結合紋理與輪廓特征的多通道行人檢測算法
2017-12-14 05:22:24韓建棟鄧一凡
計算機應用 2017年10期
韓建棟,鄧一凡
(山西大學 計算機與信息技術學院,太原 030006) (*通信作者電子郵箱hanjiandong@sxu.edu.cn)
結合紋理與輪廓特征的多通道行人檢測算法
韓建棟*,鄧一凡
(山西大學 計算機與信息技術學院,太原 030006) (*通信作者電子郵箱hanjiandong@sxu.edu.cn)
針對在復雜場景下,聚合通道特征(ACF)的行人檢測算法存在檢測精度較低、誤檢率較高的問題,提出一種結合紋理和輪廓特征的多通道行人檢測算法。算法由訓練分類器和檢測兩部分組成。在訓練階段,首先提取ACF特征、局部二值模式(LBP)紋理特征和ST(Sketch Tokens)輪廓特征,然后對提取的三類特征均采用Real AdaBoost分類器進行訓練;在檢測階段,應用了級聯檢測的思想,初期使用ACF分類器處理所有實例,保留下來的少數實例應用復雜的LBP及ST分類器進行逐次篩選。實驗采用INRIA數據集對算法進行仿真,該算法的平均對數漏檢率為13.32%,與ACF算法相比平均對數漏檢率降低了3.73個百分點。實驗結果表明LBP特征與ST特征能有對ACF特征進行信息互補,從而在復雜場景下去掉部分誤判,提高了行人檢測的精度,同時應用級聯檢測保證了多特征算法的計算效率。
聚合通道特征; Sketch Tokens特征; LBP特征; Real AdaBoost分類器; 級聯檢測
0 引言
對象檢測技術是計算機視覺中的一個重要研究課題。行人檢測作為對象檢測的一個子問題,由于在汽車安全、監控、機器人及人機交互等領域有著重要的應用前景,成為對象檢測中的一個研究熱點[1-2]。由于其易受人的姿態變化、光照變化、復雜場景以及存在遮擋等問題的影響,如何高效地進行行人檢測成為一個很難的課題。
國內外很多學者對行人檢測算法作了總結[3-4],目前主流的檢測方法主要是統計分類學習的方法。2005年Dalal等[5]提出了基于方向梯度直方圖(Histogram of Oriented Gradient, HOG)的行人檢測算法,選用支持向量機(Support Vector Machine,SVM)作為分類器進行檢測,由于該特征能較好地刻畫行人,在當時的行人檢測中取得了突破性的進展;后來又被應用于可變部件檢測(Deformable Part Model, DPM)[6-7]中,其主要思想是針對人姿態多變的問題,建立根模型和部件模型,根模型確定行人整體信息,部件確定行人局部信息,該算法在當時取得了很好的檢測性能。Wu等[8]提出了一個CENTRIST(Census Transform histogram)特征,然后分別訓練兩個分類器,最后把兩個分類器級聯進行行人檢測。由于單一特征具有自身一定的局限性,所以陸續出現一些融合多種特征的方法。Wang等[9]用HOG與局部二進制模式(Local Binary Pattern, LBP)相結合,應用積分圖快速計算提高速度,同時針對行人遮擋的問題進行了處理,證實了LBP特征能夠與HOG特征進行互補。Walk等[10]為了更好地結合時空信息,利用局部部位間的顏色自相似性(Color Self-Simlarity, CSS)刻畫人體的結構特征,同時與HOG特征和光流特征結合起來,大大提高了檢測的精度。Dollar等[11]提出了積分通道特征(Integral Channel Features, ChnFtrs),對HOG特征進行改進,同時結合LUV顏色信息提高檢測精度。文獻[12]對ChnFtrs作了改進,提出了聚合通道特征(Aggregated Channel Feature,ACF),由于其計算簡單、檢測效率高等優點,很多檢測方法將ACF作為基準,被廣泛應用于實時系統中。ST(Sketch Tokens)特征是由Lim等[13]提出的一種描述輪廓信息的中級特征,是一組用于表達圖像中各種局部邊緣信息的結構圖,作者將其和ACF特征結合,驗證了ST特征能夠彌補ACF的缺陷,從而提高了檢測精度。
在統計分類學習的行人檢測算法中,分類器的構建與特征的計算對檢測的結果起著關鍵的作用。由于現實環境的復雜性,導致很難用唯一特征來有效地刻畫行人。本文針對ACF算法在復雜場景下,由于其特征的局限性導致誤檢較多的問題,引入LBP特征與ST特征,提出了基于多通道特征的改進算法。為了提高算法的檢測速度,首先對ACF特征、LBP特征和ST特征分別訓練三種特征分類器,然后利用三種分類器傳遞置信函數值的方式進行級聯檢測。結果表明:LBP特征能夠刻畫人體區域的紋理信息,ST能夠刻畫行人整體的輪廓信息,二者與ACF特征形成有效的互補,從而提高了檢測精度。
1 相關理論
基于統計學習的行人檢測算法,首先需要確定一種或一類能夠有效刻畫行人的特征,利于這些特征選擇合適的分類器進行學習和檢測。一般的行人特征有梯度、輪廓、紋理和結構等,分類器常采用SVM、Real AdaBoost等。
1.1 特征提取
特征的好壞決定最后的檢測準確度,如何計算特征,以及計算什么特征是行人檢測技術中的關鍵。區分性強的特征,有利于分類器分類。本文分析場景中的行人,發現在行人區域除了梯度和特殊的顏色信息外還具有較強的紋理信息,身體具有獨特的輪廓信息。
1.1.1 聚合通道特征
聚合通道特征,簡稱ACF,是對ChnFtrs的改進。它應用了梯度信息和顏色信息,計算方法是:首先,計算圖像的LUV 3通道特征、梯度幅值特征以及6個梯度直方圖特征。如圖1所示。然后,在10個通道內求取特征,ChnFtrs是隨機選擇3萬個矩形框,對矩形框內的像素求和作為特征。而ACF算法是將圖像分成若干個4×4固定大小的塊,每個塊內特征點的均值作為聚合通道特征。

圖1 ACF可視化效果示例圖
1.1.2 局部二值模式
局部二值模式,簡稱LBP,是由Ojala等[14]提出的一種描述紋理的特征,被廣泛應用于人臉識別、表情識別等領域。原始的LBP特征是在3×3大小的窗口內,以窗口中心像素為閾值,將相鄰的8個像素的灰度值與其比較,若大于中心像素的灰度值,則該像素點被標記為1;否則為0。如圖2所示。

圖2 LBP特征編碼示意圖
對應的編碼值為:
其中:P為鄰域像素點個數;R為半徑;Ic和Ip分別為中心像素點和第p個鄰域像素點的灰度值;s(x)為階躍函數。s(x)的表達式為:

二值化后所得到的環形0-1二值串中,將0到1或者1到0的跳變次數不超過2次所對應的二進制稱為等價模式(Uniform Pattern),其余歸并成一類,稱為混合模式。如01000000(2次跳變)為等價模式,而11011011(4次跳變)為混合模式。當鄰域有P個像素點時,共有P(P-1)+3種模式,其中混合模式有1種,其余為等價模式。如,當P=8時,等價模式只有58種。Ojala等認為:在實際圖像中,等價模式占據了圖像中絕大多數的信息,使用等價模式可以對傳統的LBP算子進行降維,而且可以減少噪聲的影響。因此,等價模式能夠更好地用于目標檢測。
1.1.3 ST特征
ST特征是一組用于表達圖像中各種局部邊緣輪廓信息的結構圖。包括:直線、T-路口、角點、曲線、平行線等。該特征具有對噪聲不敏感的特點,有利于后期的分類。
假設有n幅圖像,相應的手繪輪廓的二值圖像集為S,在二值圖像Si(i=1,2,…,n)中,以輪廓點為中心像素的圖像塊(大小為35×35)記為sj(j=1,2,…),首先使用Daisy算法對每個圖像塊進行描述,然后采用K-means算法進行聚類,得到K種ST類,其中K取150。部分ST類如圖3所示。
從n幅圖像中采集每個ST對應的大小為35×35的圖像塊,同時裁剪中心像素不是輪廓點的圖像塊作為第151類。首先,對這些圖像塊提取特征,方法如下:
1)第一類特征的提取。求取每個圖像塊的LUV通道、梯度幅值通道、4個方向的梯度方向通道。使用不同方差(分別為0、1.5和5)的高斯濾波器對梯度幅值通道進行濾波,并采用方差0和1.5的高斯濾波器平滑4個方向的梯度方向通道。最后,將這14個梯度通道均采用方差為1的高斯濾波器平滑處理,這樣每個塊共有35×35×14=17 150個特征。
2)第二類特征(自相關性特征)的提取。自相關特征能夠有效地刻畫每個圖像塊的相似度。將1)中得到的每個圖像塊分成m×m個子圖像塊,如:當m=5時,子圖像塊的大小為7×7。對于通道k,第i(i=1,2,…,m×m)個子圖像塊內部的像素之和記為Sik,定義第i和第j個子圖像塊之間的相似度特征fijk:
fijk=Sjk-Sik;i,j=1,2,…,m×m

從而得到17 150+4 200=21 350維特征向量。
其次,隨機挑選150 000個輪廓圖像塊(每個ST類1 000個)和160 000個無輪廓的圖像塊(每個訓練圖像800個),將它們以及對應的ST類(標簽)放到隨機森林里進行訓練。訓練采用深度為20的25棵樹。
最后,通過訓練好的隨機森林檢測一個圖像的所有像素點,輸出的值是每個ST類及背景的概率圖。將這150個ST類對應的概率圖以及背景概率圖作為通道特征。

圖3 部分Sketch Tokens類
1.2 分類器
Real AdaBoost分類器[15]是經典AdaBoost分類器的一個擴展,經典AdaBoost分類器的每個弱分類器輸出為+1或-1,而Real AdaBoost的每個弱分類器輸出的是一個實數值。
算法描述如下:
給定訓練集:(x1,y1),(x2,y2),…, (xN,yN),其中xi是長度為m的特征向量,標簽為yi∈{+1,-1},i=1,2,…,N。
訓練集上的樣本初始分布:D1(i)=1/N
確定弱分類器的數量T,對式(1)~(6)進行循環T次,得到T個弱分類器。
1)將每一維特征的取值空間X劃分為若干個不相交的子空間X1,X2,…,Xn。
2)計算每個子空間上的權重:
其中:l∈{+1,-1}。
3)計算每一個弱分類器的輸出:
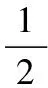
其中:ε是一個很小的正常量,用于平滑輸出;h(x)實際上是一個分段線性函數,在每個子空間上都有不同的輸出值。
4)計算歸一化因子:
5)選擇讓Q最小的弱分類器h(x)作為該輪迭代的弱分類器:
Qt=minQ,ht=arg minQ
6)更新樣本的分布:
Dt+1(i)=Dtexp(-yiht(xi))
最后的強分類器H為:

其中b是閾值。H函數的置信函數為:
(1)
2 改進算法
由于ACF只計算了顏色和梯度特征,誤檢率較高,考慮到行人具有較強的紋理和輪廓特征,本文引入了對噪聲不敏感的LBP紋理特征以及ST輪廓特征進一步提高檢測的準確度,降低誤檢率。
2.1 特征計算方法
LBP特征:首先將圖像轉換到LUV空間,在L通道上計算LBP特征,本文選擇P=8,并將跳變為0次的二值串歸并為一類,采用上文所述方法計算,共有57種等價模式,1種混合模式。將這些模式分別對應成58幅圖,作為通道特征。
映射成特征向量的方式跟ACF類似:將每個LBP直方圖通道分成d×d大小的圖像塊,最后串起來作為特征向量。
ST特征:首先使用已經訓練好的隨機森林對正負樣本計算ST類及背景類概率圖,然后按照ACF的方式分大小為d×d的塊,求其平均值,作為新的特征值,并將其串起來形成特征向量。
得到上述的特征之后,然后采用Real AdaBoost進行訓練學習。將每一維特征的取值空間分為n=256個子空間。由于樣本的特殊性,所有樣本的模板大小采用128×64。訓練采用自舉法(Bootstrapping)進行訓練,共訓練4輪,根據樣本集的大小、特征數量的大小來確定每輪的弱分類器個數分別是32、128、512、2 048,樹的深度取2。
2.2 檢測流程
具體檢測流程如圖4所示。其中,ACF分類器、LBP分類器和ST分類器都是事先單獨訓練得到。檢測大體思路是通過三種分類器級聯對圖像進行檢測。
具體步驟為:
步驟1 ACF分類器檢測采用的是軟級聯(Soft Cascade)[16],算法偽代碼如下:
d=0
Fori=1 toT
d=d+h(x)
ifdlt;b返回false,移動窗口到下個位置檢測;
else 返回true,保存當前候選區域矩形框的位置、大小和置信函數ConfACF
其中:置信函數計算公式如式(1);d是累加的置信函數;b是閾值,取b=0。
為了去除重疊窗口,減少后面分類器的計算量,對其結果進行后處理,后處理采用非極大值抑制原理。首先按照置信函數對所有候選區域進行降序排列,若兩個矩形框重疊,則留下置信度高的矩形框。本文采用貪心策略,若當前矩形框已經被抑制,則不能再抑制比其置信度更低的矩形框。第i個矩形框記為Ri,area表示區域的面積,計算兩個矩形框的重疊度:

設定閾值Th,如果overlap(Ri,Rj)gt;Th,則刪除置信度低的矩形框Rj;否則將其保留。
步驟2 通過ACF分類器的檢測會得到一些帶有置信函數的目標行人矩形框,重新計算矩形框內的LBP特征,通過LBP分類器對ACF的檢測結果進行篩選,同樣也會輸出一個置信函數ConfLBP,計算:
S1=ConfACF+ConfLBP
如果S1lt;b,則刪除當前的矩形框。
步驟3 通過ST分類器將保留下來的區域進行二次篩查,并將得到置信函數ConfST和S1進行累加:
S2=S1+ConfST
若S2lt;b,則刪除當前的矩形框,最后得到最終的結果。

圖4 檢測流程
3 實驗與分析
算法的運行環境:內存為8 GB,CPU為intel酷睿i7處理器,主頻為3.6 GHz。
實驗采用的數據集:本文采用INRIA數據集,該數據集包含城市、海灘、山等各種場景。該數據集的訓練集具有正樣本614張(包含2 416個行人),負樣本為1 218張;測試集的正樣本為288張(包含行人1 126個),負樣本453張。
3.1 評價指標
二分類問題中,根據分類器預測類別和真實類別可將樣本劃分為:真正例TP、假正例FP、真反例TN、假反例FP四種。查準率P和查全率R定義為:


本文評價算法指標采用:平均對數漏檢率(Log-Average Miss Rate, LAMR)、MR-FPPI(Miss rate-False Positives Per Image)曲線和P-R曲線。
3.2 參數的選取
為了讓ACF檢測漏檢率達到最低,本文對非極大值抑制中閾值T的取值進行了分析,如圖5所示。由圖可以看出,閾值T取0.58~0.6時漏檢率達到最低,本文取T=0.6。

圖5 閾值對ACF漏檢率的影響
計算LBP與ST特征時候,需要對圖像進行分塊,本文分別選取了2×2、4×4、8×8、16×16分塊大小計算平均漏檢率,分析分塊大小對檢測精度的影響,如圖6所示。由圖6可知,LBP與ST均采用4×4的塊大小時檢測漏檢率最低。

圖6 塊大小對漏檢率的影響
3.3 仿真實驗
為了說明本文算法的檢測效果,表1比較了本文算法及幾個經典算法(HOG、HOG+LBP、ChnFtrs、ACF)的平均漏檢率(LAMR)。
從表1可以看出本文算法的LAMR要遠低于幾種經典算法的LAMR。僅采用一級LBP篩查得到的LAMR為14.95%,經過二級篩查檢測精度進一步提高,LAMR為13.32%;本文算法與原始的ACF比較,LAMR降低了3.73個百分點。實驗結果表明,通過結合多通道特征的檢測算法可以提高行人檢測的精度。

表1 不同檢測算法錯誤率比較
對應幾種算法的MR-FPPI曲線如圖7(a)所示,從中可看出本文算法的MR-FPPI曲線位于其他幾種算法的MR-FPPI曲線下方。圖7(b)為本文算法與ACF算法的P-R曲線圖,從中可看出ACF的P-R曲線完全被本文算法的P-R曲線“包圍”。由此分析本文算法要明顯優于ACF算法。

圖7 MR-FPPI曲線與P-R曲線
為了能夠更好地說明在復雜場景下的檢測情況,圖8列舉了四幅復雜場景下“單人”和“多人”檢測結果。

圖8 檢測效果比較
從圖8可知:在復雜場景下,ACF在顏色多變的背景處容易發生誤檢,本文利于LBP特征和ST特征對ACF特征進行互補,能夠一定程度上消除這些誤檢,提高了算法的精度。
為了測試本文算法的檢測速度,對測試集的288幅圖像進行檢測,ACF的平均時間是0.14 s,ACF-LBP的平均時間是0.25 s,ACF-LBP-ST的平均時間是0.95 s,由此可知,本文算法主要時間開銷來源于ST特征的計算。綜合分析,本文算法在時間開銷的允許范圍內,有效地降低了檢測的LAMR,提高了算法精度。
4 結語
ACF算法速度快,在場景不復雜時具有較高的檢測精度,但是由于它只刻畫了顏色和梯度信息,在復雜場景下,有時會出現誤檢較多的現象,為了克服這一問題,本文對ACF特征結合了LBP特征與ST特征對其進行補充。同時在檢測中,為了提高算法效率本文采用了級聯思想,利用累加置信函數作為判別方式。在INRIA數據集進行算法測試,證實了LBP特征與ST特征能夠有效彌補ACF算法對行人特征刻畫不全的缺陷,同時在此基礎上本文算法采用了級聯的方式提高效率,但是與ACF算法比較,檢測速度還是相對有所下降,同時在某些場景下仍然存在一些誤檢的情況,遇到姿態變化較大的行人也存在漏檢情況。未來完善的地方在于是否還有更好的特征可以對ACF算法進行補充,在精度影響不大的情況下,如何進一步提高算法的效率。
References)
[1] DOLLAR P, WOJEK C, SCHIELE B, et al. Pedestrian detection: an evaluation of the state of the art[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(4): 743-761.
[2] 賈慧星, 張毓晉. 車輛輔助駕駛系統中基于計算機視覺的行人檢測研究綜述[J]. 自動化學報, 2007, 33(1): 84-90. (JIA H X, ZHANG Y J. A survey of computer vision based pedestrian detection for driver assistance system[J]. Acta Automatica Sinica, 2007, 33(1): 84-90.)
[3] BENENSON R, OMRAN M, HOSANG J, et al. Ten years of pedestrian detection, what have we learned?[EB/OL]. [2017- 01- 10]. https://arxiv.org/pdf/1411.4304.pdf.
[4] 蘇松志, 李紹滋, 陳淑媛, 等. 行人檢測技術綜述[J]. 電子學報, 2012, 40(4): 814-820. (SU S Z, LIN S Z, CHEN S Y, at al. A survey on pedestrian detection[J]. Acta Electronica Sinica, 2012, 40(4): 814-820.)
[5] DALAL N, TRIGGS B. Histograms of oriented gradients for human detection[C]// Proceedings of the 2005 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2005, 1: 886-893.
[6] FELZENSZWALB P, MCALLESTER D, RAMANAN D. A discriminatively trained, multiscale, deformable part model[C]// Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2008:1-8.
[7] FELZENSZWALB P, GIRSHICK R, MCALLESTER D, et al. Object detection with discriminatively trained part based models[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 32(9): 1627-1645.
[8] WU J, GEYER C, REHG J M. Real-time human detection using contour cues[C]// Proceedings of the 2011 IEEE International Conference on Robotics and Automation. Piscataway, NJ: IEEE, 2011.
[9] WANG X, HAN T X, YAN S. An HOG-LBP human detector with partial occlusion handling[C]// Proceedings of the 2009 IEEE 12th International Conference on Computer Vision. Piscataway, NJ: IEEE, 2009: 32-39.
[10] WALK S, MAJER N, SCHINDLER K, et al. New features and insights for pedestrian detection[C]// Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2010: 1030-1037.
[11] DOLLAR P, TU Z, PERONA P, et al. Integral Channel Features[C]// Proceedings of the 2009 British Machine Vision Conference. London: BMVC Press, 2009: 1-11.
[12] DOLLAR P, APPEL R, BELONGIE S, et al. Fast feature pyramids for object detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(8): 1532-1545.
[13] LIM J J, ZITNICK C L, DOLLAR P. Sketch tokens: a learned mid-level representation for contour and object detection[C]// Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2013: 3158-3165.
[14] OJALA T, PIETIKAINEN M, HARWOOD D. A comparative study of texture measures with classification based on feature distributions[J]. Pattern Recognition, 1996, 19(3): 51-59.
[15] SHAPIRE R E, SINGER Y. Improved boosting algorithms using confidence-rated predictions[J]. Machine Learning, 1999, 37(3): 297-336.
[16] BOURDEV L, BRANDT J. Robust object detection via soft cascade[C]// CVPR 2005: Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2005, 2: 236-243.
Multi-channelpedestriandetectionalgorithmbasedontexturalandcontourfeatures
HAN Jiandong*,DENG Yifan
(SchoolofComputerandInformationTechnology,ShanxiUniversity,TaiyuanShanxi030006,China)
In order to solving the problem that the pedestrian detection algorithm based on Aggregated Channel Feature (ACF) has a low detection precision and a high false detection rate in complex scenes, a multi-channel pedestrian detection algorithm combined with features of texture and contour was proposed in this paper. The algorithm flows included training classifier and detection. In the training phase, the ACF, the texture features of Local Binary Patterns (LBP) and the contour features of Sketch Tokens (ST) were extracted, and trained separately by the Real AdaBoost classifier. In the detection phase, the cascading detection idea was used. The ACF classifier was used to deal with all objects, then the complicated classifier of LBP and ST were used to gradually filter the result of the previous step. In the experiment, the INRIA data set was used in the simulation of our algorithm, the results show that our algorithm achieves a Log-Average Miss Rate (LAMR) of 13.32%. Compared with ACF algorithm, LAMR is decreased by 3.73 percent points. The experimental results verify that LBP and ST can be used as a complementation of ACF. So some objects of false detection can be eliminated in the complicated scenes and the accuracy can be improved. At the same time, the efficiency of multi-feature algorithm is ensured by cascading detection.
Aggregated Channel Feature (ACF); sketch tokens feature; Local Binary Pattern (LBP) feature; Real AdaBoost classifier; cascading detection
2017- 04- 07;
2017- 07- 01。
國家自然科學基金資助項目(61602288)。
韓建棟(1980—),男,山西文水人,講師,博士,CCF會員,主要研究方向:計算機視覺、數據挖掘; 鄧一凡(1992—),男,內蒙古阿拉善左旗人,碩士研究生,主要研究方向:目標檢測與跟蹤。
1001- 9081(2017)10- 3012- 05
10.11772/j.issn.1001- 9081.2017.10.3012
TP391.41
A
This work is partially supported by the National Natural Science Foundation of China (61602288).
HANJiandong, born in 1980, Ph. D., lecturer. His research interests include computer vision, data mining.
DENGYifan, born in 1992, M. S. candidate. His research interests include target detection and tracking.
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
