基于MPI并行算法的農(nóng)作物生長環(huán)境的數(shù)據(jù)分析
2017-12-18 11:34:24李得原
南方農(nóng)業(yè)·下旬 2017年10期
李得原
摘 要 為了提升作物生長模型的運算速度,MPI并行算法由于自身所具有的優(yōu)越性而被廣泛地應(yīng)用。基于此,對MPI并行計算的農(nóng)作物生長環(huán)境的數(shù)據(jù)展開分析。首先,概述MPI并行計算方法,然后分析MPI并行算法在農(nóng)作物生長環(huán)境的數(shù)據(jù)應(yīng)用情況。
關(guān)鍵詞 MPI;并行算法;農(nóng)作物;生長環(huán)境;數(shù)據(jù)
中圖分類號:TP301.6 文獻標志碼:B DOI:10.19415/j.cnki.1673-890x.2017.30.063
最近幾年,作物模型的地區(qū)性運用需求持續(xù)性遞增,被廣泛地運用在地區(qū)性生產(chǎn)力預(yù)測與預(yù)警、氣候改變走向研究中。作物模型在地區(qū)性的運用過程中,需與氣象模型、生態(tài)環(huán)境模型以及GIS等主要技術(shù)相整合,同時受到地點、參量以及時段等多種因素的共同作用,一般會出現(xiàn)模型運算量的劇增,模型驅(qū)動式變量的數(shù)據(jù)量變多以及運算時間偏長等問題[1],因而,如何借助分布式計算環(huán)境來增強作物模型在多個時間段、多個地點以及多個尺度環(huán)境的運算性能,是作物模型范圍內(nèi)急需解決的一個難題。而MPI則是其中重要的計算工具,本文正是據(jù)此來對農(nóng)作物生長環(huán)境的數(shù)據(jù)展開分析。
1 MPI并行計算法概述
MPI并行計算法是一類根據(jù)信息傳輸?shù)牟⑿惺骄幊碳夹g(shù)。傳輸消息接口是一類編程接口標準,而非具體化的編程語言。換言之,MPI界定了一組具備可移植性編程接口[2]。此計算方法具備PVM的大多數(shù)優(yōu)點之外,同時還擁有如下的特征:第一,實現(xiàn)途徑多樣,且適用于數(shù)類研發(fā)工具與基礎(chǔ)性的研發(fā)語言;第二,有效地對消息緩存區(qū)加以管理;第三,在數(shù)類并行計算機系統(tǒng)結(jié)構(gòu)中有效地運作;第四,開展異步通信程序,無論是發(fā)送還是接收過程,完全可以和運算重疊展開;第五,異步實施時,對于運用者的其他軟件并不會導(dǎo)致后果;第六,是完全能夠移植的標準式平臺。
2 MPI并行算法在農(nóng)作物生長環(huán)境的數(shù)據(jù)應(yīng)用分析
MPI并行算法的前提條件是對子模型組分進行并行式處理,把運算任務(wù)區(qū)分成主從聯(lián)系,并行處理的粒度并不大,然而運算數(shù)據(jù)對應(yīng)的通信時間則較長。因此,本文所確定的方案為把并行處理的粒度提升至子模型層面,即把生長模型的運算任務(wù)當(dāng)作一個任務(wù)項目,試圖將其區(qū)分成一系列能夠并行實施的子任務(wù),即{T1,T2,T3,…Tp|P表示子任務(wù)的數(shù)目},使得任務(wù)運算完成之后,確保Ti任務(wù)能夠馬上開始相同的運算速度,據(jù)此達到提升運算速度的目的。Ti+1任務(wù)的構(gòu)成主要是數(shù)個子模型組分的運算關(guān)系式,即{M1,M2,M3,…Mx|X表示的是子模型組分運算的關(guān)系式數(shù)},x大小主要決定于子模型組分內(nèi)部的數(shù)據(jù)依賴式聯(lián)系。在作物生長相關(guān)的模型內(nèi),Dev子模型的計算方法所涉及到的函數(shù)式無需其他公式輸出的數(shù)據(jù),即能夠視作T1任務(wù);Biomass計算方法公式與Parition計算方法公式的數(shù)據(jù)互相之間存在著依賴性,能夠被一同視作T2任務(wù);Orgmake計算方法公式充分地依賴其他4個子模型的運算結(jié)果,即能夠視作T3任務(wù)。據(jù)此為原則,獲取子模型層的并行調(diào)度方案A,并表示成A方案。
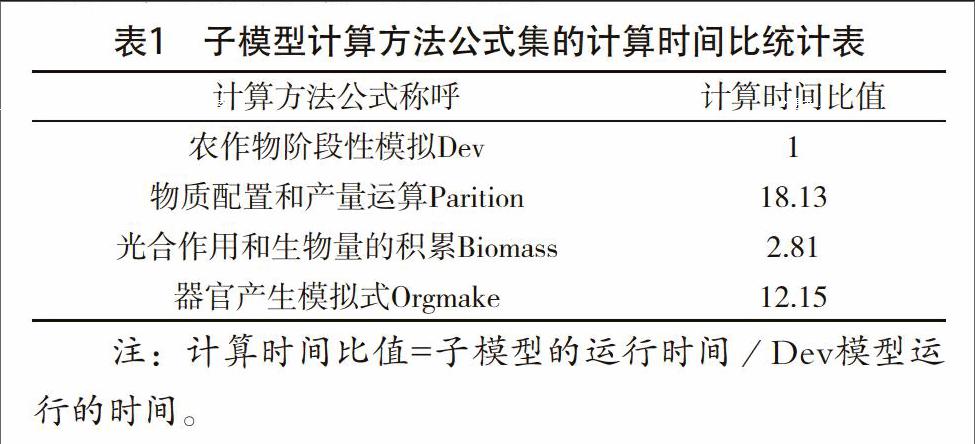
因為分配的處理器不同,對應(yīng)的運算任務(wù)及其量也存在著差異,從而會導(dǎo)致部分處理器和其他處理器率先完成任務(wù)之后處于空閑的狀態(tài)。因而,能夠通過盡量地在處理器之間均衡地配置運算的任務(wù),從而達到負載均衡的狀態(tài),也就是讓全部的處理器均可以持續(xù)性地實施上述任務(wù),提升處理器使用的效率。基于計算方法A的前提下,檢測串行模式環(huán)境中農(nóng)作物生長的模擬流程,對比不同子模型運算方法關(guān)系式的實施時間比,目的在于達到靜態(tài)負載的均衡狀態(tài)。設(shè)置了單個單機上串行流程的檢測實驗:即通過農(nóng)作物大麥1個生長季所對應(yīng)的氣溫數(shù)據(jù)當(dāng)作模型驅(qū)動式變量,檢測得到Dev子模型的運作時間是1s,具體的運算時間見表1。
基于表1的相關(guān)數(shù)據(jù)分析可以發(fā)現(xiàn),各子模型計算方法的公式對應(yīng)的實施時間差別顯著。其中,Biomass與Parition計算方法公式的輸入和輸出的數(shù)據(jù)相耦合,2個計算方法公式的運行時間比比值是20,遠遠地超出Dev計算方法公式的計算時間。在以上提及的流水線式并行計算方法A項目內(nèi),若把DEV子模型計算任務(wù)單獨視為一項任務(wù),必然導(dǎo)致其所在的處理器完成計算任務(wù)后,不得不等待執(zhí)行數(shù)據(jù)傳輸操作,使得處理器長時間處于空閑的狀態(tài)。出于維持各個處理器內(nèi)部的負載均衡目的,把Dev計算方法的公式與Biomass甚至是Parition計算方法公式合成一項運算的任務(wù),從而獲取優(yōu)化之后處理的子模型層并行式優(yōu)化調(diào)度的方案B,并表示成B方案。
另外,方案A與方案B采納的是數(shù)據(jù)平均分割法,即把各個運算的節(jié)點根據(jù)實施一樣的任務(wù),不同的僅僅為數(shù)據(jù)。同時用年作為單位來配置輸入的數(shù)據(jù),每一個運算的節(jié)點處(PC)通過平均的方式分配若干年份的相關(guān)數(shù)據(jù)[3],同時將它們依次展開完善的模擬運算,節(jié)點內(nèi)部所采納的是流水線式的并行計算方法。根據(jù)最后的運算結(jié)果可知,B方案優(yōu)于A方案。
3 結(jié)語
并行程序主要是通過互聯(lián)網(wǎng)環(huán)境時開展多處理器計算資源的一種有效性方式。以往的并行運算主要借助于高昂的高性能服務(wù)器方式,最終實現(xiàn)高成本的目的。在最近幾年中,PC級微處理器的性能日益提升,同時高速互聯(lián)網(wǎng)日益成熟和推廣,從而替在廉價數(shù)核的PC級集群環(huán)境中,借助于高速與低成本的方式為并行運算提供了良好的條件。當(dāng)下,并行計算方法已廣泛地運用在地質(zhì)勘察、分子動力學(xué)、氣象預(yù)報以及虛擬性植物等研究范圍中,從而在一定程度上提高了科學(xué)運算的效率。
參考文獻
[1]王萃寒,趙晨,許小剛,等.分布式并行計算環(huán)境[J].計算機科學(xué),2013,30(10):252-261.
[2]姜海燕,朱艷,湯亮,等.基于本體的作物系統(tǒng)模擬框架構(gòu)建研究[J]中國農(nóng)業(yè)科學(xué),2015,42(4):1207-1214.
[3]嚴美春,曹衛(wèi)星,羅衛(wèi)紅,等.小麥地上部器官建成模擬模型的研究[J].作物學(xué)報,2011,27(2):222-229.
(責(zé)任編輯:趙中正)endprint
