基于ABC-BP的土壤侵蝕量預(yù)報(bào)模型研究
2018-01-08 02:18:18王權(quán)威
水力發(fā)電 2017年9期
王權(quán)威,唐 莉
(太原理工大學(xué)水利科學(xué)與工程學(xué)院,山西太原030024)
基于ABC-BP的土壤侵蝕量預(yù)報(bào)模型研究
王權(quán)威,唐 莉
(太原理工大學(xué)水利科學(xué)與工程學(xué)院,山西太原030024)
以預(yù)測土壤沖刷量為目標(biāo),根據(jù)《中國河流泥沙公報(bào)》數(shù)據(jù)資料,建立了以土壤類型、地形、坡度、植被、降雨為輸入因子,土壤侵蝕量為輸出因子,拓?fù)浣Y(jié)構(gòu)為5-7-1的BP神經(jīng)網(wǎng)絡(luò)預(yù)測模型。針對BP神經(jīng)網(wǎng)絡(luò)模型缺陷,采用了人工蜂群算法(ABC)對BP神經(jīng)網(wǎng)絡(luò)的權(quán)值和閾值進(jìn)行優(yōu)化,建立了ABC-BP模型,并對該模型的性能進(jìn)行了驗(yàn)證。結(jié)果表明,所建立的ABC-BP土壤侵蝕量預(yù)報(bào)模型模擬值與實(shí)測值的相關(guān)系數(shù)、平均相對誤差分別為0.994 2和4.13%,兩者之間無顯著的統(tǒng)計(jì)學(xué)差異,具有較好的一致性和較高的模擬精度。
水土流失;土壤侵蝕量;t檢驗(yàn);人工蜂群算法;BP神經(jīng)網(wǎng)絡(luò)模型
0 引 言
土地是維系人類繁衍生息的基本資源,嚴(yán)重的水土流失問題會(huì)導(dǎo)致土壤養(yǎng)分流失[1]、溝壑面積增多和農(nóng)田破壞嚴(yán)重[2]、河床淤積和河道抬高[3]等諸多問題,阻礙了經(jīng)濟(jì)社會(huì)的可持續(xù)性發(fā)展。因此,開展水土流失機(jī)理、防治和預(yù)報(bào)等方面的研究工作有極其重要的現(xiàn)實(shí)意義。目前,諸多學(xué)者圍繞水土流失問題展開了大量的研究工作,取得了一定的研究成果。在水土流失機(jī)理方面,降雨是徑流產(chǎn)生的必要條件和水土流失的原動(dòng)力[4],坡度和坡形對產(chǎn)流的影響極為顯著[5]。不同的植被類型和植被覆蓋度對坡面產(chǎn)流及水土流失的影響極為重要,主要表現(xiàn)在攔截降雨和入滲方面[6]。有學(xué)者指出,不同土壤類型的坡面產(chǎn)流特性存在明顯差異[7],如相同試驗(yàn)條件下,褐土的坡面徑流量要高于棕壤土[8]。耕作措施對水土流失的影響也有相關(guān)報(bào)道。與橫廂耕作措施相比,縱廂耕作措施的水土流失問題更加嚴(yán)重[9];與常規(guī)耕作比較,深松覆蓋處理能有效減少徑流和土壤流失,少耕僅僅能減少土壤流失[10]。水土流失預(yù)測方面,目前采用的方法主要包括一些經(jīng)驗(yàn)?zāi)P秃臀锢砟P蚚11]。土壤侵蝕預(yù)測模型研究多集中于小流域尺度范圍[12-15],大尺度范圍的預(yù)測工作相對較少,并多以遙感和GIS技術(shù)為主[16-18]。
人工智能算法的預(yù)報(bào)方法將為大尺度范圍的土壤侵蝕預(yù)測工作提供重要的科學(xué)依據(jù)和全新的研究手段,但采用該方法進(jìn)行大尺度范圍的土壤侵蝕預(yù)測工作相對較少。前人在使用神經(jīng)網(wǎng)絡(luò)模型進(jìn)行小尺度土壤侵蝕預(yù)測時(shí),部分模型的輸入端常常忽略了一些重要因素,主要包括植被覆蓋程度、土質(zhì)因素、降雨等。目前,這些模型所適用的范圍相對較小,對全國范圍內(nèi)土壤沖刷量預(yù)測研究有待進(jìn)一步深入。前人在構(gòu)建此類模型時(shí),一般均采用傳統(tǒng)的神經(jīng)網(wǎng)絡(luò)算法,在使用過程中會(huì)存在搜索空間大、易陷入局部極值點(diǎn)等問題,限制了實(shí)際預(yù)測中的廣泛應(yīng)用。因此,對該模型的優(yōu)化改進(jìn)是十分必要的。人工蜂群算法(ABC)作為一種模擬蜜蜂蜂群智能搜索行為的生物智能優(yōu)化算法,由于其控制參數(shù)少、易于實(shí)現(xiàn)和計(jì)算簡潔,從而成為學(xué)術(shù)界研究的焦點(diǎn)[19]。目前,基于ABC優(yōu)化后的BP神經(jīng)網(wǎng)絡(luò)模型在水土流失方面的預(yù)測還未見報(bào)道。本文旨在構(gòu)建基于ABC優(yōu)化后的BP神經(jīng)網(wǎng)絡(luò)模型(ABC-BP模型),以實(shí)現(xiàn)土壤侵蝕量的準(zhǔn)確預(yù)報(bào),為水土流失預(yù)測工作提供技術(shù)支持。
1 基本原理
1.1 BP神經(jīng)網(wǎng)絡(luò)模型
1968年,以Rumelhart和McCelland為首的科學(xué)家小組首次提出了BP神經(jīng)網(wǎng)絡(luò),它是目前模擬精度相對較高、應(yīng)用范圍最廣的神經(jīng)網(wǎng)絡(luò)模型之一,由輸入層、隱含層、輸出層3部分構(gòu)成。圖1為BP神經(jīng)網(wǎng)絡(luò)的工作原理和基本網(wǎng)絡(luò)結(jié)構(gòu)。圖中,m、q和n分別為輸入層節(jié)點(diǎn)、隱含層節(jié)點(diǎn)和輸出層節(jié)點(diǎn)。誤差反向傳播算法的學(xué)習(xí)過程由信息的正向傳播和誤差的反向傳播2個(gè)過程組成。外界的輸入信息首先由輸入層接收,并傳遞給中間層神經(jīng)元,然后經(jīng)過中間層的信息處理后,最終傳輸給輸出層,并由輸出層向外界輸出信息。當(dāng)輸出信息與期望不吻合時(shí),便進(jìn)入誤差反向傳播機(jī)制,各層間的權(quán)值矩陣和閾值矩陣進(jìn)行不斷調(diào)整,如此反復(fù)直至達(dá)到期望要求為止。
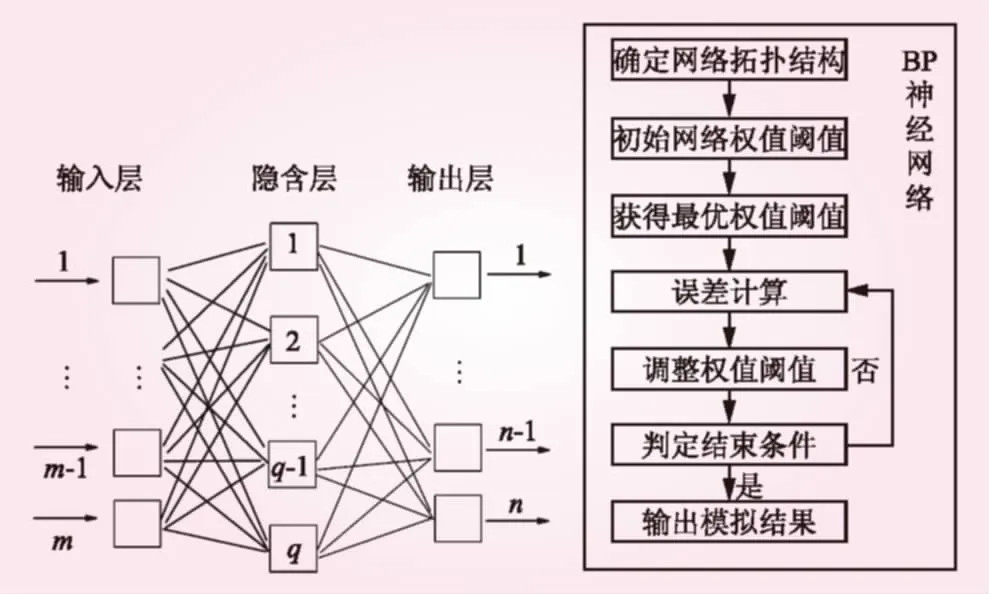
圖1 BP神經(jīng)網(wǎng)絡(luò)基本結(jié)構(gòu)及工作原理
1.2 ABC流程
在ABC中,人工蜂群主要由采蜜蜂、觀察蜂和偵察蜂3個(gè)組成部分。在蜂群進(jìn)化過程中,前2個(gè)負(fù)責(zé)執(zhí)行開采過程,后者執(zhí)行探索過程。ABC的實(shí)現(xiàn)步驟及具體過程如下:
(1)隨機(jī)產(chǎn)生SN(蜂群規(guī)模)個(gè)初始解,將其中一半與采蜜蜂對應(yīng),并計(jì)算各個(gè)解的適應(yīng)度值,將最優(yōu)解記錄下來。
(2)設(shè)置循環(huán)數(shù)Cycle=1。
(3)采蜜蜂進(jìn)行鄰域搜索產(chǎn)生新解vij,計(jì)算其適應(yīng)度,并對原蜜源位置xij和新解vij進(jìn)行貪婪選擇,即
vij=xij+φij(xij-xkj)
(1)
式中,k為不同于i的蜜源;φij為[-1,1]之間的隨機(jī)數(shù),控制著原蜜源位置xij鄰域內(nèi)蜜源位置的產(chǎn)生。候選位置形象地代表著原蜜源位置xij與鄰域內(nèi)隨機(jī)的一個(gè)蜜源xkj之間的對比關(guān)系。
(4)計(jì)算與xi相關(guān)的選擇概率Pi,即
(2)
式中,fiti為xi的適應(yīng)度值,i=1,2,…,SN。
(5)觀察蜂根據(jù)輪盤賭選擇法,以概率Pi選擇食物源,并根據(jù)式(1)進(jìn)行鄰域搜索產(chǎn)生新解,計(jì)算適應(yīng)度,并對xij和vij進(jìn)行貪婪選擇。
(6)判斷是否有要放棄的解,如果存在,則采用式(3)進(jìn)行搜索產(chǎn)生1個(gè)新解替代舊解,即
(3)
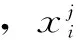
(7)記錄迄今為止最好的解。
(8)Cycle=Cycle+1,若Cycle<最大循環(huán)次數(shù)MCN,則轉(zhuǎn)(3);否則,輸出最優(yōu)結(jié)果。
2 ABC-BP神經(jīng)網(wǎng)絡(luò)模型的構(gòu)建
2.1 ABC初始值
本文選取的蜂群大小為200個(gè),極限值limit需要大于每個(gè)解的維數(shù)D,可表示為
D=Nmin×Nhidden+Nhidden+Nhidden×Noutput+Noutput
(4)
式中,Nmin、Nhidden、Noutput分別是神經(jīng)網(wǎng)絡(luò)的輸入層、隱含層、輸出層的神經(jīng)元個(gè)數(shù)。初始解是隨機(jī)產(chǎn)生的(-1,1)之間的數(shù),計(jì)算得到D值為50。
2.2 神經(jīng)網(wǎng)絡(luò)輸入輸出層的確定
結(jié)合前人研究現(xiàn)狀,水土流失的關(guān)鍵影響因素可歸結(jié)為土壤類型、地形、坡度、植被和降雨等。因此,本研究將上述5項(xiàng)作為該模型的輸入項(xiàng),土壤侵蝕量作為模型的輸出項(xiàng)。本研究的數(shù)據(jù)主要來源于《中國水土保持公報(bào)》,經(jīng)過整理得到全國不同水土流失典型監(jiān)測點(diǎn)的土壤侵蝕量資料,資料分別來自東北黑土區(qū)、北方山地丘陵區(qū)、西北黃土高原、南方紅壤區(qū)、西南紫色土區(qū)、西南巖溶區(qū)和青藏高原區(qū)。部分?jǐn)?shù)據(jù)資料見表1。總樣本數(shù)為194個(gè),以7∶3的比例將該樣本分為訓(xùn)練集和預(yù)測集,即樣本數(shù)分別為136個(gè)和58個(gè)。
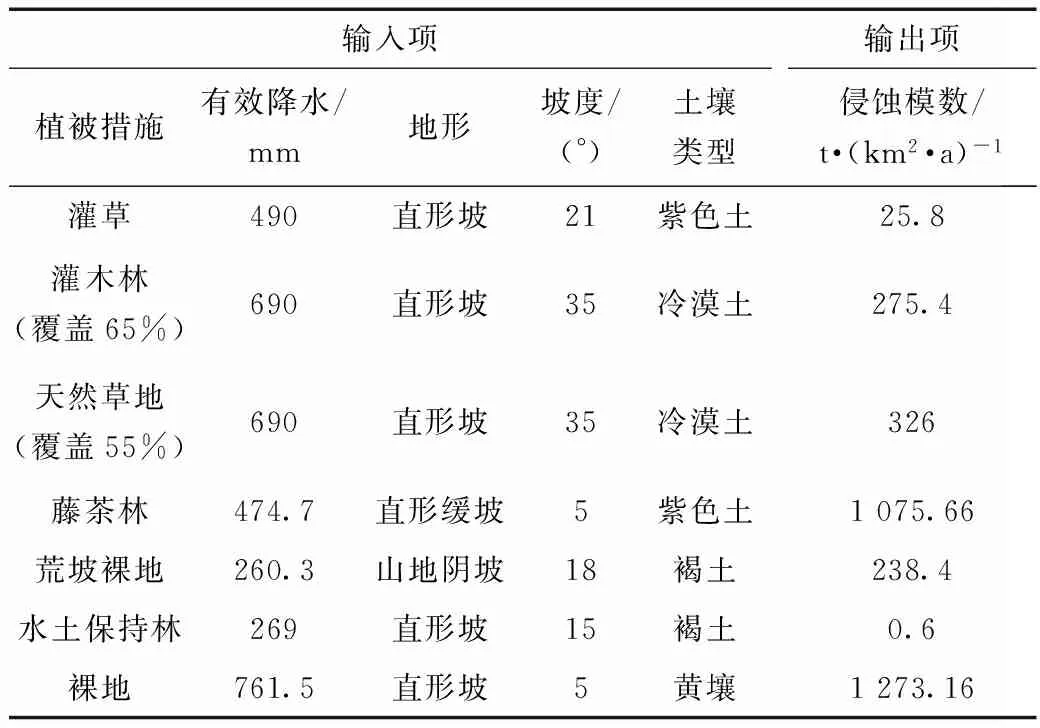
表1 基礎(chǔ)樣本資料
2.3 神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)的確定
隱含層數(shù)目與模擬精度呈正比,但過多的隱含層也可能會(huì)造成模型過于復(fù)雜等問題,通常選擇單隱含層為宜。隱含層節(jié)點(diǎn)數(shù)可以根據(jù)相關(guān)的經(jīng)驗(yàn)方法進(jìn)行確定。首先根據(jù)式(5)確定節(jié)點(diǎn)數(shù)大致范圍為4~12,通過多次試算從而確定最優(yōu)節(jié)點(diǎn)數(shù)。為保證BP 神經(jīng)網(wǎng)絡(luò)模型的非線性,從輸入層到隱含層的信息傳遞采用logistic函數(shù),隱含層到輸出層信息傳遞采用purlin 函數(shù),神經(jīng)網(wǎng)絡(luò)的訓(xùn)練采用trainlm 函數(shù)。訓(xùn)練目標(biāo)誤差為0.000 1,最大訓(xùn)練次數(shù)為5 000次,即
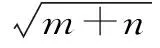
(5)
式中,q為隱含層節(jié)點(diǎn)數(shù);m為輸入層節(jié)點(diǎn)數(shù);n為輸出層節(jié)點(diǎn)數(shù);a為1~10之間的整數(shù)。
3 結(jié)果分析
3.1 最優(yōu)隱含層節(jié)點(diǎn)的確定
圖2為不同節(jié)點(diǎn)數(shù)條件下神經(jīng)網(wǎng)絡(luò)模型精度。從圖2可以看出,當(dāng)隱含層節(jié)點(diǎn)數(shù)增加時(shí),神經(jīng)網(wǎng)絡(luò)模型模擬值與實(shí)測值的平均相對誤差MAPE和均方根誤差RMSE均呈現(xiàn)先逐漸減小,然后逐漸增大的變化趨勢。在多次試算中,當(dāng)隱含層節(jié)點(diǎn)數(shù)為7時(shí),經(jīng)過2 384次訓(xùn)練后,模型的訓(xùn)練誤差為0.000 1,能夠達(dá)到模型的訓(xùn)練精度要求。因此,認(rèn)為7為合理的節(jié)點(diǎn)數(shù)。綜上所述,本研究中模型的拓?fù)浣Y(jié)構(gòu)為5-7-1。
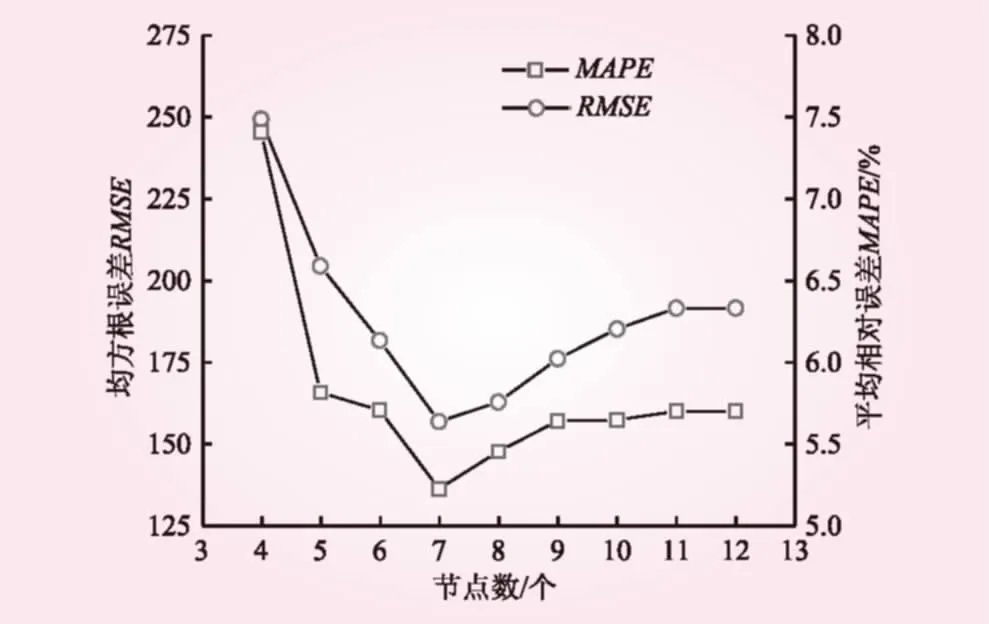
圖2 不同節(jié)點(diǎn)數(shù)條件下神經(jīng)網(wǎng)絡(luò)模型精度
3.2 訓(xùn)練組模擬效果
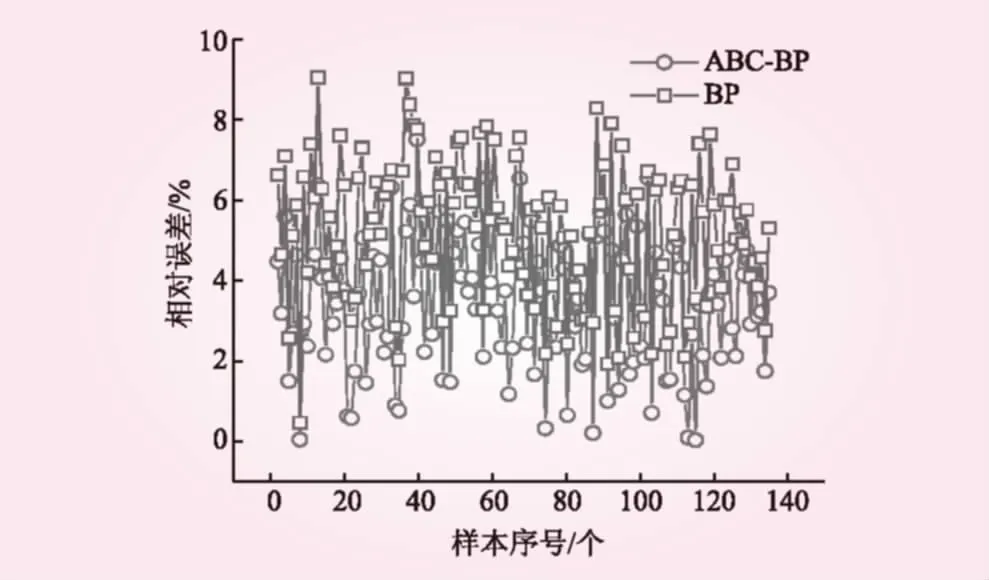
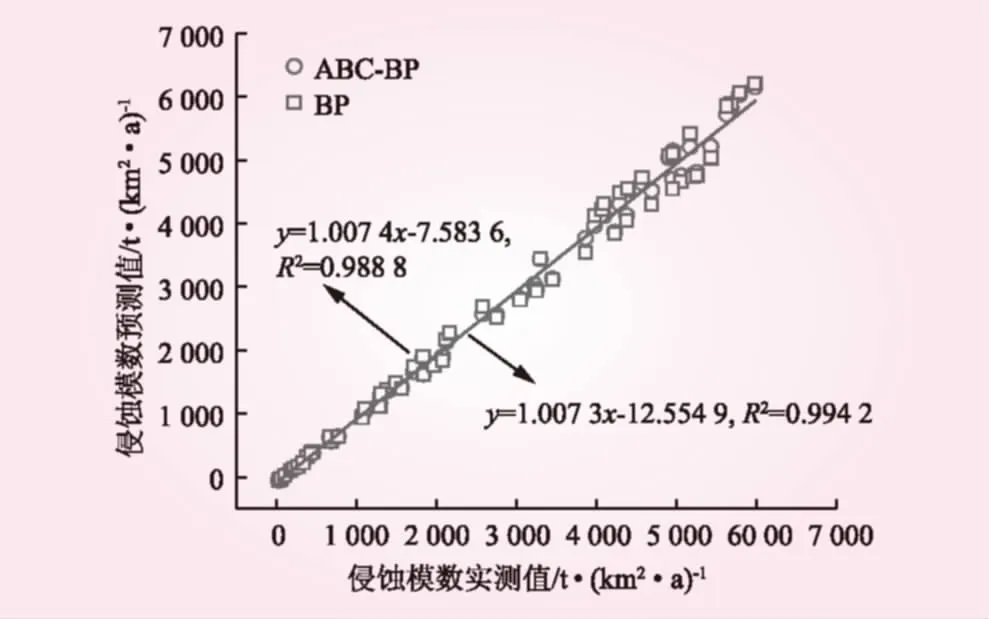
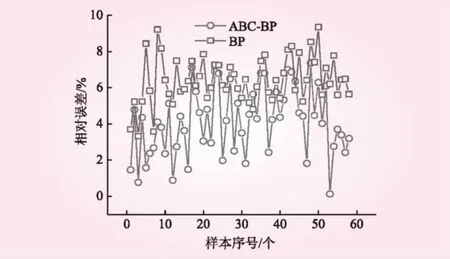
圖3為沖刷量實(shí)測值與預(yù)測值的相關(guān)關(guān)系。從圖3可以看出,BP模型和ABC-BP模型的預(yù)測值和實(shí)測值構(gòu)成的線性擬合模型的擬合度分別達(dá)到0.994 0和0.997 1,方程的斜率分別為0.999 4和0.999 8,說明這2種模型的預(yù)測值與實(shí)測值之間均具有較強(qiáng)的線性相關(guān)性,并且預(yù)測值與實(shí)測值之間能夠保持較好的一致性。圖4為各個(gè)樣本的相對誤差。從圖4可知,BP模型和ABC-BP模型預(yù)測值與實(shí)測值間的最大相對誤差分別為7.56%和9.12%,最小分別為0.003%和0.439%,平均分別為3.42%和5.24%。可以看出,ABC-BP模型的訓(xùn)練誤差明顯更小。此外,本文采用統(tǒng)計(jì)學(xué)方法對模型預(yù)測值與實(shí)測值之間的差異性進(jìn)行了統(tǒng)計(jì)學(xué)分析,分析結(jié)果見表2。從表2可以看出,t值的絕對值小于t檢驗(yàn)臨界值,即|t| 圖3 沖刷量實(shí)測值與預(yù)測值相關(guān)性 圖4 樣本相對誤差 方法自由度t檢驗(yàn)臨界值顯著性結(jié)果ABC-BP135-0.2910.771BP135-0.2290.819 圖5為沖刷量實(shí)測值與預(yù)測值的相關(guān)關(guān)系。從圖5可以看出,BP模型和ABC-BP模型的預(yù)測值與實(shí)測值構(gòu)成的線性擬合模型的擬合度分別達(dá)到0.988 8和0.994 2,方程的斜率分別為1.007 4和1.007 3,說明2種模型的預(yù)測值與實(shí)測值之間均具有較強(qiáng)的線性相關(guān)性,并且預(yù)測值與實(shí)測值之間能夠保持較好的一致性。圖6為各個(gè)樣本的相對誤差。從圖6可知,ABC-BP模型和BP模型實(shí)測值與預(yù)測值之間的最大相對誤差分別為7.37%和9.36%,最小分別為0.13%和3.33%,平均分別為4.13%和6.43%,ABC-BP模型具有更高的預(yù)測精度。表3為樣本的實(shí)測值與模擬值間的統(tǒng)計(jì)學(xué)差異性分析結(jié)果。經(jīng)計(jì)算,實(shí)測值與預(yù)測值之間并無顯著的統(tǒng)計(jì)學(xué)差異。綜上所述,2種模型均可滿足模擬預(yù)報(bào)精度要求,相對而言,ABC-BP模型的預(yù)測效果更優(yōu)。 圖5 沖刷量實(shí)測值與預(yù)測值相關(guān)性 圖6 樣本相對誤差 表3 實(shí)測值與預(yù)測值t配對檢驗(yàn)結(jié)果 本文將人工蜂群算法(ABC)與BP 神經(jīng)網(wǎng)絡(luò)相結(jié)合,建立土壤侵蝕量預(yù)報(bào)模型,把求解BP 神經(jīng)網(wǎng)絡(luò)各層權(quán)值、閥值的過程轉(zhuǎn)化為蜜蜂尋找最佳蜜源的過程,以全國不同水土流失典型監(jiān)測點(diǎn)的土壤侵蝕量資料作為研究樣本,構(gòu)建了ABC-BP土壤侵蝕量預(yù)報(bào)模型。ABC-BP模型訓(xùn)練組的平均相對誤差為3.42%,訓(xùn)練效果均優(yōu)于BP模型;預(yù)測組的平均相對誤差為4.13%,預(yù)測效果均優(yōu)于BP模型。ABC-BP土壤侵蝕量預(yù)報(bào)模型可以實(shí)現(xiàn)全國水土流失典型監(jiān)測點(diǎn)土壤沖刷量的準(zhǔn)確預(yù)報(bào)。 中國的水土流失具有較為明顯的時(shí)空動(dòng)態(tài)分布特征,將水土流失監(jiān)測點(diǎn)的地域位置信息及隨時(shí)間的演變特征融入黑箱模型,以實(shí)現(xiàn)全國水土流失的時(shí)空動(dòng)態(tài)演變還有待進(jìn)一步深入研究。此外,多種預(yù)測模型的相互結(jié)合以及模擬算法的改進(jìn),也是進(jìn)一步的研究方向。 [1] 趙心暢, 徐洪霞. 溧陽抽水蓄能電站水土流失防治措施的分析[J]. 水力發(fā)電, 2010, 36(7): 22- 24. [2] 高照良, 穆興民. 黃土水蝕風(fēng)蝕交錯(cuò)區(qū)土地利用/覆被時(shí)空變化研究——以陜西省神木縣六道溝流域?yàn)槔齕J]. 水土保持學(xué)報(bào), 2004, 18(5): 146- 150. [3] 張洪江, 吳發(fā)啟, 胡春元, 等. 土壤侵蝕原理[M]. 北京: 中國林業(yè)出版社, 1999. [4] 金雁海, 柴建華, 朱智紅, 等. 內(nèi)蒙古黃土丘陵區(qū)坡面徑流及其影響因素研究[J]. 水土保持研究, 2006, 13(5): 292-295, 298. [5] 吳星鑫, 陸寶宏, 趙超, 等. 降雨徑流預(yù)報(bào)方案的設(shè)計(jì)研究[J]. 水力發(fā)電, 2014, 40(7): 18-21, 56. [6] 喻定芳, 戴全厚, 王慶海, 等. 北京地區(qū)等高草籬防治坡耕地水土流失效果[J]. 農(nóng)業(yè)工程學(xué)報(bào), 2010, 26(12): 89- 96.[7] 徐永年, 蘇曉波, 王向東, 等. 綠化植生帶在不同坡面上的水土保持效果[J]. 水利水電技術(shù), 2002, 33(7): 62- 64. [8] 王志偉, 艾釗, 張國慶, 等. 沂蒙山區(qū)坡面侵蝕過程[J]. 中國水土保持科學(xué), 2013, 11(5): 42- 47. [9] 金軻, 蔡典雄, 呂軍杰, 等. 耕作對坡耕地水土流失和冬小麥產(chǎn)量的影響[J]. 水土保持學(xué)報(bào), 2006, 20(4): 1- 5, 49. [10] 菊燕寧, 張壯志. 水電站建設(shè)中新增水土流失預(yù)測及防治措施研究[J]. 水利水電技術(shù), 2015, 46(9): 128- 134. [11] RENARD K G, FOSTER G R, WEESIES G A, et al. RUSLE: Revised universal soil loss equation[J]. Journal of soil and Water Conservation, 1991, 46(1): 30- 33. [12] 洪華生, 楊遠(yuǎn), 黃金良. 基于GIS和USLE的下莊小流域土壤侵蝕量預(yù)測研究[J]. 廈門大學(xué)學(xué)報(bào): 自然科學(xué)版, 2005, 44(5): 675- 679. [13] 蔡崇法, 丁樹文, 史志華, 等. 應(yīng)用USLE模型與地理信息系統(tǒng)IDRISI預(yù)測小流域土壤侵蝕量的研究[J]. 水土保持學(xué)報(bào), 2000, 14(2): 19- 24. [14] 段軍彪, 景旭, 上官周平. 基于遺傳算法的BP網(wǎng)絡(luò)在小流域侵蝕量預(yù)測中的應(yīng)用[J]. 西北農(nóng)業(yè)學(xué)報(bào), 2008, 17(2): 317- 320. [15] 胡亞萍, 董貝貝, 姜宏立, 等. SVR與BP神經(jīng)網(wǎng)絡(luò)對小流域次降雨侵蝕產(chǎn)沙預(yù)測結(jié)果的比較[J]. 北方環(huán)境, 2013, 29(1): 114- 117. [16] 楊勝天, 程紅光, 步青松, 等. 全國土壤侵蝕量估算及其在吸附態(tài)氮磷流失量匡算中的應(yīng)用[J]. 環(huán)境科學(xué)學(xué)報(bào), 2006, 26(3): 366- 374. [17] 祝贏, 章文波, 劉素紅, 等. 第一次全國水利普查侵蝕模數(shù)的批量計(jì)算方法——基于CSLE和GIS的土壤水蝕模數(shù)計(jì)算器設(shè)計(jì)與應(yīng)用[J]. 水土保持通報(bào), 2012, 32(5): 291- 295. [18] 趙曉麗, 張?jiān)鱿? 劉斌, 等. 基于遙感和GIS的全國土壤侵蝕動(dòng)態(tài)監(jiān)測方法研究[J]. 水土保持通報(bào), 2002, 22(4): 29- 32. [19] 秦全德, 程適, 李麗, 等. 人工蜂群算法研究綜述[J]. 智能系統(tǒng)學(xué)報(bào), 2014, 9(2): 127- 135. StudyonSoilErosionPredictionModelBasedonArtificialBeeColonyAlgorithmandBPNeuralNetwork WANG Quanwei, TANG Li (School of Hydraulic Science and Engineering, Taiyuan University of Technology, Taiyuan 030024, Shanxi, China) Taking the prediction of soil erosion amount as a goal, a BP neural network model with a topological structure of 5-7-1 is established according to the data from the Bulletin of River Sediment in China. In the model, the soil type, topography, slope, vegetation and rainfall are taken as input data and the soil erosion amount is taken as output. In view of the shortages of BP neural network method, the weight value and threshold value of BP neural network are optimized by using Artificial Bee Colony algorithm, and then the simulation effect of ABC-BP model is analyzed. It shows that the correlation coefficient and average relative error between simulation value and measured value are 0.9942 and 4.13% respectively. The ABC-BP neural network model has perfect consistency and higher prediction precision. soil and water loss; soil erosion amount; t-test; Artificial Bee Colony algorithm; BP neural network model S157 A 0559- 9342(2017)09- 0001- 04 2017- 03- 02 國家自然科學(xué)基金資助項(xiàng)目(51509176) 王權(quán)威(1992—),男,山西呂梁人,碩士研究生,主要從事水文及水資源研究;唐莉(通訊作者). (責(zé)任編輯楊 健)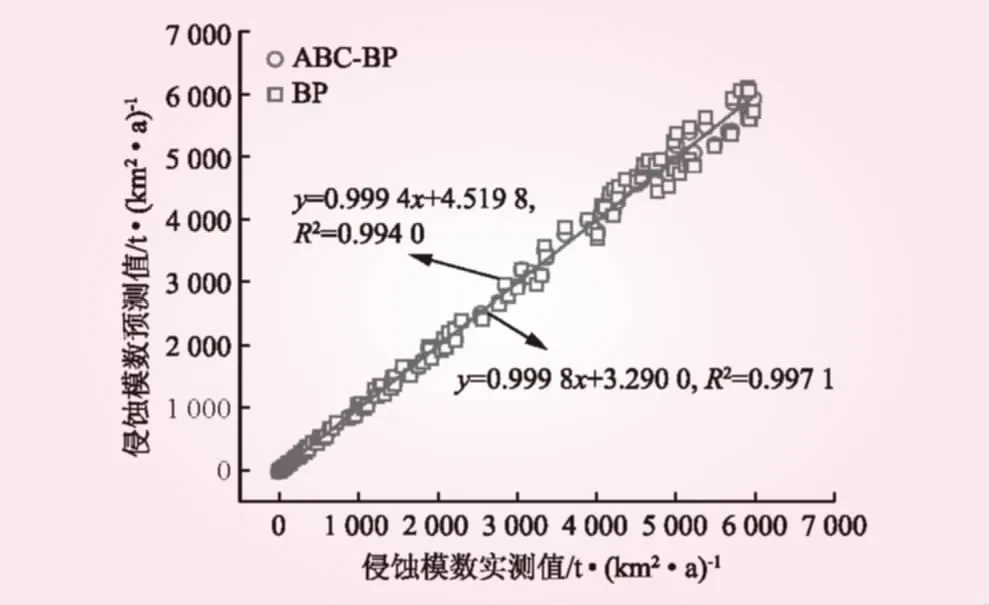

3.3 預(yù)測組模擬效果

4 結(jié) 語

猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
體育科技文獻(xiàn)通報(bào)(2022年3期)2022-05-23 13:46:54
天津外國語大學(xué)學(xué)報(bào)(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機(jī)設(shè)計(jì)與研究(2019年4期)2019-05-21 07:21:24
汽車工程學(xué)報(bào)(2017年2期)2017-07-05 08:13:02
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
