移動網絡中重傳超時問題的研究
2018-01-02 08:44:22萬文凱汪海濤
軟件 2017年12期
萬文凱,汪海濤,姜 瑛,陳 星
(昆明理工大學 信息工程與自動化學院,云南 昆明 650500)
移動網絡中重傳超時問題的研究
萬文凱,汪海濤,姜 瑛,陳 星
(昆明理工大學 信息工程與自動化學院,云南 昆明 650500)
作為廣泛使用的網絡傳輸控制協議,TCP(Transmission Control Protocol)在高速移動網絡中遇到了新的性能瓶頸。首先由于移動網絡中存在隨機位錯誤導致的丟包,而TCP協議不能有效區分這類丟包與擁塞丟包,導致TCP頻繁的降低擁塞窗口無法有效利用移動網絡的帶寬資源。其次,高速移動網絡的發展使得帶寬時延積BDP(Bandwidth-Delay Product)進一步增大,在發生丟包時TCP協議中的流量控制將導致性能瓶頸和易引起重傳超時。通過Wireshark工具抓取大量的tracing進行分析,發現重傳超時的主要原因是重傳數據包再次被丟,而TCP又不能發現丟失原因,因此無法進行再次重傳最終導致重傳超時。 針對這一問題,本文提出的方法DTOR(Detect Timeout and Retransmission)可以幫助TCP檢測到重傳數據包再次丟失并觸發再次重傳,DTOR使網絡帶寬利用率提升了20%左右。
傳輸控制協議;移動網絡;重傳超時
0 引言
研究顯示,作為廣泛使用的TCP協議在高速移動網絡中遇到了新的性能瓶頸。例如,Mascolo等人[1]還有Fu和Liew[2]設計了新的方法來辨別網絡中的非擁塞丟包和擁塞丟包,防止不必要的降低擁塞窗口(CWnd)造成帶寬利用率損失。也有人在丟失重傳階段重新設計擁塞控制算法來提高TCP的帶寬利用率。
最近,Liu和Lee[3]還有Leong等人[4]提出了基于隊列長度的自適應丟失恢復算法來取代原先TCP中的丟失恢復算法,他們將數據包丟失和擁塞控制解耦,使傳輸速率或CWnd的調整在重傳階段或者發送新數據包時僅受所評估的鏈路中隊列長度的影響。相比較傳統的TCP算法,他們的結果顯示,他們的方法能有效緩解在移動網絡中因隨機丟包造成的帶寬利用率下降問題。
為進一步的提高帶寬利用率,Zha和Liu[5]提出了機會式重傳算法(OR)和新的發送緩存區動態分配策略,來分別解決快速重傳階段的流量控制導致的性能瓶頸和application stall問題。
實驗中,在網絡帶寬為20 Mbps的環境下,通過測試數據來看,Zha和Liu[5]方案的帶寬利用率能達到 95.0%,似乎很好地解決了在丟失恢復階段隨機丟包帶來的帶寬利用率下降問題。然而,當我們把網絡帶寬提升到100 Mbps時,卻發現了一個新問題——頻繁的重傳超時(RTO),致使帶寬利用率只能達到50%左右。通過實驗數據分析,我們發現RTO問題主要是由于在TCP丟失恢復階段的重傳數據包再次被丟失,而TCP發送方不知道重傳數據包再次丟失,從而無法重傳丟失的數據包。于是,我們提出了 DTOR,一個能判斷數據包丟失的原因,并且能觸發TCP發送方再次重傳數據包,緩解RTO的方法。重傳包丟失問題的研究基本上是建立在工作[3]和[5]上的。
1 研究背景和相關工作
在這部分,我們首先回顧在當前TCP擁塞控制中已實施的各類丟失恢復算法,及其在移動網絡中低效率的原因。
1.1 快速恢復算法
Rate-Halving(RH)[7]和 proportional rate reduction(PRR)[6]分別是Linux內核版本3.2之前和之后默認的TCP快速恢復算法,當它們根據收到的ACK或SACK[8]判斷有丟包時,不管是隨機丟包還是擁塞丟包,都會去降低 CWnd,如果是隨機丟包便會出現帶寬利用不充分的情形。
還有一類基于隊列長度的自適應丟失恢復算法,這類算法將 CWnd的調整與丟包解耦,CWnd的增減只與鏈路中的隊列長度有關,如果隊列長度能保證在瓶頸鏈路中一直有數據包傳送,那么帶寬將被充分利用。
由于我們沒能在 Linux內核中找到基于隊列長度丟失恢復算法的源碼,于是我們基于相似的思想自己設計了 Queue-length Adaptive Rate Reduction algorithm(QARR),QARR是基于瓶頸鏈路排隊長度檢測的快速恢復算法,QARR可以解決移動網絡中隨機丟包帶來的性能問題,QARR與RH和PRR相比主要的不同是QARR不依賴ssthresh來指導CWnd的調整,因為CWnd在重傳結束時不收斂到ssthresh,CWnd只受隊列長度的影響。
當TCP發送方重傳完所有需要被重傳的數據包后,將發送新數據包,但需要滿足下面兩個條件:
(a)已經在網絡中的數據包數(inflight data)需要少于 CWnd,即 pipe<CWnd,pipe表示在收到第i個 ACK/DUPACK后網絡中已經發出但還未被確認的數據包的數量。
(b)新數據的序號不能超過接收方AWnd的限制。
QARR也會受到上文提到的條件a和b的限制,遇到AWnd瓶頸問題。
1.2 機會式重傳算法與application stall
1.2.1 機會式重傳算法
Liu和 Lee[11,17]在高 BDP的移動網絡環境下提出了機會式傳輸算法,Zha和Liu[5]在此基礎上進行了擴展,提出了OR算法來解決AWnd瓶頸問題。OR利用接收方的處理能力,允許發送方在重傳階段發送序號超過AW nd右邊界的新數據包。在這個策略中必須謹慎的決定哪些新數據包能被發送。機會式重傳算法可以概括為如下步驟:
(1)對于每一個收到的重復確認包,解析其中SACK段得到兩個信息:在接收緩存中的空洞數,也就是丟包數,用n1表示,和被收到的亂序數據包數,用n2表示。
(2)接著TCP發送方首先會重傳所有的丟包,如果接收方成功接收所有重傳的數據包,那么RW nd就可以向右移動n1+n2個單位。
(3)最終能夠發送的數據量還受擁塞控制的限制,即使用OR算法后數據的發送受限于min(CWnd,Awnd+) n1+n2。
實際上,OR算法這么激進,基本的假設有兩條:一是移動設備具有足夠的處理能力,能夠在重傳包到達后及時的清空接收緩存,騰出空間給后面因OR算法而發送的n1+n2個新數據包;二是重傳數據包不會再次丟失,如果丟失就和 Linux內核的處理方法一樣,等待超時。
1.2.2 Application stall
Application stall現象出現一般是由于(1)發送方不能發送新的數據包,(2)當前的發送緩存機制效率低。對于(1)發送方不總是能發送數據,在2.2.1中,已通過OR算法解決了流量瓶頸這個問題,對于情況(2),Zha和 Liu等人[5]給出了證明,將snd_buf的增長因子從 2調整為 3,即 snd_buf=3*CWnd,這樣能有效的避免重傳階段的application stall現象,具體證明過程可以參看文獻[5]。
機會式重傳的提出和對 Linux內核發送緩存動態分配策略的調整雖然很好地解決了網絡帶寬利用率低的問題,但那也只是在丟包不顯著的環境下。
2 RTO問題分析和解決方案
在帶寬為 20Mbps的情況下,使用 Zha和 Liu等人[5]的方法可以有效提高帶寬利用率,達到95.0%。然而,當帶寬增加到100Mbps,丟包率進一步增大時,會發生頻繁的RTO問題,其帶寬利用率下降到了 50%左右。通過使用 Wireshark工具抓取大量日志分析,我們發現其原因在于使用 OR算法解除流量瓶頸問題后,CW nd升上去了,而由此引發的重傳數據包再次丟失沒有觸發 TCP發送方重傳,導致了超時。
2.1 有OR算法和沒OR算法的區別
首先看一下不加OR算法,TCP如何處理同一個數據包多次丟失的情形。如圖1所示,圖中顯示有兩個丟包。當TCP發送方通過sack推斷出數據包丟失時,會立馬重傳丟失的數據包,接著在AW nd允許的范圍內發送新數據包。一段時間后,如果新發送的數據包被SACKed了,但是重傳的數據包還沒被ACKed,那么TCP發送方就可以推斷出重傳的數據包又丟了,于是再次重傳,然后繼續發送新數據包,直到被 AWnd允許的數據包都被發送完,沒有新包可以發為止。此時,如果重傳的數據包還是沒收到,那么只能等超時了。但在實際中,超時概率是很小的,Linux內核采取的是保守策略,當發生丟包時,CWnd會被減小來緩解網絡的擁塞,從而保證重傳數據包能被收到。
使用了OR算法后的情形如圖2所示,其處理同一數據包多次丟失與不加 OR算法一樣。只是此時AW nd不再是瓶頸,當被AW nd允許的數據包發送完后,為充分利用網絡帶寬,還可以繼續發送新數據包,新數據包數量等于在 2.2節中給出的n1+n2。通過對比可以發現,加了OR算法后如果重傳數據包不丟失,那么網絡將能獲得更高的帶寬利用率。
2.2 頻繁RTO問題的形成
在圖2中,給出了使用OR算法丟包后接收方的RWnd圖,丟包后,RWnd的左邊界就被這個丟包固定。當TCP發送方收到接收方回應的sack時,根據解析sack段發現有數據包丟失,于是進入快速重傳階段,首先重傳 RWnd左邊界這個丟失的數據包。由于使用了OR算法,假設重傳數據包不會再次丟失,接收方收到重傳數據包后能迅速處理RWnd內的數據。這時發送方可以繼續發送數據包的數量記為S:
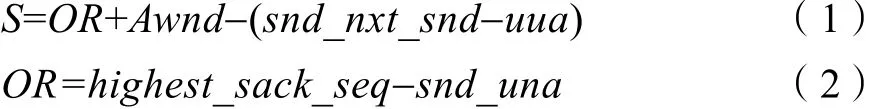
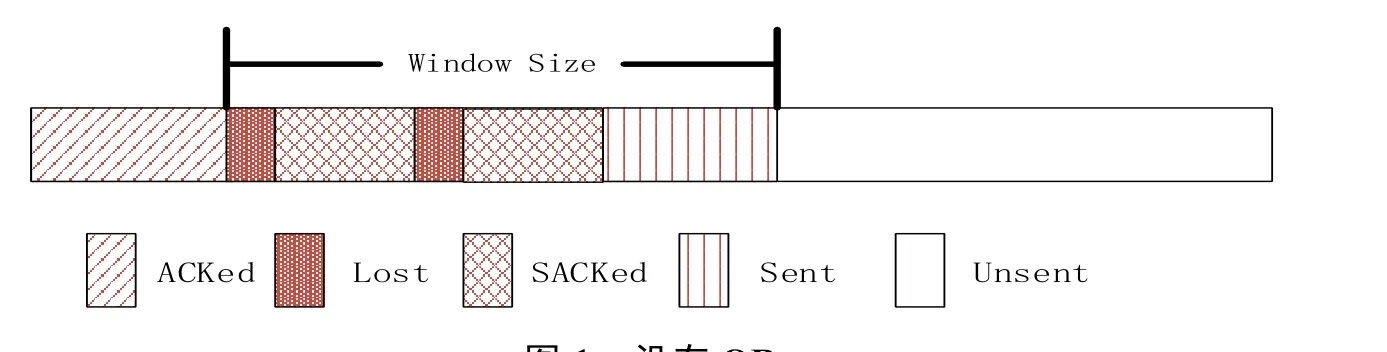
圖1 沒有 ORFig.1 Without OR
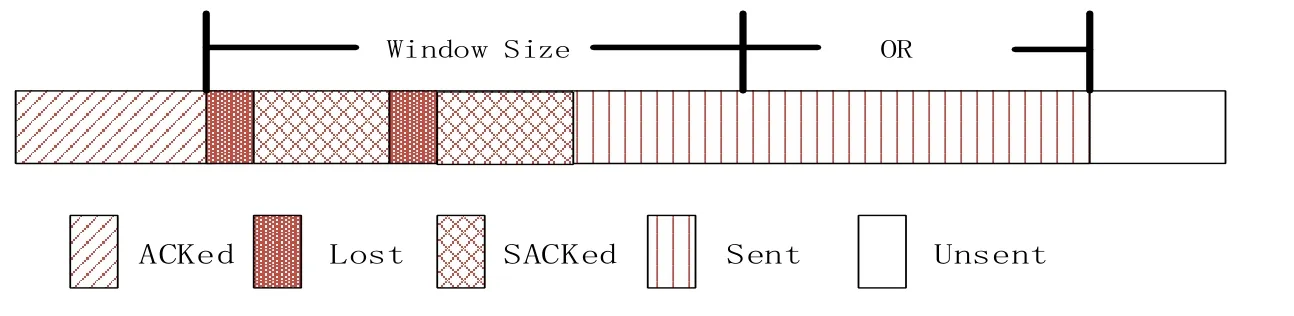
圖2 有ORFig.2 With OR
表達式(1)和(2)中的變量OR 表示使用了OR算法后額外可以發送的數據包數,snd_nxt表示將要發送的第一個新數據包的序號,snd-uua表示第一個丟失數據包的起始序號(也是RW nd的左邊界序號),highest_sack_seq表示發送緩存中已經被發送方確認接收的數據包的最高序號。經過一段時間后,如果重傳的數據包被收到,那么此時的RW nd如圖3所示,RW nd向右滑動,然后根據收到的sack繼續重傳下一個丟失的數據包。因為根據機會式重傳的假設,認為重傳包不會丟失和網絡設備有足夠的處理能力,采取的是激進發送策略,當收到重傳數據包后會立馬清理 RWnd。所以發送方并沒有像傳統方法那樣減小CWnd,控制網絡擁塞,而是為了充分利用帶寬,繼續發送 OR算法允許的新數據包。但是在有多種干擾因素存在的移動網絡中,重傳數據包再次丟失是很有可能發生的,此時的接收方窗口情形會是圖4所示那樣。
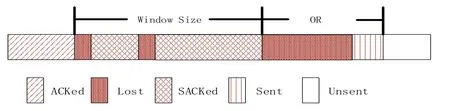
圖4 重傳包丟失Fig.4 Retransmission packet loss
如圖4所示,當RWnd右邊界內的數據包被收到后,而左邊界這個數據包被重傳多次還沒收到時,RWnd內將不再有新數據包觸發重傳 RWnd左邊界的這個數據包,因為此時 RWnd內的數據包已發送完,正在發送的是OR區域內的數據包。RWnd左邊界一直被那個重復丟失的數據包固定,不能向右滑動,那么當OR區域內的數據包陸續到達接收方時,所以沒有空間容納 OR區域的數據包,那么只能將收到的 OR區域內的數據包全部丟掉,也不能再次觸發發送方重傳。最后只能等到重傳超時,然后初始化cWnd,重新開始慢啟動重傳所有的丟包,這樣就會不可避免的造成帶寬利用率下降。
2.3 RTO問題的解決方案DTOR
我們知道,OR區域的數據包是RWnd外的數據包,在Linux內核的設計中,認為收到RW nd外的數據包是無效的,接收方會每收到一個 OR區域的數據包回復發送方一個 SACK,然后丟掉這些數據包。仔細分析接收方收到 OR區域的數據包后回復的這些SACK,會發現這些SACK和收到RWnd內最后一個數據包時回復的SACK完全一樣。因為當
3 實施方案
為了便于對所提出的優化技術和現有的丟失恢復算法進行比較評估,我們對丟失恢復算法進行了模塊化,以便在切換不同的丟失恢復算法時更加方便,不用重新編譯內核。具體來說,我們分別單獨在內核模塊中實現了RH,PRR和QARR三個丟失恢復算法。一般來說,TCP快速恢復模塊內有兩個步驟:進入或者退出快速恢復階段時的初始化,快速恢復階段對每個收到的ACK/SACK的處理。模塊化相比內建模塊是否會帶來額外性能開銷,我們會在第5章給出測試數據說明。
判斷重傳數據包丟失和觸發重傳的關鍵部分偽代碼如下:
Algorithm: DTOR
On each ACK/SACK:
begin
if !(flag and (FLAG_NOT_DUP or FLAG_SND_UNA_ADVANCED收到OR區域內的數據包后,不會帶來RWnd任何的更新。而只要是收到的數據包在 RWnd內,回復的SACK就會有變化。我們正好利用了這一點, 也就是前后SACK完全一樣,然后根據這個條件來判斷重傳的數據包又丟失了,于是觸發發送方重傳數據包,怎么判斷和觸發重傳在第4部分的實施方案會給出偽代碼進行說明。在這個時候重傳的數據包被丟的概率會大大降低,因為根據實驗觀察,等到接受方收到OR區域的數據包后回應的SACK到達發送方時,停留在網絡中的已發送還未被 ACKed/SACKed的數據包已很少,此時網絡并不擁塞。
4 性能評估
為了評測本文提出的優化方法,本文搭建了如圖5所示的測試環境。本文使用模擬環境而不是在真實的網絡環境中測試,原因是在真實環境中無法控制丟包的出現,不便于對比不同算法之間的性能。在配置模擬時,主要涉及往返時間R T T,丟包率/丟包數,帶寬等參數,參數設置主要參考[14,15]。如未特殊提到,參數具體的數值如表1所示。
需要注意的是, 移動網絡的丟包率在不同環境下的差異較大。比如在地鐵內的丟包率要遠遠高于在普通辦公場所內的丟包率。因此在本文的模擬實
or FLAG_DATA_SACKED))
struct sk_buff *_skb = tcp_write_queue_head(sk)
tcp_for_write_queue_from(_skb, sk)
if TCP_SKB_CB(_skb)->seq >= highest sack sequence
break
if TCP_SKB_CB(_skb)->seq & TCPCB_SACKED_ACKED
continue
if !(TCP_SKB_CB(_skb)->sacked & TCPCB_LOST)
lost_out += tcp_skb_pcount(_skb)
TCP_SKB_CB(_skb)->sacked |= TCPCB_LOST
if (TCP_SKB_CB(_skb)->sacked & TCPCB_SACKED_RETRANS)
TCP_SKB_CB(_skb)->sacked &=~TCPCB_SACKED_RETRANS
retrans_out -= tcp_skb_pcount(_skb)
tcp_verify_retransmit_hint(tp, _skb)
end
接收方每收到一個數據包都會返回給發送方一個SACK,每一個SACK都帶有一個標志位flag,這個flag記錄了接收方想要傳達給發送方的信息,比如收到的是否是一個重復數據包,或者是一個重傳的數據包,或者是確認了某個新數據包等。
在本文的方法中,通過flag和Linux內核預設的標志狀態FLAG_NOT_DUP、FLAG_SND_UNA_ADVANCED和FLAG_DATA_SACKED進行與或操作來判斷接收方收到SACK和上一個SACK是否完全一樣。因為數據包是按順序發送的,如果前后SACK是一樣的,那么代表現在接收的是OR區域內的數據包,RW nd區域內的數據包已經發送完,RW nd左邊界的重傳數據包還沒收到,可能已經再次丟失,且不會有新SACK觸發重傳丟失的數據包。驗中,也會對不同丟包率環境下的算法性能進行對比。在圖6中的發送端和接收端使用的是Linux內核3.10版本。發送端的峰值發送速度能達到940Mbps。
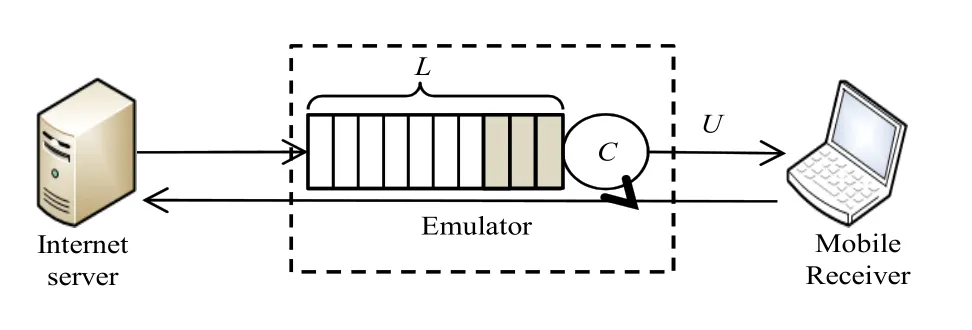
圖5 測試環境Fig.5 Test environment

表1 測試環境中的配置參數Table 1 System parameter used in the testbed
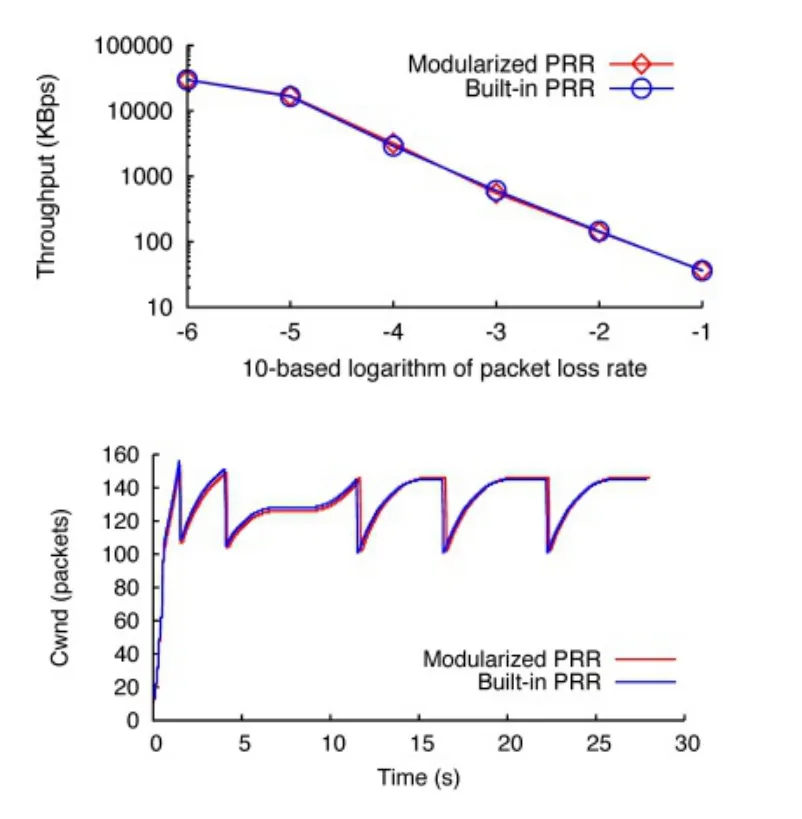
圖6 模塊化算法與內建算法性能對比Fig.6 Pluggable TCP Loss recovery kernel module verification
4.1 模塊驗證
在模擬環境中,本文使用tcpprobe內核模塊在發送端抓取TCP流內部的詳細參數變化,如擁cwnd的變化。在這一節中將驗證TCP快速重傳算法模塊化的正確性和性能開銷。
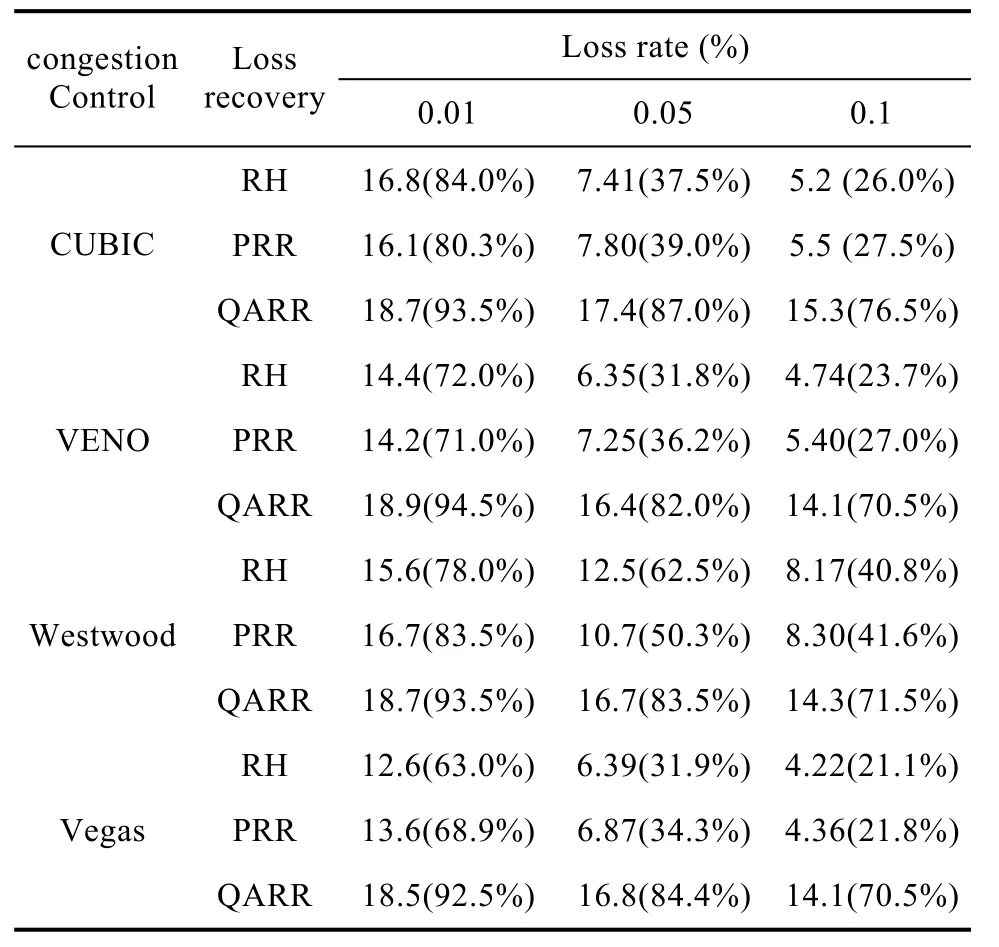
表2 未使用OR算法的帶寬利用率Table 2 Bandwidth utilization with no OR
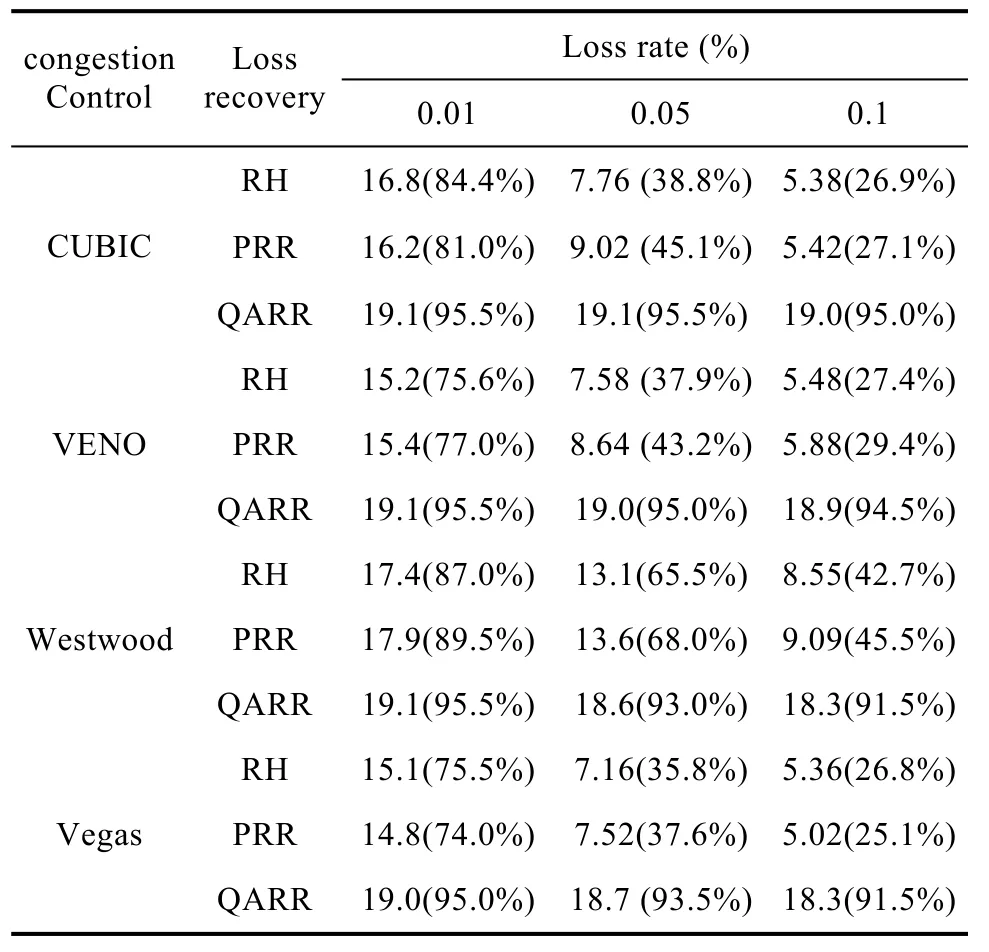
表3 使用OR算法的帶寬利用率Table 3 bandwidth utilization with OR
實驗中選用的擁塞控制算法是CUBIC,快速重傳算法是PRR。這兩個算法均是Linux 3.10中默認的算法。圖 6(左)是在模擬環境中測試一條 TCP流在0.001%至10%丟包率情況下,得到的網絡吞吐率結果。圖6(右)是在TCP流的5個特定時間點進行丟包得到的 cwnd變化圖。可以看到算法模塊化后與內建的算法在性能開銷上沒有太大出入,所以不會引入額外的性能開銷。
這里約定,OR算法和application stall解決方案是捆綁在一起使用的,后面實驗中說的使用 OR算法是指這兩者都使用。
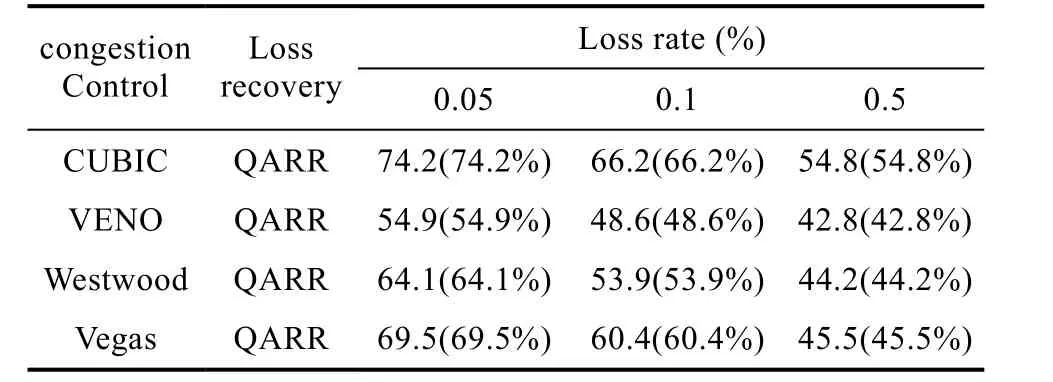
表4 未使用OR算法的帶寬利用率Table 4 bandwidth utilization with no OR
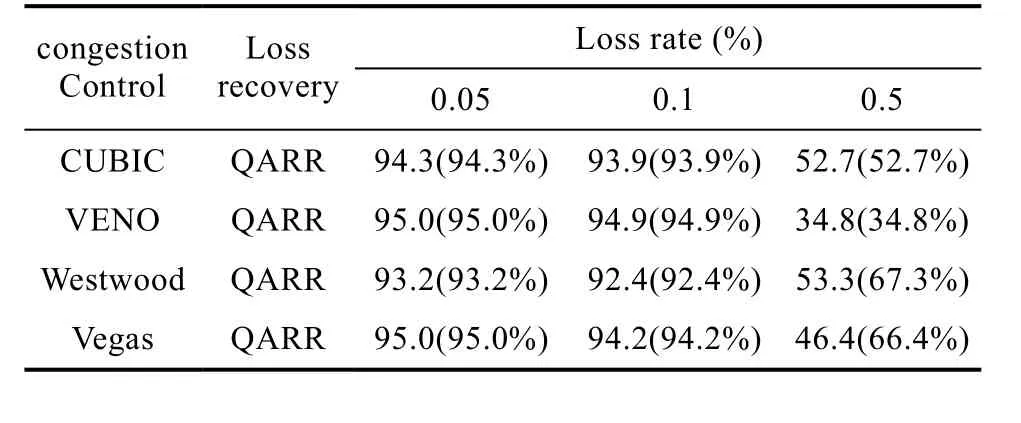
表5 使用OR算法后的帶寬利用率Table 5 bandwidth utilization with OR
4.2 OR算法對TCP性能的提升
實驗測試中,我們首先在不同丟包率下使用了12種 TCP變體組合(擁塞控制算法有 CUBIC,Westwood,Veno和 Vegas,丟失恢復算法有 RH,PRR和QARR)來評估TCP的性能。為什么要這么組合,因為CUBIC是當前Linux內核默認的擁塞控制算法,TCP Westwood和 TCP Veno是專為移動/無線網絡應對非擁塞丟包而設計的,而 TCP Vegas是基于延遲的 TCP擁塞控制算法的代表。RH是Linux Kernel3.2之前的默認丟失恢復算法,而PRR是 Linux kernel 3.2之后的默認丟失恢復算法。QARR被廣泛應用于最近提出的速率控制算法中。
表2中給出了在帶寬為 20Mbps環境下不使用OR算法的測試結果,可以看到,各類擁塞控算法與QARR的組合在三種不同丟包率環境下都要明顯要好于與RH和PRR的組合。因為QARR的CWnd變化只與鏈路排隊長度有關,而不受丟包的影響,而PRR和 RH只要發現丟包都會去降低 CWnd。在移動網絡中,很多丟包都不是因為網絡擁塞,而是一些外部環境導致的,稱為非擁塞丟包。如果是非擁塞丟包,那么就沒有必要減小擁塞窗口 CWnd,只需要重傳那些丟失的數據包即可。這樣可以保證高帶寬利用率,這也是QARR算法比RH和PRR要好的原因。
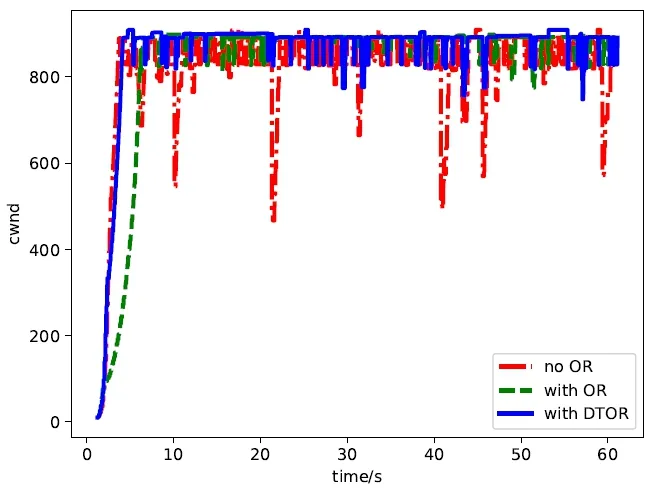
圖7 丟包率=0.05%Fig.7 lost rate=0.05%
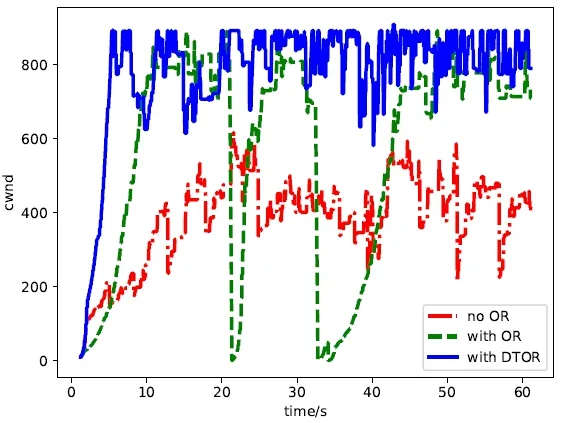
圖8 丟包率=0.5%Fig.8 lost rate=0.5%
接下來我們測量了在帶寬為 20Mbps環境下使用OR算法后的情況,如表3所示,可以看到,各類擁塞控制算法與RH和PRR組合的帶寬利用率并沒有得到改善。因為 OR算法是用來解除流量瓶頸的,而RH和PRR嚴重受非擁塞丟包的影響,受限于擁塞控制瓶頸而不是流量瓶頸,自然加了 OR算法也沒作用。反觀QARR算法使用OR算法后,帶寬利用率明顯得到了提升,因為之前QARR是受到AW nd瓶頸的限制,現在加了OR算法后,AW nd瓶頸不再是限制,當然帶寬利用率會進一步提高。
4.3 頻繁重傳超時對TCP性能的影響
在帶寬為20 Mbps,丟包率為0.1%,往返延遲RTT為100 ms的環境下,在一個RTT內的平均丟包數為0.18個,那么重傳數據包被丟失的概率就會更小,所以RTO問題不明顯。在5.3這部分的測試環境都是在帶寬為100 Mbps環境下,考慮到在移動網絡環境中造成隨機丟包的因素較多,所以將測試環境中的最大丟包率提高到 0.5%(現在 0.5%的丟包率在移動網絡中已經很常見),使重傳數據包多次丟失問題更明顯,這時一個RTT內的丟包數為4.37個,其他參數配置和在帶寬為20 Mbps環境下完全一樣。
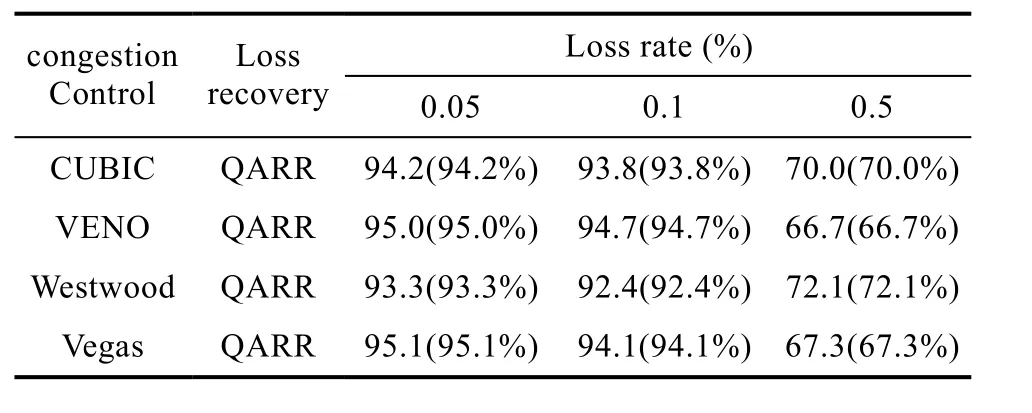
表6 使用DTOR后的帶寬利用率Table 6 bandwidth utilization with no DTOR
因為RH和PRR算法自身的限制,它們的帶寬利用率低不是受限于流量瓶頸,而我們在第3章給出的解決方案是針對解除流量瓶頸后引發頻繁的重傳超時,導致帶寬利用率下降這種情形提出的,所以我們將不再測試各類擁塞控制算法與RH和PRR的組合。
在同樣的丟包率下,網絡帶寬越大,丟包對網絡帶寬利用率造成的損失越明顯,如表4所示,在丟包率為0.05%,網絡帶寬為100Mbps的條件下,CUBIC+QARR的帶寬利用率只有66.2%,相比在帶寬為20Mbps的條件下,帶寬利用率下降了12.8%,VENO+QARR的帶寬利用率下降了27.1%。但只要丟包率不是很高,使用 OR算法后都能保證大幅度的提升帶寬利用率,如表5所示,在丟包率為0.05%和0.1%的條件下,擁塞控制算法與QARR組合的帶寬利用率都達到了90%以上。
當丟包率上升到0.5%時,OR算法的問題就顯現出來了,如表5所示, CUBIC+QARR+OR的帶寬利用率只有 52%左右, VENO+QARR+OR的帶寬利用率甚至下降到了35%,比不使用OR算法還要差。如果不啟用OR算法,TCP受限于流量瓶頸以至于CW nd升不上去,重傳數據包丟失的概率也自然就小了。
4.4 優化技術對TCP性能的影響
在圖 7中,我們給出了在丟包率為0.05%的環境下,分別不使用OR算法、使用OR算法和使用DTOR這三種情況下的CW nd的波動情況。可以看到,在丟包率不顯著的情況下,使用 OR算法沒有導致重傳超時,所以DTOR的表現和OR算法的表現基本一致。再看圖8,此時的丟包率為0.5%,使用OR算法相比不使用OR算法雖然CW nd升上去了,但同時也帶來了RTO問題,而DTOR優化機制既可以保證高吞吐率,又可以避免RTO。
如表6所示,給出了使用DTOR優化技術后的帶寬利用率情況,在丟包率只有0.05%和0.1%時,網絡帶寬利用率都達到了 92%以上,例如 TCP Westwood+QARR在丟包率為0.1%時的帶寬利用率為92.4%, TCP VENO+QARR在丟包率為0.05%和0.1%的環境下,帶寬利用率分別達到了 95%和94.7%。因為重傳包被丟失的概率很小,開啟OR算法后網絡帶寬幾乎被充分利用了,所以使用 DTOR優化技術也沒有多少提升空間。
當丟包率上升到 0.5%時,使用 DTOR后CUBIC+QARR的帶寬利用率上升到了 70%左右,相比不使用DTOR優化技術帶寬利用率提升了20%左右,TCP VENO+QARR的帶寬利用率甚至提升了30%以上。但即便使用 DTOR優化技術消除了 OR優化算法帶來的頻繁重傳超時問題,帶寬利用率也只有70%左右,還有30%的損失。如圖3和圖4所示,因為重傳數據包的多次丟失,導致 OR區域內的大量數據包被TCP接收端丟掉,這些大量被丟棄的數據包也是需要被重傳的,而重傳數據包是不計算在帶寬利用率內的。
5 結束語
通過控制網絡擁塞來保證網絡的高吞吐率、低延遲一直是一個熱點研究領域。在這篇文章中,我們提出了一個優化方法DTOR來解決重傳數據包多次丟失帶來的頻繁重傳超時問題,從而進一步提高網絡帶寬利用率。在后面,我們會繼續針對移動網絡展開更深入的研究。
[1] Mascolo S, Casetti C, Gerla M, et al. TCP westwood: Bandwidth estimation for enhanced transport over wireless links[C]//Proceedings of the 7th annual international conference on Mobile computing and networking. ACM, 2001: 287-297.
[2] Fu, Cheng Peng, and Soung C. Liew. TCP Veno: TCP enhancement for transmission over wireless access networks[C]//IEEE Journal on selected areas in communications, 2003,vol.21(2): 216-228.
[3] Liu K, Lee J Y B. Achieving high throughput and low delay by accurately regulating link queue length over mobile data network[C]//Wireless and Mobile Computing, Networking and Communications (WiMob), 2014 IEEE 10th International Conference on. IEEE, 2014: 562-569.
[4] Leong W K, Xu Y, Leong B, et al. Mitigating egregious ACK delays in cellular data networks by eliminating TCP ACK clocking[C]//Network Protocols (ICNP), 2013 21st IEEE International Conference on. IEEE, 2014: 1-10.
[5] Zha Z, Liu K, Fu B, et al. Optimizing TCP loss recovery performance over mobile data networks[C]//Sensing,Communication, and Networking (SECON), 2015 12th Annual IEEE International Conference on. IEEE, 2015: 471-479.
[6] N. Dukkipati, M. Mathis, Y. Cheng, and M. Ghobadi. Proportional rate reduction for TCP[C]// Proceedings of the 2011 ACM SIGCOMM conference on Internet measurement conference,2011: 155-170.
[7] M. Mathis and J. Mahdavi, “TCP rate-halving with bounding parameters.” Available: http://www.psc.edu/networking/papers/FACKnotes/current/.
[8] Mathis M, Mahdavi J, Floyd S, et al. TCP selective acknowledgment options[R]. Oct 1996.
[9] M. Mathis, J. Mahdavi. Refining TCP Congestion Control[C]//in ACM SIGCOMM Computer Communication Review,1996, vol.26(4):281-291
[10] E. Blanton, M. Allman, K. Fall and L. Wang, “A Conservative Selective Acknowledgment (SACK)-based Loss Recovery Algorithm for TCP,” Request for Comments 3517, 2003.
[11] Liu K, Lee J Y B. Mobile accelerator: A new approach to improve TCP performance in mobile data networks[C]//Wireless Communications and Mobile Computing Conference (IWCMC), 2011 7th International. IEEE, 2011: 2174-2180.
[12] (2015) Centos homepage. [Online]. Available: https://www.centos.org/.[13] Brakmo, Lawrence S., and Larry L. Peterson. "TCP Vegas:End to end congestion avoidance on a global Internet." IEEE Journal on selected Areas in communications, 1995, vol.13(8):1465-1480.
[14] Huang, Junxian, et al. Anatomizing application performance differences on smartphones[C]//Proceedings of the 8th international conference on Mobile systems, applications, and services. ACM, 2010:165-178.
[15] Heikkinen, Mikko VJ, and Arthur W. Berger. Comparison of user traffic characteristics on mobile-access versus fixedaccess networks[C]// International Conference on Passive and Active Network Measurement. Springer Berlin Heidelberg, 2012:32-41.
[16] Ha, Sangtae, Injong Rhee, and Lisong Xu. "CUBIC: a new TCP-friendly high-speed TCP variant." ACM SIGOPS Operating Systems Review, 2008, vol.42(5): 64-74.
[17] K. Liu and J. Y. B. Lee. On Improving TCP Performance in Mobile Data Networks[C]// IEEE Transactions on Mobile Computing, 2016, vol. 15(10): 2522-2536.
[18] S. Hemminger et al., “Network emulation with NetEm,” in Linux Conf Au. Citeseer, April 2005: 18-23.
[19] The netfilter.org: iptables project homepage. [Online].Available: http://www.netfilter.org/projects/iptables/index.html
[20] (2015)2013-2014中國移動互聯網藍皮書. [Online].Available:http://www.dcci.com.cn/media/download/63508a8 b6bbd2a88ab51bd3f3147b19d7e4c.pdf
Research on Retransmission Timeout over Mobile Data Networks
WAN Wen-kai, WANG Hai-tao, JIANG Ying, CHEN Xing
(Faculty of Information Engineering and Automation, Kunming University of Science and Technology, Kunming 650500, China)
Recent advances in high-speed mobile networks have revealed new bottlenecks in ubiquitous TCP protocol deployed in the Internet. First, due to the existence of random bit errors in the mobile network, and TCP protocol can’t effectively distinguish non-congestive loss from congestive loss, resulting in TCP frequently reduce the congestion window, and can’t effectively use the mobile network bandwidth resources. Second, the development of high-speed mobile network makes the bandwidth delay BDP (Bandwidth-Delay Product) to further increase,when the packet loss occurs, TCP protocol flow control will also lead to performance bottlenecks and retransmission timeout. Using the Wireshark tool to capture a large number of tracing for analysis, found the main reason for the retransmission timeout is that the retransmission packet is lost again, and TCP sender can’t find the cause to the loss,so loss packet can’t be retransmitted again by TCP sender, eventually leading to RTO. In response to this problem,Optimization techniques - DTOR (Detect Timeout and Retransmission) can help TCP detect that the retransmitted packet is loss again and triggers TCP sender retransmission again. Using emulated experiments showed that the proposed optimization techniques sufficiently utilize the bandwidth.
TCP; Mobile data network; Retransmission timeout
retransmission packet
TP182
A
10.3969/j.issn.1003-6970.2017.12.006
本文著錄格式:萬文凱,汪海濤,姜瑛. 移動網絡中重傳超時問題的研究[J]. 軟件,2017,38(12):29-36
國家自然科學基金(61462049)
萬文凱(1992-),男,碩士,主要研究方向:數據中心網絡。
汪海濤,副教授,主要研究方向:軟件工程。
