基于不平衡樣本的企業財務困境預測研究
2018-03-04 04:04:50呂心潔
商場現代化 2018年24期
呂心潔


摘 要:本文基于SMOTE算法和隨機森林算法提出了SMOTE-RF企業財務困境預測方法,即通過SMOTE算法構造人工數據增加少數類樣本數量,以隨機森林算法作為分類器對企業財務困境進行預測。實證結果表明,SMOTE-RF比SVM和神經網絡具有更好的預測準確性和穩定性。
關鍵詞:財務困境;不平衡樣本;SMOTE;隨機森林
一、引言
財務困境,又稱財務危機,是企業危機的最綜合、最顯著的表現。財務困境的預測一直是實務界和理論界廣泛持續進行的研究課題。正確地預測企業財務困境,對于保護相關利益主體、提高企業防范財務危機能力具有重要的現實意義。
但發生財務困境的企業只是少數,占企業總數量的比重極小。而當一個數據樣本中一個或幾個類別的數據數量遠大于其他類別的數據數量時,這樣的數據樣本就是不平衡數據樣本。因此,對上市企業的財務困境進行預測時,主要面對的是不平衡樣本。綜觀財務困境預測研究文獻,處理不平衡樣本主要有三種方法:一是忽略不平衡樣本的影響,如陳曉和陳治鴿,肖珉等。但忽略樣本的不平衡性,會使得預測模型過多關注多數類樣本,導致對少數類樣本的分類性能下降。二是采用財務困境企業與非財務困境企業1:1配對的方法構建平衡樣本,如Beaver,Altman,吳世農和盧賢義,喬卓等。構建平衡樣本,固然可以提高預測模型的準確率。但根據Zmijewski的研究,若樣本結構比例與現實中實際比例的偏差較大,會影響模型的實際預測能力。三是利用基于不平衡樣本的改進算法。通過利用采樣算法、設置懲罰系數等方法以克服樣本不平衡性帶來的影響。但構建的混合算法,在預測準確性、預測穩定性和泛化性上仍不夠理想。
基于此,本文以滬深兩市上市企業作為研究對象,構建SMOTE-RF財務困境預測模型,并以實際數據證明比其他預測模型(如SVM模型、神經網絡模型)具有更好的預測效果。
二、SMOTE-RF方法
SMOTE-RF方法即是先利用SMOTE算法仿制數據樣本中少數類樣本的信息,構造人工數據以平衡數據比例結構,再通過隨機森林方法對處理后的數據樣本進行學習分類。該方法主要是針對于不平衡數據樣本,能有效地提高模型對不平衡數據樣本的預測能力。
1.SMOTE算法
2002年,Chawla首次提出了合成少數類過取樣方法(SMOTE)。SMOTE方法主要是通過人工合成少數類樣本以提高少數類樣本的比例,降低數據結構比例的偏斜度。SMOTE方法可以增加新的并不存在的數據樣本,所以在一定程度上避免了分類器的過度擬合。SMOTE算法首先對少數類的每一個樣本x,搜索其k個最近鄰樣本,然后隨機選取這k個最近鄰中的一個樣本記為y,再在x與y之間進行隨機線性插值,構造新的少數類樣本xnew。若需要增加更多的人造樣本,只需重復上述步驟,直至所有少數類樣本均處理完畢。
2.隨機森林方法
三、實證分析
1.樣本選取
目前,國內學術界普遍采用證監會定義ST企業的標準作為財務困境公司的判定依據。本文也遵從此做法,選取滬深兩市2010年至2012年各年度的ST公司作為財務困境企業樣本,其余非ST公司(不包括金融業)作為非財務困境企業樣本。在預測時間上,本文以上市公司T-3年的財務指標數據建立預測模型,即用上市公司發生財務困境事件三年前的數據來預測該公司是否會在T年出現財務困境而被特別處理。財務困境樣本公司的首次ST年份數據和所有樣本公司的財務指標數據來自于國泰安數據庫。
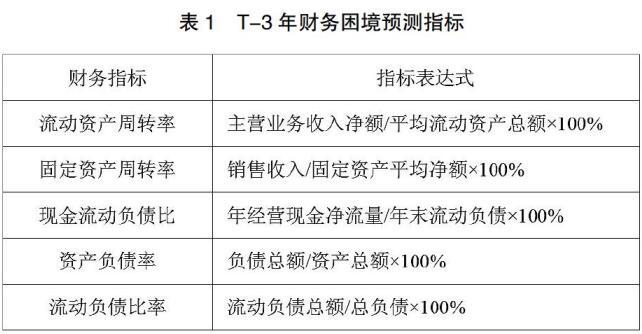
2.指標選擇
本文采用的財務指標如表1所示。
3.評價標準
每年度被ST的公司相對于上市公司整體而言只是極少數。在樣本數據中,ST企業與非ST企業的數量比最高達到了1:97,呈現出較強的不平衡性。因此,本文選取了針對不平衡問題的分類性能評價標準:Fmeasure和Gmean,公式如下:
其中,Sensitivity代表少數類正確率,Specificity代表多數類正確率,Precision代表少數類查準率。
4.預測結果及分析
為對比不同建模方法的預測能力,本文還建立了SVM模型和神經網絡模型。模型參數如下:SMOTE-RF中,分類樹的數目ntree取值200-1000,每個內部節點的候選特征數m取默認值sqrt(m);SVM的核函數選擇徑向基函數,gamma取值0.1,設置懲罰系數C為10、100、500、1000、2000;神經網絡模型采用一個隱藏層數,隱藏層節點數為1-50。預測結果如表2所示。
比較各年度分類結果可以看出,SMOTE-RF的Gmean值和Fmeasure值最高,說明SMOTE-RF方法的預測性能要優于SVM和神經網絡。同時,SMOTE-RF方法在三個年度對少數類樣本、多數類樣本的預測準確率以及Gmean值和Fmeasure值始終穩定在95%以上,表明SMOTE-RF方法具有較高的預測準確率和較好的預測穩定性。而SVM和神經網絡對該類不平衡數據樣本的預測能力則較弱,對多數類樣本判別雖較準,但少數類樣本判別正確率明顯偏低,因此Gmean值和Fmeasure值也都較低。并且,SVM的預測波動幅度較大,也驗證了”不平衡數據樣本會對傳統預測模型性能產生影響”的觀點。
四、結論
通過利用SMOTE-RF方法對我國上市企業財務困境預測的實證研究可以看到,將發生財務困境的企業放到滬深兩市所有企業中進行預測時,SMOTE-RF方法的預測準確率較高,誤判率較小,泛化性能好,說明采用SMOTE-RF方法對上市企業整體進行財務困境預測是確實可行的。
參考文獻:
[1]陳曉,陳治鴻.中國上市公司的財務困境[J].中國會計與財務研究,2000,4:55-72.
[2]消珉.我國企業集團上市公司財務預警與信用風險評估研究[D].電子科技大學,2012.5.
[3]W. Beaver. Financial Ratios as Predictors of Failure[J].Journal of Accounting Research,1966,4:71-111.
[4]E. I. Altman. Financial Ratios as Predictors of Failure[J].Journal of Accounting Research, 1996,4:71-111.
[5]吳世農,盧賢義.我國上市公司財務困境的預測模型研究[J].經濟研究,2001,6:46-55.
[6]喬卓.上市公司財務困境預測模型實證研究[J].財經科學,2002,7:21-24.
[7]Zmijewski. M.E. Methodological Issues Related to the Estimation of Financial Disterss Prediction Model[J].Journal of Accounting Research,1984,NO.22.
