基于貪婪算法的參與式感知激勵分配機制
2018-03-16 06:18:17杜景林
計算機工程與設計 2018年2期
王 程,周 杰,2,杜景林
(1.南京信息工程大學 電子與信息工程學院,江蘇 南京 210044;2.日本國立新瀉大學 工學部電氣電子工學科,新瀉 950-2181)
0 引 言
激勵機制對參與式感知有著重要的意義[1-4]。在有限的激勵預算下,任務發布者為了獲取特定時間特定區域的數據向中央服務器發出請求,移動用戶作為感知數據采集者將數據發送給中央服務器,激勵預算就會分配給被選中的移動用戶[5]。文獻[6]首次提出逆向拍賣激勵機制,主要思想:參與者收集感知數據并且將投標價格和數據一起發送到中央服務器,中央服務器會選擇最低的投標價格的數據。這種激勵機制是通過最大化收集數據的數量來提高感知結果的精度,但是忽略了數據在時間和空間上的分布,在激勵預算不足以獲取足夠的數據并且缺失的數據集中在某個區域中的時候,由于插值的原因,會導致數據重構的結果不精確。GIA考慮了參與者的位置和感知覆蓋范圍,將GBMCA(greedy budgeted maximum coverage algorithm)和RADP-VPC(reverse auction dynamic pricing)相結合,增加參與者的人數并且激勵參與者移動來擴大感知覆蓋范圍[7-9]。文獻[10]提出了兩種系統模型:一種是以平臺為中心的模型,該模型為參與者提供了報酬共享的平臺;另一種是以用戶為中心的模型,用戶可以更好地控制他們收到的報酬。IEA[11]運用進化算法迭代優化機制,在有限的預算約束下,以最大化感知覆蓋范圍為優化目標,來選擇有效的參與者,并且提出虛擬報酬這一概念,激勵退出感知活動的參與者重新加入。然而,以上文獻都沒有考慮到數據的分布情況。針對以上問題,本文提出了一種激勵機制,該方法考慮了數據的時空分布,不是通過最大化感知數據的數量而是根據數據的分布情況,將激勵預算分配給提供最有效數據的區域來最小化感知結果的平均誤差。在對平均誤差、數據數量和分布之間的關系進行研究后,發現較大數量和更加均勻分布的數據可以提高感知結果的精度。本文將激勵分配作為優化問題,通過貪婪算法對其進行優化。
由于激勵預算是有限的,收集到的感知數據是不可能覆蓋整個目標區域的,因此文獻[12]使用數據插值的方法來對缺失的數據進行重構。文章指出,在參與感知系統中,測量的密度是不均勻的,所以需要激勵參與者在目標區域收集數據,并且需要控制每塊區域的測量密度。
1 系統模型
1.1 模型描述
由文獻[12]可知,當子區域的分配足夠細致的話,每個子區域中的一個樣本就可以為感知任務提供足夠的數據精度。根據任務發布者的環境數據需求,將感知任務的整個區域和持續時間劃分在子區域集合R={r=1,2,3,…,n}中。在每個子區域中,只需要目標環境參數的一個樣本。


圖1 參與感知過程
在目標區域內,Z(ri)是變量Z(r)在點ri(i=1,2,3,…,n)處的屬性值。未知點變量Z*(r)是根據n個已知的變量值加權求和后得到的,即
(1)
其中,λi是第i個位置處的測量值得未知權重,表示各空間樣本點觀測值對估計值的貢獻程度。權重λi取決于測量點、預測位置的距離和周圍f測量值之間關系的擬合模型。選取λi需要滿足無偏性和估計方差最小這兩個條件。根據方程組(2)來求解權重系數λi
(2)
其中,r和ri表示的是未知點和第i個樣本的位置。μ是拉格朗日常數。γ(ri,rj)表示變量Z(r)在ri和rj兩點之差的方差的一半,可由式(3)得到
(3)
通過求解克里金方程組可以得到權重系數λi,然后再由式(1)得出估計值。
本文用ε來表示感知結果的平均誤差和所有子區域R真值的比,誤差主要積累在無數據樣本的子區域中,有
(4)
根據式(4),可以發現平均誤差是與有數據樣本的區域有關的。
1.2 樣本數量和分布與平均誤差之間的關系
1.2.1 樣本數量

(5)
1.2.2 樣本分布

(2)不同區域的數據重要性隨著環境的改變而改變。例如,圖3(b)顯示了市區噪聲水平的讀數。噪聲水平在區域“A1”改變巨大,而區域“A2”相對于區域“A1”改變比較穩定。如果大量數據是從區域“A1”收集來的,那么插值結果就會更加準確。顯然,更高的權重應該給環境變化劇烈的地區,例如在圖3(b)的“A1”。

圖3 樣本數據在區域中的分布權重
將整塊區域分成區域集合A={a=1,2,…,n}。用Xa,?a∈A來表示落在每個區域中的樣本集。樣本落在每個區域的概率

(6)
除此之外,不同區域的數據的重要性是由環境數據改變的程度決定的。當數據改變穩定的話,那么只需要較少的數據樣本就可以獲得準確的感知結果。因此,每個區域的權重可由區域中的數據讀數的標準偏差得到

(7)
(8)
(9)
2 激勵機制模型求解
考慮到本文中的優化問題是和樣本數量和分布相關的,那么可以將式(4)中的平均誤差作為目標函數。根據式(9)
(10)
(11)
步驟1 初始化,賦初值
將所有區域分成兩個子集——選中的集S1和未被選中的集S2。在步驟1先把所有的區域放進S2中,S1為空集。
步驟2 每次迭代過程中區域的選擇
如果S2中的區域r被選中,那么就從S2移動到S1,形成一個新集S1,那么式(11)目標函數的變化為

(12)
ir是區域r中最低的激勵需求。式(11)目標函數每單位激勵的變化為
(13)
每次迭代過程中,選擇提供最有效數據的區域r,那么區域r就從S2移動到S1。將激勵ir分配到選中的區域r,最低激勵需求的參與者將數據發送到中央服務器后獲得報酬。
步驟3 循環
耗盡激勵預算B或者所有區域已被選中,則終止算法,否則一直重復步驟2。
3 仿真實驗
3.1 程序設置
本文將從固定的無線傳感器網絡收集的環境感知數據作為真值,并且利用從公園收集的軌道數據[15]來模擬參與者的移動軌道,這個軌道數據集包含了41個參與者在特定一天中的移動軌道。下面本文采取以下步驟來設置實驗:
(1)設置區域R和激勵需求ir:本文將矩形感知區域分成4×4的區域,將持續時間分成24個時間點,因此|R|=16×24=384。把41個參與者的移動軌道放入這個感知區域,每個參與者的激勵需求在[1,20]中隨機生成,通過參與者的軌道和激勵需求來計算ir,?r∈R。
3.2 仿真結果
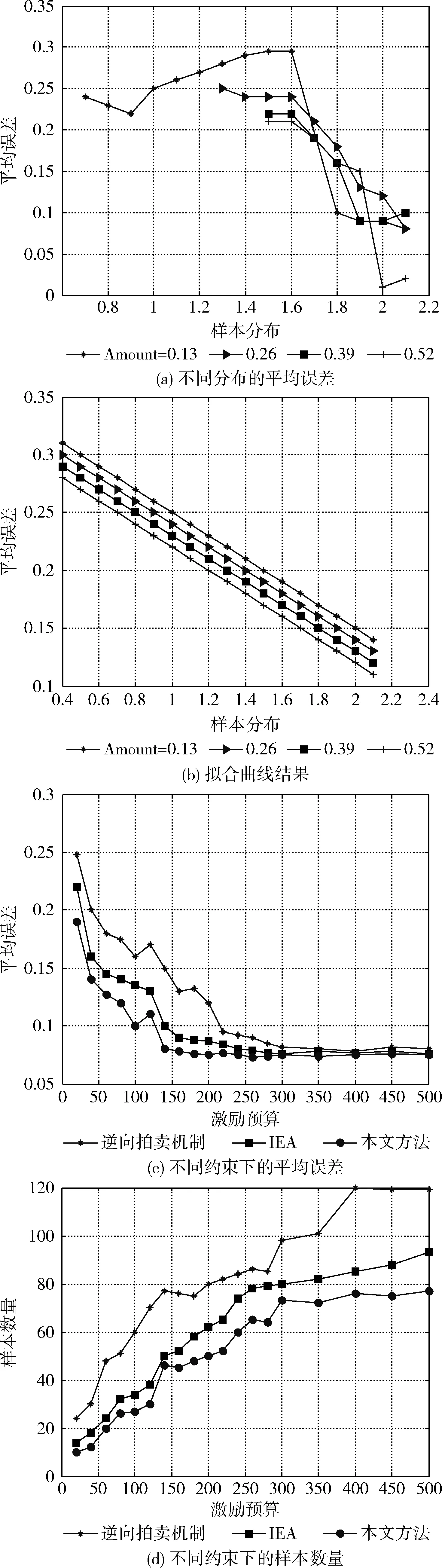
圖4 仿真結果
ε=0.3777-0.0642α-0.1247β
(14)
通過這個表達式,可以發現樣本分布要比樣本數量對平均誤差的影響更大。圖4(b)表示根據式(14)得出的預測誤差。真實誤差和根據40 000個樣本集得出的預測誤差之間只有0.021的差距,這個差距是非常小的,在接受范圍之內。
本文將12月8號收集的溫度數據作為真值,將本文方法與逆向拍賣機制和IEA的性能進行比較。圖4(a)和圖4(b)表示隨著激勵需求B的變化,這兩種方法在所選區域中的平均誤差和樣本數量。
從圖4(c)可以看出,當預算不夠時,本文方法的平均誤差與逆向拍賣機制和IEA的差距越來越大。當預算在20的時候,逆向拍賣的誤差是0.248,IEA的誤差是0.22,而本文方法的誤差只有0.193(比逆向拍賣機制少了22%,比IEA少了13%),這是因為本文方法在數據分布均勻的區域給了更高的激勵來收集數據。
從圖4(d)可以看出,本文方法所需要的區域比逆向拍賣機制和IEA都要的少,給足夠的預算,3種方法的數據精度是差不多的。本文方法所需要的數據樣本比逆向拍賣機制的少42%,比IEA少26%,減少了移動設備的能量消耗,為每個參與者增加了72%的激勵,這樣可以鼓勵移動用戶提供高質量的數據。
4 結束語
本文提出的在預算約束條件下的參與感知激勵機制可以達到更高的數據精度。與現有的激勵機制不同,本文方法不僅考慮了樣本的數量還考慮了樣本的分布。本文研究并用公式表示平均誤差,樣本數量和樣本分布之間的關系。將平均誤差最小化問題轉化為每塊區域的激勵分配優化問題,提出了一個貪婪激勵分配算法來解決優化問題。大量真實數據集的模擬驗證了該機制的有效性。與現有的逆向拍賣機制和IEA進行仿真結果對比,驗證了本文的激勵分配機制可以增加感知數據的精度,提高參與者的利益。
[1]CHENLongbiao,LIShijian,PANGang.Smartphone:Pervasivesensingandapplications[J].ChineseJournalofComputers,2015,38(2):423-438(inChinese).[陳龍彪,李石堅,潘綱.智能手機:普適感知與應用[J].計算機學報,2015,38(2):423-438.]
[2]RugeL,AltakrouriB,SchraderA.Soundofthecity-conti-nuousnoisemonitoringforahealthycity[C]//InternationalWorkshoponSmartEnvironmentsandAmbientIntelligence.IEEE,2013:670-675.
[3]DevarakondaS,SevusuP,LiuH,etal.Real-timeairqualitymonitoringthroughmobilesensinginmetropolitanareas[C]//TheACMSIGKDDInternationalWorkshoponUrbanComputing.ACM,2013:1-8.
[4]WANGHao.Resarchonincentivetechnologyinparticipatorysensingnetwork[D].Harbin:HarbinEngineeringUniversity,2014:13-14(inChinese).[王浩.參與感知網絡激勵技術研究[D].哈爾濱:哈爾濱工程大學,2014:13-14.]
[5]ZHAOLuming.Theresearchandimplementofincentivemecha-nismbasedonparticipatorysensing[D].Beijing:BeijingUniversityofPostsandTelecommunication,2015:7-8(inChinese).[趙露名.基于參與式感知的激勵機制的研究與實現[D].北京:北京郵電大學,2015:7-8.]
[6]LeeJS,HohB.Sellyourexperiences:Amarketmechanismbasedincentiveforparticipatorysensing[C]//IEEEInternationalConferenceonPervasiveComputingandCommunications.IEEE,2010:60-68.
[7]JaimesLG,Vergara-LaurensI,LabradorM.Alocation-basedincentivemechanismforparticipatorysensingsystemswithbudgetconstraints[J].Dissertations&Theses-Gradworks,2012,25(3):103-108.
[8]JaimesLG,Vergara-LaurensI,ChakeriA.SPREAD,acrowdsensingincentivemechanismtoacquirebetterrepresentativesamples[C]//IEEEInternationalConferenceonPervasiveComputingandCommunicationWorkshops.IEEE,2014:92-97.
[9]JaimesLG,Vergara-LaurensI,RaijA.Acrowdsensingincentivealgorithmfordatacollectionforconsecutivetimeslotproblems[C]//Communications.IEEE,2014:1-5.
[10]YangD,XueG,FangX,etal.Crowdsourcingtosmartphones:Incentivemechanismdesignformobilephonesensing[C]//InternationalConferenceonMobileComputingandNetworking.ACM,2012:173-184.
[11]Kumrai T,Ota K,Dong M,et al.An incentive-based evolutionary algorithm for participatory sensing[C]//Global Communications Conference.IEEE,2014:5021-5025.
[12]Mendez D,Labrador M,Ramachandran K.Data interpolation for participatory sensing systems[J].Pervasive & Mobile Computing,2013,9(1):132-148.
[13]WANG Ting.Research on 3D interpolation approaches based on Kriging with anisotropic spatial structures[D].Nanjing:Nanjing Normal University,2013:1-65(in Chinese).[王亭.顧及各向異性的三維Kriging空間插值方法研究[D].南京:南京師范大學,2013:1-65.]
[14]Ji HY,Ohm SY,Min GC.Brightness preservation and image enhancement based on maximum entropy distribution[M]//Convergence and Hybrid Information Technology,2012:365-372.
[15]Solmaz G,Akbas MI,Turgut D.Modeling visitor movement in theme parks[C]//IEEE,Conference on Local Computer Networks.IEEE Computer Society,2012:36-43.
猜你喜歡
環境保護與循環經濟(2017年2期)2017-09-26 11:52:13
中國公路(2017年11期)2017-07-31 17:56:31
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
Coco薇(2016年2期)2016-03-22 02:42:52
中國商論(2016年33期)2016-03-01 01:59:29
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
電測與儀表(2015年5期)2015-04-09 11:30:52
現代企業(2015年8期)2015-02-28 18:54:57
