一種基于混合神經網絡的車牌字符識別方法
2018-04-03 01:17:06柴偉佳王連明
東北師大學報(自然科學版) 2018年1期
關鍵詞:記憶
柴偉佳,王連明
(東北師范大學物理學院,吉林 長春 130024)
隨著交通運輸產業(yè)的迅猛發(fā)展,對智能交通系統(tǒng)的研究提出了更高的要求,而車牌識別正是智能交通系統(tǒng)的重要組成部分,其關鍵是車牌字符識別子系統(tǒng).
我國目前的車牌由漢字、阿拉伯數字和英文大寫字母組合構成,因為其中的漢字結構復雜,因此我國車牌較國外有更高的識別難度.在實際應用中,采集到的字符樣本往往存在不同程度的噪聲污染,或者是變形和部分缺失,因此要求識別系統(tǒng)具有較強的容噪能力.目前針對車牌字符識別最常用的方法是模板匹配法和神經網絡法.葉晨洲等人[1]采用基于模板匹配技術的多識別器融合方法,對漢字、數字和字母的識別率可達96%;馬俊莉等人[2]提出一種基于改進模板匹配的車牌字符識別方法,平均識別率達97%;吳進軍[3]采用支持向量機方法,對車牌字符的整體識別率可達98%.模板匹配法最大的不足是對相似字符的區(qū)分能力較差,當樣本維數較大時效率很低.并且利用模板匹配法通常需要對樣本進行特征提取,這一過程往往難以分析和操作.隨著計算機及相關技術的發(fā)展,人工神經網絡開始廣泛應用于車牌的識別問題.我國目前針對車牌字符識別一般采用的是BP神經網絡.周科偉[4]采用改進的BP算法,對漢字、數字和字母的識別率分別為86%,98%和96%;孟濤[5]采用3個BP神經網絡并聯,將其結果組合輸出的方法,識別率高達98%;咼潤華等人[6]將BP神經網絡與模板匹配法相結合,識別率為97%.但這些方法針對的識別對象都是從實際車牌中獲取的字符,樣本數量有限,且不能體現實際應用中出現的所有可能情況.
聯想記憶是生物系統(tǒng)的一個重要功能,可以使人類由事物的部分信息聯想到該事物的完整模式,因此將聯想記憶網絡應用于車牌字符識別中,可有效辨認模糊、形變或不完整的字符樣本.[7]本文基于聯想記憶網絡的這種特性,同時將其與BP神經網絡具有高容錯性和不存在偽狀態(tài)的優(yōu)勢相結合,提出了一種混合神經網絡,實驗證明該網絡性能優(yōu)于單純的聯想記憶網絡和BP神經網絡.
1 混合神經網絡設計
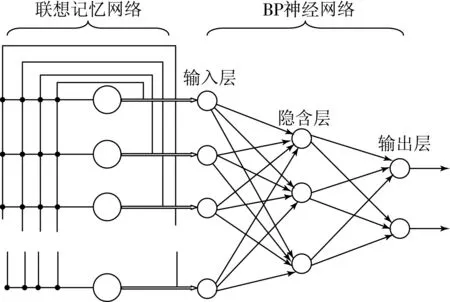
圖1 聯想記憶+BP混合神經網絡結構
最典型的聯想記憶網絡是Hopfield網絡.本文設計的混合神經網絡是將Hopfield網絡的輸出作為BP神經網絡的輸入,將BP神經網絡的輸出作為最終識別結果.該混合網絡的具體結構如圖1所示.
1.1 聯想記憶算法
Hopfield聯想記憶網絡是一種單層反饋神經網絡.它是一種動態(tài)網絡,網絡的工作過程為狀態(tài)的演化過程,它按照“能量”減小的方式演化,最終達到穩(wěn)定狀態(tài),這些穩(wěn)定的狀態(tài)叫做網絡的吸引子.[8]在本文中這些吸引子就是需要記憶的模式,由于每個吸引子都存在一定的吸引域,處在吸引域內的狀態(tài)最終都可以演化為對應的吸引子,因此聯想記憶網絡有較強的容錯能力,可實際應用于對畸變字符的識別.
設計一個聯想記憶網絡需要2個過程:在記憶階段,通過輸入標準樣本數據,調整權值,使網絡達到穩(wěn)定;在聯想階段,輸入待識別樣本,系統(tǒng)經過演化,最終收斂于某個吸引子.完成聯想記憶的關鍵在于采用有效的學習算法設計網絡權值,常用的算法有外積法、偽逆法、NDRAM(Nonlinear Dynamic Recurrent Associative Memory)算法及LSSM(Linear Systems in a Saturated Mode)算法.由于外積法要求樣本相互正交,且容量小,不適用于大量樣本的記憶,故本文實驗中將采用另外3種算法.
偽逆法:利用偽逆法時權值計算公式為
W=ΣΣI,
(1)
其中Σ表示由全部記憶模式組成的矩陣,ΣI表示Σ的偽逆矩陣.由于偽逆法生成的權值是投影到記憶模式形成的線性子空間上,所以也被稱為投影法.[9]
NDRAM算法:該算法采用非線性的S型函數作為作用函數,表達式為
(2)
式中δ表示傳遞參數,通常取δ=0.1.NDRAM算法的權值更新方式是在Hebb學習律的基礎上疊加一個反Hebb學習律,計算公式為
(3)
其中:x[0]表示神經元的初始狀態(tài),即需要記憶的模式;x[p]代表通過作用函數的p次迭代后的神經元狀態(tài);η表示學習速率,通常取η=0.01.[10]
LSSM算法:該算法的權值和閾值的設計流程如下[11]:
(1) 輸入K個N維的記憶模式x={x1,x2,…,xk}及參數τ(通常取τ=10).
(2) 由記憶模式生成一個線性子空間A,A={x1-xk,x2-xk,…,xk-1-xk}.
(3) 對A做奇異值分解,A=USVT,U={u1,u2,…,un-1,un},計算A的秩m=rank(A).
(5) 計算Tτ=T+-τT-,Iτ=XK-TτxK,其中Tτ可視為權值,Iτ可視為閾值.
1.2 BP算法
BP神經網絡是一種按誤差反向傳播算法訓練的多級前饋神經網絡,由輸入層、隱含層、輸出層構成.由于它能學習和存儲大量的輸入-輸出模式映射關系,因此在模式識別領域有相當廣泛的應用.
2 車牌字符識別算法流程

圖2 全部標準樣本圖
采用了31個省、自治區(qū)和直轄市以及5個特殊領域共計36個漢字車牌字符作為標準樣本,此外還包括數字0~9及除“I”和“O”以外的全部英文大寫字母,基本涵蓋了車牌中所有可能出現的字符.這70個標準樣本樣如圖2所示.
每個標準樣本為二值圖像,用“0”代表黑色、“1”代表白色.圖像尺寸大小為32像素×16像素,將每個標準樣本轉化為一列向量,可得到一個512×70的原始圖像矩陣,該矩陣將分別用于聯想記憶網絡和BP神經網絡的訓練學習.
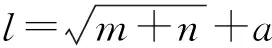

圖3 混合網絡的運行流程
3 算法仿真實驗
以往的車牌字符識別實驗,針對的識別對象一般都是實拍的車牌,很難囊括全部漢字及英文數字字符,并且前期經過了一定預處理,因此無法量化、真實地體現識別算法的性能.本文則是基于實驗室條件下,通過對標準樣本進行加噪、旋轉、切割,全面量化地模擬了實際情況中樣本的污損情況.為了考察本文提出的混合網絡的識別能力,將對5種算法組合情況進行實驗,即偽逆法+BP算法,NDRAM算法+BP算法,LSSM算法+BP算法,單獨BP算法及單獨LSSM算法.在識別過程中,選取圖2中偶數位置上的35個樣本進行實驗,用平均錯誤率來表征各網絡的識別水平.平均錯誤率定義為
(4)
其中:errorrate為35個樣本的平均識別錯誤率;errors為當前噪聲條件下網絡未能正確識別的總次數;sum為當前噪聲條件下網絡進行識別實驗的總次數.
3.1 加噪的車牌字符識別
在回憶階段采用的待識別對象為加入不同程度的椒鹽噪聲的字符樣本.該實驗主要模擬實際應用中由于污漬、磨損、光照不均等情況對車牌識別系統(tǒng)的干擾.為去除隨機性的影響,對每個待識別樣本進行10次實驗,因此(4)式中sum取值為350.記錄每種算法在噪聲密度0~1區(qū)間的平均錯誤率,最終得到如圖4所示的錯誤率曲線.
由圖4可以看出,基于LSSM+BP算法的混合網絡的性能是最佳的,在噪聲密度不大于0.7時對樣本可達100%正確識別.其性能不僅遠優(yōu)于其他混合網絡和單獨的BP神經網絡,相對于單獨的LSSM網絡也有了進一步提升.
3.2 旋轉的車牌字符識別
主要研究5種網絡對不同旋轉角度下的車牌字符樣本的識別情況.與加入隨機噪聲不同,由于每次實驗輸出的結果是確定的,所以對每個樣本只需進行一次識別實驗,即(4)式中sum值取為35.對35個標準樣本進行1°~18°的旋轉,記錄每種網絡在樣本旋轉不同角度時的平均識別錯誤率,得到實驗結果見圖5.由圖5可以看出,基于LSSM+BP算法的混合網絡在樣本旋轉角度不大于7°時錯誤率依然是最低的.由于在實際應用中,進行最終的字符識別之前通常會對車牌進行傾斜校正[12],因此小角度旋轉的樣本的識別率才是關注重點.從這個角度來說,基于LSSM+BP算法的混合網絡的性能仍然是最佳的.
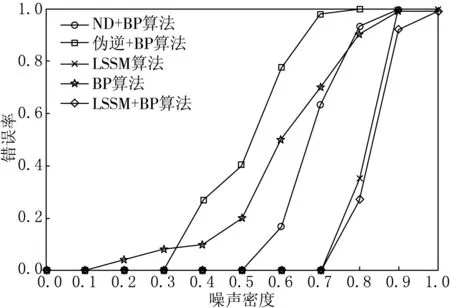
圖4 不同噪聲密度下幾種算法的錯誤率比較 圖5 旋轉不同角度時幾種算法的錯誤率比較
3.3 切割的車牌字符識別
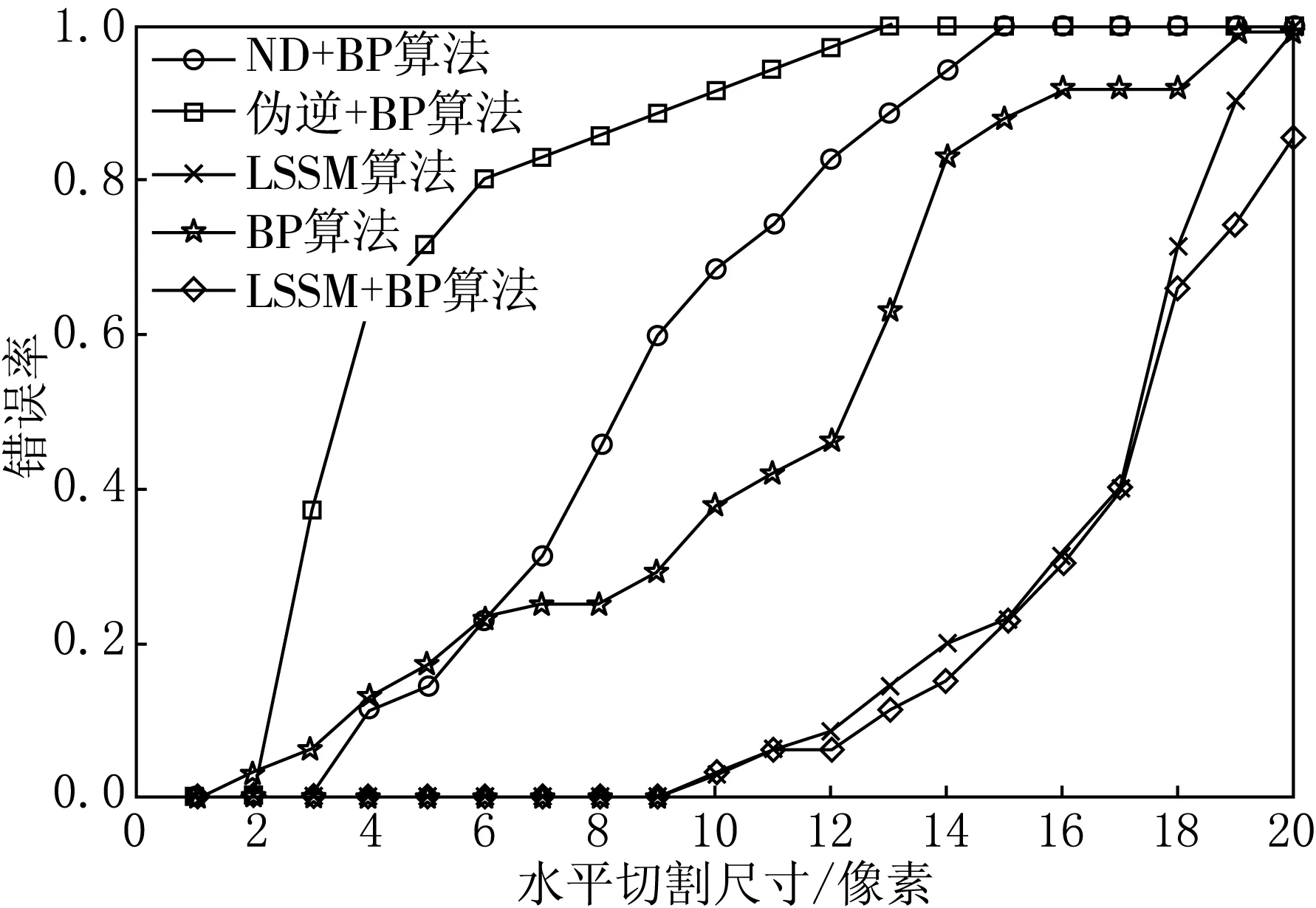
圖6 切割掉不同尺寸時幾種算法的錯誤率比較
針對5種算法對不完整的車牌字符的識別率問題,對35個樣本進行1~20行的橫向切割,割除掉的部分補0后送入網絡進行識別.錯誤率計算方法與旋轉的車牌字符識別完全相同.實驗得到的錯誤率曲線如圖6所示.
由圖6可以看出,基于LSSM+BP算法的混合網絡在水平切割尺寸小于9像素時均可輸出正確結果,遠優(yōu)于另外2種混合網絡和單獨的BP神經網絡.
綜合上述實驗可以得到:基于聯想記憶+BP算法的混合網絡性能優(yōu)于單獨的聯想記憶網絡和單獨的BP神經網絡;在3種混合網絡中,尤以基于LSSM+BP算法的混合網絡是最優(yōu)的.在聯想記憶網絡識別錯誤的結果中,一種是誤判成其他標準模式,另一種則是進入偽狀態(tài).這是由于Hopfield聯想記憶網絡是一種動態(tài)網絡,存在較多的偽吸引子,所以輸出的結果會呈現諸多不確定狀態(tài),而BP神經網絡的輸出結果只能是70個標準樣本中的一個,不存在偽狀態(tài).因此,將聯想記憶算法和BP算法結合起來,可利用BP算法的容錯能力,將聯想記憶網絡輸出的接近標準樣本的偽狀態(tài)“糾正”回標準模式,進一步提高網絡識別率.為了直觀展示該混合網絡的優(yōu)越性,圖7給出了基于LSSM+BP算法的混合網絡的部分輸出結果.

圖7 LSSM+BP混合網絡的部分輸出結果
4 結論
本文提出了一種基于聯想記憶算法與BP算法相結合的混合神經網絡,并將該網絡用于對加噪、旋轉和切割3種情況下的車牌字符樣本的識別.該方法充分利用了聯想記憶網絡對形變、模糊和不完整樣本的識別能力以及BP神經網絡的糾錯能力.通過大量對比實驗,證明混合網絡在使用LSSM+BP算法時性能最佳,可糾正LSSM網絡輸出的部分偽狀態(tài),進一步降低誤識率.由于目前單一神經網絡很難滿足對復雜條件下樣本的高識別率的要求,本文提出的混合神經網絡的方法為車牌識別等模式識別領域的研究和方法的改進提供了一種新的思路.在后續(xù)的研究中,將進一步探討該方法在現實交通環(huán)境中對車牌字符的識別效果,并對網絡的算法進行改進,以便應對更加復雜的實際環(huán)境.
[參考文獻]
[1]葉晨洲,楊杰,宣國榮.車輛牌照字符識別[J].上海交通大學學報,2000,34(5):672-675.
[2]馬俊莉,莫玉龍,王明祥.一種基于改進模板匹配的車牌字符識別方法[J].小型微型計算機系統(tǒng),2003,24(9):1670-1672.
[3]吳進軍.車牌識別技術的研究[D].杭州:浙江大學,2006.
[4]周科偉.Matlab環(huán)境下基于神經網絡的車牌識別[D].西安:西安電子科技大學,2009.
[5]孟濤.車牌識別關鍵技術的實現和研究[D].武漢:華中科技大學,2006.
[6]咼潤華,蘇婷婷,馬曉偉.BP神經網絡聯合模板匹配的車牌識別系統(tǒng)[J].清華大學學報(自然科學版),2013,53(9):1221-1226.
[7]張德豐.MATLAB神經網絡編程[M].北京:化學工業(yè)出版社,2011:194-199.
[8]陳明.MATLAB神經網絡原理與實例精解[M].北京:清華大學出版社,2015:282-284.
[9]PERSONNAZ L,GUYON I,DREFUS G.Collective computational properties of neural networks:new learning mechanisms[J].Physical Review A,1986,34(5):4217-4228.
[10]CHARTIER S,PROULX R.NDRAM:nonlinear dynamic recurrent associative memory for learningbipolar and nonbipolar correlated patterns[J].Neural Networks,IEEE Transactions on,2005,16(6):1393-1400.
[11]LI J H,MICHEL A N,POROD W.Analysis and synthesis of a class of neural networks:linear systems operating on a closed hypercube[J].Circuits and Systems,IEEE Transactions on,1989,36(11):1405-1422.
[12]文祝青,羅威,杜華英.基于BP神經網絡的車牌號碼識別[J].現代計算機,2015,12(35):64-68.
猜你喜歡
現代裝飾(2021年6期)2021-12-31 05:29:04
小學生優(yōu)秀作文(高年級)(2021年10期)2021-11-02 03:05:24
華人時刊(2020年15期)2020-12-14 08:10:44
學苑創(chuàng)造·A版(2020年10期)2020-11-06 05:21:26
華人時刊(2017年13期)2017-11-09 05:38:52
作文周刊·小學一年級版(2016年27期)2017-06-03 23:21:17
絲綢之路(2016年9期)2016-05-14 14:36:33
新湘評論·下半月(2016年4期)2016-05-05 22:12:41
新湘評論·下半月(2016年4期)2016-05-05 22:12:41
海外文摘(2016年4期)2016-04-15 22:28:55
