基于被引片段識別的科技文摘綜述
2017-12-15 00:04:18李綱徐健余輝馬亞雪
現代情報 2017年9期
李綱 徐健 余輝 馬亞雪
[摘要][目的/意義]基于被引片段識別的科技文摘生成是文獻計量學、信息檢索和自然語言處理等領域共同關注的研究問題。通過梳理相關成果,可為后續研究提供借鑒。[方法/過程]本文首先介紹被引片段概念,進而從被引片段識別與分類、文摘生成與評價等步驟對相關研究進行綜述。[結果/結論]當前被引片段識別總體上可以分為機器學習和檢索兩類,分面判定還存在標準不一致的問題,摘要生成與評估方法相關研究較欠缺。
[關鍵詞]被引片段;科技摘要;引文上下文
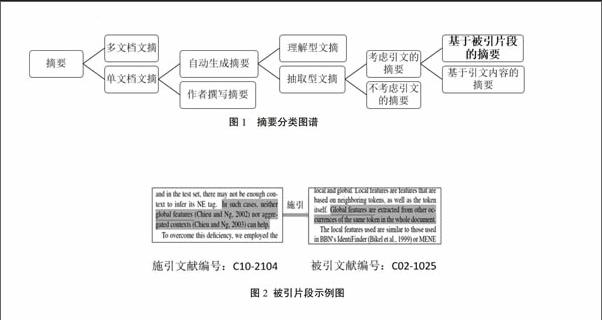
科研工作者在科學研究活動中通常需要閱讀大量科技文獻以了解研究領域現狀。在當前學術論文數量與日俱增的情況下,通過閱讀科技文獻的摘要將大幅度減小科研工作者閱讀文獻的壓力。當前科技文獻摘要的形成過程可分為作者撰寫和自動生成兩種方式。前者雖然能精準地概括文章的核心內容,但由于其是從作者角度而非讀者角度完成的,因此很難客觀地反映該文對學界的貢獻與影響。自動文摘作為一種自動凝練目標文獻核心內容的方法,具有效率高和客觀性強的特點,因而在信息檢索與信息抽取等領域具有廣泛的應用。按照摘要與原文的關系的不同,自動文摘技術可分為抽取型文摘和理解型文摘,后者受當前語義理解和自然語言處理技術限制較大,所以目前關于自動文摘的研究主要集中在抽取型文摘上嘲。傳統抽取型摘要的做法是計算目標文獻中各句子重要性并選取若干關鍵句生成文摘,這樣生成的摘要同樣不能從讀者角度反映該文的影響力。于是,越來越多的研究者嘗試從引文角度考慮該問題闈。基于引文的摘要技術的基本概念是引文內容,又稱引文上下文(citation context),包含了對被引文獻的介紹與述評,從讀者角度揭示了被引文章對學界的影響。當前,如何通過引文上下文生成摘要存在直接法與間接法兩種思路,前者對目標文獻的引文句進行組織進而完成摘要生成,后者需從被引文獻中識別出被引片段并對其進行融合,生成最終的摘要。為方便對本文所評述自動摘要方式有直觀的理解,筆者歸納了摘要的種類并繪制摘要的分類圖譜,如圖1所示。
引文上下文是指引文標記所處的上下文,當前廣泛用于引用動機識別、主題識別、信息檢索、文檔聚類等領域。直接使用引文上下文生成單文檔文摘最早開始于2008年Qazvinian等的研究,作者對被引文獻的引文上下文進行聚類與排序,從而生成被引文獻的摘要。Kaplan等將指代消解(corefcrenee resolver)應用于引文上下文的抽取,實驗證明該方法相比于其他方法在抽取引文上下文時效果更優,抽取出的內容可進一步用于文摘生成。HUE21等將引文句視為文獻的使用上下文,并將之與結構上下文組成混合引文上下文開展基于影響點的文摘研究。直接利用引文上下文生成文摘目前已有較多的成果,但引文上下文中除包含對被引文獻的介紹和評述外還包含了施引者的觀點,因此有學者指出直接使用引文上下文的文摘存在主題偏移和信息缺失的問題,因此基于被引片段的文摘生成受到越來越多研究者的關注。
基于被引片段的文摘研究最早開始于文獻“GeneratingImpact-Based Summaries for Scientific Literature”,與直接使用引文上下文生成摘要相比,這種方式生成的摘要來自于原文,從而避免了主題偏移的問題。Mei利用文章的所有引文上下文構建其影響模型,在原文中尋找能反映該影響的句子,并加以組織生成文摘。Cohan通過對被引片段進行聚類,從各類簇中抽取重要性較高的幾個句子形成文摘。在web of knowledge、Google Scholar平臺上以檢索式“cited spans summary”“reference text spans summary”等為關鍵詞進行檢索,發現相關結果并不多,大量的成果集中于2014TAC和2016CL-SciSumm的會議論文上。同時,國內針對被引片段的自動文摘相關成果則更加少。通過查找相關文獻進行擴充,通過人工閱讀共得到相關文獻26篇。當前基于被引片段的文摘步驟可概括為兩步:首先從被引文獻中識別并抽取被引片段,并判定其在語篇中的功能;其次,從被引文獻中抽取若干句子本文通過文獻。本文首先用實例介紹被引片段的概念,接著以兩次文摘比賽的步驟歸納與評述該領域研究現狀,以期為后續相關研究提供借鑒。
1被引片段概念
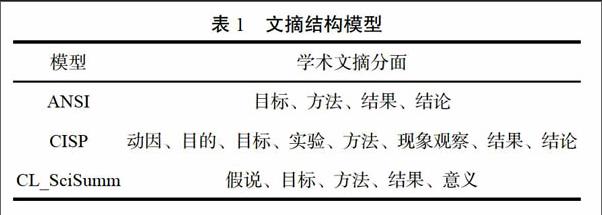
在引文分析領域,“被引片段”是一個嶄新的概念,是引文內容分析未來發展的重要的研究方向。單篇文獻會包含多個研究主題,而其他文獻在引用它時僅僅是因為某個主題。施引者會引用其認定對自己研究有參考價值的內容,這部分內容正是本文所述的被引片段(Cited Spans or Reference Span)。一般認為,在一次引用過程中被引片段與引文上下文具有對應關系,相比于被引頻次,被引片段更清晰與具體地說明了該文獻對學界的貢獻與影響,圖2用實例說明被引片段的概念:
在圖2中,施引文獻C10-2104中被標注的句子就是引文上下文,文獻C02-1025中被標注的句子為被引片段。文獻C10-2104因為需要對“global features”來源進行說明而引用了文獻C02-2105。此時,文獻C02-1025中關于“global features”的描述語句“Global features are extracted from other occurrences of the same token in the whole document”則可稱為對應的被引片段。在這次引用過程中,文獻C02-1025中關于“global feature”的研究對文獻C10-2104具有一定參考價值與借鑒意義。在單次引用中,被引片段從內容角度揭示了該文獻被引用的原因,反映了該文獻對后續研究的借鑒作用。通過組織與整合某篇文獻的多個被引片段,即可全面地評估其對學界的影響,進而生成摘要。
2被引片段識別與分類
2.1被引片段識別endprint
被引片段識別就是從被引文獻中尋找與引文上下文相對應的那部分內容,識別結果可以是句子的一個片段、也可以是一個整句或者若干連續句子的集合。目前被引片段的識別方法總體上可以分為:基于信息檢索的方法、基于機器學習的方法兩類。
2.1.1基于信息檢索的方法
基于信息檢索的方法將被引文獻中的句子按照與引文上下文的相似性或重要性進行排序,選擇排名最靠前的句子作為被引片段。基于相似性的方法認為被引文獻中與某引文上下文中相似度越高的句子越可能是其對應的被引片段。例如,Molla通過擴充句子規模、增加句子上下文窗口的方式對傳統的TF-IDF公式進行改進計算引文上下文與被引句之間的余弦相似度,并選取最相似的三句話作為被引片段。Cohan利用向量空間模型計算引文上下文與被引文獻中各句子的相似性,并將基于偽相關反饋的重排序技術引入到被引片段識別過程中。日本學者Nomoto將引文上下文視為問題,而被引文獻中的句子為待選答案,被引片段的識別就轉化為問答系統的問題。該方法將基于單層神經網絡預測的相似性和基于詞袋模型計算的余弦相似性進行融合,進而定位被引片段。而基于重要性的排序方法則認為,句子在被引文獻中越重要則其越有可能被其他文獻引用。例如,Klamp提出一種改進的關鍵句識別算法(Textrank),將引文上下文與句子的相似性最為句子的初始權重,經過隨機游走過程確定被引文獻中句子的重要性并進行排序。
由上可知,無論是基于相似度計算還是基于重要性排序,基于信息檢索的被引片段識別方法過程簡單,效率較高。但是將被引片段識別問題轉化為信息檢索問題在理論上還缺乏一定的依據,關于相似性與重要性的假設也需進一步推敲。筆者認為,只有從語義理解的角度對被引文獻與引文上下文間的關系進行探索才能更精準地尋找被引片段。此外,這種方法在操作過程中還存在兩個問題:第一是排名前幾位的句子在位置上不一定相鄰,這不符合被引片段連續幾個句子的特征,第二是被引片段選取的門檻難以確定。
2.1.2基于機器學習的方法
相較于基于信息檢索的識別方法,更多研究者使用機器學習方法來識別和抽取被引片段。按照實現方法的不同,該方法又可分為分類學習方法(Classification)和排序學習(Learning to rank)的方法。前者將被引片段識別問題轉化為句子的二元分類問題,即被引文獻中所有句子被判定為匹配與不匹配兩個類別,所有匹配的句子被即被視為被引片段。目前常用的分類方法有支持向量機,樸素貝葉斯,常用的分類特征有位置特征和相似度特征。后者則融合多種排序特征對句子進行排序,Cao等和Lu等學者分別利用SVMRANK和RANKLIB工具進行此方面的探索。
綜上所述,無論是基于分類學習的方法還是基于排序學習的方法,均可以有效利用多種信息作為特征進行學習,但都存在一個較大的問題:類別不均衡。在尋找引文上下文的過程中,被引文獻中僅少數幾個句子被標注為被引片段,正負例比率較低使該方法識別占少數的被引片段比較困難。此外,分類器可能將被引文獻中的所有句子都判定為非被引片段,同時也有可能將幾十甚至幾百個句子都判定為被引片段,這將大大降低該方法的可用性。此外,也有學者通過人工定義抽取規則,實現被引片段的識別。該方法具有較高的執行效率,過程易于理解,但在實際操作過程中相關啟發式規則的歸納費時費力,且規則覆蓋范圍有限,從而使得該方法具有過適應性(over-fitting)。
2.1.3被引片段識別評價
被引片段識別結果的評價根據粒度可分為句子和單詞兩個層面,前者通過計算系統識別出的被引片段和人工標注結果之間重合度(Overlap)完成,后者則使用ROUGE完成,具體指標有準確率,召回率和F1值。目前各研究團隊被引片段識別結果與人工標注的結果有很大的差異,以2016年JCDL舉辦的CL-SciSumm比賽為例,目前關于被引片段識別的準確率最高僅為12%。這說明當前關于被引片段研究還不成熟,需要就被引片段理論與特征開展進一步探究。
2.2被引片段分類
被引片段分類的目的是形成結構化的文摘,下面分別介紹文摘結構相關理論、被引片段分類及其評估過程。
2.2.1文摘結構相關理論
作者在撰寫科技文獻的摘要時,需注意其分面邏輯性(即先寫什么后寫什么)以提高文摘質量和主題表達能力。同樣地,在自動文摘生成過程中,也要按照一定的標準對備選句子進行分類、組織與篩選。結構化文摘通過收集有關目標文獻各方面信息生成文摘,使得對目標文摘描述具有全面性和簡潔性。目前,國內情報學領域期刊如現代圖書情報技術、圖書情報工作等均要求作者投稿時提交結構化摘要,這也是目前學術文摘規范未來發展的趨勢。當前主流的文摘結構表示模型主要有ANSI模型、CISP模型等(具體情況見表1)。其中ANSI模型是從摘要的結構進行劃分文摘分面的,而CISP是從正文撰寫角度進行摘要分面劃分。2016年CL-SciSumm比賽將文摘分面定義為假說、目標、方法、結果、意義五類,參賽者需判定前一步驟識別出的被引片段的類別。
從表1中可以看出,當前關于文摘結構分面尚未有統一的標準,這與各學科研究內容與研究模式有一定關系。此外,對于一些觀點類、評述類的文獻來說,上述偏實驗研究類論文的文摘結構也并不適合。
2.2.2被引片段分類研究
被引片段作為最終摘要內容的來源,需要判定其在整個摘要結構中的功能,該過程可視為一個多元分類問題。筆者認為,既然被引片段來自于被引文獻,則其分類與基于正文的學術文摘結構識別當屬具有相關之處。Guo等分別利用支持向量機算法實現了基于文本內容特征的文摘語句分類。Yamamoto等在分類特征的選取上考慮了動詞時態、語句位置等信息。白光祖等針對不同類別建立特征詞集,研究小樣本情形下學術文摘類別判定問題。具體到被引片段分類上,Lu等在被引片段分類過程中,使用了正文和引文中文本與其所在章節標題的用詞信息。Malenfant等認為被引片段與其對應引文的類別是一樣的,因此可根據引文類別推斷被引片段的類別。Li等使用多個分類器進行投票以提高分類準確率。在實際引用過程中,方法、結果類引用較多,而意義、假說部分的內容引用次數較少,針對被引片段分布偏斜問題主要解決方法有基于分類器算法的改進和訓練集的重構。與其他多分類問題一樣,被引片段分類的評價指標主要是各個類別Precise-Recall和F-measure指標。此外,整體層面的評價指標有正確率,各類別性能的宏平均和微平均等。endprint
3文摘生成與評估
3.1文摘生成
目前,基于被引片段的文摘基本思路可概括為:為被引文獻中的每句話進行重要性打分,通過一定策略抽取重要性較高的句子生成滿足長度條件的摘要。在句子重要性打分方面,Mei等利用所有引文句和原文推測文獻影響力模型,該模型可以視為被引片段集合,之后計算文中各句子與該模型的KL距離作為句子重要性值。Cao等提出一種改進的流形排序算法,該方法將文獻內部句子問相似性與引文句間相似性的值進行線性融合,通過隨機游走過程迭代計算每個句子權重并從中選擇最重要的句子。陳海華等使用支持向量回歸(SVR)方法融合位置、長度、相似性特征預測文獻中各句子重要性得分。Li等計算文獻中各句包括基于層次主題模型(HLDA)的相似度、句子長度、句子位置等在內的5種數值特征,利用線性加權的方式計算句子重要性。Saggion等用向量空間模型表示標題、摘要、全文、引文句等文本,利用線性回歸模型對包括相似性、位置、重要性等特征參數進行學習。系統生成的摘要不僅僅要求內容全面,而且要求簡潔,冗余信息少,基于被引片段的科技文摘賽事一般將之設置為選擇性任務。值得注意的是,當前大多數研究并未嚴格使用識別出的被引片段與其類別生成結構化摘要,該部分研究還比較欠缺。
自動摘要的長度一般設定為固定句子數或字符數,這與具體任務要求有關。例如2016年CL-SciSumm比賽官方要求目標摘要字數為250個字符,而有的學者將長度設置為若干句子數目。還有的學者考慮了目標文獻本身長度按比例設置摘要長度。在實際生成摘要的過程中,存在若干用詞相同、語義相近的句子組成摘要的情形,此時就需要結合一定的去重策略篩除語義冗余的句子,使摘要盡可能全面的覆蓋文章的各個方面。當前很多研究利用最大邊緣算法(Maximum Marginal Relevance,MMR)通過計算待選句子和已選句子的相似度,選擇超過某閾值的句子生成摘要。針對自然語言中多詞一義的問題劉天祎等指出要結合相關知識庫才能更好地實現語義層面的去重。
3.2文摘評估
摘要評估是針對系統生成摘要的長度、全面性、真實性、可讀性等方面的評判。具體而言,文摘評價標準的制定可以分為主觀評測和基于標準結果的兩種情況,前者需要人工閱讀系統生成的文摘并給出評價。后者需要提前定義目標文獻文摘的參考答案(Golden standards),一般而言由原文作者撰寫的摘要和人工生成兩種,通過對比該參考答案與系統生成文摘的相似性進行文摘質量的評價。文摘領域的評價指標一般使用ROUGE,該方法基于N元詞共現信息計算系統生成文摘和人工生成文摘的匹配程度,包括ROUGE-N、ROUGE-L、ROUGE-W、ROUGE-SU四種評測標準。
目前幾乎所有的評價方案均只限于內容的完備性和準確性上,關于摘要連貫性、可讀性等方面還未有較好的評估方案。在今后的研究中,應考慮引入用戶對生成摘要的質量反饋機制,提高生成摘要的連貫性和可讀性。
4結語
當前關于被引片段文摘的研究多集中在微軟亞洲研究院組織的比賽上,而學界對于被引片段概念的了解與接受程度普遍較低,從而導致相關研究比較少,國內研究則更是少之又少。本文按步驟對基于被引片段文摘技術進行深入分析與探討,從而對整體研究進行述評。研究發現,當前相關研究及其應用中還存在若干問題與困難。具體如下:被引片段識別與分類是該領域研究的主流,然而對被引片段概念、特征等在理論層面的探討較少,目前被引片段標注過程不規范,并未經過多人標注;相關研究表明零被引文獻也是有價值的,但該文摘方法不太適合零被引和低被引的情況,同時也存在某文獻被引片段過于集中導致文摘覆蓋面低的問題(例如,文獻的方法被引用了若干次,而文獻的結果部分無人引用);相比于網頁,學術文獻一般在10頁到30頁之間,將如此長篇幅的文本壓縮成不到300個單詞的文摘,其壓縮比例和困難程度均比較大,從目前研究來看,機器生成文摘與人工生成文摘差異較大,效果并不能使人滿意;自動文摘最終的用戶是讀者,不僅要對信息進行濃縮還要保障其可讀性和可理解性,這種抽取型文摘僅僅是若干句子的集合,句子順序混亂與句子間邏輯缺乏,相關研究缺乏用戶對文摘質量的反饋。
當前,關于被引片段的自動文摘研究受到文獻計量、信息檢索、自然語言處理、文本挖掘等領域的共同關注。相關研究尚處于起步階段,尚存較多待解決問題,未來研究中應著重剖析被引片段概念的內涵,優化其識別與分類的方法,設計更加科學合理的文摘結構,同時考慮被引片段范圍集中的問題,生成更加全面、客觀的摘要,引入讀者對文摘的反饋機制,帶動該項研究實用性水平的提升。endprint
