基于Isomap的樹增強樸素貝葉斯分類器的信用預(yù)測
2018-01-23 10:21:11葉曉楓許義仿
中州大學(xué)學(xué)報 2017年6期
葉曉楓,許義仿
(華北水利水電大學(xué) 數(shù)學(xué)與統(tǒng)計學(xué)院,鄭州 450046)
信用評估是如今金融機構(gòu)評估風(fēng)險的主要方法,主要包括三個步驟:明確信用影響因素;獲取影響因素的動態(tài)特征;構(gòu)建模型評估客戶信用等級[1-2]。當(dāng)前國內(nèi)外常用的信用評估方法和理論有數(shù)學(xué)規(guī)劃、統(tǒng)計方法、決策樹、專家系統(tǒng)、支持向量機、K近鄰方法、貝葉斯網(wǎng)絡(luò)、神經(jīng)網(wǎng)絡(luò)等。由于樸素貝葉斯具有較強的推理能力與穩(wěn)定分類效率,對缺失數(shù)據(jù)不敏感,與其他算法相比有較小的誤差率,因而被稱為是一種有效而簡單的概率分類方法。因現(xiàn)實世界大部分問題與樸素貝葉斯中的“獨立性假設(shè)”不符合,所以符合實際語義環(huán)境的分類器的改進起引了許多學(xué)者的研究興趣,樹增強樸素貝葉斯分類器[3](Tree Augmented Na?ve Bayesian Classifier,TAN)、通用貝葉斯網(wǎng)絡(luò)分類器 (General Bayesian Networks Classifier,GBN)、選擇性樸素貝葉斯分類器[4](Selective Na?ve Bayesian Classifier,SNB)、判別分析的樸素貝葉斯分類器[5](Discriminate Analysis Na?ve Bayesian Classifier,DANB)等都屬于這一類的改進。
TAN模型可以使用多項式時間復(fù)雜度找到最優(yōu)的增強樹貝葉斯網(wǎng)絡(luò)分類結(jié)構(gòu),這不但能確保計算的可行性,而且擴展了樸素貝葉斯分類器,放寬了樸素貝葉斯“各屬性相互獨立”限制條件。然而對于信用評估模型來說,信用評估數(shù)據(jù)具有非線性、高維度、特征多等特點,如何從高維數(shù)據(jù)中提取有效的特征直接關(guān)系著評估模型的準確率。
本文在現(xiàn)有的基礎(chǔ)上提出基于Isomap的樹增強樸素貝葉斯(Isomap-TAN)信用評估模型,將數(shù)據(jù)降維作為數(shù)據(jù)預(yù)處理中的一步,簡化樹增強樸素貝葉斯分類模型的結(jié)構(gòu),并選取1069家企業(yè)的財務(wù)指標數(shù)據(jù)進行實證分析,結(jié)果表明模型的分類精度得到改善。
1 模型介紹
1.1 Isomap 數(shù)據(jù)降維
Isomap算法以多維尺度變換(MDS)為基礎(chǔ)。Isomap的主要思想是:計算最近鄰圖中的最短距離得到測地距離,之后運用MDS算法獲得嵌入在高維空間中的低維光滑流形的表示[6]。
Isomap算法[7]步驟如下:
步驟1 計算樣本點之間的歐氏距離矩陣,建立鄰域關(guān)系圖G(V,E),對每個xi(i=1,2,…,N)計算其k近鄰xi1,xi2,…xik,記為Nj,以點xi為定點,歐氏距離d(xi,xij)為邊,建立鄰域關(guān)系圖G(V,E)。
確定近鄰點有2種方法:
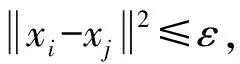
ii.利用k-近鄰法,事先給定近鄰個數(shù)k,然后確定近鄰點。
步驟2 計算測地距離D=(dij)n×n以達到近鄰關(guān)系圖G(V,E)中尋找最短路徑的目標,即
步驟3 對距離D=(dij)N×N運用古典MDS方法,求得最低維嵌入Y={y1,y2,…,yN}。
1.2 樹增強樸素貝葉斯分類模型
樹增強樸素貝葉斯分類模型(Tree Augmented Na?ve Bayesian Classifier,TAN)是定義在U*={A1,A2…An,C}上的有約束貝葉斯網(wǎng),Ai是離散屬性變量,C是類變量。Pa(C)=φ,Pa(Ai)至多有一個除C以外的其他屬性可以有一個相關(guān)的邊指向它[8]。如圖1所示,Geiger[9]表示了這類模型的證明過程。由Chow等[10]的學(xué)習(xí)樹結(jié)構(gòu)的貝葉斯網(wǎng)算法可知,若所有屬性都是離散屬性,那么可以構(gòu)造出學(xué)習(xí)TAN網(wǎng)絡(luò)結(jié)構(gòu)的算法。

圖1 樹增強樸素貝葉斯網(wǎng)絡(luò)結(jié)構(gòu)圖
TAN算法[11]描述如下:
(1)將訓(xùn)練樣本輸入并初始化變成統(tǒng)一的格式,然后定義屬性變量與類變量,且用離散化方法處理所有的連續(xù)變量。
(2)判斷。如果是分類任務(wù),則轉(zhuǎn)向(4);如果是訓(xùn)練任務(wù),則轉(zhuǎn)向(3)。
(3)成立貝葉斯概率表和TAN結(jié),然后檢驗所有的訓(xùn)練樣本。
i.當(dāng)i≠j時,計算每對屬性變量的條件互信息熵I(Xi;Xj|C),
ii.成立一個結(jié)點是X1,X2…Xn的加權(quán)完全無向圖,其中Xi,Xj之間的權(quán)重是I(Xi,Xj|C),i≠j。
iii.成立該無向圖的最大權(quán)重跨度樹。
iv.找到一個屬性結(jié)點當(dāng)作根節(jié)點,且令所有邊的方向都變?yōu)橛筛?jié)點指向外,這樣可以將無向圖變?yōu)橛邢驁D。
v.將類結(jié)點指向加入到有向圖里,然后增加從類結(jié)點指向Xi的弧,最后得到樹增強樸素貝葉斯網(wǎng)絡(luò)結(jié)構(gòu)。
vi.依據(jù)v產(chǎn)生的結(jié)構(gòu)圖,建立貝葉斯概率表。
(4)調(diào)用貝葉斯概率表,得出分類結(jié)果。
1.3 融合Isomap數(shù)據(jù)降維的樹增強樸素貝葉斯分類模型
運用Isomap融合樹增強樸素貝葉斯分類算法構(gòu)建信用評估模型的基本想法:用Isomap算法進行數(shù)據(jù)降維作為樹增強樸素貝葉斯分類算法的前置預(yù)處理系統(tǒng),對高維度、非線性的企業(yè)財務(wù)樣本進行降維處理,從而簡化樹增強樸素貝葉斯分類模型結(jié)構(gòu),縮短訓(xùn)練時間,提高分類精度。
1.3.1 指標體系的選擇
財務(wù)指標是指公司總結(jié)、評估財務(wù)狀況以及經(jīng)營成果的相對指標,通過分析公司的財務(wù)指標可以幫助銀行正確判斷和評價公司的經(jīng)濟效益,進而決定是否貸款給這些公司。為了判斷公司是否具備按時還貸的良好信用,幫助銀行對上市公司進行準確的貸款發(fā)放,財務(wù)指標的選擇就非常重要。
通過研究其他文獻選取的有效財務(wù)指標以及大公國際信用評級的主要財務(wù)指標,本文選取了上市公司的15個財務(wù)指標,指標分類為運營能力(流動資產(chǎn)周轉(zhuǎn)率、應(yīng)收賬款周轉(zhuǎn)率、存貨周轉(zhuǎn)率)、盈利能力(毛利率、凈資產(chǎn)收益率、每股主營業(yè)收入、凈利率)、償債能力指標(資產(chǎn)負債率、速動比率、流動比率、現(xiàn)金比率)、發(fā)展能力(股東權(quán)益增長率、凈資產(chǎn)增長率、每股收益增長率、總資產(chǎn)增長率)。
1.3.2 模型的構(gòu)建
圖2為融合Isomap數(shù)據(jù)降維的樹增強樸素貝葉斯分類模型架構(gòu)圖,算法描述如下:
(1)指標體系的構(gòu)建。在財務(wù)數(shù)據(jù)庫中,抽取能夠表示企業(yè)信用等級的指標。
(2)特征提取。降低特征向量的維數(shù)用Isomap算法。
(3)建立分類器。針對樣本分類的樹增強樸素貝葉斯算法。
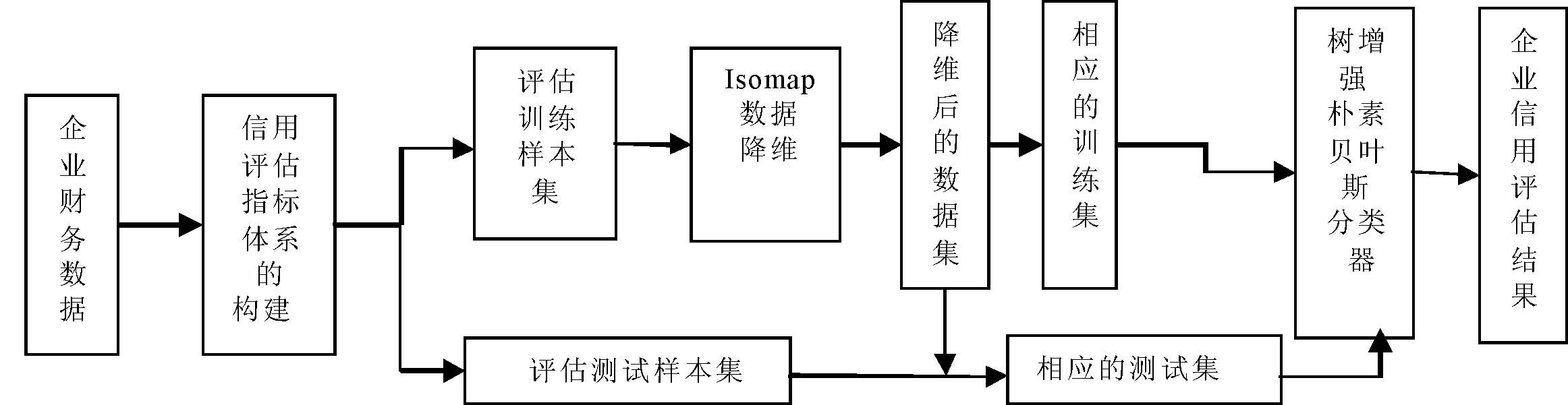
圖2 Isomap融合樹增強樸素貝葉斯的信用評估架構(gòu)圖
2 實驗
2.1 數(shù)據(jù)來源
本文根據(jù)在滬深交易所上市的1069家企業(yè)的財務(wù)指標數(shù)據(jù)進行實證研究,其全部實驗數(shù)據(jù)均選自新浪財經(jīng)網(wǎng)。從中選取了15個財務(wù)指標作為關(guān)鍵變量,并且這15個指標全是數(shù)值型屬性變量,類變量有兩個狀態(tài){good,bad},相應(yīng)地將全部企業(yè)劃分為兩類:good,即“具有信用好的條件”的企業(yè);bad,即“不具有信用好的條件”的企業(yè)。從1069個企業(yè)樣本中抽取769個作為訓(xùn)練集,剩下300個樣本作為測試集。
2.2 數(shù)據(jù)預(yù)處理
2.2.1 離差標準化
根據(jù)源數(shù)據(jù)呈現(xiàn)的特征,當(dāng)數(shù)據(jù)之間存在較大的變異程度,就考慮對源數(shù)據(jù)進行離差標準化。因為本文的量綱有很多不同并且數(shù)據(jù)差異很大,所以我們對源數(shù)據(jù)進行離差標準化,結(jié)果顯示數(shù)據(jù)大小標準化后比較集中,沒有變異程度很大的數(shù)據(jù)。本文在做離差標準化時,采用Matlab進行自主編程。
2.2.2 離散化
根據(jù)TAN 模型的要求,變量必須為離散型變量。所見到的信用評估問題中,經(jīng)常包含混合變量,其中混合變量包括連續(xù)性的屬性變量和離散型變量,因此對離散型變量需采用離散化方法。本文采用Fayyad[12]對連續(xù)變量進行預(yù)離散化,從而滿足TAN算法的要求。
2.2.3 利用Isomap降維
利用Isomap算法能夠?qū)Ω呔S特征數(shù)據(jù)進行低維描述,即用最近鄰居方法將k值(k=3,L30)代入,反復(fù)代入k值從而達到參數(shù)尋優(yōu),最后得到最小殘差的k值(這里k表示最近鄰居點個數(shù))。Isomap算法是在Matlab軟件上實現(xiàn)的,利用Matlab軟件可以得出不同k值的低維嵌入殘差圖,然后對由不同k值得到的一系列的殘差圖進行分析,得出k=4時是最小殘差,殘差圖如圖3所示。當(dāng)橫坐標維數(shù)(Isomap dimensionality)增加時,縱坐標殘差(Residual variance)是減小的,這就表示Isomap算法的使用能夠?qū)崿F(xiàn)數(shù)據(jù)降維,而數(shù)據(jù)“內(nèi)在”的真實維度是找到曲線上突然停止顯著下降的“肘”點來判斷的[13]。
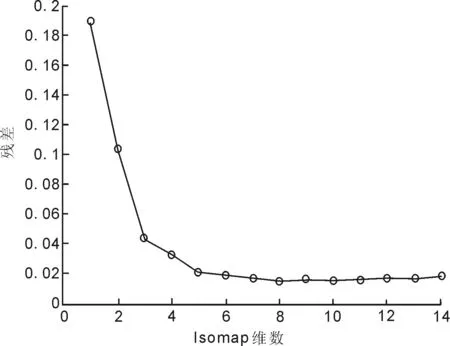
圖3 殘差和Isomap維數(shù)的關(guān)系
由圖3可以看出,當(dāng)維數(shù)d<3時,曲線明顯下降至“肘”點;當(dāng)維數(shù)d>3時,曲線變平緩而殘差大致相同。因此能夠得出結(jié)論:Isomap算法得到的降維后的真實“內(nèi)在”維數(shù)為d=4。
2.3 實驗結(jié)果及分析
為驗證Isomap-TAN評估模型的性能,選擇樸素貝葉斯模型和未降維的TAN模型進行對比分析,各模型的分類精度如表1所示。

表1 分類準確率測試結(jié)果 %
本文用R軟件編寫NB和TAN的分類程序。從表1可以看出,對不同的樣本,Isomap-TAN評估模型有一定的優(yōu)勢:當(dāng)評估good企業(yè)時,Isomap-TAN模型優(yōu)于TAN 模型;對bad企業(yè)進行評估時,Isomap-TAN模型優(yōu)于NB模型。就整體而言,本文提出的Isomap-TAN信用評估模型整體預(yù)測準確率為95.75%,高于樸素貝葉斯模型和樹增強樸素貝葉斯模型。這是因為經(jīng)過Isomap算法的降維處理,將原始數(shù)據(jù)從15維降到4維,減少了噪音的干擾,使柔和的重要特征指標體系更具有代表性,有效提高了分類的精度,而沒有經(jīng)過降維處理的樹增強樸素貝葉斯評估模型,可能由于指標過多,指標之間存在冗余,從而影響了其分類的精度。雖然在數(shù)值上提高的精度不是很大,但是在處理大樣本數(shù)據(jù)的時候,反映到具體數(shù)據(jù)中的差別有可能就會特別大。綜上所述,基于Isomap的樹增強樸素貝葉斯分類模型在經(jīng)過Isomap算法的降維處理后,不僅能簡化樹增強樸素貝葉斯分類模型的結(jié)構(gòu),降低模型的計算復(fù)雜度,而且提高了分類精度,在一定程度上可以幫助銀行對企業(yè)進行比較客觀的信用評估。
3 結(jié)語
建立科學(xué)的信用評估模型,能夠為研究人員提供重要的決策支持,減少損失。本文提出的Isomap-TAN模型結(jié)合Isomap和TAN的優(yōu)點,利用Isomap算法進行降維處理,從原始數(shù)據(jù)的15維變量降到了4維,將柔和的四維特征作為樹增強樸素貝葉斯模型的輸入特征,最終得到了Isomap-TAN信用評估模型。選取2015年1069家企業(yè)進行實驗分析,分析顯示此模型的分類精度比樸素貝葉斯與樹增強樸素貝葉斯模型高,這樣不但能夠?qū)somap算法運用在非線性的金融數(shù)據(jù)上,而且為銀行信用評估提供了一種新的思路。
[1]Li X L,Zhong Y.An Overview of personal oredit scoring:techniques and future work[J].International Journal of Intelligence Science,2012,2(4):181-189.
[2]肖進,劉敦虎,顧新,等.銀行客戶信用評估動態(tài)分類器集成選擇模型[J].管理科學(xué)學(xué)報,2015(3):114-126.
[3]Friedman N,Dan G,Goldszmidt M.Bayesian network classifiers[J].Machine Learning,1997,29(2):131-163.
[4]Langley P,Sage S.Induction of selective bayesian classifiers[C]// Tenth International Conference on Uncertainty in Artificial Intelligence.Morgan Kaufmann Publishers Inc,2013:399-406.
[5]李旭升,郭耀煌.基于多重判別分析的樸素貝葉斯分類器[J].信息與控制,2005,34(5):580-584.
[6]趙連偉,羅四維,趙艷敞,等.高維數(shù)據(jù)流形的低維嵌入及嵌入維數(shù)研究[J].軟件學(xué)報,2005,16(8):1423-1430.
[7]段志臣,芮小平,張立媛.基于流形學(xué)習(xí)的非線性維數(shù)約簡方法[J].數(shù)學(xué)的實踐與認識,2012,42(8):230-241.
[8]李旭升,郭春香,郭耀煌.擴展的樹增強樸素貝葉斯網(wǎng)絡(luò)信用評估模型[J].系統(tǒng)工程理論與實踐,2008,28(6):129-136.
[9]Geiger D.An entropy-based learning algorithm of Bayesian conditional trees[C]// Eighth International Conference on Uncertainty in Artificial Intelligence.Morgan Kaufmann Publishers Inc,1992:92-97.
[10]Lee C H L,Liu A,Chen W S.Pattern discovery of fuzzy time series for financial prediction[J].IEEE Transactions on Knowledge & Data Engineering,2006,18(5):613-625.
[11]郭春香,李旭升.貝葉斯網(wǎng)絡(luò)個人信用評估模型[J].系統(tǒng)管理學(xué)報,2009,18(3):249-254.
[12]Fayyad U M.Multi-interval discretization of continuous-valued attributes for classification learning[C]// International Joint Conference on Artificial Intelligence,1993:1022-1027.
[13]康莉.基于流形學(xué)習(xí)的分類算法及其應(yīng)用研究[D].西安:西安科技大學(xué),2010.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
