國全電信軟件解決方案提供商。AI公司自成立以來,始終站在世界技術(shù)的前沿,推動(dòng)中國新一代電信的發(fā)展。AI公司總部設(shè)在北京中關(guān)村,在全國各地乃至新加坡、印度均設(shè)有機(jī)構(gòu),員工人數(shù)將近2萬多名,2001年總收入達(dá)18900萬美元。曾被世界經(jīng)濟(jì)論壇評(píng)為全球500家高速成長的企業(yè)之一。
近年來,隨著社會(huì)的發(fā)展,企業(yè)與員工的關(guān)系,將不再是簡單的勞資關(guān)系,而是通過若干維度的緊密連接,形成的一個(gè)全面的生存共同體,人類社會(huì)已經(jīng)進(jìn)入到了新經(jīng)濟(jì)時(shí)代。知識(shí)經(jīng)濟(jì)是以人力資本投入為主的經(jīng)濟(jì),充分利用人才資本和知識(shí)是這個(gè)時(shí)代的強(qiáng)大精神體現(xiàn)。人力資源不僅是最積極、最活躍的生產(chǎn)要素,而且毫無疑問是最重要的第一生產(chǎn)要素。[1]
2 相關(guān)技術(shù)理論
案例相似度算法:
案例的全局相似性算法采用加權(quán)局部相似度量如[3]下
Sim(X,Y)=wjSim(Xi,Yi)
其中,Sim(X,Y)表示目標(biāo)案例X與源案例Y的相似度,wj表示特征i的權(quán)重,Sim(Xi,Yi)表示目標(biāo)案例X與源案例Y在特征i上的相似度,相似度計(jì)算實(shí)質(zhì)上就是對(duì)屬性間距離進(jìn)行度量,Sim(X,Y)應(yīng)當(dāng)滿足以下的條件和性質(zhì)[4][5]
①sim (X,Y)∈[0,1]
②當(dāng)且僅當(dāng)X=Y,sim(X,Y)=1
③sim (X,Y)=sim(Y,X)
④sim (X,Y)≥sim(X,Z)+sim(Z,Y)-1
本文中兩種類型用戶的屬性之間的相似度計(jì)算公式如表1所示。
3 模型設(shè)計(jì)
3.1 用戶類型的設(shè)計(jì)
用戶在登錄推薦系統(tǒng)前,可以根據(jù)自己的求職意向,在AI公司人才檔案系統(tǒng)更新自己的求職意向。本文會(huì)以用戶在人才檔案系統(tǒng)存儲(chǔ)的最新用戶信息為基礎(chǔ),同時(shí)根據(jù)系統(tǒng)用戶登錄的行為將用戶分為:首次登錄系統(tǒng)用戶和非首次登錄系統(tǒng)用戶。
對(duì)于在AI公司人才檔案系統(tǒng)里面修改簡歷信息或者求職意向的用戶,系統(tǒng)會(huì)根據(jù)用戶修改后的用戶信息,為用戶進(jìn)行職位推薦;對(duì)于首次登錄系統(tǒng)對(duì)用戶,系統(tǒng)會(huì)采用基于案例推理的算法為用戶提供推薦服務(wù),否則,系統(tǒng)會(huì)根據(jù)用戶的行為數(shù)據(jù),采用基于模型的協(xié)同過慮算法為用戶提供推薦服務(wù)。
3.2 推薦模型的設(shè)計(jì)
經(jīng)查閱相關(guān)文獻(xiàn)可知,影響職位推薦列表等影響因素有很多,并且每一種影響因素對(duì)最終推薦列表的影響程度均是不同的。因此,本文采用層次分析法[6](The analytic hierarchy process)簡稱AHP,來確定不同屬性信息權(quán)重。該方法的具體步驟如下: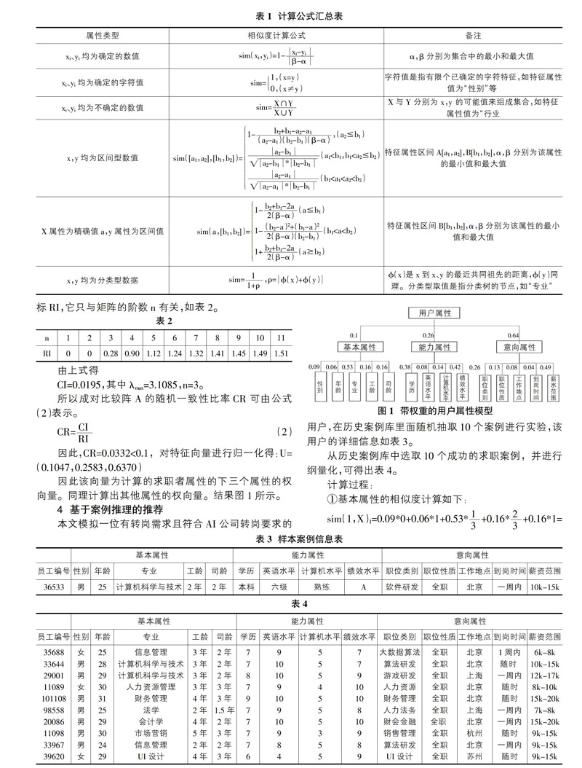
3.2.1 建立層次結(jié)構(gòu)模型
根據(jù)AI公司的業(yè)務(wù)需求,并結(jié)合相關(guān)文獻(xiàn)知識(shí),本文將影響最終職位推薦列表的屬性信息分為用戶屬性及職位屬性。用戶屬性包括用戶基本屬性、用戶能力屬性、用戶意向?qū)傩浴?/p>
3.2.2 成對(duì)比較矩陣
在確定權(quán)重時(shí),Satty等人提出一致矩陣法,成對(duì)比較矩陣中aij的取值,盡可能的降低因元素性質(zhì)不同而難以比較的難度。比較矩陣的元素可參考Satty提議的標(biāo)度表進(jìn)行賦值。用成對(duì)法比較得到的成對(duì)比較矩陣A如下:
1/1 1/3 1/53/1 1/1 1/35/1 3/1 1/1
對(duì)應(yīng)的特征向量為Z=(0.1506,0.3715,0.9161)
3.2.3 相似度一致性檢測(cè)
衡量矩陣A不一致程度的指標(biāo)CI計(jì)算公式如下:
CI= (1)
從有關(guān)資料可查出成對(duì)比較矩陣A的隨機(jī)一致性指標(biāo)RI,它只與矩陣的階數(shù)n有關(guān),如表2。
由上式得
CI=0.0195,其中λmax=3.1085,n=3。endprint
所以成對(duì)比較陣A的隨機(jī)一致性比率CR可由公式(2)表示。
CR= (2)
因此,CR=0.0332<0.1,對(duì)特征向量進(jìn)行歸一化得:U=(0.1047,0.2583,0.6370)
因此該向量為計(jì)算的求職者屬性的下三個(gè)屬性的權(quán)向量。同理計(jì)算出其他屬性的權(quán)向量。結(jié)果圖1所示。
4 基于案例推理的推薦
本文模擬一位有轉(zhuǎn)崗需求且符合AI公司轉(zhuǎn)崗要求的用戶,在歷史案例庫里面隨機(jī)抽取10個(gè)案例進(jìn)行實(shí)驗(yàn),該用戶的詳細(xì)信息如表3。
從歷史案例庫中選取10個(gè)成功的求職案例,并進(jìn)行綱量化,可得出表4。
計(jì)算過程:
①基本屬性的相似度計(jì)算如下:
sim(1,X)1=0.09*0+0.06*1+0.53*+0.16*+0.16*1=0.503
②能力屬性相似度計(jì)算如下:
sim(1,X)2=0.38*1+0.08*+0.14*1+0.42*=0.727
③意向?qū)傩韵嗨贫扔?jì)算如下:
sim(1,X)3=0.26*+0.13*1+0.08*1+0.04*1+0.49*=0.647
因此,歷史案例與目標(biāo)案例的綜合相似度為:
sim(1,X)=0.1*sim(1,X)1+0.26*sim(1,X)2+0.64*sim(1,X)3=0.653
同理計(jì)算出其他屬性綜合相似度并由大到小排列為:
0.788>0.787>0.765>0.677>0.675>0.666>0.654>0.653>0.650>0.416
因此我們將這些相似度排在前5名對(duì)應(yīng)的員工的職位推薦給目標(biāo)用戶。
參考文獻(xiàn):
[1]趙柳.人力資源權(quán)益模式研究[D].成都:西南財(cái)經(jīng)大學(xué),2011:1-2.
[2]梁艷.基于基于案例推理的職位推薦[D].河北師范大學(xué),2012.
[3]任凱,浦金云.基于案例屬性特征區(qū)間相似度的改進(jìn)算法研究[J].控制與決策,2010,25(1):308-310.
[4]黃正.協(xié)同過濾推薦算法綜述[J].價(jià)值工程,2012,21(1),226-228.
[5]杜淼.兩類層次分析法的轉(zhuǎn)換及在應(yīng)用中的比較[J].計(jì)算機(jī)工程與應(yīng)用,2012,48(9):114-119.endprint
