區塊鏈的存儲容量可擴展模型*
2018-04-08 00:48:28賈大宇信俊昌王之瓊王國仁
計算機與生活 2018年4期
賈大宇,信俊昌+,王之瓊,郭 薇,王國仁
1.東北大學 計算機科學與工程學院,沈陽 110819
2.東北大學 中荷生物醫學與信息工程學院,沈陽 110819
3.沈陽航空航天大學 計算機學院,沈陽 110136
1 引言
區塊鏈技術隨著比特幣等數字加密貨幣的日益普及而越來越受關注。區塊鏈技術是一種新型的去中心化協議,能安全存儲數字貨幣、股權債權等數字資產。區塊鏈技術通過運用數據加密[1]、時間戳、分布式共識[2]和經濟激勵等手段,有效地解決了拜占庭將軍問題[3]中的共識問題,實現了在節點無需互相信任的分布式系統中去中心化的點對點交易,從而有效降低了現實經濟的信任成本,重新定義了互聯網時代的產權制度。
雖然區塊鏈技術顯著提高了數據的安全性與可靠性,但是目前區塊鏈技術的儲存擴展性較差。以比特幣為例,截至2017年5月8日,共產生465 402個區塊,總容量為107.89 GB,鏈上已認證地址9 892 723個[4]。因為區塊鏈技術要求比特幣的網絡中每個完全節點都保存著完整的區塊鏈信息,所以目前有近1 000萬個節點貢獻了100 GB以上的磁盤空間來儲存區塊鏈數據。也就是說,目前的比特幣系統用了近1 000 PB的存儲空間僅保存了100 GB左右的數據,這極大地浪費了存儲空間。并且比特幣的容量和參與的節點數量會隨著時間的推移迅猛增加,區塊鏈技術就會越來越多地占用海量節點的大量存儲空間。這也極大地限制了以區塊鏈技術為基礎的數據庫系統的發展與應用。
為了增加區塊鏈技術的儲存擴展性,本文提出了一種區塊鏈存儲容量可擴展模型,并采用一種數據副本分配策略對模型進行了優化。
本文的主要貢獻如下:
(1)提出了一種區塊鏈存儲容量可擴展模型。模型將區塊鏈中各個區塊保存在一定比例的節點中,而不是所有節點。同時,增加了節點可靠性驗證,在保證數據安全的同時,減少了區塊鏈的儲存空間。
(2)提出了一種區塊鏈數據副本分配策略,對容量可擴展模型中副本數的計算過程進行了優化。
(3)通過實驗證明,區塊鏈存儲容量可擴展模型具有一定的穩定性、容錯性和安全性,同時減少了海量節點的大量存儲空間,有效地增加了區塊鏈的儲存擴展性。
2 相關工作
區塊鏈系統基于P2P技術[5]提供了一個只可以寫入的全公開日志。參與區塊鏈網絡的節點都遵循POW(proof of work)協議[6],即工作量證明。協議通過運算,得出一個滿足規則的隨機數,最先計算出結果的節點即獲得本次記賬權,發出本輪需要記錄的數據,全網其他節點驗證后一起存儲。存儲框架如圖1所示,網絡中的每個節點都保存著完整的數據副本。
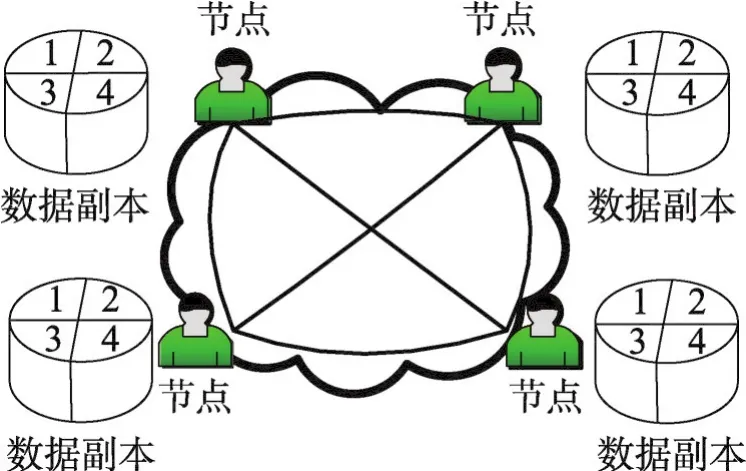
Fig.1 Storage framework of traditional blockchain圖1 傳統區塊鏈技術存儲框架
近年來,學者對區塊鏈進行了大量研究。Boyd等人[7]提出了一種基于區塊鏈的用戶登錄方法,使每個用戶都可以公平地登錄和使用服務器。Gervais等人[8]提出了一種框架來量化地分析區塊鏈在各種共識和網絡參數下的安全性。Herbert等人[9]提出了一種基于區塊鏈技術的軟件驗證方法,改善了軟件被盜版使用的問題。Karame[10]詳細分析了比特幣和其他基礎區塊鏈系統的安全性,并找出了其中潛在的安全隱患。Ali等人[11]提出了Blockstake命名存儲系統,系統設計了四層架構,充分利用了區塊鏈的去中心化特點,保證了數據的高安全性。King[12]和Bentov[13]等人實現了POS(proof of stake)權益證明機制,相對于POW機制,一定程度減少了數學運算帶來的資源消耗,提升了區塊鏈系統的性能。
3 區塊鏈存儲容量可擴展模型
本文利用分布式存儲方法[14-15],提出了區塊鏈存儲容量可擴展模型。其核心思想是將一條完整的區塊鏈分成若干部分,分布存儲在系統中,如圖2所示。
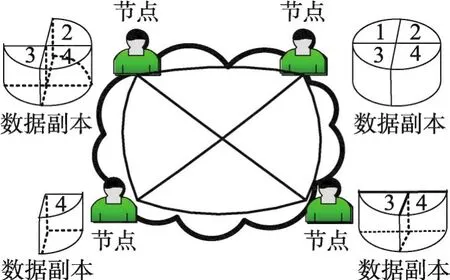
Fig.2 Storage framework of scalable model圖2 可擴展模型存儲框架
在現有的區塊鏈技術中,一個攻擊者想要篡改數據,需要控制網絡中50%以上的節點。在區塊鏈分布式存儲后,網絡中區塊鏈的副本數減少,攻擊者就可以在控制少于50%節點數的情況下修改區塊鏈數據,這在一定程度上降低了區塊鏈的安全性。但是隨著區塊鏈技術的廣泛應用,海量節點正源源不斷地加入到區塊鏈系統中。攻擊者想要控制區塊鏈系統中的很少一部分節點也幾乎是不可能的。盡管如此,針對區塊鏈容量可擴展模型還提出了節點可靠性驗證的方法,增加了區塊鏈的安全性。區塊鏈存儲容量可擴展模型框架如圖3所示。
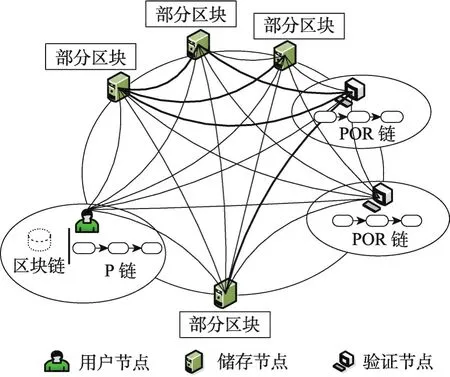
Fig.3 Scalable model for storage capacity of blockchain圖3 區塊鏈存儲容量可擴展模型
區塊鏈存儲容量可擴展模型中的節點包含3個角色:用戶節點、儲存節點和驗證節點。用戶節點是原始數據擁有者,儲存節點是副本的保存者,而驗證節點是儲存節點穩定性的驗證者。一個節點可以同時具備兩種或者三種角色。同時,模型建立了兩條新的區塊鏈:P(position)鏈和POR(proofs of retrievability)鏈。P鏈保存在用戶節點中,記錄數據各個副本被保存在存儲節點的位置。POR鏈保存在驗證節點中,記錄各個儲存節點的可靠性評價。將儲存節點位置信息和儲存節點的可靠性評價寫入基于區塊鏈技術的P鏈和POR鏈中,也是利用了區塊鏈不可被篡改的特點,保證數據的安全性。
3.1 數據存儲
在區塊鏈存儲容量可擴展模型進行數據存儲時,模型采用了POR數據可檢索性證明[16-17]方法對用戶節點區塊鏈中的區塊進行加密處理,得到相應的密文和密鑰。POR方法是保存在外地服務器上數據的可檢索性的加密證明。其實現的具體過程是:用戶節點將密文交由儲存節點保存后,可以隨時查詢儲存節點中數據的完整性;儲存節點會在被查詢時,隨機選擇一部分密文數據發送給用戶節點;用戶節點通過密鑰與接收密文的計算結果進行比對,得出儲存節點中的數據是否完整。因此,利用POR方法可以在少量文件傳輸的通信成本下,實時驗證出系統中數據的完整性。
在模型進行數據存儲過程中,首先采用POR方法對用戶節點中的每個區塊進行加密,得到相應的密文和密鑰。然后,用戶節點計算出每個區塊需要保存的副本數。接著,模型將POR方法生成的密鑰保存到本地存儲器中,并發給驗證節點保存;將加密后的區塊數據保存到儲存節點中。此時,模型將訪問驗證節點中保存的儲存節點可靠性信息,從中找出可靠值較高的儲存節點來保存各個區塊數據。驗證節點為了保證儲存節點可靠性信息不會被惡意篡改,將其保存在POR鏈中。之后,將每個區塊按照所需要的副本數保存在相應數量的選出的儲存節點中。當數據副本被保存后,為了保證用戶節點進行數據讀取,模型將儲存節點的地址返回給用戶節點,并將其保存在P鏈中,保證儲存節點地址數據的安全性。
區塊鏈存儲容量可擴展模型的數據存儲過程如圖4、圖5所示。

Fig.4 Step(1)~(3)of stored procedure圖4 存儲過程步驟(1)~(3)
過程1存儲容量可擴展模型數據存儲過程。
(1)采用POR方法對每個區塊進行加密;
(2)用戶節點計算出每個區塊所需保存副本數;
(3)將POR方法生成的密鑰保存到本地存儲器中,并發給驗證節點,保存到POR鏈中;
(4)用戶節點向模型發送存儲數據的請求;
(5)模型訪問驗證節點POR鏈中各個儲存節點的可靠性信息,選出可靠性最高的作為本次操作的儲存節點;
(6)將選出的儲存節點返回給用戶節點;

Fig.5 Step(4)~(8)of stored procedure圖5 存儲過程步驟(4)~(8)
(7)用戶節點按照所需要的副本數保存在相應數量的選出的儲存節點中;
(8)將保存各個區塊的儲存節點的地址返回給用戶節點,保存在P鏈里。
3.2 數據讀取
在區塊鏈存儲容量可擴展模型進行數據讀取時,首先用戶節點訪問本地磁盤中的P鏈,得到各個區塊儲存的位置信息,根據位置信息找到相應的儲存節點。然后,儲存節點將保存的數據返回給用戶節點。用戶節點根據本地保存的POR方法生成的密鑰,對接收密文數據進行恢復,得到原始數據。
區塊鏈存儲容量可擴展模型的數據讀取過程如圖6所示。
過程2存儲容量可擴展模型數據讀取過程。
(1)用戶節點訪問P鏈信息,找到保存每個區塊的各個儲存節點;
(2)儲存節點將保存的數據返回給用戶節點;
(3)用戶節點根據完整返回的副本數據,利用本地保存的密鑰對數據進行解密,恢復出原始數據。
3.3 儲存節點可靠性驗證
在區塊鏈存儲容量可擴展模型中,儲存節點保存著區塊數據。但是由于一些特殊狀況,儲存節點可能出現將數據修改或將數據丟失等故障。為了減小由于儲存節點故障導致的區塊數據的不穩定性,驗證節點會根據POR方法生成的密鑰,隨時驗證存儲節點隨機發回的部分密文數據,實時檢測儲存節點數據存儲情況。然后,驗證節點將實時的檢測情況寫入POR鏈中,當用戶節點再次申請儲存數據時,提供最新的儲存節點可靠性值,使用戶節點選出此時最穩定的存儲節點保存區塊數據。
區塊鏈存儲容量可擴展模型中儲存節點可靠性驗證過程如圖7所示。在實際應用中,模型對于儲存節點可靠性的評價標準可以采取如下方法。首先,模型會給每個儲存節點分配相同的可靠性值。然后,驗證節點每隔相同的一段時間檢測儲存節點數據的可靠性,相隔時間根據對數據安全需求的具體情況來制定。當儲存節點中數據完整時,其可靠性值不變。當儲存節點數據被修改或者丟失時,則減少其可靠性值,并保存到POR鏈中。最后,當模型選擇高可靠性的儲存節點時,以POR鏈中的各個儲存節點可靠性值作為衡量標準。
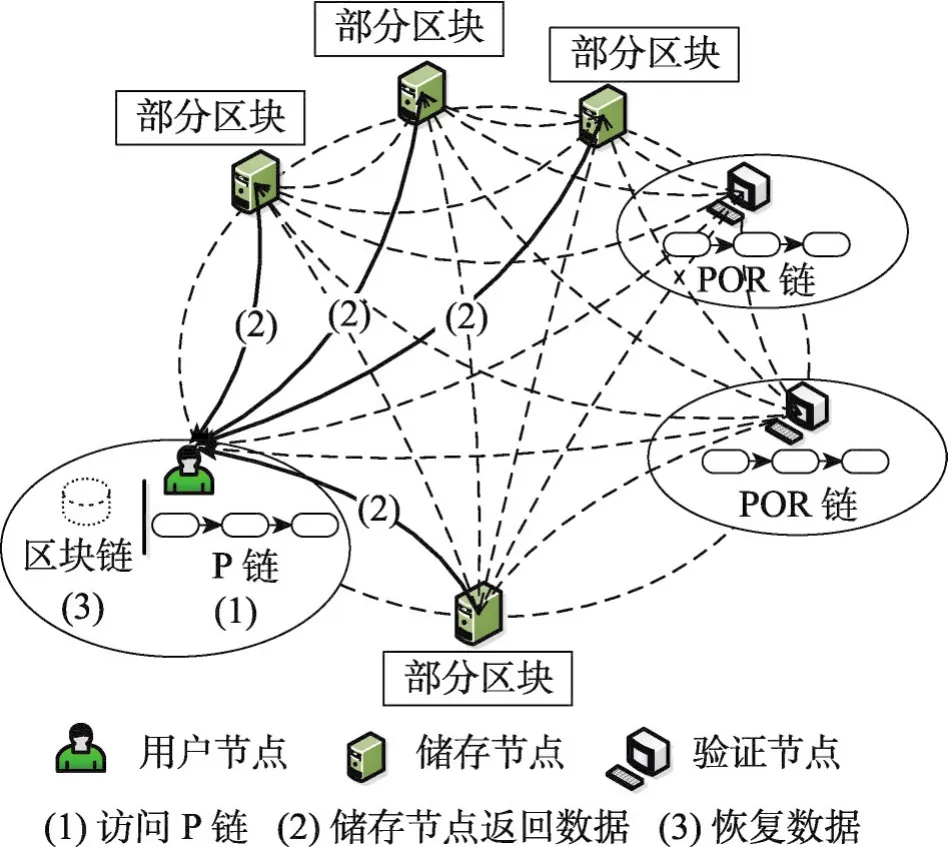
Fig.6 Data reading procedure圖6 數據讀取過程
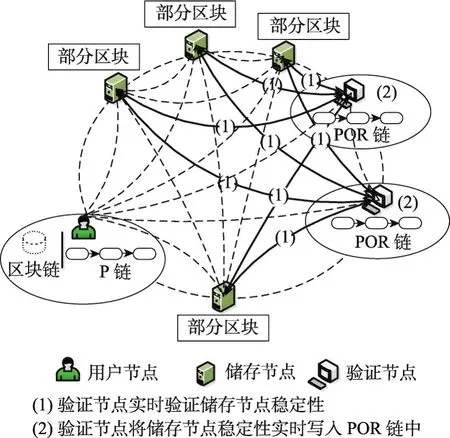
Fig.7 Reliability verification of storage nodes圖7 儲存節點可靠性驗證過程
3.4 系統激勵機制
在比特幣的應用中,礦工通過計算得出下一個區塊的哈希值。正是礦工們的大量計算,保證了比特幣的安全性。因此,比特幣系統會對每個挖礦成功者獎勵一定數量的比特幣。這也激勵了成百上千的礦工消耗自身CPU的計算能力和大量電力去挖礦。而在區塊鏈存儲容量可擴展模型中,儲存節點和驗證節點提供了自己的大量磁盤空間,保證了用戶節點的數據安全。本文對于儲存節點和驗證節點也提出一種激勵機制,可以令他們自身作為用戶節點,在模型中安全存儲一定空間的數據。
4 數據副本分配策略
在區塊鏈存儲容量可擴展模型的數據存儲過程的第二個步驟中,用戶節點首先計算每個區塊保存的副本數。但區塊鏈的每個新區塊都是在上一個區塊基礎上計算來的,不同的區塊安全性不同。因此,本文根據每個區塊的安全性,提出了一種區塊鏈的數據副本分配策略,優化了模型的存儲過程。
數據副本分配策略,首先根據系統節點總數得出保存每個區塊的最少副本數。然后根據系統安全性需求,確定出一定數量連續的區塊保存相同的副本數。最后根據區塊鏈的難度設定,計算出每個區塊需要保存的副本數。
區塊鏈技術的創始人Nakamoto[18]在論文中假設了一個雙重支付的攻擊場景,攻擊者試圖比誠實節點更快地產生一條平行鏈條代替區塊鏈。攻擊者是否能夠成功趕超誠實鏈,可以近似地看成賭徒破產問題。此時,假設p為誠實節點制造出下一節點的概率,q為攻擊節點制造出下一節點的概率,那么攻擊者在區塊增加了第z塊時,攻擊者取得的進展服從泊松分布,分布期望為:

追趕上誠實鏈條的概率Pz為:
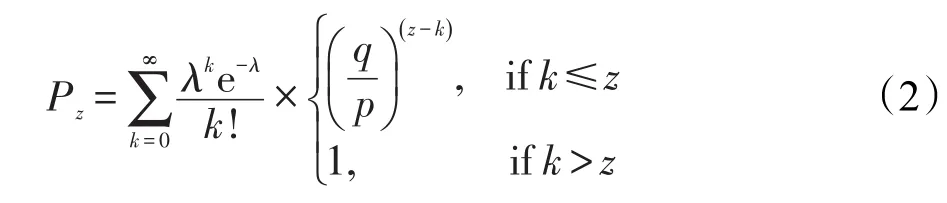
為了避免對無限數列求和,將式(2)轉換為:
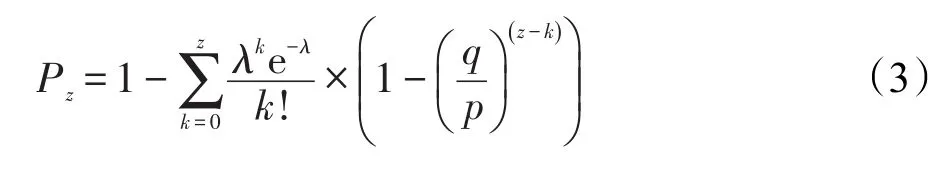
本文利用Java編寫代碼,計算出在q=0.1時,z取0到30概率Pz的大小。并用Matlab將函數f(z,Pz)畫出圖像,如圖8所示。
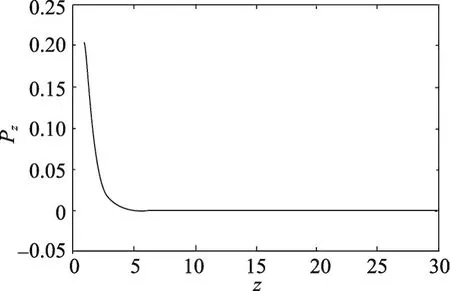
Fig.8 Image off(z,Pz)圖8 函數 f(z,Pz)圖像
由于隨著z的增加,Pz減小速率很快,當z取值較大時,圖8不能明顯表示出Pz的值。因此,當z取10到15時,畫出了f(z,Pz)的圖像,如圖9所示。
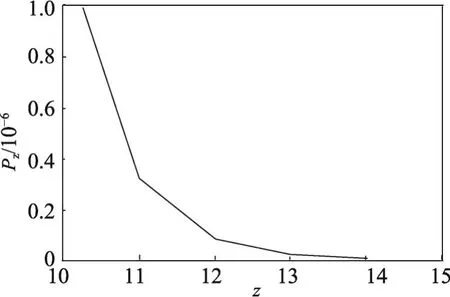
Fig.9 Image off(z,Pz)whenzis selected from 10 to 15圖9 當z取10到15時函數 f(z,Pz)圖像
可以看出,隨著區塊的增加,攻擊者越來越難趕超誠實鏈。越原始的區塊中數據被篡改的可能性就越低,安全性也就越高。因此,在數據副本分配策略中,每個區塊的副本數由區塊所在位置決定,將區塊鏈中較原始的區塊保存少量份數,而較新的區塊保存足夠多的份數,二者函數關系如式(4)所示。設M為區塊鏈中節點總數,i為區塊鏈中區塊的編號,n為區塊鏈目前的總區塊數,mi為區塊i需要保存的份數,Pn-i為第i個區塊被攻擊者追趕上的概率,也可以看作為第i個區塊的安全性系數。

但是,在區塊鏈機制中,如果50%以上節點保存了相同的數據,則這個數據被視作真實數據。從而,控制了網絡中一半數量以上的節點,就會控制整個網絡的數據。因此,也不能令每個區塊的副本數特別小,而是要根據不同區塊鏈系統安全性需要,規定出每個區塊保存的最小副本數k。
同時,Borel定律[19]定義了任何低于1/1050的概率都是不可能的。因此,根據式(3)可以計算出,當z增加到一定數值時,Pz的概率會達到10-50以下。此時,攻擊節點想要趕上誠實節點變為不可能事件。因此,將每z個區塊作為一組數據分片,保存相同的副本數量。
最后,得出每個區塊的副本數。每zmin個區塊被分割成一個分片,第i個分片保存mi份副本,但副本數最小為k。
因此,數據副本分配策略過程如下所示。
過程3數據副本分配策略過程。
(1)根據區塊鏈網絡的計算能力,預估出攻擊節點制造出下一節點的概率q;
(2)將q帶入式(3),計算當Pz≤10-50時,z的最小取值zmin;
(3)根據區塊鏈的用戶總量和區塊總數,確定出在保證數據安全前提下,每個區塊保存副本數的最小值k;
(4)將區塊鏈中節點總數M和區塊鏈目前的區塊數n帶入式(4),計算出每個位置的分片保存的副本數mi;
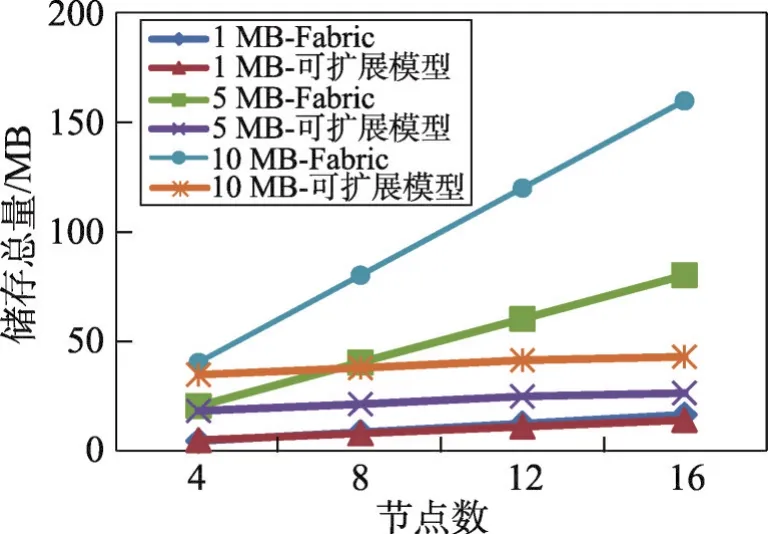
(5)對完整的區塊鏈進行分片處理,每zmin個區塊被分割成一個分片,第i個分片保存mi份副本,當mi 此處,本文給出了當q=0.1時,數據副本分配策略中每個區塊的副本數。 首先,根據式(3)進行計算,為了簡化分組過程,z的取值為10的整數倍。當z≥100時,P的概率已達到10-50以下。因此,將每100個區塊作為一組數據分片,保存相同的副本數量。 然后,利用式(4)計算每組分片保存的副本數。此時,為了方便計算,對式(3)的計算結果利用Matlab對函數f(z,Pz)做了weibull擬合,擬合結果為式(5)。 其中,a=1.905(1.886,1.924),b=0.723(0.715 4,0.730 7),擬合方差(SSE)為1.215E-05,確定系數(R-square)為0.999 7。 從擬合結果可以看出,z與Pz呈負指數關系。因此,為了簡化分片過程,將式(3)化簡為式(6)來計算分片保存副本數,分片結果如圖10所示。 當n增加時,每新增100個區塊組成一個分片,該分片由此時全網中所有節點保存。而對于之前分片的副本數,由式(6)根據此時網絡中的節點總數重新計算。如果在新增100個區塊的時間里,全網的節點數激增,計算出的所需副本數比網絡中已存副本數多,則將之前分片副本數增加至式(6)計算數量;如果網絡中已存副本數比計算出的所需副本數量大,則可以令部分存儲節點釋放其儲存空間,但保證網絡中已存副本量大于等于所需副本數量。 區塊鏈存儲容量可擴展模型利用此副本分配策略會在保證數據可靠性和安全性的前提下,增加區塊鏈的存儲容量。 假設:當可擴展模型采用基于式(6)的副本分配策略進行數據存儲時,模型中共有節點數M,其中存在不穩定節點數量為d(d≤M),不穩定節點會有e(e≤1)的概率出現數據丟失情況。則新產生的區塊分片保存副本數mn/100=M,每一個分片的副本數mj為式(7)所示,j為分片序號。 此時,當所有不穩定節點第一次出現數據丟失時,數據可以被完全恢復的概率為: 在式(8)中要求: (1)當d (2)當d 當不穩定節點出現多次數據丟失時,由于在區塊鏈存儲容量可擴展模型的POR鏈中記錄了每次的數據丟失情況,并每次將該節點的可靠性值隨即減少。可靠值被減少后,不穩定節點被選作儲存節點的概率就會降低。數據會被保存在較穩定的節點中,可以被恢復的概率就會提高。 Fig.10 Allocation scheme of copies圖10 區塊副本數分配方案 實驗的開發環境為Intel Core i5-6500 3.20 GHz CPU和16 GB內存的PC機上。利用VMware Workstation 12.5.2建立了16個節點,每個節點為內存1 GB,硬盤大小為60 GB的ubuntu16.04系統。借助IBM開發的開源Hyperledge Fabric v0.6版本,構建起P鏈和POR鏈區塊鏈項目。 首先,測試基于區塊鏈存儲容量可擴展模型系統的穩定性。實驗分別建立了4個、8個、12個和16個節點,所有節點均為儲存節點,且其中3個節點同時為用戶節點和驗證節點。實驗運行調用chaincode_example02.go交易代碼,每完成一次交易,生成5.39 KB的廣播消息。 在所有節點都正常運行且不被攻擊的情況下,在數據分片時,以500 KB為一個組進行分片,每個分片的最小副本數為2份,副本數與分片位置的函數根據式(4)計算得出。當實驗完成交易186次、930次和1 860次,生成廣播數據1 MB、5 MB和10 MB時,區塊鏈容量可擴展模型與基于Hyperledge Fabric v0.6的區塊鏈系統中所有節點儲存總容量如圖11所示。 Fig.11 Storage space occupied by scalable model and Hyperledge Fabric圖11 可擴展模型與Hyperledge Fabric占用的存儲空間 通過分析圖11的實驗結果,可以得到以下結論。 (1)在節點數較少的情況下,存儲容量可擴展模型所有節點儲存總量與Fabric區塊鏈相比相差不大。但當節點數增多時,容量可擴展模型所占用的存儲空間與Fabric區塊鏈系統相比明顯減少。 (2)當存儲數據量較小時,存儲容量可擴展模型所有節點儲存總量與Fabric區塊鏈相比相差不大。這是由于儲存容量可擴展模型在存儲交易數據的同時,在P鏈中保存了儲存節點位置信息,在POR鏈中保存了儲存節點的可靠性評價信息。并且在P鏈與POR鏈中的每條數據大小都為固定值,因此當存儲數據量不斷增加時,容量可擴展模型所占用的存儲空間與Fabric區塊鏈系統相比明顯減少。 (3)當存儲數據量不斷增加時,區塊鏈容量可擴展模型所需的儲存空間的增量趨于平緩。 因此,容量可擴展模型在多節點、大數據的應用上,具有良好的存儲擴展性。 同時,區塊鏈存儲容量可擴展模型與Fabric區塊鏈系統的處理時間如圖12和圖13所示。容量可擴展模型的處理時間要略多于Fabric區塊鏈系統,且隨著節點數量和存儲數據大小增加,可擴展模型的處理時間基本呈線性增加。 Fig.12 Time to process 1 MB data by scalable model and Hyperledge Fabric圖12 可擴展模型與Hyperledge Fabric處理1 MB數據時間 Fig.13 Time to process 5 MB data by scalable model and Hyperledge Fabric圖13 可擴展模型與Hyperledge Fabric處理5 MB數據時間 然后,測試系統的容錯性。假設在8個、12個和16個儲存節點中存在不穩定節點,不穩定節點會丟失本地的部分儲存數據。為了符合實際應用情況,實驗設置了4個不穩定節點,且這4個不穩定節點均不是驗證節點,它們出現不穩定概率分別為0.8、0.6、0.4和0.2。當實驗完成交易930次,得到數據5 MB,分片方法與上個實驗相同時,區塊鏈容量可擴展模型、僅基于數據副本分配策略的區塊鏈系統與基于Hyperledge Fabric v0.6的區塊鏈系統各自恢復的數據總量的百分比如圖14所示。 Fig.14 Fault tolerance of scalable model圖14 可擴展模型容錯性測試 當不穩定節點出現時,Fabric基本不受影響,僅基于數據副本分配策略的區塊鏈系統受影響最大,區塊鏈容量可擴展模型所受影響較小。這是由于容量可擴展模型和僅基于數據副本分配策略的區塊鏈系統相比,利用POR鏈中對各個節點的可靠性評價,選出了穩定性更好的節點存儲數據。并且從實驗中可以看出,當節點數增加,也就是系統中副本數增加時,容量可擴展模型數據恢復比例有所增加,系統的容錯性增強。 最后,測試區塊鏈容量可擴展模型的安全性。本文借助了Blockbench[20]對區塊鏈安全測試方法:當有攻擊者故意修改儲存節點中的存儲數據時,區塊鏈會產生分叉,此時系統的安全性可以根據分叉鏈產生的區塊數量來判斷,區塊數量越少,系統越安全。在實驗中,建立了16個節點,運行Hyperledge Fabric與區塊鏈容量可擴展模型,攻擊出現在系統運行第100秒,在第250秒時結束。兩個系統正常運行和被攻擊時的實驗結果如圖15所示。 Fig.15 Security of scalable model圖15 可擴展模型安全性測試 從實驗中可以看出,Hyperledge Fabric和區塊鏈存儲容量可擴展模型被攻擊時,并沒有產生分叉鏈,這是因為實驗中容量可擴展模型也是基于Hyperledger Fabric技術構建的。Hyperledger的一致性協議保證了區塊的安全性,讓被攻擊的鏈不產生分叉。但是在攻擊停止后,Hyperledger和容量可擴展模型都用了一段時間才從攻擊中恢復,并且容量可擴展模型比Hyperledger需要的恢復時間更長。 通過實驗證明,基于Hyperledger Fabric的區塊鏈存儲容量可擴展模型在被攻擊時,雖然需要更多的處理時間,但具有良好的安全性。 區塊鏈的協議要求全網中每個節點都保存著同一條完整的區塊鏈信息,這導致了區塊鏈的容量受到網絡里存儲空間最小的節點的限制。本文提出了一個區塊鏈存儲容量可擴展模型。模型將區塊鏈中各個區塊保存在一定比例的節點中,而不是所有節點中。并且模型增加了節點可靠性驗證,保證了數據的安全性。模型中用戶節點根據數據副本分配策略將每個區塊保存相應的副本數,并基于POR數據可檢索性證明方法對副本數據進行加密,并將密鑰發送個驗證節點。驗證節點利用POR方法實時更新儲存節點的穩定性值,依此選擇高穩定性節點來儲存用戶節點的數據副本。最后,經實驗證明,區塊鏈存儲容量可擴展模型在具有一定的穩定性、容錯性和安全性的同時,有效地增加了區塊鏈的儲存擴展性。 未來可以進一步研究數據副本分配策略,提出更準確的計算數據副本方法,在保證數據安全性的前提下,減少更多儲存空間。同時,也可以將區塊鏈存儲容量可擴展模型應用于Ethereum和Parity等不同的區塊鏈系統中,提高不同區塊鏈系統的存儲擴展性。 [1]Bonneau J,Miller A,Clark J,et al.SoK:research perspectives and challenges for Bitcoin and cryptocurrencies[C]//Proceedings of the 2015 IEEE Symposium on Security and Privacy,San Jose,May 17-21,2015.Washington:IEEE Computer Society,2015:104-121. [2]Yuan Yong,Wang Feiyue.Blockchain:the state of the art and future trends[J].Acta Automatica Sinica,2016,42(4):481-494. [3]Eyal I,Gencer A E,Sirer E G,et al.Bitcoin-NG:a scalable blockchain protocol[C]//Proceedings of the 13th USENIX Symposium on Networked Systems Design and Implementation,Santa Clara,Mar 16-18,2016.Berkeley:USENIX Association,2016:45-59. [4]Blockmeta.The blockchain data of Bitcion[EB/OL].[2017-05-07].https://blockmeta.com/btc-stat. [5]Amalarethinam D I G,Balakrishnan C,Charles A.An improved methodology for fragment re-allocation in peer-topeer distributed databases[C]//Proceedings of the 4th International Conference on Advances in Recent Technologies in Communication and Computing,Bangalore,Oct 19-20,2012.Piscataway:IEEE,2012:78-81. [6]Li Jingrui,Wolf T.A one-way proof-of-work protocol to protect controllers in software-defined networks[C]//Proceedings of the 2016 Symposium on Architectures for Networking and Communications Systems,Santa Clara,Mar 17-18,2016.New York:ACM,2016:123-124. [7]Boyd C,Carr C.Fair client puzzles from the Bitcoin blockchain[C]//LNCS 9722:Proceedings of the 21st Australasian Conference on Information Security and Privacy,Melbourne,Jul 4-6,2016.Berlin,Heidelberg:Springer,2016:161-177. [8]Gervais A,Karame G O,Wüst K,et al.On the security and performance of proof of work blockchains[C]//Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security,Vienna,Oct 24-28,2016.New York:ACM,2016:3-16. [9]Herbert J,Litchfield A.A novel method for decentralised peer-to-peer software license validation using cryptocurrency blockchain technology[C]//Proceedings of the 38th Australasian Computer Science Conference,Jan 27-30,2015.Sydney:Australian Computer Society,2015:27-35. [10]Karame G.On the security and scalability of Bitcoin's blockchain[C]//Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security,Vienna,Oct 24-28,2016.New York:ACM,2016:1861-1862. [11]Ali M,Nelson J C,Shea R,et al.Blockstack:a global naming and storage system secured by blockchains[C]//Proceedings of the 2016 USENIX Annual Technical Conference,Jun 22-24,2016.Berkeley:USENIXAssociation,2016:181-194. [12]King S,Nadal S.PPCoin:peer-to-peer crypto-currency with proof-of-stake[EB/OL].[2017-04-02].http://www.peercoin.net/bin/peercoinpaper.pdf. [13]Bentov I,Lee C,Mizrahi A,et al.Proof of activity:extending Bitcoin's proof of work via proof of stake[J/OL].Cryptology ePrintArchive,2014:452. [14]Tung Y C,Lin K C J,Chou F C.Bandwidth-aware replica placement for peer-to-peer storage systems[C]//Proceedings of the 2011 Global Communications Conference,Houston,Dec 5-9,2011.Piscataway:IEEE,2011:1-5. [15]Ng W S,Ooi B C,Tan K L,et al.PeerDB:a P2P-based system for distributed data sharing[C]//Proceedings of the 19th International Conference on Data Engineering,Bangalore,Mar 5-8,2003.Washington:IEEE Computer Society,2003:633-644. [16]Juels A,Kaliski B S.PORs:proofs of retrievability for large files[C]//Proceedings of the 2007 ACM Conference on Computer and Communications Security,Alexandria,Oct 28-31,2007.New York:ACM,2007:584-597. [17]Armknecht F,Bohli J M,Karame G O,et al.Outsourced proofs of retrievability[C]//Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security,Scottsdale,Nov 3-7,2014.New York:ACM,2014:831-843. [18]Nakamoto S.Bitcoin:a peer-to-peer electronic cash system[EB/OL].[2017-05-07].http://www.bitcoin.org/bitcoin.pdf. [19]Borel E.Probabilities and life[M].New York:Dover Publications Inc,1962. [20]Dinh T T A,Wang Ji,Chen Gang,et al.BLOCKBENCH:a framework for analyzing private blockchains[C]//Proceedings of the 2017ACM International Conference on Management of Data,Chicago,May 14-19,2017.New York:ACM,2017:1085-1100. 附中文參考文獻: [2]袁勇,王飛躍.區塊鏈技術發展現狀與展望[J].自動化學報,2016,42(4):481-494.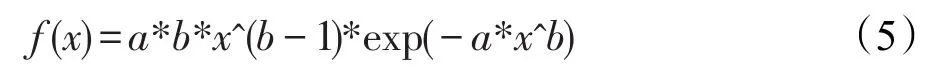

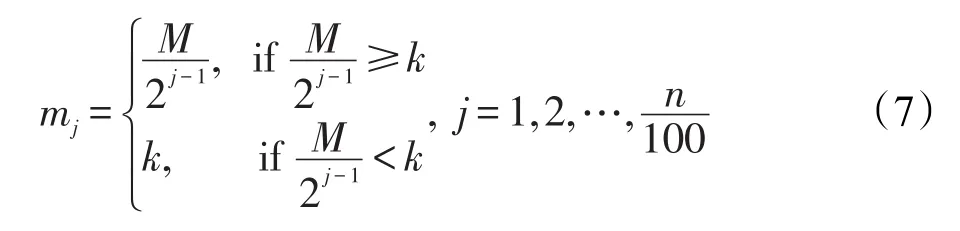


5 實驗結果

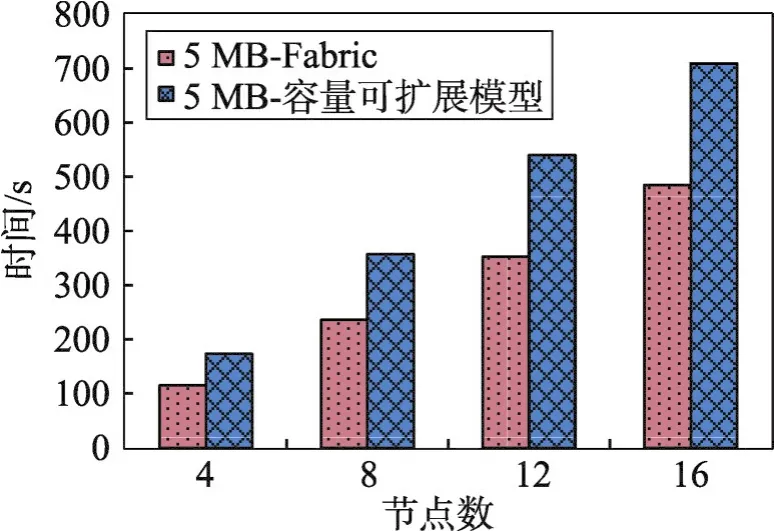
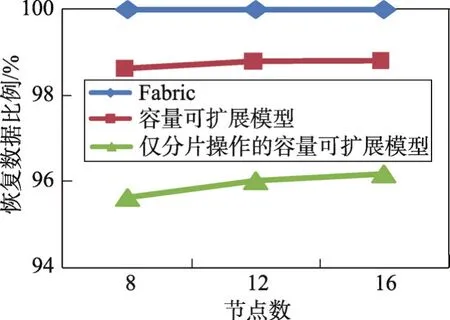
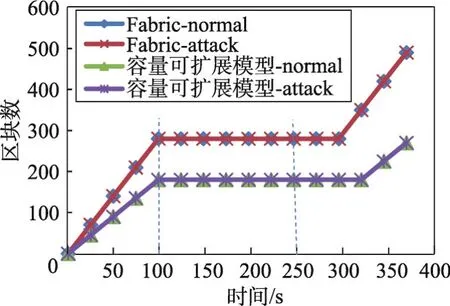
6 結束語
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38現代儀器與醫療(2022年2期)2022-08-11 09:51:40汽車工程師(2021年12期)2022-01-18 06:02:43中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50數學物理學報(2020年2期)2020-06-02 11:29:24商用汽車(2016年11期)2016-12-19 01:20:16光學精密工程(2016年6期)2016-11-07 09:07:19信息安全與通信保密(2016年3期)2016-08-23 01:23:46商用汽車(2016年6期)2016-06-29 09:18:54商用汽車(2016年4期)2016-05-09 01:23:12
