基于刻面分類標識和聚類樹的構件檢索方法
2017-12-14 05:22:22錢曉捷杜勝浩
計算機應用 2017年10期
錢曉捷,杜勝浩
(鄭州大學 信息工程學院,鄭州 450001) (*通信作者電子郵箱iezzdxdsh@126.com)
基于刻面分類標識和聚類樹的構件檢索方法
錢曉捷,杜勝浩*
(鄭州大學 信息工程學院,鄭州 450001) (*通信作者電子郵箱iezzdxdsh@126.com)
針對如何從規模龐大的軟件構件庫中快速且高效地檢索出目標構件的問題,提出一種基于刻面分類標識和聚類樹的構件檢索方法。使用構件標識集合對構件進行刻面分類標識描述,克服了單純采用刻面分類法對構件進行分類描述和檢索時帶來的主觀因素的影響;引入聚類樹的思想,對構件進行基于語義相似度的聚類分析,建立構件聚類樹,能有效地縮小檢索范圍,減少檢索構件與構件庫中構件比較的次數,提高檢索效率。最后在實驗中與一般檢索方法對比,實驗結果表明該方法的構件查準率為88.3%,查全率為93.1%;而且在大規模的構件庫中使用時依然有良好的檢索效果。
軟件構件;刻面分類;構件標識;聚類樹;構件檢索
0 引言
構件是軟件的基本構成成分,也是軟件體系結構的基本構成要素。目前,軟件構件技術已經比較成熟。如何從規模龐大的構件庫中快速準確地檢索到軟件開發者所需的軟件構件仍是一個值得研究的問題。構件的檢索與構件的描述和分類有著非常密切的關系,對構件進行合理的描述和分類,在構件檢索時能夠簡化檢索過程、提高檢索效率。目前,大部分的構件檢索方法都基于刻面分類方法。刻面分類法被廣泛應用于歐洲和印度的圖書館[1],Prieto-Díaz[2]將其引入到軟件復用和構件檢索領域[2]。國外系統工程領域的專家在其提出的3C(Concept, Content, Context)構件模型中對構件描述時采用了刻面分類表示方法,Srinivas等[3]采用聚類分析的方法提高構件檢索的效率;Vodithala等[4]使用遺傳算法優化構件檢索;Dutta等[5]基于圖的方法在構件庫中進行構件檢索。在國內,王淵峰等[6]基于刻面分類描述構件并結合樹匹配思想進行了構件檢索的實驗;陸敬筠等[7]針對刻面描述構件檢索方法的不足,結合領域本體相關知識,采用領域本體和刻面描述相結合的方法進行了構件檢索研究;張雷等[8]也針對構件的描述提出了構件的標識表示與自動提取算法,并采用功能倒排索引檢索構件庫中的構件;童浩等[9]在蟻群算法的基礎上提出了基于數據挖掘的構件決策模型,輔助構件的檢索工作;姚全珠等[10]基于樹匹配的思想,通過計算葉子節點親和度進行構件匹配,提出了云端構件匹配模型。
本文結合刻面分類和構件的標識對構件進行描述,通過構件標識集合從構件描述文本中提取功能術語,利用向量表示文本,構建構件的向量空間模型,使構件檢索匹配問題轉化為向量空間中向量計算的問題,實現構件間的松弛匹配。同時使用基于語義相似度的構件聚類算法,建立一棵構件聚類索引樹,從而增大了構件檢索的查全率和查準率,提高了構件的檢索效率。
1 構件的標識表示與向量化
1.1 構件的標識表示
構件的標識用來表示構件的主要信息。考慮到構件檢索的特點和詞頻權重等因素,構件的標識集合應包括領域術語集合和刻面術語集合。本文對構件的標識表示基于刻面分類法,采用多面分類機制并結合Web服務需求,將構件的屬性劃分為層次、應用領域、 操作系統和形態四個主刻面,每個主刻面下包含若干子刻面。其中,每個刻面都由一組基本的術語構成[11]。根據構件標識集合對構件進行特征詞提取,其提取過程如圖1所示。
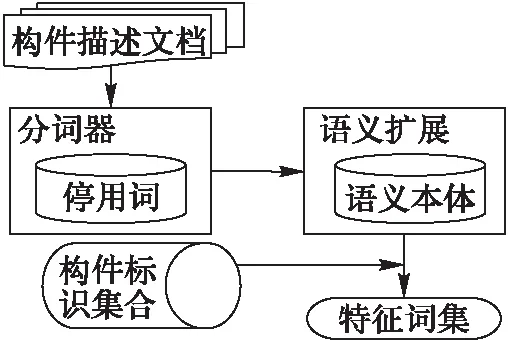
圖1 特征詞提取過程示意圖
對構件描述文本分詞時,導入手工輸入的停用詞集,過濾停用詞;根據語義庫的內容對分詞結果擴展,結合構件標識集合得到構件特征詞。采用特征詞集對構件進行標識表示,能夠更加準確地描述構件的特征,方便了構件向量模型的建立,從而簡化了構件相似度的計算。
1.2 構件標識向量化
對構件進行標識表示時,構件的特征詞間相互獨立,利用向量來表示構件標識文本,構造構件向量,建立向量空間模型。在構件向量空間模型中,構件是由構件標識(特征詞)組成的集合,并且每個特征詞都有其相應的權重,將權重值作為向量值構成構件向量。例如,構件Comp表示為C={t1,t2,…,ti,…,tn},其中,ti(1≤i≤n)為第i個特征詞,n為特征詞的個數;同時,對ti給定其權重wi,即CW=(w1,w2,…,wi,…,wn)。特征詞權重的計算方法通常是使用詞頻-逆向文件頻率(Term Frequency-Inverse Document Frequency, TFIDF)算法,該算法最早由Salton等在文獻[12]中提出,并隨著不同研究人員的研究不斷改進。本文對構件進行標識表示時,一個構件可能沒有某些子刻面(構件庫中存在構件含有這些子刻面)。因此,本文中計算特征詞權重值的公式采用文獻[13]中使用的特征詞加權公式,公式形式如下:
(1)
其中:CWi為構件的第i個特征詞ti的權重值;fi表示ti在構件庫中出現的頻率;n為構件庫中構件總數;ni為構件庫中含有ti的構件數;m為采用刻面分類描述構件標識得到的特征值(子刻面)的總數;d為構件Comp的標識描述中含有的特征詞的個數。使用詞頻來代替傳統用0和1表示向量,完成構件的向量化表示,有利于體現特征詞在構件描述中的作用程度。
2 構件聚類樹
2.1 構件聚類樹的結構
聚類樹是一種數據集聚類分層表示的樹結構[14-15]。聚類樹將數據劃分為層次結構,從而成為一個高效檢索的索引結構。本文中的構件聚類樹是一棵非空的5層結構的聚類樹,其結構如圖2所示。
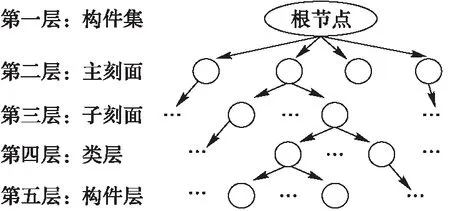
圖2 構件聚類樹結構
該聚類樹有且只有一個根節點,代表構件庫中所有構件組成的構件集,根節點為聚類樹的第一層;第二層為主刻面層,粗略地對構件進行劃分;第三層為子刻面層,對主刻面下的構件進行細致的劃分,將構件劃分到某個子刻面;第四層為類層,對屬于同一子刻面的構件進行聚類,得到若干聚類中心;第五層為構件層即葉子節點層,該層的節點包含構件的特征詞并指向具體的構件。
2.2 構件聚類樹的構造過程
構件庫中所有構件組成的集合構成了該聚類樹的根節點,得到構件聚類樹的第一層。按照刻面分類劃分的主刻面粗略地將構件劃分到各個主刻面下,形成第二層。然后,根據主刻面下的子刻面對構件進行詳細劃分,同一主刻面下,構件只屬于某一個子刻面,形成第三層。第四層為類層,是對子刻面下的構件聚類得到的,本文采用K近鄰聚類算法對構件進行語義相似聚類。文中通過計算兩個構件向量的余弦相似度來表示這兩個構件的相似程度,計算公式如下:

(2)
其中:Sim(C1,C2)是構件Comp1和構件Comp2的余弦相似度;CW1i是構件Comp1的第i個子刻面的向量權重;CW2i是構件Comp2的第i個子刻面的向量權重;m是采用刻面分類描述構件標識得到的特征詞(子刻面)的總個數。子刻面下構件聚類的步驟如下:
Step1 初始化聚類中心。將構件庫中的構件按照式(1)向量化,從子刻面下的構件中選取k個構件作為初始聚類中心,在選擇聚類中心時盡量使得k個作為中心的構件的相似度很小,得初始聚類中心Cl=(Cl1,Cl2,…,Clk)。
Step2 根據式(2),分別計算當前子刻面下其他構件與這k個作為類中心的構件的相似度,并歸類于與其相似度最大的那個聚類中心。
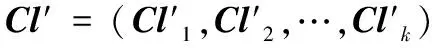
Step4 判斷新得到的聚類中心Cl′與原聚類中心Cl是否完全相同,若完全相同則結束聚類,跳到Step7;否則判斷count的值是否小于1 000,若不小于則跳到Step7,否則繼續向下執行。
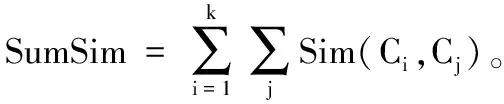

Step7 聚類完成,結束聚類算法。
對每個子刻面下的構件都按照上述聚類算法進行聚類,于是得到構件聚類樹第四層的節點。聚類樹第五層為構件層,屬于同一類的構件被分在一個類下,構件層的節點直接指向其對應的具體的構件。
3 基于刻面標識和聚類樹的構件檢索
3.1 構件檢索機制
構件檢索與構件的分類和描述密切相關,不同的分類方法對應著不同的檢索機制。通過刻面分類標識關聯的特征詞集合,多角度標識待檢索構件。另外,匹配松散度也是構件檢索中得一個重要參數。檢索條件與檢索結果精確匹配是所有研究人員最為想要的,但在實際實驗過程中,這種精準匹配的機會并不多,大多數情況下還是尋找能夠最大相似匹配的構件。目前,基于刻面描述的構件的檢索主要采用的還是以傳統的數據庫檢索技術為主,并結合同義詞詞典和刻面術語間的層次結構來實現構件的松弛匹配[6]。
本文的檢索方法基于語義相似度,具備一定的模糊匹配功能;另外,用戶對要檢索的構件的描述可能不完整,不能包含所有刻面分類標識集合中的特征詞,本文的檢索方法為用戶設置默認值,使其具備一定的張弛能力,從而使檢索結果具有良好的查準率與查全率。
3.2 構件檢索過程
經過構件的向量化處理,構件檢索最終轉化為構件相似度的計算。其基本思想如下:在建立了構件聚類樹的基礎上,根據采用刻面分類法劃分得到的刻面分類標識集合提取待檢索構件(用戶的檢索條件QU)描述中的特征詞,根據構件向量模型將待檢索構件向量化。
(3)
待檢索構件的特征詞的權重值計算公式與式(1)略有不同,采用式(3)進行計算。其中,QWi為檢索構件Query的第i個特征詞ti的權重值,fi為ti在構件庫中出現的頻率,n為構件庫中的構件總數,ni為構件庫中含有ti的構件數,m為基于刻面分類描述構件標識得到的特征值(子刻面)的總個數,d為檢索構件Query的標識描述中含有的特征詞的個數。依次計算檢索構件與構件聚類樹第四層的類層中的各個節點(表示聚類中心的構件)的相似度,相似度計算公式類似于式(2),即
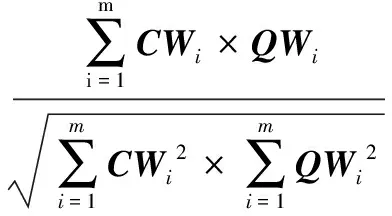
(4)
其中:Sim(C,QU)是作為聚類中心的構件Comp與檢索構件Query的余弦相似度;CWi是構件Comp的第i個子刻面的向量權重;QWi是檢索構件Query的第i個子刻面的向量權重;m是基于刻面分類描述構件標識得到的特征詞(子刻面)的總個數。在每個子刻面的多個聚類中心中選取與檢索構件相似度最大的聚類中心,記錄該類中的所有構件。根據刻面劃分原理,一個主刻面下不同子刻面包含的構件不同,與檢索構件擁有較高相似度的聚類中心下的所有構件都可作為檢索結果候選構件,于是對同一主刻面不同子刻面下被記錄的構件求并集;由于一個構件含有多個刻面值(特征詞),故同一個構件會出現在不同主刻面下,因此再對不同主刻面下滿足條件的所有構件求交集,使得到的檢索結果中的構件不重復。計算所得構件集合中的構件與檢索構件的相似度,滿足要求的構件與檢索構件的相似度記為S1(0≤S1≤1);上述構件集合中的構件在不同主刻面下都有其與所屬類的聚類中心的相似度,為了體現聚類中心在計算檢索構件與檢索結果中的構件的最終相似度的作用,將構件在不同主刻面下的相似度求和取平均數,記為S2(0≤S2≤1),于是可以得到檢索構件與上述構件集中構件的最終相似度記為S(0≤S≤1),S=(S1+S2)/2。通過在不同閾值下進行的實驗測試,發現閾值取為0.7,即構件相似度S≥0.7時,檢索結果的查準率和查全率較好,故在本文中閾值設為0.7,第5章的實驗也是在此默認值下進行的。最后,對相似度S≥0.7的構件進行排序,得到最終檢索結果。
算法流程描述如下。
輸入 檢索構件Query描述文本;構件聚類樹T;構件刻面標識集合FT。
輸出 相似度從大到小的N個構件。
1)
forFT中的所有特征詞
2)
if(FT的特征詞i在檢索構件的描述中出現)
3)
array_Qi=1;
4)
else
5)
array_Qi=0;
6)
array_QWi=QWi;
7)
end for;
8)
forT的類層中的所有節點
9)
Sim_QC=Sim(C,QU);
10)
end for;
11)
forT的子刻面層的所有節點
12)
maxSim=max(Sim_QC,k);
13)
相似度最大類中的所有構件保存到maxSim_C;
14)
end for;
15)
forT的主刻面層的所有節點
16)
unionCQ=Union(maxSim_C,n);
17)
unionCQ中的構件與聚類中心的相似度的值保存到unionCQ_Sim;
18)
end for;
19)
array_mixCQ=Mix(unionCQ,n);
20)
array_mixCQ_Sim記錄array_mixCQ中的構件與所屬類中心的相似度;
21) forarray_mixCQ中的所有構件
22)
S1=Sim(C,QU);
23)
S2=n個主刻面下的相似度的平均值;
24)
if((S1+S2)/2≥0.7)
25)
result=(array_mixCQi, (S1+S2)/2);
26)
end for
27)
sort(result);
算法說明:步驟1)~7)是將檢索構件進行向量化表示,步驟6)按式(3)進行計算;步驟8)~10)用式(4)計算檢索構件與聚類樹類層各節點(即作為聚類中心的構件)的相似度;步驟11)~14)是選取與檢索構件相似度最大的節點作為聚類中心,步驟12)中的k為聚類個數;步驟15)~18)是對同一主刻面下不同子刻面中所有構件求并集;步驟19)和步驟20)是對不同主刻面下得到的構件集合求交集同時記錄構件與所屬聚類中心的相似度;步驟21)~26)是計算檢索構件與符合要求構件的總相似度;步驟27)是將得到的檢索結果中的構件排序呈現給用戶。該檢索算法的空間復雜度取決于構件的個數;由于構件庫的刻面數一般不超過8個,在本文算法中相對于構件的個數可以忽略不計,故算法的時間復雜度為O(n)。
4 實驗結果及分析
為驗證本文所提出的構件檢索方法能提高檢索的效率,本文使用模擬構件庫進行構件檢索實驗。通過對開源中國(www.oschina.net)的開源軟件庫中的部分開源組件和控件(視為構件)信息進行采集處理得到實驗數據集,構建了一個包含Web應用、程序開發、圖像處理、數據庫、手機/移動開發等領域共2 559個構件的本地構件庫。
檢索效果通過評測查準率P、查全率R和F-measure[16]三個指標來體現。三個指標的計算公式分別為P=nr/Nq,R=nr/Nr,F-measure=2PR/(P+R),其中:nr是檢索結果中滿足檢索條件的構件個數;Nq是檢索得到的構件的總個數;Nr是構件庫中滿足檢索條件的構件個數。F-measure是對檢索結果的查準率和查全率的一個綜合評價,能夠有效地評價檢索的查準和查全效果。只有當P和R相近且都較大時,F-measure才會較高。
4.1 實驗結果對比實驗
分別根據文獻[8]和文獻[17]的思想實現了基于構件標識自動提取的功能倒排索引構件檢索方法和分級聚類索引構件檢索方法,并與本文提出的檢索方法在相同的數據集和實驗平臺上進行對比實驗。為突出聚類樹在本文所提出的檢索方法的作用,本文還實現了基于刻面分類標識和聚類分析的構件檢索方法,這種方法類似于文獻[13]中提出的檢索方法,不使用聚類樹思想,在構件向量化表示之后直接對構件庫中的構件聚類,檢索時采用第3章中描述的檢索方法。因此,對比實驗共分為4組,各組對應檢索方法如表1所示。

表1 四組構件檢索方法
通過Matlab 8.5實驗仿真平臺和MyEclipse10對上述算法進行實現。分別對這4組方法進行10次檢索實驗,每次實驗使用30個檢索構件,計算得到查準率和查全率的平均值,再計算F-measure的值。各組檢索結果如表2所示。

表2 檢索實驗數據對比表
從表2中的4組實驗檢索結果可以明顯看出D組的查準率、查全率和F-measure的值都要比C組的高很多,說明在檢索方法中采用了聚類樹比單純使用聚類分析得到的效果較好。另外,也可看出相對于A組和B組的檢索方法,使用本文提出的檢索方法(D組)得到的查準率和查全率有明顯提高,而且F-measure的值也比其他兩種方法得到的要大。
4.2 擴大構件庫規模實驗
考慮到構件庫的規模正逐漸擴大,為驗證本文方法在大規模構件庫中檢索時的效果依然良好,采用隨機抽取本地構件庫中的構件重復入庫的方法[8],增加本地構件庫中構件的數量。分別在7 677個、12 795個、17 913個以及23 031個構件的模擬構件庫中重新進行檢索實驗,依然進行10次、每次30個檢索構件的檢索實驗。查準率、查全率和F-measure值的實驗結果分別如圖3~5所示。

圖3 不同構件庫規模的查準率比較
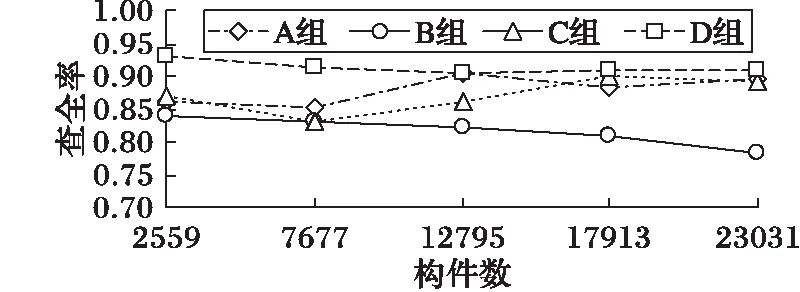
圖4 不同構件庫規模的查全率比較
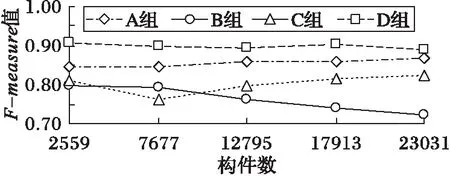
圖5 不同構件庫規模的F-measure值比較
另外,為說明構件庫規模增大后算法的檢索效率情況,給出不同算法查詢響應時間,如圖6所示。
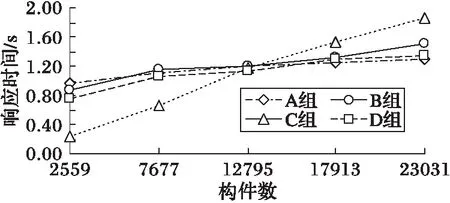
圖6 不同構件庫規模的查詢響應時間比較
實驗結果表明,構件庫的規模增大后,本文算法的查準率和查全率仍在87%以上,F-measure值保持在0.90左右,比其他三種算法的檢索結果要好;而且查詢響應時間的增加在對數級別以下。所以,本文方法是行之有效的,而且擁有較好的檢索效果,同時也可在規模較大的構件庫中使用。
5 結語
本文提出的基于刻面分類標識和聚類樹的構件檢索方法對構件進行刻面分類標識描述,并通過構件向量模型將構件向量化表示,建立構件聚類樹,在檢索構件時直接計算檢索構件與聚類中心的語義相似度,將具有較高相似度的構件提供給用戶供用戶選擇。實驗結果表明,本文的檢索方法有著較高的查準率與查全率,并且在構件庫規模的擴大后依然有較好的檢索效果。本文方法的檢索效果依賴于構件的描述和構件聚類,因此后續工作將對構件的描述方法和構件聚類算法進行重點研究,結合Web服務發現領域的相關知識,完善構件描述方法、優化構件聚類,從而進一步提高檢索效果。
References)
[1] RANGANATHAN S R, GOPINATH M A. Prolegomena to Library Classification [M]. 3rd ed. Madras: Madras Library Association, 1967.
[3] SRINIVAS C, RADHAKRISHNA V, RAO C. Clustering and classification of software component for efficient component retrieval and building component reuse libraries [J]. Procedia Computer Science, 2014, 31(1): 1044-1050.
[4] VODITHALA S, PABBOJU S. A dynamic approach for retrieval of software components using genetic algorithm[C]// Proceedings of the 2015 IEEE International Conference on Software Engineering and Service Science. Piscataway, NJ: IEEE, 2015: 406-410.
[5] DUTTA S, SENGUPTA S. Retrieval of software component version from a software version database: a graph based approach [C]// Proceedings of the 2015 International Conference on Advances in Computer Engineering and Applications. Piscataway, NJ: IEEE, 2015: 255-259.
[6] 王淵峰, 張涌, 任洪敏, 等.基于刻面描述的構件檢索[J]. 軟件學報, 2002, 13(8): 1546-1551. (WANG Y F, ZHANG Y, REN H M, et al. Retrieving components based on faceted classification [J]. Journal of Software, 2002, 13(8): 1546-1551.)
[7] 陸敬筠, 宋培鐘.領域本體和刻面描述相結合的構件檢索研究[J]. 計算機應用與軟件, 2013, 30(8): 36-38. (LU J Y, SONG P Z. On component retrieval method based on the combination of facets description and domain ontology [J]. Computer Applications and Software, 2013, 30(8): 36-38.)
[8] 張雷, 陳立潮, 潘理虎, 等.構件的標識表示與檢索方法研究[J]. 小型微型計算機系統, 2013, 34(5): 1076-1079. (ZHANG L, CHEN L C, PAN L H, et al. Study on tags representation of components and tags based components retrieval [J]. Journal of Chinese Computer Systems, 2013, 34(5): 1076-1079.)
[9] 童浩, 孫航, 李晶, 等.基于改進蟻群算法的構件檢索方法[J]. 計算機應用研究, 2015, 32(7): 2057-2059, 2064. (TONG H, SUN H, LI J, et al. Method based on improved ant colony algorithm for component retrieving [J]. Application Research of Computers, 2015, 32(7): 2057-2059, 2064.)
[10] 姚全珠, 馮歡, 田琳, 等.基于云端的構件庫檢索模型[J]. 計算機應用, 2016, 36 (增刊1): 262-264. (YAO Q Z, FENG H, TIAN L, et al. Retrieval model based on cloud component library [J]. Journal of Computer Applications, 2016, 36 (Supp1): 262-264.)
[11] 王映輝.構件式軟件技術[M]. 北京: 機械工業出版社, 2012: 86. (WANG Y H. Component-Based Software Technology [M]. Beijing: China Machine Press, 2012: 86.)
[12] SALTON G, CLEMENT T Y. On the construction of effective vocabularies for information retrieval[C]// SIGPLAN 1973: Proceedings of the 1973 Meeting on Programming Languages and Information Retrieval. New York: ACM, 1973: 11.
[13] 劉大昕, 趙磊, 王卓, 等.一種基于刻面分類和聚類分析的構件分類檢索方法[J]. 計算機應用, 2004, 24 (增刊1): 89-90. (LIU D X, ZHAO L, WANG Z, et al. A method of component classification retrieval based on facet classification and cluster analysis [J]. Journal of Computer Applications, 2004, 24 (Supp1): 89-90.)
[14] YU D T, ZHANG A D. Cluster tree: integration of cluster representation and nearest neighbor search for large datasets with high dimensions [J]. IEEE Transections on Knowledge and Data Engineering, 2003, 15(5): 1316-1337.
[15] 田曉珍, 任姚鵬, 王春紅, 等.一種改進的構件聚類索引樹的研究[J]. 現代計算機, 2014(8): 12-15, 25. (TIAN X Z, REN Y P, WANG C H, et al. Research on an improved component cluster index tree [J]. Modern Computer, 2014(8): 12-15, 25.)
[16] RIJSBERGEN C J. Information Retrieval [M]. London, UK: Butterworths Press, 1979: 120.
[17] 王文霞.基于分級策略和聚類索引樹的構件檢索方法[J]. 計算機技術與發展, 2016, 26(4): 110-11. (WANG W X. A component retrieval method based on classified policy and cluster index tree [J]. Computer Technology and Development, 2016, 26(4): 110-11.)
Componentretrievalmethodbasedonidentificationoffacetedclassificationandclustertree
QIAN Xiaojie, DU Shenghao*
(SchoolofInformationEngineering,ZhengzhouUniversity,ZhengzhouHenan450001,China)
To quickly and efficiently retrieve the target component from a large software component library, a component retrieval method based on identification of faceted classification and cluster tree was proposed. The component with facet classification identification was described by using the set of component identification, which overcomes the impact of subjective factors when only using facets classification to describe and retrieve components. By introducing cluster tree, the component cluster tree was established by analysis clustering of components based on semantic similarity, thus narrowing the retrieval area, reducing the number of comparisons with component libary, and improving the search efficiency. Finally, the proposed method was experimented and compared with other common retrieval methods. The results show that the precision of the proposed method is 88.3% and the recall ratio is 93.1%; moreover, the proposed method also has a good retrieval effect when searching in a large-scale component library.
software component; faceted classification; component identification; cluster tree; component retrieval
2017- 05- 11;
2017- 06- 29。
國家社會科學基金資助項目(14BYY096)。
錢曉捷(1963—),男,江蘇無錫人,副教授,碩士,CCF會員,主要研究方向:嵌入式系統、計算機系統結構; 杜勝浩(1990—),男,河南濮陽人,碩士研究生,主要研究方向:軟件體系結構、數據挖掘。
1001- 9081(2017)10- 2973- 05
10.11772/j.issn.1001- 9081.2017.10.2973
TP311.131
A
This work is partially supported by the National Social Science Foundation of China (14BYY096).
QIANXiaojie, born in 1963, M. S., associate professor. His research interests include embedded system, computer system architecture.
DUShenghao, born in 1990, M. S. candidate. His research interests include software architecture, data mining.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
兒童故事畫報(2019年5期)2019-05-26 14:26:14
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
少兒科學周刊·少年版(2015年3期)2015-07-07 21:00:00
