小范圍BGP路由異常特征分析
2018-01-05 10:06:48陸岳昆張沛李丹丹馬嚴
中國教育網(wǎng)絡(luò) 2017年11期
關(guān)鍵詞:特征
文/陸岳昆 張沛 李丹丹 馬嚴
針對BGP網(wǎng)絡(luò)中頻發(fā)的小規(guī)模路由異常問題,本文研究小規(guī)模BGP路由異常的特征規(guī)律,并利用Spark和Hadoop的高性能存儲與計算能力,設(shè)計一套包括UPDATE采集、事件采集、UPDATE存儲、特征計算模塊的BGP異常特征分析系統(tǒng)。基于此系統(tǒng),討論8種BGP異常特征定義以及其計算方法,分析路由劫持和路由泄露這兩類異常發(fā)生時的特征表現(xiàn),進而分析各個特征對異常檢測與分類的顯著性和差異性,對于今后小范圍BGP異常的檢測與分類具有參考價值。
小范圍BGP路由異常特征分析
文/陸岳昆 張沛 李丹丹 馬嚴
BGP域間路由異常事件包括攻擊、配置錯誤、大規(guī)模電源故障。這些異常導致錯誤的或無法控制的路由行為,影響了全局路由基礎(chǔ)架構(gòu)。最常見的兩種BGP路由異常是路由劫持和路由泄露。有統(tǒng)計顯示,大約20%的路由劫持和路由泄露持續(xù)不超過10分鐘,但是卻能在2分鐘內(nèi)影響到90%的互聯(lián)網(wǎng)。
目前,已經(jīng)有學者對BGP異常的特征進行了研究,并應(yīng)用到了模式識別和機器學習方法上,取得了不錯的成效。但是這些研究也存在著一些的缺陷:
1.目前的BGP異常特征研究集中在描述大范圍異常特征表現(xiàn),但是小規(guī)模異常特征研究較少。小規(guī)模異常相對不容易被察覺,但是其發(fā)生的頻率更高。這類小規(guī)模的異常事件,除了持續(xù)時間短之外,還有只影響某個特定IP地址前綴,受影響的IP數(shù)量較少的特點。
2.樣本之間的相關(guān)性過強。若來自同一異常事件的樣本具有較強的相關(guān)性,可能導致特征中的偶然因素被放大。
3.不同異常發(fā)生的原因是不相同的,研究過程中應(yīng)該按照異常類型區(qū)別對待。路由劫持是一種攻擊方式,由某個AS非法地宣告IP地址前綴造成。而路由泄露往往是由于配置錯誤,導致路由轉(zhuǎn)發(fā)策略違反了商業(yè)關(guān)系。不同的異常類型可能在特征上有不同的表現(xiàn)。不同類型的異常被簡單的歸為一類是不合適的。
鑒于以上對于BGP異常特征研究的缺陷,本文著重研究了小范圍的BGP路由異常事件的特征表現(xiàn)。為了解決樣本相關(guān)性較強的問題,本文從BGP Stream項目中選取了上百個小規(guī)模的路由劫持和路由泄露事件作為樣本,保證了樣本之間的獨立性。這些異常事件有著確定的受影響的IP地址前綴和發(fā)生時間,通過RIPE項目的BGP UPDATE報文,可以回溯出這些異常事件的特征值。同時為了突出不同異常的特征表現(xiàn),在研究過程中對特征的異常類型進行了區(qū)分。在此基礎(chǔ)上,考察了8個BGP異常特征,使用基于Spark和Hadoop的系統(tǒng)架構(gòu)完成研究。最終,北京郵電大學得到了若干小范圍BGP路由異常的特征規(guī)律和結(jié)論。這些規(guī)律和結(jié)論將有助于未來小范圍BGP異常的檢測和分類。
系統(tǒng)架構(gòu)
系統(tǒng)分為RIPE路由器、UPDATE采集、UPDATE存儲、BGP Stream事件源、事件采集、特征計算六個功能模塊。
RIPE 路由器:RIPE(Regional Internet Registry for Europe)是歐洲、中東和中亞部分地區(qū)互聯(lián)網(wǎng)注冊機構(gòu),負責為服務(wù)提供商分配和注冊互聯(lián)網(wǎng)號碼資源。RIPE組織使用Quagga路由軟件收集了BGP路由器的原始數(shù)據(jù),包括全量的路由表BVIEW數(shù)據(jù)(每八個小時更新一次)和差量的UPDATE數(shù)據(jù)(每五分鐘更新一次)。
UPDATE采集模塊:本模塊負責下載RIPE項目22個rrc(Route Reflector Client)的UPDATE數(shù)據(jù)。原始的UPDATE數(shù)據(jù)是以二進制的形式存儲的,本模塊使用RIPE提供的解析工具libBGPdump,把報文解析成可閱讀的形式。模塊將解析后的文件存入Hadoop。
UPDATE存儲模塊:Hadoop是一個軟件框架,它的作用是方便使用簡單的程序在大量的計算機上對數(shù)據(jù)集進行分布式處理。本文分析了RIPE項目一個月的UPDATE數(shù)據(jù),數(shù)據(jù)文件大小為417.6GB。由于要從較大規(guī)模數(shù)據(jù)中發(fā)現(xiàn)BGP異常特征規(guī)律,所以需要一個可靠的、高效的數(shù)據(jù)存儲模塊。
BGP Stream異常事件源:BGP Stream收集了BGP網(wǎng)絡(luò)中有關(guān)路由劫持和路由泄露的免費資源。BGP Stream使用自動化方法選擇最大和最重要的異常。提供異常信息包括異常類型,涉及的IP地址前綴、AS號、發(fā)生時間等。
事件采集模塊:本模塊使用Python實現(xiàn)了爬取BGP Stream收集的異常事件,一起異常事件可以用三元組的方式描述:[prefix,time,type]。prefix表示受影響的IP地址前綴,time表示異常的發(fā)生時間,type表示異常類型。
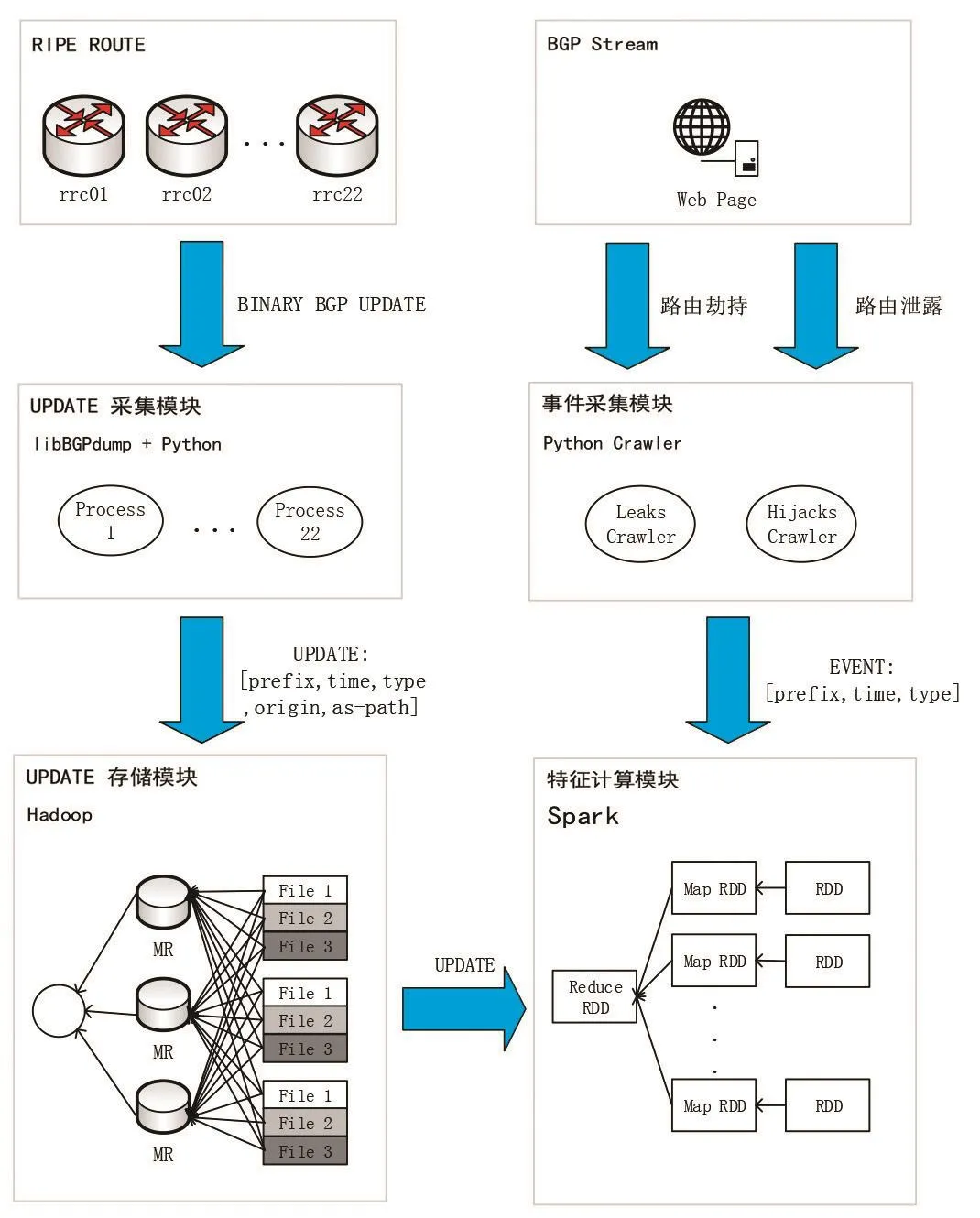
圖1 系統(tǒng)架構(gòu)
Spark特征計算模塊:Spark是一個基于MapReduce的快速的通用的大規(guī)模數(shù)據(jù)處理引擎。Spark建立在統(tǒng)一抽象的RDD之上。RDD是一個容錯的、并行的數(shù)據(jù)結(jié)構(gòu)。RDD提供了map、filter、reduceByKey等數(shù)據(jù)操作方式。本模塊從Hadoop中讀取BGP UPDATE報文,結(jié)合從事件采集模塊收集的異常事件,分析若干異常特征。本研究將時間區(qū)間劃定為一天,分析器將統(tǒng)計異常發(fā)生當天的特征數(shù)據(jù)。系統(tǒng)架構(gòu)如圖1所示。
特征選擇和計算方法
當一個BGP路由器發(fā)生異常時,其余的BGP路由器會為失敗的路由重新進行路由選擇算法。在路由重新選擇的過程中,BGP路由器會發(fā)布路由宣告和撤回消息。這些更新信息可以幫助我們發(fā)現(xiàn)BGP異常的特征規(guī)律。下文將討論以下特征以及其計算方法。
宣告/撤回數(shù)量
在過去大規(guī)模的BGP路由異常事件中,通常路由的不穩(wěn)定性會表現(xiàn)在UPDATE報文中的宣告和撤回數(shù)量上。所以本研究將宣告和撤回數(shù)量作為一個BGP異常事件特征。宣告和撤回數(shù)量特征計算公式如下:

AVi和WVi表示事件集合中編號為i的事件宣告/撤回數(shù)量。RIPE項目22個rrc每五分鐘對外發(fā)布一次UPDATE報文文件,每個rrc每天生成288個報文文件。Xij和Yij代表著一個報文文件中的宣告/撤回數(shù)量序列。ENUM表示事件集合中的事件數(shù)量。
重復宣告/隱式撤回
宣告的類型可以分為三種。如果一條宣告聲明了一個原來不可達的IP地址前綴,那么這條宣告被稱作新的宣告。如果一條宣告聲明了一個可到達的IP地址前綴,并且具有相同的路由,即UPDATE中PREFIX域和ASPATH域相同,那么這條宣告被稱作重復宣告。如果一條路由替換了當前的路由,即PREFIX域和AS-PATH的源相同,但是AS-PATH發(fā)生了變化,那么這條宣告被稱為隱式撤回。當BGP路由異常發(fā)生時,路由處于不穩(wěn)定的狀態(tài),有時會伴隨重復宣告和隱式撤回。重復宣告計算公式如下:
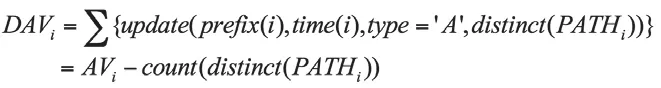
DAVi表示事件i的重復宣告數(shù)量,PATHi是事件i所有UPADTE中所有ASPATH。上式證明了重復宣告數(shù)量等于宣告數(shù)量與路徑集合大小的差。
隱式撤回IWVi的計算,需要基于路由表的狀態(tài),可以根據(jù)BGP UPDATE來維護路由表狀態(tài)。隱式撤回的計算方法如下:
步驟1 收集PREFIX域為prefix(i),TIME域為time(i)的宣告UPDATE。
步驟2 將UPDATE按照(前綴,采集點,源)為鍵值,(時間,路徑)為值分組。
步驟3 分組后,對于每一個分組,都產(chǎn)生一個(時間,路徑)的序列。對每個序列應(yīng)用如下算法:
步驟3.1 對元組序列按照時間升序排序。
步驟3.2 pre_path用于記錄分組路由,implicate_num用于記錄分組隱式撤回數(shù)量。算法1具體闡述求一個分組隱式撤回數(shù)量方法,如下所示。RETURN implicate_num

步驟4 將所有分組隱式撤回數(shù)相加,得到IWVi。
AS源數(shù)量
AS源數(shù)量是一個判定BGP路由異常的重要指標。多源自治域系統(tǒng)沖突發(fā)生當一個特定的IP地址前綴被超過一個AS自治域宣告為源。IP地址前綴的源可以從UPDATE的AS-PATH域獲得,AS-PATH從左往右的最后一個節(jié)點為前綴的源。AS源數(shù)量指標是計算時間窗口內(nèi),事件前綴不重復的源個數(shù)。AS源數(shù)量計算公式如下:

MUASi為事件i的AS源數(shù)量,pathi(-1)表示事件iUPDATE中AS-PATH域路徑從左往右第一個AS的集合。
宣告類型
UPDATE宣告中的ORIGIN是一個必須存在的字段,它定義了AS-PATH路徑起源的信息。ORIGIN的值有以下三種:
IGP:網(wǎng)絡(luò)層可達性信息來自O(shè)RGIN AS內(nèi)部。
EGP:網(wǎng)絡(luò)層可達性信息獲得通過EGP協(xié)議。
INCOMPLETE:網(wǎng)絡(luò)層可達性信息獲得來自其他渠道。
不同的值在BGP路由選擇算法中有不同的權(quán)重,如果AS-PATH相同,優(yōu)先選擇低等級的ORIGIN類型,優(yōu)先等級IGP<EGP<INCOMPLETE。不同的異常發(fā)生可能在宣告的類型上也有區(qū)分。宣告類型特征計算公式如下:

ATij為事件宣告類型為j的特征值,ATij的含義是j類型宣告的比例。
路徑長度
當BGP重新選擇路由時,路徑長度有很大概率會發(fā)生改變。尤其當發(fā)生路由劫持或者路由泄露時,路徑長度的變化會更加明顯。路由劫持發(fā)生時,原有的路由線路不再可用,BGP路由器會嘗試新的替代線路。路由泄露發(fā)生時,雖然IP地址前綴所屬的AS沒有發(fā)生變化,但是由于路徑中間AS的轉(zhuǎn)發(fā)策略配置不當,違反了Valley-free的商業(yè)關(guān)系,往往會導致路徑長度變得更長。路徑長度特征計算公式如下:

PLij表示標號為i的異常事件,路徑長度為j的數(shù)量。同樣Xij表示一組報文數(shù)量的序列。MPL表示最大路徑長度。
路徑編輯距離
當BGP路由異常發(fā)生時,路由處于不穩(wěn)定的狀態(tài),采集點會檢測到大量來自同一AS源但路徑卻不相同的宣告。編輯距離是一種反應(yīng)兩條路徑差異程度的量化特征指標,量化方法是一條路徑經(jīng)過至少多少次操作可以變成另一條路徑。操作方式包括添加一個AS節(jié)點、刪除一個AS節(jié)點,替換一個AS節(jié)點。例如路徑[1,3,2,5,4]和路徑[1,3,6,4]的編輯距離為2,前者通過將2替換成6,刪除5,兩次操作可以得到后者。兩條路徑的編輯距離求解有基于動態(tài)規(guī)劃的多項式時間復雜度求解算法,狀態(tài)轉(zhuǎn)移方程如下:
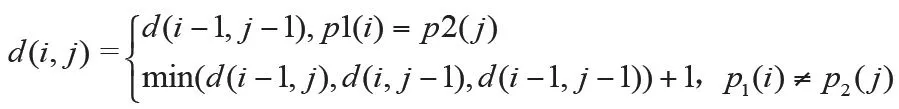
d(i,j)表示長度為i的一條路徑(記為p1)與長度為j的一條路徑(記為p2)的編輯距離。如果P1(i)=P2(j),則不需要任何操作,狀態(tài)轉(zhuǎn)移到(i-1,j-1)。
基于路徑編輯距離求解算法,我們定義最大路徑編輯距離特征如下:
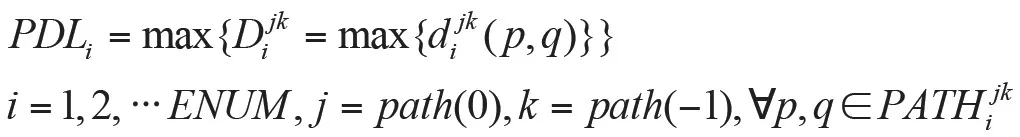
PDLi表示編號為i的事件的最大編輯距離。對于同一IP地址前綴,采集點編號為j,宣告源編號為k。按照(i,j,k)對宣告進行分組,D表示組內(nèi)最大編輯距離。p,q表示組內(nèi)兩條宣告路徑,d表示兩條路徑的編輯距離。
特征采集結(jié)果分析

圖2 宣告數(shù)量。橫軸表示宣告數(shù)量的對數(shù)值,縱軸表示對應(yīng)概率分布函數(shù)值F
本研究基于系統(tǒng)結(jié)構(gòu)設(shè)計,對提出的小范圍BGP異常特征,按照所述定義與計算方法進行了實際采集與分析。其中UPDATE更新報文來自RIPE項目中采集,數(shù)據(jù)規(guī)模包括其全部22個rrc數(shù)據(jù)。本研究異常事件數(shù)據(jù)來自BGP Stream,一共考察了259起路由劫持事件和523起路由泄露事件。未被BGP Stream通報的IP地址前綴,其相關(guān)UPDATE被視為正常。本研究隨機抽樣了1000起正常事件,用于參照。正常事件同樣用三元組(prefix,time,type)表示。大部分小范圍BGP異常發(fā)生事件不超過一天,同時要考慮到BGP Stream通報異常發(fā)生時間和相關(guān)UPDATE收集時間,為了保證相關(guān)指標能夠被有效采集到,本研究選用24小時作為事件的采樣時隙。
圖2比較了路由泄露、路由劫持和正常情況下宣告數(shù)量。
圖2結(jié)果表明整體宣告數(shù)量上正常情況<路由劫持<路由泄露。正常情況下前綴的宣告數(shù)量集中在數(shù)量級以內(nèi)(75.82%)。路由劫持事件發(fā)生時,有一定比例(47.32%)宣告數(shù)量在數(shù)量級以上。路由泄露事件發(fā)生時,前綴的宣告數(shù)量集中在至(80.15%)。圖2三條曲線形態(tài)有較大差異,表明當小范圍BGP異常發(fā)生時,宣告數(shù)量與正常情況有較大區(qū)別,同時路由泄露和路由劫持在宣告數(shù)量這個特征上有較高區(qū)分度。
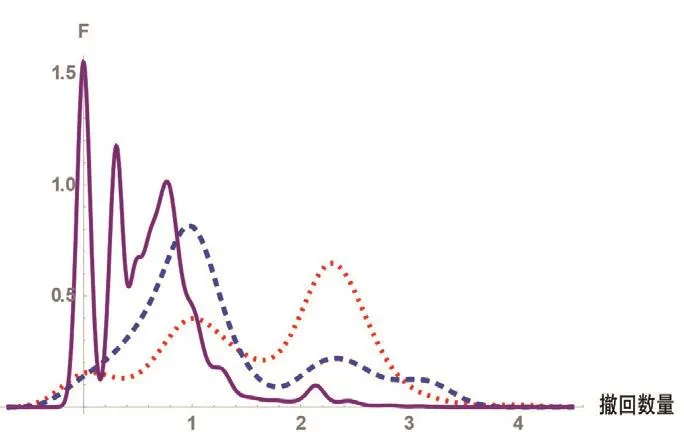
圖3 撤回數(shù)量。橫軸表示撤回數(shù)量的對數(shù)值,縱軸表示對應(yīng)概率分布函數(shù)值F

圖4 重復宣告。橫軸表示重復數(shù)量的比例,縱軸表示對應(yīng)概率分布函數(shù)值F
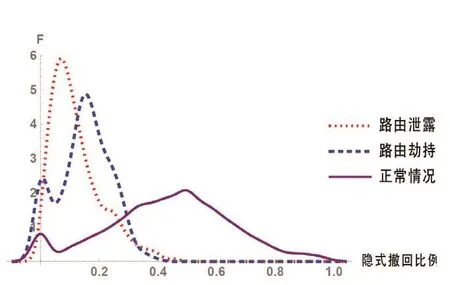
圖5 隱式撤回。橫軸表示隱式撤回數(shù)量的比例,縱軸表示對應(yīng)概率分布函數(shù)值 F
圖3比較了路由泄露、路由劫持和正常情況下撤回數(shù)量特征值。從圖3可以看出,正常情況下,一個前綴不會在短時間內(nèi)出現(xiàn)大量的撤回,87.19%前綴撤回數(shù)量小于101。當路由發(fā)生時,撤回的數(shù)量這一比例開始下降,只有38.83%的被劫持前綴撤回數(shù)量小于101。路由泄露在撤回數(shù)量這一特征上與前兩者有著更明顯的差別,特征值集中在105的數(shù)量級上。
圖4比較了路由泄露、路由劫持和正常情況下重復宣告比例。從圖4可以看出無論是路由劫持還是路由泄露發(fā)生時,在重復宣告數(shù)量這一特征上不會產(chǎn)生明顯變化。
圖5比較了路由泄露、路由劫持和正常情況下隱式撤回比例。
當BGP路由異常發(fā)生時,隱式撤回的比例要小于正常情況。這表明異常會伴隨著連續(xù)的重復宣告。根據(jù)前文關(guān)于重復宣告和隱式撤回的定義,兩者的區(qū)別在于重復宣告沒有對UPDATE按照時間排序,而隱式撤回考慮到了UPDATE的到達先后順序。比較圖4和圖5正常情況下的曲線,兩條曲線是相似的。這說明正常情況下,相同的宣告產(chǎn)生與時間這一因素無關(guān)的。而異常情況下宣告方式與時間因素相關(guān),可以分為兩個階段:第一個階段產(chǎn)生大量宣告,這些宣告大多互不相同;第二個階段開始連續(xù)產(chǎn)生相同的宣告。
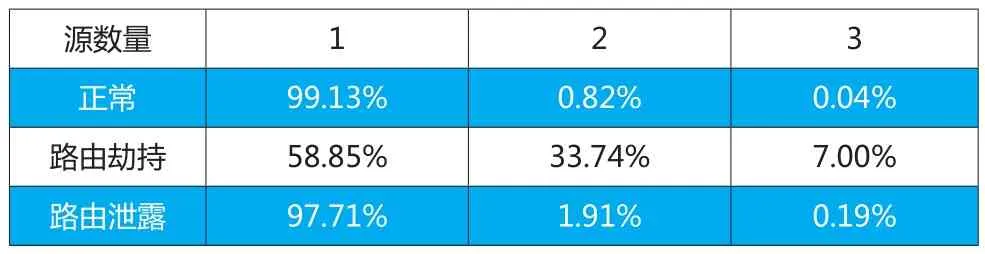
表1 AS源數(shù)量

表2 宣告類型
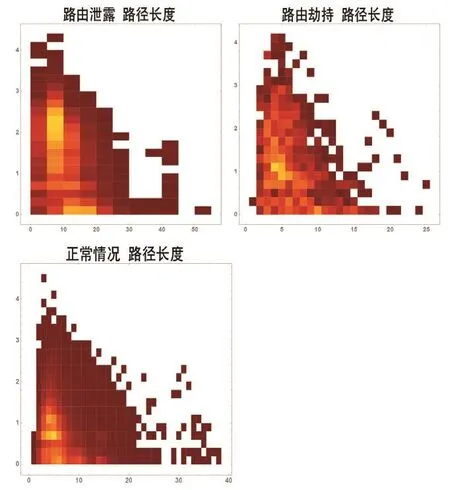
圖6 路徑長度
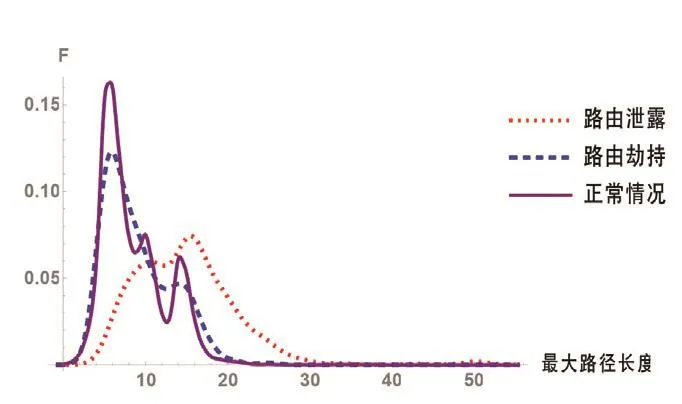
圖7 最大路徑長度
表1比較了路由泄露、路由劫持和正常情況下AS源數(shù)量。對于正常情況和路由泄露,幾乎所有前綴只會有一個AS源。但是四成的被劫持前綴被觀測到在短時間內(nèi)出現(xiàn)多個AS自治域相互“爭奪”一個IP地址前綴的現(xiàn)象。在AS源數(shù)量這一特征上,路由劫持異常具有顯著性。
表2比較了路由泄露、路由劫持和正常情況下宣告類型比例。研究中沒有發(fā)現(xiàn)帶有EGP標識的UPDATE。同時與正常情況相比,當小范圍的BGP路由異常發(fā)生時,宣告類型的比例沒有發(fā)生明顯變化。
圖6比較了路由泄露、路由劫持和正常情況下路徑長度。圖6橫軸表示路徑長度,縱軸表示數(shù)量以10為底的數(shù)量級。可以看出,三種情況下UPDATE路徑長度均集中在5附近(正常情況路徑平均長度5.24,路由劫持4.64,路由泄露6.71),稍有不同的是數(shù)量上正常情況<路由劫持<路由泄露。但是根據(jù)圖7顯示的結(jié)果,路由泄露發(fā)生時的最大路徑長度顯著大于正常情況和路由劫持。綜上所述,雖然三種情況下整體路徑長度分布相似,但是路由泄露異常更容易產(chǎn)生不合理的超長的路徑。
圖8路由泄露、路由劫持和正常情況下路徑編輯距離。結(jié)果顯示編輯距離特征和最長路徑長度相似,與正常情況相比,路由劫持特征不顯著,路由泄露的編輯距離要大于前兩者。
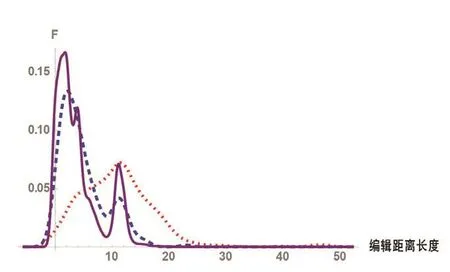
圖8 編輯距離。橫軸表示編輯距離,縱軸表示對應(yīng)概率分布函數(shù)值F
過濾式異常特征分析
北京郵電大學分別采集了BGP路由泄露、路由劫持、正常三類樣本,數(shù)量一共1782起,特征維度一共個58維度,形成了一個的特征矩陣。BGP異常分析受特征之間的相關(guān)性和冗余所影響,同時采集的特征維度過多浪費了計算資源。Fisher算法和mRMR是兩種常用的過濾式算法,用于解決特征相關(guān)性和冗余的過濾式方法。
1. Fisher過濾法
Fisher方法的關(guān)鍵思路是從特征中找出一些特征,滿足這些特征在樣本數(shù)據(jù)中,不同類別的數(shù)據(jù)點之間的距離盡可能大,而同一類的數(shù)據(jù)間的分數(shù)盡可能小。同一類別的數(shù)據(jù)的距離用類別方差和來描述,方差和越小說明對于該特征類別內(nèi)數(shù)據(jù)越一致。不同類距離用特征均方和描述,均方和越大說明類別間區(qū)分度越好。Fisher分數(shù)實際就是前者與后者的比值。特征向量F={X1,X2…X58},對于第r個特征,其Fisher分數(shù)公式如下:
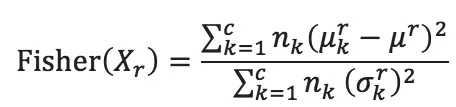
其中c代表3種樣本類型,nk代表第k類樣本數(shù)量,μ代表對于特征r第k類的平均值,μr代表特征r整體平均值,σ 代表征r第k類標注差。
2. mRMR
mRMR方法的關(guān)鍵思想是最大化特征相對于目標類的相關(guān)性,同時最小化特征之間的冗余。mRMR方法基于互信息公式,對于兩個特征Χk和Χl,其概率密度及聯(lián)合概率密度為 p(Χk)、p(Χl) 和 p(Χk,Χl)。互信息的計算公式如下:
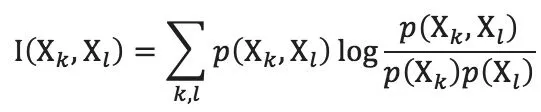
一般使用兩種變體mRMR算法:相互信息差異(MID),互信息(MIQ)。MID和

表3 特征過濾
MIQ評分公式如下:
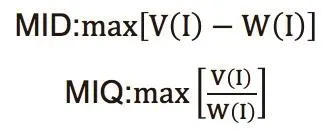
V(I)和W(I)分別為:
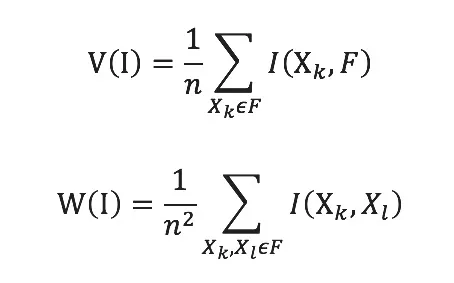
Fisher方法和mRMR方法分別計算分數(shù),表3列出了前15名特征。從表中數(shù)據(jù)可以看出宣告/撤回數(shù)量、重復宣告/隱式撤回、AS源數(shù)量、路徑長度均對異常分類具有幫助,宣告類型則沒有幫助。路徑長度的維度雖然有50維,然而對分類有幫助的的維度主要集中在長度小于20的維度。
基于本文討論的小規(guī)模BGP網(wǎng)絡(luò)異常特征的定義、采集方法和特征與異常類型的關(guān)聯(lián)分析,未來的工作重點將是如何進行小范圍BGP網(wǎng)絡(luò)異常檢測。
傳統(tǒng)的BGP網(wǎng)絡(luò)異常檢測單模型的檢測方法,例如De Urbina等人使用SVM方法進行BGP路由異常檢測。Huang提出了基于PCA的檢測算法。Deshpande提出了基于最大似然估計的檢測算法。
單模型方法的缺陷在于很難在檢測效率和準確度兩者之間做出適當?shù)钠胶狻1狙芯坑媱澰谖磥聿捎秒p模型組合的異常檢測策略,將本文采集的特征數(shù)據(jù)濾篩選后通過GBDT方法離線處理生成新的組合特征,然后使用LR邏輯回歸的方法進行分類。如何將本研究結(jié)果運用到具體的異常檢測算法中,將是今后的研究重點。
(責編:陶春)
為北京郵電大學網(wǎng)絡(luò)技術(shù)研究院)
猜你喜歡
數(shù)學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數(shù)理化(高中版.高考數(shù)學)(2022年3期)2022-04-26 14:04:16
數(shù)學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數(shù)學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
