基于負載感知的數據流動態負載均衡策略
2017-12-14 05:36:04李梓楊王躍飛
計算機應用 2017年10期
李梓楊,于 炯,,卞 琛,王躍飛,魯 亮
(1.新疆大學 軟件學院, 烏魯木齊 830008; 2.新疆大學 信息科學與工程學院, 烏魯木齊 830046) (*通信作者電子郵箱yujiong@xju.edu.cn)
基于負載感知的數據流動態負載均衡策略
李梓楊1,于 炯1,2*,卞 琛2,王躍飛2,魯 亮2
(1.新疆大學 軟件學院, 烏魯木齊 830008; 2.新疆大學 信息科學與工程學院, 烏魯木齊 830046) (*通信作者電子郵箱yujiong@xju.edu.cn)
針對大數據流式計算平臺中存在節點間負載不均衡、節點性能評估不全面的問題,提出基于負載感知算法的動態負載均衡策略,并將算法應用于Flink數據流計算平臺中。首先通過有向無環圖的深度優先搜索算法獲取節點的計算延遲時間作為評估節點性能的依據,并制定負載均衡策略;然后基于數據分塊管理策略實現流式數據的節點間負載遷移技術,通過反饋實現全局和局部的負載調優;最后通過實驗評估時空代價論證算法的可行性,并討論重要參數對算法執行效果的影響。經實驗驗證算法通過優化流式計算任務的負載分配提高了任務的執行效率,與采用Flink平臺現有的負載均衡策略相比,任務執行時間平均縮短6.51%。
數據流;負載均衡;深度優先搜索;負載感知; Apache Flink
0 引言
隨著云計算、物聯網、移動互聯和社交媒體等新技術和新服務模式的不斷興起,全球數據量呈爆炸式增長趨勢,人類已經全面進入大數據[1]時代。大數據蘊含大信息,大信息提煉大知識,大知識創造高價值并從更高的層面為用戶提供更優質的服務。同時,數據價值的時效性變得越來越明顯,為了更及時地從數據中提煉有價值的信息,必須不斷提高數據分析的實時性,大數據流式計算應運而生。與批處理模式[2]相比,流處理模式[3]具有實時性、易失性、無序性、無限性和突發性的特征[4],能夠在數據產生后即時提煉價值,已在對數據分析實時性要求較高的場景中得到廣泛應用。為了滿足這種實時性要求,集群應具備較高的響應能力和較低的計算延遲,同時要求計算結果的準確性和可靠性[5],這對流式計算的技術發展提出了更高的要求。然而面對高速連續大規模的數據,計算節點間負載傾斜的問題尤為突出,嚴重影響了集群的性能。但已有的研究成果多面向批處理環境,無法應用于流式計算平臺,負載不均衡仍是制約流式計算集群響應能力和吞吐量的瓶頸。
Apache Flink[6-9]是針對流數據處理的分布式計算平臺,支持流處理和批處理兩種模式,提供Exactly-Once的可靠性流式計算[10]和豐富的時間窗口[11]機制。憑借低延遲、高吞吐的性能優勢[12],Flink在得到學術界廣泛關注的同時,也在產業界的應用中取得顯著成果:阿里巴巴構建了上千節點的Blink集群參與在線搜索和實時推薦業務,Google云平臺宣布對Flink的相關技術支持。但在不斷深入的產業化進程中Flink也面臨一些挑戰,須經過不斷改進和完善以滿足應用需求。本文提出基于Flink的數據流動態負載均衡策略,通過負載感知算法獲取節點的計算延遲時間作為負載均衡策略的依據。實驗結果表明,本文算法能通過優化負載分配縮短任務的執行時間,平均優化比達到6.51%。
1 相關工作
在大數據流式計算中,數據由源點(Source)發出,依次經過不同算子(Operator)的處理,最終計算結果在匯點(Sink)被持久化。在不考慮迭代計算的前提下,計算節點的拓撲是一個AOV-網(Activity On Vertex Network),其中節點代表處理數據的算子,弧代表數據流動的方向。而在分布式數據流計算中,同一個算子往往被映射到多個不同的物理節點上,這樣每個計算節點都可能有多個前驅和多個后繼。在傳統的流式計算平臺中,數據元組大多以〈key,value〉的形式在節點間被計算和傳輸,節點根據元組key的Hash值決定每個元組的路由。但這種方式本身具有一定的隨機性和盲目性,用戶無法干預數據元組的路由選擇,節點也不考慮其后繼的計算負載而是隨機地完成交付。不可避免地,會出現在某一時間段內大多數元組被發往相同的目標節點,而其他節點沒有得到負載分配,從而導致節點間負載傾斜。在Flink中,節點對數據元組的路由策略主要有廣播、輪詢和隨機分配三種方式[7],均不考慮節點的負載情況,會造成與上述同樣的問題。
為了更好地解決數據流負載均衡問題,已有學者提出了基于各種資源評估模型和感知策略的負載均衡算法,但極少應用于Flink平臺:文獻[13]提出一種用靈活算子遷移算法解決內存不足造成的背壓(Backpressure)問題,以理論計算的節點剩余內存作為性能評估指標,即最大可持續吞吐量(Maximum Sustainable Throughput, MST)。文獻[14]根據關鍵路徑上的性能感知和非關鍵路徑上的能耗感知數據制定任務調度計劃,達到響應時間與能耗的最低值;但未考慮計算節點的內存、網絡等其他性能指標的影響。文獻[15]針對Storm平臺分別提出在線和離線的自適應任務調度策略,有效減小了任務調度中的通信開銷,但算法本身復雜度很高。文獻[16]提出的SkewReduce策略建立了用戶定義的代價模型,根據任務執行中收集的元數據在鄰近代價閾值時啟動分區映射過程,實現負載的均勻分配。文獻[17]提出針對用戶定義數據流上的延遲評估模型,通過計算資源和任務并行度的彈性變化,在計算資源最小化的同時提供低延遲保障;但資源彈性變化和任務調度過程開銷較大。
針對上述存在的問題,本文的主要工作有:
1)針對單一性能評估指標存在的局限性,提出依據節點處理元組的延遲時間評估節點性能的思想。
2)提出一種基于有向無環圖(Directed Acyclic Graph, DAG)的深度優先搜索的負載感知(load-aware)算法,用于檢測節點的計算延遲時間,將流式計算模型的AOV-網轉化為AOE-網(Activity On Edge Network),每個計算節點都能獲取其后繼的負載信息,為路由決策提供支持。
3)提出一種負載均衡策略,節點可根據負載感知的檢測結果重新分配其后繼的計算負載,該策略可同時滿足全局和局部的負載均衡需求。
4)提出一種流式數據分塊管理的思想,通過小頂堆結構管理數據塊,提出有狀態(stateful)流式計算的分塊負載遷移技術。
2 負載感知技術
在分布式計算環境下,負載均衡策略的依據是計算節點的資源利用率,通過將資源利用率過高節點的計算負載遷移到資源利用率較低的節點中實現節點間負載的均衡。一個節點的可用資源包括CPU、內存、磁盤I/O、網絡傳輸等,而現有研究成果多將CPU或內存利用率等單一指標作為性能評估依據,這在實際應用中是存在局限性的。
事實上,節點中任何一種資源的匱乏都會成為節點響應能力的瓶頸,導致數據元組在內存中被滯留而計算延遲加長。因此,任何單一的性能評估指標在實際應用中都存在局限性,而計算延遲是反映節點負載和響應能力的綜合體現,延遲越長說明節點負載越高、響應能力越弱;反之說明節點有充足的剩余計算資源。負載感知技術通過延遲檢測算法獲取節點的計算延遲數據,并將其作為制定負載均衡策略的依據。
2.1 延遲檢測算法
為了獲取數據元組經過每個節點的延遲時間,通過有向無環圖的深度優先搜索算法遍歷整個節點拓撲,為每個節點不同的訪問狀態標記不同的顏色,并記錄每個節點狀態改變的時間戳:初始狀態下所有節點都標記為白色,表示節點未被訪問過。當節點被首次發現后標記為灰色,并記錄當前時間為節點的發現時間(Operator discover time, O.d)。當節點的所有后繼都被訪問完成且數據到達匯點后,該節點被標記為黑色,表示已完成對該節點對應所有路由的檢測,同時記錄當前時間為節點的完成時間(Operator finish time, O.f)。
由上述可知,發現時間是節點收到數據元組的時間,完成時間是由該節點發出的數據元組完成所有計算并到達匯點的時間,是一條路徑的完成時間。特別地,數據源點的發現時間是其發出數據元組的時間,完成時間是集群中每個節點都完成一次計算的時間;而匯點不對數據進行處理且沒有后繼,其發現時間與完成時間相等,都是其收到數據元組的時間,即source.f=sink.f=sink.d。
集群在算法開始執行前根據其結構拓撲圖執行相關初始化操作:將所有節點的訪問狀態標記為白色,節點的發現和完成時間都記為空(NIL),通過DFS-Visit(G,G.source)調用節點訪問算法,從源點開始對整個拓撲進行深度優先搜索。
算法1 DAG深度優先節點訪問算法。
輸入 節點拓撲DAG:G={V,E};當前待訪問的節點O。
輸出 當前節點發現時間O.d;當前節點完成時間O.f;當前節點及其后繼的延遲檢測表latency。
1)
init(latency);
/*初始化二維表latency用于記錄延遲時間*/
2)
O.d← getTimeStamp();
/*獲取當前系統時間戳作為節點O的發現時間*/
3)
O.color← GRAY;
/*將當前節點標記為灰色,表示該節點已被發現*/
4)
O.bsl← 0;
/*bsl為節點O黑色后繼的延遲時間和,初始值為0*/
5)
foreachS∈G.adj[O]
/*依次遍歷節點O的所有后繼*/
6)
ifS.color=WHITE then
/*如果后繼節點為白色,即尚未被訪問過*/
7) DFS-Visit(G,G.S);
/*對該后繼節點進行深度優先搜索*/
8)
else
/*由定理1可知,所有非白色的后繼節點均為黑色*/
9)
S.d←S.getDiscoverTime();
/*獲取上一次搜索得到的發現時間*/
10)
S.d←S.getFinishTime();
/*獲取上一次搜索得到的完成時間*/
11)
O.bsl←O.bsl+(S.f-S.d);
/*記錄所有黑色后繼的延遲時間和*/
12)
latency.add(S,S.d,S.f);
/*記錄后繼節點的發現時間和完成時間*/
13)
end if
14)
end foreach
15)
O.f← getTimeStamp()+O.bsl;
/*當前系統時間與黑色后繼延遲時間相加作為當前節點的完成時間*/
16)
O.color← BLACK;
/*將當前節點標記為黑色,表示該節點已完成搜索*/
17)
latency.add(O,O.d,O.f);
/*記錄當前節點的發現時間和完成時間*/
18)
load_ aware (O,latency);
/*利用2.2節所述策略,對當前節點執行局部的負載感知*/
19)
returnlatency;
/*返回當前節點及其后繼的延遲時間表*/
在DFS-Visit(G,O)第6)~12)行中,算法依次檢查當前待訪問節點的所有后繼,并從所有白色節點向后深度優先搜索。算法認為所有非白色后繼節點均為黑色,可直接獲取其上一次搜索中保存的發現和完成時間,并延長當前節點的完成時間(第11)行)。定理1保證了推斷的正確性,即保證算法的正確性以及每個節點有且僅有一組發現和完成時間。
定理1 黑白定理。在有向無環圖的深度優先搜索算法中,對于任意節點On及其任意一個后繼節點On+k,有On.dgt;On+k.f(On被發現時其后繼節點的訪問狀態為黑色)或On.dlt;On+k.dlt;On+k.f≤On.f(On被發現時其后繼節點的訪問狀態為白色)其中之一必然成立。
證明 當On.dlt;On+k.d時,即節點On+k在On被標記為灰色之后才被發現,且On+k是On的后繼,根據深度優先搜索的規則,只有當On+k被處理完成之后算法才返回On,On+k被標記為黑色的時間應在On之前,即On+k.flt;On.f。當On.dgt;On+k.d時,即On+k在On被發現之前先被發現,這說明On+k在對其另一個前驅的深度優先搜索過程中已經被訪問過,因此在On被發現之前On+k已經被標記為黑色,即On.dgt;On+k.f。
定理1說明在On第一次被發現的時刻,其所有后繼節點只可能為黑色或白色,不可能為灰色,所以算法的推斷是正確的。這樣保證每個節點僅被訪問一次,有且僅有一組發現和完成時間,保證負載感知一致性并減少遞歸調用的次數,降低算法的時間復雜度,提高效率。
當深度優先搜索算法完成后,整個集群完成對節點計算延遲的檢測并獲得檢測結果,每個節點On都得到如表1所示的計算延遲檢測表,其中On+k(1≤k≤m)為節點On的所有后繼,節點根據延遲檢測的結果進行負載感知并在需要時啟動負載均衡算法。

表1 計算延遲檢測表
2.2 基于AOE-網的負載感知
通過深度優先搜索的延遲檢測算法,獲取了每條路徑的計算延遲,On.f-On.d是節點On所對應路徑的延遲時間,即On的計算延遲。在流式計算節點拓撲圖中,如果將On+k的延遲作為弧On→On+k的權值,則可以將流式計算拓撲的AOV-網轉化為對應的AOE-網。
定義1 數據流AOE-網。如圖1所示,在數據流AOE-網中,每個節點代表對應算子的物理映射,弧代表對應的數據流向,弧的權值代表對應弧頭節點的計算延遲,記為:
w(On,On+k)=On+k.f-On+k.d
(1)
其中:On和On+k分別是該弧的弧尾和弧頭;On+k.d和On+k.f分別為節點On+k的發現和完成時間。對于指向同一個節點的兩條弧,由于在深度優先搜索算法中對其弧頭節點訪問了兩次,且第二次訪問時該節點為黑色,根據定理1及DFS-Visit算法第9)~12)行的執行結果,這兩條弧應具有相同的權值,即對應弧頭節點在第一次訪問時的計算延遲。
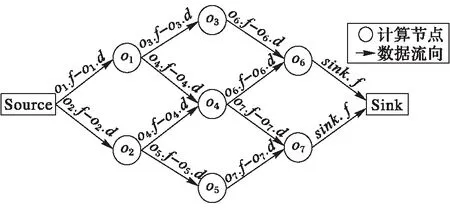
圖1 流式計算AOE-網拓撲圖
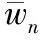
(2)
maxn=MAX(w(On,On+1),w(On,On+2),…,
w(On,On+m))
(3)
其中:w(On,Oi)是節點Oi的計算延遲,也是弧On→Oi的權值。計算延遲的方差為:
(4)
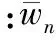
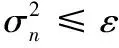
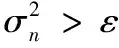
3 負載均衡策略
通過基于DAG的深度優先搜索的負載感知算法,獲取了每個節點的計算延遲。負載均衡策略的目標是通過將計算延遲過長節點的負載遷移到計算延遲較短的節點中去,即把負載過高節點的計算負載遷移到負載較低的節點中去,從而實現節點間的負載均衡。為了能夠控制和改變數據元組的路由,將節點的輸出數據分為不同的“塊”,并使用堆結構管理這些數據塊,實現有狀態流式計算的負載遷移技術,同時兼容Flink的狀態管理機制。
3.1 數據分塊與管理機制
流式數據的分塊機制是由計算節點對每個待輸出的數據元組執行兩次映射來確定對應的目標節點:節點先通過元組key的Hash值確定對應的數據塊,再通過數據塊的記錄找到對應的目標節點并輸出元組。
定義3 流式數據塊。設計算節點On的后繼節點集合為Sn={On+1,On+2,…,On+m},共包含m個節點且為同一算子的不同物理映射,該節點對應數據塊的集合為Bn={block1,block2,…,blockk},k?m,且每個block是一個三元組:
blocki=〈On,dest,size〉
(5)
其中:i是該數據塊的編號;On是該數據塊所屬的節點;dest是該數據塊對應的目標節點,即blocki.dest=Oj,且nlt;j≤n+m;size是該數據塊已經處理的元組數目,表示該數據塊的大小。k?m保證每個后繼節點對應多個數據塊。其中數據元組到block的映射采用傳統哈希映射法:
i=[Hash(key) modk]+1
(6)
則該元組對應的數據塊為blocki。當節點需要輸出一個元組時,先根據key的Hash值找到對應的數據塊,再通過blocki.dest記錄的內容找到對應的目標節點并輸出該元組,同時執行一次blocki.size++更新數據塊的大小。
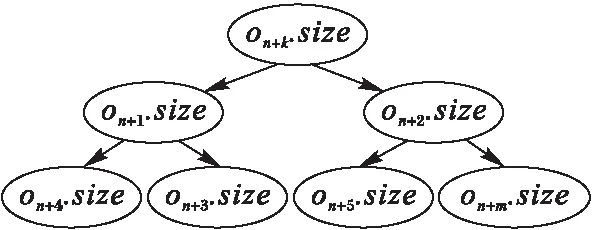
圖2 數據塊小頂堆結構
一般認為,在有狀態的流式計算中數據塊保存的狀態數據大小與處理過的數據量正相關,且遷移大數據塊產生的開銷較大,因此節點總是希望遷移數據量最小的塊以降低負載遷移的代價。如圖2所示,節點用堆管理數據塊,即所有數據塊按照block.size的大小構成小頂堆,堆頂元素為所有數據塊中數據量最小的。當堆頂元素被遷出或有新元素遷入時,由節點自動調整堆結構,保證堆頂元素始終是剩余元素中數據量最小的。這樣每次發生負載遷移時都遷出堆頂的數據塊,以降低負載遷移的開銷同時避免發生遷移抖動。
3.2 負載均衡與負載遷移策略
算法2 負載均衡算法。
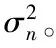
1)
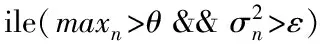
/*當參數超過設定的閾值時,反復執行負載均衡算法*/
2)
quicksort(Wn, desc);
/*對Wn中的元素降序排序*/
3)
fori←1 tom/2 do
/*從延遲最長的后繼節點向下依次執行負載遷移*/
4)
t← |Wn[i]-(Wn[i]+Wn[m-i])/2|;
/*計算待遷移數據塊的數目t*/
5)
load-migrate(Wn[i],Wn[m-i],t);
/*從Wn[i]向Wn[m-i]遷移t個數據塊*/
6)
end for
7)
Wn← DFS-Visit(G,On);
/*完成負載遷移后,對當前節點執行一次局部負載感知*/
8)
maxn← max(Wn);
/*根據式(3)計算Wn中計算延遲最長的元素*/
9)
/*根據式(4)計算Wn中所有元素的方差*/
10)
end while
由算法2可知,這是一種啟發式局部反饋的負載均衡策略,針對需要負載均衡的節點不斷檢測其后繼的負載情況并在需要時遷移負載,直到均衡為止。特別地,當On為數據源點時,是對整個集群進行負載均衡。
在算法2第5)行中,當需要遷移負載時通過調用遷移函數實現節點間的負載遷移,這里分別涉及到遷出節點On+i,遷入節點On+m-i及其前驅節點On。當需要從On+i向On+m-i遷移t個數據塊時,負載遷移的執行過程如下:
1)對節點On執行數據流靜默:暫停向遷出節點On+i發送數據元組,并將需要發送的元組保存在On的緩存中。
2)從遷出節點On+i的堆頂取出一個數據塊并調整堆結構,將該數據塊對應的狀態數據發送至遷入節點On+m-i,并調整其堆結構。
3)修改節點On記錄的對應數據塊路由信息,即block.dest←On+m-i,將該數據塊的元組路由到新的目標節點。
4)返回執行第2)步,將節點On+i中數據量最小的t個數據塊全部遷移至On+m-i后,執行第5)步。
5)恢復On被靜默的發送數據流,將其緩存中的數據發往新的目標節點。
數據流計算中節點間的高效負載遷移任務通過以上步驟完成。在Flink中,對于有狀態的流式計算,每個TaskManager的計算狀態存儲在自身的RocksDB數據庫中,并能夠定期將狀態的快照(Snapshot)信息固化在文件系統或Hadoop分布式文件系統(Hadoop Distributed File System, HDFS)中。這能夠很好地兼容負載均衡和遷移策略:如果將節點的狀態數據以塊為單位進行組織和存儲,并使用堆管理這些數據塊,就可用負載遷移算法實現節點間有狀態流式數據的負載遷移。
3.3 參數影響與代價評估
實驗結果表明,部分參數的取值對算法的執行效果有影響:θ和ε是由用戶設定的兩個參數值,也是啟動負載遷移算法的閾值,它們共同決定了負載感知算法的敏感程度,決定了負載感知算法的敏感程度:閾值過小會導致算法過于敏感,負載遷移過于頻繁甚至出現遷移抖動的現象;閾值過大會導致算法過于遲鈍,造成數據元組被阻塞,使下一次負載遷移產生較大的時空代價。k是每個節點數據分塊的數目,它決定了負載遷移的粒度,k的值應遠大于節點后繼的數目,這樣保證每個節點都對應多個block。參數值過小會導致每個數據塊元組數量過多,負載遷移開銷過高,產生過度遷移和遷移抖動的問題;參數值過大會影響算法的執行效率,需要多次負載感知和遷移才能實現負載均衡。因此參數的取值對算法的執行效果至關重要。
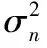
在空間上,計算延遲檢測表中的數據包括節點名稱和對應的兩個時間戳。在Java中,時間戳占用8 Byte,節點名稱可用一個整型變量(4 Byte)記錄,而一個節點的后繼不超過500個節點,因此延遲檢測表占用內存空間應不超過O(n)=(2×8 Byte+4 Byte)×500=10 000 Byte≈10 KB。在負載遷移策略中,每個節點存儲的路由信息表的空間復雜度為O(1),小頂堆結構占用內存應不超過O(n)=4 Byte×3×500=6 000 Byte≈6 KB。這對于目前的硬件存儲能力和千兆以太網的傳輸速率而言是不值一提的。實驗結果表明算法在空間復雜度上是可行的。
4 實驗與分析
作為一款開源免費的新興分布式數據流計算框架,Apache Flink已經得到比較廣泛的應用。實驗以Flink為平臺,分別執行WordCount和TeraSort兩個標準Benchmark,分別在相同環境下對動態負載均衡算法和現有負載均衡策略進行對比,從而檢驗動態負載均衡及負載遷移策略的性能。
4.1 實驗環境
實驗搭建的Flink集群運行在10臺普通物理PC上,每個節點的軟硬件環境配置參數如表2所示,其中包括1個JobManager節點,8個TaskManager節點和1個HDFS節點作為數據的源點和匯點。同時,作為Flink平臺的奠基性成果,文獻[6]分別采用WordCount和TeraSort兩個標準的Benchmark進行驗證。為了驗證動態負載均衡算法對Flink平臺的優化效果,實驗也采用這兩個Benchmark作為基準測試。通過多次預實驗進行反饋調節,最終確定實驗相關參數設定:θ=0.13 ms,ε=0.01 ms2,parallelism.default=8,k=100,taskmanager.numberOfTaskSlots=1,這樣每個節點啟動一個線程,占用單核的CPU資源,從而形成負載傾斜且節點資源不足造成計算延遲過長的實驗現象,以驗證算法的優化效果。其中,WordCount實驗測試數據為有100萬個英文單詞的文本數據,TeraSort實驗的測試數據為1 GB待排序的數值型數據。

表2 工作節點配置參數表
4.2 實驗與分析
如表3所示,在WordCount實驗中共設立了兩個實驗組和三個對照組分別在對應環境下執行作業,并在作業執行過程的重要時間點記錄時間戳,跟蹤記錄任務執行的相關參數作為對比和分析的依據。由于動態負載均衡算法是對現有Flink平臺的優化,因此三個對照組分別代表了Flink現有負載均衡策略在不同場景下的執行效率,而兩個實驗組是在相同環境下分別啟用了動態負載均衡算法與原系統的負載均衡策略形成對比實驗。
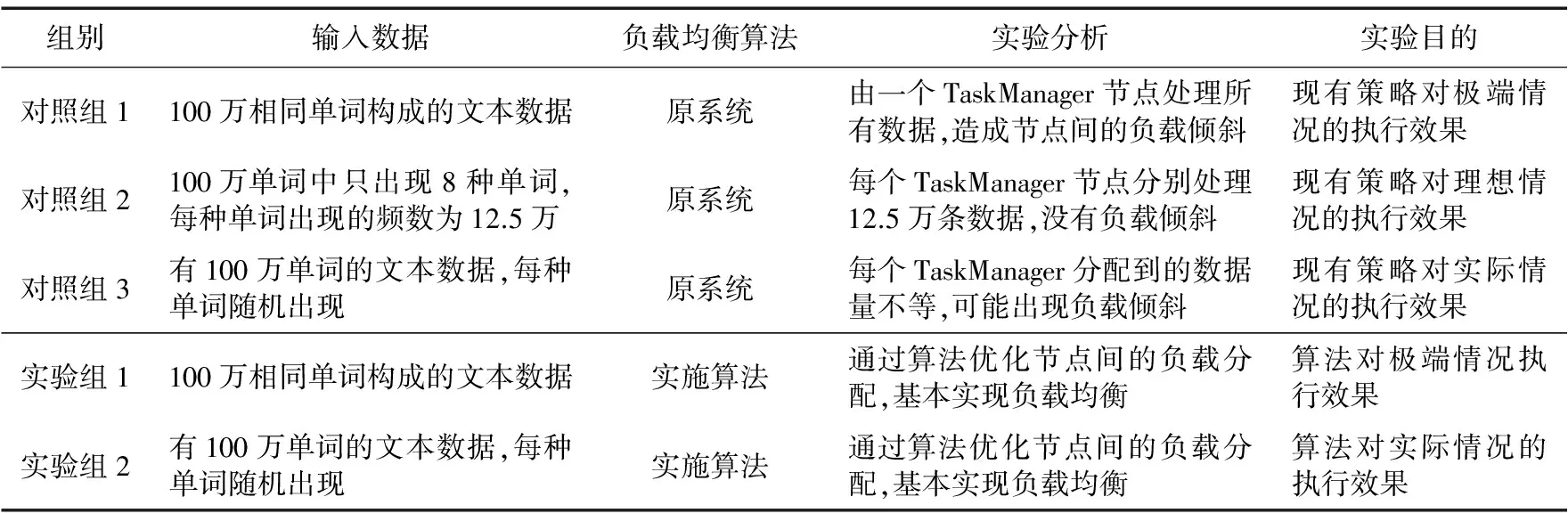
表3 對照實驗信息表
啟動負載均衡算法的條件之一是maxngt;θ,因此主要關注每組實驗中負載最重、計算時間最長的TaskManager節點(稱主工作節點),并記錄以下三個運行參數:任務執行時間、主工作節點處理的數據量和平均每處理1萬單詞使用的時間。為了避免個別任務存在的偶然性誤差,實驗將每個對照組的任務分別執行10次并計算相關參數的平均值,得到如圖3所示的實驗結果。從圖3(a)中可以看出:在相同環境下:實驗組1通過實施動態負載均衡算法,將對照組1中原本由單節點處理的100萬條數據分配給8個節點,有效縮短了任務執行時間,優化比為66.80%。實驗組2通過實施負載均衡算法,優化了對照組3中節點間的負載分配,減少主工作節點的計算負載,優化比為6.51%。這說明動態負載均衡算法在負載傾斜比較嚴重的情況下優化效果更好。對照組2是一種理想情況,其任務執行時間最短說明負載均衡算法還有繼續優化和提升的空間。在圖5(b)中,實驗組數據的平均處理時間與數據量的比值有明顯的上升,其中實驗組1的上升最明顯,這是因為其負載傾斜嚴重導致較大的遷移代價。
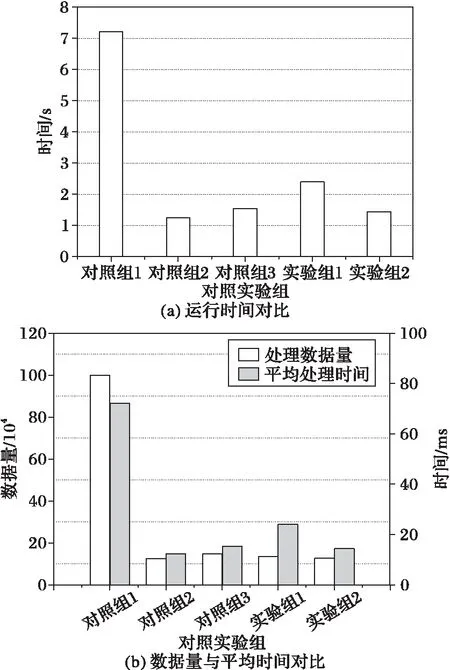
圖3 實驗結果對比
為了進一步對比分析負載均衡算法對任務執行過程的影響,在任務執行過程中數據匯點每收到10萬條數據記錄一個時間戳Ti,通過兩個時間戳之間的差值得到處理這些數據的時間延遲,即Pi=Ti-Ti-1。選取每個實驗組中各項參數距離均值最近的一次任務作為該實驗組的代表,分析其任務執行過程中集群響應能力的變化情況。
如圖4所示,對照組1和實驗組1分別是在相同環境下原系統和動態負載均衡策略的任務執行情況,實驗組1中集群分別在P2、P4和P6時間段內發生了3次負載遷移,分別將相同數據量的計算時間縮短了484.9 ms、96.8 ms和21.4 ms,其中第一次負載遷移的優化效果最明顯,因為原本單節點的計算負載被分配給8個節點,顯著提高任務執行效率。同時,在P2、P3和P6時間段內的計算時間較上一時間段有上升,這是因為負載遷移過程產生了一定的時間開銷,其中第一次遷移的數據量最大,因此P2的上升最明顯,但整個任務的執行時間減少,因此這種開銷是值得的。
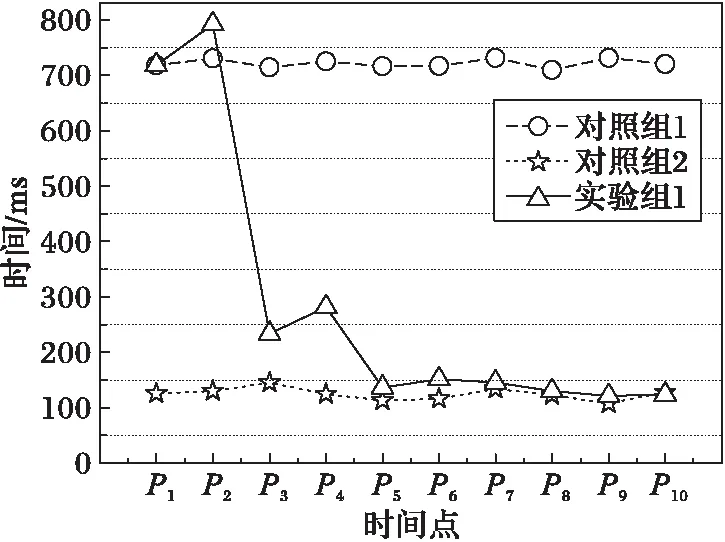
圖4 實驗組1的時間變化對比
如圖5所示,實驗組2和對照組3分別是相同環境下的任務執行情況,實驗組2中集群通過在P2和P5時間段內發生的兩次負載遷移,分別將相同數據量的計算時間縮短了20.6 ms和5.8 ms,且抑制了對照組3中計算時間明顯波動的情況。該組對照實驗的負載傾斜不嚴重,因此算法的優化效果并不明顯,且負載遷移產生的開銷較小。
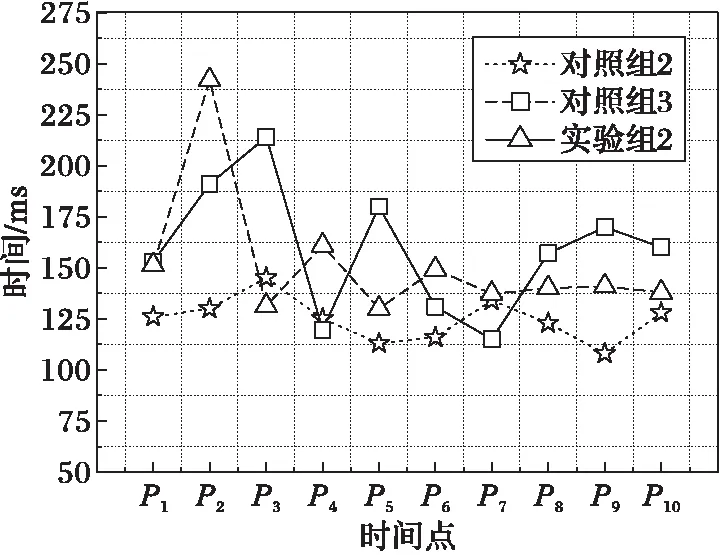
圖5 實驗組2時間變化對比
實驗結果表明:在數據傾斜度較大且待遷移數據量較小的情況下,負載均衡算法的優化效果比較顯著。在節點間負載比較均衡的情況下,算法可抑制計算延遲的劇烈波動,但對性能的優化效果沒有前者顯著。負載遷移策略的執行會導致少量的計算延遲,但延遲在合理可接受的范圍內,且能有效提高整個任務的執行效率。
為了進一步分析相關參數對算法的影響,實驗通過控制變量ε=0.01 ms2,k=100不變,分別設定不同的θ值,重復執行實驗組1,得到如圖6所示的實驗結果。
如圖6所示,θ取值過小導致算法過于敏感,頻繁的負載遷移產生過多的開銷。θ取值過大導致算法過于遲鈍,其中當θ=0.2 ms或θ=0.3 ms時執行的2次負載遷移未實現最優的負載分配,但由于閾值過高而沒有出觸發新的負載遷移。因此,實驗最終確定參數θ=0.13 ms,集群會根據負載傾斜程度的不同執行2次或3次負載遷移,且不會發生遷移抖動,取得比較理想的負載均衡效果。
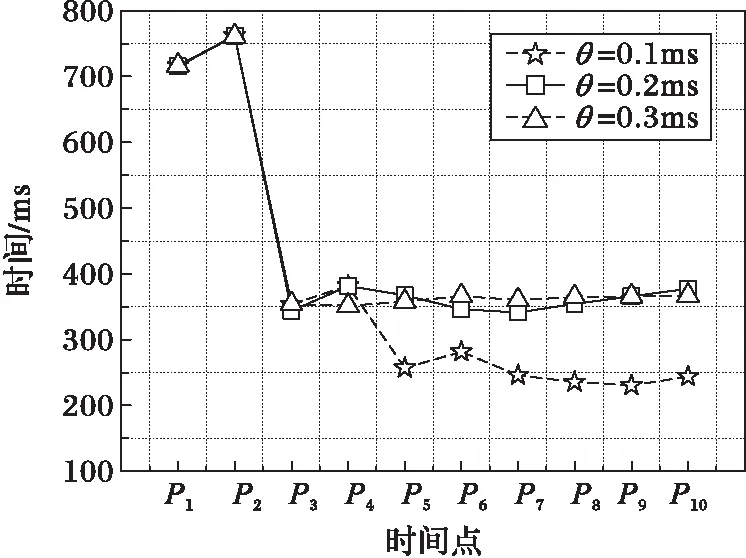
圖6 參數影響分析
TeraSort是分布式計算平臺中用于對數據排序的Benchmark,在不同平臺下對1 GB數據排序效率是衡量分布式系統出處理能力的公認標準。為驗證算法對較復雜計算的優化效果,實驗采用Hadoop的TeraGen作業生成1 GB數據,執行開源項目incubator-Flink[18]中提供的TeraSort作業,分別使用平臺原有的負載均衡策略和動態負載均衡策略進行測試,得到如圖7所示的實驗結果:在相同的執行環節中,負載均衡算法分別在P2和P4時間段內啟動了兩次負載遷移,通過優化節點間的負載分配降低了主工作節點的計算負載,提高了任務的執行效率,減少了任務執行的總時間;但由于需要遷移的數據量較大,遷移過程中產生較大的時間開銷,且節點間的負載傾斜本身不是很明顯,因此沒有其對WordCount作業的優化效果顯著。
5 結語
在大數據流式計算系統中,節點間負載不均衡是造成集群性能下降的主要原因,而資源評估不全面是制約負載均衡技術發展的瓶頸。本文提出基于計算延遲時間的數據流負載感知技術,以及動態負載均衡和負載遷移策略,通過優化節點間的負載分配提高了任務的執行效率。但本文算法也存在一定的缺陷:負載遷移技術會造成一定的時間開銷,導致一段時間內的計算延遲加長;另外目前只能通過反饋調節機制確定算法的相關參數。
下一步研究將針對數據流速本身波動造成資源分配不均的問題,研究數據流彈性資源[17]計算中的負載均衡算法。在計算資源彈性變化的場景中根據負載感知的結果進行負載調優,其中節點加入和離線時如何遷移負載將是下一步研究的重點。
References)
[1] 孟小峰, 慈祥.大數據管理: 概念、技術與挑戰[J]. 計算機研究與發展, 2013, 50(1): 146-169. (MENG X F, CI X. Big data management: concepts, techniques and challenges [J]. Journal of Computer Research and Development, 2013, 50(1): 146-169.)
[2] DEAN J, GHEMAWAT S. MapReduce: simplified data processing on large clusters[J]. Communications of the ACM, 2008, 51(1): 107-113.
[3] 陳付梅, 韓德志, 畢坤, 等.大數據環境下的分布式數據流處理關鍵技術探析[J]. 計算機應用, 2017, 37(3): 620-627. (CHEN F M, HAN D Z, BI K, et al. Key technologies of distributed data stream processing based on big data[J]. Journal of Computer Applications, 2017, 37(3): 620-627.)
[4] 孫大為, 張廣艷, 鄭緯民.大數據流式計算: 關鍵技術及系統實例[J]. 軟件學報, 2014, 25(4): 839-862. (SUN D W, ZHANG G Y, ZHENG W M. Big data stream computing: technologies and instances[J]. Journal of Software, 2014, 25(4): 839-862.)
[5] QIAN Z, HE Y, SU C, et al. TimeStream: reliable stream computation in the cloud[C]// Proceedings of the 8th ACM European Conference on Computer Systems. New York: ACM, 2013: 1-14.
[6] ALEXANDROV A, BERGMANN R, EWEN S, et al. The stratosphere platform for big data analytics[J]. The VLDB Journal, 2014, 23(6): 939-964.
[7] CARBONE P, KATSIFODIMOS A, EWEN S, et al. Apache Flink: stream and batch processing in a single engine[J]. Bulletin of the IEEE Computer Society Technical Committee on Data Engineering, 2015, 36(4):28-38.
[8] KOSTAS T, ELLEN F. Introduction to Apache Flink[M]. Sebastopol: O’Reilly Media, 2016: 54.
[9] TANMAY D. Learning Apache Flink[M]. Birmingham: Packt Publishing, 2017: 63.
[10] CARBONE P, FRA G, EWEN S, et al. Lightweight asynchronous snapshots for distributed data flows[EB/OL]. [2017- 01- 10]. https://arxiv.org/pdf/1506.08603.
[11] CARBONE P, TRAUB J, KATSIFODIMOS A, et al. Cutty: aggregate sharing for user-defined windows[C]// Proceedings of the 25th ACM International on Conference on Information and Knowledge Management. New York: ACM, 2016: 1201-1210.
[12] CHINTAPALLI S, DAGIT D, EVANS B, et al. Benchmarking streaming computation engines: Storm, Flink and Spark streaming[C]// Proceedings of the 2016 IEEE International Parallel and Distributed Processing Symposium Workshops. Piscataway, NJ: IEEE, 2016: 1789-1792.
[13] COLLINS R L, CARLONI L P. Flexible filters: load balancing through backpressure for stream programs[C]// Proceedings of the Seventh ACM International Conference on Embedded Software. New York: ACM, 2009: 205-214.
[14] SUN D, ZHANG G, YANG S, et al. Re-Stream: real-time and energy-efficient resource scheduling in big data stream computing environments[J]. Information Sciences, 2015, 319: 92-112.
[15] ANIELLO L, BALDONI R, QUERZONI L. Adaptive online scheduling in Storm [C]// DEBS 2013: Proceedings of the 7th ACM International Conference on Distributed Event-Based Systems. New York: ACM, 2013: 207-218.
[16] KWON Y C, BALAZINSKA M, HOWE B, et al. Skew-resistant parallel processing of feature-extracting scientific user-defined functions[C]// Proceedings of the 1st ACM Symposium on Cloud Computing. New York: ACM, 2010: 75-86.
[17] LOHRMANN B, JANACIK P, KAO O. Elastic stream processing with latency guarantees[C]// Proceedings of the 2015 IEEE 35th International Conference on Distributed Computing Systems. Piscataway, NJ: IEEE, 2015: 399-410.
[18] Fabian Hueske. Incubator-Flink[EB/OL]. [2017- 03- 26]. https://github.com/physikerwelt/incubator-flink.
Dynamicdatastreamloadbalancingstrategybasedonloadawareness
LI Ziyang1, YU Jiong1,2*, BIAN Chen2, WANG Yuefei2, LU Liang2
(1.SchoolofSoftware,XinjiangUniversity,UrumqiXinjiang830008,China;2.SchoolofInformationScienceandEngineering,XinjiangUniversity,UrumqiXinjiang830046,China)
Concerning the problem of unbalanced load and incomplete comprehensive evaluation of nodes in big data stream processing platform, a dynamic load balancing strategy based on load awareness algorithm was proposed and applied to a data stream processing platform named Apache Flink. Firstly, the computational delay time of the nodes was obtained by using the depth-first search algorithm for the Directed Acyclic Graph (DAG) and regarded as the basis for evaluating the performance of the nodes, and the load balancing strategy was created. Secondly, the load migration technology for data stream was implemented based on the data block management strategy, and both the global and local load optimization was implemented through feedback. Finally, the feasibility of the algorithm was proved by evaluating its time-space complexity, meanwhile the influence of important parameters on the algorithm execution was discussed. The experimental results show that the proposed algorithm increases the efficiency of the task execution by optimizing the load sharing between nodes, and the task execution time is shortened by 6.51% averagely compared with the traditional load balancing strategy of Apache Flink.
data stream; load balancing; depth-first search; load awareness; Apache Flink
2017- 04- 25;
2017- 06- 19。
國家自然科學基金資助項目(61262088,61462079,61562086,61363083);新疆維吾爾自治區高校科研計劃項目(XJEDU2016S106)。
李梓楊(1993—),男,新疆烏魯木齊人,碩士研究生,CCF會員,主要研究方向:云計算、分布式計算; 于炯(1964—),男,北京人,教授,博士生導師,博士,CCF高級會員,主要研究方向:網絡安全、網格計算、分布式計算; 卞琛(1981—),男,江蘇南京人,副教授,博士,CCF會員,主要研究方向:網絡計算、分布式系統; 王躍飛(1991—),男,新疆烏魯木齊人,博士研究生,主要研究方向:云計算、分布式計算、數據挖掘; 魯亮(1990—),男,新疆烏魯木齊人,博士研究生,CCF會員,主要研究方向:云計算、分布式計算、內存計算。
1001- 9081(2017)10- 2760- 07
10.11772/j.issn.1001- 9081.2017.10.2760
TP393.02
A
This work is partially supported by the National Natural Science Foundation of China (61262088, 61462079, 61562086, 61363083), the Educational Research Program of Xinjiang Uygur Autonomous Region (XJEDU2016S106).
LIZiyang, born in 1993, M. S. candidate. His research interests include cloud computing, distributed computing.
YUJiong, born in 1964, Ph. D., professor. His research interests include network security, grid computing, distributed computing.
BIANChen, born in 1981, Ph. D., associate professor. His research interests include network computing, distributed system.
WANGYuefei, born in 1991, Ph. D. candidate. His research interests include cloud computing, distributed computing, data mining.
LULiang, born in 1990, Ph. D. candidate. His research interests include cloud computing, distributed computing, in-memory computing.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52
中學生數理化·高一版(2020年3期)2020-04-21 08:03:20
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
數學大世界(2018年1期)2018-04-12 05:39:14
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
