流計算與內存計算架構下的運營狀態監測分析
2017-12-14 05:35:56趙永彬王佳楠
計算機應用 2017年10期
趙永彬,陳 碩,劉 明,王佳楠,賁 馳
(1.國網遼寧省電力有限公司 信息通信調度監控中心,沈陽 110004; 2.中國科學院 沈陽計算技術研究所,沈陽 110168;3.中國科學院大學,北京 100049; 4.國家電網公司 東北電力調控分中心,沈陽 110180) (*通信作者電子郵箱258098970@qq.com)
流計算與內存計算架構下的運營狀態監測分析
趙永彬1,陳 碩1*,劉 明1,王佳楠2,3,賁 馳4
(1.國網遼寧省電力有限公司 信息通信調度監控中心,沈陽 110004; 2.中國科學院 沈陽計算技術研究所,沈陽 110168;3.中國科學院大學,北京 100049; 4.國家電網公司 東北電力調控分中心,沈陽 110180) (*通信作者電子郵箱258098970@qq.com)
為滿足對電網實時運營狀態分析過程中對用戶實時用電量數據等大規模實時數據進行實時分析處理的需求,實現對電網運營決策提供快速準確的數據分析支持,提出一種流計算與內存計算相結合的大規模數據分析處理的系統架構。將經過時間窗劃分的用戶實時用電量數據進行離散傅里葉變換(DFT),實現對異常用電行為評價指標的構建;將基于抽樣統計分析構造出的用戶用電行為特征,采用K-Means聚類算法實現對用戶用電行為類別的劃分。從實際業務系統中抽取實驗數據,驗證了提出的異常用電行為和用戶用電分析評價指標的準確性。同時,在實驗數據集上與傳統的數據處理策略進行對比,實驗結果表明流計算與內存計算相結合的系統架構在大規模數據分析處理方面更具優勢。
流計算;內存計算;特征構建;異常監測;行為劃分
0 引言
對于電網企業運營狀態的描述,通常需要對企業的眾多業務領域中各維度的數據進行全流程的監測分析,從而實時、精準地獲得企業當前的業務情況[1]。現如今,電網運營監控中心的建設正朝著規模化、集中化、統一化、自動化的趨勢發展,如何對包含上千萬用戶的各個業務系統中的數據進行集成,高效處理分析每小時產生的多達上百GB的數據,成為提高運營監測水平的關鍵問題。同時,傳統依靠專家經驗建立起的指標型異常監測手段往往不能滿足更為豐富的業務場景,因此如何建立準確可靠的分析預測模型,為運營決策的制定提供可靠的支持,也成為當前電網企業運營狀態監測分析的主要研究方向[2]。
當前運營監測系統中所采用的傳統分布式數據提取工具和批處理離線數據分析平臺存在實時性較差的性能短板[3],已無法適應當前實時監測分析的業務需求。電力能源數據分析平臺的建設,正不斷朝著規模化、云平臺化、集成化的趨勢發展,其研究方向的重點較多地體現在對業務積累數據價值的挖掘上[4],缺少一種對實時業務數據進行快速分析處理實現運營狀態實時監控的策略。內存計算框架的普及,進一步加速了大規模數據的分析處理[5],但其仍然無法滿足對大規模實時業務數據的分析需求。
考慮到實際運營監測過程中的數據規模與實時性需求,本文采用了將STORM分布式流計算框架[6]與SAP HANA內存計算平臺[7]相結合的方式,作為實時數據監測分析的系統架構。并以用戶實時用電量數據為例,通過時間窗劃分、離散傅里葉變換(Discrete Fourier Transform, DFT)、K-Means聚類算法等數據分析手段建立起異常用電行為識別和用戶用電類型分析的分析評價模型。最后,基于實際的電量業務數據,評價異常監測與用戶分析算法的計算結果,并比較采用流計算與內存計算相結合的系統架構相對于傳統數據分析平臺的性能優勢。
1 異常用電與用戶特征的評價指標
在電網企業運營狀態的分析中,根據用戶的實時用電量數據,可以針對用戶的用電情況建立起全方位的評價指標。通過分析用戶實時用電量的波動情況,可以對用戶的異常用電行為進行監測。通過提取用戶高峰期用電特征,對所有用戶行為進行聚類分析,即可實現對用戶類型的劃分。
1.1 異常用電行為的評價指標
用戶的異常用電行為通常根據其實時用電量的波動情況進行衡量。為實現對用戶異常用電行為的及時發現并發出報警,在實際的運營監測過程中,需要以較短的分析時間間隔對用戶的實時用電量數據進行分析,實現對用戶異常用電行為的實時監測。
因此,本文選擇以5 min為一個時間窗,為避免噪聲數據和缺失值的影響,對每個用戶各時間窗內的實時用電量數據進行等距抽樣,對每個時間窗內保留50個數據點。基于各時間窗內數據點的分析計算結果,實現對每個用戶各時間窗對應時段用電行為的異常情況進行判定。
為實現對時間窗內離散數據點的波動情況進行更為準確直觀的評價,本文對時間窗內用戶實時用電量的離散抽樣點進行DFT,其具體定義[8]如下:
對于時間窗內N(0≤n≤N-1)個實時用電量數據構成的有限長序列x(n),它的離散傅里葉變換x(k)仍為一個長度為N(0≤k≤N-1)的頻域有限長序列。則有:
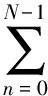
(1)
基于DFT的計算結果,分別設置頻率閾值W和比重閾值A,計算所有大于頻率閾值的頻域分量對應的權重分量在所有分量中的占比,即:
(2)
其中:k為頻域分量wi大于W的分量數;n為所有的頻域分量數;ai為wi所對應的幅值。將計算結果與比重閾值A進行比較,即可時間對異常用電行為的監測。本文將頻域閾值W選置為30π,將比重閾值A置為0.2。
1.2 用戶用電特征的評價指標
用戶用電類型的特征向量,可以通過用電高峰時段中一個小時內等距劃分出的多個時間段的用電量均值和方差進行描述。本文以每兩個時間窗,即每10 min計算用戶實時用電量的均值和方差,構造如下形式的12維特征向量。
X=[m1,m2,…,m6,v1,v2,…,v6]T
(3)
其中:mk(1≤k≤6)為各時間段內用戶用電量的均值;vk(1≤k≤6)為各時間段內用戶用電量的方差。
(4)
其中:n為每個時間段內的實時用電量樣本數,根據異常用電行為監測過程中的抽樣結果,可得n=100。
基于構造的用戶用電行為特征向量,將其代入K-Means聚類算法,獲得平方差準則最小的k個聚類簇,即可劃分出每個用戶用電行為所對應的類別,其計算過程[9]如下:
第1步 設整體樣本為n,從整體樣本中任意抽取k個對象作為初始簇的中心,記為mi(i=1,2,…,k)。
第2步 分別計算每個數據點p到k個簇中心的距離d(p,m),即:
d(i,j)=
其中:i=(xi1,xi2,…,xiq)和j=(xj1,xj2,…,xjq)為q維數據點。
第3步 找到對象p的最小距離,將p劃分到與mi相同的簇中。
第4步 將所有的對象進行計算,根據每個新簇內的數據點,計算出新簇的簇中心。
(6)
其中:mk代表第k個簇的中心;N代表該簇的數據點數。
第5步 重復上述計算過程,直到每個聚類簇中心位置變化量的平方和小于指定的收斂閾值,停止計算,獲得最終聚類結果。
2 數據實時監測分析系統的實現
對電網運營狀態進行實時監測分析的過程,通常需要經過包括數據的抽取、數據的清洗、數據的整合、數據的實時計算、數據的階段性分析、數據的展示以及數據的存儲在內的7個數據處理階段。
2.1 數據處理流程與系統架構劃分
為滿足對電網企業運營狀態實時監測分析過程中高實時性與大吞吐量的性能要求,本文采用了如圖1所示的流計算與內存計算技術相結合的系統架構,以滿足電網企業各業務類型數據的實時監測分析需求。
在使用用戶的實時用電量數據實現對異常用電行為的監測和用戶用電行為的分析時,共需要經過以下9個數據處理和分析過程:
1)將用電量數據加入消息隊列,作為流計算的數據源;
2)針對噪聲值完成數據清洗等預處理操作;
3)根據區域、用電等級等數據特征進行數據分類;
4)對各時間窗內的實時用電量記錄進行等距抽取;
5)對抽樣結果調用離散傅里葉變換實現異常監測;
6)基于流計算結果,構造用戶用電行為的特征向量;
7)調用K-Means聚類算法實現用電行為的分析;
8)讀取內存數據庫中的結果實現數據的實時展示;
9)將監測分析的結果作為歷史數據寫入磁盤。
其中:第2)~4)步的數據預處理過程由流計算層實現;第5)~7)步的數據分析計算過程由內存計算層實現。
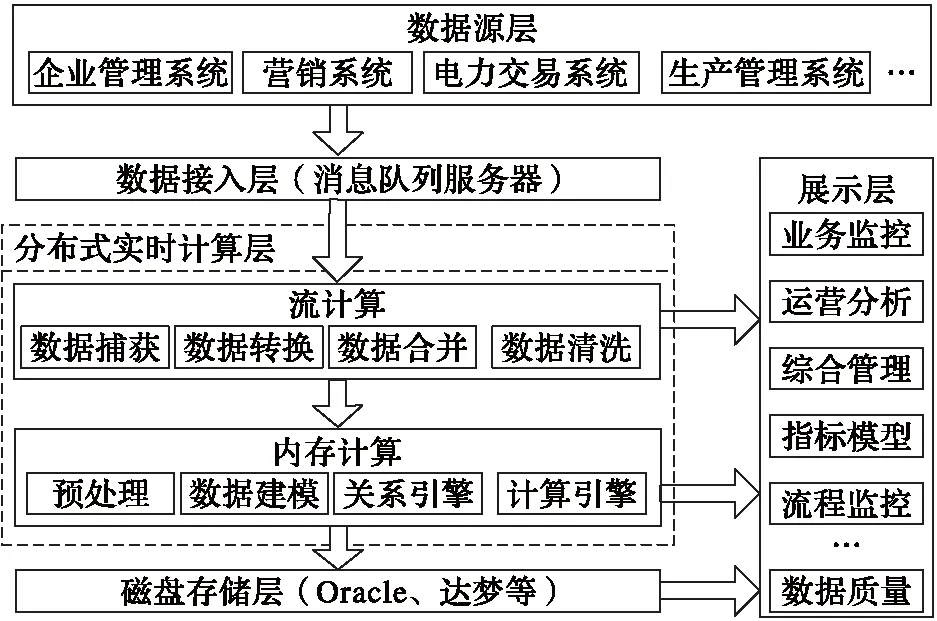
圖1 系統總體架構
2.2 基于Kafka并行化數據接入
Kafka憑借其基于話題的分布式消息隊列特性[10]與大多數分布式流計算系統均有著良好的性能兼容性。故將其作為數據接口層中消息隊列的實現方案,用以對數據源進行分發、產生穩定的數據源。
Kafka將接收到的數據根據其所屬的業務系統和對應的業務類型分發進多個話題,每個話題則成為一種類型的數據源,如定義用戶實時用電量“話題”。話題中的數據存儲進由如圖2所示的多個分區隊列,為應用程序提供并發讀取每個分區隊列數據的方式,以提高數據的讀取效率。
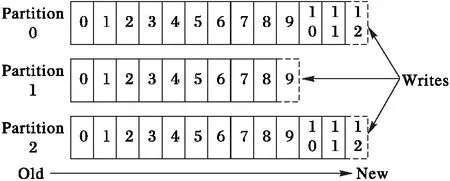
圖2 Kafka話題的分區隊列邏輯圖
2.3 基于Storm完成數據預處理
憑借其如圖3所示的Master-Worker分布式系統架構[11],Storm具備大吞吐量、可擴展性、高容錯性、高可靠性和易操作性的性能優勢,符合大規模用戶實時用電量數據的處理需求,故將其作為流計算層的實現方案。

圖3 Storm集群架構
Storm將數據流處理過程抽象為如圖4所示的處理邏輯單元組合[12],通過定義Spout和Bolt分別實現數據流過程中對應數據源操作和各階段數據處理操作;同時,配置各處理邏輯單元間的數據流向關系,實現數據處理邏輯的高效復用,提高數據處理效率[13]。
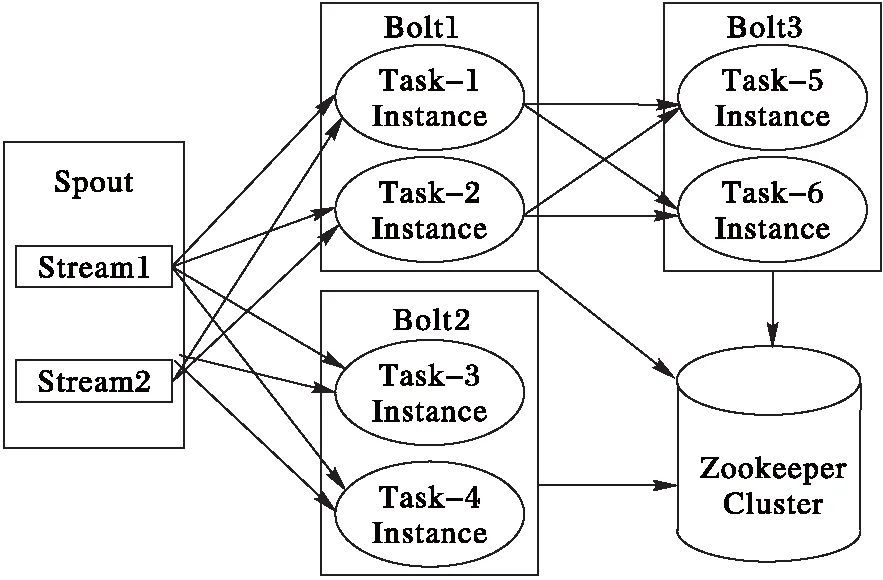
圖4 Storm內部處理邏輯圖
整個數據預處理階段的數據操作可劃分為數據讀取、數據清洗、數據分類、數據抽樣四個步驟,每個步驟與其對應的處理邏輯單元數量如表1所示。

表1 數據處理操作及其對應邏輯單元數
2.4 基于SAP HANA加速數據分析
SAP HANA是一款由SAP公司開發的基于內存技術實現高效數據處理的分析平臺[14],其系統架構如圖5所示。其內存計算引擎與內存關系引擎相結合的架構優勢[15],降低了數據分析處理過程中的讀寫開銷,滿足對數據進行高效分析計算的目的,因此將其作為內存計算層的實現方案。
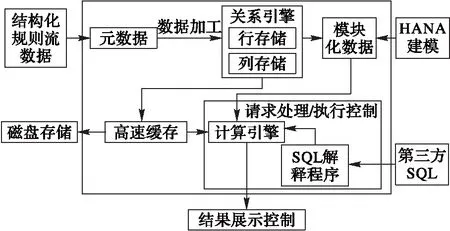
圖5 內存計算模塊邏輯架構
將經過Storm完成數據合并、清洗、時間窗劃分等一系列預處理操作后,將預處理后的結果數據加入SAP HANA的內存關系數據庫中,作為后續分析計算過程中的數據源。
SAP HANA提供了便捷的數據建模方式,在滿足各類型數據集成需求的同時,為每條數據定義處理操作即可實現DFT計算和K-Means聚類分析等處理過程。使用其內置的預測分析算法庫(Prediction and Analysis Library,PAL)即可實現對常用聚類分類算法的調用。
2.5 基于內存關系引擎定制存儲模式
SAP HANA的內存關系引擎提供了行式存儲和列式存儲兩種存儲模式。根據不同類型的數據對應的讀寫需求,選擇合適的存儲模式[16],實現最優的讀寫效率。
1)行式存儲。適用于需要讀取數據記錄全部字段的數據分析操作,同時基于索引提高數據的查詢效率,用于存儲完成預處理后進行數據分析的中間結果。
2)列式存儲。無需額外索引,提供較高效率的數據壓縮方法,適用于需要分別訪問單個屬性的數據記錄,用于存儲提供給展示層的最終結果。
為實現高效的分析,完成數據預處理過程后的待分析數據通常選用行式存儲方式。為加快數據的查找讀取,對于數據分析結果則通常采用列式存儲方式。
3 實驗結果分析與平臺性能對比
本文采用的實驗環境是由包含一個Nimbus節點和四個Supervisor節點共計五臺PC構成的Storm集群。每臺PC均配備Intel Core I5 6500處理器和8 GB內存的計算存儲資源。集群中還部署了Kafka和SAP HANA平臺。
3.1 異常用電實時監測的實驗結果
本文將某電力公司在2015年6月10日用電高峰時段中1 000萬條用戶實時用電量數據按產生時間順序依次寫入Kafka分布式消息隊列,作為本次實驗的數據源;并分別就異常用電行為監測的準確性和數據處理平臺計算的實時性兩個指標進行實驗測試。
異常用電行為實時監測的準確性由準確率Precision和召回率Recall指標衡量,其計算公式如下:
Precision=TP/(TP+FP)
Recall=TP/(TP+FN)
其中:TP表示識別為正樣本即異常用電行為的數據中識別正確的數量;FP表示識別為正樣本的數據中識別錯誤的數量;FN表示所有識別為負樣本的數據中標注錯誤的數量,即實際為異常用電行為卻未被識別的樣本數量。
將原始數據經由Storm流計算系統完成噪聲過濾、分類合并、時間窗劃分及抽樣等一系列預處理操作,轉換為各用戶在不同時間窗內的用電量記錄數據,并在SAP HANA中完成離散傅里葉變換(DFT)及異常用電行為評價指標的計算,根據所設置的閾值對異常用電行為進行識別。
結合電量業務系統中已有的異常用電記錄,可以得到對實驗數據集中1 268個異常用電行為實時監測記錄識別結果的準確率Precision=82.7%,召回率Recall=96.8%。實驗結果表明,本文采用的DFT方法能夠監測出對絕大多數異常用電行為,但監測結果正確率的進一步提高還需依靠更精確的特征分析算法和專家運營決策共同實現。
通過統計表2中各處理策略在處理不同規模數據時的時間開銷,實現對異常狀態監控的處理實時性進行全面比較。實驗分別在不同平臺架構下設計了相同功能的處理程序,并以每100萬條數據為一個數據量梯度,測試了10個數據量級下各處理平臺對應的時間開銷。在每個數據量級下分別進行三次測試,對所獲得時間開銷測試結果取平均,獲得最終的實驗分析結果。

表2 數據處理平臺的實現方式
從圖6所示的實驗結果可知,將流計算和內存計算技術相結合的系統架構既具備了分布式流處理系統高吞吐量的性能優勢,也具備了內存計算系統的低讀寫開銷,能夠較好地滿足大規模數據實時處理的性能需求。
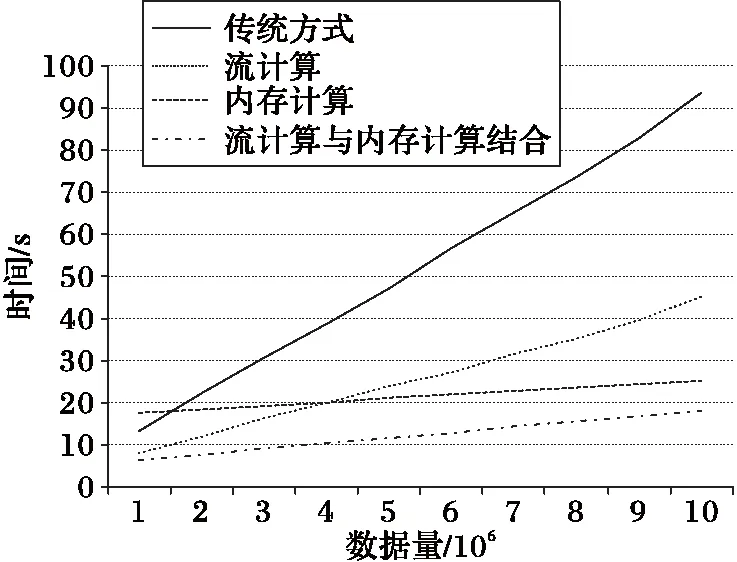
圖6 各實現方式的處理耗時對比
3.2 用戶用電行為分析的實驗結果
基于流計算過程中得到的數據抽樣結果,對每兩個時間窗內的數據記錄計算其均值和方差,構成用戶用電行為的特征向量進行K-Means聚類分析。其中設置K-Means算法的類別數K=5,迭代輪次n=1 000,收斂閾值α=1.0。
將K-Means算法所得到的各用戶類型標簽與業務系統中記錄的用戶用電等級進行比對。由表3中所示的比對結果可知,由K-Means得到的各類別用戶數與用戶實際用電等級數量分布基本相同。
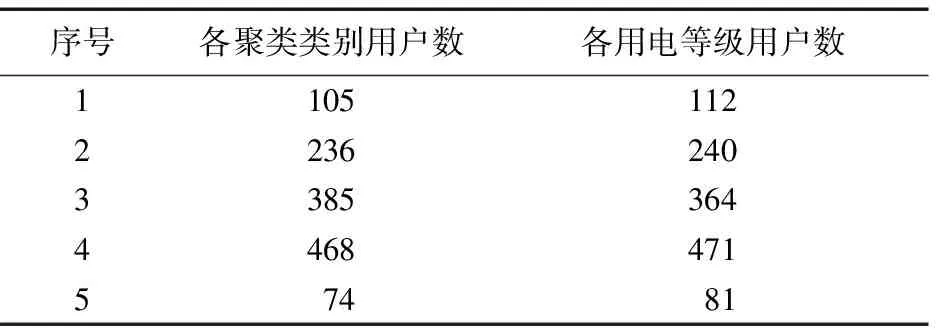
表3 聚類標注與實際用電等級對比
為驗證流計算和內存計算技術結合的系統架構對數據分析性能的優化情況,將SAP HANA的PAL算法庫中提供的K-Means算法模型與Hadoop的Mahout算法庫以及Spark的MLlib算法庫所提供的K-Means算法模型進行性能比較。分別統計數據處理過程中的計算時間占比與讀寫時間占比,并將3次測試結果取平均得到如表4所示的結果。
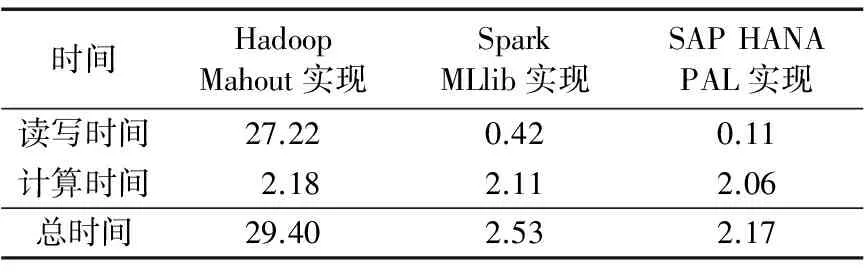
表4 數據分析過程的算法開銷 s
由處理性能對比結果可知,相對于Hadoop將中間結果寫入硬盤的策略,SAP HANA的內存計算引擎顯著降低了數據迭代分析過程的讀寫開銷。與同為內存計算引擎的Spark計算框架相比,SAP HANA自帶的內存數據庫進一步加速了待分析數據的讀取過程。盡管內存資源在系統中仍較為寶貴,但SAP HANA等內存計算平臺更適用于較大規模數據的階段性實時迭代分析。
4 結語
針對電網企業運營狀態的分析,電量數據已成為最為直接有效的特征依據。兼具高吞吐量與高實時性的優勢,流計算與內存技術相結合已逐漸成為面向企業大規模數據和高實時需求的解決思路。本文基于用戶實時用電量數據實現對用戶異常用電的監測以及用電行為的分析,結合流計算滿足了數據的大規模實時處理的需求,采用內存技術進一步提升了系統的計算性能和讀寫效率,為分析和監控提供高實時性、大吞吐量的性能保證。同時,為電力企業后續的大規模實時數據分析提供了一種可靠高效的借鑒思路。
References)
[1] 蔡勇.數據挖掘技術在電網運營監控平臺建設中的研究與應用[D]. 上海: 上海交通大學, 2012: 5-6. (CAI Y. Research and application of data mining technology in grid operational monitoring platform [D]. Shanghai: Shanghai Jiao Tong University, 2012: 5-6.)
[2] 陳云.分布式電力大數據計算分析平臺設計與實現[D]. 成都: 電子科技大學, 2016. (CHEN Y. The design and implementation of the distributed computing and analysis platform for power system [D]. Chengdu: University of Electronic Science and Technology of China, 2016.)
[3] 程學旗, 靳小龍, 王元卓, 等.大數據系統和分析技術綜述[J]. 軟件學報, 2014, 25(9): 1889-1908. (CHENG X Q, JIN X L, WANG Y Z, et al. Survey on big data system and analytic technology [J]. Journal of Software, 2014, 25(9): 1889-1908.)
[4] 李洋, 何寶靈, 劉海濤, 等.面向全球能源互聯網的分布式電源云服務與大數據分析平臺研究[J]. 電力信息與通信技術, 2016(3): 30-36. (LI Y, HE B L, LIU H T, et al. Research on distributed generation cloud service and big data analysis platform for global energy interconnection [J]. Electric Power Information and Communication Technology, 2016(3): 30-36.)
[5] 程敏.基于PostgreSQL和Spark的可擴展大數據分析平臺[D]. 北京: 中國科學院大學, 2016. (CHEN M. Scalable big data analysis platform based on Postgre SQL and Spark [D]. Beijing: University of Chinese Academy of Sciences, 2016.)
[6] Apache Software Foundation. Storm documentation [EB/OL]. [2016- 05- 23]. http://storm.apache.org/releases/1.0.3/index.html.
[7] SAP Corporation. SAP HANA introduction [EB/OL]. [2016- 06- 14]. https://www.sap.com/china/product/technology-platform/hana.html.
[8] 熊元新, 陳允平.離散傅里葉變換的定義研究[J]. 武漢大學學報 (工學版), 2006, 39(1): 89-91. (XIONG Y X, CHEN Y P. Research on definition of discrete Fourier transform [J]. Engineering Journal of Wuhan University, 2006, 39(1): 89-91.)
[9] LIKAS A, VLASSIS N, J. VERBEEK J. The globalk-means clustering algorithm [J]. Pattern Recognition, 2003, 36(2): 451-461.
[10] Apache Software Foundation. Kafka introduction [EB/OL]. [2016- 07- 08]. http://kafka.apache.org/intro.
[11] 王銘坤, 袁少光, 朱永利, 等.基于Storm的海量數據實時聚類[J]. 計算機應用, 2014, 34(11): 3078-3081. (WANG M K, YUAN S G, ZHU Y L, et al. Real-time clustering for massive data using Storm [J]. Journal of Computer Applications, 2014, 34(11): 3078-3081.)
[12] 李一辰, 李緒志, 閻鎮.實時流計算在航天地面數據處理系統中的應用[J]. 微電子學與計算機, 2014, 31(9): 15-19. (LI Y C, LI X Z, YAN Z. Real-time stream computing in aerospace system’s data disposing [J]. Microelectronics amp; Computer, 2014, 31(9): 15-19.)
[13] 孫大為, 張廣艷, 鄭緯民.大數據流式計算: 關鍵技術及系統實例[J]. 軟件學報, 2014, 25(4): 839-862. (SUN D W, ZHANG G Y, ZHENG W M. Big data stream computing: technologies and instances [J]. Journal of Software, 2014, 25(4): 839-862.)
[14] 嵇智源, 潘巍.面向大數據的內存數據管理研究現狀與展望[J]. 計算機工程與設計, 2014, 35(10): 3549-3506. (JI Z Y, PAN W. Present research status and prospects of in-memory data management in big data era [J]. Computer Engineering and Design, 2014, 35(10): 3549-3506.)
[15] 黃嵐, 孫珂, 陳曉竹, 等.內存集群計算: 交互式數據分析[J]. 華東師范大學學報 (自然科學版), 2014(5): 216-227. (HUANG L, SUN K, CHEN X Z, et al. In-memory cluster computing: Interactive data analysis [J]. Journal of East China Normal University (Natural Science), 2014(5): 216-227.)
[16] 張延松, 王珊, 周烜.內存數據倉庫集群技術研究[J]. 華東師范大學學報 (自然科學版), 2014(5): 117-132. (ZHANG Y S, WANG S, ZHOU X. Research on in-memory data warehouse cluster technologies [J]. Journal of East China Normal University (Natural Science), 2014(5): 117-132.)
Monitoringandanalysisofoperationstatusunderarchitectureofstreamcomputingandmemorycomputing
ZHAO Yongbin1, CHEN Shuo1*, LIU Ming1, WANG Jianan2,3, BEN Chi4
(1.Informationamp;TelecommunicationBranch,StateGridLiaoningElectricPowerCompany,ShenyangLiaoning110004,China;2.ShenyangInstituteofComputingTechnology,ChineseAcademyofSciences,ShenyangLiaoning110168,China;3.UniversityofChineseAcademyofSciences,Beijing100049,China;4.ElectricPowerControlNortheastBranchCenter,StateGridCorporationofChina,ShenyangLiaoning110180,China)
In real-time operation state analysis of power grid, in order to meet the requirements of real-time analysis and processing of large-scale real-time data, such as real-time electricity consumption data, and provide fast and accurate data analysis support for power grid operation decision, the system architecture for large-scale data analysis and processing based on stream computing and memory computing was proposed. The Discrete Fourier Transform (DFT) was used to construct abnormal electricity behavior evaluation index based on the real-time electricity consumption data of the users by time window. TheK-Means clustering algorithm was used to classify the users’ electricity behavior based on the characteristics of user electricity behavior constructed by sampling statistical analysis. The accuracy of the proposed evaluation indicators of abnormal behavior and user electricity behavior was verified by the experimental data extracted from the actual business system. At the same time, compared with the traditional data processing strategy, the system architecture combined with stream computing and memory computing has good performance in large-scale data analysis and processing.
stream computing; memory computing; feature construction; anomaly detection; behavior partition
2017- 05- 02;
2017- 07- 11。
遼寧電力公司科技項目(SGLNXT00DKJS1600242)。
趙永彬(1975—),男,遼寧沈陽人,高級工程師,碩士,主要研究方向:智能電網、Web工程、信息集成; 陳碩(1983—),男,遼寧沈陽人,高級工程師,博士,主要研究方向:智能電網、Web工程、信息集成; 劉明(1979—),男,遼寧沈陽人,高級會計師,碩士,主要研究方向:電力信息; 王佳楠(1993—),男,河南洛陽人,碩士研究生,主要研究方向:智能電網、電網大數據; 賁馳(1965—),女,遼寧沈陽人,高級工程師,主要研究方向:電量采集與計費統計。
1001- 9081(2017)10- 3029- 05
10.11772/j.issn.1001- 9081.2017.10.3029
TP39
A
This work is partially supported by the Science and Technology of Liaoning Electric Power Company (SGLNXT00DKJS1600242).
ZHAOYongbin, born in 1975, M. S., senior engineer. His research interests include smart grid, Web engineering, information integration.
CHENShuo, born in 1983, Ph. D., senior engineer. His research interests include smart grid, Web engineering, information integration.
LIUMing, born in 1979, M. S., senior accountant. His research interests include electric power information.
WANGJianan, born in 1993, M. S. candidate. His research interests include smart grid, grid big data.
BENChi, born in 1965, senior engineer. Her research interests include power collection and billing statistics.
猜你喜歡
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
電子制作(2018年18期)2018-11-14 01:48:24
商用汽車(2016年11期)2016-12-19 01:20:16
山東工業技術(2016年15期)2016-12-01 05:31:22
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
創業家(2015年5期)2015-02-27 07:53:25
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
