高校圖書館智慧學科服務實踐
2018-02-18 15:50:30曹畋
新世紀圖書館 2018年11期
關鍵詞:高校圖書館
摘 要 開展學科服務已成為高校圖書館的一項工作職責,是高校圖書館服務教學的重要表現形式。然而,高校圖書館開展學科服務卻長期面臨投入大、績效低等問題,導致相當一部分學校的圖書館學科服務一直沒能跟上高校院系發展和需求。為此,南京曉莊學院圖書館開始實踐采用智能化技術提升學科服務的新思路、新模式,在人力投入基本不變的情況下,極大的提升了學科服務能力與質量。
關鍵詞 學科服務 高校圖書館 智慧圖書館
分類號 G258.6
DOI 10.16810/j.cnki.1672-514X.2018.11.011
傳統的高校學科服務模式基本可以概括為學科館員對口某學科服務的人工服務模式,但在服務過程中也暴露出諸多問題,如果沿用傳統的學科館員人工服務模式將很難從根本上解決學科服務中的精準化問題[1]。
其實,國內外的高校學科服務一直都在努力緩解當前學科服務模式對人工服務的高度依賴,而其中建設學科服務平臺就是一種被普遍認可的辦法。早在2003年明尼蘇達大學就開發并應用了一種集科研、課程及學科導航于一體的學科服務平臺。國外比較早期的還有哈佛大學圖書館建立的科研存儲平臺,伊莎卡學院開發的資料存儲歸檔平臺等。國內高校主要依托CALIS提供的專業學科導航服務,也有上海交通大學、浙江理工大學、香港大學等部分高校開發了自己的學科服務平臺[2]。然而縱觀國內外主流的高校學科服務平臺,基本都還停留在存儲和導航的基礎功能上,少數平臺即便有了在線咨詢功能,但主要模式仍依靠學科館員在線人工服務,對人工的依賴程度仍然很高。
1 當前高校圖書館學科服務問題
本文結合高校圖書館學科服務普遍情況和南京曉莊學院圖書館(以下簡稱本館)情況,對傳統學科服務模式中的問題歸納如下。
(1) 高校學科服務需要面向相關院系相關專業提供深入的跟蹤服務,傳統學科服務模式下對學科館員數量和學科館員質量的要求都很高。高校圖書館人員結構復雜、信息素質水平偏低的現狀雖然不斷改善,但仍然難以全面、高水平地開展覆蓋各學科的學科服務。加之培養學科館員的周期長、成本高等問題,本館的學科服務團隊建設一直沒有取得突破性進展。
(2) 傳統學科館員制度下的學科服務模式中,學科館員是服務的中心,而嵌入式高校學科服務是以每一位用戶為中心的,也就是說目前在學科服務中實際存在著用戶和學科館員兩個中心。未來要強化用戶的中心地位,必須設法將傳統的學科館員與相關經驗、數據等分離開來。
(3) 現有學科服務平臺主要實現學科導航服務,存在缺乏互動性、難以定制等缺陷,師生訪問量也一直不高。從學科館員的角度來看,由于制作和維護學科導航的工作量大,專業性強且難以和其他知識發現工具整合,所以很多傳統學科服務平臺處于不更新狀態。有些學科館員以計算機水平低等理由,直接將工作推給圖書館技術部門的同志,更使得學科導航脫離了院系需求。
(4) 目前也有一些基于互聯網的學科服務平臺,但這類平臺主要以導航為主,缺乏知識整理和知識發現的功能。智能化將是未來學科服務平臺發展的重要趨勢。
(5) 高校圖書館的專家館員在線咨詢增長率遠低于其他類型的在線專家咨詢系統增長率,甚至一些師生干脆選擇搜索引擎和問答類網站獲取學術信息。高校圖書館亟待提供更深入的知識服務,才能確立其在教學、科研服務中的重要地位。
2 智慧學科服務建設思路與功能需求
對高校圖書館而言,高校圖書館“十三五”規程中明確了“高校圖書館是為人才培養和科學研究服務的學術性機構”,使得圍繞高校圖書館職能的智能學科服務模式研究更具必要性和迫切性[3]。智慧學科服務的研究與實踐將是高校圖書館發展的必然趨勢之一。在物聯網、傳感器、大數據、云計算、人工智能等高新技術聯合推動下,近年來智能技術取得重大突破和越來越廣泛的應用,而現有模式下學科館員服務的種種問題以及學科服務工具的先天性缺陷,都有望在智能化條件下得以徹底解決。
高校圖書館智能學科服務相對其他智能推薦系統具有明顯的特殊性,體現在學校容易實現單點登錄且容易獲取師生的學習研究方向。另外,高校圖書館智能學科服務面對的服務群體對內容的需求有著非常大的周期性變化,如某學生一門學科學完后開始其他學科的學習,前后關注內容將發生很大變化。針對這一特點,本館學科服務模式的建設原則是:緊緊圍繞高校教學和科研服務,系統地應用智能化技術,逐漸完善適合南京曉莊學院的高校圖書館智能學科服務模式。
根據上述原則,南京曉莊學院的智能學科服務建設思路是:首先根據本校教學、科研具體需求構建可行性建設方案,然后將可行性建設方案交相關領域專家進行篩選,最終將通過篩選的方案在可監控的數據環境下進行測試,測試過程中不斷收集和評估績效。對績效差的方案和調整后仍然不理想的方案進行淘汰,最終通過測試將不需要再調整的模式固定下來[4]。本館的智能學科服務模式功能需求,主要包括以下幾個方面。
(1) 為高校師生提供搜索方式獲取電子教育資源,支持模糊搜索。
(2) 為高校師生主動提供個性化的教育資源或知識片段推薦。
(3) 工作人員分為系統管理員及信息維護員。系統管理員負責保障整個系統的運維。信息維護員主要負責數據管理及維護工作。
(4) 記錄用戶網絡學術行為。系統需要對所有用戶的網絡學術行為進行動態記錄,包括IP地址、登錄信息、訪問時間或Session ID等信息,這些信息構成的大數據將用于分析用戶的在線學術行為。
(5) 海量在線知識管理。將圖書館海量的資料轉換為有用的且易于提取的知識信息,首先需要利用專門的數據處理平臺對其進行摘要化處理和關系化處理。數據處理平臺還將提供包括資源訪問情況、資源偏好評分等多項基于大數據的分析功能。
(6) 個性學科知識推薦服務。系統不但具備對登錄用戶進行個性化學科知識推薦服務能力,而且對沒有登錄系統的用戶也能根據實時頁面操作捕獲到用戶可能感興趣的知識并進行推薦。登錄與非登錄用戶的個性學科服務推薦原理不同,登錄用戶的個性學科知識推薦服務更專業,更符合學科服務的特殊要求,而非登錄用戶獲得的推薦類似于商品興趣推薦。
(7) 按學科分類樹進行知識分類的功能。系統將建立一個類似高校學科目錄設置的樹形學科分類樹,有助于極大提升推薦的精確度。學科分類樹一般分為五層,其中學科層次較少的分三層,學科層次較多的可以分七層。學科分類樹的根節點按照一級學科分類進行設置,相應的第二層也直接對應二級學科分類設置。學科分類樹的第三層和第四層,一般對應著專業課程名稱和課程的細分知識點,第四層也可以按照相關課程的目錄來設置。如果學科分類樹有必要設置到第五層,那么可以用章節中涉及知識點的關鍵字描述。當然,范圍很廣的關鍵詞是不能用于該層知識點描述的。除了節點本身名稱、說明外,每個節點還要附加一個關鍵字集合A,用于反向定位至該節點。學科分類樹中上層節點中,相鄰或是相近的兩個節點既要有共同部分,更要體現差異部分。學科分類樹中每個節點建立一個推薦知識片段集合B,推薦知識片段盡量全面體現本節點內容,同時要避免范圍過大影響定位。學科分類樹中每一個節點都對應一個推薦知識片段地址集合C,推薦知識片段的地址集合必須是本節點相關的URL(Uniform Resoure Locator)。
3 智慧學科服務模型
本館通過前期對讀者行為大數據的跟蹤研究,提出了兩種發掘用戶興趣的辦法。第一種辦法是通過抽取用戶檢索詞和圖書的TF-IDF信息,并形成常用檢索詞順序列表,得到用戶特征向量和知識特征向量,再對用戶和知識的相似點計算對比,就能找到用戶感興趣的知識片段[5]。第二種辦法是分片聚類,首先根據檢索詞、時間、空間等屬性抽取出用戶即時行為分片,然后將所有分片一起聚類分析,得到相似分片分組,分別運用相關算法找到目標用戶可能需要的圖書或知識片段。
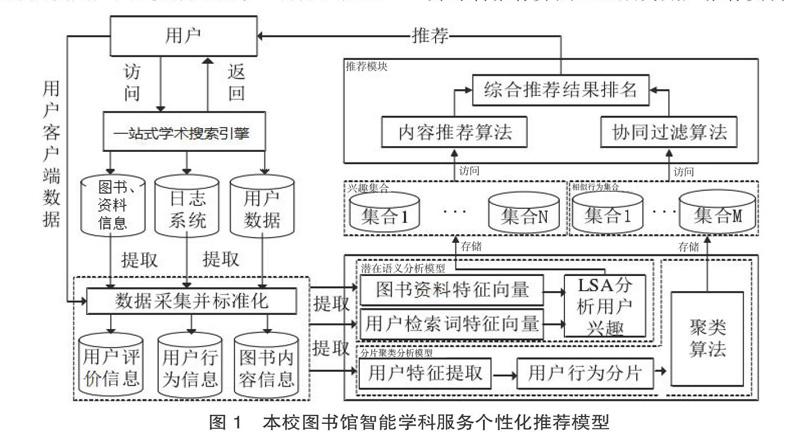
如圖1所示,一站式學術搜索引擎作為高校圖書館智能學科服務個性化推薦的基礎支撐,與用戶交互、記錄用戶行為,并用爬蟲(網絡機器人) 采集網上各類教學科研的資料信息。數據采集模塊采集以上信息,標準化后存入智能學科服務個性化推薦系統數據庫以及HDFS中,同時數據預處理模塊對數據進行預處理。采用潛在語義分析模型和基于分片聚類的分析模型分析用戶數據,分別產生興趣集和相似分片集。最后采用不同的推薦算法分別執行推薦并綜合推薦算法Rank后為用戶推薦資料[6]。
4 智能學科服務業務架構
圖書館學科服務目標作為業務系統的核心,圍繞該核心系統應從業務上劃分為六個部分,分別是學科分類樹、知識聚類、智能推薦算法、資源建設、用戶行為及評價體系。各個部分的功能如下。
(1) 學科分類樹。該模塊提供最基礎的學科分類信息,建議參考國家《學位授予和人才培養學科目錄》 并結合本校專業設置情況、課程情況進行設置。該模塊也為資源建設、用戶行為、智能推薦算法選擇提供重要依據。
(2) 知識聚類。這一模塊主要是針對海量的圖書館資源的知識聚類,通過知識聚類,減少系統即時運算時間并提高知識推薦準確度。通過調整學科分類樹和知識聚類來達到最佳的預分類海量知識的效果。
(3) 智能推薦。該部分能協調其他五個部分數據,最終形成針對每一個用戶定制的推薦結果。系統即便在無法獲取用戶偏好的情況下,仍然可以根據用戶標簽來推薦,有效地避免了冷啟動問題。
(4) 資源建設。除常規的資源建設外,系統可循環收集反饋數據,建立動態的資源庫。用戶二次加工的資源將實時轉化為新的資源,以此提升資源建設的效率和針對性。
(5) 用戶行為。通過用戶在線操作的動態日志跟蹤和記錄,實現對用戶網上學術行為的記錄。這些海量記錄將用于智能推薦模塊分析用戶學習趨勢,并結合其專業與課程學習情況,對用戶行為進行教學引導。
(6) 評價體系。對教學資源進行評分,并反饋推薦結果的有效性,為智能推薦的優化提供數據支持。
5 高校圖書館智能學科系統部署架構
本系統采用大數據分析技術,并綜合采用Google公司推出的MapReduce及開源Hadoop云計算技術,通過挖掘海量數據所蘊含的信息,建立特定模型進行預測。
為滿足總體需求,系統引入大數據處理、存儲設計部署。本館智能學科系統架構部署了Hadoop Cluster、Mongo DB Sharing Cluster、Zookeeper Cluster、Spark Cluster四個數據集群及相關存儲,另外還部署了學科分類樹集群、個性化推薦Web集群兩個應用集群,用于提供相應的應用請求和分類樹建構需求[7]。
(1)Hadoop Cluster。此部署集群又分為兩個功能部分。第一個功能是對大量URL進行處理并對爬取內容進行分析與使用,從而對學科分類樹構成輔助。另一個功能是在分布式計算的個性化推薦中輔助Mahout使用。在操作中為常將Second Name Node單獨部署在一臺服務器上,這樣可以防止Name Node單點故障,讓日志文件能寫入共享存儲,提升Name Node的可靠性。
(2)Mongo DB Sharing Cluster。利用了Mongo DB的Sharding和復制集技術來搭建存儲分類樹文檔庫及推薦信息庫,不但提升了可用性、穩定性,和安全性而且易于集群的擴展部署。
(3)Zookeeper Cluster。搭建具有一個決策節點和兩個數據節點的Zookeeper集群,用于在分布式任務協調中分配相關數據存儲,為分類樹應用管理、存儲和配置信息庫使用。
(4)Spark Cluster。該集群負責個性化推薦中基于Web應用的實時推薦算法的計算任務,由于實時性強、并行性強,需要配置大容量內存和高性能服務器進行支持。該集群通過重用Hadoop集群中yarn部署。
(5) 學科分類樹集群。該集群負責用戶上網日志提取及相關內容抓取。由于信息量大,關鍵字提取及時性要求高,為滿足性能要求需要部署多臺爬蟲服務器。
(6) 個性化推薦Web集群。部署該部分主要是為緩解系統使用高峰中在線支持及實時推薦的計算壓力。通過單獨部署個性化推薦Web服務集群和前端部署負載均衡軟件的辦法相結合,提升個性推薦服務保障能力。
6 結語
圖書館智能學科服務對高校圖書館提升自我服務能力,優化高校教育教學資源配置都有著重要的意義。本文結合高校學科服務需求,通過對大數據技術及推薦技術等的調研,最終形成針對高校特征的智能學科輔助服務模式。該模式在解決信息過載、冷啟動以及減少技術復雜性上都做了一些嘗試,為部署高校圖書館智能學科服務平臺邁出了試探性的步伐,相信隨著高校圖書館的不斷升級和學科服務深入,以及教學相關數據的不斷積累,智能學科服務模式將成為高校圖書館普遍重視的研究領域。
傳統的高校學科服務模式基本可以概括為學科館員對口某學科服務的人工服務模式,但在服務過程中也暴露出諸多問題,如果沿用傳統的學科館員人工服務模式將很難從根本上解決學科服務中的精準化問題[1]。
其實,國內外的高校學科服務一直都在努力緩解當前學科服務模式對人工服務的高度依賴,而其中建設學科服務平臺就是一種被普遍認可的辦法。早在2003年明尼蘇達大學就開發并應用了一種集科研、課程及學科導航于一體的學科服務平臺。國外比較早期的還有哈佛大學圖書館建立的科研存儲平臺,伊莎卡學院開發的資料存儲歸檔平臺等。國內高校主要依托CALIS提供的專業學科導航服務,也有上海交通大學、浙江理工大學、香港大學等部分高校開發了自己的學科服務平臺[2]。然而縱觀國內外主流的高校學科服務平臺,基本都還停留在存儲和導航的基礎功能上,少數平臺即便有了在線咨詢功能,但主要模式仍依靠學科館員在線人工服務,對人工的依賴程度仍然很高。
1 當前高校圖書館學科服務問題
本文結合高校圖書館學科服務普遍情況和南京曉莊學院圖書館(以下簡稱本館)情況,對傳統學科服務模式中的問題歸納如下。
(1) 高校學科服務需要面向相關院系相關專業提供深入的跟蹤服務,傳統學科服務模式下對學科館員數量和學科館員質量的要求都很高。高校圖書館人員結構復雜、信息素質水平偏低的現狀雖然不斷改善,但仍然難以全面、高水平地開展覆蓋各學科的學科服務。加之培養學科館員的周期長、成本高等問題,本館的學科服務團隊建設一直沒有取得突破性進展。
(2) 傳統學科館員制度下的學科服務模式中,學科館員是服務的中心,而嵌入式高校學科服務是以每一位用戶為中心的,也就是說目前在學科服務中實際存在著用戶和學科館員兩個中心。未來要強化用戶的中心地位,必須設法將傳統的學科館員與相關經驗、數據等分離開來。
(3) 現有學科服務平臺主要實現學科導航服務,存在缺乏互動性、難以定制等缺陷,師生訪問量也一直不高。從學科館員的角度來看,由于制作和維護學科導航的工作量大,專業性強且難以和其他知識發現工具整合,所以很多傳統學科服務平臺處于不更新狀態。有些學科館員以計算機水平低等理由,直接將工作推給圖書館技術部門的同志,更使得學科導航脫離了院系需求。
(4) 目前也有一些基于互聯網的學科服務平臺,但這類平臺主要以導航為主,缺乏知識整理和知識發現的功能。智能化將是未來學科服務平臺發展的重要趨勢。
(5) 高校圖書館的專家館員在線咨詢增長率遠低于其他類型的在線專家咨詢系統增長率,甚至一些師生干脆選擇搜索引擎和問答類網站獲取學術信息。高校圖書館亟待提供更深入的知識服務,才能確立其在教學、科研服務中的重要地位。
2 智慧學科服務建設思路與功能需求
對高校圖書館而言,高校圖書館“十三五”規程中明確了“高校圖書館是為人才培養和科學研究服務的學術性機構”,使得圍繞高校圖書館職能的智能學科服務模式研究更具必要性和迫切性[3]。智慧學科服務的研究與實踐將是高校圖書館發展的必然趨勢之一。在物聯網、傳感器、大數據、云計算、人工智能等高新技術聯合推動下,近年來智能技術取得重大突破和越來越廣泛的應用,而現有模式下學科館員服務的種種問題以及學科服務工具的先天性缺陷,都有望在智能化條件下得以徹底解決。
高校圖書館智能學科服務相對其他智能推薦系統具有明顯的特殊性,體現在學校容易實現單點登錄且容易獲取師生的學習研究方向。另外,高校圖書館智能學科服務面對的服務群體對內容的需求有著非常大的周期性變化,如某學生一門學科學完后開始其他學科的學習,前后關注內容將發生很大變化。針對這一特點,本館學科服務模式的建設原則是:緊緊圍繞高校教學和科研服務,系統地應用智能化技術,逐漸完善適合南京曉莊學院的高校圖書館智能學科服務模式。
根據上述原則,南京曉莊學院的智能學科服務建設思路是:首先根據本校教學、科研具體需求構建可行性建設方案,然后將可行性建設方案交相關領域專家進行篩選,最終將通過篩選的方案在可監控的數據環境下進行測試,測試過程中不斷收集和評估績效。對績效差的方案和調整后仍然不理想的方案進行淘汰,最終通過測試將不需要再調整的模式固定下來[4]。本館的智能學科服務模式功能需求,主要包括以下幾個方面。
(1) 為高校師生提供搜索方式獲取電子教育資源,支持模糊搜索。
(2) 為高校師生主動提供個性化的教育資源或知識片段推薦。
(3) 工作人員分為系統管理員及信息維護員。系統管理員負責保障整個系統的運維。信息維護員主要負責數據管理及維護工作。
(4) 記錄用戶網絡學術行為。系統需要對所有用戶的網絡學術行為進行動態記錄,包括IP地址、登錄信息、訪問時間或Session ID等信息,這些信息構成的大數據將用于分析用戶的在線學術行為。
(5) 海量在線知識管理。將圖書館海量的資料轉換為有用的且易于提取的知識信息,首先需要利用專門的數據處理平臺對其進行摘要化處理和關系化處理。數據處理平臺還將提供包括資源訪問情況、資源偏好評分等多項基于大數據的分析功能。
(6) 個性學科知識推薦服務。系統不但具備對登錄用戶進行個性化學科知識推薦服務能力,而且對沒有登錄系統的用戶也能根據實時頁面操作捕獲到用戶可能感興趣的知識并進行推薦。登錄與非登錄用戶的個性學科服務推薦原理不同,登錄用戶的個性學科知識推薦服務更專業,更符合學科服務的特殊要求,而非登錄用戶獲得的推薦類似于商品興趣推薦。
(7) 按學科分類樹進行知識分類的功能。系統將建立一個類似高校學科目錄設置的樹形學科分類樹,有助于極大提升推薦的精確度。學科分類樹一般分為五層,其中學科層次較少的分三層,學科層次較多的可以分七層。學科分類樹的根節點按照一級學科分類進行設置,相應的第二層也直接對應二級學科分類設置。學科分類樹的第三層和第四層,一般對應著專業課程名稱和課程的細分知識點,第四層也可以按照相關課程的目錄來設置。如果學科分類樹有必要設置到第五層,那么可以用章節中涉及知識點的關鍵字描述。當然,范圍很廣的關鍵詞是不能用于該層知識點描述的。除了節點本身名稱、說明外,每個節點還要附加一個關鍵字集合A,用于反向定位至該節點。學科分類樹中上層節點中,相鄰或是相近的兩個節點既要有共同部分,更要體現差異部分。學科分類樹中每個節點建立一個推薦知識片段集合B,推薦知識片段盡量全面體現本節點內容,同時要避免范圍過大影響定位。學科分類樹中每一個節點都對應一個推薦知識片段地址集合C,推薦知識片段的地址集合必須是本節點相關的URL(Uniform Resoure Locator)。
3 智慧學科服務模型
本館通過前期對讀者行為大數據的跟蹤研究,提出了兩種發掘用戶興趣的辦法。第一種辦法是通過抽取用戶檢索詞和圖書的TF-IDF信息,并形成常用檢索詞順序列表,得到用戶特征向量和知識特征向量,再對用戶和知識的相似點計算對比,就能找到用戶感興趣的知識片段[5]。第二種辦法是分片聚類,首先根據檢索詞、時間、空間等屬性抽取出用戶即時行為分片,然后將所有分片一起聚類分析,得到相似分片分組,分別運用相關算法找到目標用戶可能需要的圖書或知識片段。
如圖1所示,一站式學術搜索引擎作為高校圖書館智能學科服務個性化推薦的基礎支撐,與用戶交互、記錄用戶行為,并用爬蟲(網絡機器人) 采集網上各類教學科研的資料信息。數據采集模塊采集以上信息,標準化后存入智能學科服務個性化推薦系統數據庫以及HDFS中,同時數據預處理模塊對數據進行預處理。采用潛在語義分析模型和基于分片聚類的分析模型分析用戶數據,分別產生興趣集和相似分片集。最后采用不同的推薦算法分別執行推薦并綜合推薦算法Rank后為用戶推薦資料[6]。
圖1 本校圖書館智能學科服務個性化推薦模型
4 智能學科服務業務架構
圖書館學科服務目標作為業務系統的核心,圍繞該核心系統應從業務上劃分為六個部分,分別是學科分類樹、知識聚類、智能推薦算法、資源建設、用戶行為及評價體系。各個部分的功能如下。
(1) 學科分類樹。該模塊提供最基礎的學科分類信息,建議參考國家《學位授予和人才培養學科目錄》 并結合本校專業設置情況、課程情況進行設置。該模塊也為資源建設、用戶行為、智能推薦算法選擇提供重要依據。
(2) 知識聚類。這一模塊主要是針對海量的圖書館資源的知識聚類,通過知識聚類,減少系統即時運算時間并提高知識推薦準確度。通過調整學科分類樹和知識聚類來達到最佳的預分類海量知識的效果。
(3) 智能推薦。該部分能協調其他五個部分數據,最終形成針對每一個用戶定制的推薦結果。系統即便在無法獲取用戶偏好的情況下,仍然可以根據用戶標簽來推薦,有效地避免了冷啟動問題。
(4) 資源建設。除常規的資源建設外,系統可循環收集反饋數據,建立動態的資源庫。用戶二次加工的資源將實時轉化為新的資源,以此提升資源建設的效率和針對性。
(5) 用戶行為。通過用戶在線操作的動態日志跟蹤和記錄,實現對用戶網上學術行為的記錄。這些海量記錄將用于智能推薦模塊分析用戶學習趨勢,并結合其專業與課程學習情況,對用戶行為進行教學引導。
(6) 評價體系。對教學資源進行評分,并反饋推薦結果的有效性,為智能推薦的優化提供數據支持。
5 高校圖書館智能學科系統部署架構
本系統采用大數據分析技術,并綜合采用Google公司推出的MapReduce及開源Hadoop云計算技術,通過挖掘海量數據所蘊含的信息,建立特定模型進行預測。
為滿足總體需求,系統引入大數據處理、存儲設計部署。本館智能學科系統架構部署了Hadoop Cluster、Mongo DB Sharing Cluster、Zookeeper Cluster、Spark Cluster四個數據集群及相關存儲,另外還部署了學科分類樹集群、個性化推薦Web集群兩個應用集群,用于提供相應的應用請求和分類樹建構需求[7]。
(1)Hadoop Cluster。此部署集群又分為兩個功能部分。第一個功能是對大量URL進行處理并對爬取內容進行分析與使用,從而對學科分類樹構成輔助。另一個功能是在分布式計算的個性化推薦中輔助Mahout使用。在操作中為常將Second Name Node單獨部署在一臺服務器上,這樣可以防止Name Node單點故障,讓日志文件能寫入共享存儲,提升Name Node的可靠性。
(2)Mongo DB Sharing Cluster。利用了Mongo DB的Sharding和復制集技術來搭建存儲分類樹文檔庫及推薦信息庫,不但提升了可用性、穩定性,和安全性而且易于集群的擴展部署。
(3)Zookeeper Cluster。搭建具有一個決策節點和兩個數據節點的Zookeeper集群,用于在分布式任務協調中分配相關數據存儲,為分類樹應用管理、存儲和配置信息庫使用。
(4)Spark Cluster。該集群負責個性化推薦中基于Web應用的實時推薦算法的計算任務,由于實時性強、并行性強,需要配置大容量內存和高性能服務器進行支持。該集群通過重用Hadoop集群中yarn部署。
(5) 學科分類樹集群。該集群負責用戶上網日志提取及相關內容抓取。由于信息量大,關鍵字提取及時性要求高,為滿足性能要求需要部署多臺爬蟲服務器。
(6) 個性化推薦Web集群。部署該部分主要是為緩解系統使用高峰中在線支持及實時推薦的計算壓力。通過單獨部署個性化推薦Web服務集群和前端部署負載均衡軟件的辦法相結合,提升個性推薦服務保障能力。
6 結語
圖書館智能學科服務對高校圖書館提升自我服務能力,優化高校教育教學資源配置都有著重要的意義。本文結合高校學科服務需求,通過對大數據技術及推薦技術等的調研,最終形成針對高校特征的智能學科輔助服務模式。該模式在解決信息過載、冷啟動以及減少技術復雜性上都做了一些嘗試,為部署高校圖書館智能學科服務平臺邁出了試探性的步伐,相信隨著高校圖書館的不斷升級和學科服務深入,以及教學相關數據的不斷積累,智能學科服務模式將成為高校圖書館普遍重視的研究領域。
參考文獻:
[ 1 ]蔚海燕,衛軍朝.研究型圖書館學科服務的轉變:從學科館員到學科服務平臺[J].大學圖書館學報,2013(6):74-81.
[ 2 ]劉靜春.大數據時代高校數字圖書館學科資源聚合“云”服務平臺構建研究[J].圖書館學刊,2016(6):105-107.
[ 3 ]湯妙吉.圖書館智能化專業學科服務平臺建設[J].現代情報,2016(6):100-102,107.
[ 4 ]曹畋.大數據環境下的圖書館異構數據統一訪問與轉化系統[J]. 圖書館理論與實踐,2016(2):80-84.
[ 5 ]曹畋. 試論“互聯網+”下的智能閱讀推廣[J].圖書館理論與實踐,2016(8):94-96.
[ 6 ]曹畋.基于多Agent的高校智慧學習輔助平臺建設實踐[J].圖書館學研究,2017(24):37-41.
[ 7 ]曹畋.構建基于Agent的高校圖書館智能教學輔助平臺[J].新世紀圖書館,2017(7):47-51.
猜你喜歡
現代經濟信息(2016年19期)2016-10-20 16:13:56
出版廣角(2016年15期)2016-10-18 00:19:57
科技視界(2016年21期)2016-10-17 19:32:37
科技視界(2016年21期)2016-10-17 19:25:20
商(2016年27期)2016-10-17 06:39:10
商(2016年27期)2016-10-17 06:38:27
商(2016年27期)2016-10-17 06:30:59
科學與財富(2016年28期)2016-10-14 23:43:29
科學與財富(2016年28期)2016-10-14 00:28:44
科技視界(2016年20期)2016-09-29 13:17:57
