Spark Streaming框架下的氣象自動站數據實時處理系統
2018-03-20 00:43:02趙文芳劉旭林
計算機應用 2018年1期
趙文芳,劉旭林
(1.北京市氣象信息中心,北京 100089; 2.北京市氣象探測中心,北京100176)(*通信作者電子郵箱lxulin@bjmb.gov.cn)
0 引言
目前,氣象自動站實現了分鐘加密觀測,具有產生快、實時性強、數據量大等特點,已經成為監視天氣變化、決策服務輔助支持的重要手段[1-3],不僅在天氣預報、氣象服務中發揮重要作用,同時也為大城市防災減災、適應氣候變化、環境評估等提供基礎的數據支撐。氣象業務現代化的進展對自動站數據提出了越來越高的要求,中國氣象局在“十三五”規劃中明確提出了要實現自動站數據1 min內到達預報員桌面的要求;北京市氣象局提出了要實現自動站數據在秒級甚至更短時間內完成各類要素實時統計的要求,以便為災害天氣的監視提供及時準確的氣象服務。基于自動站的數據服務面臨很大的挑戰,需要在秒級甚至更短時間內完成高并發的處理存儲、統計和在線共享服務,因此,實現自動站數據的快速處理、有效存儲和及時服務,盡可能發揮它的應用效益,顯得尤為重要。
Spark作為下一代大數據處理引擎,具有速度快、易用、通用等特點,在近幾年廣泛應用于多個行業的并行數據分析,得到了很多領域和科研機構的肯定。Spark Streaming是Spark提供的對實時數據進行流式計算的組件,可以進行大規模的流式數據處理,HBase是一個高可靠性、高性能、面向列的分布式數據庫,適合處理實時隨機讀寫超大規模的數據。將實時計算框架和分布式數據庫系統結合起來實現對海量數據的實時處理和高效檢索查詢,逐步成為了大數據技術在汽車、交通、氣象等行業應用的新興研究領域[4-7]。例如,美國最權威的集汽車銷售和資訊服務為一體的網站Edmunds,結合Spark Streaming技術與HBase建立了實時儀表板系統,用于顯示用戶的活動信息、訪客ID、日志內容和頁面瀏覽內容等。考克斯汽車公司基于Spark Streaming技術創建實時儀表狀態系統,監控道路狀況、汽車各項指標、駕駛者的行為數據[8]。國家氣象信息中心也開展了基于HBase建立氣象地面分鐘數據分布式存儲系統的研究,以及Hadoop在氣象數據密集型領域的應用實驗;廣東省氣象局開展了基于Hadoop實現風暴追蹤算法和數值預報產品的服務應用實驗等[9-16]。
本文結合北京市氣象局的氣象預報、決策氣象與公眾氣象服務等業務對自動站數據的需求,尤其是實況和統計的時效要求,重點研究了Spark Streaming框架下的自動站數據流處理技術和基于HBase的存儲管理技術,設計了并行的自動站流式入庫、實時溫度極值統計、風要素極值統計和降水量累計等算法,實現了一種分布式的自動站數據流式處理,在Cloudera環境下建立了自動站實時處理系統。
1 業務現狀
目前,北京市氣象局主要依托全國綜合氣象信息共享系統(China Integrated Meteorological Information Sharing System, CIMISS)[17]實現京津冀自動站數據的處理、入庫存儲與管理,通過CIMISS的氣象數據統一服務接口(Meteorological Unified Service Interface Community, MUSIC)來獲取實時數據。CIMISS系統中自動站數據的全流程處理平均耗時不超過1 min,基本能滿足業務對實況的時效要求。然而,由于MUSIC接口沒有提供自動站要素的實時統計功能,因此只能通過編寫客戶端程序實現,即遠程調用接口服務獲取某時間段內的要素值再進行計算得出結果。這種做法存在一定弊端:1)由客戶端程序計算的要素統計值不能回寫到CIMISS數據庫中,無法實現統計功能的共享,造成很多不必要的重復性開發工作。2)由不同開發人員編寫的客戶端程序,可能由于算法差異導致統計結果不一致,從而降低數據的可用性。3)客戶端程序需要經過多次迭代運算才能得出最終結果,耗時較長,無法在秒級甚至更短時間內實現,不能滿足用戶對自動站實時統計的時效需求,迫切需要改進。
2 系統設計
2.1 系統技術框架
CDH(Cloudera Distribution Hadoop)是Cloudera公司發行的Apache Hadoop項目軟件包,里面包含了Hadoop和運行在其之上的各類存儲計算框架,如Spark、Hive、HBase、Flume、Impala和Cloudera Search等。除了擁有開源Apache Hadoop的優勢,CDH還具有以下獨特的優點:1)使用Cloudera Manager可以實現CDH的自動安裝,簡化了Hadoop的安裝部署,避免了繁雜的多節點配置工作。2)對于Hadoop及其生態系統監控都非常方便。Cloudera Manager提供一個基于Web的用戶界面,可以查看群集運行狀況,修改CDH相關配置以及管理CDH各種服務。
為了滿足實際的業務需求,本文采用了Flume技術、Spark Streaming技術、CDH技術和HBase技術。其中,Flume技術完成自動站數據從觀測臺站到CDH平臺的實時發送;Spark Streaming技術實現對自動站數據的流式處理和要素統計的并行化處理,以提高運算時效;HBase為系統提供數據存儲服務,CDH技術為系統提供平臺支撐和運行環境。
Flume是分布式的,可以同步處理到達的多個文件。Spark Streaming將輸入數據流以時間片(秒級)為單位進行拆分,然后以類似批處理的方式處理每個時間片數據,使用基于內存的Spark作為執行引擎,具有高效和容錯的特性,并達到秒級延遲。利用Spark Streaming進行自動站的數據處理,在幾十毫秒內就能完成自動站入庫和要素統計查詢任務,完全能滿足氣象自動站數據1 min內到達預報員桌面的要求,因此,將Flume和Spark Streaming結合起來,可以實現自動站數據的實時高效處理。
本文的研究和實驗均基于CDH的分布式計算框架而開展。
2.2 體系結構設計
系統體系結構設計如圖1所示,主要包括4個層次:表現層、邏輯層、服務層和數據層,是一種典型的多層體系結構。表現層也是用戶層,主要指客戶端,可以是瀏覽器或者業務系統等。邏輯層對應系統的功能,包括數據查詢檢索、數據入庫和要素統計等,由運行在Spark Streaming計算框架服務之上的功能模塊實現。服務層是運行于在CDH平臺上的各種服務,這里主要包括實現HBase訪問接口的REST (REpresentational Sate Transfer)網關(Gateway)服務和Thrift網關(Gateway)服務以及Spark Streaming計算框架服務。數據層指應用數據的存儲層,該層利用HBase存儲了氣象自動站實況數據和多種要素統計數據。
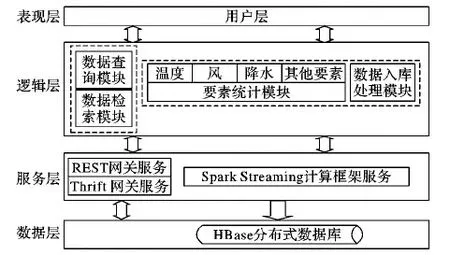
圖1 系統體系結構
2.3 功能設計
從數據的處理流程來講,系統包括數據收集、數據入庫、要素統計、數據查詢檢索、基于MUSIC的HBase數據接口訪問五大業務功能。
1)數據收集。利用CIMISS的數據收集與分發系統(Collecting and Transferring System, CTS)系統將觀測數據發送到Flume的監控目錄,Flume將收到的數據實時發送到Spark Streaming的監控輸入目錄。Flume是分布式的,可以同步處理到達的多個文件,同時它也提供了許多可調的故障恢復和容錯機制,當某個節點出現故障時,數據能夠被傳送到其他節點上而不會丟失,從而保證數據的完整性。
2)數據入庫。支持國家級自動站和區域自動站格式的解析讀取,為自動站數據創建自定義的數據結構體,通過Map映射將原始的文本氣象數據轉為包含數據結構體的離散流(Discretized Stream, DStream)對象序列,從而寫入HBase。
3)要素統計。支持自動站常規要素的各類實時統計,主要包括逐3 h、6 h、12 h、24 h的溫度極值和風極值統計以及逐5 min、10 min、3 h、6 h、12 h、24 h累計降水量統計。利用Spark對數據進行轉換和聚合,通過多次的迭代計算實時實現每個站點的統計結果,寫入HBase的相關數據表中。
4)數據的查詢檢索。為自動站實況和統計提供各種條件的查詢檢索功能。使用Solr(Search On Lucene Replication)對查詢常用字段建立輔助索引,通過Solr多條件查詢快速獲得符合過濾條件的Rowkey,通過指定Rowkey在HBase中查詢到符合條件的結果。
5)基于MUSIC的HBase數據接口訪問。HBase提供了兩種接口方式獲取自動站數據,包括Thrift網關(Gateway)和REST網關(Gateway)服務。其中,Thrift網關(Gateway)服務利用Thrift序列化技術用以支持C++、PHP(Hypertext Preprocessor)、Python等多種語言對HBase的訪問;REST網關(Gateway)服務支持超文本傳輸協議(HyperText Transfer Protocol, HTTP)的應用編程接口(Application Programming Interface, API)方式訪問HBase。系統通過拓展MUSIC接口功能,增加支持REST網關(Gateway)服務和Thrift網關(Gateway)服務的接口函數,實現了MUSIC接口服務對HBase的數據訪問。
3 系統關鍵技術
3.1 基于列模式設計自動站表結構
3.1.1 Rowkey和列族的設計
Rowkey是HBase表的主鍵,設計合理的Rowkey有助于提高HBase的查詢檢索速度。自動站數據是基于時間序列的,它的查詢和統計都和觀測時間相關,必須將觀測時間存入到Rowkey中,但是,含有觀測時間的Rowkey會按時間戳的方式單調遞增,很容易引起單區熱點問題,從而不能將集群的整體性能發揮出來。為了避免上述問題的出現,該系統將行主鍵中的站號利用MD5(Message-Digest Algorithm 5)方法散列化,以便將所有的數據散列到不同的Region上。自動站表模式設計如表1所示,由行主鍵加兩個列族構成。行主鍵的設計采用MD5(站號)+觀測時間組合的方式,兩個列族分別存放自動站觀測要素和自動站要素統計值。例如,每分鐘的溫、壓、濕、風等要素觀測值對應于列族aws_data,而自動站的溫度統計、風統計、降水量統計值則對應于列族aws_stat。
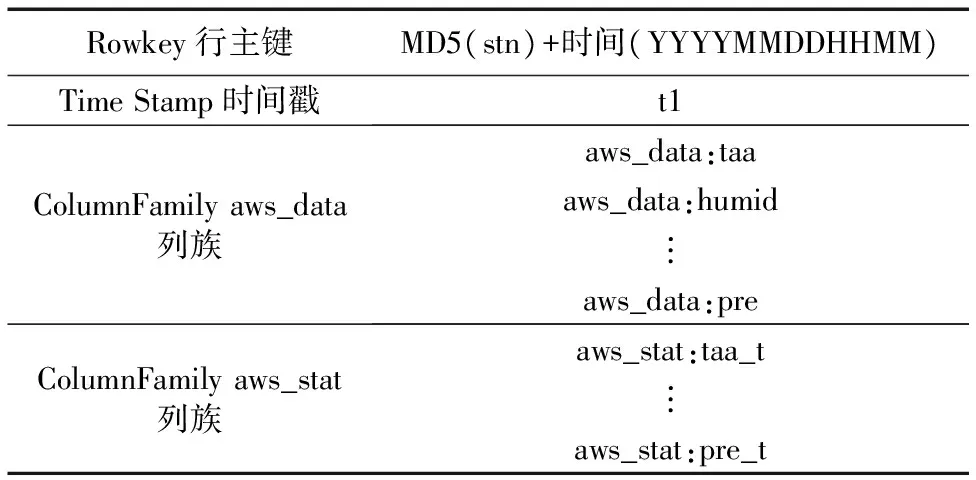
表1 自動站表結構
3.1.2 利用MD5實現對行主鍵Rowkey散列化
MD5是在20世紀90年代初由麻省理工學院(Massachusetts Institute of Technology, MIT)的計算科學實驗室和RSA(Rivest-Shamir-Adleman) Data Security Incorporation開發的,經MD2(Message-Digest Algorithm 2)、MD3(Message-Digest Algorithm 3)和MD4(Message-Digest Algorithm 4)發展而來的,在計算機安全領域廣泛使用的一種散列函數。Message-Digest泛指字節串的哈希變換,就是將一個任意長度的字節串變換成一定長的整數(128位),成為一個不可逆的字符串,這樣即使用戶看到源程序和算法描述,也無法將一個MD5值變換回原始的字符串,從而確保了數據的安全性[18-19]。
本文在設計自動站數據表的Rowkey時,將字符串(String)類型的觀測時間轉化為時間戳存為長整(Long)型,對字符串(String)類型長度為5的站號利用MD5加密,加密后的站號+Long型的觀測時間,MD5(站號)+時間(YYYYMMDDHHMM)作為Rowkey。以下是創建Rowkey的Java部分代碼。
String stn=cells[0];
String otime=cells[1];
String otime_long=String.format("%s%s%s%s%s",otime.substring(0,4),otime.substring(5,7),otime.substring(8,10),otime.substring(11,13),otime.substring(14,16));
Long currTime=Long.parseLong(otime_long);
byte[] userHash=Md5Utils.md5sum(stn);
byte[] timestamp=Bytes.toBytes(-1*currTime);
byte[] Rowkey_b=new byte[Md5Utils.MD5_LENGTH+timestamp.length];
int offset=0;
offset=Bytes.putBytes(Rowkey_b,offset,userHash,0,userHash.length);
Bytes.putBytes(Rowkey_b,offset,timestamp,0,timestamp.length);
Put put=new Put(Rowkey_b);
3.2 自動站流式入庫和要素統計算法設計
3.2.1 流式入庫算法設計
自動站流式入庫算法用于將原始文本數據寫入HBase表。自動站數據包括自動站號、觀測時間、溫度、降水、濕度、風等要素觀測值,以字符串方式存儲,每一行代表一個自動站記錄。Spark Streaming處理的數據流DStream由一系列RDD(Resilient Distributed Datasets)組成。Spark Streaming的編程就是利用自帶的接口來對DStream進行操作,因此,參照這種編程思想,該算法的關鍵在于自動站數據從原始文本格式到DStream的轉換,需要定義一個類對象用于存儲自動站要素觀測值,然后生成DStream<類對象>數據集,通過map函數實現原始數據到DStream的映射轉換。具體的算法步驟描述如下:
1)將原始數據讀入并存為DStream
2)創建一個類對象aws_access,用于存放自動站的相關信息與數據,包括臺站基本信息、觀測時間、觀測要素值等。定義成員變量和成員函數,支持要素觀測值的獲取和設置以及對原始文本數據的逐行解析。
3)自定義一個繼承接口函數,用于解析原始數據并轉化為aws_access對象。
4)對DStream
5)對數據集DStream
6)提交Put對象完成數據寫入HBase。
自動站數據寫入HBase算法流程如圖2所示。

圖2 自動站數據寫入HBase算法流程
3.2.2 要素統計算法設計
設計合理的鍵值對(key,value),實現從實際數據到鍵值對的映射,可以很方便地實現迭代計算。
自動站逐5 min累計降水量算法步驟描述如下:
1)建立一個選擇條件,用于從HBase中獲取1 h內的所有站的分鐘降水數據。
2)從HBase中獲取相應結果并轉為JavaRDD對象。
3)調用鍵值對轉換接口函數MaptoPair將JavaRDD對象轉為JavaPairRDD對象(key,value);選擇站號+觀測時間組合方式作為key,value為每分鐘降水,如果該分鐘降水值缺測,則設置為0。觀測時間為5的倍數,單位為分鐘,即每小時的05分、10分……。以站號為54511、觀測時間2016年4月20日08時05分為例,將觀測時間是01-05分(即08:00—08:05)的數據,都轉為觀測時間為2016年4月20日08時05分的(key,value)鍵值對。
4)對JavaPaieRDD對象運用groupByKey函數和Reduce函數,得出統計結果。
5)創建Put對象,根據統計結果對Put對象進行初始化,最后提交給HBase寫入數據表相應的列從而完成統計過程。
逐10 min、3 h、6 h、12 h、24 h累計降水量算法與逐5 min累計降水量算法類似,溫度和風要素極值統計與降水量算法步驟也類似,只是調用的迭代函數不一樣。
3.2.3 動態資源池應用
動態資源池用于給YARN(Yet Another Resource Negotiator)或 Impala應用指定資源配置和策略。系統利用Cloudera Manager的Web管理功能,添加一個動態資源池用來運行Spark Streaming提交的作業任務,在YARN頁面的控制面板配置權重、虛擬內核、內存大小以及正在運行的應用程序最大數量等參數。通過調整這些參數和分析對比運行Spark Streaming作業的耗時,找出作業運行的最佳參數設置方案,實現Spark Streaming運行調優。
4 實驗與分析
為了檢驗氣象自動站實時處理系統進行數據入庫處理和實時統計的能力,實際部署了一套自動站實時處理系統,并進行了一系列的測試。
不同的氣象業務場景對氣象自動站資料的關注側重點有所不同。在實時天氣預報和氣象服務中,預報員對氣象自動站資料的關注重點是數據時效性,即分鐘、小時和日數據能否及時到達預報員桌面以及實現要素的實時快速統計;在天氣復盤推演、氣候極值統計和天氣過程分析等領域,預報員對氣象自動站資料的關注重點是時間序列較長的30 d和90 d數據的完整性和一致性。為了滿足這些需求,自動站資料至少需要保存1~3個月。分別選擇1 min、1 h、1 d、30 d、90 d的京津冀自動站分鐘數據作為5個測試數據集,依次編號為數據集1、數據集2、數據集3、數據集4、數據集5。京津冀總共3 802個自動站,一個站一個觀測時次產生的數據大約4 kb。
4.1 系統運行環境
本文基于Apache Flume 1.5、Spark1.5、JDK(Java Development Kit) 1.7、HBase1.04實現上述系統原型,選擇Cloudera 5.5作為系統的運行環境,采用YARN模式作為系統的運行方式。其中,Cloudera集群由10臺實體服務器構成,每臺服務器的配置為32核CPU,128 GB內存,4 TB磁盤。
在Cloudera環境下,需要將YARN、HBase、Spark、Solr服務合理地部署在不同的節點上,以便充分利用集群資源給系統運行提供更好的性能保障。選擇運行Cloudera Manager服務的節點同時作為分布式文件系統(Hadoop Distributed File System, HDFS)的名字空間節點(namenode),并運行Spark Master、HMaster Server和YARN資源管理(ResourceManager) 服務,具體如圖3所示。

圖3 Cloudera服務部署
4.2 不同Rowkey對寫入HBase操作的性能影響測試
測試主要考察在數據量以及其他系統配置不變的情況下,通過設計不同的Rowkey而引起的HBase寫入耗時的變化,選擇本地模式運行程序。
進行兩組實驗,對編號為1~3的數據集進行20次入庫測試,取平均耗時作為結果。當設計Rowkey為時間(yyyymmddhhMM)+站號的方式時,3個數據集的平均入庫耗時分別為14 s、144 s、498 s;當設計Rowkey為MD5(站號)+時間(yyyymmddhhMM)的方式時,3個數據集的平均入庫耗時分別為4 s、24 s、121 s。結果如圖4。
由圖4可以看出,如果Rowkey按照時間戳的方式遞增而且首字段直接是時間信息,所有的數據都會集中在HBase的一個分區服務(RegionServer)上,造成數據檢索時的熱點問題(hot splot),導致查詢效率下降。由此可見,對于時間序列的數據集,Rowkey的設計對HBase的性能影響比較大。

圖4 HBase寫入性能隨Rowkey變化的測試結果
4.3 HBase寫入時效隨Spark運行參數變化測試
進行實時場景和批量數據寫入場景兩種測試,選擇Spark on YARN運行方式。在進行測試之前,先調整YARN服務的可用資源。在10個節點的集群中,每個節點有32個core以及128 GB的內存;其中,1個節點運行YARN資源管理(Resource Manager)服務,9個節點運行YARN節點管理(NodeManager)服務;考慮到每個節點上操作系統、Hadoop的Daemon進程以及其他組件進程的運行也需要一定資源,在該測試中分配給YARN 75%的資源,即每個節點上NodeManage可用資源為96 GB內存和24個core。
實時場景的測試使用數據集1和數據集2作為樣本數據。啟動Spark Streaming應用進程,結合CTS和Flume將數據發送到Spark Streaming的監控目錄下,通過Web頁面記錄每次作業的耗時。對每個數據集進行20次測試,取平均耗時作為測試結果。測試結果表明,數據集1入庫平均耗時為30.64 ms,數據集2入庫平均耗時為6.37 s,完全能滿足實時業務的需求。
批量數據寫入HBase場景測試的主要目的是考察在數據量、任務提交方式及其他配置不變的情況下,通過改變num-executors、executor-cores和executor-memory三個運行參數而引起的時效變化。數據集3包括17 551個文件,數據總量389 MB,數據集4包括54萬個文件,數據總量11.86 GB,數據集5包括159萬多個文件,數據總量34.56 GB。考慮到數據集4和數據集5主要應用在非實時業務場景,而數據集3主要應用在實時業務場景,選擇對數據集3進行9組實驗,詳細的參數配置如表2。
在實驗中,num-executors從10逐漸增大到90。由圖5可知,數據寫入HBase的耗時隨num-executors的增加呈下降趨勢。當num-executors取值從[20,30),[30,40),[40,50)時,耗時并沒有明顯的變化。在num-executors分別設置為[60,70),[70,80),[80,90)的三組實驗中,啟用spark.default.parallelism參數,程序運行效率得到提升。當num-executors為70、executor-cores為3、executor-memory為4 GB、spark.default.parallelism為600時,整體性能達到最優。spark.default.parallelism參數用于設置每個stage的默認task數量。前5組實驗沒有啟用這個參數,而Spark默認設置task為幾十個,導致60%至70%的Executor進程沒有task執行,因此盡管Executor參數在增大,但程序的耗時基本沒有變化。由此可見,這個參數如果不設置或者設置不當會直接影響Spark作業性能。
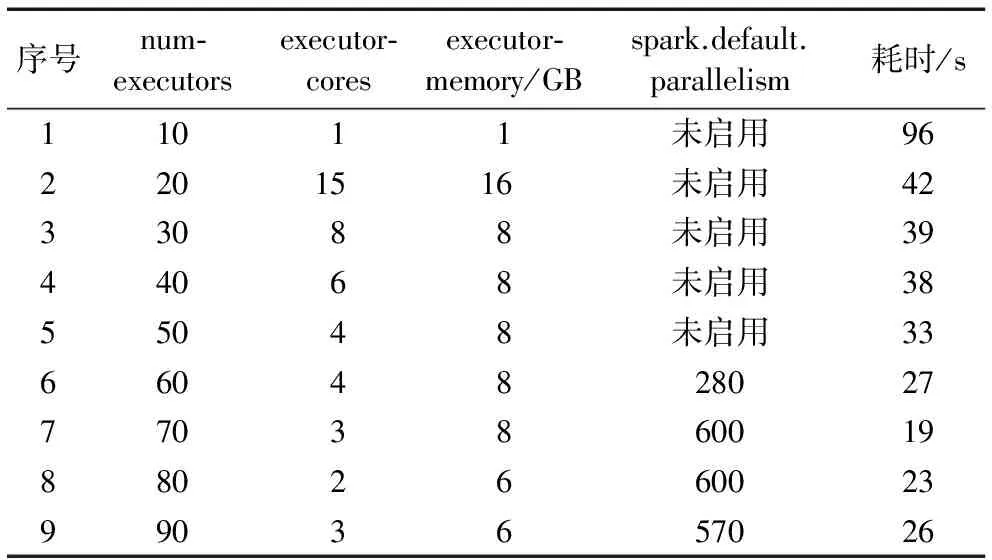
表2 Spark Streaming作業運行參數配置及耗時
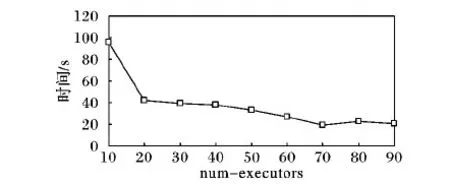
圖5 耗時隨num-executors參數變化測試結果
對數據集4和數據集5進行寫入HBase測試。啟用參數spark.default.parallelism并設置為1 000,spark運行參數按照表7中序號為7的組合參數,數據4和數據集5耗時分別為161 s和249 s;相比現有業務環境下,數據集4批量導入關系型數據庫耗時196 min,數據集5批量導入關系型數據庫耗時578 min,性能分別提升了73倍和139倍。
從對數據集3~5的測試結果來看,Spark作業性能與運行參數、平臺分配給YARN的可用資源、spark.default.parallelism等諸多因素有關,在其他參數不變的情況下,性能與num-executors參數也不是簡單的線性關系,因此,在實際運行中,需要統籌考慮這些參數的影響,選擇一個最優的參數組合。此外,針對大量小文件的批量導入HBase,除了考慮spark運行參數,還可以先對原始文件進行合并和sequence序列化處理;當氣象自動站小文件累計容量達到40 GB以上,可以考慮增加Cloudera集群節點,通過擴充硬件資源來提升效率。
4.4 不同查詢條件下的HBase查詢性能測試
進行四組查詢測試,每組測試運行20次,取其平均耗時,結果如表3。從表3可以看出,當查詢只以Rowkey作為唯一條件時候,不借助Solr索引查詢響應比較快,達到毫秒級。當查詢需要根據時間設置HBase的start key和end key時候,不借助Solr索引查詢達到秒級,而借助索引后能達到毫秒級。
4.5 要素統計性能測試
對數據集進行逐日和逐時溫度、風、降水量要素的統計計算,耗時結果如表4。不同類型統計運行耗時有一定差別,但都到達了秒級甚至毫秒級。然而,在現有業務平臺中完成一個月逐日的要素統計需要14~16 min才能完成,由此可見利用Spark Streaming來實現自動站要素統計是完全可行的。
4.6 系統的業務應用案例
該系統投入業務化運行后,全面支持了北京市氣象局的自動站數據基礎業務,為預報員和其他氣象工作人員提供了精準的自動站實況和要素統計數據。尤其是自動站逐5 min累計雨量的實時統計功能,為各區局的氣象決策服務提供了十分方便的數據服務,同時提升了數據的綜合服務能力。此外,基于Thrift網關方式的數據接口服務已經成功為市局多個業務系統提供自動站要素的統計數據支撐;在2016年7月24日和8月12日二次降水天氣過程中,以REST網關方式訪問系統數據的用戶總數達到556,由此可見,系統在市局和各區局得到了推廣應用,贏得用戶一致好評。
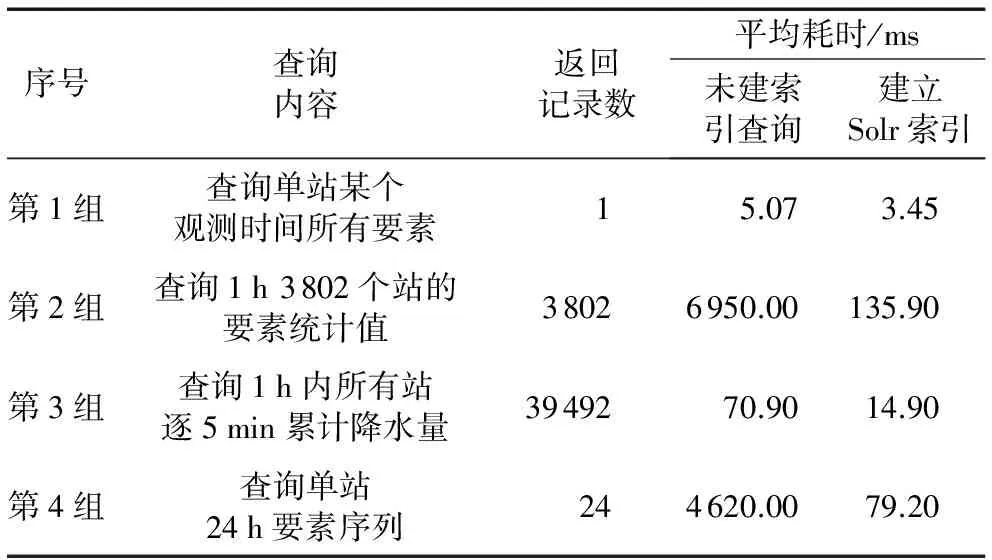
表3 查詢用例

表4 自動站要素統計耗時
5 結語
本文基于Cloudera的CDH搭建了大數據平臺,將Flume和Spark Streaming技術相結合,研發了基于Spark Streaming的氣象自動站實時處理系統,可以快速實現自動站的要素統計和流式入庫。與傳統的處理方式相比,基于流式計算框架實現氣象數據的入庫處理和統計效率更高,處理流程也簡單。可見,該系統對提升自動站數據業務的綜合應用能力具有重要意義,完全具備可行性和適用性。
另外,通過拓展MUSIC接口實現對HBase的數據訪問,為氣象業務系統提供自動站數據的實時要素統計查詢服務,既滿足了業務需求,同時也克服了CIMISS要素統計功能的不足。此外,利用HBase存儲自動站數據,可以作為CIMISS環境下自動站數據存儲的實時備份,為氣象業務提供更可靠的數據保障服務。這項工作為深入推進CIMISS本地化開發和應用提供了良好的借鑒。
在后續的研究與應用工作中,將進一步關注MUSIC的發展,研發更多的接口功能函數,通過MUSIC平臺發布出來,為更多的業務系統和用戶提供自動站的實時要素統計數據服務,更好發揮自動站數據的應用效益。此外,還將繼續開發更多氣象資料處理和統計算法,在Spark Streaming下進行算法的實現和實驗。
References)
[1] 田蘭,金石聲,李波,等.基于XML和正則表達式的氣象數據處理系統[J].計算機科學,2013,40(11A):432-435.(TIAN L, JIN S S, LI B, et al. Processing system of meteorological data based on XML and regular expression [J]. Computer Science, 2013, 40(11A): 432-435.)
[2] 李峰,秦世廣,周薇,等.綜合氣象觀測運行監控業務及系統升級設計[J].氣象科技,2014,42(4):539-544.(LI F, QIN S G, ZHOU W, et al. Upgrading design of integrated atmospheric observing monitoring operation and system platform [J]. Meteorological Science and Technology, 2014, 42(4): 539-544.)
[3] 錢崢,曹艷艷,趙科科,等.私有云在市級氣象業務平臺的實現與應用[J].氣象科技,2014,42(4):641-646.(QIAN Z, CHAO Y Y, ZHAO K K, et al. Implementation and application of private cloud in municipal-level meteorological operation platform [J]. Meteorological Science and Technology, 2014, 42(4): 641-646.)
[4] ZHAO S, YANG X, LI X, et al. A Hadoop-based visualization and diagnosis framework for earth science data [C]// Proceedings of the 2015 IEEE International Conference on Big Data. Piscataway, NJ: IEEE, 2015: 1972-1977.
[5] DUFFY D Q, SCHNASE J L, THOMPSON J H, et al. Preliminary evaluation of MapReduce for high-performance climate data analysis [EB/OL]. [2016- 04- 08]. https://ntrs.nasa.gov/archive/nasa/casi.ntrs.nasa.gov/20120009187.pdf.
[6] KARUN A K, CHITHARANJAN K. A review on Hadoop-HDFS infrastructure extensions [C]// Proceedings of the 2013 IEEE Conference on Information and Communication Technologies. Piscataway, NJ: IEEE,2013:132-137.
[7] VORA M N. Hadoop-HBase for large-scale data[C]// Proceedings of the 2011 International Conference on Computer Science and Network Technology. Piscataway, NJ: IEEE,2011: 601-605.
[8] 曾沁,李永生.基于分布式計算框架的風暴三維追蹤方法[J].計算機應用,2017,37(4):941-944.(ZENG Q, LI Y S. Three dimensional storm tracking method based on distributed computing architecture [J]. Journal of Computer Applications, 2017, 37(4): 941-944.)
[9] 李英俊,韓雷.基于三維雷達圖像數據的風暴體追蹤算法研究[J].計算機應用,2008,28(4):1078-1080.(LI Y J, HAN L. Storm tracking algorithm development based on the three-dimensional radar image data [J]. Journal of Computer Applications, 2008, 28(4): 1078-1080.)
[10] 鄭芳,許先斌,向冬冬,等.基于GPU的GRAPES數值預報系統中RRTM模塊的并行化研究[J].計算機科學,2012,39(6A):370-374.(DENG F, XU X B, XIANG D D, et al. GPU-based parallel researches on RRTM module of GRAPES numerical prediction system [J]. Computer Science, 2012, 39(6A): 370-374.)
[11] 吳石磊,安虹,李小強,等.組網雷達估測降水系統并行化方案的設計與實現[J].計算機科學,2012,39(3):271-275.(WU S L, AN H, LI X Q, et al. Parallel program design and implementation on precipitation program of networking weather radar system [J]. Computer Science, 2012, 39(3): 271-275.)
[12] 楊潤芝,沈文海,肖衛青,等.基于MapReduce計算模型的氣象資料處理調優試驗[J].應用氣象學報,2014,25(5):618-627.(YANG R Z, SHEN W H, XIAO W Q, et al. A set of MapReduce tuning experiments based on meteorological operations [J].Journal of Applied Meteorological Science, 2014, 25(5): 618-627.)
[13] 陳東輝,曾樂,梁中軍,等.基于HBase的氣象地面分鐘數據分布式存儲系統[J].計算機應用,2014,34(9):2617-2621.(CHEN D H, ZENG L, LIANG Z J, et al. HBase-based distributed storage system for meteorological ground minute data [J]. Journal of Computer Applications, 2014, 34(9): 2617-2621.)
[14] 薛勝軍,劉寅.基于Hadoop的氣象信息數據倉庫建立與測試[J].計算機測量與控制,2012,20(4):926-929.(XUE S J, LIU Y. Establishment and test of meteorological data warehouse based on Hadoop [J]. Computer Measurement and Control, 2012, 20(4): 926-929.)
[15] 薛勝軍,周天波,周天杰.基于Hadoop的氣象云儲存與數據處理應用淺析[J].數字技術與應用,2012,15(5):82-84.(XUE S J, ZHOU T B, ZHOU T J. Analysis of meteorological cloud storage and data processing based on Hadoop [J]. Digital Technology & Application, 2012,15(5): 82-84.)
[16] 楊鋒,吳華瑞,朱華吉,等.基于Hadoop的海量農業數據資源管理平臺[J].計算機工程,2011,37(12):222-224.(YANG F,WU H R, ZHU H J, et al. Massive agricultural data resource management platform based on Hadoop [J]. Computer Engineering, 2011, 37(12): 222-224.)
[17] 熊安元,趙芳,王穎,等.全國綜合氣象信息共享系統的設計與實現[J].應用氣象學報,2015,26(4):500-513.(XIONG A Y, ZHAO F, WANG Y, et al. Design and implementation of China integrated meteorological information sharing system [J]. Journal of Applied Meteorological Science, 2015, 26(4): 500-513.)
[18] BHARDWAJ A,VANRAJ, KUMAR A, et al. Big data emerging technologies: a CaseStudy with analyzing twitter data using apache hive [C]// Proceedings of the 2015 2nd International Conference on Recent Advances in Engineering & Computational Sciences. Piscataway, NJ: IEEE, 2015: 1-6.
[19] 王金柱,李元誠.MD5算法在J2EE平臺下用戶管理系統中的應用[J].計算機工程與設計,2008,29(18):4728-4764.(WANG J Z, LI Y C. Application of MD5 algorithm based on J2EE in user management system [J]. Computer Engineering and Design, 2008, 29(18): 4728-4764.
This work is partially supported by the Public Welfare Industry Research Funds of China Meteorological Bureau (201206031).
ZHAOWenfang, born in 1980, M. S., senior engineer. Her research interests include big data, cloud computing, machine learning, meteorological big data processing.
LIUXulin, born in 1963, M. S., research fellow. His research interests include high performance computing, software architecture, data diming, knowledge discovery.
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
今日農業(2019年14期)2019-09-18 01:21:54
今日農業(2019年12期)2019-08-15 00:56:32
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年15期)2019-01-03 12:11:33
今日農業(2019年16期)2019-01-03 11:39:20
