容錯處理器陣列的多邏輯列并行重構算法*
2018-01-26 02:46:06章子凱武繼剛姜文超劉竹松
計算機工程與科學 2018年1期
關鍵詞:物理
章子凱,武繼剛,姜文超,劉竹松
(廣東工業大學計算機學院,廣東 廣州 510006)
1 引言
隨著納米科技的不斷進步,超大規模集成電路VLSI(Very Large Scale Integration)的集成技術和制造工藝發展日趨成熟,單一芯片上可以集成的處理器單元也越來越多。這些芯片可以并行高速處理大量的數據信息,多核、眾核高性能計算機的計算能力得到了極大增強。然而,在集成密度呈指數倍增長的趨勢下,大規模集成電路制造和使用過程中處理器單元出現故障的概率也隨之增大,嚴重影響了電路的可靠性。所以,為片上網絡設計快速高效的容錯系統,是一個十分有意義的研究課題。
最常用的容錯技術為冗余重構方法(Redundancy Approach)和降階重構方法(Degradable Approach)。在冗余重構方法[1 - 5]中,原有處理器陣列上額外附加了預先固定數目的冗余處理器單元,當處理器陣列中某些常規單元出現故障時,冗余單元將會替代故障單元。這種方法重構出的目標陣列是固定的。雖然冗余方法比較容易實現,但是它通常需要足夠數量的備用處理器單元。一旦冗余處理器單元替代失敗,系統將會失效。在降階重構方法[6 - 8]中,陣列中不附加額外的處理器單元。當陣列中某些單元出現故障時,使用盡可能多的無故障單元來重構出一個目標陣列,最大限度地提高無故障處理器單元的利用率。在實際應用中可以根據需求來靈活調整目標陣列的大小,但重構后所得陣列規模通常小于初始物理陣列。
文獻[9]利用啟發式算法以及文獻[10]利用遺傳算法,將規模較小的物理陣列重構出一個最大的目標陣列。文獻[11]提出了基于啟發式策略和動態規劃思想的新技術,通過降低目標陣列中長連接的數目來減少通信鏈路的長度,從而在保持系統性能的前提下降低了功率的損耗。文獻[12]提出了一種新的技術來加速可降階的處理器陣列的重構過程。文獻[13]研究了在含有開關故障的情況下處理器陣列上的選路策略。
此外,文獻[14]將二維陣列上的重構問題推廣到三維陣列上,提出了一種三維處理器陣列上的貪心列選路算法。文獻[15]提出了三維的處理器陣列上的不回溯的重構算法,該方法在不丟失邏輯列的情況下,通過消減回溯的操作加速重構過程。
但是,這些重構技術大多數都是討論串行重構算法,對于并行重構算法的研究尚不多見。文獻[16]提出了基于多線程技術的并行重構算法,但是后繼線程必須在前一個線程選路深度達到一定條件時才能開始。文獻[17]提出了橫向劃分的基于分治策略的并行構造單一邏輯列的算法,使得重構速度有了很大的提升,加速比的提升尤為顯著。因為單條邏輯列的重構生成可能波及到物理陣列上的很大區域(類似于數據的強相關性)。所以邏輯列的并行生成以及邏輯列的歸并過程,會使得相關性很強的數據被重復讀取和擦除。事實上,在重構過程中由于沒有辦法判斷在物理陣列上能夠波及的具體范圍,往往需要把整個物理陣列都讀取進來。這種沒有細致考慮處理器之間依賴性的劃分方式,使得內存讀取數據冗余很多,總線通信量很大甚至會出現擁堵,運算過程不夠連貫,數據利用率較低。文獻[18] 采用硬件描述語言 VHDL(Very-High Speed Integrate Circuit Hardware Description Language)設計重構了文獻[16]中的算法,通過引腳協調相鄰選路過程之間的矛盾,使得該算法能夠多列同時向下選路,提高了重構效率。但是,該算法重構出的陣列不能保證是最大的目標陣列,而且算法擴展到大規模處理器陣列時,性能不佳。
本文提出了基于橫向分塊劃分的并行分治重構策略,在行穿越和列選路約束條件下,實現了最大的目標子陣列的重構,最大限度地保證了大規模集成電路中無故障處理器單元的利用率。本文主要貢獻如下:(1)提出了一種處理器陣列橫向分塊的重構算法,使得內存中的數據利用率提高,總線之間的通信量銳減,運算過程相對連貫,數據重復調用率降低。(2)實現了數據的分塊劃分與并行處理,執行過程中生成的邏輯子陣列也是可用陣列,根據目標陣列大小的需求,算法可以隨時終止。(3)實現了多條邏輯列的并行生成,與現有的算法相比,本文提出的算法是目前運算速度最快的并行重構算法。(4)算法具有良好的可擴展性,更加有利于大規模以及超大規模處理器陣列的重構。
2 容錯處理器陣列及重構算法回顧
物理處理器陣列是指多處理器之間以開關鏈接而成的網狀(Mesh)結構,開關功能的轉換用來實現物理陣列的邏輯重構。在芯片制造完成后,制造工序中不同環節的可能失誤,往往不能保證物理陣列中可用處理器的原始數量。特別是當這種高性能處理器架構應用到航空航天飛行器中時,發射與飛行中的各種不確定因素,不可避免地會引發處理器的故障。 容錯技術成為系統可靠性不可或缺的保障。由于陣列結構自身具有潛在的并行處理能力,處理器間的邏輯重構同樣可以實現高度的并行化,因此對其容錯重構的并行算法研究依然方興未艾。
在本文中,H表示一個m×n的物理處理器陣列,該陣列可能含有不能工作的處理器單元,這種處理器單元被稱為故障處理器單元。ρ表示H上故障處理器單元的比率,從而在物理處理器陣列中正常工作的處理器單元個數N=(1-ρ)·m·n。通過開關狀態變化而構造的無故障處理器陣列稱為邏輯陣列,記作T。H中出現的行(列)叫做物理行(列),在T中出現的行(列)叫做邏輯行(列)。
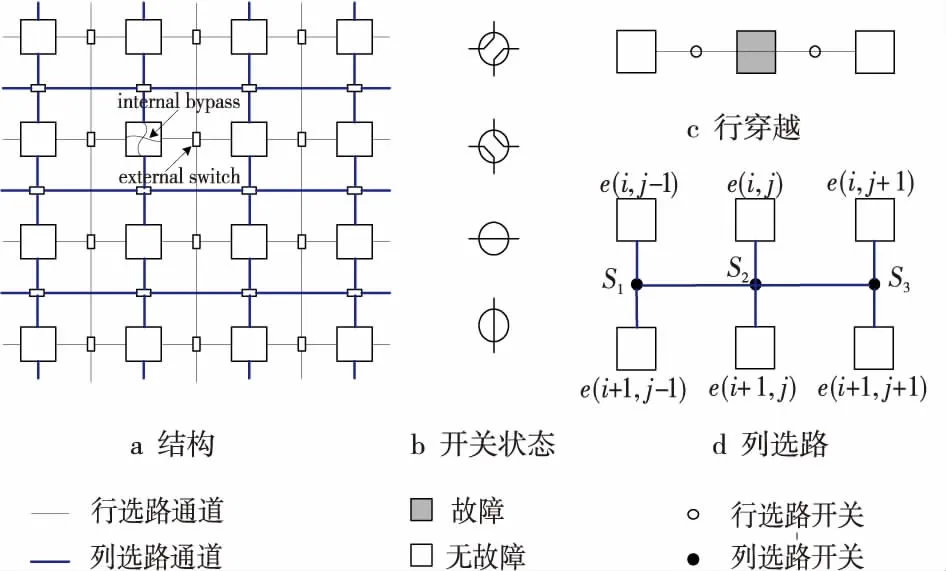
Figure 1 Architecture,switch states and routing schemes圖1 容錯結構、開關狀態和選路方式
圖1a給出了一個大小為4×4的物理處理器陣列。相鄰的處理器單元(字母e表示)通過開關和鏈路進行連接。每個開關具有4種狀態,如圖1b所示。圖1中,每個方框代表一個處理器單元,圓圈代表開關。其中灰色方框表示故障處理器單元,白色方框為無故障處理器單元。通過改變處理器單元間的開關狀態可使無故障處理器單元之間進行通信,從而使這種結構具有容錯性。處理器陣列重構算法通常使用兩種控制方案即行穿越和列選路得到邏輯陣列。如圖1c所示為行穿越方案,當e(i,j)是故障單元時,e(i,j-1)可以通過e(i,j)中的內部穿越線路和e(i,j+1)進行數據通信。在列選路中,當|j-j′| ≤d時,e(i,j)通過改變相關的開關狀態和e(i+1,j′)相連。一般來說,為了減小開關機制的復雜性以及物理實現的代價,應使d越小越好。本文沿用文獻[7,8]的規定,即:d≤1。本文定義adj(e)為處理器單元e通過開關狀態變化可以連接的列距離小于或等于1的下一行處理器單元的集合。如圖1d中所示的列選路,e(i,j)可以通過改變開關,連接第i+1行中的三個處理器單元e(i+1,j-1)、e(i+1,j)和e(i+1,j+1)中的一個。所以adj(e(i,j))={e(i+1,j-1),e(i+1,j),e(i+1,j+1)}。
處理器陣列的常用串行重構算法(記作GCR(Greedy Column Rerouting)[7,8])采用從左至右的方式選擇后繼單元構造邏輯列,每次迭代產生當前最左的邏輯列,這些邏輯列組成目標陣列。其迭代過程如下:
(1)選取位于第一個物理行上當前最左的無故障處理器單元u作為當前邏輯列的起始點。
(2)選取集合adj(u) 中當前最左的處理器單元v作為處理器單元u的后繼點。
在迭代過程中的每一步,GCR算法都試圖將當前處理器單元v與位于集合adj(v)中最左的且沒有被檢測過的處理器單元相連。一旦v在集合adj(v)中找不到可連接的后繼單元,即無法通過處理器單元v連接后面的節點形成邏輯列,則算法將回溯到當前處理器單元v的前驅處理器單元w,選擇位于集合adj(w)-v中最左的處理器單元作為w的后繼點。上述迭代過程持續進行直到以下兩種情況:(1)當前位于第k-1行的處理器單元v已與位于最后一行(第k行)上的處理器單元相連;(2)算法回溯到第一行中的某個單元u。GCR算法以從左至右、從上到下的方式構造當前最左邏輯列,直到物理陣列中無法再生成新的邏輯列。GCR算法的詳細描述見文獻[8]。
目前,最新的并行重構算法是文獻[15]提出的PRDC(Parallel Reconfiguration algorithm based on Divide-and -Conquer)算法,其設計思想可遞歸地描述如下:
在每條邏輯列的生成過程中,將整個邏輯列視作位于上半個物理陣列中的邏輯列段lup與位于下半個物理陣列的邏輯列段ldown的‘歸并’對接的結果。這種歸并對接操作記作++,即l=lup++ldown。算法遞歸地生成lup與ldown,直到邏輯列段的長度為1時終止。多個邏輯列段的歸并使用同樣數目的處理器實現同步并行。PDRC算法的詳細描述見文獻[15]。
目前,PRDC算法對單條邏輯列的生成實現了并行化,而對于最大目標陣列的多條邏輯列同步并行生成,沒有相關算法提出。本文提出的算法就是用來解決多條邏輯列并行生成最大目標陣列問題。
3 陣列分塊與多列并行重構
處理器陣列結構本身適合分治算法的應用,它可以被劃分成具有相似規模的子塊,子塊上可以同時進行選路操作,從而提高邏輯陣列的重構速度。基于這個原理,利用分治法潛在的良好并行性,本文提出了處理器陣列分塊劃分的多邏輯列并行重構算法(記為 MPGCR(Multple Columns Parallel Greedy Reconfiguration)算法)。首先,對整個物理陣列進行橫向分塊劃分;然后在劃分后形成的子塊上同時采用GCR算法進行選路重構,得到邏輯子陣列;最后并行歸并這些邏輯子陣列,得到目標邏輯陣列。
MPGCR算法分為三個過程,分別是陣列分塊劃分、子陣列重構以及子陣列的歸并。具體過程介紹如下。
3.1 陣列分塊劃分與子陣列重構
在陣列分塊劃分過程中,初始物理陣列均勻劃分成多個物理子陣列。為了準確描述本文的算法,我們對此過程給出如下相關定義。
在子陣列重構過程中,物理子陣列Bi重構出的邏輯子陣列用Ti表示。將p個物理子陣列B0,B1,B2,…,Bp-1分配給p處理器,并行使用GCR生成相應的邏輯子陣列T0,T1,T2,…,Tp-1。
3.2 子陣列的歸并
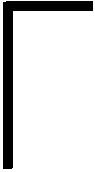
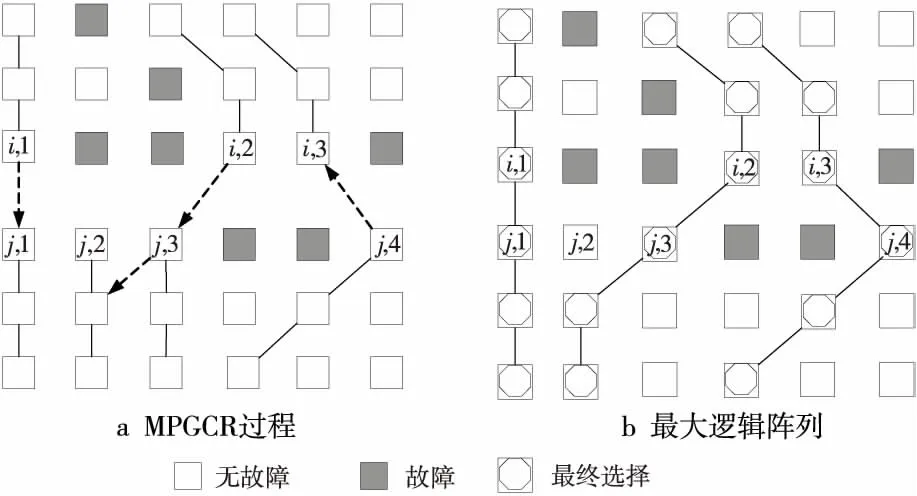
圖2給出了4個物理子陣列B0,B1,B2,B3的歸并過程。首先,在初次歸并過程中,物理子陣列所對應的邏輯子陣列T0,T1,T2,T3被分成{T0,T1},{T2,T3}兩組,同時進行子陣列歸并,得到更新的目標子陣列T0、T1,然后進行第二次歸并,得到目標陣列T0。
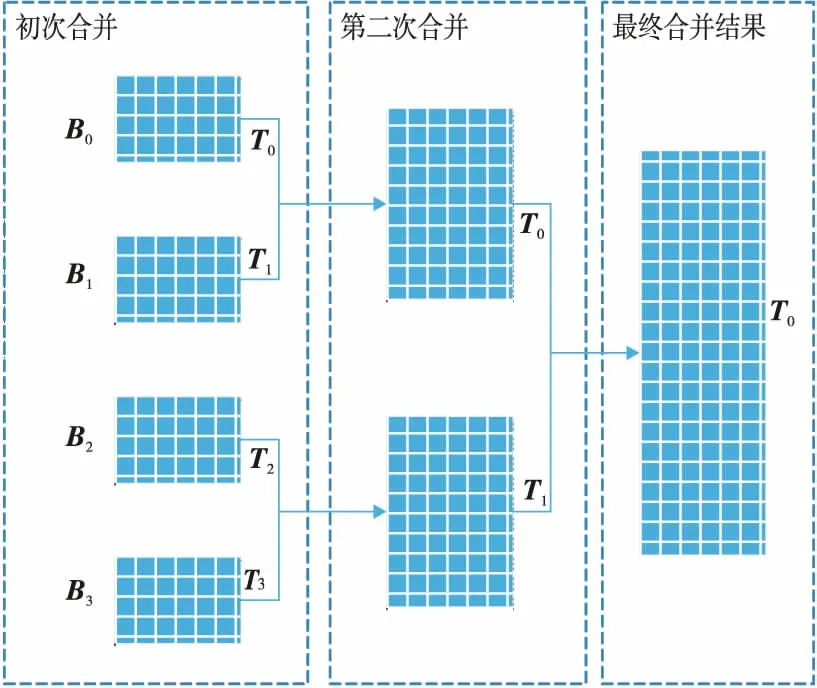
Figure 2 Procedure of merge圖2 歸并的整體過程
在兩個子陣列的具體歸并過程中,設相鄰邏輯處理器子陣列為Ti、Tj(j=i+1),這兩個子陣列上邏輯列段的集合分別為Ci、Cj。設Ci、Cj中分別有x、y個邏輯列段,那么對應的Ci= {Ci,0,Ci,1,Ci.2,…,Ci,x-1},Cj= {Cj,0,Cj,1,Cj,2,…,Cj,y-1}。令處理器單元ei,x、ej,y分別為邏輯列Ci,x、Cj,y的結束斷點和開始節點。col(ei,x)、col(ej,y)表示的是邏輯陣列端點ei,x、ej,y所對應的物理陣列的列數。 在歸并Ti、Tj的過程中,我們從集合Ci、Cj的最左邏輯列段開始,進行選路操作,歸并邏輯列。遞歸執行這個歸并過程,直到沒有目標子邏輯列生成為止,最終得到目標邏輯子陣列。
具體目標邏輯子陣列的選路歸并操作過程,通過對col(ei,x)、col(ej,y)大小的比較,可分為如下三種情況:
(1)直接選路。
若col(ei,x)=col(ej,y),則這兩條邏輯列可以通過直接相連,生成一條邏輯列。然后,選擇當前已更新邏輯陣列的最左邏輯列段,進行下一條目標邏輯列的生成。
如圖3所示,col(ei,1)=col(ej,1),所以在選路時,ei,1與ej,1直接相連,組成了一個大的邏輯列。然后通過對ei,1與ej,2的判斷進行下一步選路操作。
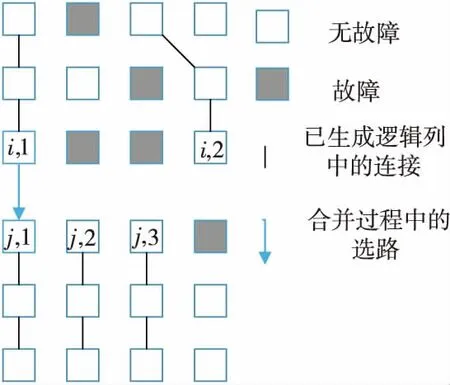
Figure 3 Direct_Routing圖3 子塊直接對接方式
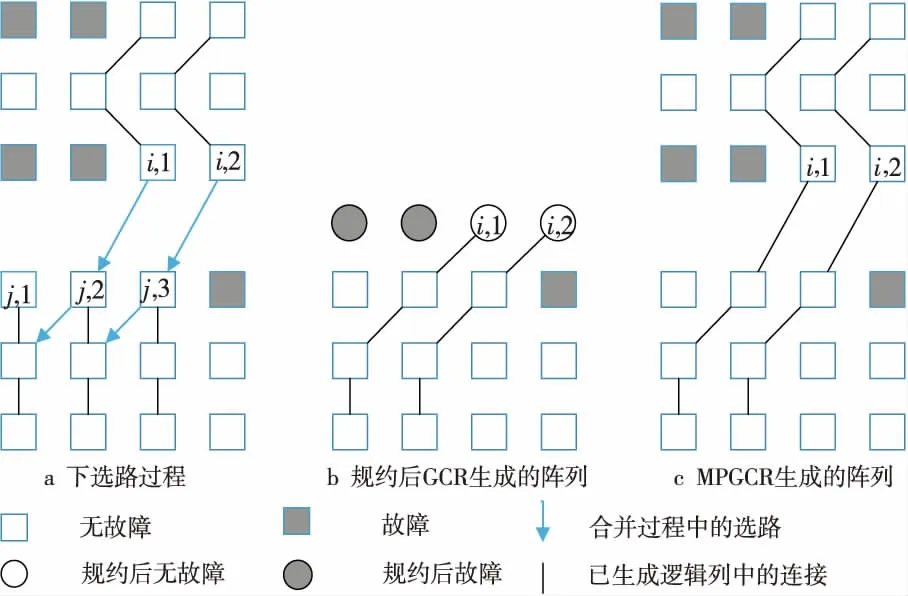
(2)下選路。
若col(ei,x) >col(ej,y),則從ei,x開始通過GCR算法進行下選路。下選路又分為三種情況:
①從ei,x開始選路可以到達Cj,y,則通過這條路徑生成一條邏輯列。然后,選擇當前已更新邏輯陣列的最左邏輯列段,進行下一條目標邏輯列的生成。
如圖4a所示,從ei,1點進行GCR選路,與Cj,1上的點有連接,組成了一條大的邏輯列。然后通過對ei,2與ej,2的判斷進行下一步選路操作。
②從ei,x開始選路,若不能到達Cj,y,但可以到達Cj,z(假設在邏輯列段中,能夠連接的最左邏輯列的列數為z),則通過這條路徑生成一條邏輯列。然后,選擇當前已更新邏輯陣列的最左邏輯列段,進行下一條目標邏輯列的生成。
如圖4b所示,從ei,1點進行GCR選路,但是最終沒能與Cj,1上的點有連接,而是連接到Cj,2上的點,形成了一條大的邏輯列。然后通過對ei,2與ej,3的判斷進行下一步選路操作。
③從ei,x開始選路,未能到達集合Cj中的任何一個邏輯列段,則不能生成邏輯列。然后,選擇當前已更新邏輯陣列的最左邏輯列段,進行下一條目標邏輯列的生成。
如圖4c所示,從ei,1點進行GCR選路,但是最終沒能與任何邏輯列上的點有連接,形不成大的邏輯列。然后通過判斷ei,2與ej,2進行下一步選路操作。
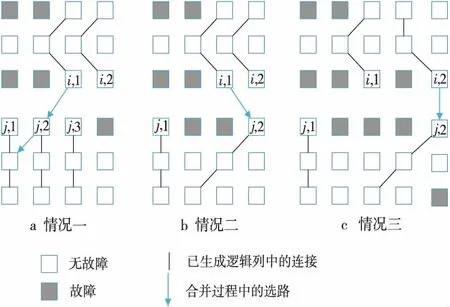
Figure 4 Down_Routing圖4 子塊下選路方式
(3)上選路。
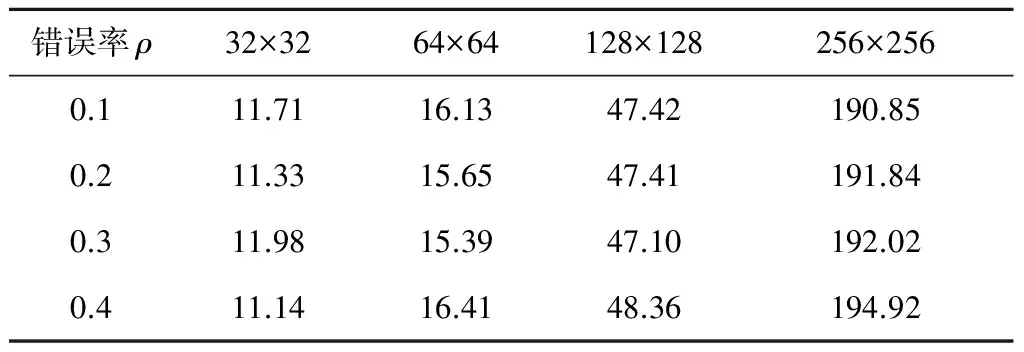
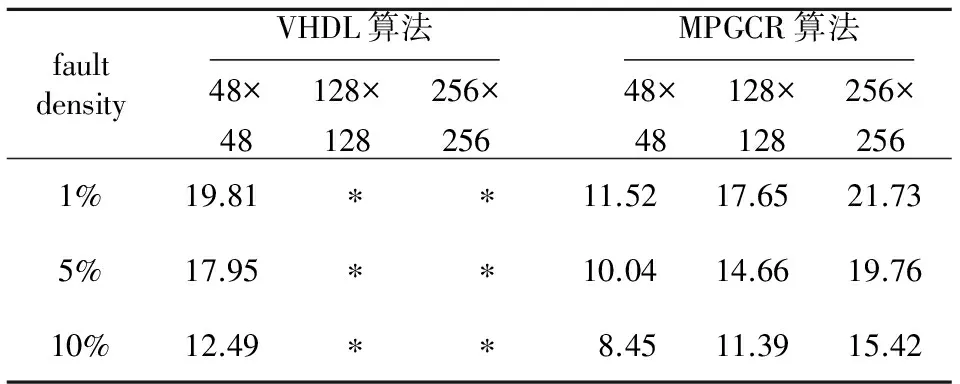
若col(ei,x) ①從ej,y開始選路與Ci,x相交,則生成一條邏輯列。然后,選擇當前已更新邏輯陣列的最左邏輯列段,進行下一條目標邏輯列的生成。 如圖5a所示,從ej,1點進行GCR選路,與Ci,1上的點有連接,組成了一條大的邏輯列。然后通過對ei,2與ej,2的判斷進行下一步選路操作。 ②從ej,y開始選路,若不能到達Ci,x,但可以到達Ci,z(假設在邏輯列段中,能夠連接的最左邏輯列的列數為z),則通過這條路徑生成一條邏輯列。然后,選擇當前已更新邏輯陣列的最左邏輯列段,進行下一條目標邏輯列的生成。 如圖5b所示,從ej,1點進行GCR選路,但是最終沒能與Ci,1上的點有連接,而是連接到Ci,2上的點,形成了一條大的邏輯列。然后通過判斷ei,3與ej,2進行下一步選路操作。 ③從ej,y開始選路,未能到達集合Ci中的任何一個邏輯列段,則不能生成邏輯列。然后,選擇當前已更新邏輯陣列的最左邏輯列段,進行下一條目標邏輯列的生成。 如圖5c所示,從ej,1點進行GCR選路,但是最終沒能與任何邏輯列上的點有連接,形不成大的邏輯列。然后通過判斷ei,2與ej,2進行下一步選路操作。 Figure 5 Up_Routing圖5 子塊上選路方式 算法的偽代碼描述如下: Input:H: physical array ofm×n; B(B0,B1,B2,…,Bp-1):divided block list; T(T0,T1,T2,…,Tp-1):reconstructed subarrays list; p: number of processors. Output:T0: Target array. Algorithm MPGCR(H,B,p) begin /* divideHinto subarrays:B0,B1,B2,…,Bp-1*/ 1. If 0≤i≤p-1 then Bi=(Hi*k,Hi*k+1,Hi*k+2,…,H(i+1 )*k-1)T else Bp-1=(H(p-1)*k,H(p-1)*k+1,H(p-1)*k+2,…,Hm-1)T; /* reconstruct subarrays in parallel */ 2. for each processoriin {0,1,…,p-1} parallel do /* call GCR onBito reconstructTi*/ Ti←GCR(Bi); /* Conquer:block routing to reconstruct final logical array */ 3.num←p; 4. while (num>1) do begin Ti← Merge (T2i,T2i+1); end 5. return; end 算法中的子陣列歸并過程的偽代碼描述如下: Input:H: Original physical array; Ti、Tj: logical arrays.(j=i+1)。 Output:Ti/2: merged logical array。 Procedure Merge(Ti,Tj) begin 1.Ci←The set of logical segments inTi; 2.Cj←The set of logical segments inTj; 3.N←The size of listCi; 4.M←The size of listCj; /*ei,x、ej,yare the end PE and the start PE ofCi,x、Cj,y,respectively*/ 5. while (x ifcol(ei,x)=col(ej,y) then Direct_Routeing(H,ei,x,ej,y);/*直接選路*/ else ifcol(ei,x)>col(ej,y) then Down_Routeing(H,ei,x,Cj,y);/*下選路*/ else Up_Routeing(H,ej,y,Ci,x);/*上選路*/ end 為了更好地理解MPGCR算法,本文以一個6×6的處理器陣列為例,如圖6所示,在2核處理器運行環境下,展示算法并行構造最大邏輯陣列的過程。 首先,整個物理陣列被均勻地分給了2個處理器,每個處理器分得一個3×6的子陣列。然后,2個處理器同時調用GCR算法,構建出對應的邏輯子陣列。如圖6a所示,上半部分構建出了3×3的邏輯子陣列;下半部分構建出了3×4的邏輯子陣列。 然后對邏輯子陣列的首尾單元進行標記,進而進行合并操作判斷。 處理器單元ei,1,ei,2,ei,3,ej,1,ej,2,ej,3,ej,4分別對應所在邏輯列的列尾單元和列首單元。因為col(ei,1)=col(ej,1),所以直接選路,即ei,1與ej,1直接相連。然后判斷ei,2和ej,2,因為col(ei,2)>col(ej,2),所以實施下選路,運用GCR算法從ei,2選路直到遇到Cj,2上的處理器單元為止。因為ei,2連到邏輯列Cj,2和Cj,3,所以接下來判斷ei,3與ej,4。因為col(ei,3) 在合并過程結束后,我們就可以得到如圖6b所示的6×3最大邏輯陣列。 Figure 6 Construction process of the logical array圖6 邏輯陣列的構造過程 本文提出以下引理和定理來證明MPGCR算法和GCR算法能生成同樣列數的邏輯陣列(即最大邏輯陣列)。 引理1對于兩個陣列,如果它們重構出的邏輯列數分別是x、y,那么將這兩個陣列歸并后重構出的邏輯列數不超過min{x,y}。 引理2子塊上選路或下選路過程重構出的邏輯列個數與物理陣列歸并后重構出的邏輯列個數相同。 證明對于兩個相鄰物理子塊Bi、Bj(j=i+1),假設Ci,x、Cj,y是歸并過程某一時刻的邏輯列段。假設在下選路過程中,col(Ci,x)>col(Cj,y)。那么下一步是從Ci,x的下端點ei,x進行GCR選路。由于引理1,我們可以將Ci,x邏輯列段規約成下端點ei,x,這個規約并不會減少邏輯列數。子物理塊Bi、Bj可以歸并成物理子塊Bi/2,在這個新的物理塊中產生的邏輯列數與我們規約出的新的物理陣列產生的邏輯列數顯然是相同的。 □ 如圖7a展示出了兩個物理子塊Bi、Bj的下選路過程。處理器單元ei,1、ei,2分別是邏輯列段Ci,1、Ci,2的下端點。我們將邏輯列段Ci,1、Ci,2規約成端點,沒有邏輯列生成的端點都認為是壞點。如圖7b展示出了規約形成的物理陣列,經過GCR選路,得到2條邏輯列。圖7c是兩個物理子塊Bi、Bj歸并得到的物理陣列,經過GCR選路,也得到了2條邏輯列。 上選路是下選路的反向過程。同理可知,上選路也會生成相同列數的邏輯陣列。所以,子塊上選路或下選路過程重構出的邏輯列個數與物理陣列歸并后重構出的邏輯列個數相同。 Figure 7 Logical column reduce and Down_Routing圖7 邏輯列歸約與下選路 定理1MPGCR算法與GCR算法重構出同樣列數的目標邏輯陣列。 證明在MPGCR算法中,子陣列劃分階段H被分成B0,B1,B2,…,Bp-1,這個過程沒有進行任何重構選路操作,不會影響重構產生邏輯列的個數。子陣列重構階段,p個子塊調用GCR算法并行重構生成p個邏輯子陣列,這個過程中的運算只涉及到GCR算法,所以對生成邏輯列個數也不會產生影響。在子陣列歸并階段,進行了logp次歸并操作。在每一次的歸并選路過程中,由引理2可知,上選路和下選路都不會減少最終生成的邏輯列數。子塊直接對接的情況更不會對生成的邏輯列數產生影響。所以,MPGCR算法與GCR算法重構出同樣列數的目標邏輯陣列。 □ 現在我們對算法的時間復雜度進行如下分析:假設陣列規模為m×n,并行重構過程有p個處理器,初始物理陣列被分成p個基本物理子陣列。由p個處理器并行操作,劃分過程花費O(1)時間。每個子陣列重構花費時間是O(m·n/p)。最壞情況下,兩個具體子陣列歸并過程中,每生成一條目標邏輯子列,需要經過m/p(子陣列的行數)次選路操作。在這種情況下,兩個具體子陣列歸并,最多需要n/(m/p)次目標邏輯子列生成。子陣列的歸并總共需進行logp次,所以整個歸并過程需要花費時間O((m/p·n)(p/m) logp)=O(nlogp)。 因此,算法的時間復雜度是O(m·n/p+nlogp)。 本文的編程語言為C++,實驗環境是AMD A10 PRO-7800B R7,3.50 GHz CPU,4.00 GB RAM,Visual C++ 2010 開發平臺。由于并行運算的速度很快,本實驗對算法運行時間的測量采用了對程序運行的時鐘周期計數的方法,單位為μs。實驗結果為測量50次隨機實例得到的平均值。 由于文獻[15]中的PRDC算法是目前加速比最高的并行算法,且能夠生成最大目標邏輯陣列,所以本文提出的算法與PRDC算法進行對比。為客觀評價算法的性能,本文采用與文獻[15]相同的數據集構建方法,在初始化陣列時使用隨機方法產生故障單元,從而保證了實驗數據的合理性以及實驗結果的可對比性。 從圖8可以看出,當陣列錯誤率為0.4,可用處理器數為2時,MPGCR算法明顯快于PRDC算法,并且陣列越大,新算法相對PRDC算法的運算加速,在時間上就越明顯。而且,在處理器陣列規模是64×64時,算法性能改進幅度最大。具體來說,在處理器陣列規模是32×32時,新算法相對于PRDC算法快了0.34μs,將PRDC算法改進了2.83%;在處理器陣列規模是64×64時,新算法相對于PRDC算法快了13.91μs,將PRDC算法改進了39.55%;在處理器陣列規模是128×128時,新算法相對于PRDC算法快了16.9μs,將PRDC算法改進了17.53%;在處理器陣列規模是256×256時,新算法相對于PRDC算法快了55.95μs,將PRDC算法改進了13.96%。 Figure 8 Comparisons of running time on using cores圖8 核數為2,算法運算時間對比 陣列越大,新算法相對PRDC算法的運算加速,在時間上就越明顯。這是因為在可用處理器規模確定的情況下,處理器陣列越大,新算法比PRDC算法分攤到每一個處理器上的通信代價就會越小,處理器每一次運算所用數據中冗余的數據量也會越小。這個實驗說明,本文所提出的算法更加適合大規模的處理器陣列重構。 在處理器陣列規模是64×64時,算法性能改進幅度最大。這是因為,現有處理器緩存結構對并行計算存在一個通信瓶頸問題。本文提出的新算法,雖然相對于PRDC算法來說減少了總線通信、數據冗余,但是邏輯單列生成對多條物理列的依賴性,處理器緩存結構的現狀,是不可改變的。所以,新算法在2核運算,處理器陣列規模是64×64時,達到通信瓶頸。當陣列規模更大的時候,通信上會有一定阻塞,影響了性能的穩定性。所以,在處理器陣列規模是64×64時,算法性能改進幅度最大。 圖9反映了在陣列錯誤率為0.4時,新、舊算法分別在4核與8核上的運行時間對比。它們的共同規律就是新算法在較大陣列上比原算法在運行時間上改進得相對明顯。這說明本文提出的算法具有良好的可擴展性。 Figure 9 Comparisons of running time using 4 cores & 8 cores圖9 核數為4和8時,算法運算時間對比 Figure 10 Comparison of running time on 128×128 arrays圖10 在128×128陣列上,算法運算時間對比 圖10展示了陣列大小固定為128×128,錯誤率為0.4時,可用處理器數目變化對運行時間的影響。當可用處理器數目為2時,運算速度顯著快于PRDC算法。隨著參與運算的處理器的增多,本文算法相對于PRDC算法的改進就越少。具體來說,在參與并行重構的處理器數目為2時,MPGCR算法相對于PRDC算法的加速為 17.5%;在參與并行重構的處理器數目為4時,MPGCR算法相對于PRDC算法的加速為 10.9%;參與并行重構的處理器數目為8時,MPGCR算法相對于PRDC算法的加速為 8.2%。 這是因為,在陣列大小固定的情況下,隨著可用處理器數目增多,新算法分攤到每一個處理器上的通信代價就會變小,每一個參與并行運算的處理器每一次運算所用數據中冗余的數據量也會變小。 表1是本文MPGCR算法在參與并行重構運算的處理器數目為4,陣列錯誤率不同且陣列大小不同時,重構陣列所耗費的時間。從表1中可以看出,在不同規模的陣列中,新算法的運行時間對錯誤率并不敏感。這是因為,算法運行時間包括運算時間以及通信代價,因為通信所耗費的時間在整個運行時間中占據了較大的比例。 Table 1 Running time of MPGCR using4 cores on H128×128 為了更好地展示MPGCR算法的優缺點,我們將其與VHDL并行重構算法[18]進行性能比較。雖然VHDL并行重構算法的擴展性欠佳,也不能確保得到最大邏輯陣列,但是該算法在小規模處理器陣列上的重構速度較快,而且能很好地應用于FPGA并行運算。由文獻[18]可知,VHDL并行重構算法在物理陣列為48×48時,加速比達到最大。由于VHDL并行重構算法重構大小為48×48的物理陣列時,使用24個核(實驗所用的CPU支持單核雙線程)參與并行運算,最能直觀地反映出VHDL算法的并行特性。因此,我們計算了在24核并行運算時,MPGCR算法在不同規模處理器陣列下所能達到的加速比,并引用VHDL并行重構算法的結果進行對比。表2是MPGCR算法與VHDL并行重構算法,在24核并行運算時的加速比。 Table 2 Speed up of MPGCR and VHDL parallelreconfiguration algoritym using 24 cores 表2中“*”表示實驗在當前條件下不能得到數據。 從表2可以看出,在小規模處理器陣列上,MPGCR算法的加速比低于VHDL并行重構算法,這是因為VHDL算法是啟發式算法,不能保證得到最大的邏輯子陣列。MPGCR算法具有良好的可擴展性,能夠在較大陣列上得到良好的加速比,加速比隨著陣列大小的增加而呈現上升趨勢,并且能夠確保得到最大的邏輯子陣列。 本文根據網格開關連接處理器陣列結構的潛在并行性,提出了一種新的處理器陣列劃分方式,使用分治法,設計了一種可以多條邏輯列并行重構的算法。算法在有很好并行性的同時,減少了通信以及計算的數據冗余。實驗結果表明,與現有的并行重構算法相比,MPGCR算法同樣能生成最大規模的目標陣列并且當物理陣列大小為64×64,錯誤率為0.4,2核并行運算時,與現有算法對比,新算法并行重構速度提高了39.5%。 [1] Lam C W H,Li H F,Jayakumar R.A study of two approaches for reconfiguring fault-tolerant systolic arrays[J].IEEE Transactions on Computers,1989,38(6):833-844. [2] Chen Y Y, Upadhyaya S J,Cheng C H.A comprehensive reconfiguration scheme for fault-tolerant VLSI/WSI array processors[J].IEEE Transactions on Computers,1997,46(12):1363-1371. [3] Zhang L.Fault-tolerant meshes with small degree[J].IEEE Transactions on Computers,2002,51(5):553-560. [4] Horita T, Takanami I. Fault-tolerant processor arrays based on the 1 1/2-track switches with flexible spare distributions[J].IEEE Transactions on Computers,2000,49(6):542-552. [5] Zhang L,Han Y,Xu Q,et al.On topology reconfiguration for defect-tolerant NoC-based homogeneous manycore systems[J].IEEE Transactions on Very Large Scale Integration Systems,2009,17(9):1173-1186. [6] Kuo S Y,Chen I Y.Efficient reconfiguration algorithms for degradable VLSI/WSI arrays[J].IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems,2006,11(10):1289-1300. [7] Low C P,Leong H W.On the reconfiguration of degradable VLSI/WSI arrays[J].IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems,1997,16(10):1213-1221. [8] Low C P.An efficient reconfiguration algorithm for degradable VLSI/WSI arrays[J].IEEE Transactions on Computers,2000,49(6):553-559. [9] Fukushi M, Horiguchi S.Reconfiguration algorithm for degradable processor arrays based on row and column rerouting[C]∥Proc of the 19th IEEE International Symposium on Defect and Fault Tolerance in VLSI Systems,2004:496-504. [10] Fukushi M, Fukushima Y,Horiguchi S.A genetic approach for the reconfiguration of degradable processor arrays[C]∥Proc of IEEE International Symposium on Defect & Fault Tolerance in VLSI & Nanotechnology Systems,2005:63-71. [11] Jigang W, Srikanthan T. Reconfiguration algorithms for power efficient VLSI subarrays with four-port switches[J].IEEE Transactions on Computers,2006,55(3):243-253. [12] Jigang W,Srikanthan T,Han X.Preprocessing and partial rerouting techniques for accelerating reconfiguration of degradable VLSI arrays[J].IEEE Transactions on Very Large Scale Integration Systems,2010,18(2):315-319. [13] Zhu Y,Wu J,Lam S K,et al.Reconfiguration algorithms for degradable VLSI arrays with switch faults[C]∥Proc of IEEE International Conference on Parallel & Distributed Systems,2012:356-361. [14] Shen Y, Wu J,Jiang G.Multithread reconfiguration algorithm for mesh-connected processor arrays[C]∥Proc of International Conference on Parallel and Distributed Computing,Applications and Technologies,2012:659-663. [15] Wu J, Jiang G,Shen Y,et al.Parallel reconfiguration algorithms for mesh-connected processor arrays[J].Journal of Supercomputing,2014,69(2):610-628. [16] Jiang G,Wu J,Sun J.Efficient reconfiguration algorithms for communication-aware three-dimensional processor arrays[J].Parallel Computing,2013,39(9):490-503. [17] Jiang G,Wu J,Sun J.Non-backtracking reconfiguration algorithm for three-dimensional VLSI arrays[C]∥Proc of 2013 International Conference on Parallel and Distributed Systems,2012:362-367. [18] Zhou Mei-ting,Wu Ji-gang,Jiang Gui-yuan.Parallel reconfiguration for processor arrays with faults utilizing VHDL[J].Journal of Chinese Computer Systems,2015,36(2):375-380.(in Chinese) 附中文參考文獻: [18] 周美婷,武繼剛,姜桂圓.容錯處理器陣列的并行重構及VHDL實現[J].小型微型計算機系統,2015,36(2):375-380.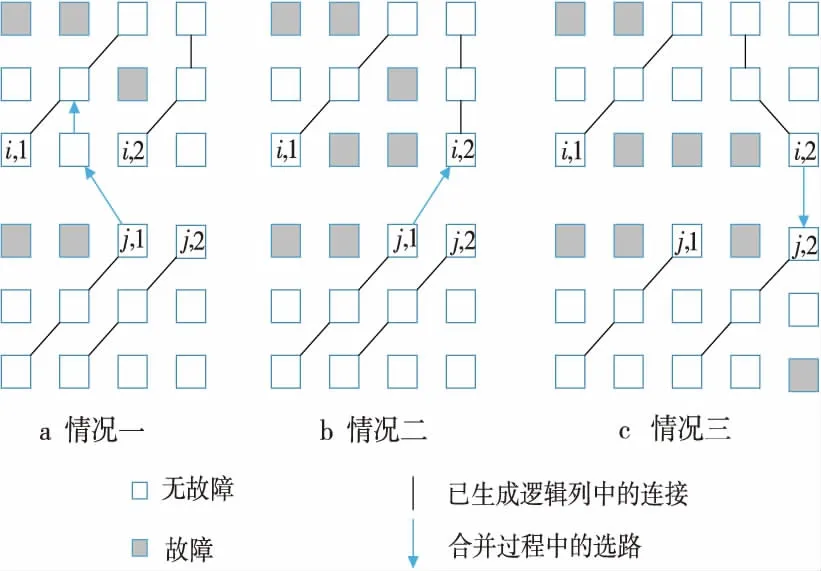
3.3 算法分析
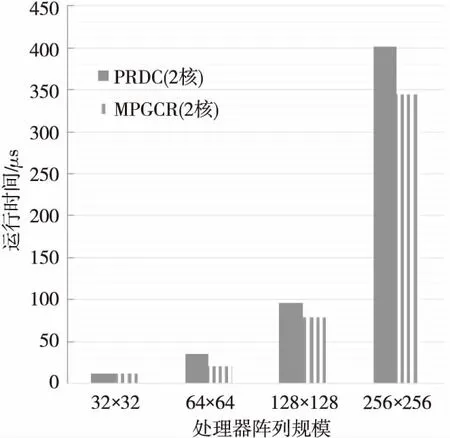
4 實驗結果與分析
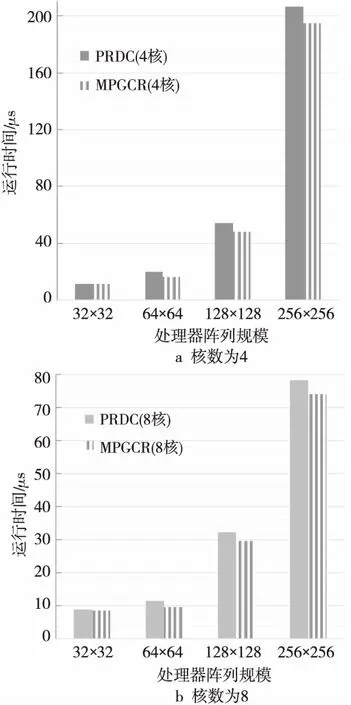
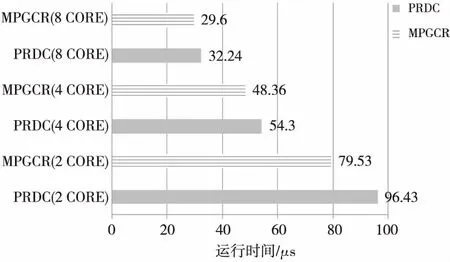
5 結束語
猜你喜歡
中學生數理化·八年級物理人教版(2023年11期)2023-12-26 07:50:02井岡教育(2022年2期)2022-10-14 03:11:44中學生數理化(高中版.高考理化)(2022年5期)2022-06-01 06:27:46中學生數理化(高中版.高考理化)(2022年1期)2022-04-26 13:53:42中學生數理化(高中版.高考理化)(2022年3期)2022-04-26 13:41:26中學生數理化(高中版.高考理化)(2022年3期)2022-04-26 13:41:24課堂內外(初中版)(2022年2期)2022-02-28 02:00:30云南教育·中學教師(2020年9期)2020-11-16 00:27:58中學生數理化·八年級物理人教版(2019年9期)2019-11-25 07:33:00中學生數理化·八年級物理人教版(2017年9期)2017-12-20 08:11:28
