混合PSO優化卷積神經網絡結構和參數
2018-03-26 02:30:01唐賢倫周家林
電子科技大學學報 2018年2期
唐賢倫,劉 慶,張 娜,周家林
(重慶郵電大學工業物聯網與網絡化控制教育部重點實驗室 重慶 南岸區 400065)
深度學習可以自動提取特征并將特征進行分類,因此得以廣泛應用[1-3]。作為深度學習方法之一的卷積神經網絡(convolutional neural networks, CNNs),在視頻人體動作識別[4]等領域已得到成功應用。
文獻[5]把卷積神經網絡第一次成功應用在手寫字符識別領域。在特征圖連接問題上,傳統CNNs第一降采樣層與第二卷積層之間特征圖全連接,對于經典的LeNet[6]結構,第一降樣層和第二卷積層之間特征圖連接也是由人為經驗決定的特定連接。雖然利用粒子群優化算法[7]和遺傳算法等智能算法[8]訓練相對簡單的神經網絡已經取得了很好的結果,把粒子群應用到光學字符識別應用中也取得了顯著成效[9],但是這些算法訓練的網絡特征圖之間都是經驗指導的固定連接結構,而全連接結構使得連接數量過多,降低網絡的運算速率,同時全連接結構使得網絡結構對稱,不利于提取不同的特征;而特定的連接結構又受到經驗的影響,不能普遍適用。
本文提出一種將粒子群優化卷積網絡參數和離散粒子群優化[10]卷積神經網絡特征圖連接結構相結合的新方法,使用粒子群預訓練參數,并使用離散粒子群優化第一采樣層和第二卷積層特征圖之間結構連接,使得網絡在非經驗指導下自動尋得最優連接。網絡結構在傳統結構基礎上增加一個全連接層,非線性函數采用指數激活單元(exponential linear unit, ELU)[11],實驗證明,將經過參數和結構優化后的網絡應用到手寫數字識別應用中可以達到較理想的識別效果。
1 卷積神經網絡
權值共享、局域感受野和降采樣是卷積神經網絡的三大特征,可以實現識別圖像的縮放、位移和扭曲不變性。圖1為本文構建網絡。

圖1 卷積神經網絡結構圖
本文采用非線性激活函數指數激活單元(exponential linear unit, ELU)[11]來加速深度網絡學習并提高分類識別率。跟修正線性單元(rectified linear units, ReLUs)[12]相似,ELU激活函數同樣可以取得正值來避免梯度消失。與ReLUs激活函數不同的是,ELU激活函數可以取得負值使得平均單元激活值接近于零。ELU非線性函數的表達式為:

式中,超參數α控制值使當網絡輸入為負值時輸出也為負值,α>0。
2 混合PSO優化卷積神經網絡
本文采用粒子群優化卷積神經網絡參數,和離散粒子群優化卷積神經網絡特征圖之間的連接結構,用BP對該網絡微調參數。
2.1 粒子群優化算法
粒子群算法(particle swarm optimization, PSO)通過隨機初始化一群粒子,并根據法則更新其速度和位置,最終找到最優解。首先對粒子群進行初始化[13]:

式中,Ui(0)、Umax以及Umin分別表示粒子向量初速度、速度上限及下限;Xi(0)表示粒子的初始位置;RS表示元素為(-1,1)的隨機向量,向量的維數與Xi(0)相同;G是待優化參數之前經驗值組成的向量;r是(0,1)范圍內隨機值。速度及位置更新公式為:

式中,c1和c2為加速因子,為正常數;r1和r2為(0,1)范圍內的隨機數;w為慣性因子。
慣性因子是粒子保持飛行速度的系數,本文采用非線性化調整策略對慣性因子進行改進,即:
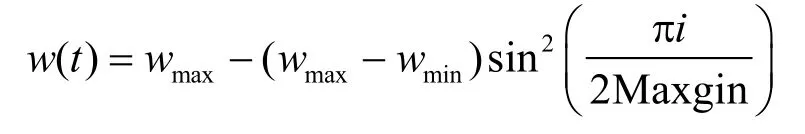
式中,wmax、wmin分別為最大、最小慣性因子;i、Maxgin是當前的及最大的迭代次數。
2.2 離散粒子群優化算法
離散粒子群優化算法(discrete particle swarm optimization, D-PSO)和PSO幾乎相似,有以下不同。位置的初始化方式為:

式中,函數Y=F(X)定義為:RS表示元素為(-1,1)的隨機向量,向量的維數與Xi(0)相同;G表示S2與C3層之間的特征圖連接結構為全連接的向量。
位置更新公式為:

其中非線性函數為sigmoid函數:
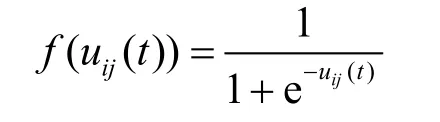
式中,xij(t)表示粒子i在時間t第j個位置;uij(t)為對應速度;rij(t)為(0,1)之間隨機數。其中uij(t)要設定一個上下限,保證f(uij(t))值不能太靠近0或1。
2.3 算法流程
算法的基本流程如下。
1)在S2層和C3層間用全連接方式的情況下,用PSO優化參數。
① 初始粒子群相關參數;根據式(3)、式(4)初始化各粒子參數變量速度及位置,其中式(4)中的G表示按照經驗值初始化卷積神經網絡時的網絡權值向量,由卷積核、連接層權值及偏置等參數組成;把位置轉換成網絡參數形式,并把均方差作為適應度值。
② 對所有粒子執行如下操作:
a.根據式(5)和式(6)更新粒子的速度和位置;
b.計算粒子適應度,若得到的適應度值優于個體極值,則將個體極值位置向量設成當前位置向量;
c.若粒子適應度優于全局最優,就把全局最優位置設成當前位置;
d.如果滿足停止條件,全局極值位置即為所求變量值,并停止搜索;否則,返回步驟②繼續搜索;
2)用D-PSO優化特征圖連接結構。
① 初始化D-PSO相關參數;根據式(3)隨機初始化速度和由式(7)初始化位置;對每個粒子,將粒子的位置變量轉換成特征圖連接結構的形式,計算粒子的適應度值。
② 對所有粒子執行如下操作:
a.根據式(5)和式(8)更新粒子的速度和位置;
b.計算適應度,若得到的適應度優于個體最優值,就將個體最優值位置設成當前位置;
c.若粒子適應度優于全局最優值,就將全局最優值位置設成當前位置;
d.如果達到停止要求,立即停止循環,全局極值位置為所求變量值;否則,返回步驟②繼續搜索。
3)先將PSO尋得的全局最優位置轉換為網絡權值的形式初始化卷積神經網絡參數,在此基礎之上再用D-PSO尋得的全局最優位置轉換為特征圖的連接結構,最后用BP算法微調混合PSO訓練后的網絡參數。
3 實驗結果及分析
在MNIST及CIFAR-10數據集上進行了實驗分析。為了避免隨機性和不穩定性,實驗均進行了10次重復,最后取均值作為最終結果。實驗用的電腦處理器是Intel(R)Core(TM)i5-3470 CPU @3.20 GHz,安裝內存(RAM)為8.00 GB,64位的Windows 7操作系統,沒有采用GUP進行并行計算。
3.1 MNIST實驗
MNIST手寫數字數據集包含60 000個訓練樣本,10 000個測試樣本,共10類,圖像為灰度圖像。
3.1.1 不同激活函數的網絡速度及識別率對比
3種網絡結構與圖1類似,但缺少F5全連接層,其中S2與C3層之間特征圖為全連接方式,使用不同的非線性函數。CNN-S使用常用的Sigmoid函數,CNN-ReL使用ReLUs,CNN-ELU使用ELU。網絡樣本分批訓練,每個批次50個樣本。
圖2及表1表明,相同的結構和訓練樣本時,CNN-ELU網絡收斂速度及識別率都優于其余二者。網絡為Sigmoid函數時,訓練速度緩慢,易陷入過擬合;而ReLUs函數相比Sigmoid函數具有單側抑制性及稀疏激活性;與ReLUs函數相似,ELU函數同樣可以取得正值來避免梯度消失并能取負值以使平均單元激活值接近零,提高學習速度。本文方法采用ELU非線性激活函數,加速了網絡收斂。

圖2 采用不同非線性函數各網絡結構誤差收斂狀況對比

表1 采用不同非線性函數各網絡結構錯誤率對比 %
3.1.2 不同連接結構的網絡識別率對比
實驗中CNN-1網絡為S2與C3層全連接;CNN-2網絡的S2層與C3層特征圖連接結構為經驗連接;CNN-3網絡的S2與C3層結構為隨意連接;CNN-DPSO網絡S2層與C3層特征圖之間連接結構由離散粒子群優化過后得到。離散粒子群的粒子數為20個,c1=c2=1.494,wmax=0.9,wmin=0.2,迭代20次。本文采用ELU函數,由表1可以看出采用ELU的網絡,迭代次數超過10次,圖像識別率的提高并不明顯,故后面所有實驗均最多迭代10次。10次迭代后,CNN-3、CNN-2、CNN-1、CNN-DPSO這4種結構的網絡誤識別率分別為1.37%、1.36%、1.28%、1.20%。
由于S2與C3層特征圖之間為全連接時,使得連接數量過多,降低網絡的運算速率;而固定連接結構受到經驗的影響,不能普遍適用。離散粒子群算法在無經驗指導的情況下智能優化S2與C3層特征圖之間的連接,可以消除冗余連接,從而提高了效率。因此采用DPSO優化后的網絡使識別率高于其他連接結構的網絡。證明了將DPSO用來優化特征圖連接能夠使卷積神經網絡在無經驗指導下獲得較好的識別效果。
3.1.3 不同訓練方法的識別率對比
實驗中NN表示神經網絡;DBN表示深度信念網絡;CNN-ELU網絡結構與3.1.1節中描述相同;CNN-F網絡如圖1,用反向傳播算法訓練;CNN-F-PSO網絡結構與CNN-F相同,用PSO訓練網絡。CNN-F-HPSO網絡采用混合PSO訓練網絡。
由表2和表3可以看出,卷積神經網絡效果普遍優于NN和DBN網絡,說明CNN結構更適合用于提取二維圖像特征。本文采用混合PSO優化參數及特征圖間的連接防止網絡過早陷入局部最優,并有效利用特征圖間的信息,使得在相同的迭代次數時,本文算法識別率略高于其他算法。在達到幾乎相同甚至更高的識別率時,本文方法較傳統CNN方法需要更少運行時間,從而表明本文方法的可行性。

表2 不同訓練方法不同訓練次數的誤識別率對比 %

表3 傳統CNN方法與本文方法識別錯誤率與消耗時間對比
3.1.4 與其他方法識別結果對比

表4 各種方法誤識率對比
表4中其他方法是國內外學者在MNIST數據集上的研究成果[14]。由表4可知,本文方法優于上述傳統方法,但也不是最優方法,因為相對于其他卷積網絡,本文方法網絡較淺,特征圖數較少,且沒有對圖像進行移動、縮放、傾斜、壓縮等人為的扭曲變形預處理,也沒有進行去斜處理和寬度歸一化處理。但本文方法加速了網絡收斂,相對上述傳統方法,提高了識別率,證明該方法的可行性。
3.2 CIFAR-10實驗
CIFAR-10數據集包含10類彩色圖像,其中有50 000個訓練樣本,10 000個測試樣本。簡單地對CIFAR-10進行灰度化等預處理操作后,稱之為CIFAR-10- gray。數據的預處理方式與文獻[15]的相同,即先灰度化,再均值方差歸一化,然后白化處理;網絡迭代訓練次數同樣是50次。網絡結構設置8C-8S-16C-16S-240F也與文獻[15]中的3種結構相同。本文將文獻[15]中的3種網絡結構稱為CNN-1、CNN-2、CNN-3網絡,它們的激活函數均用ReLUs-Softplus[15],池化方式分別為最大池化、隨機池化、概率加權池化。結果對比如表5所示。

表5 不同方法的誤識率對比 %
由于只對數據集進行灰度化預處理,并且灰度化也會損失一些重要特征,從表5可知文中方法并沒有達到非常好的效果,但仍略微優于文獻[15]中的CNN-1、CNN-2、CNN-3網絡的識別效果,證明了本文方法不僅在MNIST數據集上有較好的識別效果,應用于CIFAR-10數據集上也是有效可行的。
4 結束語
基于混合PSO的卷積神經網絡訓練方法與其他方法相比提高了訓練效率,并在訓練時間接近時,網絡識別率得到提高;達到同樣的識別效果,本文方法收斂需要的訓練次數較少。因此本文方法加速了誤差收斂,只需少量次數迭代訓練網絡就能達到甚至優于其他傳統方法的識別效果。雖然優化結構和參數時增加了訓練復雜度,但經優化后的網絡提高了信息處理效率,因此比較適合識別大規模數據。
[1]LECUN Y, BENGIO Y, HINTON G.Deep learning[J].Nature, 2015, 215: 436-444.
[2]戴曉愛, 郭守恒, 任淯, 等.基于堆棧式稀疏自編碼器的高光譜影像分類[J].電子科技大學學報, 2016, 45(3):382-386.DAI Xiao-ai, GUO Shou-heng, REN Yu, et al.Hyperspectral remote sensing image classification using the stacked sparse autoencoder[J].Journal of University of Electronic Science and Technology of China, 2016, 45(3): 382-386.
[3]ARORA C, SABETZADEH M, BRIAND L, et al.Automated checking of conformance to requirements templates using natural language processing[J].IEEE Transactions on Software Engineering, 2015, 41(10):944-968.
[4]ZHANG Zhong, WANG Chun-heng , XIAO Bai-hua, et al.Cross-view action recognition using contextual maximum margin clustering[J].IEEE Transactions on Circuits and Systems for Video Technology, 2014, 24(10): 1663-1668.
[5]LECUN Y, BOSER B, DENKER J S, et al.Backpropagation applied to handwritten zip code recognition[J].Neural Computation, 1989, 1(4): 541-551.
[6]LECUN Y, BOTTOU L, BENGIO Y, et al.Gradient-based learning applied to document recognition[J].Proceedings of the IEEE, 1998, 86(11): 2278-2324.
[7]YUAN Q, YIN G.Analyzing convergence and rates of convergence of particle swarm optimization algorithms using stochastic approximation methods[J].IEEE Transactions on Automatic Control, 2015, 60(7): 1760-1773.
[8]OULLRTTE R, BROWNE M, HIRASAWA K.Genetic algorithm optimization of a convolutional neuralnetwork for autonomous crack detection[C]//Congress on Evolutionary Computation.Portland: IEEE, 2004, 1: 516-521.
[9]FEDOROVICI L O, PRECUP R E, DRAGAN F, et al.Evolutionary optimization-based training of convolutional neural networks for OCR applications[C]//2013 17th International Conference on System Theory, Control and Computing (ICSTCC).Sinaia: IEEE, 2013: 207-212.
[10]LIU Dong, JIANG Qi-long, CHEN J X. Binary inheritance learning particle swarm optimisation and its application in thinned antenna array synthesis with the minimum sidelobe level[J].IET Microwaves, Antennas & Propagation, 2015,9(13): 1386-1391.
[11]CLEVERT D A, UNTERTHINER T, HOCHREITER S.Fast and accurate deep network learning by exponential linear units (ELUs)[C]//International Conference on Learning Representations.San Juan: Computer Science,2016: arXiv:1511.07289.
[12]XIONG Shi-fu, WU Guo, LIU Di-yuan.The Vietnamese speech recognition based on rectified linear units deep neural network and spoken term detection system combination[C]//9th International Symposium on Chinese Spoken Language Processing (ISCSLP).Singapore: IEEE,2014: 183-186.
[13]LI Y H, ZHAN Z H, LIN S J, et al.Competitive and cooperative particle swarm optimization with information sharing mechanism for global optimization problems[J].Information Sciences, 2015, 293: 370-382.
[14]LECUN Y, CORTES C, BURGES C J C.The MNIST database of handwritten digits[EB/OL].[2016-07-12].http://yann.lecun.com/exdb/mnist/.
[15]余萍, 趙繼生, 張潔.基于非線性修正函數的卷積神經網絡圖像識別研究[J].科學技術與工程, 2015, 15(34):221-225.YU Ping, ZHAO Ji-sheng, ZHANG Jie.Image recognition of convolutional neural networks based on rectified nonlinear units function[J].Science Technology and Engineering, 2015, 15(34): 221-225.
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
