基于信任擴展和列表級排序?qū)W習的服務推薦方法
2018-03-14 09:22:54方晨張恒巍張銘王晉東
通信學報 2018年1期
方晨,張恒巍,張銘,王晉東
?
基于信任擴展和列表級排序?qū)W習的服務推薦方法
方晨1,2,張恒巍1,2,張銘1,2,王晉東1,2
(1. 信息工程大學三院,河南 鄭州 450001;2. 數(shù)字工程與先進計算國家重點實驗室,河南 鄭州 450001)
針對傳統(tǒng)基于信任網(wǎng)絡(luò)的服務推薦算法中信任關(guān)系稀疏以及通過QoS預測值排序得到的服務推薦列表不一定最符合用戶偏好等問題,提出基于信任擴展和列表級排序?qū)W習的服務推薦方法(TELSR)。在分析服務排序位置信息的重要性后給出概率型用戶相似度計算方法,進一步提高相似度計算的準確性;利用信任擴展模型解決用戶信任關(guān)系稀疏性問題,并結(jié)合用戶相似度給出可信鄰居集合構(gòu)建方法;基于可信鄰居集合,利用列表級排序?qū)W習方法訓練出最優(yōu)排序模型。仿真實驗表明,與已有算法相比,TELSR在具有較高推薦精度的同時,還可有效抵抗惡意用戶的攻擊。
服務推薦;排序?qū)W習;概率型用戶相似度;信任關(guān)系
1 引言
隨著互聯(lián)網(wǎng)的普及和云計算技術(shù)的迅猛發(fā)展,網(wǎng)絡(luò)上提供的Web服務呈指數(shù)級增長。用戶迫切地需要一種有效的服務推薦方法來解決其面臨的選擇困境。因此,服務推薦技術(shù)在服務計算領(lǐng)域獲得了廣泛的關(guān)注。Web服務的服務質(zhì)量(QoS, quality of service)包括服務失效率、響應時間、成本、吞吐量等[1],是用戶進行服務選取時需要考慮的重要屬性之一。而由于Web服務廣泛地分布在網(wǎng)絡(luò)中,一些QoS屬性如響應時間、吞吐量等經(jīng)常受到網(wǎng)絡(luò)環(huán)境動態(tài)變化的影響,具有很大的不確定性,這就造成了服務推薦可靠性差的問題。
為解決此問題,研究者們考慮將協(xié)同過濾算法應用到服務推薦過程中,通過預測QoS值并以此對服務進行排序來實現(xiàn)推薦[2]。為了提高QoS預測的準確性,研究者們對傳統(tǒng)協(xié)同過濾算法做出了一系列改進,包括引入用戶的信任網(wǎng)絡(luò)[3]、服務調(diào)用模式[4]、服務的上下文信息[5]等。主要存在的問題為1) 沒有有效利用服務的排序位置信息;2) 引入的信任網(wǎng)絡(luò)中用戶直接信任關(guān)系稀疏,難以提供足夠的輔助信息。
近幾年來,有研究者考慮將排序?qū)W習技術(shù)引入推薦算法中來,通過直接優(yōu)化最終的排序列表來提高推薦系統(tǒng)的準確性[6]。作為一種強監(jiān)督性機器學習算法,排序?qū)W習能夠整合大量復雜特征并自動學習最優(yōu)參數(shù),降低了考慮單個因素進行排序的風險,且能夠通過多種方法來規(guī)避過擬合問題,獲得了學術(shù)界越來越多的關(guān)注[7]。然而,目前很少有研究將傳統(tǒng)協(xié)同過濾算法與排序?qū)W習技術(shù)結(jié)合起來,并應用到服務推薦領(lǐng)域。
針對上述問題,本文提出基于信任擴展和列表級排序?qū)W習的服務推薦方法(TELSR, trust expansion and listwise learning-to-rank based service recommendation method)。該方法首先在分析服務排序位置信息重要性的基礎(chǔ)上,給出概率型用戶相似度計算方法(PUSC, probabilistic user similarity computation method),提高相似度計算準確性;然后,提出信任擴展模型充分挖掘用戶信任網(wǎng)絡(luò)信息,并結(jié)合用戶相似度構(gòu)建可信鄰居集合;最后,利用可信鄰居集合改進列表級排序?qū)W習算法,通過訓練得到最符合用戶偏好的服務推薦列表。本文的主要貢獻有以下3點。
1) 給出概率型用戶相似度計算方法,有效利用了服務的排序位置信息,提高了相似度計算準確性。
2) 提出信任擴展模型,充分挖掘了用戶信任關(guān)系,構(gòu)建出可信鄰居集合,能夠抵抗惡意用戶的攻擊。
3) 改進列表級排序?qū)W習算法,可輸出最符合用戶興趣偏好的服務推薦列表。
2 相關(guān)工作
協(xié)同過濾最早是由Goldberg等[8]在1992年提出的,后來被廣泛應用于電子商務領(lǐng)域,并且取得了極大的成功。其核心思想是:在用戶群中尋找與目標用戶評分行為相似的鄰居用戶,然后基于這些鄰居用戶對服務的評分向目標用戶做出推薦[9]。目前,已有很多學者將協(xié)同過濾算法應用到服務推薦過程中,并對其做出了一系列的改進。王海艷等[10]引入服務的推薦個性屬性特征來改進傳統(tǒng)的相似度計算式,并結(jié)合用戶之間的信任關(guān)系對服務的評分值進行預測,進而對用戶做出推薦。Liu等[11]利用服務的流行度特征改進相似度計算,并根據(jù)用戶和服務的地理位置來縮小相似用戶的尋找范圍,相比傳統(tǒng)推薦算法更加高效;Hu等[12]在尋找相似鄰居時融入了服務調(diào)用的時間信息,并通過線性加權(quán)的方式綜合了基于相似用戶和相似服務的QoS預測結(jié)果。文獻[10~12]均是通過改進相似度計算來提高算法準確性,屬于基于近鄰的協(xié)同過濾算法。此外,還有部分研究者利用數(shù)學模型來預測服務的QoS,并取得了較好的成果。Wei等[13]利用矩陣分解模型將高維的用戶—服務矩陣分解為低維的用戶矩陣和服務矩陣,并將位置屬性融入矩陣分解的正則項中,有效提高了QoS預測精度;胡堰等[14]借助隱含類別表示用戶指標偏好、用戶及服務情境三者之間的依賴關(guān)系,并建立隱語義概率模型用于預測用戶在特定服務情境下的個性化指標偏好,然后計算出每個候選服務的效用值進行推薦;Wang等[15]考慮到了QoS值在不同時間段的動態(tài)變化特性,對QoS預測值的殘差進行零均值拉普拉斯先驗分布假設(shè),將QoS預測問題轉(zhuǎn)化為Lasso回歸問題進行求解。文獻[13~15]有效利用了數(shù)學模型的精確性,屬于基于模型的協(xié)同過濾算法。可見,上述工作的研究重點均集中在提高QoS值預測的準確性方面,而近年來有研究者發(fā)現(xiàn)QoS值預測的準確性并不能確保服務推薦的準確性,引言已給出相關(guān)示例。
排序?qū)W習作為一種強監(jiān)督性機器學習算法,能夠直接針對最終的推薦列表進行優(yōu)化,這一特性可以避免根據(jù)QoS值排序來間接得到推薦列表帶來的缺陷。根據(jù)優(yōu)化目標的不同,排序?qū)W習主要分為3類:點級(pointwise)、對級(pairwise)、列表級(listwise)[7]。點級排序的處理對象是單獨的一個項目,通過預測評分實現(xiàn)推薦,其相當于傳統(tǒng)的預測QoS值的服務推薦方法;對級排序是根據(jù)評分來定義項目對之間的偏序關(guān)系,最終通過整合所有項目對的偏序關(guān)系得到整個排序列表,而其時間復雜度高,且在整合推薦列表時會損失一定的準確性;列表級排序的處理對象是所有的項目,直接對整個排序列表進行優(yōu)化,在運行效率和推薦準確性方面具有更明顯的優(yōu)勢,因此,成為被研究最多的方法。
Huang等[6]利用基于排列概率的相似度來尋找更準確的鄰居用戶,然后通過最小化目標用戶和鄰居用戶在未評分項目集合上的交叉熵損失函數(shù),來得到最優(yōu)的排序列表。Weimer等[16]提出了一種最大化邊界矩陣因式分解算法CoFiRank,通過直接優(yōu)化排序評價標準NDCG來進行推薦。Shi等[17]提出一種基于上下文感知的推薦方法,利用張量分解優(yōu)化MAP評測準則,是首個能夠挖掘用戶隱式反饋和上下文信息,并將列表級排序?qū)W習和協(xié)同過濾算法相結(jié)合的方法。但是列表級排序?qū)W習算法依然面臨著用戶惡意評分、數(shù)據(jù)稀疏性等傳統(tǒng)難題,且目前還缺乏將該算法改進并應用到服務推薦領(lǐng)域的研究。
3 基于信任擴展和列表級排序?qū)W習的服務推存方法
本節(jié)給出基于信任擴展和列表級排序?qū)W習的服務推薦方法,該方法首先將用戶表示為已調(diào)用服務集合的概率分布,基于Kullback-Leibler(KL)距離進行概率型用戶相似度的計算,以此提高用戶相似度計算的準確性;然后,利用信任擴展模型充分挖掘用戶信任網(wǎng)絡(luò)中的信任關(guān)系,并結(jié)合用戶相似度構(gòu)建為目標用戶構(gòu)建可信鄰居集合,以此抵抗某些惡意用戶的攻擊;最后,利用可信鄰居集合改進列表級排序?qū)W習算法,訓練出最優(yōu)的服務排序列表推薦給用戶。其中,概率型用戶相似度計算方法、可信鄰居集合構(gòu)建算法(TNSC, trusted neighbor set construction algorithm)以及列表級排序?qū)W習預測算法(PABL, prediction algorithm based on listwise learning-to-rank)為TELSR的核心,下面重點對它們進行介紹。
3.1 概率型用戶相似度計算方法
協(xié)同過濾算法的核心步驟是尋找相似用戶,可采用的方法主要有Pearson相關(guān)系數(shù)、余弦相似性、修正的余弦相似性等[10]。目前大多數(shù)服務推薦算法都是基于Pearson相關(guān)系數(shù)改進得來的,其基本定義如下。
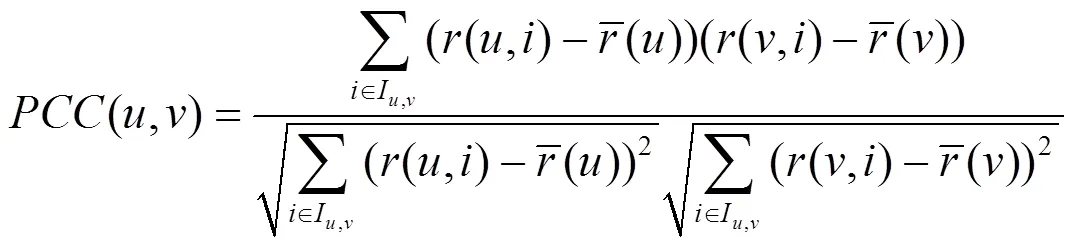
用戶調(diào)用服務示例如圖1所示,假設(shè)用戶A、B、C共同調(diào)用過的服務集合為I={a,b,c,d},這4個服務的QoS(如可用性,用百分制表示)分別為A=(0, 20%, 80%, 100%), B=(10%, 0, 80%, 100%), C=(0, 22%, 100%, 89%),采用Pearson相關(guān)系數(shù)計算得,即用戶B、用戶C和用戶A是同等相似的。從圖1可以看出,如果根據(jù)服務可用性大小對服務進行排序,用戶B對于服務a、b的排序與用戶A是相反的,而用戶C對于服務c、d的排序與用戶A是相反的。此時,若利用用戶B做推薦,則其向用戶A推薦的最好服務是d,正好符合用戶A的需求;若利用用戶C做推薦,則其向用戶A推薦的最好服務是c,違背用戶A的需求。相比之下,用戶B的推薦結(jié)果更加可信,所以理論上用戶B與用戶A的相似度應該更大。原因在于,在實際推薦系統(tǒng)中,用戶主要關(guān)注排在推薦列表中前面質(zhì)量較優(yōu)的服務,對于排在后面質(zhì)量較差(如可用性低于50%)的服務給予的關(guān)注較少。因此,服務的排序位置是除了QoS數(shù)據(jù)之外另一個能夠反映用戶興趣偏好的重要信息。
基于此,本文充分挖掘服務的排序位置信息,借鑒Mollica等[18]提出的Plackett-Luce模型,將每個用戶表示為已調(diào)用服務集合排列的概率分布,然后進行用戶相似度的計算,從而找到更加準確的相似用戶。為方便下文討論,定義如下。
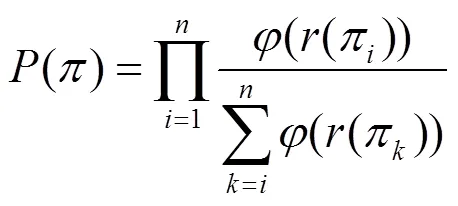
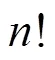
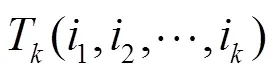
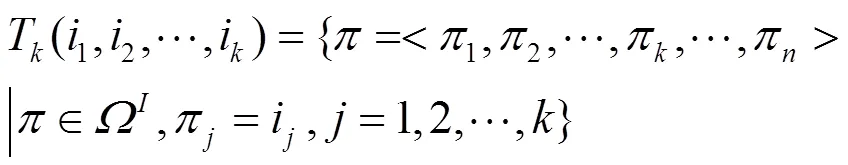
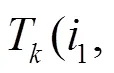
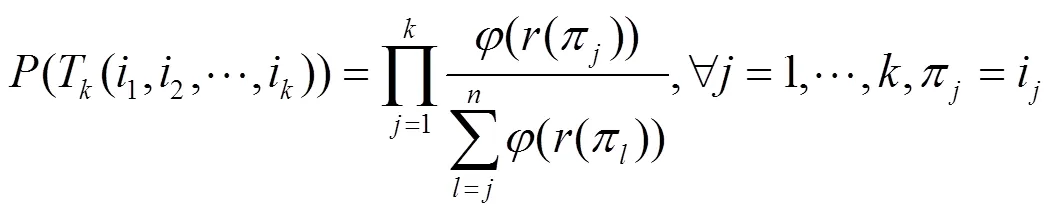
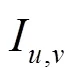
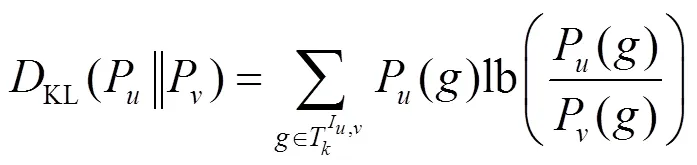
定義7 概率型用戶相似度。用戶和之間的概率型相似度可定義為
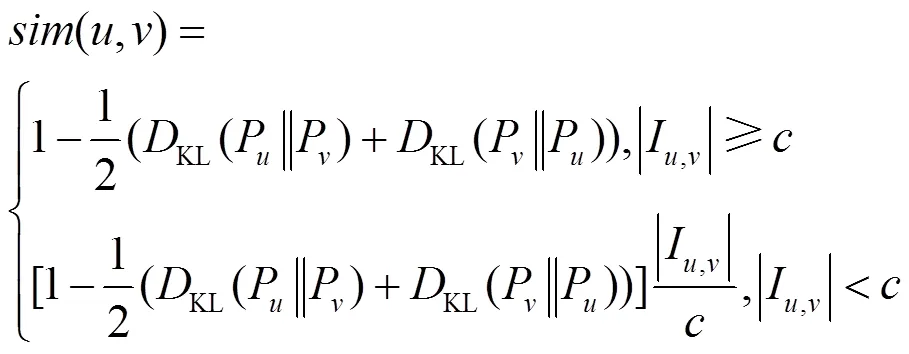
算法1 概率型用戶相似度計算
begin
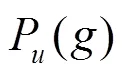
6) end for
end

3.2 可信鄰居集合構(gòu)建算法
利用PUSC可計算其他用戶與目標用戶的相似度,然后選取出相似度較大的用戶作為鄰居進行推薦。但是當推薦系統(tǒng)中存在惡意用戶對服務QoS值進行虛假評價時,此時,若把這類用戶當作鄰居,會極大影響推薦的精度。基于此,本文利用用戶間的信任關(guān)系建立可信鄰居集合來進行推薦,從而避免惡意用戶的攻擊。為了解決傳統(tǒng)基于信任的服務推薦算法中信任關(guān)系稀疏性問題,本文提出信任擴展模型,同時考慮直接信任關(guān)系和間接信任關(guān)系。
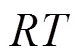
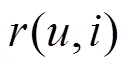
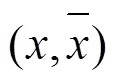
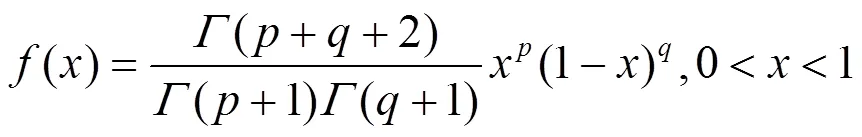
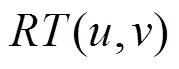

由式(8)可知,用戶和之間的直接信任度與有效推薦行為次數(shù)成正比,因此,其可以甄別某些用戶反常的惡意評價行為。然而,在實際推薦系統(tǒng)中,用戶之間的相互交互記錄往往較少,導致直接信任關(guān)系稀疏性問題。為此,本文利用信任關(guān)系的傳遞特性來擴大用戶的信任范圍,并給出如下定義。
間接信任傳遞關(guān)系如圖2所示。由圖2可知,用戶和均與用戶和之間存在直接信任關(guān)系,根據(jù)信任關(guān)系的傳遞性,可以通過用戶和建立起用戶和之間的間接信任關(guān)系。
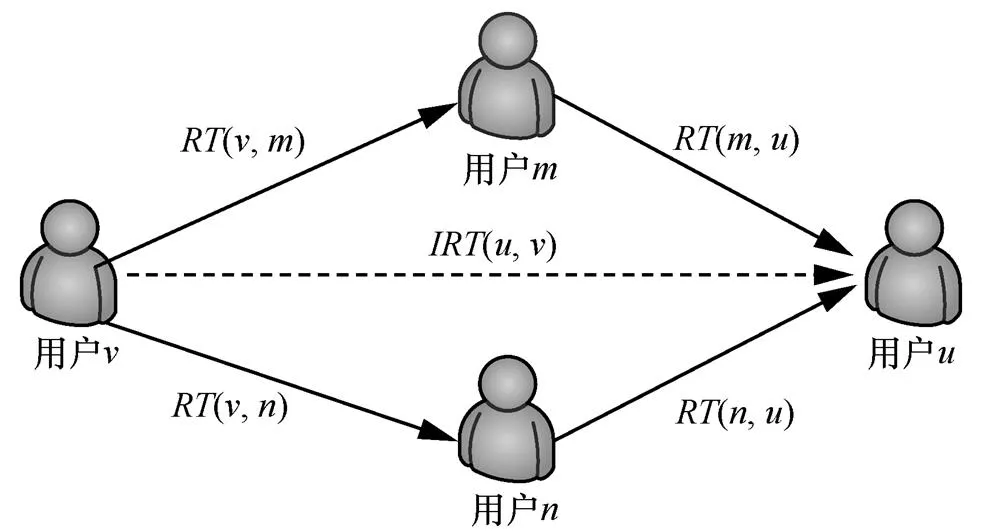
圖2 間接信任傳遞關(guān)系
定義11 間接信任度。若用戶的直接信任集合為,利用中所有與用戶有直接信任關(guān)系的用戶來進行信任傳遞,則用戶和之間的間接信任度為

定義12 綜合信任度。通過綜合直接信任度和間接信任度,得到用戶之間的綜合信任度為
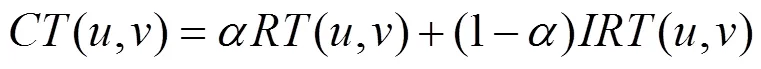
定義13 可信相似度。綜合考慮用戶和之間的概率相似度和綜合信任度,得到用戶和的可信相似度為

基于可信相似度的定義,本文提出可信鄰居構(gòu)建算法,如算法2所示。
算法2 可信鄰居構(gòu)建
輸入 目標用戶,其他用戶集合,參數(shù)
輸出 目標用戶的可信鄰居集合N
begin
7) end for
8)N←按照可信相似度由大到小對用戶進行排序,選取前個用戶作為目標用戶的可信鄰居集合
end
3.3 列表級排序?qū)W習預測算法
為了利用可信鄰居集合來提高服務推薦的準確性,本文首先利用矩陣分解模型來預測服務的QoS值,然后利用列表級排序?qū)W習算法訓練出最優(yōu)的服務排序模型。為了方便描述,定義參數(shù)如下。
1) 參數(shù)定義
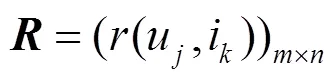
:用戶服務評分矩陣,其中,m為用戶的個數(shù),n為服務的個數(shù)。
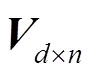
:維的服務隱含特征矩陣。
:隱含特征數(shù)。

:矩陣V的第k列向量,代表服務的隱含特征向量。
2) 矩陣分解模型
矩陣分解模型是在協(xié)同過濾推薦算法中應用最為廣泛的模型之一。其主要思想是將用戶服務評分矩陣近似分解為低維的用戶隱含特征矩陣和服務隱含特征矩陣,計算式為
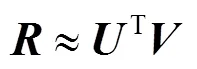
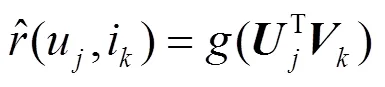
算法通過最小化預測評分矩陣和原評分矩陣的誤差來實現(xiàn)QoS值的精確預測[21]。在現(xiàn)實生活中,人們對于一個服務的評價往往會受到所信任好友的影響。因此,為了提高服務推薦的準確性,本文在預測QoS值時加入可信鄰居用戶的影響,將式(13)改進為
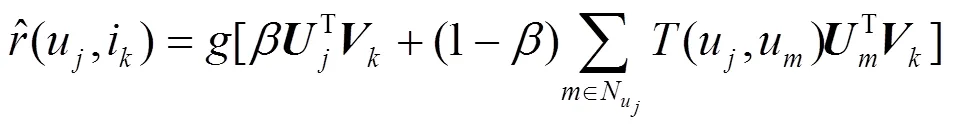
3) 列表級排序?qū)W習模型
列表級排序?qū)W習直接針對最終的排序列表進行優(yōu)化,可以避免僅僅根據(jù)QoS值排序帶來的不準確性。其核心思想是:將預測排序列表和正確排序列表之間的交叉熵作為損失函數(shù),通過訓練過程最小化其交叉熵,從而使最終得到的預測排序模型最接近正確排序模型[7]。本文基于top-1概率,將交叉熵損失函數(shù)定義如下。
定義14 top-1概率。服務在用戶的推薦列表中排在第一位置的概率,定義為
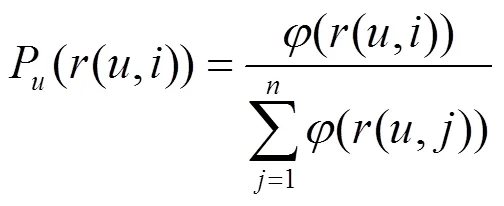
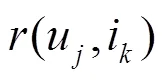
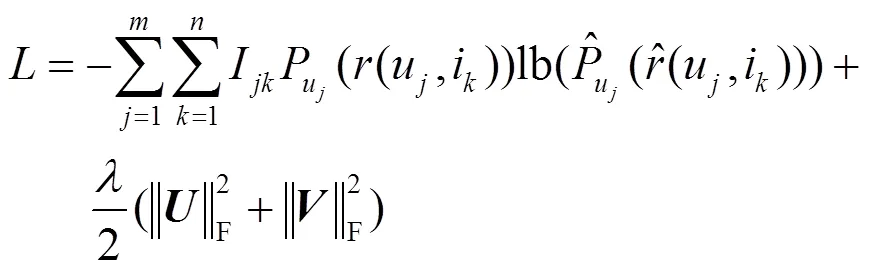
基于交叉熵損失函數(shù)的定義,給出列表級排序?qū)W習預測算法,具體如算法3所示。
算法3 列表級排序?qū)W習預測
輸出 每一個用戶的最佳服務推薦列表
begin
1) 根據(jù)訓練數(shù)據(jù)集,利用式(15)計算得到正確排序列表的概率分布
2) 利用式(14)算出初始所有服務的QoS預測值
3) 利用式(15)算出初始預測排序列表的概率分布
4) 利用式(16)計算初始交叉熵損失函數(shù)
6) 更新用戶隱含特征矩陣和服務隱含特征矩陣
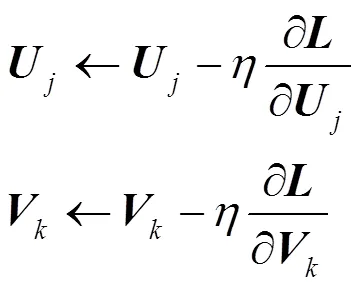
7) 記錄上次交叉熵損失函數(shù)
8) 利用式(14)算出新的所有服務的QoS預測值
9) 利用式(15)算出新的預測排序列表的概率分布
13) end for
15) 將所有服務按照top-1概率由大到小進行排序,得到最佳服務排序列表,推薦給用戶
16) end for
end
3.4 TELSR描述
經(jīng)過上述分析,TELSR的具體過程如下。
1) 運用PUSC計算每一個用戶與其他用戶的概率型相似度。
2) 運用TNSC為每一個用戶建立可信鄰居集合。
3) 根據(jù)訓練數(shù)據(jù)集得到用戶服務評分矩陣,初始化用戶隱含特征矩陣和服務隱含特征矩陣。
4) 運用PABL得到每一個用戶的最佳服務推薦列表。
TELSR首先通過Plackett-Luce模型將用戶表示為已調(diào)用服務集合的概率分布,并利用PUSC計算用戶的概率型相似度,其優(yōu)點在于利用了服務的排序位置信息,使相似度計算更加準確;為了消除推薦系統(tǒng)中惡意用戶隨意打分的影響,利用TNSC為用戶建立可信鄰居集合,其優(yōu)點在于充分挖掘用戶間的直接信任關(guān)系和間接信任關(guān)系,緩解了用戶信任網(wǎng)絡(luò)稀疏性問題;最終利用可信鄰居集合改進QoS預測值的準確性,并利用列表級排序?qū)W習的強大數(shù)據(jù)處理能力,訓練出最優(yōu)的排序模型,為用戶提供最符合其偏好的服務推薦列表。
3.5 算法時間復雜度
4 實驗結(jié)果與分析
4.1 實驗設(shè)置
本實驗使用由Zheng等[22]收集并公共發(fā)布的WS-DREAM數(shù)據(jù)集,它是由分布在全球20多個國家的150個電腦節(jié)點收集的QoS信息,構(gòu)成了約150萬條QoS調(diào)用記錄,其內(nèi)容主要包括Web服務的往返響應時間RTT、數(shù)據(jù)塊大小、響應結(jié)果等屬性,表1展示了該數(shù)據(jù)集的部分服務實例信息。
本文選用往返響應時間RTT作為評價QoS的標準,當用戶調(diào)用某服務超過100次時,計算出RTT的均值,最終得到一個150×100的用戶服務矩陣。為了研究算法的推薦準確性,本文從原始的用戶服務矩陣中隨機地剔除部分QoS值,形成了5個不同的稀疏矩陣,其密度分別為0.04、0.08、0.12、0.16、0.20。之所以選擇小密度矩陣,是因為在海量的Web服務環(huán)境中,用戶只調(diào)用過很少的服務,因此,其真實的用戶服務矩陣就是很稀疏的。
本文使用5重交叉驗證作為實驗方法,將稀疏矩陣隨機分為5份,每次選擇其中的4份即矩陣的80%作為訓練集,選擇余下的1份即矩陣的20%作為測試集。每次實驗重復5次,取平均值得到最終的評估結(jié)果。由于本文認為用戶更在意最終獲得的服務推薦列表中服務排序的準確性,因此,采用NDCG(normalized discounted cumulative gain)作為衡量算法推薦性能的標準。NDCG值越大,表示算法的推薦性能越好[7]。
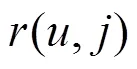
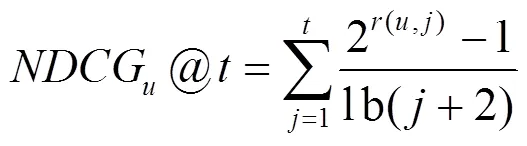
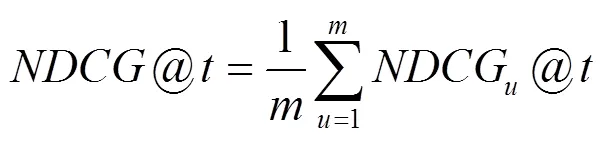
4.2 參數(shù)對算法性能的影響

表1 部分數(shù)據(jù)集信息

圖3 參數(shù)對于推薦性能的影響
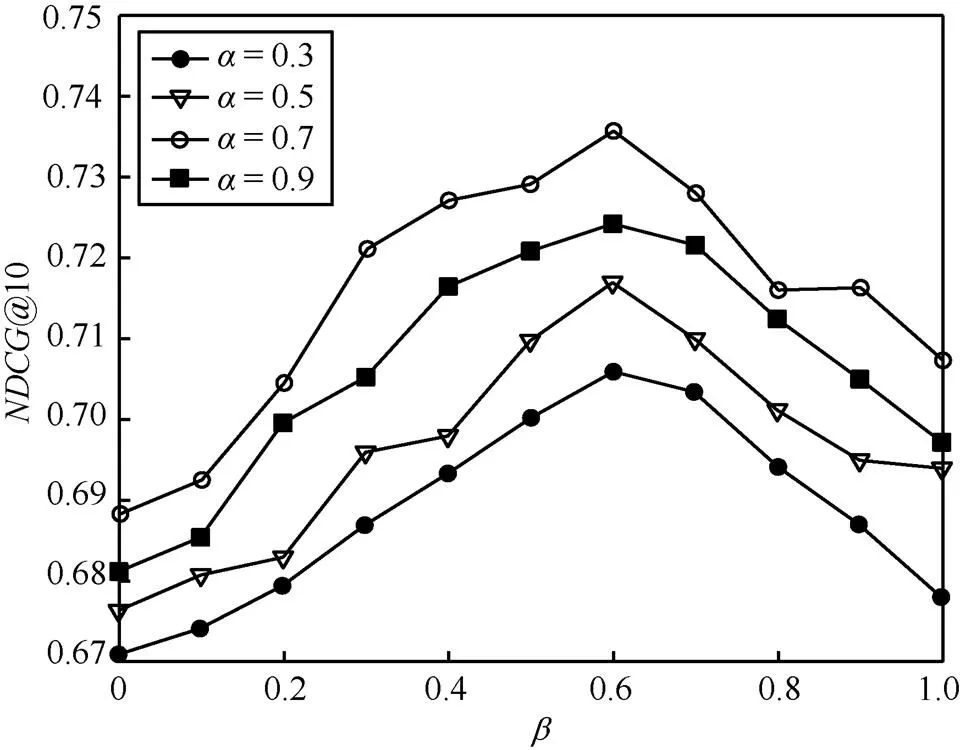
圖4 參數(shù)對于推薦性能的影響
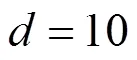
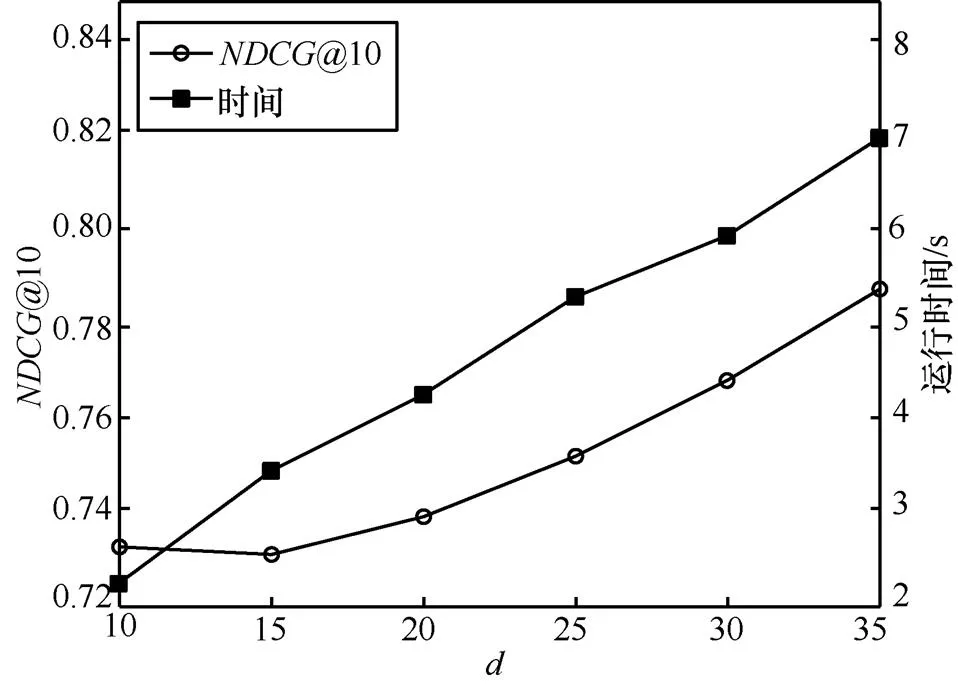
圖5 隱含特征數(shù)d對于推薦性能的影響
4.3 算法運行時間的比較
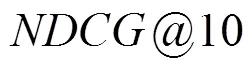
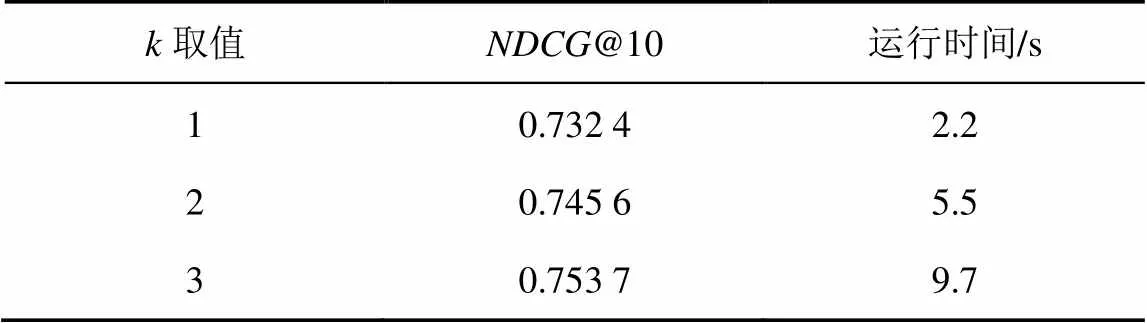
表2 k取值的影響
由表2可以看出,隨著的取值不斷增大,算法的推薦性能提高非常小,但是算法的運行時間卻大幅增加。當=3時,算法的推薦性能@10比=1時提高了2.9%,但是運行時間增加了341%。而=1時,算法就可以在較短的運行時間內(nèi)實現(xiàn)較好的推薦性能。因此,本文實驗中均設(shè)置=1。
為了衡量算法的運行時間性能,將TELSR與以下4種經(jīng)典的推薦算法做比較。
1) CF-DNC[23]
該算法首先利用“興趣相似用戶集選取算法”動態(tài)選取目標用戶的相似鄰居,然后提出“用戶信任計算模型”,篩選出目標用戶的可信鄰居用戶集,最后提出了一種新的協(xié)同過濾算法,綜合利用可信鄰居的評分信息,對服務的評分值進行預測。
2) TACF[12]
該算法有效融合了服務調(diào)用時間信息,提出“時間感知的相似度算法”,尋找更加準確的相似用戶和相似服務,然后設(shè)計“個性化隨機游走算法”來克服數(shù)據(jù)的稀疏性,最后利用混合協(xié)同過濾算法預測服務的QoS值。
3) listPMF[24]
該算法改進了概率矩陣分解模型,根據(jù)用戶評分得到用戶的偏好序列,并通過最大化預測的偏好序列和已知的偏好序列的后驗概率來實現(xiàn)項目的推薦,屬于基于列表級排序的協(xié)同過濾算法。
4) listCF[6]
該算法通過計算用戶共同打分項目集合的Jansen-Shannon散度,來度量用戶的相似度,并通過最小化目標用戶和鄰居用戶的加權(quán)交叉熵損失函數(shù)來做預測,屬于基于列表級排序的協(xié)同過濾算法。
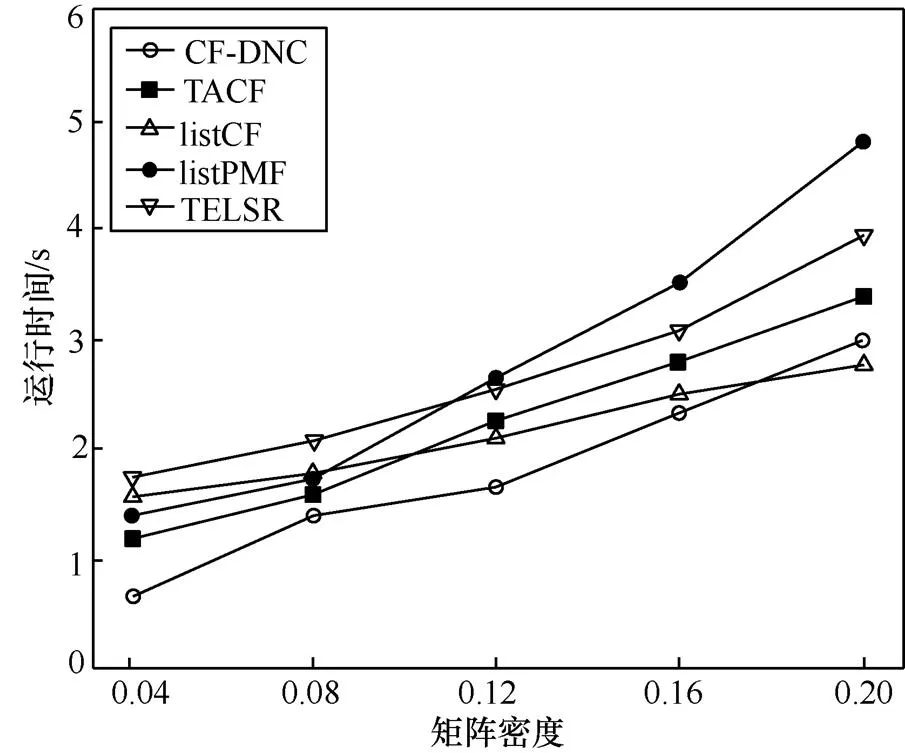
圖6 不同算法運行時間的比較
由圖6可以看出,隨著矩陣密度的增加,本文提出的TELSR的運行時間比listPMF短,但是比CF-DNC、TACF和listCF稍長,具體原因如下。
1) listPMF基于用戶和項目的隱含特征矩陣來預測用戶的偏好序列。當矩陣密度增加時,需要預測的用戶偏好序列數(shù)量增多,且隨著隱含特征矩陣的不斷更新,算法計算量成倍增長,導致listPMF的運行時間大幅度增加,甚至超過了TELSR。
2) CF-DNC和TACF均是在傳統(tǒng)的Pearson相關(guān)系數(shù)的基礎(chǔ)上改進的相似度計算方法,可以直接利用數(shù)據(jù)集中的QoS值。而TELSR采用PUSC,首先需要根據(jù)已有的QoS數(shù)據(jù)計算出用戶調(diào)用服務的概率分布,才能進行下一步的相似度計算。
3)listCF選取出鄰居用戶之后,直接利用列表級排序算法進行QoS值預測。而TELSR還增加了用戶信任度的計算,并結(jié)合用戶相似度提出了可信鄰居構(gòu)建算法TNSC。
由于TELSR屬于混合型算法,內(nèi)容同時涉及用戶相似度、信任度和QoS預測,因此,其計算量更大,但根據(jù)第3.5節(jié)和圖6可知,隨著矩陣密度的增加,其運行時間仍保持了線性增長的趨勢,說明TELSR算法是可以應用在大型Web服務數(shù)據(jù)集上的。
4.4 推薦準確性的比較
2) 在5種算法中,listCF和TELSR表現(xiàn)最為優(yōu)異,它們均屬于listwise CF,但是TELSR在listCF的相似度的基礎(chǔ)上加入了信任度的計算,因此其推薦性能相對于listCF有所提升,且提升幅度隨著矩陣密度的增加而增加。因為隨著矩陣中已知QoS值的服務的增多,TELSR能夠在用戶之間發(fā)現(xiàn)更多的有效推薦行為,從而使其信任度計算更加準確,進一步提升了算法的推薦性能。
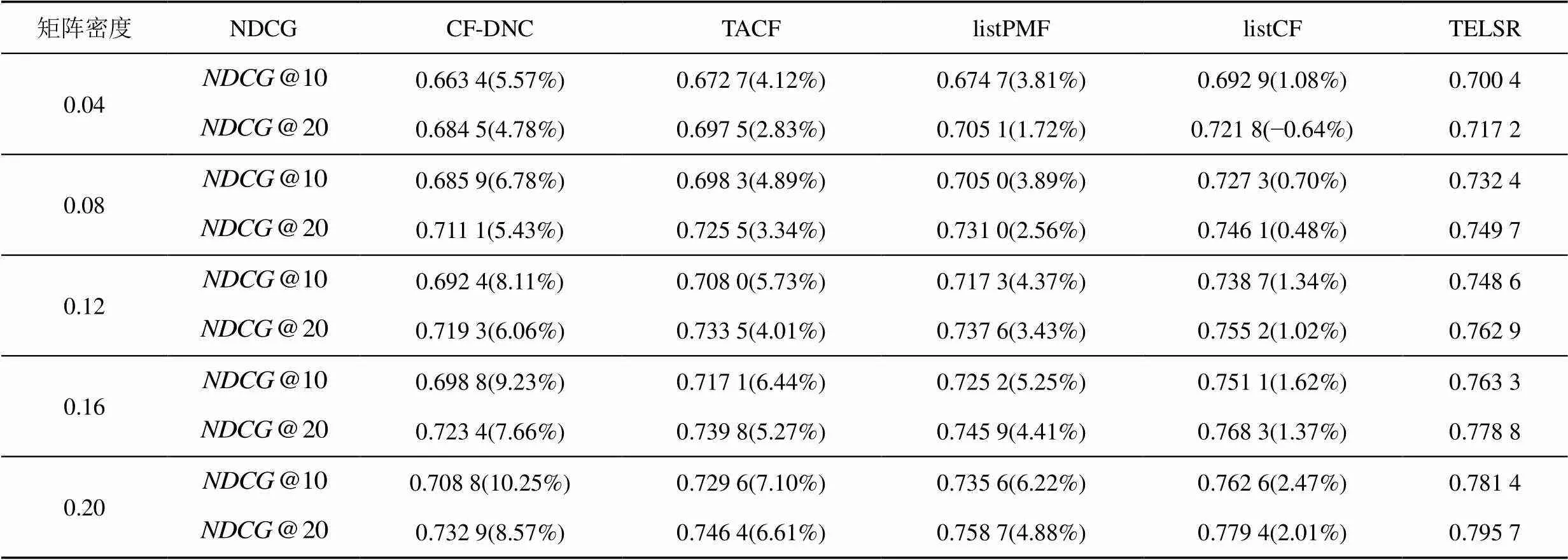
表3 推薦準確性比較
4.5 抵抗惡意用戶能力的比較
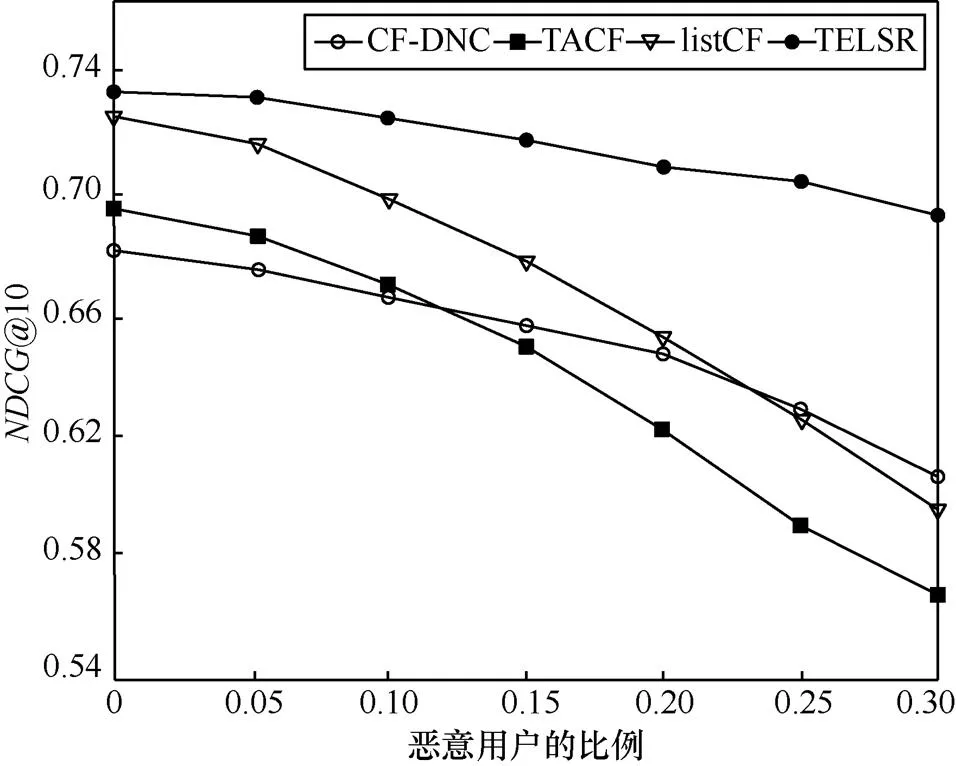
圖7 抵抗惡意用戶能力比較
由圖7可知,隨著惡意用戶比例的增加,TACF和listCF的推薦性能下降很快,因為它們沒有建立任何防御機制,一旦系統(tǒng)中的相似用戶演變?yōu)閻阂庥脩簦惴ǖ臏蚀_性會受到很大的影響;而CF-DNC考慮到了用戶的信任關(guān)系,具備一定的抗攻擊能力,但是其在計算相似度時沒有考慮服務的排序位置信息,所以導致推薦精度不夠高;TELSR利用概率分布模型計算用戶相似度,并結(jié)合用戶的信任關(guān)系進行服務推薦,在具備較高推薦精度的同時,還能夠較好地抵抗惡意用戶的攻擊。
5 結(jié)束語
本文針對傳統(tǒng)服務推薦算法中僅依據(jù)QoS預測值排序帶來的不準確性以及用戶信任關(guān)系稀疏性問題,提出基于信任擴展和列表級排序?qū)W習的服務推薦方法。該方法首先在分析服務排序位置信息重要性的基礎(chǔ)上,給出概率型用戶相似度計算方法,提高了用戶相似度計算的準確性;然后,利用信任擴展模型充分挖掘用戶之間的信任關(guān)系,并給出可信鄰居構(gòu)建算法,以抵抗某些惡意用戶的攻擊;最后,利用可信鄰居集合改進矩陣分解模型,并給出列表級排序?qū)W習預測算法,為用戶訓練出最優(yōu)的服務排序模型。實驗證明,TELSR具有較高的推薦精度,并且可以應用到大型的Web服務數(shù)據(jù)集上。下一步工作將優(yōu)化用戶信任模型,并考慮QoS值的時間效應,進一步增強推薦模型在動態(tài)環(huán)境中的適用性。
[1] 李玲, 劉敏, 成國慶. 一種基于FAHP的多維QoS的局部最優(yōu)服務選擇模型[J]. 計算機學報, 2015, 38(10): 1997-2010.
LI L, LIU M, CHENG G Q. A local optimal model of service selection of multi-QoS based on FAHP[J]. Chinese Journal of Computers, 2015, 38(10): 1997-2010.
[2] MA Y, WANG S G, YANG F C, et al. Predicting QoS values via multi-dimensional QoS data for Web service recommendations[C]//IEEE Conference on Web Services. 2015: 249-256.
[3] LIU Z, MA J, JIANG Z, et al. IRLT: integrating reputation and local trust for trustworthy service recommendation in service-oriented social networks[J]. Plos One, 2016, 11(3):e0151438.
[4] 張莉, 張斌, 黃利萍, 等. 基于服務調(diào)用特征模式的個性化Web服務QoS預測方法[J]. 計算機研究與發(fā)展, 2013, 50(5):1066-1075.
ZHANG L, ZHANG B, HUANG L P, et al. A personalized Web service quality prediction approach based on invoked feature model[J]. Journal of Computer Research and Development, 2013, 50(5): 1066-1075.
[5] QI L, DOU W, ZHOU Y, et al. A context-aware service evaluation approach over big data for cloud applications[J]. IEEE Transactions on Cloud Computing, 2015, PP (99): 1.
[6] HUANG S S, WANG S Q, LIU T Y, et al. Listwise collaborative filtering[C]//The 38th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR). 2015: 343-352.
[7] 黃震華, 張佳雯, 田春岐. 基于排序?qū)W習的推薦算法研究綜述[J]. 軟件學報, 2016, 27(3): 691-713.
HUANG Z H, ZHANG J W, TIAN C Q. Survey on learning-to-rank based recommendation algorithms[J]. Journal of Software, 2016, 27(3): 691-713.
[8] GOLDBERG D. Using collaborative filtering to weave an information tapestry[J]. Communications of the ACM, 1992, 35(12): 61-70.
[9] PARK C, KIM D, OH J, et al. TRecSo: enhancing top-recommendation with social information[C]//International Conference Companion on World Wide Web, International World Wide Web Conferences Steering Committee. 2016: 89-90.
[10] 王海艷, 楊文彬, 王隨昌. 基于可信聯(lián)盟的服務推薦方法[J]. 計算機學報, 2014, 37(2): 301-311.
WANG H Y, YANG W B, WANG S C. A service recommendation method based on trustworthy community[J]. Chinese Journal of Computers, 2014, 37(2): 301-311.
[11] LIU J, TANG M, ZHENG Z, et al. Location-aware and personalized collaborative filtering for Web service recommendation[J]. IEEE Transactions on Services Computing, 2015, 9 (5): 686-699.
[12] HU Y, PENG Q, HU X. A time-aware and data sparsity tolerant approach for Web service recommendation[C]//IEEE International Conference on Web Services. 2014: 33-40.
[13] WEI L, YIN J, DENG S, et al. Collaborative Web service QoS prediction with location-based regularization[C]//IEEE International Conference on Web Services. 2012: 464-471.
[14] 胡堰, 彭啟民, 胡曉惠. 一種基于隱語義概率模型的個性化Web服務推薦方法[J]. 計算機研究與發(fā)展, 2014, 51(8): 1781-1793.
HU Y, PENG Q M, HU X H. A personalized Web service recommendation method based on latent semantic probabilistic model[J]. Journal of Computer Research and Development, 2014, 51(8): 1781-1793.
[15] WANG X Y, ZHU J K, ZHENG Z B, et al. A spatial-temporal QoS prediction approach for time-aware Web service recommendation[J]. ACM Transactions on the Web, 2016, 10(1): 1-25.
[16] WEIMER M, KARATZOGLOU A, LE Q V, et al. Cofirank maximum margin matrix factorization for collaborative ranking[C]//The 21th Int’l Conference on Neural Information Processing Systems. 2007: 1-8.
[17] SHI Y, KARATZOGLOU A, BALTRUNAS L, et al. TFMAP: optimizing MAP for top-context-aware recommendation[C]//ACM Special Interest Group on Information Retrieval. 2012: 155-164.
[18] MOLLICA C, TARDELLA L. Bayesian mixture of Plackett-Luce models for partially ranked data[J]. Statistics, 2015, 2(4): 208-222.
[19] CAO Z, QIN T, LIU T Y, et al. Learning to rank: from pairwise approach to listwise approach[C]//The 2007 ACM conference on Machine learning. 2007: 129-136.
[20] FANG W, ZHANG C, SHI Z, et al. BTRES: beta-based trust and reputation evaluation system for wireless sensor networks[J]. Journal of Network & Computer Applications, 2015(59): 88-94.
[21] 郭弘毅, 劉功申, 蘇波, 等. 融合社區(qū)結(jié)構(gòu)和興趣聚類的協(xié)同過濾推薦算法[J]. 計算機研究與發(fā)展, 2016, 53(8): 1664-1672.
GUO H Y, LIU G S, SU B, et al. Collaborative filtering recommendation algorithm combining community structure and interest clusters[J]. Journal of Computer Research and Development, 2016, 53(8): 1664-1672.
[22] ZHENG Z B, ZHANG Y L, LYU M R. Distributed QoS evaluation for real-world Web services[C]//The 8th International Conference on Web Services. 2010: 83-90.
[23] 賈冬艷, 張付志. 基于雙重鄰居選取策略的協(xié)同過濾推薦算法[J]. 計算機研究與發(fā)展, 2013, 50(5): 1076-1084.
JIA D Y, ZHANG F Z. A collaborative filtering recommendation algorithm based on double neighbor choosing strategy[J]. Journal of Computer Research and Development, 2013, 50(5): 1076-1084.
[24] LIU J, WU C, XIONG Y, et al. List-wise probabilistic matrix factorization for recommendation[J]. Information Sciences, 2014(278): 434-447.
Trust expansion and listwise learning-to-rank based service recommendation method
FANG Chen1,2, ZHANG Hengwei1,2, ZHANG Ming1,2, WANG Jindong1,2
1. The Third College, Information Engineering University, Zhengzhou 450001, China 2. State Key Laboratory of Mathematical Engineering and Advanced Computing, Zhengzhou 450001, China
In view of the problem of trust relationship in traditional trust-based service recommendation algorithm, and the inaccuracy of service recommendation list obtained by sorting the predicted QoS, a trust expansion and listwise learning-to-rank based service recommendation method (TELSR) was proposed. The probabilistic user similarity computation method was proposed after analyzing the importance of service sorting information, in order to further improve the accuracy of similarity computation. The trust expansion model was presented to solve the sparseness of trust relationship, and then the trusted neighbor set construction algorithm was proposed by combining with the user similarity. Based on the trusted neighbor set, the listwise learning-to-rank algorithm was proposed to train an optimal ranking model. Simulation experiments show that TELSR not only has high recommendation accuracy, but also can resist attacks from malicious users.
service recommendation, learning-to-rank, probabilistic user similarity, trust relationship
TP393
A
10.11959/j.issn.1000-436x.2018007
方晨(1993-),男,安徽宿松人,信息工程大學碩士生,主要研究方向為服務推薦、數(shù)據(jù)挖掘等。

張恒巍(1978-),男,河南洛陽人,博士,信息工程大學副教授,主要研究方向為網(wǎng)絡(luò)安全與攻防對抗、信息安全風險評估。
張銘(1993-),男,河南安陽人,信息工程大學碩士生,主要研究方向為云資源調(diào)度。

王晉東(1966-),男,山西洪洞人,信息工程大學教授,主要研究方向為網(wǎng)絡(luò)與信息安全、云資源管理。
2017-04-05;
2017-12-26
張恒巍,13083710760@163.com
國家自然科學基金資助項目(No.61303074, No.61309013);河南省科技攻關(guān)計劃基金資助項目(No.12210231003)
: The National Natural Science Foundation of China (No.61303074, No.61309013), Henan Science and Technology Research Project (No.12210231003)
猜你喜歡
中等數(shù)學(2022年2期)2022-06-05 07:10:50
中學生數(shù)理化·七年級數(shù)學人教版(2022年11期)2022-02-14 07:14:12
小學生學習指導(低年級)(2020年6期)2020-07-25 02:31:36
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
小天使·一年級語數(shù)英綜合(2019年2期)2019-01-10 11:57:30
小學生學習指導(低年級)(2018年9期)2018-09-26 05:59:44
瘋狂英語·新讀寫(2018年2期)2018-09-07 09:32:10
兒童繪本(2018年5期)2018-04-12 16:45:32
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
