大數據下醫保欺詐的有效識別模型
2018-03-12 00:38:48陳清鳳朱畝鑫
汕頭大學學報(自然科學版) 2018年1期
關鍵詞:模型
陳清鳳,朱 寧,朱畝鑫
(桂林電子科技大學數學與計算科學學院,廣西 桂林 541004)
0 引言
隨著參保覆蓋面和基金規模的迅速擴大,定點服務機構的大量增加,我國的醫保信息系統也得到了廣泛的應用,如何利用海量的醫療數據建立有效的醫保欺詐預警模型,為醫保中心實施監管的工作提供決策支持,是當前所要解決的首要任務.
對于醫療保險欺詐的理論分析和實證研究,國外學者主要從社會心理學、博弈論以及數據挖掘的角度進行研究.Arrow[1]根據信息不對稱理論,首次對健康保險欺詐問題進行了探討和研究.隨后Pauly[2],Schiller,Moreno[3]分別從管控道德風險和剔除受投保方操縱信號的方式反制欺詐.在此基礎上,Artis[4],Chiappori[5],Brocket[6]等人分別采用Probit、AAG、Pridit、logit等統計模型,對具體的欺詐行為進行識別.但由于這些模型對數據有一定的要求,加上欺詐的復雜性,這使得傳統的單一模型在實際的應用中受到很大的限制.為此Marisa S[7],Sokol[8],Lious[9],等人把人工智能識別模型和統計回歸模型進行有效的組合,分別建立了基于BP神經網絡模型、遺傳算法、貝葉斯網絡、糊集聚類算法、數據挖掘的欺詐識別模型,并用于特定的例子中,識別效果較好.除此之外基于啟發式和機器學習的電子欺詐識別技術也被廣泛的應用于醫療保險欺詐識別.
國內學者對醫療保險欺詐問題主要是運用信息不對稱和博弈論,圍繞欺詐的類型、表現形式、欺詐的成因分析和反欺詐措施等三個方面進行理論研究,關于社會醫療保險欺詐的識別和度量的研究還較少[10].對于社會醫療保險欺詐的識別,較早應用的是徐遠純[11]根據粗糙集理論的特征屬性提出的欺詐風險識別方法,隨后陳輝金、韓元杰[12]基于數據挖掘和信息融合技術建立孤立點集來挖掘可疑數據;梁子君[13]利用貝葉斯網絡建立了識別、評估和管控欺詐風險的概念模型;葉明華[14]把統計回歸和神經網絡進行有效融合,建立了基于江、浙、滬機動車保險索賠數據構建了欺詐識別的BP神經網絡模型.楊超[15]在葉明華的研究的基礎上,運用嵌入logistic回歸分析的BP神經網絡模型研究識別被保險人道德風險引致的欺詐.總的來說,如何從海量的復雜隱秘的醫療保險數據中識別出具有欺詐行為的信息還沒有得到具體的解決,為此把統計方法與大數據相結合的識別模型的研究是有意義的.
本文在大數據背景對醫療保險欺詐這一課題進行研究,首先對給定的醫療數據進行預處理,通過主成分分析構建欺詐識別的有效指標體系;其次由K-Means聚類得到可疑的醫保欺詐行為的類別;再次,利用因子分析方法,根據特征因子分析詐騙類的特征確定其詐騙方式;最后把模型用于由樣本經驗分布的反函數生成的大數據中.具體流程如圖1.
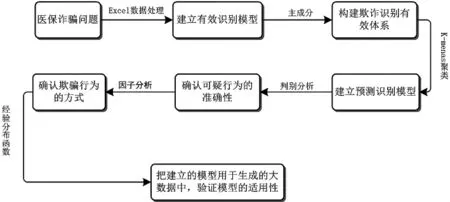
圖1 醫保欺詐模型流程圖
1 數據預處理
本文以2015年“深圳杯”數學建模夏令營A題:醫保欺詐行C醫保數據為研究數據,共289 001條記錄.為了構造醫保詐騙有效識別的數據集,本文利用大數據挖掘技術對參保人信息進行數據預處理,利用Excel軟件中的vlookup函數對原始數據進行定性篩選,去掉不必要的數據.
數據清洗基于課題的研究意義和方向,結合給出的6個表格的醫療數據,進行數據清洗.首先利用Excel中的透視表剔除缺失值個數大于列數20%的行,并刪除對于本次數據挖掘沒有意義數據,保留相關數據列,觀察得到的數據集中沒有重復記錄,省去了對重復記錄的處理.其次是對于缺失的必要數據,例如刷卡次數缺失的數據,其占總樣本的25.5%,采用數據歸約中多項式回歸的方法填補空缺,其他指標也如此.
數據的轉換清洗得到的數據轉換為便于處理的形式,日期采用“年-月-日”格式,醫囑ID號精簡成數字型.
生成有效識別數據集從給定的數據中提取出用于描述樣本的指標,從而解釋醫療數據的標簽和分類的來由.根據參保人信息數據集和醫保交易記錄數據集中的屬性對數據進行適當處理,進而派生出所需要的識別指標.對醫保交易記錄數據集中的重要屬性進行不重復計數處理,派生出總費用、刷卡總次數、一次性消費最高額、平均消費金額以及醫囑子類、開囑醫ID、下醫囑科室、核算分類、執行科室和病人科室的不重復計數這10個指標.
本文選取了具有代表性的屬性,并根據參保人信息數據集中的PAPMI_PAPER_DR(身份證ID)和醫保交易記錄數據集中的WorkLoad_PAPMI_DR(病人病歷ID)將兩數據集進行自然連接,從而生成目標數據集,即醫保詐騙有效識別數據集,見表1.此時數據集已經從初始的289 001條原始記錄整合成58 014條目標記錄.
表1 參保人信息和醫保交易記錄交叉數據集
數據標準化根據zij=(xij-x)i/si對提取出的數據集進行標準化處理,其中zij為標準化后的變量值,xij為實際變量值.
2 欺詐識別的有效指標體系的構建
由于得到的識別指標過多,如果對所有的指標進行分析可能會存在信息重疊,對部分個體的欺詐識別因子進行主成分分析,提取綜合指標來消除指標間相關性.首先,對指標進行了相關分析,運用SAS統計軟件導入包含58 014個醫保人信息的數據集,計算出各指標之間的Pearson相關系數,結果如表2.
由表2可以看出,部分指標之間存在著嚴重的相關性,如病人科室不重復計數和下醫囑科室不重復計數間的相關系數高達0.999,接近于1;一次性消費最高數額和總費用的相關系數也達到了0.758,說明原指標變量間有一定的相關性.此時如果直接對原來的指標進行分析就會造成信息的重復使用而使得結果不準確.
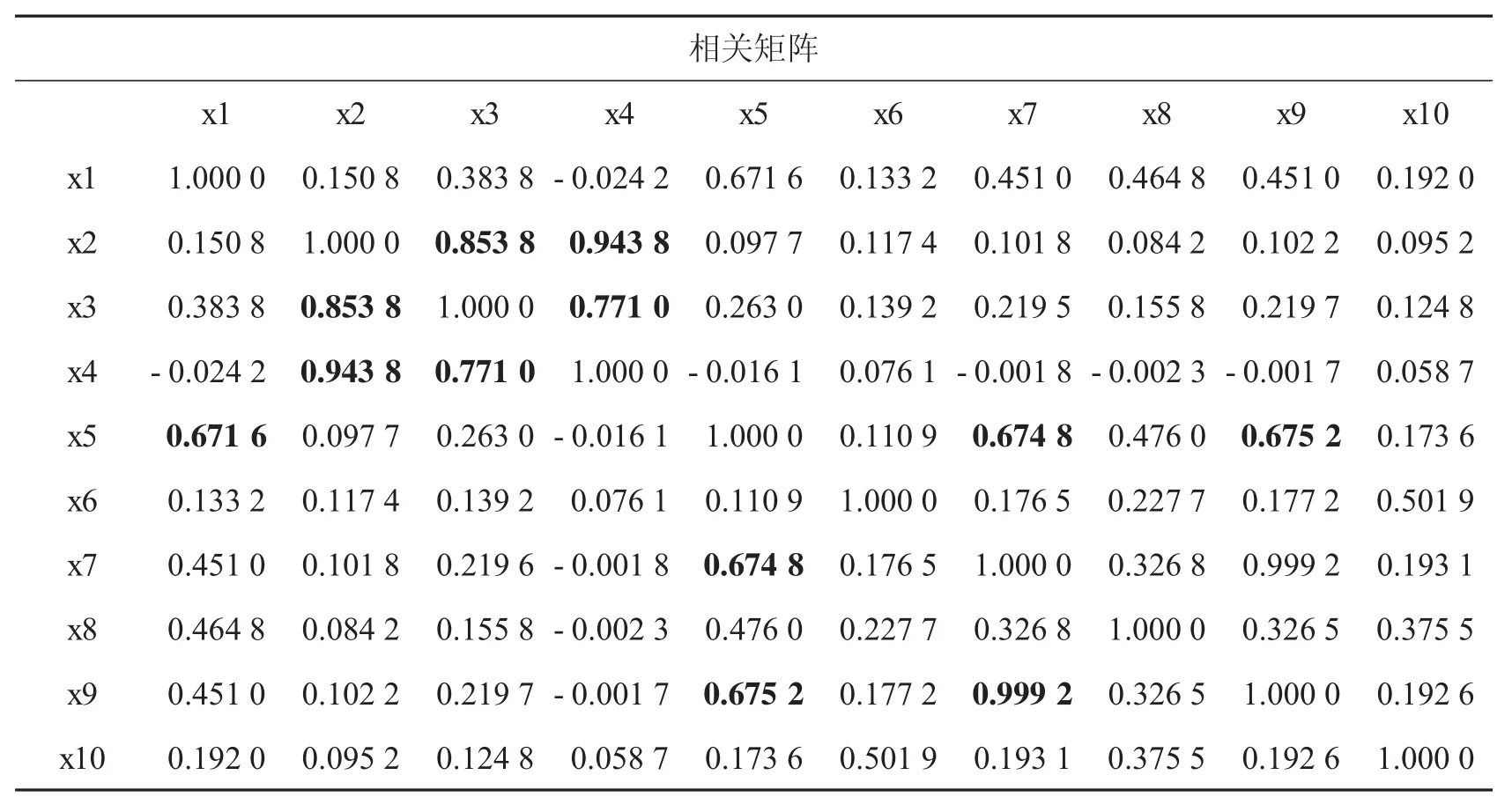
表2 指標之間Pearson相關系數
隨后,通過主成分分析來消除指標之間的相關性,提取出欺詐識別模型的綜合指標,結果如表3.
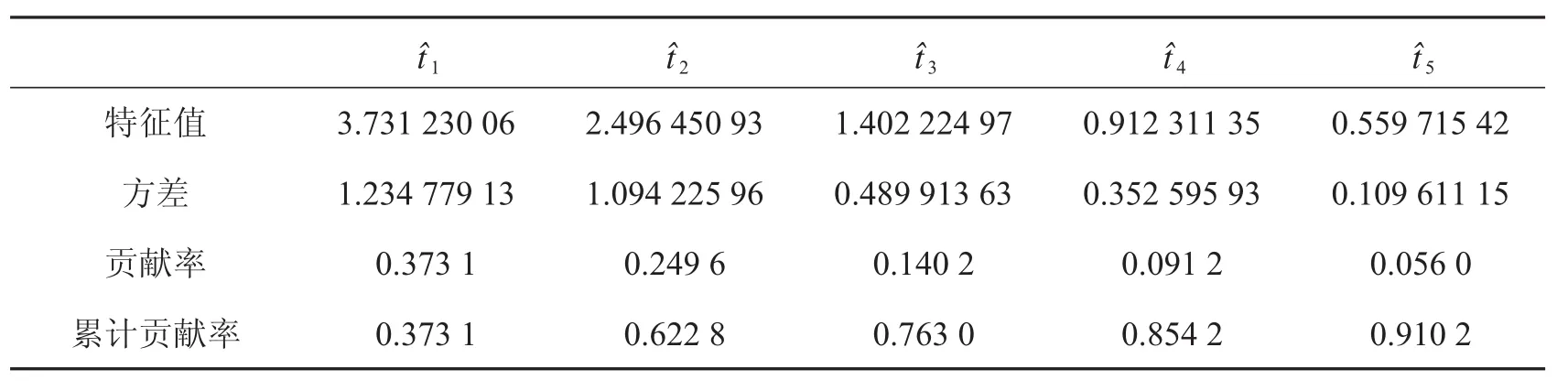
表3 主成分分析結果
由表3的數據可以看出,前五個主成分的累計貢獻率已達到91.02%,可以認為它們能較好地概括原始指標的大部分信息,即用前五個主成分作為欺詐識別指標.
3 欺詐識別的統計模型
3.1 隨機樣本的類平均聚類
為了更好的識別出醫保數據中的欺詐行為,根據收集到的六萬人的消費交易記錄,利用類平均聚類對其進行聚類獲取先驗信息,將主成分分析得到的前五個主成分作為綜合指標,通過無放回簡單隨機抽樣方法抽取5組樣本(每一組容量5 000)進行聚類,下面對其中一組建立醫保詐騙識別模型.聚類的信息如表4.
從R2統計量來看,當NCL(聚類數)>5時下降較緩慢,且NCL=5時下降較大,半偏相關統計量達到最大;從偽F統計量來看,NCL=5時,取得極大值,且NCL=5時,PST2(偽F統計量)取得極大值.由此可知,隨機樣本分成5類較合適.
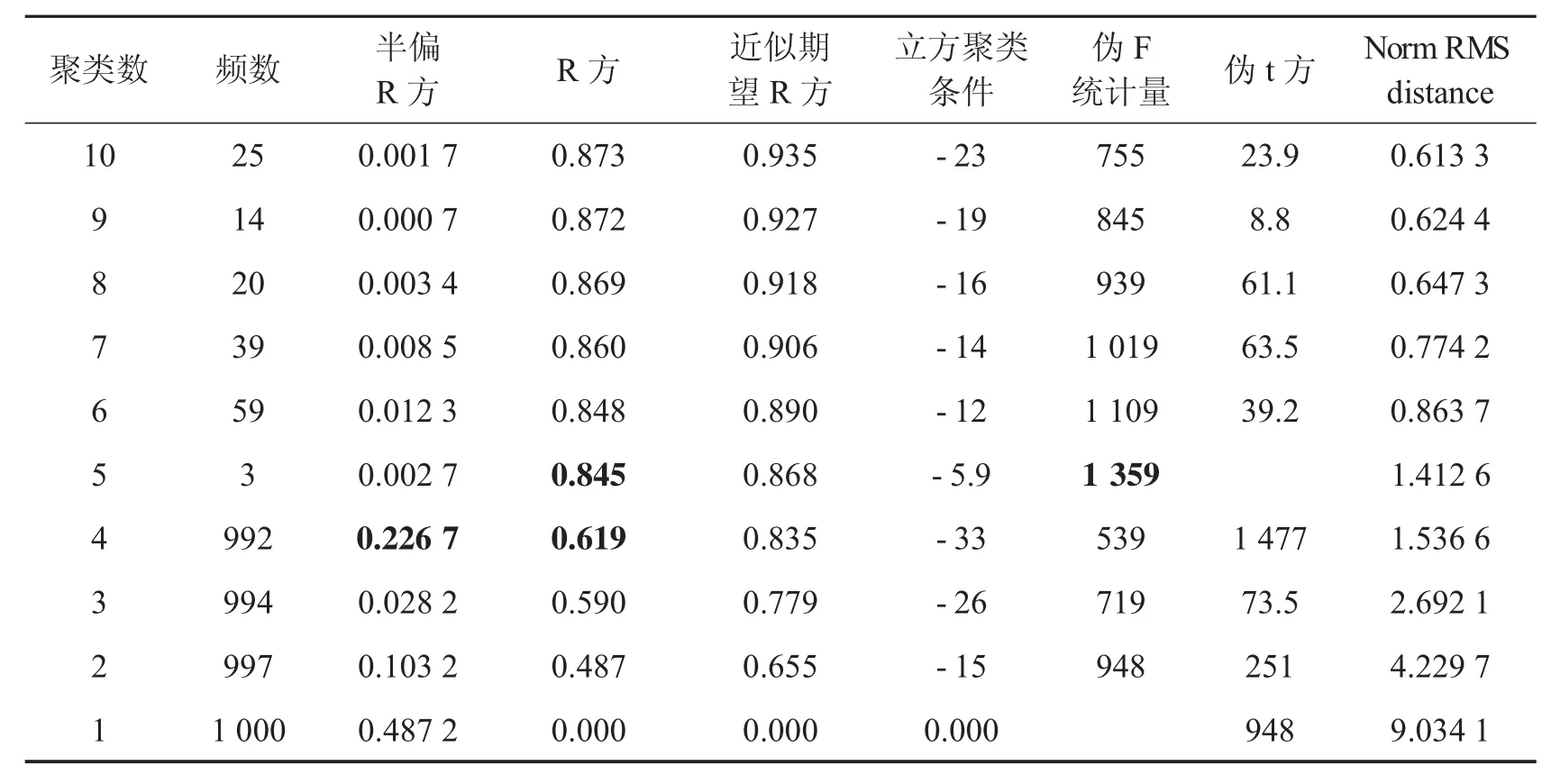
表4 隨機樣本類平均聚類結果
重復以上步驟,再對隨機抽取的其他4組樣本進行K-Means聚類分析,過程與上面樣本類似.通過對利用無放回簡單隨機抽取方法抽取到的5組樣本量為5 000的樣本依次進行主成分聚類分析,其中有3組樣本認為聚成5類最合適,其余2組比較分散,將這些信息作為先驗信息,根據最大似然函數的原理認為全部樣本聚成5類是合適的.聚類結果如表5.

表4 K-Means動態聚類
由表4看出第五類包含的樣本最多,共有50 111條記錄,其次是第三類,而第1、2、4類的個數較少.由于醫療保險詐騙事件屬于小概率事件,且詐騙的形式有多種,比如拿著別人的醫保卡配藥、在不同的醫院和醫生處重復配藥等,可以表現為單張處方藥費特別高、一張卡在一定時間內反復多次拿藥等.由表4的數據可直觀的認為第1、2、4類屬于醫保詐騙的可能性較大,因為它們組內均方根的標準差和從凝聚點到各類內觀測值的最大距離都比較大,說明這些類之間有一定的差異,存在著問題,需要謹慎對待.
3.2 模型檢驗—判別分析
為了驗證K-Means動態聚類結果的合理性,利用判別分析中的交叉確認估計來判斷聚類準確性,結果如表5和表6.
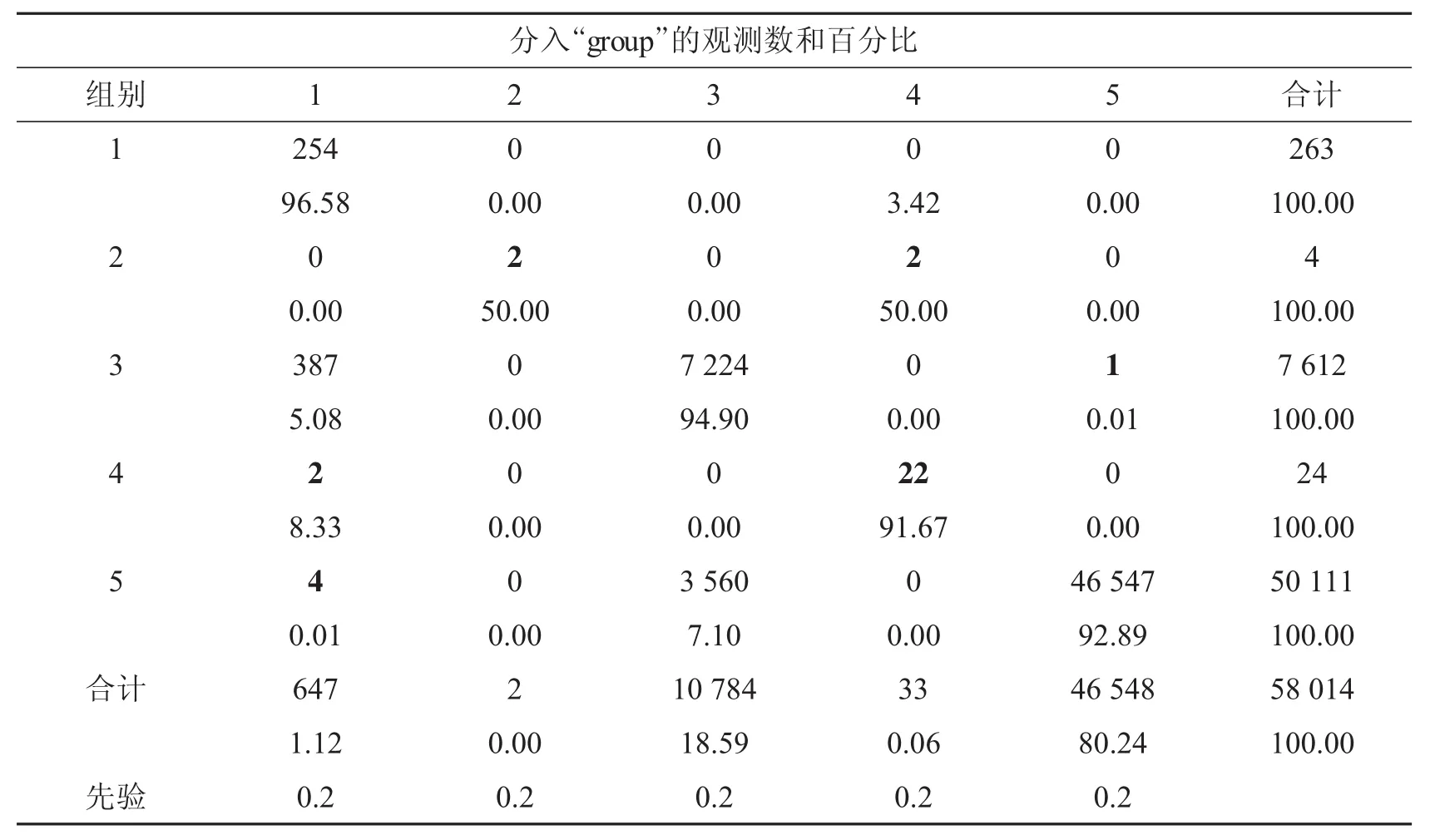
表5 各組錯判具體情況

表6 錯判概率
由表5和表6的數據可知,聚類時總體的錯判概率為0.147 9.其中第1組中錯判的樣本量為9個,錯判概率為0.034 2,且這9個錯判的樣本都被錯判到第4組;第2組中錯判的樣本量為2,錯判概率高達0.500 0,且這2個錯判的樣本都被錯判到第4組;第3組中錯判的樣本量為388,錯判概率為0.051 0,其中387個樣本被錯判到第1組,1個樣本被錯判到第5組;第4組中錯判的樣本量為2,錯判概率為0.083 3,且這2個錯判的樣本都被錯判到1組;第5組中錯判的樣本量為3 564,錯判概率高達0.071 1,其中4個樣本被錯判到第1組,3 560個樣本被錯判到第3組.
結合K-Means聚類的結合和判別分析的結果可知,在57 723個非欺詐個體中有391個可能屬于欺詐個體,錯判概率為0.677%;而初始判斷為欺詐類別的291個樣本中有0個被錯判,此時錯判概率為0%.由此可以初始確定的詐騙類別是合理的.
3.3 醫保欺詐識別的特征模型—因子分析
利用因子分析找出潛在的對醫療數據中較為可疑的醫療數據的特征進行分析,通過公共因子來查找出K-Means聚類中的第1,2,4類可疑詐騙的基本特征,最終確定詐騙方式.設特征值(Eigenvalues)、貢獻率(Contribution rate)和累計貢獻率分別用(Cumulative contribution rate)Eig、CR、CCR表示,則進行因子分析后的統計量如表7.
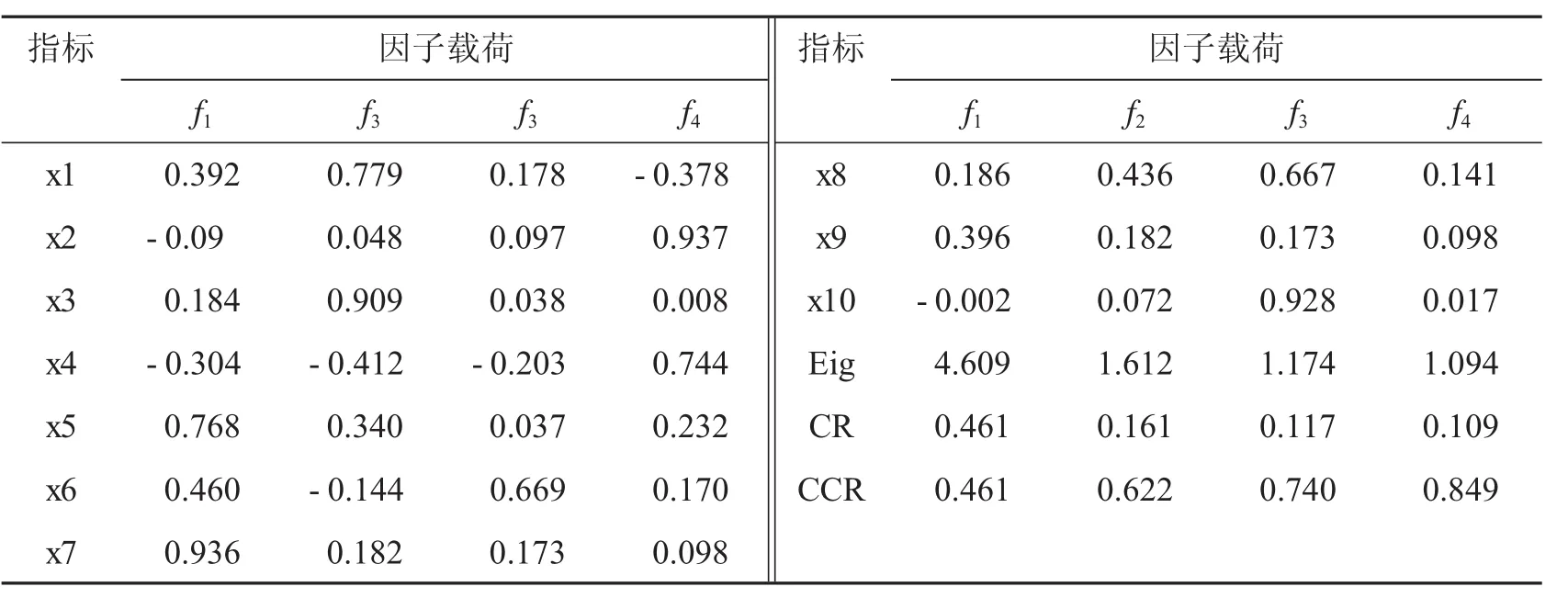
表7 因子分析統計量
從表7可以看出,在以100%的累計方差貢獻率確定的10個因子中,前4個因子特征值大于1,累計方差貢獻率高達84.9%,故考慮提取4個公因子.又從最大方差旋轉的因子載荷矩陣可知,公因子f1主要在病人科室非重復計數、開囑醫生ID非重復計數、執行科室非重復計數上具有較大的正載荷,故命名為科室分類因子;公共因子f2主要在刷卡次數、費用有很大的正載荷,故命名為刷卡費用因子;公共因子f3主要在執行科室非重復計數、醫囑子類非重復計數有較大的正載荷,故命名為醫療服務因子;公共因子f4主要在一次性消費最高金額、平均消費金額有很大的正載荷,故命名為費用因子.
通過上述分析可發現此類有個共同特點就是一次性消費平均消費最高金額,病人科室非重復計數所占比率最高,存在故意串通醫生開大處方行為,購大量藥品等來套取統籌醫保基金的嫌疑,屬于醫療保險服務供方與需方合謀的詐騙行為.
以此類推可以得到第2、第4類的詐騙方式.其中,第2類欺詐的方式可定義為販賣藥品詐騙,是指醫保患者通過醫保卡去不同的醫保定點醫院多次重復看病、取藥,然后再將多取的藥品販賣,從而達到騙取醫保基金的目的;第4類詐騙方式定義為分解收費詐騙,即定點醫療機構在為參保患者提供醫療服務過程中,人為地將一個完整的連續的醫療服務項目分成兩個或兩個以上的醫療服務項目,并按分割后的項目進行收費,從中獲取差價進行醫療詐騙.
綜上所述,可將欺詐行為分成三大類:
1.醫療保險服務供應方的詐騙行為;
2.醫療保險需求方的詐騙行為;
3.醫療保險服務供應方與需求方合謀的詐騙行為.
結合各類的具體特征,又可以將各欺詐行為分別定義為分解收費詐騙、販賣藥品詐騙、提供虛假證明或偽造病歷詐騙、冒名頂替詐騙.
3.4 大數據下的模型的優越性
為了驗證模型的適用性,將識別模型應用于生成的海量數據中運行.首先,把第一個指標的數據(刷卡次數(x1))由origin軟件擬合出樣本的分布函數為:
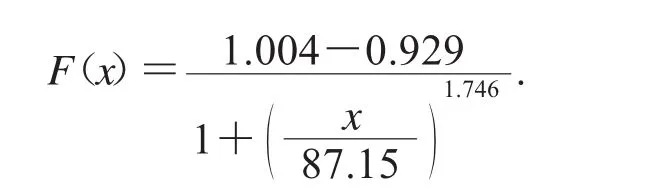
其次,產生符合該分布隨機,通過分布F(x)反函數求出隨機數對應的樣本x值,重復以上步驟便可得其他各指標的數據的樣本的分布函數,最后把提出的識別欺詐模型帶入求得的樣本值中,再利用上述方法重新運行一遍,以便驗證之前所用方法是否正確.
4 結論
研究結果表明:基于主成分K-Means聚類和因子分析的數據挖掘方法對醫保欺詐行為能夠進行較為準確的預警,與直接進行聚類相比,文中提出的模型運行速度較快、效率較高,并適用于大數據中的欺詐行為的識別.在設計思路上從統計分析的角度出發,定量地研究了如何從大量數據中識別出少數的可疑的醫保詐騙行為.
[1]ARROW K J.Uncertainty and the welfare economics of medical care[J].Uncertainty in Economics,1978,82(2):141-149.
[2]PAULY M V.Taxation,health insurance,and market failure in the medical economy[J].Journal of Economic Literature,1986,24(2):629-675.
[3]SCHILLER J.The impact of insurance fraud detection systems[J].Journal of Risk and Insurance,2006,73(3):421-438.
[4]ARTíS M, AYUSO M, GUILLéN M.Detection of automobile insurance fraud with discrete choice models and misclassified claims[J].Journal of Risk and Insurance,2002,69(3):325-340.
[5]CHIAPPORI P A,SALANIE B.Testing for asymmetric information in insurance markets[J].Journal of Political Economy,2000,108(1):56-78.
[6]BROCKETT P L.Fraud classification using principal component analysis of RIDITs[J].Journal of Risk and Insurance,2002,69(3):341-371.
[7]VIVEROSMS,NEARHOSJ P,ROTHMAN MJ.Applying data mining techniques to a health insurance information system[C]//VLDB'96 Proceedings of the 22th International Conference on Very Large Data Bases.San Francisco:Morgan Kaufmann Publishers Inc.1996:286-294.
[8]SOKOL L,GARCIA B,RODRIGUEZ J,et al.Using data mining to find fraud in HCFA health care claims[J].Topics in Health Information Management,2001,22(1):1-13.
[9]LIOU FM,TANG Y C,CHEN J Y.Detecting hospital fraud and claim abuse through diabetic outpatient services[J].Health Care Management Science,2008,11(4):353-358.
[10]林源.國內外醫療保險欺詐研究現狀分析[J].保險研究,2010(12):115-122.
[11]徐遠純,柳炳祥,盛昭瀚.一種基于粗集的欺詐風險分析方法[J].計算機應用,2004,24(1):20-21.
[12]陳輝金,韓元杰.數據挖掘和信息融合在保險業欺詐識別中的應用[J].計算機與現代化,2005(9):110-112.
[13]梁子君.保險公司操作風險管理——用貝葉斯網絡評估和管理保險欺詐[D].上海:上海財經大學,2006.
[14]葉明華.基于BP神經網絡的保險欺詐識別研究——以中國機動車保險索賠為例[J].保險研究,2011(3):79-86.
[15]楊超.基于BP神經網絡的健康保險欺詐識別研究[D].青島:青島大學,2014.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
