基于多模板的魯棒運動目標跟蹤方法*
2018-01-27 01:40:46陸惟見尚振宏李潤鑫
傳感器與微系統 2018年2期
陸惟見,尚振宏,劉 輝,李潤鑫,錢 謙
(昆明理工大學 信息工程與自動化學院,云南 昆明 650500)
0 引 言
由于光照變化、遮擋、目標形變、攝像機抖動等諸多因素的影響,實現魯棒的視覺跟蹤[1]仍然是一件非常困難的事情。基于目標特征跟蹤是視覺跟蹤中最為重要的一類方法,研究發現,諸如深度去噪自編碼器和卷積神經網絡等深度學習[2,3]方法挖掘出的數據多層表征更能夠反映數據更深層的本質,文獻[4]使用了多層PCA卷積提取目標分層次特征。文獻[5]使用了自編碼機挖掘數據的多層表征。這些方法均通過卷積神經網絡或神經網絡來提取目標的特征表達,但由于過多的池化層,使目標特征丟失了其局部結構信息,在發生遮擋或目標形變時容易丟失。文獻[6]提出的基于卷積網絡的跟蹤器(convolutional network-based tracker,CNT)算法簡化了卷積網絡的結構,剔除了池化層,使用由第一幀目標獲得的一組濾波器與后續幀卷積,提取包含目標局部結構和內部幾何布局信息的特征描述。上述算法和一些經典算法[7~9]使用的滑動平均模型更新方法過于依賴于上一幀或最近幀定位到的目標信息,跟蹤的歷史信息未充分利用。這種滑動平均的目標模型更新方法在跟蹤精度較高的情況下,對目標外表變化較為魯棒。但如果跟蹤精度不高,錯誤信息的累積會導致目標發生漂移甚至丟失現象。
目標模型更新的難點在于穩定性和可塑性之間的平衡,目前主要的模型更新算法可分為滑動平均更新法[10,11]和選擇特征更新法[12,13]。兩種方法僅依賴于上一幀或最近幀定位到的目標信息,已經跟蹤到的目標對后續跟蹤沒有發揮作用,跟蹤的歷史信息未充分利用。在跟蹤過程中,若目標與初始目標模型差異較大時,較難準確跟蹤。
擁有復雜記憶系統的人類可以適應各種情況下的跟蹤任務[14],受此啟發,并針對上述問題,本文使用歷史跟蹤結果構建目標特征模板庫并結合CNT算法的卷積網絡特征提取,提出了一種基于多模板及卷積網絡的魯棒跟蹤方法。在CNT算法的基礎上,通過構建并更新多樣性模板庫,不僅依賴上一幀,而是利用跟蹤結果的歷史信息為運動目標跟蹤提供更完整的候選匹配信息,提高了算法的準確性和穩定性。
1 CNT目標跟蹤算法
CNT算法提出了一種簡化的卷積網絡,使用由第一幀目標獲得的一組濾波器與后續幀作卷積,提取包含目標局部結構和內部幾何布局信息的特征描述。為保證論文的完整性,將CNT算法簡述如下,算法的詳細論述見文獻[6]。
1.1 目標描述
首先,將輸入圖像轉換為n像素×n像素的灰度圖像I,對I按w×w大小進行密集采樣獲得一組重疊的局部圖像塊,圖像Ii的采樣樣本集Υi為
Υi=Patch(Ii)={Y1,…,Yl}
(1)
式中l=(n-w+1)×(n-w+1),為減少光照變化影響,每個圖像塊Yi均進行均值相減和L2歸一化操作。
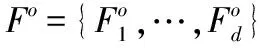
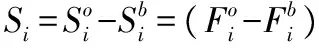
(2)
將d個使用同一組濾波器的特征S疊加得到三維特征張量C∈R(n-w+1)×(n-w+1)×d,為使特征C對目標形變魯棒,用稀疏向量c近似vec(C)∈R(n-w+1)2d,其可通過最小化式(3)求得
(3)
1.2 模型更新
稀疏描述子c在式(3)中作為目標模型,為適應跟蹤過程中目標外觀的變化,須對式(3)所表示的目標模型進行更新,CNT使用滑動平均的方法更新模型
(4)
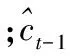
1.3 跟蹤算法
CNT的跟蹤算法建立在粒子濾波框架下,其核心思想是根據t時刻系統狀態的一個觀測結果Ot={o1,…,ot},利用概率理論迭代估計系統t時刻的狀態st,即找到后驗概率分布P(st│Ot)
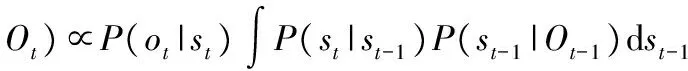
(5)
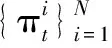
(6)
根據粒子濾波原理,最優的目標狀態估計可以通過最大化粒子集的后驗估計來實現,即
(7)
2 多模板目標跟蹤算法
CNT算法基于單一模板,通過迭代更新這一模板特征進行運動目標跟蹤。由于復雜背景和目標形變的影響,迭代更新過程中錯誤信息的累積會導致目標發生漂移甚至丟失的現象。
本文提出了改進算法通過模擬人類的記憶系統,將跟蹤過程中得到的目標信息進行儲存,用于構建多樣性模板庫,利用跟蹤結果的歷史信息為運動目標跟蹤提供更完整的候選匹配信息。在跟蹤過程中,對CNT算法得到的跟蹤結果進行遮擋判定,選取合適的跟蹤結果用于構建模板庫,在更新過程中需剔除模板庫內的冗余模板,保持模板庫的多樣性。經上述步驟,多樣性模板庫在CNT算法的目標匹配階段為其提供了更完整的候選匹配信息。
2.1 遮擋判定
視覺跟蹤任務可以看作一種時域運動估計問題。在連續視頻序列中,相鄰幀目標不會發生較大變化。跟蹤開始時,在第一幀人為標定目標,以此目標作為目標模型對下一幀目標進行定位。隨著跟蹤進行,經過篩選的模板不斷進入,模板庫將逐漸被建立起來。
跟蹤過程中,需在模板庫內選擇合適的模板作為目標模型進行匹配,為避免部分遮擋的目標成為模板進入模板庫, 設計了一種通過比較目標和背景相似度的遮擋判定方法:對第t-1幀跟蹤結果xt-1周圍進行高斯采樣得n個與xt-1重疊率為γ背景采樣,記為Bt-1={b1,…,bn} 。在CNT算法的粒子濾波框架下,通過計算xt和Bt-1={b1,…,bn}的最大后驗估計判斷當前幀跟蹤結果的遮擋情況
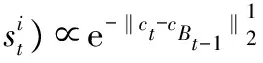
(8)
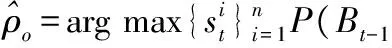
(9)
當ρo小于預設的閾值δ時,認為目標模型未被遮擋。
2.2 模板庫建立
為了防止在跟蹤過程中模板庫的無限擴充,設模板庫最多可容納N個模板,Nt,Nt≤N為第t幀時模板庫內模板的個數。則模板庫可定義為
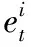
(10)
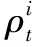
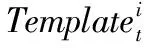
設閾值T作為衡量跟蹤結果與目標的相似性度量,模板庫建立的算法流程如下:
1)以第一幀選定的目標為模板庫內初始模板,設置模板計數器i←1。
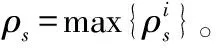
4)當ρs>εT,ε為用于保證入庫模板質量的系數,取值范圍(1,2],選擇ρs所對應的xi為當前幀的跟蹤結果,其中,xi∈Xt。由目標xi系統狀態和式(9)可計算出ρo。

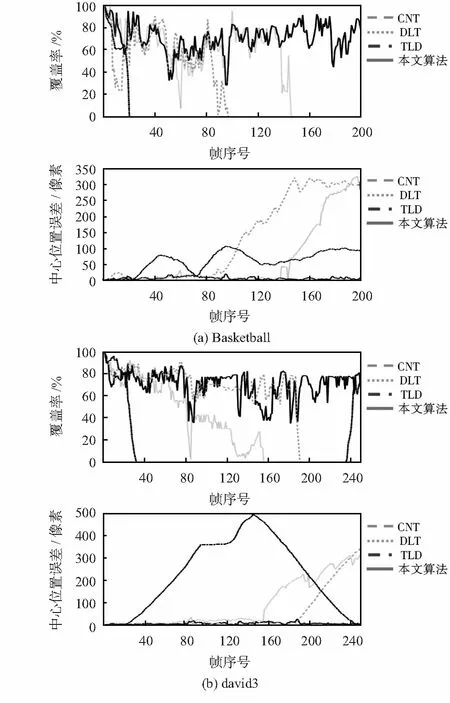
6)若ρs 閾值的確定易受目標和背景紋理結構以及跟蹤窗口大小等的影響。調節閾值T可以調節模板庫內模板之間的差異以及模板入庫的頻率。 (11) 為了驗證本文算法的有效性和正確性,使用MATLAB進行編程,對國際公共測試視頻VOT2015[15]中的trellis_c,Basketball和david3視頻序列進行跟蹤實驗。實驗結果按性質分成定性分析和定量分析兩類,定性分析給出圖像結果,定量分析給出統計結果。在定量分析中,將本文算法與近年熱點算法跟蹤—學習—檢測[16](tracking-learning-detection,TLD)算法以及基于深度特征學習的跟蹤[5](deep learning-tracking,DLT)算法在覆蓋率和中心位置誤差方面進行比較。 圖1為基于trellis_c視頻序列進行的,將本文算法和原始CNT算法進行對比實驗,測試目標在發生光照變化或復雜背景紋理情況下算法的魯棒性。 如圖1所示,在130幀左右目標的形變不明顯,背景和前景(目標)對比明顯,背景的紋理變化相較于前景較為復雜。在跟蹤過程中,原始CNT算法由于模型更新過程引入過多的背景信息其跟蹤結果已經開始發生漂移,而本文算法仍舊可以對目標繼續跟蹤。原始CNT算法僅依賴上一幀得到的目標信息進行迭代更新,信息具有局限性和單一性,當發生形變和復雜背景時,錯誤信息的累積往往導致錯誤跟蹤。本文算法維持著模板庫的多樣性,隨著跟蹤進行,模板庫不斷的豐富,當出現復雜背景的情況,能夠從模板庫找到相應的模板對目標進行較準確的定位跟蹤。 圖1 trellis_c場景2種算法跟蹤結果 圖2測試算法的抗遮擋和抗形變性能,在視頻序列Basketball和david3上進行,本文算法與原始CNT算法、TLD算法和DLT算法對比實驗。對于Basketball視頻序列,在第18幀左右當目標發生嚴重遮擋時,TLD算法已經不能對目標進行跟蹤,DLT算法、CNT算法和本文算法仍能夠對目標進行跟蹤,但在第80幀后目標形態發生較大變化,CNT算法和DLT算法出現了跟蹤漂移的情況,而本文算法仍然能夠繼續跟蹤。對于david3視頻序列,在第23幀目標第一次被遮擋時,TLD算法出現跟蹤失敗,跟蹤無法進行的情況。在隨后的跟蹤過程中,由于目標的形變,在150幀后DLT算法出現了跟蹤框尺度異常和漂移的問題。CNT算法也在190幀左右目標被完全遮擋時跟蹤失敗,只有本文算法還能繼續跟蹤。 圖2 Basketball和david3視頻跟蹤結果 對圖3的實驗結果進行定量分析,本文算法與上述算法在覆蓋率[15]和中心位置誤差[15]的對比結果如圖3所示。由圖可知,本文算法的覆蓋率一直維持在一定范圍內,并且中心位置誤差為4種算法中最小。其他3種算法由于跟蹤過程中目標的遮擋和形變出現了跟蹤失敗或跟蹤框漂移的情況,所以覆蓋率在某一時刻變為0,中心位置誤差逐漸增大。其中在david3視頻序列中,TLD算法在第25幀跟蹤失敗,跟蹤框停止移動,但在235幀后目標又移動到其跟蹤框范圍內,所以其覆蓋率曲線呈現凹形,中心位置誤差曲線呈現凸形。 圖3 定量分析對比 通過上述實驗結果可以看出,TLD算法在目標發生遮擋時的魯棒性較低,DLT算法和CNT算法在目標發生前形態變化前跟蹤比較穩定,但在目標形態和初始狀態有了較大差異或遮擋時,其模型更新方法易受到錯誤信息的干擾,出現跟蹤框尺度變換異常或跟蹤漂移的狀況。CNT算法依賴初始目標特征的迭代更新,當目標的局部結構和內部幾何布局發生較大變化時容易導致跟蹤錯誤。而本文算法維持著目標的差異性和多樣性模板庫,當遮擋和形變后,可以從模板庫內找到遮擋之前目標的相似信息,實現目標持續跟蹤。 針對滑動平均模型更新法和選擇特征模型更新法過于依賴于上一幀或最近幀定位到的目標信息,不能很好地應對復雜背景和目標形態變化的情況,本文使用歷史跟蹤結果構建目標特征模板庫并結合CNT算法的卷積網絡特征提取,為運動目標跟蹤提供了更完整的候選匹配信息。實驗證明:改進算法在保留了原始CNT算法抗遮擋能力的前提下,提升了在復雜背景和目標形變時的魯棒性和準確性。 [1] 安 寧,閆 斌,熊 杰.基于壓縮感知的多尺度絕緣子跟蹤算法[J].傳感器與微系統,2016,35(3):140-143. [2] Clement F,Camille C,Laurent N,et al.Learning hierarchical featues for scene labeling[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(8):1915-1929. [3] Alex K,Sutskever I,Hinton G E.ImageNet classification with deep convolutional neural networks[C]∥Advances in Neural Information Processing Systems,LakeTahoe,USA:NIPS,2012:748-764. [4] 李寰宇,畢篤彥,楊 源,等.基于深度特征表達與學習的視覺跟蹤算法研究[J].電子與信息學報,2015,37(9):2033-2039. [5] Wang N,Yeung D Y.Learning a deep compact image representation for visual tracking[J].Advances in Neural Information Processing Systems,2013,26(1):809-817. [6] Zhang K,Liu Q,Wu Y,et al.Robust visual tracking via convolutional networks[J].IEEE Transactions on Image Processing,2015,25(4):1-18. [7] Zhang K,Zhang L,Yang M H. Real-time compressive tra-cking[C]∥European Conference on Computer Vision,Berlin,Germany:Springer,2012:864-877. [8] Bolme D S,Beveridge J R,Draper B A,et al.Visual object tra-cking using adaptive correlation filters[C]∥Computer Vision and Pattern Recognition,San Francisco,USA:IEEE,2010:2544-2550. [9] Bolme D S,Draper B A,Beveridge J R.Average of synthetic exact filtes[C]∥Computer Vision and Pattern Recognition,Anchorage,USA:IEEE,2009:2105-2112. [10] Collins R T,Liu Y,Leordeanu M.Online selection of discriminative tracking features[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2005,27(10):1631-1643. [11] Grabner H,Leistner C,Bischof H.Semi-supervised on-line boosting for robust tracking[C]∥European Conference on Computer Vision,Berlin,Germany:Springer-Verlag,2008. [12] 沈志熙,楊 欣,黃席樾.均值漂移算法中目標模板更新算法研究[J].自動化學報,2009,35(5):478-483. [13] Hong Zhibin.Multi-store tracker(MUSTer):A cognitive psycho-logy inspired approach to object tracking[C]∥Computer Vision and Pattern Recognition,Boston,USA:IEEE,2015:749-758. [14] Kristan M,Matas J,Leonardis A,et al.The visual object tracking VOT2015 challenge results[C]∥Computer Vision Workshops,Santiago,USA:IEEE,2015:1-23. [16] Kalal Z,Matas J,Mikolajczyk K.PN learning: Bootstrapping binary classifiers by structural constraints[C]∥Computer Vision and Pattern Recognition,San Francisco,USA:IEEE,2010:49-56.2.3 模板庫更新
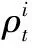
3 實驗結果與分析
3.1 定性分析


3.2 定量分析
4 結束語
猜你喜歡
汽車工程師(2021年12期)2022-01-17 02:29:54
當代陜西(2020年14期)2021-01-08 09:30:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
貴州師范學院學報(2016年4期)2016-12-01 03:54:07
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
祝您健康(1987年3期)1987-12-30 09:52:32
