
基于詞向量的微博話題發現方法
2018-01-03 01:54:54李帥彬李亞星馮旭鵬劉利軍黃青松
計算機應用與軟件 2017年12期
李帥彬 李亞星 馮旭鵬 劉利軍 黃青松,2
1(昆明理工大學信息工程與自動化學院 云南 昆明 650500) 2(云南省計算機應用重點實驗室 云南 昆明 650500)
基于詞向量的微博話題發現方法
李帥彬1李亞星1馮旭鵬1劉利軍1黃青松1,2
1(昆明理工大學信息工程與自動化學院 云南 昆明 650500)2(云南省計算機應用重點實驗室 云南 昆明 650500)
針對微博的短文本、口語化和大數據等特性,提出基于詞向量的微博話題發現方法。爬取實驗數據結合中文語料庫訓練得到詞的向量表示,再通過定義的文本詞向量模型得到文本的詞向量表示,相較于傳統的向量空間表示模型,詞向量表示模型能夠解決微博短文本特征稀疏、高維度問題,同時,能夠解決文本語義信息丟失問題;采用改進的Canopy算法對文本進行模糊聚類;對相同Canopy內的數據用K-means算法做精確聚類。實驗結果表明,該方法與經典Single-Pass聚類算法相比,話題發現綜合指標提高4%,證明了所提方法的有效性和準確性。
話題發現 詞向量 短文本 Canopy聚類
0 引 言
2015年中國社交應用用戶行為研究報告指出:綜合社交媒體中新浪微博的使用率高達43.5%[1]。微博的短文本性、即時性和交互性等優點獲得了大批忠實粉絲,但微博提供信息傳播途徑的同時,也為不良信息、謠言甚至惡意攻擊話題提供了傳播渠道。因此及時發現微博熱點話題并監管,對政府部門輿情引導具有重要意義[2-3],同時,還可以服務于企業戰略決策和廣告精準營銷。但微博短文本、口語化、大數據量等特性給話題發現帶來極大的困難。
話題發現研究主要集中于基于文本的聚類算法和基于概率的話題模型。傳統聚類算法中文本多采用向量空間模型表示[4]。向量空間模型表示的文本存在稀疏性和高維度缺點,且高維度的向量不利于計算;另一個缺點是忽略詞之間的語義關系。例如,文獻[5-6]采用向量空間模型結合Single-Pass聚類算法來對短文本進行會話抽取和話題檢測。Single-Pass算法思想為按順序讀取數據,每次處理一個數據,根據新數據與已有類的相似度,將該數據判斷為已有類或者單獨成為新的類,這樣可以實現數據的增量聚類,但該算法依賴數據的次序,且用于短文本聚類時特征稀疏。針對特征稀疏性,文獻[7]用維基百科來擴充特征,還有的文獻用搜索引擎來輔助特征的選擇。第一種方法對知識庫完備性要求比較高。第二種方法依賴于搜索引擎的結果并且搜索海量的特征需要消耗大量的時間。LDA模型是基于概率的話題模型的代表。文獻[8-9]用LDA模型發現話題和追蹤話題,朱雪梅等[10]指出LDA可以一定程度解決語義丟失問題。但單斌等[11]LDA話題模型綜述中指出LDA模型雖能夠自動獲取海量文本信息的主題或話題,但大多數基于LDA的話題演化方法都假定話題數目是固定的。陳福等[12]指出新浪微博這樣的短文本在線網絡,直接用LDA進行語義獲取具有一定的局限性,同時指出對微博這樣的在線短文本,基于內容的比較和關鍵詞語義識別非常重要。駱衛華等[13]提出了分治多層聚類話題發現算法,基于分治策略解決大規模數據集問題。缺點是采用傳統的向量空間模型表示文本,詞語語義相似性考慮不足。路榮等[14]通過挖掘短文本的隱主題解決稀疏性問題,然后用一種兩層的K均值和層次聚類混合聚類方法解決大規模數據問題,但具體幾篇微博能將一個新聞事件完整表示出來有待驗證。McCallun A[15]等提出兩層聚類方法,解決高維度大數據量問題。但方法中劃分Canopy時,每次隨機選擇一個種子文檔,導致兩個問題:劃分容易先形成規模大的Canopy,影響后面話題精確聚類的效率;初始種子選擇不當,導致迭代次數和冗余度增加。陳強等[16]基于Canopy算法基礎上提出K-Canopy算法。但其采用傳統的信息檢索技術將文本轉換為一組加權的特征值構成的向量,導致高維度向量,增加空間消耗,不利于計算;劃分簇時采用漢明距離比較文本相似度,雖然能夠提高效率,但精度難以保證。
Hinton等[17]首先提出詞向量的概念,詞向量的基本思想是利用詞的上下文信息,用固定維數的實數來表示詞,通過詞間相似性表示詞間的語義信息。詞向量自提出受到各國學者關注,2003年Bengio提出三層神經網絡構建語言模型,根據上下文信息預測下一個詞,2013年Mikolov提出并開源了Word2Vec[18]模型。詞向量已經用于微博的情感分析[19]、微博采集和個性化推薦[20]。文獻[21]中用詞向量來對搜索詞進行主題分類、聚類來挖掘搜索意圖和興趣。已有文獻充分表明詞向量能夠解決維度災難和特征稀疏性問題,并且能夠結合上下信息,防止語義信息丟失。
綜上所述:本文提出一種基于詞向量的微博話題發現方法VCK(Vector Canopy&K-means),方法有效解決短文本、口語化等特性造成的維度災難、特征稀疏和語義鴻溝問題。該方法定義微博的詞向量表示模型,然后利用改進的Canopy算法對數據做初始簇聚類,獲得聚類中心個數和中心向量。最后利用K-means算法做精確聚類。
1 基于詞向量的話題發現方法
本文方法主要工作包括微博文本的詞向量表示、Canopy算法初始簇聚類。任務的流程如圖1所示。首先模擬登錄新浪微博爬取數據,數據除了包括微博內容,還包括發微博的微博賬號等級、粉絲數、所發微博的轉發數和評論數;然后,對文本做預處理、計算微博的權重和微博的詞向量表示;其次,利用改進的Canopy算法對詞向量表示的微博文本進行模糊簇聚類;最后,根據Canopy算法得到的簇個數和簇的中心初始化K-means算法的聚類數目和初始中心,進而做精確聚類。
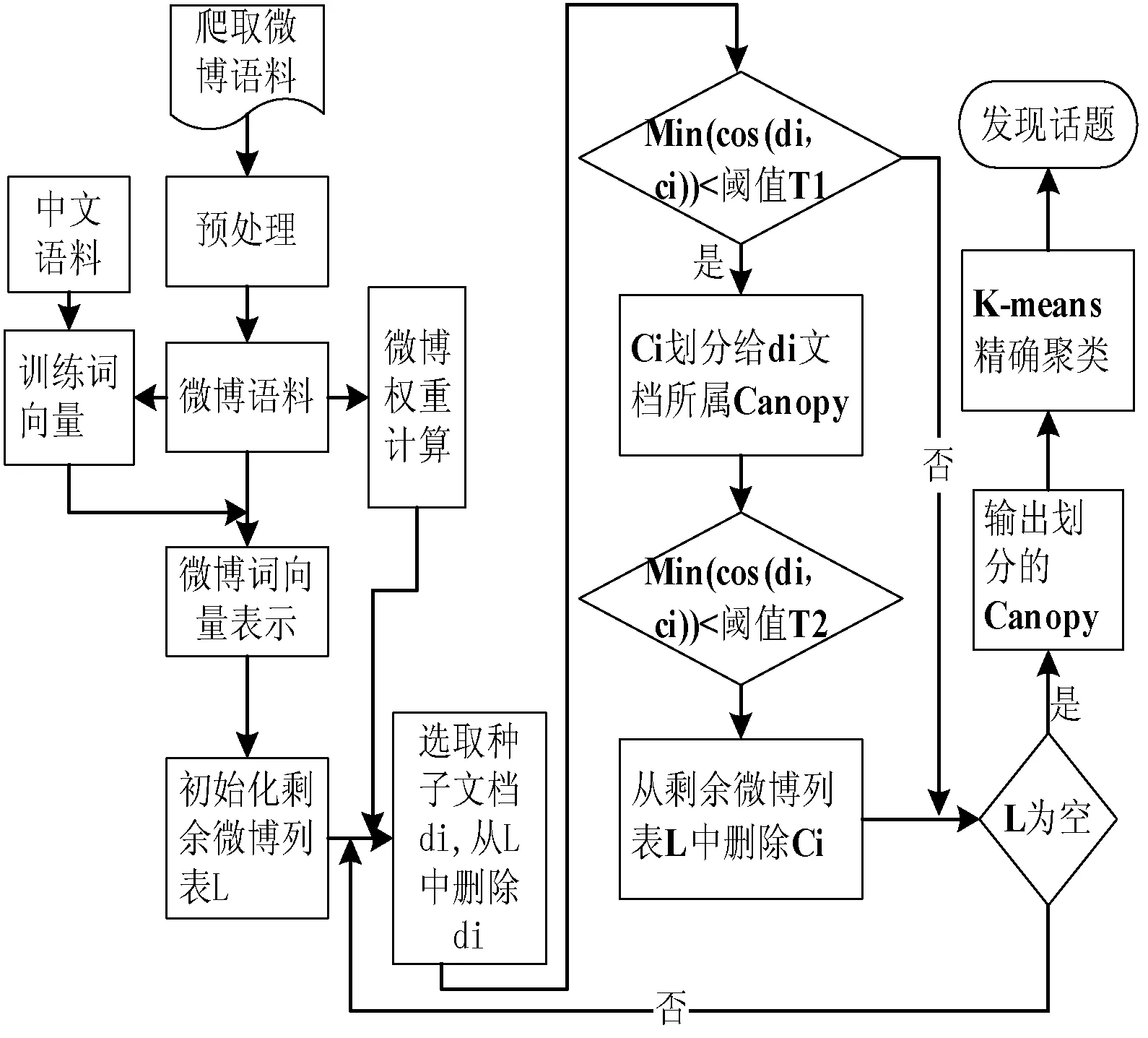
圖1 VCK流程圖
因為Canopy算法粗聚類之后造成各簇之間有數據重疊,所以利用K-means算法在同一個Canopy簇中再做精確聚類,同時,Canopy算法得到的簇中心和簇數目有效地解決了K-means算法依賴初始中心和聚類數目選擇的問題。
1.1 微博的詞向量表示
爬取的微博語料內容含有很多無意義詞語和符號,為了提高實驗的效率和精度需要做一些預處理工作,具體在實驗環節介紹。為了方便理解,先給出文中用到的一些定義。
定義1(詞的向量表示)W={d1,d2,…,dn}:其中n表示詞的向量維度,每個詞的維度相同,di表示詞對應i維上的值。
定義2(微博的詞集合表示)S={w1,w2,…,wm}:其中m表示文本中詞的個數,不同文本含有的詞的個數不一定相同,wi表示文中第i個詞。
Mikolov等[18]在文中指出,詞向量的學習不僅僅能夠學習到其語法特征,還能夠利用向量加減的方式進行語義上面的計算。根據此得出如下定義。
定義3(微博的詞向量表示)D={x1,x2,…,xn}:其中n和定義1中詞的維度相同,表示文本的詞向量的維度,xi表示文本向量第i為上的值。xi由如下公式計算得到:
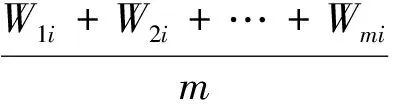
(1)
式中:m和定義2中文本含有詞的個數相同,表示文本中詞的數量,Wmi表示文本中第m個詞對應的詞向量中第i維的值。
定義4(簇Canopy的中心向量)Center={y1,y2,…,yn} 其中n表示中心向量的維度,大小與定義3和定義1中的維度相同,yi表示向量第i維上對應的實數值。yi由如下公式計算得到:

(2)
式中:t表示Canopy算法得到的每個初始簇聚類中文本的數目,Dti表示Canopy中第t個文本的向量中第i維值。
1.2 微博的權重計算
不同的微博對話題的影響力和傳播力不同,本文用微博的權重衡量微博的話題影響力。微博D的權重Q計算方法如下:
Q=Weight×(TRi+LRi+CRi)
(3)
式中:Weight是根據微博用戶特征定義的權值,微博用戶分為加V認證用戶和非認證用戶。王國華等[22]指出熱門微博發布主體中加V用戶比例高達72.3%,同時指出加V認證或粉絲數較多的用戶在微博的話題傳播過程中起到巨大的推動作用。
(4)
其中:P為認證用戶取值,Q為非認證用戶取值。
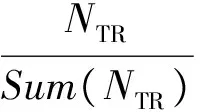
(5)
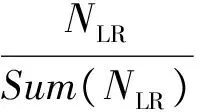
(6)
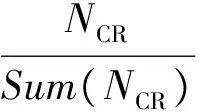
(7)
其中:NTR、NLR、NCR分別表示每條微博的轉發數、點贊數和評論數,Sum(NTR)、Sum(NLR) 、Sum(NCR)分別表示所有微博的轉發數之和、點贊數之和和評論數之和。
1.3 基于改進的Canopy算法的粗聚類
1.3.1 Canopy算法簡介
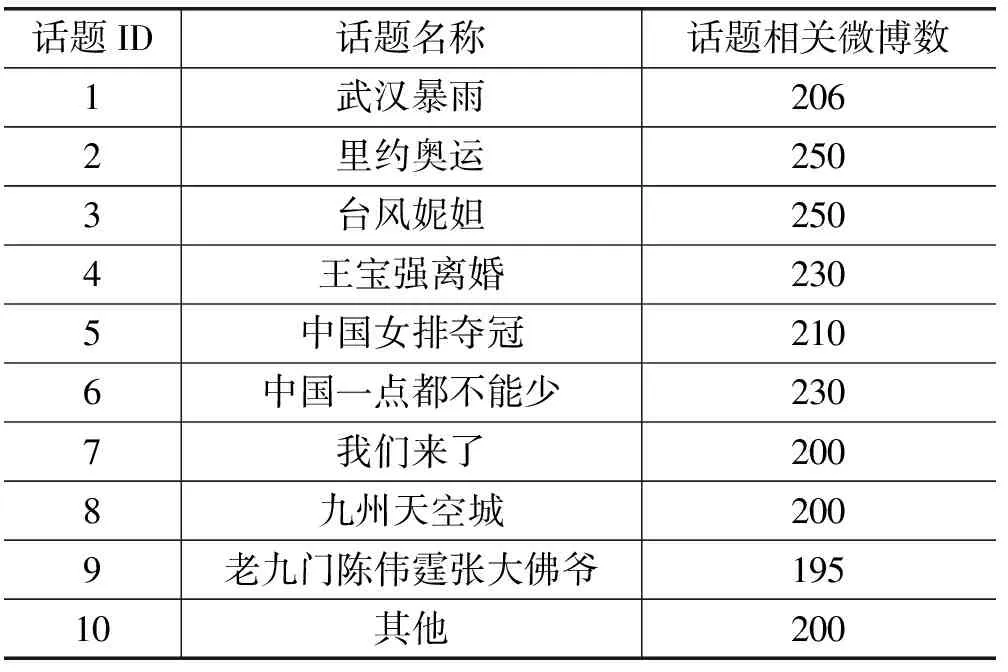
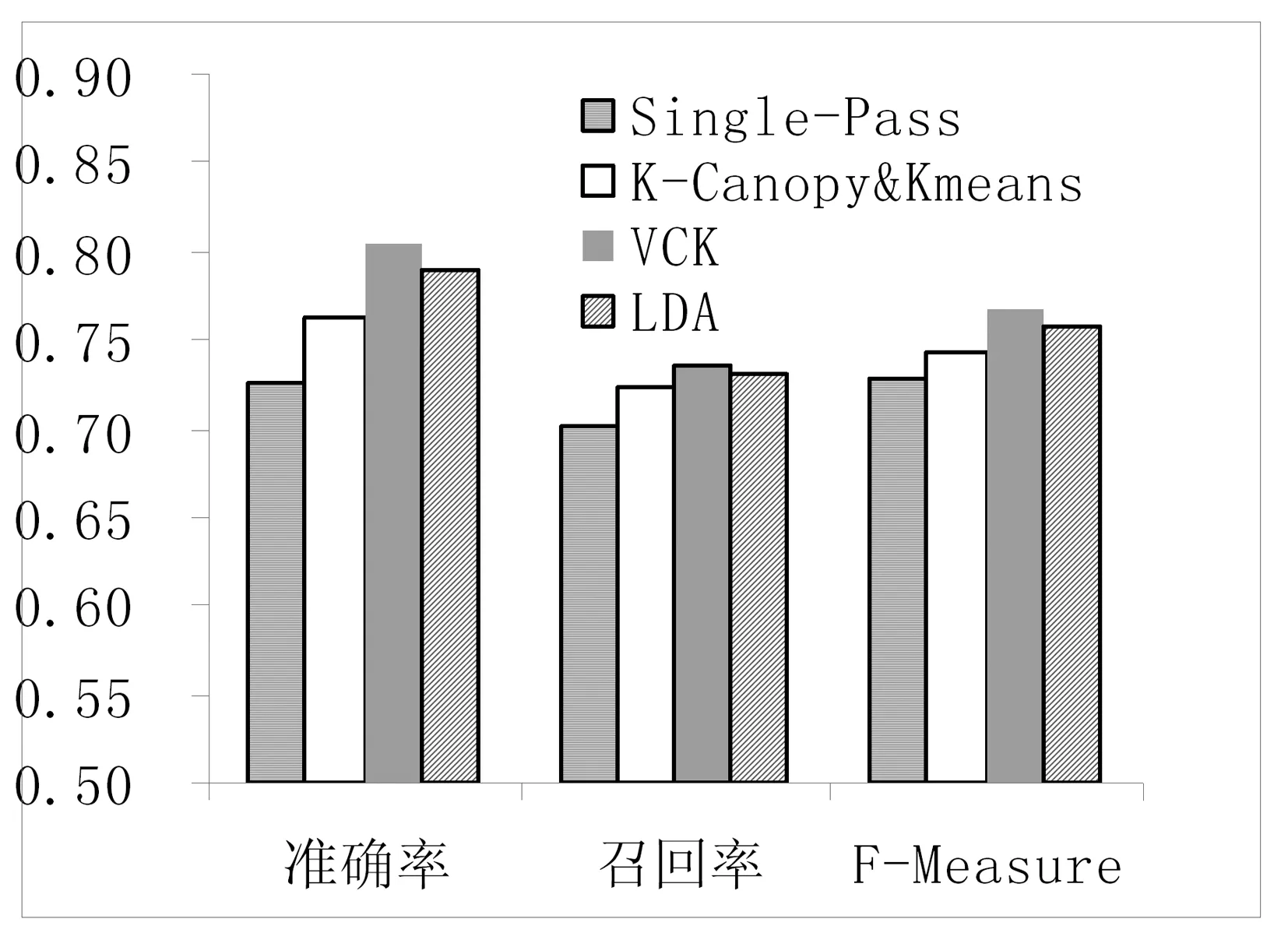
MaCallum A等[15]提出了一種適用高維度和大數據量的聚類算法。算法把數據劃分成相互重疊的簇,最后利用傳統聚類(Kmean、EM)算法對同一簇的文檔做精確聚類。劃分簇時定義兩個閾值T1和T2(T2 圖2 Canopy算法劃分結果 1.3.2 改進的Canopy算法 劃分簇過程中文本相似度的計算是關鍵,相似度計算越精確,劃分得到的簇越符合實際生活中話題文本的真實聚集情況。計算精度高低同時決定算法的迭代次數。本文試圖提高算法的計算精度來提高劃分的精度,進而計算出更符合實際情況聚類,有利于提高話題發現的準確率和速度。 本文主要從以下方面來提高計算精度:1) 微博文本向量用定義3表示。文本的詞向量表示充分考慮了上下文語義相似性,使文本相似性計算隱射到語義層面,用以解決向量空間模型中特征詞孤立和語義鴻溝問題,同時,詞向量的低維度特性能夠減少計算量,降低空間消耗,提高計算速度等。2) 根據式(3)微博權重Q選取種子文檔。高權重的微博文本話題完整,內容真實客觀,影響力大,用以解決隨機選擇種子文檔帶來的迭代次數和冗余度增加問題。3) 余弦距離公式計算相似度。余弦距離計算兩個向量的夾角余弦,傾向于對向量內容的比較,而對絕對的數值不敏感,修正了可能存在的度量標準不統一問題,優于漢明距離公式。本文從上述方面來提高了文本間相似性計算的精確度,使得話題相似文檔更容易落入T2子集中,降低了數據冗余度,減少了迭代次數,提高了計算效率和準確率。改進的算法流程如下: 算法1改進的Canopy算法 輸入:剩余文檔集L,閾值T1、T2。 輸出:Canopy簇集合,各Canopy的中心向量。 1.Cluster_Canopy(L ,T2,T1){ 2.SL=Sort(L)//權重排序微博隊列L,SL排序后的微博 //文本列表 3.While(SL!=NULL){ //循環直至SL為空 5.Dseed =SL.get();//根據權重獲得種子文檔 6.Cluster.add(Dseed);//將種子文檔作為新的Canopy簇 //中心,Cluster表示聚類簇 7.從剩余文檔集隊列SL中刪除文檔Dseed 8.for(C: SL){ 9. dist=cos(Dseed,C); 10. if(dist 11. 文檔C加入Dseed所在Canopy的簇中。 12. if(dist 13. 從剩余文檔隊列SL中刪除C文檔,C不能作為種子文檔,即C不能作為新Canopy簇中心 14.} }}//for end 15.得到簇Cluster加入Canopy簇集合隊列CanopyClusters中 16.}//while end 17. for(Cluster : CanopyClusters){ 18. 利用定義4獲得Canopy簇的中心向量 19. 將中心向量加入中心向量隊列centerClusters中} //for end 20. k=CanopyClusters.size()//獲得中心向量的個數} 算法中文本間距離采用余弦距離公式,通過上節文檔的詞向量表示,得到文本的詞向量表示,如文本D1{x1,x2,…,xn},D2{x1,x2,…,xn},則距離計算公式如下: (8) 2.1 實驗語料和預處理 微博話題發現沒有標準的測試集,本實驗采用的語料是從新浪微博2016年7月到2016年8月間采集的熱點話題微博,通過人工標注得到10個話題,具體語料如表1所示。 表1 實驗數據 預處理包括:去除特殊符號、去除停用詞、分詞。爬取的微博內容含有很多對內容沒有意義的符號和詞,如特殊符號#、@、表情符號、鏈接、“的”、“了”等停用詞。分詞后少于3個詞的文本對話題信息表達不完善,故刪除此類文本。最后,獲得干凈的、具有意義和信息完善的語料。 本文用Word2Vec工具的CBOW模型得到定義1定義的詞向量。然后,用定義3得到文本的詞向量表示。 2.2 實驗評價標準 對于簇聚類的評價標準采用文獻[16]中聚類準確度、類內凝聚度、類間分離度來衡量切分準確度和質量,具體定義如下: (9) (10) 式中:CorrectNum表示該Canopy中包含最多文檔類別的文檔數,TotalDocs表示該Canopy包含的文檔數。式(9)表征Canopy的純度。 (11) (12) 式(11)計算的是類內凝聚度,num是Canopy的數量,size是第i個Canopy所包含的文檔數量,center是定義4中Canopy的中心向量,Dist是計算文檔Doc和center之間的距離,類內凝聚度越高說明切分質量越好;式(12)計算類間分離度,該值越小,說明切分質量越好。 對于話題發現采用準確率(P)、召回率(R)和F-Measure值作為評價標準。 準確率: (13) 召回率: (14) F-Measure: (15) 式中:A表示已檢測到與話題相關的微博數,B表示已檢測到與話題不想關的微博數,C表示未檢測到與話題相關的微博數。 2.3 實驗結果及分析 2.3.1 傳統Canopy算法、K-Canopy算法與VectorCanopy算法的對比實驗 為了說明VectorCanopy(V-Canopy)算法的有效性,通過比較相同參數條件下算法的各項指標來說明。算法參數中,當T2較大時,Canopy個數比較少;相反T2較小時,Canopy個數較多。當T1較小時,Canopy的大小相對較小;相反T1較大時,Canopy的大小相對較大,數據冗余度較嚴重。本文更關注數據切分的準確性和切分的質量,但對于數據切分的速度允許一定的損失,因為數據切分的質量決定后期話題發現的準確度和速度,從而影響話題發現相關商業活動的有效性和投資回報率等。如微博廣告精準投放對話題的質量要求越高越好。實驗采用文獻[16]參數指標作為實驗中參數的值,即T1=0.05,T2=0.03。實驗結果見表2。 表2 Canopy、K-Canopy和V-Canopy算法數據劃分實驗結果對比 通過對比實驗可以發現,在相同的參數的情況下,K-Canopy比傳統的Canopy算法的準確度提高了約5%,類內凝聚度提高了約11%,類間分離度減低了約13%。V-Canopy 與K-Canopy相比,精確度提高了約4%,類內凝聚度和類間分離度也較好。但是實驗發現,K-Canopy算法的速度優于V-Canopy算法,因為V-Canopy算法采用相似余弦距離公式,精度提高了,但效率降低。 為了說明文本的詞向量表示和余弦距離公式的有效性,通過比較V-Canopy算法下分別采用傳統向量空間表示文本、傳統快速距離公式即詞的共現占比和采用詞向量空間模型和余弦距離公式的各項指標來說明。實驗中的參數同上。實驗結果見表3所示。 表3 Canopy、VeCanopy、CosCanopy和V-Canopy算法劃分數據實驗結果對比 通過對比實驗可以發現,VeCanopy算法的精確度、類內凝聚度和類間分離度指標優于傳統的向量空間表示文本,因為詞向量考慮了上下文語義的相似性,提高了文相似度。CosCanopy算法的精確度、類內凝聚度和類間分離度指標優于Canopy算法,但相對于VeCanopy略顯不足,因為向量空間模型的缺點降低了余弦距離公式相似度比較的精度。V-Canopy算法的各項指標都優于單獨采用詞向量表示或余弦距離公式算法。 2.3.2 話題發現上實驗結果對比 為了比較本文話題發現的可行性和優良性,VCK算法得到的結果與K-Canopy&Kmeans算法、Single-Pass算法和LDA算法比較,LDA和single-pass采用傳統的向量空間模型和余弦距離,K-Canopy采用傳統的向量空間模型,VCK采用詞向量模型和余弦距離模型。實驗結果見圖3。 圖3 四種方法的比較 實驗結果表明, VCK算法的綜合指標比K-Canopy高約3%,比Single-Pass高約4%,比LDA高約2%。充分說明了采用詞向量表示模型和余弦距離能夠提高話題發現的精度,說明了詞向量能夠結合語義提高文本間語義相似度,從而提高聚類的準確性。 在以上實驗基礎上,隨機抓取3萬條微博做測試,V-Canopy的準確率達到58%,VCK算法準確率達到80%,驗證了方法的有效性和合理性。 本文提出了基于詞向量的微博話題發現方法,針對微博文本短、特征稀疏、數據量大的特點,用詞向量表示文本。與傳統方法相比,有效地解決了文本向量高維度、稀疏性問題。同時,詞向量模型是通過一個詞所在上下文的詞來推測這個詞向量中的維度值,所以相對于傳統方法能夠很好地解決語義信息丟失的問題。然后,采用改進的Canopy算法對文本做模糊簇聚類。最后,Canopy的個數作為Kmeans初始中心個數,對相同的Canopy內的數據做精確聚類。實驗結果表明,該方法的精確度優于K-Canopy&Kmeans方法。 本文的方法中Canopy簇聚類采用余弦距離,與K-Canopy方法中的漢明距離相比,計算效率降低,后續工作考慮采用Hadoop[23]平臺增加計算并發性來提高效率。 [1] 中國互聯網信息中心(CNNIC).2015年中國社交應用用戶行為研究報告[R].http://www.cnnic.net.cn/hlwfzyj/hlwxzbg/sqbg/201604/t20160408_53518/P0201607225514 29454480.pdf. [2] 蒙祖強,黃柏雄.一種新的網絡熱點話題提取方法[J].小型微型計算機系統,2013,34(4):743-748. [3] 何躍,帥馬戀,馮韻.中文微博熱點話題挖掘研究[J].統計與信息論壇,2014(6):86-90. [4] Salton G,Wong A,Yang C S.A vector space model for automatic indexing[J].Communications of the ACM,1975,18(11):613-620. [5] 黃九鳴,吳泉源,劉春陽,等.短文本信息流的無監督會話抽取技術[J].軟件學報,2012,23(4):735-747. [6] Yang Y,Pierce T,Carbonell J.A study of retrospective and on-line event detection[C]//Proceedings of the 21st annual international ACM SIGIR conference on Research and development in information retrieval.ACM,1998:28-36. [7] 葉成緒,楊萍,劉少鵬.基于主題詞的微博熱點話題發現[J].計算機應用與軟件,2016,33(2):46-50. [8] 張曉艷,王挺,梁曉波.LDA模型在話題追蹤中的應用[J].計算機科學,2011,38(10A):136-139. [9] 張晨逸,孫建伶,丁軼群.基于MB-LDA模型的微博主題挖掘[J].計算機研究與發展,2011,48(10):1795-1802. [10] 朱雪梅.基于Word2Vec主題提取的微博推薦[D].北京理工大學,2014. [11] 單斌,李芳.基于LDA話題演化研究方法綜述[J].中文信息學報,2010,24(6):43-49. [12] 陳福,林闖,薛超,等.短句語義向量計算方法[J].通信學報,2016,37(2):11-19. [13] 駱衛華,于滿泉,許洪波,等.基于多策略優化的分治多層聚類算法的話題發現研究[J].中文信息學報,2006,20(1):29-36. [14] 路榮,項亮,劉明榮,等.基于隱主題分析和文本聚類的微博客新聞話題發現研究[C]//全國信息檢索學術會議,2010. [15] McCallum A,Nigam K,Ungar L H.Efficient clustering of high-dimensional data sets with application to reference matching[C]//Proceedings of the sixth ACM SIGKDD international conference on Knowledge discovery and data mining.ACM,2000:169-178. [16] 陳強,杜攀,陳海強,等.K-Canopy:一種面向話題發現的快速數據切分算法[J].山東大學學報(理學版),2016,51(9):106-112. [17] Hinton G E.Learning distributed representations of concepts[C]//Proceedings of the eighth annual conference of the cognitive science society,1986:1-12. [18] Mikolov T,Chen K,Corrado G,et al.Efficient Estimation of Word Representations in Vector Space[J].Computer Science,2013. [19] Socher R,Perelygin A,Wu J Y,et al.Recursive deep models for semantic compositionality over a sentiment treebank[C]//Deep Models for Semantic Compositionality Over a Sentiment Treebank.Conference on Empirical Methods in Natural Language Processing (EMNLP 2013),2013. [20] 俞忻峰.新浪微博的數據采集和推薦方案研究[D].南京理工大學,2015. [21] 楊河彬.基于詞向量的搜索詞分類、聚類研究[D].華東師范大學,2015. [22] 王國華,鄭全海,王雅蕾,等.新浪熱門微博的特征及用戶轉發規律研究[J].情報雜志,2014(4):117-121. [23] 趙慶.基于Hadoop平臺下的Canopy-Kmeans高效算法[J].電子科技,2014,27(2):29-31. MICROBLOGGINGTOPICDETECTIONBASEDONTHEWORDDISTRIBUTEDREPRESENTATION Li Shuaibin1Li Yaxing1Feng Xupeng1Liu Lijun1Huang Qingsong1,2 1(FacultyofInformationEngineeringandAutomation,KunmingUniversityofScienceandTechnology,Kunming650500,Yunnan,China)2(YunnanKeyLaboratoryofComputerTechnologyApplications,Kunming650500,Yunnan,China) Aiming at the characteristics of microblogging short text, colloquialization and big data, a new method based on the distributed representation is proposed. We crawled the experimental data combined with the Chinese corpus training to get the vector representation of the word.Then we got the word vector representation of the text by defining the text word vector model.Compared with the traditional vector space representation model,the word vector representation model can solve the sparse and high dimensional problem of microblog short text,and can solve the problem of text semantic information loss.We used the improved Canopy algorithm to fuzzy text clustering,and the data in the same Canopy were clustered by the K-means algorithm. Experiments showed that the comprehensive index of the proposed method’s increased 4% compared with the Single-Pass algorithm. The experimental results proved the validity and accuracy of the proposed method. Topic detection Word distributed representation Short text Canopy cluster 2017-02-01。國家自然科學基金項目(81360230,81560296)。李帥彬,碩士生,主研領域:機器學習,自然語言處理。李亞星,碩士生。馮旭鵬,碩士。劉利軍,講師。黃青松,教授。 TP3 A 10.3969/j.issn.1000-386x.2017.12.009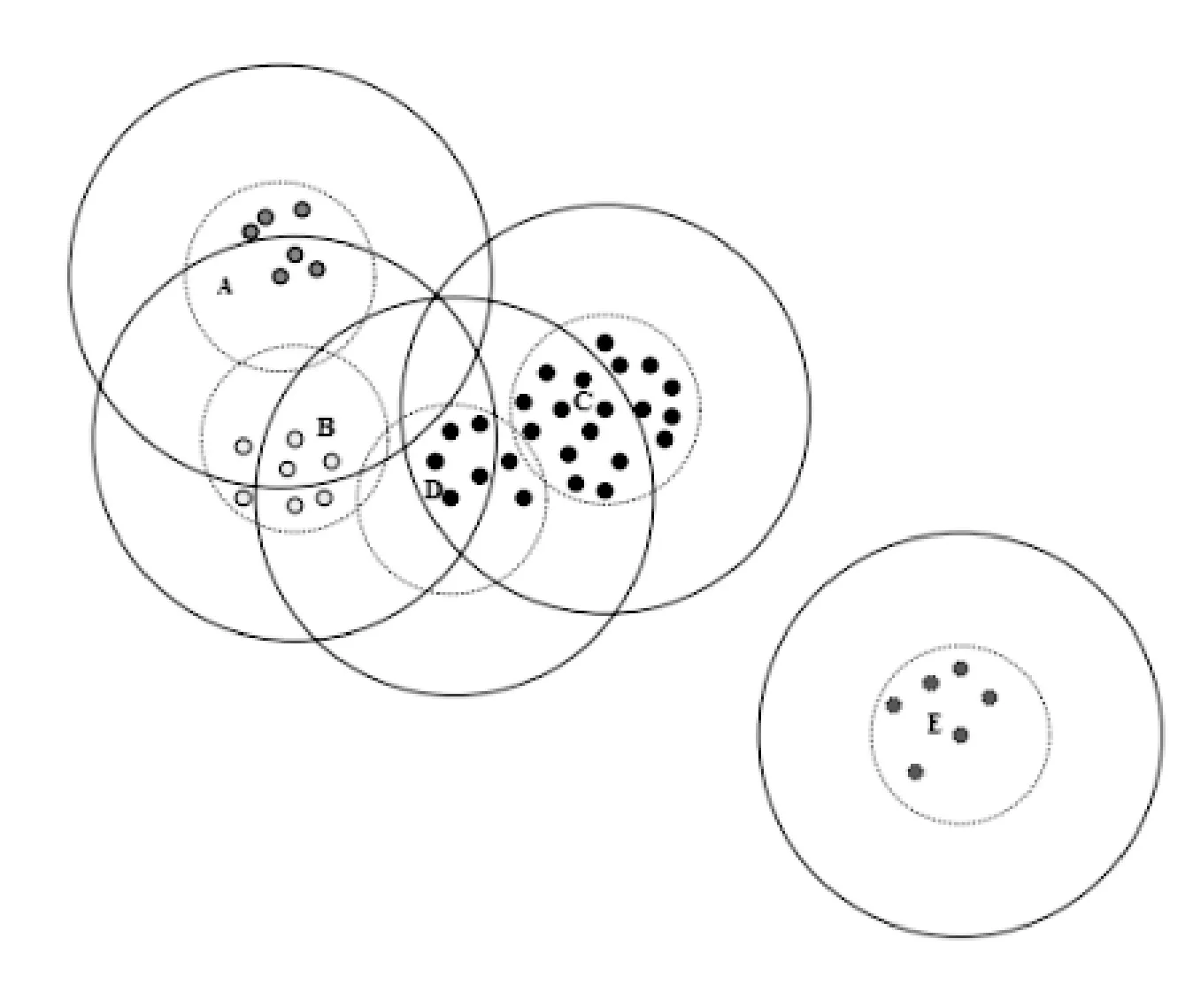
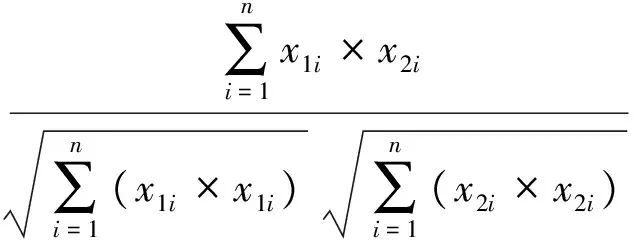
2 實驗及結果分析


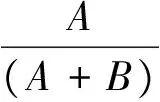
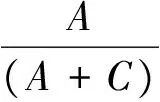
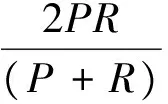

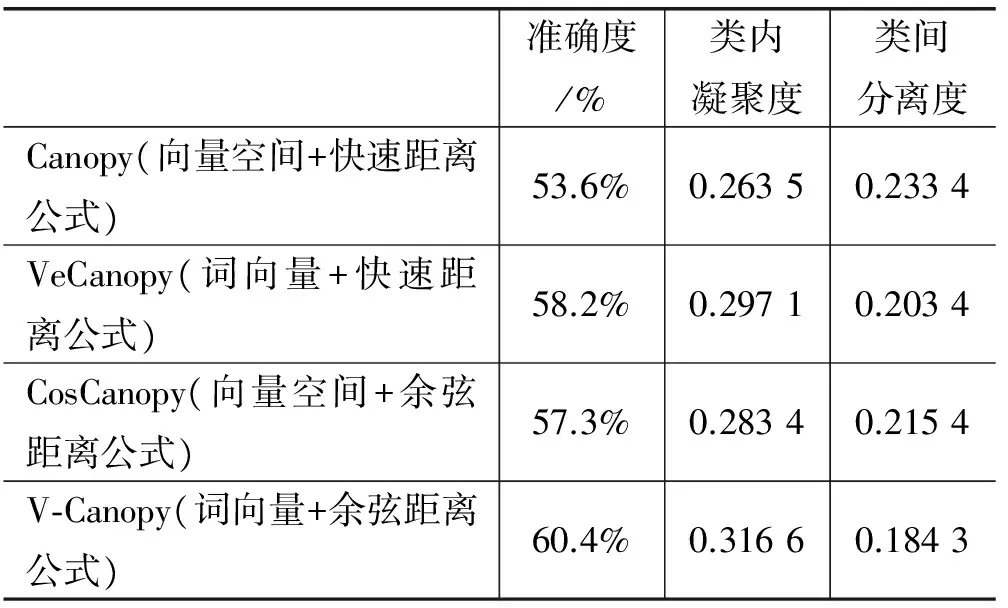
3 結 語
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42開放教育研究(2020年2期)2020-03-31 01:54:14制造技術與機床(2019年10期)2019-10-26 02:48:08小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50電子制作(2018年18期)2018-11-14 01:48:06發明與創新(2016年38期)2016-08-22 03:02:52太空探索(2016年5期)2016-07-12 15:17:55現代語文(2016年21期)2016-05-25 13:13:44小學教學參考(2015年20期)2016-01-15 08:44:38大連民族大學學報(2015年2期)2015-02-27 08:28:11
