誘導二元語義廣義概率有序加權平均算子在財務管理決策中的應用*
2018-04-12 09:36:57李肖瑞冷歐陽
沈陽工業大學學報(社會科學版) 2018年2期
李肖瑞, 冷歐陽
(1. 鄭州工業應用技術學院 商學院, 鄭州 451199; 2. 國家電網公司 呼倫貝爾供電公司, 內蒙古 呼倫貝爾 021008)
在當今的商業環境下,各種企業所面臨的競爭環境同樣激烈,如果不想被別的企業所取代必須制定相應的對策。在這種大環境下,財務管理決策這個對于企業生存與發展至關重要的管理決策問題越來越被人們重視。在企業的有關資金方面,最重要的包括投資、籌資、經營運作以及利潤分配。企業財務管理中的各項活動都涉及到財務決策問題,良好的財務決策有助于企業構建優效的經營機制、確立恰當的發展戰略、合理運作資金,并且強迫企業在競爭中求發展,使得自己的優勢產品做得更好,并且能夠在這個過程中獲得更大的經濟效益,在市場中立于不敗之地。企業的財務決策不是單個人或單方面決定的結果,而是由多人共同參與決策分析并制定決策的整體過程,因此是一個群決策問題。
在相當多的方面(如關于群的決策),國外學者對OWA算子進行整合,并且提出了IOWA算子[1]和GOWA算子[2]。IOWA算子根據誘導變量進行參數的重新排序,反映了決策者的重要性和決策的準確性,解決了之前OWA算子中依靠參數進行決策分析的問題;而GOWA是經典OWA算子的直接拓展。這兩類集結算子使得信息的表達和處理更具有實用性。近年來,有關這兩類算子的研究已引起學者的高度重視,如周禮剛等提出的誘導連續區間有序加權平均算子的應用[3]等。現在很多學者提出將廣義有序的IGOWA算子應用到多屬性群的決策中[4-5]。伴隨著有關學者研究的進一步加深,某國外學者在廣義平均的基礎上提出了IGOWA算子[6],并在此基礎上提出了POWA算子[7]和TWO-TLIGOWA算子[8],這些算子都是OWA算子的延伸。
現在,IGOWA算子的多屬性群決策探究能夠較好地反映信息結合過程,對于概率信息,Merigó介紹了語言概率序列加權平均(ILPOWA)算子[9],但尚缺乏2TLIGOWA算子和2TLGPWA算子的結合。本文對于準則值是二元語義的情況,利用概率信息和誘導變量建立相應的集結算子。
如何計算算子權重同樣是探究集結算子時的一個關鍵問題。許多學者致力于研究如何確定算子屬性權重,常用的方法有最小方差法[10]、最小離差法[11]、貝葉斯最大熵法[12]以及一些拓展的權重方法,如加權函數法[13]、最小距離法[14]、改進的極大極小差距模型[15]等。這些方法的共同特點是從公平性角度出發確定權重,換言之,所有屬性都應該被認為是同樣重要的,這顯然存在不合理之處。例如,在實際決策矩陣中,對于一個給定的屬性,若在同一個屬性下每一個方案的屬性值幾乎相同,則這個屬性在方案選取時起到的作用比較微弱,應該給予它一個比較小的權重;相反地,如果該性質值差異較大,則應賦予一個較大的權重。為此,本文結合公平性,并同時兼顧屬性值的差異性,提出一個非線性二次偏差最優定權模型。進而,本文結合集結算子和權重定權模型,提供了基于2TLIGPOWA算子的財務管理決策辦法。最后,通過算例分析并證明了本文該方法的有效性。
一、預備知識
1. 二元語義及其集結算子
二元語義使用一個二元組(si,ai)表示語言評價信息[16]。其中,si表示點評信息匯合的語句,ai表示計算出來的語句與開始語句點評集中最相近語句之間的差異,此差別是[-0.5,0.5)內的數,即符號平移的觀點[17-18]。接下來對二元語義進行詳盡的說明。
定義1若si∈S是一個語句,θ為S→S×[-0.5,0.5),則相對應的二元語義公式為
θ(si)=(si,0) (si∈S)
(1)
定義2設實數β∈[0,g]表示語句集結運算的成效,g+1表示集合S中元素個數,稱(si,ai)為與β相對應的二元語義方式,Δ為[0,g]→S×[-0.5,0.5),則有
Δ(β)=(si,ai)
(2)
式中:i=round(β),round表示四舍五入取整算子;ai=β-i,ai∈[-0.5,0.5)。
定義3設(si,ai)是一個二元語義,則si是S中第i個元素,ai∈[-0.5,0.5),存在逆函數Δ-1為S×[-0.5,0.5)→[0,g],使之轉換為相對應的數,β∈[0,g],即
Δ-1(si,ai)=i+ai=β
(3)
假設(si,ai),(sj,aj)為兩個二元語義,則有如下性質:
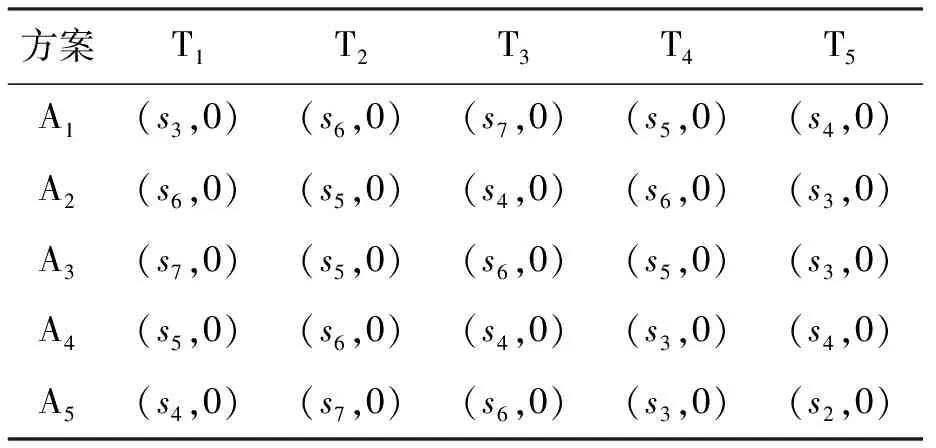
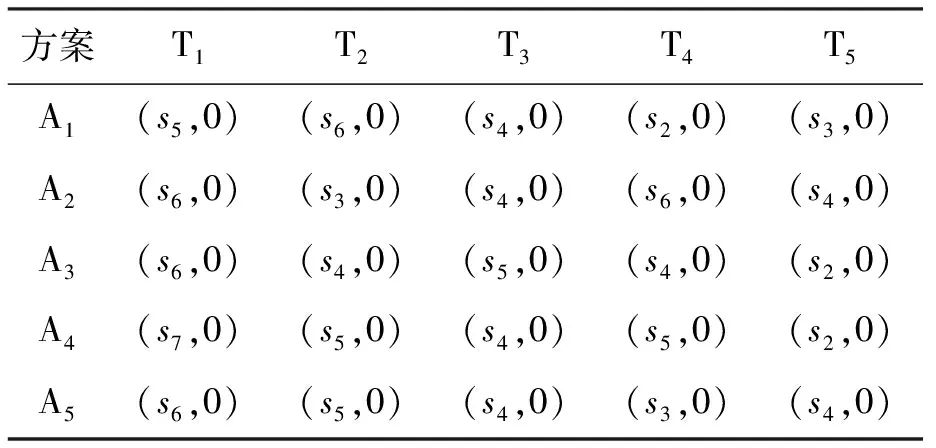
(1) 若i (2) 若i=j,ai=aj,則(si,ai)=(sj,aj);ai 2. IOWA算子 OWA算子的另一個方式是利用誘導因子,得到誘導有序加權平均(IOWA)算子,n元函數IOWA的映射Sn→S滿足 IOWA((u1,a1),(u2,a2),…,(un,an))= (4) IOWA算子所采用的集結方式如下:通過(ui,ai)中的誘導變量ui的數值大小排列順序來對IOWA算子進行排序,再根據ai進行有序加權的集結。aj的大小與位置并不影響wj,wj只受誘導變量所處位置的影響[19-20]。在上述過程中,IOWA算子區別于OWA算子之處為:IOWA算子通過誘導變量來進行排序,而OWA算子則通過數據值大小來進行排序。在一般情況下,現實決策過程中的誘導變量可以體現決策者的重要性或者其所作決策的精確性。因此,相比而言IOWA算子的排序方法更為合理。 3. POWA算子 POWA算子是在考慮每一個概念重要程度的時候利用概率和OWA的集結所構成的一種集結算子[21-22],n元函數POWA的映射Sn→S滿足 (5) 根據不同權重向量的選取,可得到多種類型的POWA算子。特別情況下,若β=0,得到概率集結算子;若β=1,則得到OWA算子。 1. ILPOWA算子 Merigó定義了ILPOWA算子,它是語言概率平均(LPA)算子和誘導IOWA算子的結合[23],在同一個表達式中根據每個概念重要性進行分析。因此,它能夠以概率和決策者的態度特征來表達客觀信息,同時能夠使用語言變量進行不確定信息表達,表達式為 ILPOWA((u1,sa1),(u2,sa2),…,(un,san))= (6) 2. 2TLIGPOWA算子 在復雜環境下進行多屬性群決策時,往往不能實現精確評價,決策者希望評價值越精確越好。為了更好地提高算子的適用性,將多種不同信息的集成算子通過適合的控制參數整合到一個函數表達式里,再通過對控制參數的調整讓決策者獲得對應的調整結果,不同的參數取值對應著不同的信息集成算子[24-25]。通過上述研究內容,本文提出了一個有所拓展的集成算子,即誘導二元語義廣義概率有序加權平均(2TLIGPOWA)算子。 定義4n元函數2TLIGPOWA的映射Sn,Sn→S滿足 2TLIGPOWA((u1,(s1,a1)),(u2,(s2,a2)),…, (7) 2TLIGPOWA算子由2TLIGOWA算子和2TLGPWA算子兩部分組成,具體為 2TLIGPOWA((u1,(s1,a1)),(u2,(s2,a2)),…, (8) 式中:bj為第j大的ui所對應的bi,bi=Δ-1(si,ai),β∈[0,1]。 假設有粒度為7的語言術語集S={s0=很差,s1=差,s2=稍差,s3=相當,s4=稍好,s5=好,s6=很好};相應的誘導集結變量(ui,(si,ai))為((5,(s2,0)),(7,(s4,0)),(2,(s3,0)),(9,(s6,0)));w=(0.2,0.2,0.3,0.3)為權重向量,概率權重為v=(0.3,0.3,0.2,0.2),λ=1。其中,概率信息的重要程度為60%,2TLIGOWA中權重向量w的重要程度為40%,利用2TLIGPOWA算子集結,結果為 2TLIGPOWA= 0.4(0.2s6+0.2s4+0.3s2+0.3s3)+ 0.6(0.3s2+0.3s4+0.2s3+0.2s6)= s3.56 (9) 需要注意的是,當權重向量沒有標準化時,2TLIGPOWA能夠表達為 2TLIGPOWA((u1,(s1,a1)),(u2,(s2,a2)),…, (10) 2TLIGPOWA既單調、有界,也具有置換不變性、冪等性。 定理1(單調性) 設f是2TLIGPOWA算子,如果(sxi,axi)≥(syi,ayi)(i=1,2,…,n),則 f((u1,(sx1,ax1)),(u2,(sx2,ax2)),…, (un,(sxn,axn)))≥f((u1,(sy1,ay1), (u2,(sy2,ay2),…,(un,(syn,ayn))) (11) bimin≤ f((u1,(s1,a1)),(u2,(s2,a2)),…, (un,(sn,an)))≤bimax (12) 定理3(置換不變性) 設f是2TLIGPOWA算子,(syi,ayi)是(sxi,axi)的任一置換,則 f((u1,(sx1,ax1)),(u2,(sx2,ax2)),…, (un,(sxn,axn)))=f((u1,(sy1,ay1), (u2,(sy2,ay2),…,(un,(syn,ayn))) (13) 定理4(冪等性) 設f是2TLIGPOWA算子,對于任意i,均有(si,ai)=(s,a),則 f((u1,(s1,a1)),(u2,(s2,a2)),…, (un,(sn,an)))=(s,a) (14) f((u1,(s1,a1)),(u2,(s2,a2)),…,(un,(sn,an)))= 許多研究者致力于研究算子屬性權重,常用的屬性權重確定方法有最小方差法、最小離差法、貝葉斯最大熵法以及一些拓展的權重方法,如加權函數法、最小距離法、改進的極大極小差距模型等,這些方法的共同特點是從公平性角度確定權重,換言之,所有屬性都應該被認為是同樣重要的[26]。但上述方法忽略了輸入變量信息對確定屬性權重的影響,即他們均認為屬性值的分布對確定屬性值沒有影響。例如,對于兩個矩陣X1和X2(X2是由X1的列向量互換得到),即 若按照上述學者的定權模型,對X1和X2中相同屬性,將會得到相同的權重,這顯然存在不合理之處。 此外,在實際決策矩陣中,對于一個給定的屬性,若在同一個屬性下每一個方案的屬性值幾乎相同,那么在選擇方案時該屬性作用不大,權重賦予得應當較小一點;反之,倘屬性值差入較大,則對該屬性應賦予一個較大的權重。為此,本文考慮公平性并兼顧屬性值的差異性,創造性地提出一個非線性二次偏差最優定權模型,即 (15) 式中:k1,k2為相對重要程度;Dij為規范化處理后的屬性值。 當k1=0時,表示決策者希望每一個屬性權重盡可能相等。當k2=0時,表示決策者希望屬性所有偏差最大化。 ILPOWA算子與2TLIGPOWA算子的異同可歸納為以下諸點。 相同點:(1)模糊環境下的屬性值描述是以語言變量來表征的。(2)均考慮了概率信息和誘導變量進行多屬性決策。 不同點:(1)拓展的ILPOWA算子是在語言變量的基礎上進行細化,利用二元語義進行屬性值的描述,使屬性值更加精確。(2)參數λ不一樣的取值可表征不一樣的集結算子,擴增ILPOWA算子的可用范圍,ILPOWA算子是2TLIGPOWA算子的一特例。(3)搭建了一個新的權重模型,使決策更與實情相符。 2TLIGPOWA算子的主要優點在于它能夠在不精確的環境下,利用概率和決策者的態度特征來分析語言信息,即它能夠在分析風險和不確定問題時形成一個語言決策。基于2TLIGPOWA算子的財務管理決策方法如下: 步驟1A={a1,a2,…,am}作為方案集,T={T1,T2,…,Tn}作為方案的性質或屬性,構成評價矩陣sk。 步驟4歸一化處理該綜合評價矩陣,再以式(9)來確定屬性權重。 步驟5利用2TLIGPOWA算子對應的公式進行計算,按照之前的計算步驟選擇最好的決策結果,同時,將方案按照從最優到最差進行排序,以便于選取多個方案時的靈活運用。 該方法是有普適性的,它可用于財務投資、融資、經營及利潤分配等財務管理各方面。 本文以電力企業的財務投資為例,來檢驗基于2TLIGPOWA算子的財務管理決策法的有效性。某電力企業擬對5個備選方案作選優投資,分別是A1、A2、A3、A4、A5,為了保證決策的準確性和有效性,決策者必須客觀地考慮盡可能出現的所有結果,即考慮非常好的經濟形勢(T1)、好的經濟形勢(T2)、一般的經濟形勢(T3)、差的經濟形勢(T4)、非常差的經濟形勢(T5)這五種情況。 步驟1三個專家進行群決策分析,每人對每一種方案根據未來可能出現的情形提出自己的觀點。由于所給信息可變且模糊,因而專家們以語言信息來對方案作評,在0~8的粒度中進行評價,根據可能出現的兩個標準形成二元語義評價矩陣(見表1)。按照以上方法,相應可以得出其他兩個專家的評價矩陣(見表2、3)。 表1 第一個專家評價矩陣 表2 第二個專家評價矩陣 表3 第三個專家評價矩陣 步驟2通過專家對于各個方案的綜合評價,將三個矩陣集結為一個評價矩陣。假設每個專家的權重為Z=(0.3,0.4,0.3),利用加權平均算法可以得到基于三個專家評價的綜合評價矩陣,如表4所示。 表4 綜合評價矩陣 步驟3為了更好地進行決策分析,使用誘導變量u=(13,5,8,15,7)來表達決策的精確性。誘導變量的優點在于它能夠表達包括時間、壓力、個人特點等相關心理方面在內的復雜的決策過程。 接下來需要確定參數β、λ和概率p。假設β=0.5,λ=2,p=(0.2,0.1,0.2,0.3,0.2)。由于未來每一種情況都有可能出現,因此對于決策來說有具有不確定性。利用OWA算子能夠根據決策者的態度特征低估或高估概率結果。 步驟4將綜合評價矩陣進行歸一化后,相對重要性p1、p2分別為0.6和0.4,代入非線性二次偏差最優定權模型中進行最優化分析,得到權重向量為 w=(0.187,0.140,0.092,0.268,0.313) 步驟5利用2TLIGPOWA算子進行集結,結果如表5所示。 表5 各方案集結結果 由表5可知,方案排序為A3>A5>A4>A2>A1,得到第3個方案最優,即選擇A3來投資。 本文主要研究了二元語義的多重屬性財務掌控管理決策問題,結合研究內容提出一個新的集結算子,并探討了它的相關性質,依據同一屬性下不同方案的屬性值情況建立非線性二次偏差最優權重模型。基于上述研究結果,結合決策者具備的概率特征,提出一種基于概率信息的多屬性財務管理決策方法。在現實狀況下,在財務掌控管理決策的過程中,決策者可以根據具體狀況對算子參數作出調整,來獲得一個更好的財務管理決策方案。在多屬性財務管理決策問題的未來研究中,可以在模糊不確定以及區間不確定性環境下進行進一步的探討。 參考文獻: [1] Yager R R,Filev D P.Induced ordered weighted ave-raging operators [J].IEEE Transactions on Systems,Man and Cybernetics,1999(2):141-150. [2] Yager R R.Generalized OWA aggregation operators [J].Fuzzy Optimization and Decision Making,2004(3):93-107. [3] 周禮剛,陳華友,王曉,等.誘導連續區間有序加權平均算子及其在區間數群決策中的應用 [J].控制與決策,2010(2):179-184. [4] Wan S P,Feng W,Lin L L,et al.Some new genera-lized aggregation operators for triangular intuitionistic fuzzy numbers and application to multi-attribute group decision-making [J].Computers & Industrial Engineering,2016(1):286-301. [5] 譚睿璞,張文德.基于廣義直覺語言算子的多屬性群決策方法 [J].控制與決策,2016(11):2005-2012. [6] Merigó J M.Probabilities in the OWA operators [J].Expert Systems with Applications,2012(3):11456-11467. [7] Merigó J M,Anna M,Gil L.Induced 2-tuple linguistic generalized aggregation operators and their application in decision-making [J].Information Sciences,2013(4):1-16. [8] Merigó J M,Montserrat C,Daniel P M.Linguistic group decision-making with induced aggregation ope-rators and probabilistic information [J].Applied Soft Computing,2014(4):669-678. [9] 于超,樊治平.考慮決策者行為的新產品開發方案選擇方法 [J].沈陽工業大學學報(社會科學版),2017(2):134-138. [10]Yari G,Chaji A R.Maximum Bayesian entropy me-thod for determining ordered weighted averaging opera-tor weights [J].Computers Industrial Engineering,2012(1):338-342. [11]Ahn B S.Extreme point based multi-attribute decision analysis with incomplete information [J].European Journal Operational Research,2015(3):748-755. [12]Yao O Y.Improved minimax disparity model for obtaining OWA operator weights:issue of multiple solutions [J].Information Sciences,2015(1):101-106. [13]劉培德,張新.直覺不確定語言集成算子及在群決策中的應用 [J].系統工程理論與實踐,2012(4):2704-2711. [14]王中興,劉久兵,陳晶.基于二元語言評價的群決策方法 [J].數學的實踐與認識,2015(8):136-143. [15]谷云東,高建偉,劉慧暉.基于二元語義前景關聯分析的風險型多準則決策方法 [J].控制與決策,2014(9):1633-1638. [16]林義征,袁宏俊,宋馬林.基于相關性指標與廣義IOWA算子的區間型組合預測模型 [J].統計與決策,2016(6):8-12. [17]Zeng S Z,Merigó J M,Su W H.The uncertain probabilistic OWA distance operator and its application in group decision-making [J].Applied Mathematical Modelling,2013(9):6266-6275. [18]Daniel P M.Linguistic group decision-making with induced aggregation operators and probabilistic information [J].Applied Soft Computing,2014(1):669-678. [19]Li C G,Zeng S Z,Pan T J,et al.A method based on induced aggregation operators and distance measures to multiple attribute decision-making under 2-tuple linguistic environment [J].Computer and System Sciences,2014(7):1339-1349. [20]Bapi D,Debashree G.Partitioned Bonferroni mean based on linguistic 2-tuple for dealing with multi-attribute group decision-making [J].Applied Soft Computing,2015(4):166-179. [21]文杏梓,羅新星,歐陽軍林.基于決策者信任度的風險型混合多屬性群決策方法 [J].控制與決策,2014(3):481-486. [22]陳華友,何迎東,周禮剛,等.廣義直覺模糊交叉影響平均算子及其在多屬性決策中的應用 [J].控制與決策,2014(7):1250-1256. [23]Zhou L G,Chen H Y.On compatibility of uncertain additive linguistic preference relations based on the linguistic COWA operator [J].Applied Soft Computing,2013(8):3668-3682. [24]Zhou L G,Wu J X,Chen H Y.Linguistic continuous ordered weighted distance measure and its application to multiple attributes group decision-making [J].Applied Soft Computing,2014(5):266-276. [25]劉金培,林盛,陳華友.二元語義Bonferroni集成算子及其在多屬性群決策中的應用 [J].運籌與管理,2013(5):122-127. [26] Wan S P.Some hybrid geometric aggregation operators with 2-tuple linguistic information and their applications to multi-attribute group decision-making [J].International Journal of Computational Intelligence Systems,2013(4):750-763.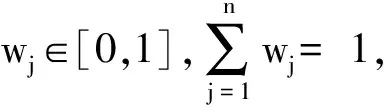
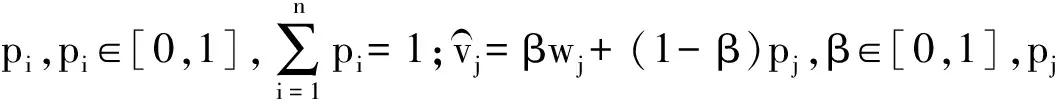
二、2TLIGPOWA算子的構建
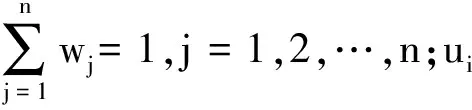
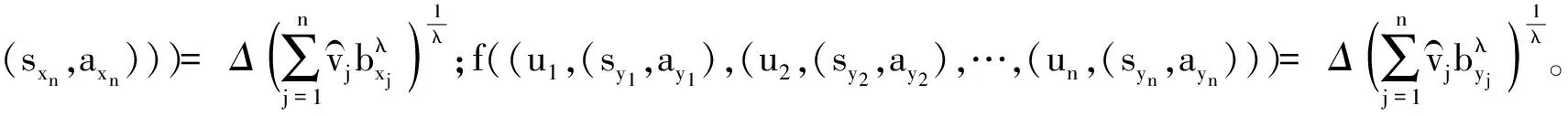
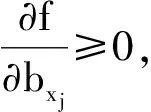
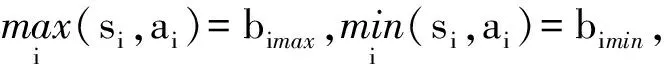
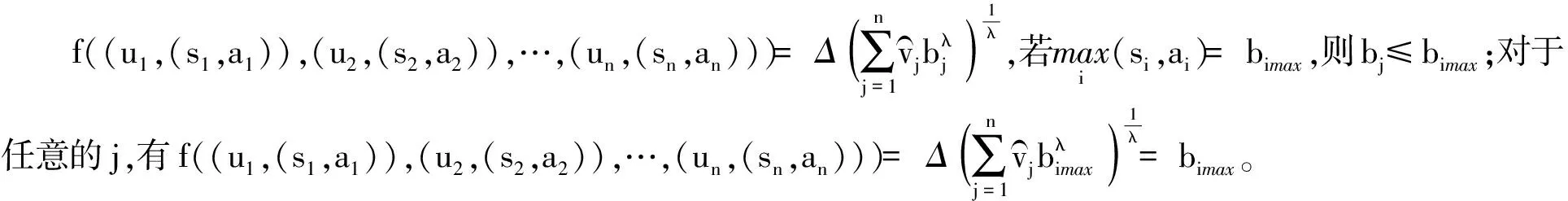
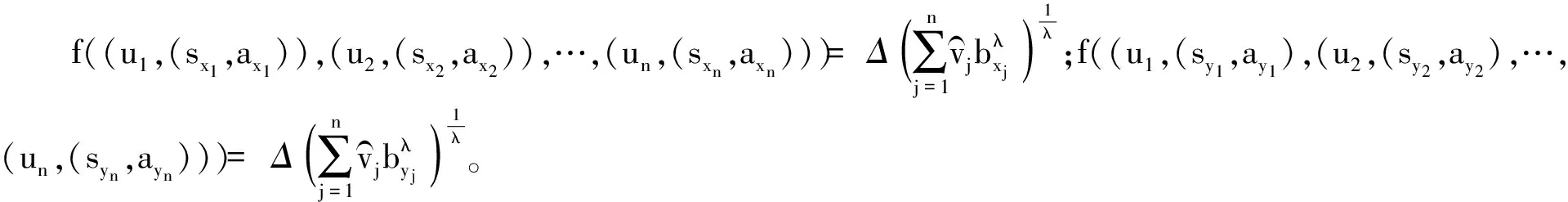
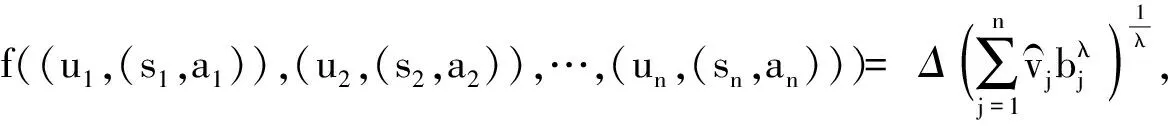
三、屬性權重模型
四、基于2TLIGPOWA算子的財務管理決策方法
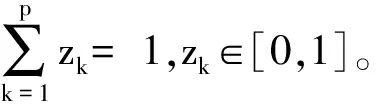
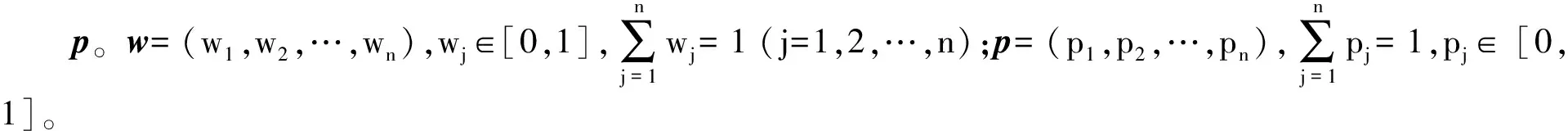
五、算例分析



六、結 論
猜你喜歡
石油瀝青(2021年4期)2021-10-14 08:50:44
世界科學技術-中醫藥現代化(2021年10期)2021-03-02 05:52:06
開放教育研究(2020年2期)2020-03-31 01:54:14
現代語文(2016年21期)2016-05-25 13:13:44
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
大連民族大學學報(2015年2期)2015-02-27 08:28:11
中國工程咨詢(2015年2期)2015-02-14 02:59:26
俄羅斯問題研究(2012年1期)2012-03-25 09:54:51
體育師友(2012年4期)2012-03-20 15:30:10
當代修辭學(2011年6期)2011-01-29 02:49:50
