基于網絡和標簽的混合推薦算法研究
2018-03-22 01:37:15趙立新三門峽職業技術學院信息傳媒學院
數碼世界 2018年3期
趙立新 三門峽職業技術學院信息傳媒學院
伴隨著互聯網發展,web信息增長態勢呈現出顯著的指數增長特點,極易導致信息超載。在信息超載的情況下,用戶難以有效獲取所需信息,使信息使用效率呈現出大幅度降低。基于搜索技術,用戶可采用關鍵字對所需信息進行搜索,但該技術缺乏對個性化的用戶需求的滿足。推薦算法可立足于用戶喜好,為用戶進行信息推薦,能實現對信息過載的有效解決。
網絡理論工具能實現對復雜系統的深入理解和有效分析。基于網絡和標簽的混合推薦算法,具有更高的推薦精度以及個性化程度。
1 推薦算法概述
推薦算法,是指基于用戶行為,通過相關數學算法對用戶喜好事物進行推測。單一的推薦算法各自具有本身的缺陷,因此,在實際中,大多采用混合推薦算法。混合推薦算法,是指通過加權、串聯以及并聯等方式對單一推薦算法進行融合。混合推薦算法能實現對單一推薦算法技術弱點的有效避免,并融合其技術優勢。相對于獨立的推薦算法,混合推薦算法的準確率更高[1]。
2 常見的推薦算法
2.1 基于網絡的推薦算法
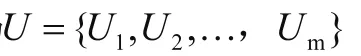
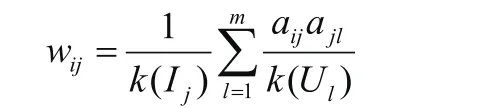

2.2 基于內容的推薦算法
基于內容的推薦算法,通常采用TF—IDF法對用戶模型進行構建。TF—IDF統計法可評估字詞在文件中呈現出的重要性。TF代表文檔d中詞條的出現頻率,IDF代表反文檔頻率,將文件的總數目和含有詞語的文件數目相除,并對商取對數[3]。
基于內容的推薦算法,以用戶所選擇的具體項目為依據,在項目中對關鍵詞進行提取,通過關鍵詞相應的TF—IDF值對向量進行構成,以對用戶配置文件進行表示,以同樣的方式對候選項目進行表示。通過夾角余弦等相關數學算法對用戶與項目存在的相似度進行計算,并將具備最高相似度的項目向用戶進行推薦。此方法在對具備多內容特征文件進行用戶推薦時應用較多[4]。
3 基于網絡和標簽的混合推薦算法
3.1 基于標簽TF—IDF值的用戶偏好模型

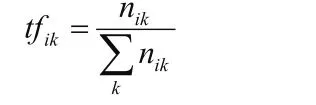


3.2 基于標簽支持度的用戶偏好模型
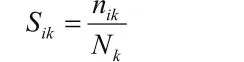

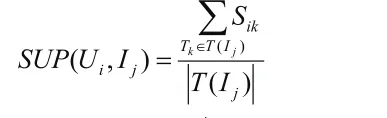
3.3 基于網絡和標簽的混合推薦模型
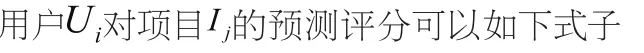
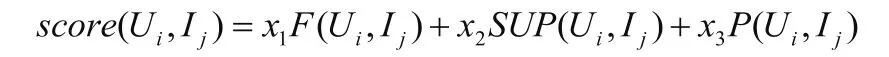
在實質上,本文論述的混合推薦算法主要是基于網絡的推薦算法,并輔之以兩類用戶偏好值,即將附加評分對基于網絡的推薦評分進行增加。
3.4 算法描述

第一步,對基于標簽的用戶偏好模型進行構建
輸出:將用戶偏好配置的相應文件以及用戶標簽支持度等進行輸出

第二步,對項目資源相應的分配矩陣進行計算
輸入:將用戶集合
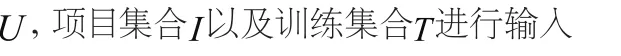

第三步,對用戶尚未選擇項目實施預測評分的計算

綜上所述,NBI算法以用戶—項目相應的二分圖結構為依據,對項目呈現出的推薦程度進行計算,以用戶所選擇的具體項目為依據對用戶尚未選擇的其他項目的相應推薦程度進行計算,并對具體的推薦列表進行獲取,其核心思想是對項目與項目存在的關系進行了利用。本文論述的混合推薦算法以NBI算法作為基礎,以用戶所選擇具體項目體現的標簽信息為依據,分別對TF—IDF法和標簽支持度法進行運用,實現對用戶偏好模型的科學構建,在此基礎上,以待預測的具體項目相應的標簽為依據對用戶對此類項目呈現的偏好程度進行計算,并與NBI推薦模型實施線性組合,對用戶推薦相關信息。相關實踐證明,基于網絡和標簽的混合算法,相對于獨立的推薦算法,具有更高的推薦精度,能更好滿足用戶的個性化需求。
[1]張新猛,蔣盛益,李霞,等.基于網絡和標簽的混合推薦算法[J].計算機工程與應用,2015,51(1):119-124.
[2]宋瑞平.混合推薦算法的研究[D].蘭州大學,2014.
[3]劉傳寶.基于網絡關系特征的混合推薦算法研究[D].吉林大學,2016.
[4]曹春萍,徐幫兵.一種帶隱私保護的基于標簽的推薦算法研究[J].計算機科學,2017,44(8):134-139.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
